深入解析Function Calling与Skills:从基础到实战的完整指南
从智能体出发:三种与外界交互的方式
之前我们已经分别介绍了MCP、Function Calling、A2A乃至Claude Skills。但许多读者仍感到困惑。究其原因,可能在于这些孤立的知识点缺乏连贯性。要真正理解它们,或许需要从全局视角和目标出发进行梳理。
追根溯源,这一切仍需从智能体(Agent)开始。因为MCP、Function Calling、A2A这三者与智能体直接相关,属于智能体与外界交互的三种核心方式:

Function Calling:大模型调用外部函数的基础能力
首先是Function Calling。这是一种让大语言模型在推理过程中,能够主动选择并调用外部函数或工具的核心能力:

具体的交互逻辑如下:在对话过程中,大语言模型会根据用户的问题(例如:“今天北京的天气如何?”)判断是否需要调用外部函数。如果需要,模型会输出一个结构化的JSON请求,其中包含了要调用的函数名称和相应的参数。随后,我们的后台程序会基于这个JSON请求执行实际的函数调用:
