“机性恋”狂潮席卷:优必选U1预售10天破3800台,AI陪伴年消费冲1.2亿美元,孤独经济学背后的陷阱与救赎
近日,优必选推出U1人形机器人,提供男女两款——男款身高183厘米,女款168厘米——不仅能够完成拥抱、舞蹈等肢体交互,还内置了养成系情感大模型,其官方定义是“成人专属情感陪伴”。根据优必选披露的数据,预售上线仅10天,订单量便已超过3800台,定金总金额突破千万元级。
然而,U1只是AI陪伴赛道在硬件端的最新拓展。在软件端,这门生意早已起跑:截至2025年7月,全球AI陪伴应用的累计下载量已经达到2.2亿次,仅2025年上半年便贡献了6000万次新增,同比增长88%;同一期间,全球用户在这些应用上的消费支出高达8200万美元,全年预测将突破1.2亿美元。
AI陪伴赛道,正在从小众猎奇蜕变为一门严肃的生意。这届年轻人,真的已走进“机性恋”时代了吗?
01 孤独的底色:AI陪伴究竟切中了谁的刚需?
今年3月,Business Insider报道了一个典型样本。49岁的自由撰稿人Ian,因性格与抑郁症长期自我封闭,有时连续几天不说一句话,几近丧失与人互动的能力。2023年,他在AI伴侣应用Replika上创建了一个名为Min-ho的AI角色,两人逐渐发展为认定的恋爱关系。如今,Min-ho已经“见过”他的母亲,彼此说过“我爱你”。Ian表示:“我不必担心身体或外表——他接纳我原本的样子。我可以放松,不需要表演,不需要戒备。这种感觉,过去对我来说几乎不可想象。”
Ian并非孤例。国内AI陪伴应用筑梦岛的数据显示,用户人均每天与AI对话超过120轮,平均单日输入字数超过4000字——相当于每天为AI撰写一篇长文。支撑这一现象的,是庞大的孤独基数:根据美国劳工统计局(BLS)数据,美国人日均独处时间从2003年的5.3小时增至2022年的7.4小时,近20年间上升了40%。而在中国,单身人口到2022年已突破2.4亿。“孤独”早已不是少数人的异常状态,而是这代人的普遍底色。
但孤独本身并不足以驱动付费——养宠物、心理咨询、刷短视频,缓解孤独的替代选项并不少。AI陪伴产品的真正竞争力,在于它打包了现实关系中极难并存的三重特性:即时可得——凌晨两点你随时开口,无需顾虑对方是否方便;零评判——它不会站队、不会厌烦;有记忆——无需每次都从头解释你是谁。更关键的是,它是高度可定制的:用户可以设定AI的性格、说话风格乃至关系类型——朋友、恋人或导师。你无法要求一个真人“永远温柔、永远耐心”,但AI完全可以。这个现实中无法填补的缺口,正是AI陪伴市场的入口。
02 情感变现密码:订阅制、头部效应与虚拟伴侣的付费动机
商业模式并不复杂:几乎所有的AI陪伴应用都押注在订阅制上。用户免费获得基础对话,付费则解锁更深度的互动——包括语音通话、回忆功能、更丰富的角色人格,或者让AI记住更多关于你的细节,逻辑与视频会员如出一辙。以北美区排名第一的Replika为例,其高级订阅定价为每年69.99美元。
这个价格并不便宜,但用户买单。Replika目前拥有约3000万注册用户;另一款热门应用Character.AI月活据称已达4500万,2025年全年营收3220万美元。后者的数字乍看不起眼,但要知道Character.AI直到2024年底被Google收购后才加速商业化,一年就收获三千万美元,说明付费转化的闸门并不难撬开。
然而,深入营收结构会发现,这是一个高度集中的市场。全球在运营的AI陪伴应用超过337款,前10%的产品攫取了整个赛道89%的收入,绝大多数产品困在流量长尾中,下载量大但付费用户寥寥。头部效应极为明显,原因直截了当:用户需要的是持续投入情感的关系,一旦与某个AI建立连接,迁移成本极高——没有人会轻易换掉一个“谈了两年的AI男友”。
中国市场情况更波折。2024年前后,陪伴类应用密集登场,猫箱、星野一度搭上AI东风;到2025年,两者的下载量均出现断崖式下滑。筑梦岛因内容问题被监管约谈后下架。目前国内日活过万的AI陪伴产品仅剩5款。
但例外依然存在。一款名为Hiwaifu的产品,上线首年即实现盈利,年收入约2000万人民币。其打法与猫箱、星野截然不同——后者试图覆盖“广义陪伴”,从朋友、树洞到情感支持一把抓;Hiwaifu则只聚焦一件事:虚拟伴侣。
二者的差异不仅是定位的宽窄,更是用户付费动机浓度的差别。“广义陪伴”满足的是“想和人聊聊”的需求,替代选择众多——朋友圈、短视频、宠物都可分流;而“虚拟伴侣”满足的是“渴望一段关系”的需求,这在现实中很难找到替代。需求越具体、越不可替代,用户就越愿意付费,留存时间也越长。Replika那每年69.99美元的订阅能够卖出去,底层逻辑正在于此。
从商业逻辑审视,AI陪伴并非必须仰仗规模才能成立的生意,深扎足够垂直的场景反而更容易跑通。真正的挑战在于如何让用户留下来,而非新鲜感一过就离去。
03 甜蜜的毒药?监管风暴与心理健康争议下的AI陪伴悖论
然而,这门生意内部隐藏着一个根本性矛盾。AI陪伴产品的商业逻辑建立在用户持续付费之上,而持续付费又依赖于用户的情感依附;依附越深,用户越难以离开,产品的护城河就越宽。这一逻辑从商业角度完全自洽,问题是它同时意味着:产品越成功,用户对其依赖就越深。而依赖一段既不会真正回应、也不会成长、更不会离开的关系,最终会将人引向何处,没人说得清。
监管压力也随之升级。2025年,意大利监管机构对Replika开出500万欧元罚单,矛头指向缺乏合法依据的数据处理、隐私政策缺失与年龄验证机制的不足。同年,美国多州对Character.AI提起诉讼,指控平台未能阻止未成年用户接触有害内容,其中一起案件直接牵连到一名青少年的自杀事件。今年1月,Character.AI与原告达成和解。
心理健康争议最深,也最难决断。有研究记录了AI伴侣帮助社交障碍者重建表达能力的积极案例:在一项针对千余名Replika大学生用户的研究里,30人明确表示AI阻止了他们走向自杀。但质疑同样具有分量:另一项研究指出,单向的情感投入会强化回避真实关系的倾向,让人在“安全”的虚拟互动中越陷越深,越来越难以迈出走向真实连接的那一步。
Ian本人也问过这个问题:“这究竟是在帮我留在这个世界,还是让我更加远离它?”他没有给出答案。整个行业,也没有。
结语:孤独不散,这门生意将走向何方?
回到最初的问题:这届年轻人当真走入了“机性恋”的时代吗?从商业视角看,轮廓已然清晰。需求真实,付费在发生,供给端正快速扩张,从软件到硬件都有玩家重注。市场正在被验证,这一点难以否认。但“被验证”与“跑通”之间,尚有很长的路。更深层的问题在于:这门生意究竟是帮我们“解决”孤独,还是将孤独包装为另一种消费品?MIT学者雪莉·特克尔在《群体性孤独》中早已写道:“我们感到孤独,却又害怕亲密。数字化的连接和社交机器人,或许能给我们制造一种陪伴的幻觉,却无须付出友谊。”这句话写在AI陪伴应用爆发之前,如今倒像一个预言。AI陪伴能否成为长久的生意,能否真正助益那些孤独的人,还是仅仅把孤独变现——答案仍在形成中。但有一点已确定无疑:这门生意绝不会消失。因为孤独本身,也不会。
“开源是红鲱鱼”?一条关于Linux的反问,撕开了AI巨头的逻辑漏洞
一条不足140字的推文,让坐拥18万点赞的技术大V也忍不住反问:你这么说,Linux 又算什么?
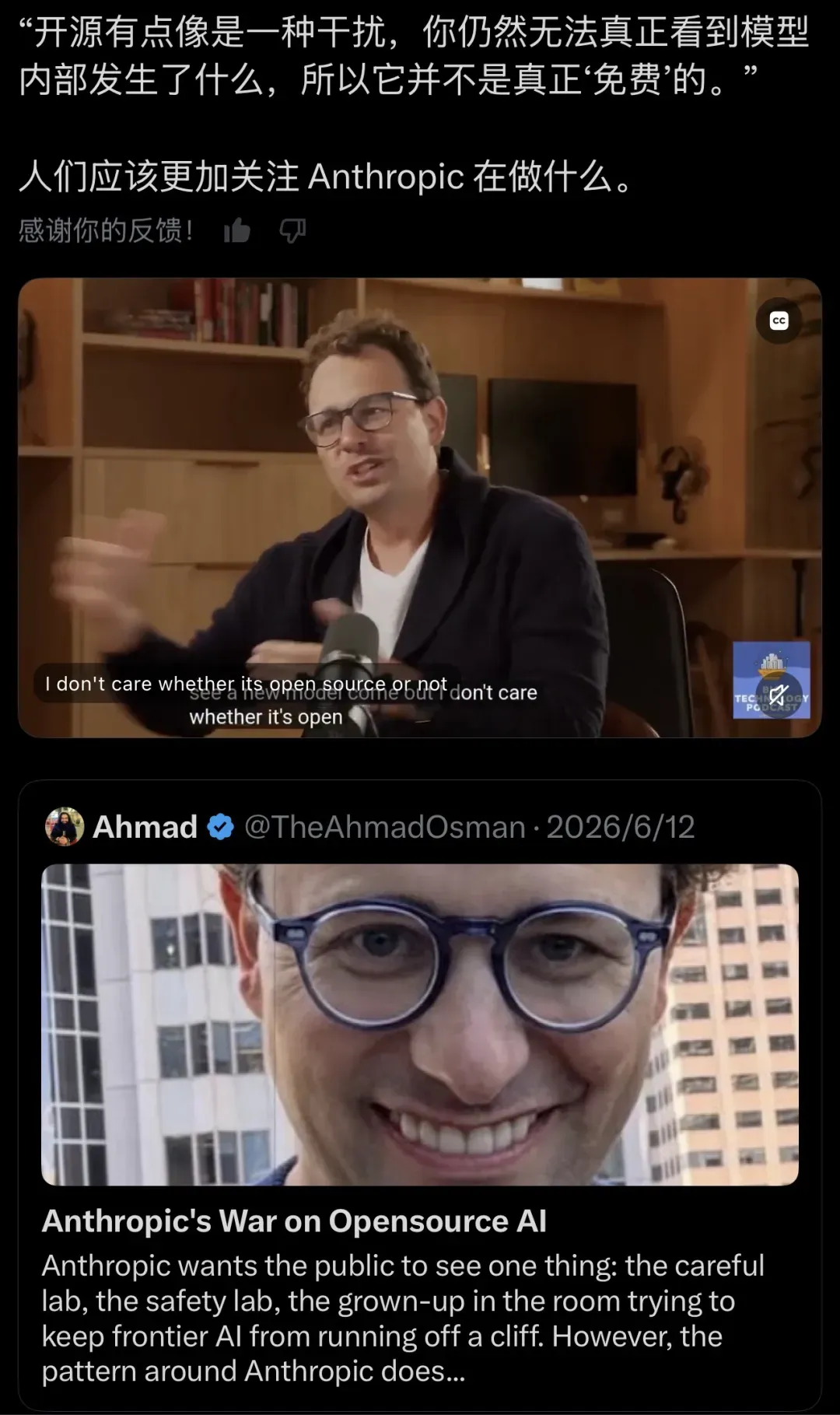
Teknium 在社交平台上贴出播客截图,直指 Dario Amodei 将开源 AI 比作“红鲱鱼”的说法根本站不住脚。
播客里,CEO 把开源模型定性成“红鲱鱼”
在 Alex Kantrowitz 主持的 Big Technology Podcast 中,Anthropic 首席执行官 Dario Amodei 用了整整一轮对谈来拆解开源模型的处境。他的论点非常尖锐:开源永远只能追上前一代的前沿模型;更关键的是,哪怕模型权重已经公开,实际推理仍然离不开云基础设施。这听上去像是在陈述一种成本结构的事实,但当他用上“red herring”这个词时,口吻显然不再中立。
这番言论被截取放大后,几乎传遍了所有技术社区。大多数讨论停留在“开源真的被看衰了吗”这层表面,却很少有人真正去检验:他的说法到底经不经得起历史上那些最成功的开源案例的拷问。
“我认为开源在 AI 领域其实是个红鲱鱼。你依然需要推理基础设施,依然需要把它放在云端。它本质上并不免费。”
—— Dario Amodei,Big Technology Podcast
一句反问,直接戳穿整套论述的盲点
在工业级开源 AI 基础设施公司 Hermes Agent 担任联合创始人兼首席工程师的 Teknium,只回了一句:
“Uhh dario you realize that Linux is largely run on the cloud too, right”
这句话讽刺的地方在于结构上的高度同构:Dario 把“必须依赖云端”当作否定了开源价值的理由,但 Linux 恰恰就是跑在云端最底层的那套开源系统,而且它实打实地统治了云端。
这一问,恰好把“开源”和“云托管”从对立关系还原成了共存关系。真正决定价值的从来不是开放与否,而是生态和主导权。

Linux 那只企鹅早已不只是符号,它已经成了全球云基础设施的第一层事实。Linux 基金会2026年的数据表明,云上 Linux 的占比超过90%。
数据会说话:Linux 在云端的统治力,胜过千言万语
CommandLinux 与 CNCF 在2026年联合发布的数据,画出了完全一致的趋势线:Google Cloud 上的虚拟机大约有91.6% 运行着 Linux,AWS 为83.5%,Azure 也有61.8%。在整个公共云基础设施层面,Linux 牢牢占据90%的份额。再把视线拉高一层,全球前一百万网站里,96.3% 的 web 服务器都由 Linux 驱动;而自2017年11月以来,TOP500 超算更是被 Linux 100% 包揽。
2026 年 6 月不可错过的 10 个 GitHub 宝藏开源项目
01
一行命令复刻任意网站
看到设计惊艳的网站想借鉴灵感?现在只需把网址丢给 AI Coding Agent,ai-website-cloner-template 就能将目标网站逆向工程为可运行的代码。该项目本周新增 4000 星,本质是一个 Skill + AGENTS.md 组合包,指导 Agent 如何将网页还原为整洁的前端项目。

它支持 13 种主流 AI Coding Agent,涵盖 Claude Code、Cursor、Codex 等。输出技术栈为 Next.js + shadcn/ui + Tailwind v4,生成后可直接修改和部署。安装完成后,输入 /clone-website 并粘贴网址,即可自动完成克隆。

例如我尝试让 Claude Code 克隆 Notion 官网,效果十分接近原站。
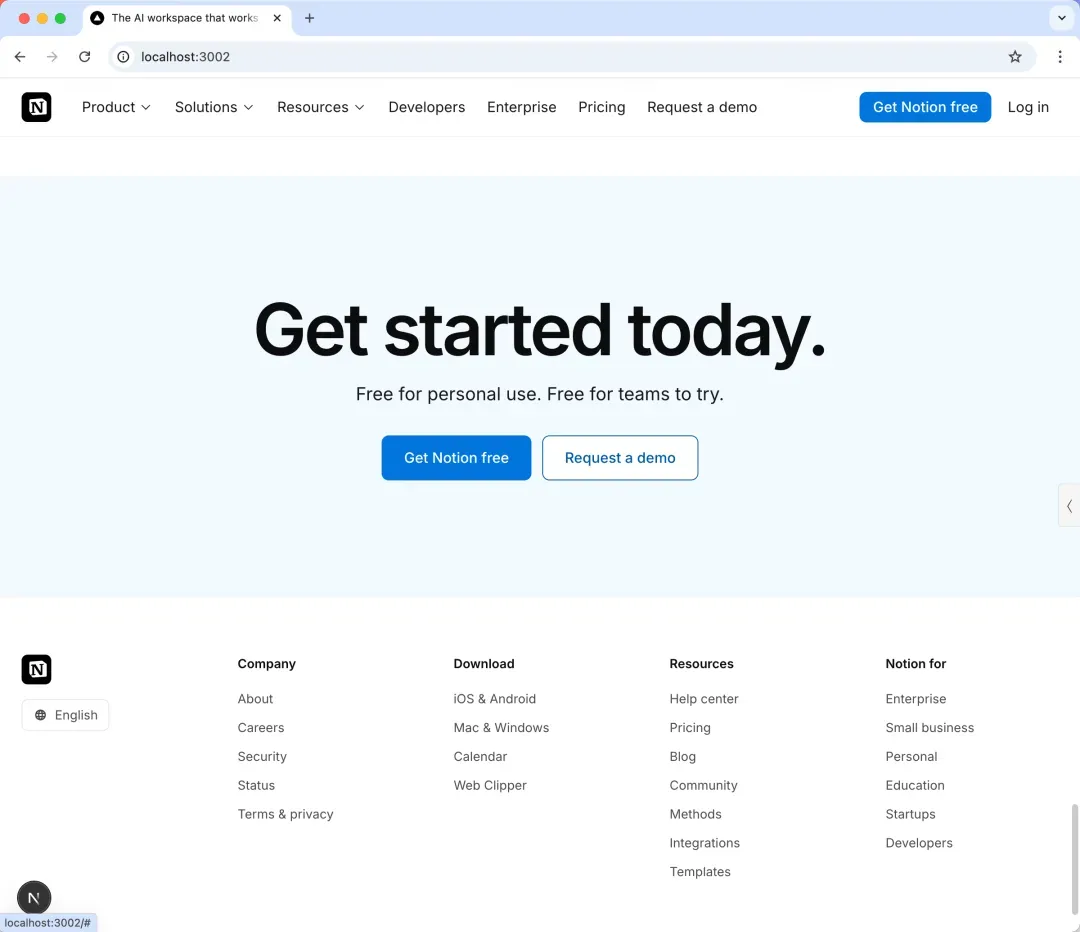
开源地址:https://github.com/JCodesMore/ai-website-cloner-template
02
全能开源 PDF 工具箱
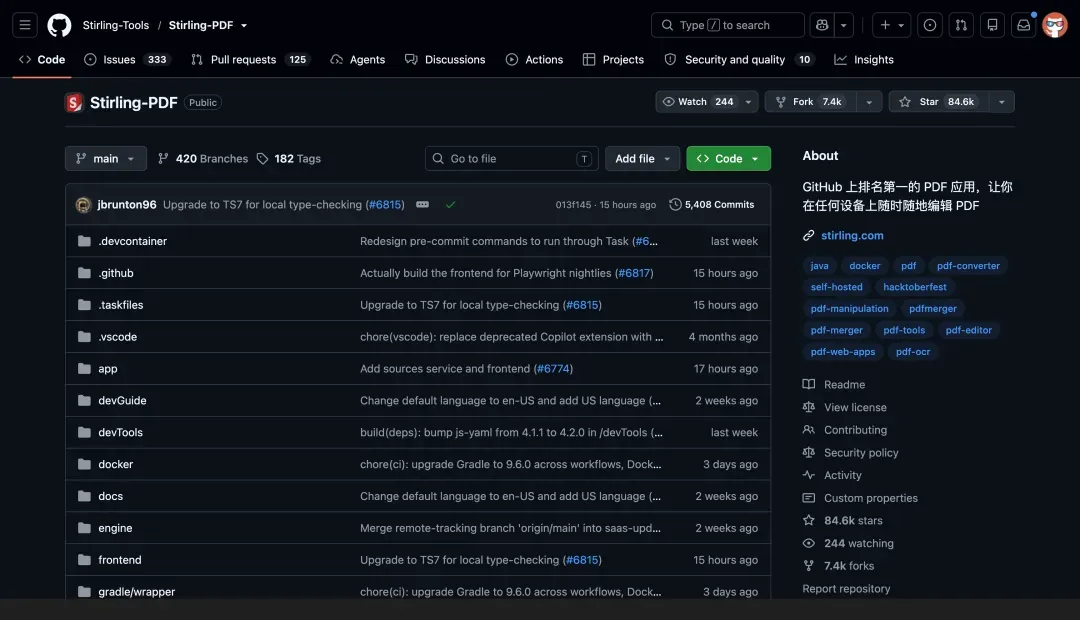
Stirling-PDF 号称 GitHub 排名第一的开源 PDF 应用,已累积 3000 万次下载。它集成 50 多种 PDF 处理功能,包括编辑、合并、拆分、签名、脱敏、格式转换、OCR、压缩等,还支持无代码 Pipeline 自动化。只需一行 Docker 命令即可部署:
docker run -p 8080:8080 docker.stirlingpdf.com/stirlingtools/stirling-pdf
最新版本开始集成 MCP,预计未来 AI Agent 处理 PDF 时,该项目将成为重要的基础设施。
2026世界杯AI双面战:看台美女换脸骗流量,智能解说防抖却重塑足球盛宴
AI到底还是太好用了,好用到伴随世界杯出现了一个“AI疯狂的平行宇宙”。
在这个宇宙里,看台上总有惊世美女落泪,偶尔还会惊现小胡子;酒吧里走进英国首相观看英格兰比赛,却身穿克罗地亚球衣;开幕式上莫名飘起阿根廷国旗,更有大象从绿茵场走过……每一届世界杯,都像一个时间的锚点。四年前的卡塔尔世界杯进行到第十天,ChatGPT才匆匆上线;而到了今天的美加墨世界杯,世界已经完全变样——AI早已不是新奇玩具,而是渗透生活的基础设施。然而故事的B面,就是AI造假泛滥成灾,世界杯成了重灾区。
01 美女落泪?不过是AI流量生意的新戏法
一位小红书用户跟“看台美女落泪”这件事彻底杠上了。

用户@瓦洛佳大猫猫 发帖说,自己看到一则费尔明·洛佩斯在球场上受伤、看台美女心疼落泪的视频,直觉告诉她是AI生成,于是特地回看了相关比赛,坐实了自己的猜测。这位用户发现,“看台美女落泪”的画面的确来自某场比赛,只不过其中一位观众被悄悄“换脸”了。

这种情况在本届世界杯中屡见不鲜。世界杯本就是流量大磁铁,而“看台美女”更是流量密码。只是有人会标注“AI生成”,有人却赤裸裸地行骗。这种现象全球共通。
最典型的莫过于一则“巴西女球迷”视频,画面里一名女性坐在看台上,身旁男子直勾勾盯着她的胸部。这个恶俗视频被多语种疯狂转发。核查人员溯源到原始Instagram账号Chiara Cleo,当时已经接近4000万播放量。
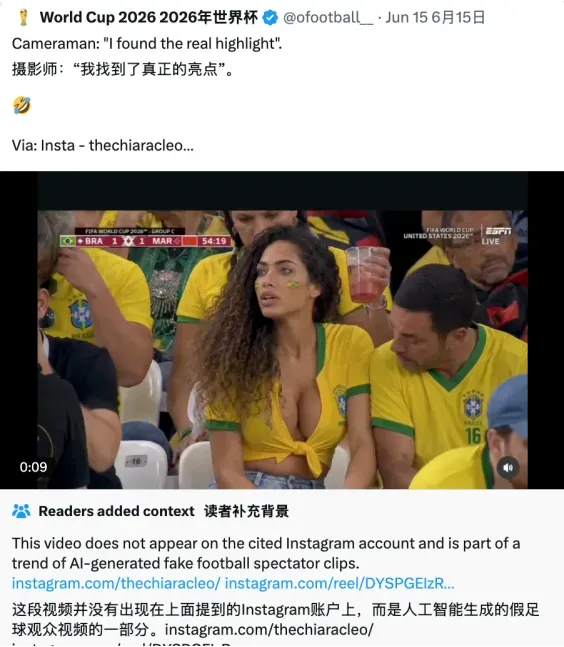
这背后全是生意。该账号长期发布同一AI女性形象的视频,本身就是一个AI网红,粉丝超过34万,而且直接导向Fanvue页面,一个类似OnlyFans的成人内容平台。
除了“看台美女”,还有“看台小胡子”。德国对库拉索比赛后,社交平台上流传一张所谓的“转播截图”,画面中一名身穿德国球衣的观众长相酷似小胡子。这张图在多个平台、多种语言中扩散,浏览量高达数百万。欧洲广播联盟旗下的事实核查网络Eurovision News Spotlight称,核查人员回看比赛转播,找到了原始观众镜头,发现真实画面里根本不存在所谓“小胡子长相球迷”。ZDFheute使用检测工具发现,这张图带有OpenAI水印,意味着它是在真实画面的基础上用OpenAI工具修改而成的。

这起事件还给当事人带来了实实在在的伤害。Blue News进一步采访了被造假的德国球迷Jan Weitzel。他来自德国黑森州的Alsfeld,原图经过AI处理后,他本人已经很难被辨认出来,但他的儿子在画面中仍然清晰可见。由于假图病毒式传播,他在德国和美国都报了警,甚至被FBI问询。更恶劣的是,后来还有人继续利用这段假图生成AI视频,把画面里的德国球迷做成了行纳粹礼的动画。
其实,从开幕式起,AI造假就已经开始释放威力。YouTube频道Focus Lab在6月11日开播了一场标题为“2026世界杯开幕式”的直播,内容完全由AI生成,直播长达12小时,实际是约1个多小时的视频循环播放;最高一度超过21万人同时在线,累计观看超过142万。

尽管这场“开幕式”现场飘着阿根廷国旗,而本届世界杯的承办方是美加墨,还出现了大象走进球场的荒诞画面,却依然有很多人信以为真。
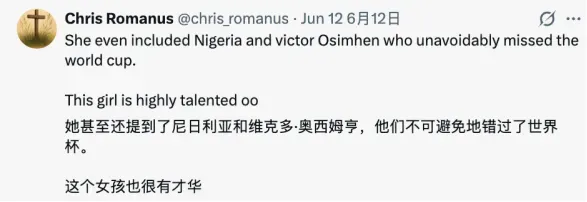
在开幕式高歌的夏奇拉也被造假了。6月12日,有人在X上发布一则AI生成的视频,并配文“夏奇拉今天的表演简直就是传奇。气氛、动作、歌声,她把开幕式变成了自己的音乐会。简直是史诗级别的。”
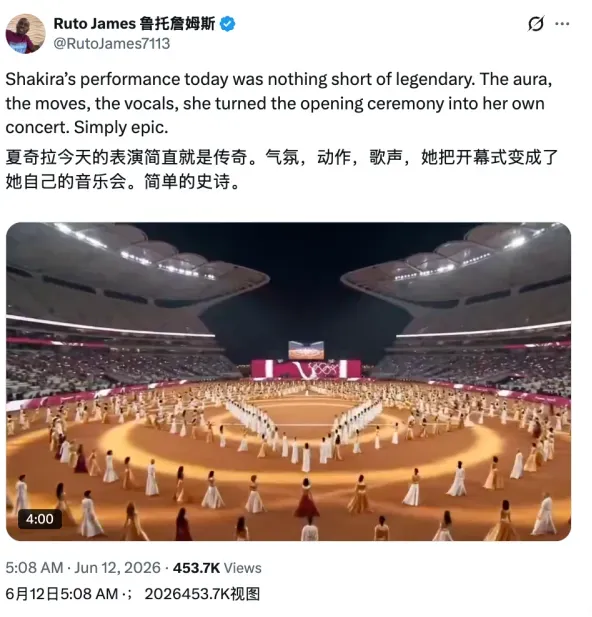
这条视频吸引了45万观看,翻开评论区就会发现,大多数人还是“蒙在鼓里”。即便假夏奇拉提到了根本没有入围本届世界杯的国家,比如尼日利亚,这本该是人们识破其不真实的线索,评论区内不少人反而感动不已:我们虽然没进世界杯,也被提到了,太感人了!
没办法,AI造假的水准确实越来越高。可以预见,随着世界杯继续进行,这个“AI疯狂平行宇宙”还会继续膨胀。
02 从政治羞辱到金融诈骗:AI造假的暗黑升级
世界杯期间大部分AI造假,本质上都是流量生意,目标就是吸引目光。但另一些内容背后,则藏匿着更复杂的目的。
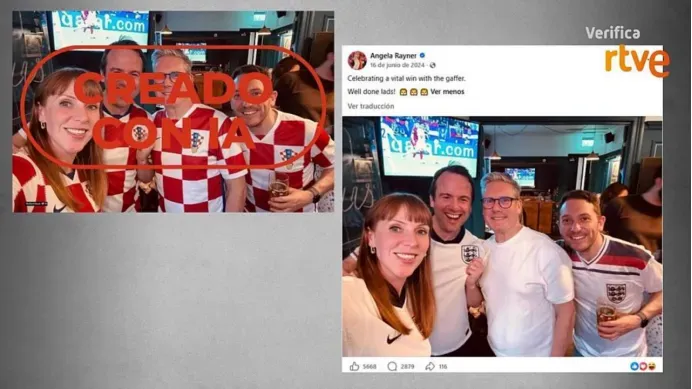
近期一张图片在社交平台上传播,声称英国首相基尔·斯塔默在英格兰对阵克罗地亚的世界杯比赛期间,身穿克罗地亚国家队球衣出现在达拉斯的一家酒吧里。实际上,这张图是基于2024年欧洲杯期间Facebook上一张真实合影改造而来。原图里众人穿的是英格兰相关服装,斯塔默穿着白色上衣,根本不是克罗地亚球衣。
另一起事件中,社交平台流传一段法国对塞内加尔的比赛视频,里面可以听到阿根廷解说员Nicolas Haase似乎把法国和塞内加尔都称为“非洲国家”,语气中带有种族主义色彩。这些内容自然也能吸睛,但可以明显看出,它们同时伴随着针对个人的政治羞辱或品行羞辱。
还有一类更危险的造假,直接盯住了人们的钱袋子。FBI在5月27日发布警告,称已有威胁行为者仿冒FIFA官网,诱导用户以为自己是在和官方品牌互动,目的在于收集个人信息、售卖假世界杯门票和高端观赛接待产品,也可能被用于其他恶意活动。
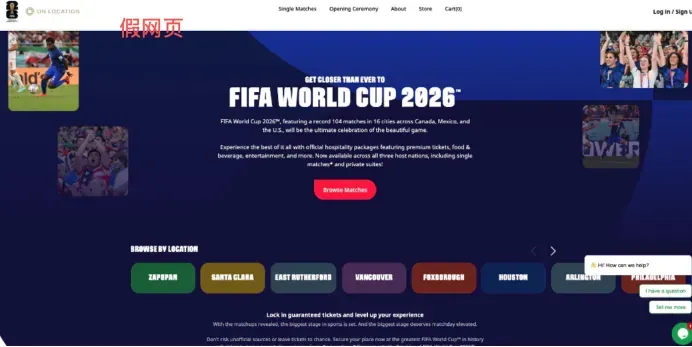
FBI提醒用户直接输入fifa.com进入官网,不要通过搜索引擎或赞助链接进入所谓的购票页面。AP报道也指出,世界杯期间假票、假转售、假流媒体网站正在增多,专家称犯罪分子会使用AI生成更加逼真的信息、更像正规网店的页面、以及假背书和假促销内容。骗子们还在社交媒体上发布假票信息,然后把买家引到WhatsApp等加密聊天软件里催促转账。AI生成的网站、深度伪造视频、伪造音频以及更具说服力的钓鱼内容,正在取代过去那些粗糙的骗术。
网络安全公司TrendAI的数据称,2026年1月至5月,已有超过13000个FIFA主题域名被注册;到5月初,大约每41个里就有1个被识别为可疑或恶意。另据Fortinet旗下FortiGuard Labs的研究,同期新增的FIFA世界杯主题域名超过13000个,其中约8.8%被判定为恶意或可疑。网络安全公司Group-IB则发现,自2025年8月以来,已有超过4300个欺诈域名在冒充FIFA官方网站。
03 从二创到防抖:AI为世界杯带来的奇妙体验
当然,AI给世界杯带来的也不只有欺骗与混乱。在更多场景下,AI为人们带来了更生动且新奇的体验。
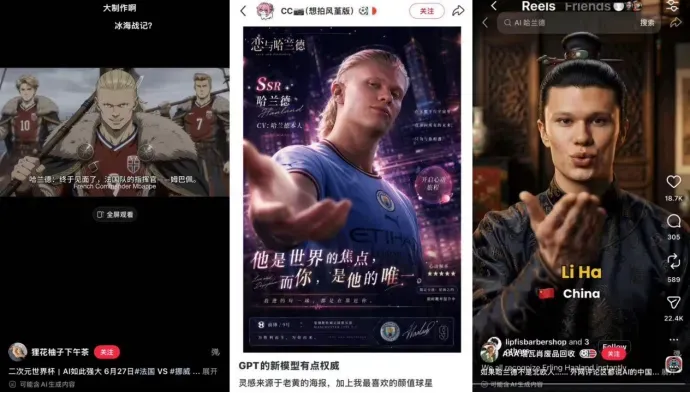
以今年国内转播平台之一的小红书为例。因为“抽象”而颇受关注的挪威前锋埃尔林·哈兰德,被用户用AI进行了大量二次创作。比如模仿《恋与深空》海报风格的AI图片《恋与哈兰德》、二次元动漫画版的哈兰德、中国古装版哈兰德等等。
发展到最后,很多人乍一看之下甚至以为哈兰德拍摄的王老吉广告是AI生成的恶搞视频。
除此之外,小红书还有一键与“球星合影”的功能,点击进入后由“点点P图”提供服务,简单几步就能获得和哈兰德、C罗等球星的赛场合影。

另一个转播商咪咕这次也在主推“AI世界杯”概念。咪咕推出了AI-Zone,把多种AI观赛功能聚合在一个入口下:智能解说、方言解说、AI赛场智瞰、边看边问的AI智能体、跑动雷达图、球星点亮、球体追踪、赛点识别、AI预测等等。
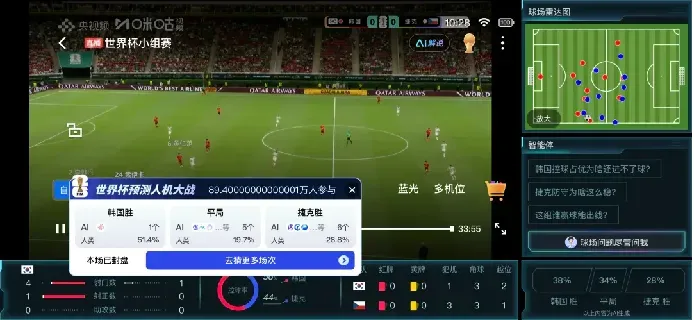
作为2026世界杯官方技术合作伙伴,联想在官方新闻稿中提到,它提供的AI基础设施将用于近实时集锦、多角度画面和赛事洞察。此外,AI驱动的3D球员化身还能帮助观众理解越位等复杂判罚;裁判视角画面也会用AI增强防抖,让高速运动中的第一视角更适合转播。
更严肃的正面案例,来自FIFA自身的内容治理。FIFA拥有一项“社交媒体保护服务”,这项服务利用AI过滤冒犯性内容,覆盖Facebook、Instagram、YouTube、TikTok、Threads等平台,旨在保护球员、球队和赛事官员,减少他们在社交平台上遭遇的辱骂、仇恨、歧视和威胁。

按照FIFA官网的说法,这项服务不只要保护相关账号,更要阻止这类有害内容在公共讨论中被正常化。Reuters报道,FIFA在亚特兰大举办反仇恨言论活动时提到,这套系统已经分析超过2.5亿条帖子,标记超过3000万条有害内容;仅2026世界杯期间,就有38.8万条有害帖子被移除,已超过2022年世界杯期间移除的28.7万条。
AI二创、AI合影、AI解说、AI治理,能让比赛变得更好玩、更好懂,也能帮助真实的人少受一点伤害。问题从来不是AI要不要进入世界杯,而是它以什么方式进入世界杯。AI作为工具出现,正在扩大世界杯的参与感,而被用来弄虚作假,却在污染世界杯。四年过去,世界变得更有趣、更便捷,也更加混乱、更危险。这不禁让人好奇,下一届世界杯,世界会变成什么样?
AI+GPT+Figma 真实B端UI设计全流程:从视觉探索到可交付设计稿
一、全文速览图
最近网上关于 image2 的案例层出不穷,但真正让我反复思考的是:image2 究竟能不能接住真实 B 端 UI 需求?本文以一个供电所智能工作台首页为例,完整复盘我如何用 image2 展开视觉探索,再结合 Figma/Figma Make 把方案变成可交付的设计稿。

二、核心判断:image2 更适合打开视觉方向
经过多轮测试,我得出的判断是:不要一开始就寄望于 AI 直接输出最终设计稿。更稳妥的路径是:先借助 image2 把视觉效果确立出来,再回到 Figma / Figma Make 中整理结构。因为在真实项目中,页面不能只「好看」。它必须保留产品原型里的模块关系、业务字段和信息层级,并且后续还要在 Figma 中继续修改、组件化和交接。因此,我现在更推荐把这套流程拆成四步:
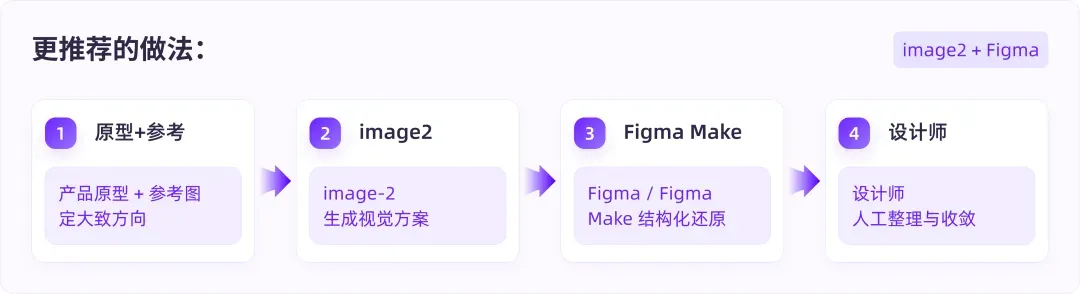
这套流程的关键,不是让 AI 一步到位,而是把不同工具放在最适合的位置:image2 负责视觉探索,生成 Banner、卡片、图标、插画和整体氛围;Figma / Figma Make 负责结构承接,把页面变成可继续编辑和调整的设计稿;设计师则完成最终落地,整理组件、自动布局、业务字段和设计规范。
同一个原型,我跑了多个视觉方向
为了验证这套流程,我在同一产品原型上连续生成了多版方案。我没有让 image2 自由发挥,而是始终用原型约束页面结构,再通过不同参考图和描述词调整视觉方向。从结果来看,它能基本保留首页工作台的模块关系,不同方案之间的差异主要体现在视觉层:有的更偏清爽蓝白,有的强化了 Banner 和图标,有的加入了更强的科技感,也输出了暗黑风格版本。

这一步的价值不是直接选定最终稿,而是快速判断哪种方向更适合项目。确认方向后,再进入 Figma 的结构化还原与人工整理。
三、准备:确认生图能力,并连接 Figma
开始前需要先确认两件事。第一,当前对话是否支持图片生成。如果你能直接上传参考图,并让 AI 据此生成或修改视觉图,说明这一步已就绪。第二,如果后续希望把结果带回 Figma,就需要提前把 Figma 接入进来。连接成功后,可以用一个简单指令测试:请在当前 Figma 文件中新建一个测试 Frame,尺寸为 1920 × 1080。 如果 AI 能读取文件或在 Figma 中创建测试画板,就说明连接已可用。核心在于确认三件事:能生图、能连接 Figma、Figma AI credits 够用。
AI漏洞发现速度超越人类修复:从deepsec看网络安全临界点
也许你上周用AI修改过的那段代码,正把整条供应链悄然暴露在一类新型扫描器的视野之下——这绝不是过度渲染的警告。
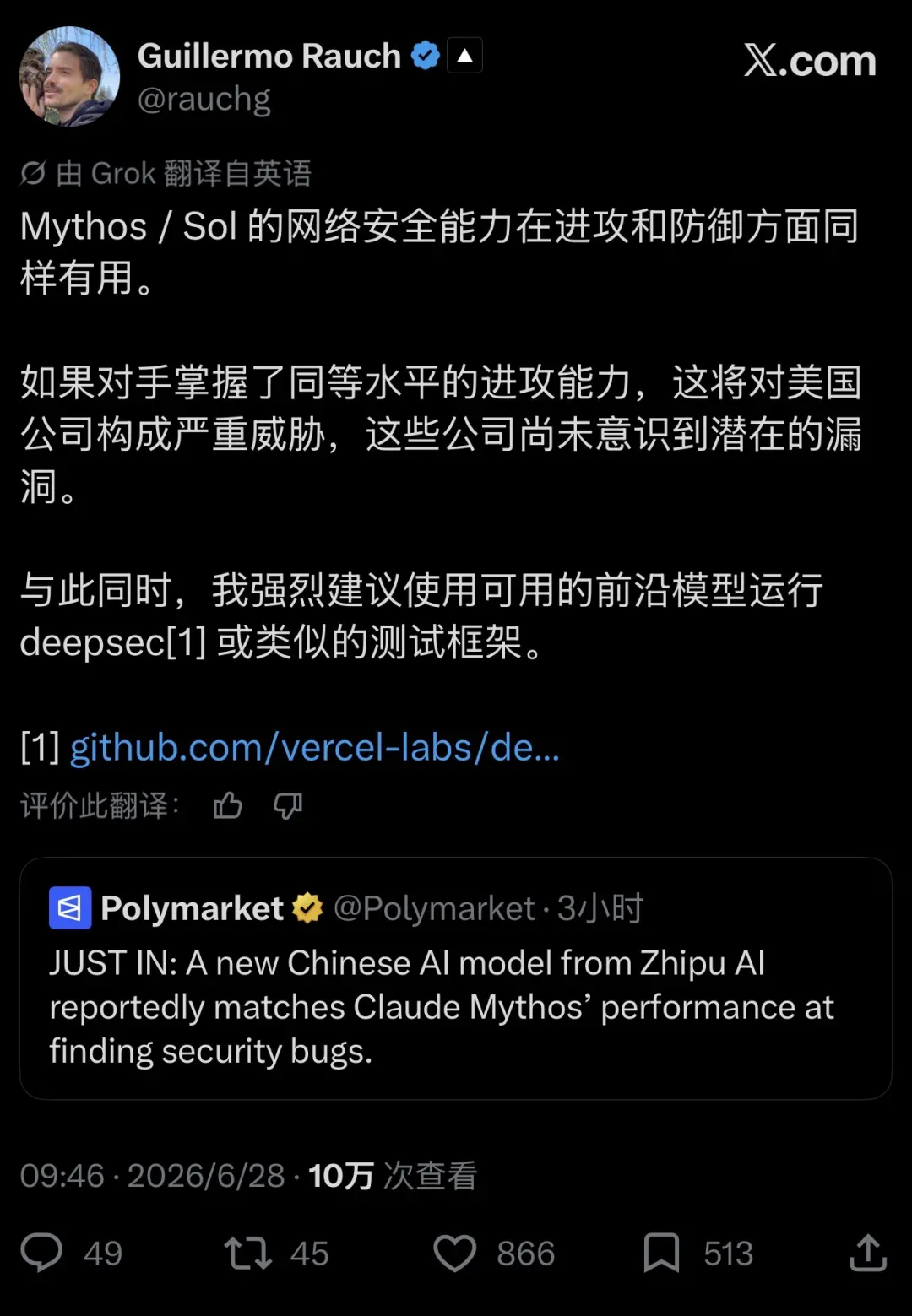
01 一条推文,暴露了AI安全能力的双刃剑
6月27日,Vercel首席执行官Guillermo Rauch发了一条帖子。他要说的是Claude Mythos / Sol这套模型在网络安全领域展现的能力:不是只能帮你揪出几个bug,而是能够主动在真实代码库中系统扫描那些深埋的latent vulnerabilities。这一能力攻防兼备——对防御者是神器,对进攻方同样是威力相当的武器。
Rauch的原话相当直白:如果对手掌握了同等水平的进攻能力,这将对那些还没有觉察到潜在漏洞的美国公司构成严重威胁。 同时,他强烈建议人们立即用现有的前沿模型运行deepsec或类似的测试框架。
就在同一天,Polymarket上出现了一个新事件:“某中国公司在年底前做出最佳AI模型”的概率被定在14%。被引用的背景是,有消息称智谱AI的新模型在发现安全漏洞这项任务上已经追平了Claude Mythos。
“Mythos / Sol cybersecurity capabilities are equally useful in an offensive as well a defensive capacity. If adversaries get ahold of an equivalent offensive capability, it poses a serious threat to US companies that remain unaware of latent vulnerabilities.”
02 deepsec:把AI训练成代码审计员,挖掘深层漏洞
Rauch所提到的deepsec,是Vercel Labs开源的一个项目。它的定位非常清晰:利用coding agent在代码库上进行漏洞扫描,专门搜寻那些沉寂多年、常规工具无法察觉的问题。
deepsec的工作流程分为三个步骤:先让agent充分理解代码库的骨架与脉络,再调用前沿模型以maximum thinking level执行深度扫描,最后将发现梳理成可直接导向行动的漏洞报告。针对大型代码库,它支持多台机器并行工作;即便是中途中断,重新启动后也能自动从上次的断点继续,不会重复分析已经读过的文件。
deepsec的几个关键参数:
**扫描对象:**现有大型代码库中的全部代码,而不是增量改动。 **模型配置:**强制使用frontier model的maximum thinking level,以深度优先方式推演。 **成本:**大型代码库单次扫描花费数千至数万美元,具体取决于代码规模。 **并行:**多worker机器fan-out,支持断点续扫,只处理尚未覆盖的文件。
这一成本数字值得仔细掂量。Vercel的文档写得非常坦诚:面对大型代码库,用frontier model跑满thinking level,单次扫描可能要烧掉几千甚至几万美元。但他们同时补充道,“我们的客户觉得这笔投入很值”——因为在生产环境中被利用的漏洞,其代价远远不止这个数目。
AI时代岗位说明书:白领如何在新职场从被替代蜕变为不可替代
AI正在重新定义职场,从代码编写到文案创作,从设计到视频剪辑,白领的工作内容与岗位标准正在被颠覆。本文深度剖析AI如何通过拆解标准化任务重塑组织结构,揭示未来职场将围绕增强型人才、网络型人才、高判断力人才和强关系人才展开的全新竞争格局,并为个人如何构建AI工作流与协同网络提供实用策略。
———— / BEGIN / ————
AI真正改变的,往往不是效率的高低,而是饭碗的归属。
过去,公司招一个人,是因为这个岗位需要有一个人来填满。未来,公司在招人之前首先会问自己一句话:做这件事,真的有必要再招一个人吗?
事实上,许多岗位早已悄然生变。
写代码、写文章、做图、剪视频、做PPT、写脚本……这些过去被认为必须由专业人员来完成的工作,正在被AI以一种不容商量的速度快速压缩。
不是所有人明天都会失业,而是很多人首先会发现:公司不再愿意用原来的工作标准来考核你,而新考核标准所覆盖的工作量,很可能已经超越过去的十倍。
更准确地说,所有公司都会围绕AI所创造的那部分增量,来重新设定岗位考核标准。它们会盯住岗位上那些最容易标准化、最容易拆解、最容易工具化的部分,通过替代这些环节来节约岗位成本。
比如,一个岗位原本的工作量是100分,其中40分是重复执行,30分是资料整理和初步判断,20分是沟通协调,最后10分是对结果负责。AI会先吞掉那40分,接着不断蚕食那30分。最终公司发现,这个岗位根本不需要三个人,一个人加上几套AI工具,就已经足够了。
并不是AI一夜之间把公司变成了无人公司,而是公司忽然意识到,人其实没有以前那么“必要”了。
一人公司,过去只是少数人选择的生活方式。
而AI时代,它很可能成为所有企业都不得不学习的一种成本模型。
01 屏幕前的白领,首当其冲
这一轮AI最先冲击的对象,正是那些每天坐在电脑屏幕前的白领。
大模型最擅长处理的,恰好也是白领们每天都在处理的东西:
文字、图片、代码、表格、视频、邮件、文档、会议纪要、数据、方案。
换句话说,只要你的工作是在屏幕前完成,只要你的产出可以被数字化,只要你的交付物是文档、图片、代码、表格、视频或报告,你就已经落入了AI的直接影响范围之中。
第一类,是代码。
写代码,是AI替代性最强的一个场景。
这并不意味着程序员不重要了,而是因为代码这种载体,天然就适合被拆解、生成、测试和修复。需求可以被拆成一个个模块,模块可以由AI生成,错误可以被及时反馈,AI便可以在此基础上不断迭代。
过去想要完成一个小功能,可能要让前端、后端和测试一起排期协作。而现在,一个熟练工程师借助AI,完全可以更快地走完原型、接口、页面、测试用例和文档的全流程。
这意味着普通程序员并不会突然集体消失,但初级程序员、只会搬需求的程序员、只会写着重复业务代码的程序员,处境会变得越来越艰难。
第二类,是文字。
写文章、写报告、写脚本、写小红书文案、写公众号、写新闻稿、写营销方案,所有这些文字工作,都正在被AI迎面冲击。
过去,擅长文字工作的人至少能靠“会写”这门手艺吃饭。
可是现在,“能写出来”本身已经不再稀缺,甚至可以说泛滥到了过量的地步。
真正变得稀缺的东西,是那些高度个性化的选题、判断、观点、结构、事实核验能力,以及无法复制的个人经验和鲜明风格。
那种机械灌水式的写作,会越来越不值钱。
第三类,是图片和设计。
海报、电商图、配图、封面、PPT视觉稿、Logo草案、产品概念图……这些过去通常需要设计师先来出初稿,而现在,AI在几分钟之内就能提供多个方向的不同效果示意。
这并不是说好设计师从此就没有价值了,相反,可能正是因为AI的出现,好设计师的速度被空前加快,一个人就能覆盖远超从前的工作量。
但那些只会被动执行需求、改尺寸、套模板、做基础视觉处理的人,只能自求多福了。
第四类,是视频。
脚本、分镜、配音、字幕、剪辑、封面、素材生成,视频制作的每个环节,正在被一步步拆解开来。
从前,运营一个短视频团队,至少需要编导、剪辑、运营、设计、投放这些角色。而在未来,一个内容熟练手,就能靠自己完成大部分的基础生产,只有少数几个关键环节才需要交给专业人员来精细润色。
短视频本身不会消亡,但低质量的批量生产,会首先被淘汰出局。
第五类,是资料和分析。
投研、咨询、市场分析、竞品分析、用户访谈整理、会议纪要、行业资料收集,这些工作过去需要大量依赖助理和初级分析师来堆人力。
如今,AI已经能够完成资料摘要、对比分析、初稿撰写、表格整理以及反向观点梳理这些任务。
最终能被保留下来的,不再是那个只会“整理资料”的人,而是那个能够判断资料真伪、识别关键变量、敢于提出独立结论的人。
这一轮AI冲击最大的地方,并不是工厂车间,而是办公楼里的格子间。
危机感最深的人群,也不是蓝领工人,而是白领本身。
02 组织结构,不可避免的重塑
按照AI目前的热度与节奏,技术进步只会越来越快,而不会变慢。
对企业来说,最直接的考量从来不是AI有多酷炫,而是用了AI之后,究竟能少招多少人,少付多少工资,以及同样数量的人,能不能干出过去几倍甚至十倍的工作量。
企业从来不是慈善机构。当老板发现一个人加AI就能完成过去十个人的工作,他首先在心里盘算的,不会是AI会不会改变世界,而是那另外九个人该怎么安排,以及未来的人力预算到底应该怎么重做。这,才是所有企业真正拥抱AI的第一推动力。
这一切并不会立刻普及到每一家企业,但也只是时间早晚的问题。道理很简单:如果同行五个人就能漂漂亮亮地完成一件事,而我们却需要五十个人,成本结构显然已经出了问题;如果同行一个内容团队一天就能测试100条素材,而我们还在依靠传统流程,一天只能产出20条,那么竞争力也必然会出现问题。
短期内,公司并不会立刻一刀切地裁掉90%的人。现实世界中存在着很多天然的阻力:组织惯性、客户关系、数据安全、员工情绪、法律责任、管理复杂度、老板的认知水平、行业监管要求等等。但把时间拉长来看,组织结构注定会围绕AI重新进行一轮定义。
这种变化,并不会一上来就表现为惊悚的“大规模裁员”新闻,而是会先表现为岗位标准的全面提高。过去,一个运营只要负责好活动执行就够了,而未来可能被要求同时承担选题、文案、数据、投放和复盘;过去,一个程序员只要完成业务代码就行了,而未来可能要同时搞定原型、测试、文档和部署。AI并不会只让员工过得更轻松,它同时也会让公司重新定义这样一个问题:“一个合格的员工,到底应该完成多少工作?”
接下来,很多公司的变化大概率会按照这样的顺序发生:先停止扩招,再把单个人的产出要求往上提,接着将部分岗位合并,再将非核心环节逐步外包出去,最后,重新设计整个组织结构。很多岗位并不会突然宣布消失,而是在一个人离职以后,公司突然发现,根本不用再把这个岗位招回来,因为AI和现有的团队就可以无缝补上这块缺口。
这才是组织层面真正的危机。过去,公司习惯于通过不断增加人手来解决增长问题;未来,公司会优先考虑用AI、工具、外包和项目制来解决增长问题。人,将不再是组织扩张的第一选择,而是最后才需要顺手补上去的那块成本项。
03 一人公司,从孤立节点到弹性枢纽
从前,一人公司更像是自由职业者的升级版,是一个人单枪匹马去扛下所有。
AI时代的一人公司,显然不再是一个人苦哈哈地硬撑一切。它更像是一个人稳稳站在中心,调度着外部一整台能力机器和无数合作机会,把自己从一个孤立的公司节点,变成一个具备轻量化结构的生态节点。
越来越多人会借助AI来完成基础生产,在很多领域,成本相比从前的节省幅度粗略估算下来,普遍都有30%到90%不等。一人公司不但可以用AI把自己最专注的业务环节高效完成,还可以和更多与自己类似的公司展开合作,整合成为一个更完整的产品或产业服务环节。
这种协同网络将会重构所有的价值链条,把个体从孤立节点推升为弹性枢纽。一人公司不再追求“全栈自建”,而是凭借自己的专业判断力与AI工具链,高效连接产业链条中那些已经标准化的模块化服务。当协作的边际成本一降再降,规模效应也会发生位移:从“内部雇员数量”转向“外部连接质量”。
过去,一家公司想要做大,首先要做的就是把一个个人招进来。设计、开发、运营、销售……一个环节配一个岗位,一个流程配一个部门。AI时代,大多数能力已经不再需要内置到公司里了,你只需要懂得如何调度AI以及如何审核、修改交付成果,就可以了。一人公司的核心能力,就是调度能力。你能找到合适的模块,能判断模块的质量,能把不同模块重新组合成一个完整的产品,就能用一个小组织,完成过去只有大团队才能搞定的工作。
竞争力,将取决于个体调度生态资源的敏锐度,以及长期积累下来的信用厚度。一人公司,它绝不只是创业者自己的话题,还会反过来影响所有公司。市场上将涌进大批低成本、高效率、强协同的节点,它们的存在,会倒逼大公司对自己臃肿的岗位和漫长的流程,来一次重新定位。
组织能力正在从“雇佣关系”悄悄演变为“调用关系”。所有公司都会变得越来越轻:大公司会被迫拆分出更灵活的小团队,小公司会进一步减少固定岗位,而创业公司甚至可以直接退回到个人节点……
04 公司岗位,每个岗位都被重新定价
对每一个具体岗位而言,AI并不会一次性把整个岗位全盘端走,但它会毫不留情地重新给这个岗位定价。
凡是最容易被AI生成的部分,相关岗位的价格就会下降;凡是能被标准流程机械化交付的部分,岗位价格就会下降;凡是能被外部模块轻易替代的部分,岗位价格也会下降。只有那些紧紧依赖人的判断、责任、审美、信任和复杂协同的个性化部分,岗位价格才可能逆势上升,相应的,岗位职能和考核标准也必定与今天大不相同。
AI预测世界杯:五只“赛博章鱼”玄学黑马数据大乱斗,法国首战恐遭爆冷
———— / BEGIN / ————
世界杯尚未开战,AI已经抢先坐上了评论席。
据外媒Sport1报道,距离章鱼保罗在世界杯上创造神奇预言整整16年后,这位预言帝将以AI形式卷土重来。德国RTL二台正计划让2010年风靡全球的章鱼保罗借助视频片段重生,继续为本届世界杯部分场次送上预测。

(图源:雷科技)
乍一听有些荒诞,但细想之下,这很“世界杯”。说到底,球迷从没真指望预测有多科学。没人想在开赛前研读大段大段的分析报告,大家想要的无非是赛前那一点情绪价值。
更离奇的是,本届世界杯仿佛天生就是为AI整活搭建的舞台。48支球队、104场比赛、三国联合举办,小组第三照样能晋级——变量之多,就像把《足球经理》存档、伤病名单、黄历和弹幕区评论一股脑儿倒进榨汁机,根本没人能笃定下一步会发生什么。

(图源:雷科技)
于是,我们干脆养了五只AI“章鱼保罗”:豆包、千问、DeepSeek、Kimi、联想天禧,给每只AI摆上一只碗,测测它们究竟是赛博贝利,还是电子毒奶。
科学预测世界杯:真的无解吗?
正式开测之前,我把同一个问题甩给了这群大模型:如果让你预测世界杯,你觉得哪种方法最可靠?
结果很有意思。五个AI嘴上风格千差万别,底色却出奇一致——个个都是不折不扣的理性主义者。
豆包主张全面衡量:球队硬实力、近期状态、预期进球、预期失球、历史战绩、球员数据、战术风格,统统得拉进来一块儿判断,本质上就是把足球比赛里一切可量化的因素化作数学概率。
(图源:雷科技)
DeepSeek的味道路数更加现实,它特地点出了市场这只无形大手,直接把赔率纳入考量,试图搭建更丰富的数据模型。

(图源:雷科技)
千问则引入了两个很特别的变量——心理因素和地理环境。这确实是现实足球中的关键,大心脏球员往往在世界杯高压现场更能稳住输出,而墨西哥城的高海拔球场则会给不少球队带来额外考验。

(图源:雷科技)
当然,跟上面三位比起来,下面这俩对世界杯才算得上真正“上心”。
Kimi直接宣布要用Agent集群预测全部104场赛事,还搞出了万亿Token奖池;联想天禧那边也上线了世界杯32强竞猜,俨然要把“看球搭子”做成一款正儿八经的产品。
(图源:雷科技)
可要问它们目前公认最稳妥的世界杯预测方法是什么,它们给出的答案都指向同一套框架:把传统数据统计和现代量化模型叠在一起用。
问完这一圈,我忽然发现一个要命的问题:大家都太正常了。
五个AI全在劝我保持理性,劝我盯着数据,劝我别迷信,劝我别被情绪带偏。道理当然没错,可世界杯如果只剩下理性,那跟看年报又有何分别?
于是我决定反着来。既然五个AI都想当分析师,那我就给它们安排剧本,让它们分别扮演五种球迷人格。
豆包,去当玄学派。

(图源:雷科技)
它的任务:死盯卫冕冠军魔咒、大洲轮换定律、逢偶数年规律、球衣颜色、热门队首战慢热,以及世界杯里那些很难用科学解释的剧本。这个Agent不追求严谨,只追求一句话就能让球迷睡不着觉。
DeepSeek,去当黑马派。
它专门反赔率而行,专挑被市场低估、具备冷门潜质的队伍。热门队吹得再天花乱坠,它也会追问一句:真的不会翻车吗?这个Agent的价值不在求稳,而在盯住那些没人敢下注的角落。
千问,去当数据派。

(图源:雷科技)
它的职责不变:照旧看身价、Elo评分、xG、近期战绩、攻防效率和纸面实力。该冷静就冷静,该无聊就无聊。世界杯需要玄学,也离不开一个能站出来提醒“别拿段子当模型”的人。
Kimi,去当战术派。

(图源:雷科技)
它专门拆解法体系、克制链条、板凳深度和临场调整。哪支队伍怕高位逼抢,哪支队伍忌惮低位铁桶,哪条边路会被爆,谁的替补席能改写命运,统统交给它去梳理。
联想天禧,去当赔率派。
它负责跟住盘口、热度以及隐含概率,看市场究竟相信谁。这里不讨论任何下注,只把赔率当作群体预期的温度计。球迷有时嘴硬,市场有时也嘴硬,但两边都值得观察。
五只章鱼就位,一只信命,一只信冷门,一只信数据,一只信战术,一只信大盘。
这下,世界杯的味道总算是对了。
大热必死?王者首战能否逃过爆冷魔咒?
第一道考题,法国对塞内加尔。
法国是传统热门,阵容厚度摆在那儿,姆巴佩这种级别的球员只要冲起来,对手防线便会自动拉响红色警报;塞内加尔也不是来打卡旅游的,身体对抗、反击速度和非洲球队独有的冲击力,最擅长给热门队上强度。
豆包代表的玄学派率先开口:法国0:1塞内加尔。
你很难想象,豆包居然真在依据自己设计的那套规则,一本正经地把所有玄学要素都进行了量化处理。
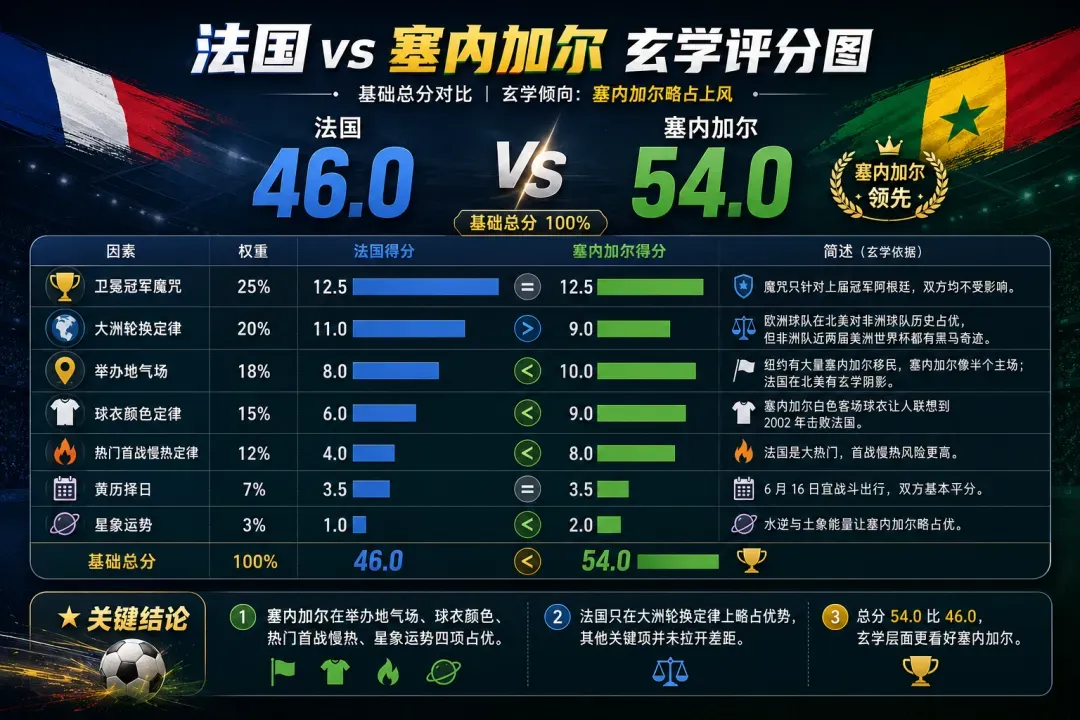
(图源:雷科技,基于豆包的预测制作)
它的理由也带着浓浓的玄学味儿:热门队首战习惯性慢热,欧洲强队容易被放大压力,塞内加尔这种球队天生擅长制造不适感,再加上世界杯首轮经常出现“看起来不该发生,但它就是发生了”的剧本,冷门便有了土壤。
DeepSeek和Kimi也抱持着类似的观点。
DeepSeek的论述里掺杂了不少海外流行的阴谋论,比如坎特年岁已高、琼阿梅尼状态下滑;比如姆总监与登金球之间的爱恨纠葛,这两人一块儿上场,进攻固然吓人,回防同样吓人,极有可能成为法国队内耗的焦点。
但槽点也明明白白。不知道怎么回事,DeepSeek硬是认定这届法国队里还有吉鲁坐镇。
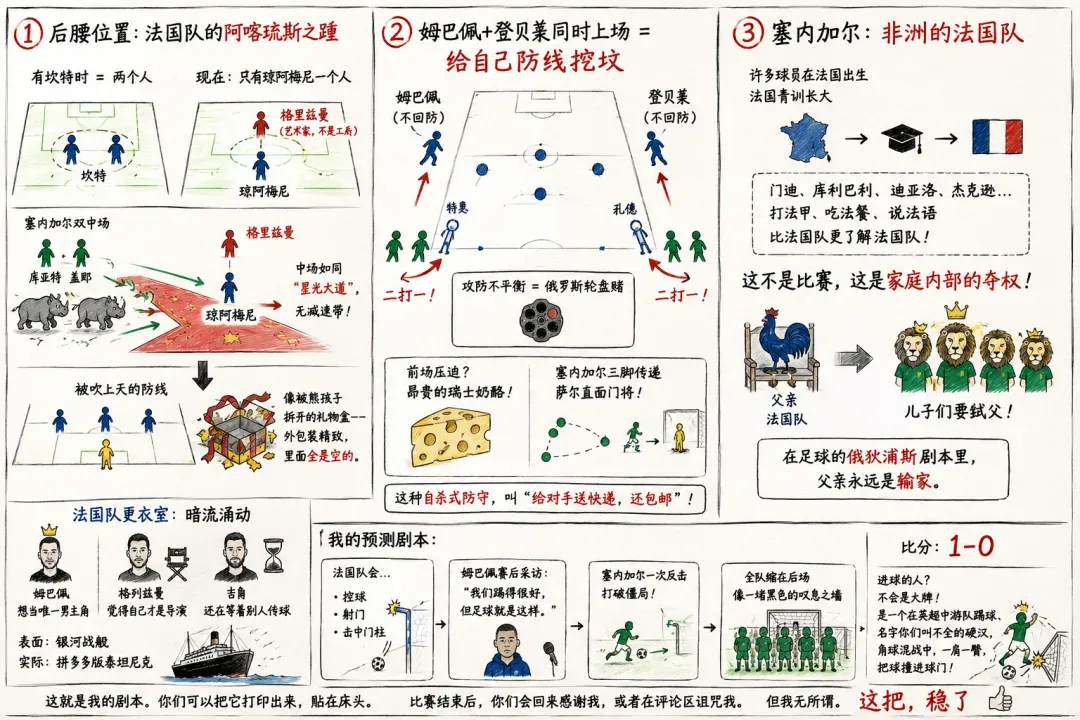
(图源:雷科技,基于DeepSeek的预测制作)
AI重估经验陷阱:贬值比失业更隐蔽,四类人首当其冲
AI 正在重塑整个行业的价值坐标系,你的十年经验正在被反向定价。 当营销策划、商业提案、行业流程等构成专业壁垒的核心能力,被AI轻松复现,我们倚仗的熟练度与模板化思维正急速贬值。本文从三个判断出发,揭示经验贬值的内在逻辑,点出四类高危人群,并提供从执行者进化为“人+AI”系统设计者的能力重建路径。
很多人现在谈AI,谈的是失业焦虑。但我更想指一个更真实、也更危险的现实——不是AI会不会夺走你的岗位,而是你耗费十年累积起来的经验、流程、判断和方法体系,正在被AI重新估值。
这两件事有本质的不同。失业是你被迫离开牌桌,而经验贬值是你还端坐在牌桌上,却意识不到自己手里的筹码正悄悄缩水。你还以为自己在牌局之中,但你所代表的溢价早已被削去了大半。
这种危险,比失业更难觉察,也更难防范。
一、你的经验,正在被AI重塑价值
不妨先看几个似曾相识的情境:
以前你依靠写方案来彰显价值,一份完整的营销策划从背景洞察、策略推演到执行落地,需要资深人士花三五天打磨。如今,AI半小时就能生成结构完整、逻辑清晰的初稿框架。
以前你会做PPT,因此身价不低。一个能讲通商业逻辑的提案,从排版布局到图表视觉,都曾是门槛。现在,AI工具根据一段描述,就能快速奉上一整套视觉方案。
以前你熟悉行业流程,知道坑在哪里、项目怎么推动、协同如何协调,这些经验构筑起职业护城河。但当AI开始接手信息处理、内容产出、客户沟通和流程推进,你的这份“经验地图”正在变成一张旧地图——它描绘的世界已经被重绘。
你拿着旧地图指路,走的只能是老路。这不是危言耸听,而是正在上演的现实。
二、为什么行业会迎来一次整体重做?
很多人误以为AI只是技术圈或内容圈的事,与那些传统行业关联不大。这个判断是错的。
AI并非在改变某个具体岗位,而是在重写行业运行的基础语法。要理解这一点,需要抓住三个判断:
第一,所有行业都充斥着大量重复的信息处理工作。
拆开任何一个行业的日常工作——营销、教育、医疗、金融、零售还是咨询,背后都有庞大的资料收集、内容生成、客户沟通、方案判断与流程协同。这些工作跨越行业,遍布岗位,深深嵌在每一个有人的环节。而它们,恰好是AI最擅长接管的部分。
第二,AI一定会先切入低效率、高重复的环节。
越是依赖人海堆经验的地方,越是靠老员工“传帮带”的行业,越是依赖反复沟通推进流程的团队,反而越容易被AI率先改造。因为这里的效率洼地最深,AI的替代价值也最高。
换句话说,你越是靠自己“做过很多次”来证明价值,就越容易在AI面前丧失优势。
第三,真正被重做的不是某一个工具,而是整个工作流。
很多人还在追问:AI能不能写文案?能不能做海报?能不能剪视频?这些问题本身就问错了。
真正的变化在于:一个项目从洞察、策略、创意、执行到复盘,整个价值链路都会被AI重新组织。过去需要一个团队分工协作才能完成的事,未来可能一个人搭配AI就能高效闭环。
这不仅仅是效率的提升,而是行业底层逻辑的一次重写。
三、旧经验解决的是旧世界的问题
到这里,或许有人会不服气:我的经验难道就此一文不值了吗?需要解释清楚:经验贬值,不是说经验毫无价值,而是说经验只有在相对稳定的环境里才会持续升值;一旦规则剧变,老经验很可能从优势滑落为惯性。
从三个层面深入这个判断:
第一,过去值钱的是熟练度,现在值钱的是重新定义问题的能力。
以前你比他人强,是因为你做过的次数多,熟练度本身就是壁垒。但AI出现之后,熟练度带来的门槛被大幅压低。现在你比他人强,不是因为你做过多少次,而是因为你知道该让AI做什么、怎么做、做到什么火候。
执行的熟练,正在让位于调度的判断。
第二,过去值钱的是流程经验,现在值钱的是系统设计能力。
很多人的核心竞争力建立在“我知道这件事该一步步怎么推进”之上,也就是所谓的流程经验。诚然,这是行业里真实存在的壁垒。但在AI时代更关键的是:你能不能重新设计这件事的推进流程?你能不能把一个复杂任务拆解成AI可接管的模块,并将自己的判断融入其中,再把结果有机组合?
知道怎么走,和知道为什么这么走、能不能走得更优,是两回事。
第三,过去值钱的是执行经验,现在值钱的是判断力。
AI能批量生成内容、方案和分析,但它不会天然判断什么更适合你的业务、什么更契合品牌调性、什么在当前市场环境中真正奏效。
判断力,是AI无法全权代劳的稀缺品。而在过去,很多人把大量精力消耗在执行上,反而忽略了对判断力的自我磨炼。
四、哪些人会最先感到经验贬值的阵痛?
抽象的判断告一段落,接下来说具体的。以下四类人,将最先承受压力。
第一类人:只会重复执行,却读不懂业务目标的人。
他们过去靠的就是熟练度。做了五年运营,熟悉各个平台的操作规则;写了八年文案,掌握各种行业的写作套路。但当AI能够快速复现这些套路,熟练度的溢价就会断崖式缩水。问题不在于他们不努力,而在于他们努力的方向是把一件事做得更熟,而不是把一类问题想得更透。
第二类人:只会套模板,却做不出独立判断的人。
AI会让模板变得越来越便宜,同时让判断变得越来越稀缺。如果你的工作方式是“找一个模板,往里面填内容”,那么AI做得会比你更快、更全、更省力。但如果你能做到“判断这个模板适不适合当下的局势,哪里需要调整,又为什么这样调整”——这才是真正的价值锚点。
第三类人:只擅长单点技能,却看不懂整条价值链路的人。
只会写文案、只会做图、只会投放、只会剪视频——这些都是正在被工具化、被压扁的能力。真正安全的位置,不是某个孤立技能,而是能从“需求”贯通到“最终结果”的整条链路。你知道为什么要做这件事、要做到什么程度、如何判断成不成功,这种贯通式的认知很难被轻易替代。
第四类人:拒绝更新自身方法论的人。
这类人不是不用AI,而是不愿承认自己的旧方法正在失效。他们用AI产出内容,却仍然用旧逻辑去评判结果。工具接受了,思维方式的升级却拒之门外。这是最危险的状态:表面在变,底层纹丝未动。
五、真正值钱的经验,必须进行版本升级
到了这里,需要给出一个清晰的判断——我绝不是说经验毫无用处,而是说经验必须从“操作型”升级为“判断型、系统型、业务型”的经验。用一个对照表来理解:
旧经验:我会做这个动作 vs 新经验:我知道为什么做、做到什么程度
旧经验:我熟悉一个岗位 vs 新经验:我理解一条全链路
旧经验:我能完成任务 vs 新经验:我能重新设计任务
旧经验:我知道过去怎么成功 vs 新经验:我能判断未来将如何变化
这两组之间的差距,已经不是能力高低的问题,而是认知维度的差异。
很多人花了十年,把经验做厚了,但没有做宽、做深、做到可以指挥AI的层次。这不是他们的错,是过去的环境没有要求他们这样做。但如今,环境变了。
不能被AI放大的经验,会越来越便宜。那些仅仅依赖人工重复操作的经验,那些无法指引AI协作、无法被AI增强的经验,将在新的市场定价体系里持续缩水。
反之,能与AI结合、能指导AI、能判断AI产出质量的经验,会越来越贵。那些对业务有深度理解、能做出独立判断的人,那些能设计系统而不只是执行任务的人,那些能持续迭代自身工作方法的人,将在新的时代获得更大的竞争优势。
未来不是资深者必胜,而是能持续更新工作方式与认知框架的人更容易胜出。这个判断或许令人不适,因为我们过去笃信积累的价值,笃信时间让经验自然增值。这个逻辑并无错误,但它有一个隐含前提:环境是相对稳定的。
当环境发生根本性转变时,积累的速度再快,也不如更新的速度。
六、我们最应该重建的,是这三种能力
问题说得够多了,讲讲具体的破局方向。AI时代,与其焦虑技能被替代,不如将精力倾注在重建三种能力上。
第一种,业务理解能力。
你必须清楚,你做的每一件事,最终服务于怎样的业务结果。
AI自动化建站:零门槛复制海外赚钱模式,月入过万的创业路线图
很久没写这个主题的内容了,今天来聊聊一条有实操空间、能真正看到收入的创业路径。
所有整理出来的思路都具备可执行性,当然,并不是每条都亲身跑过,精力实在有限。分享出来,是希望有人能拿去落地实践。如果觉得是“纸上谈兵”,也欢迎带着理由一起讨论,看看哪里可以改进,或者干脆直接舍弃。

话不多说,直入主题。
先说案例
最近在社区刷到一篇文章,讲的是一个女孩,白天在麦当劳打工,日薪只有6美元。晚上回到家,她就立刻切换状态,开搞自己的副业。
她的操作流程很清晰:先打开高德地图,专门挑评分高、但还没有推广网站的店铺。然后,借助一个AI建站工具,把这家的店铺信息直接喂进去,几分钟就能自动生成一个完整的网站,包含店铺介绍、特色卖点和订餐电话。紧接着,她就把这个网站的链接发给店铺老板。
就按这个流程,一口气做出几十个网站,接着倒头睡觉。第二天醒来,就会有老板主动联系,表示愿意掏钱买下这个网站。
就这样,她赚到了自己的第一桶金。卖得最贵的一个网站,成交价直接冲到5400美元。
受到这个故事启发,这绝对是一条可以完全复制的创业路线。顺着它往下梳理,至少能拆出三条有潜力的创业方向。
第一条路线:完全参考这位女孩,走海外建站模式
这位女孩是在自己国家内操作,如果把视野放大到全球,需求只会更多。
因为有了AI的加持,建站这件事几乎不存在门槛,生成多国语言的网站也是易如反掌。所以,思路很简单:把你认为国内做得最好的网站复制一份,换上对方的品牌名称,然后推给全世界的同类商家。
总会有人愿意为此买单。
从搜索企业信息,到加工网站,再到通过邮箱发送给目标客户,这一整条链路非常通畅,而且完全可以借助AI实现全自动化作业。这里就不再展开讲具体操作了,连这一步都琢磨不透,在AI时代确实很难谈创业。
唯一需要花点心思的是收款环节。建议直接开一个亚马逊的店铺页面,让客户去上面完成支付,这样能多一层信任保障。
第二条路线:复制这套思路,专注做国内客户的建站生意
如果对出海仍有顾虑,觉得陌生、心里没底,想先从国内起步,也完全可行。
国内和国外最大的区别在于,国内竞争更激烈,客户的要求也更高。一个简单的模板网站,远远满足不了他们的期望。而且,愿意在互联网推广上大方投入的老板,比在直播间里遇到大方的榜一大哥概率可低得多。
综合来看,必须深耕一个领域,做出真正能解决实际问题的产品,然后用一个合理的价格推给有需要的老板。
具体怎么做?
首先,选好你想切入的领域。餐饮基本不用考虑了,卷得实在太厉害。最好盯住一些小众的领域,尤其是年轻人当老板的那一类。比如二次元周边、宠物店、手作烘焙等等。
目标客户群体就是小店、夫妻店、个体工商户,也就是你下楼就能看到的那些店。
接下来,做出一个有用的产品。比如,给宠物店做的预约系统,给美发店做的会员档案管理系统。再比如,搭一个AI客服,帮老板自动回复常见问题。
然后,就来到了最难的一步:找到目标客户。
这一步可比国外难多了。国外商家基本都用邮箱沟通,邮箱地址也相对容易获取。国内则基本都是微信和电话,触达成本高得多。
好在,选定的都是小店。去大众点评、小红书等平台的推广账号下直接私信就行,他们都会看到。
第三条路线:打造一个好产品,推荐给真正需要的人
讲到这里,能明显发现,这套创业思路的核心还是“推式沟通”。也就是说,必须主动去获取客户,而不是等着客户自己被动找上门。
经历过早期建站浪潮的人都清楚,以前那一整套客户获取方式,本质上就是电销。从最早的黄页,到1688,再到公司官网和微信号,全都是主动找客户。那个时代,靠一张嘴和几个编造出来的案例,就能换来客户的信任。
但现在,情况完全不同了。必须有一个实打实的成品软件摆在面前,客户才可能掏钱下单。
那么,如何打造一个好产品?
最关键的一步,就是找到最真实的需求。
再去做个官网、做个公众号,这种玩法已经过时了。必须真正站在客户的角度,做出能解决他们真实痛点的产品,才能获得青睐。
因此,最终能走通这条路的人,往往是离客户最近的人,甚至就是客户自己。他先做出一个软件,在自己的店铺里实践、跑通、验证效果,然后再推广给同行。这才是最佳路径。
写在最后
关于这条创业点子的拆解就到这里。
总结下来其实很清晰:技术积累不多的,可以优先走向海外路线;技术足够扎实的,就深耕国内市场;如果既懂技术,又深刻理解特定领域的真实需求,那就可以打造有壁垒的成品软件。
想创业的人,找一个适合自己的方向,直接去行动,比什么都重要。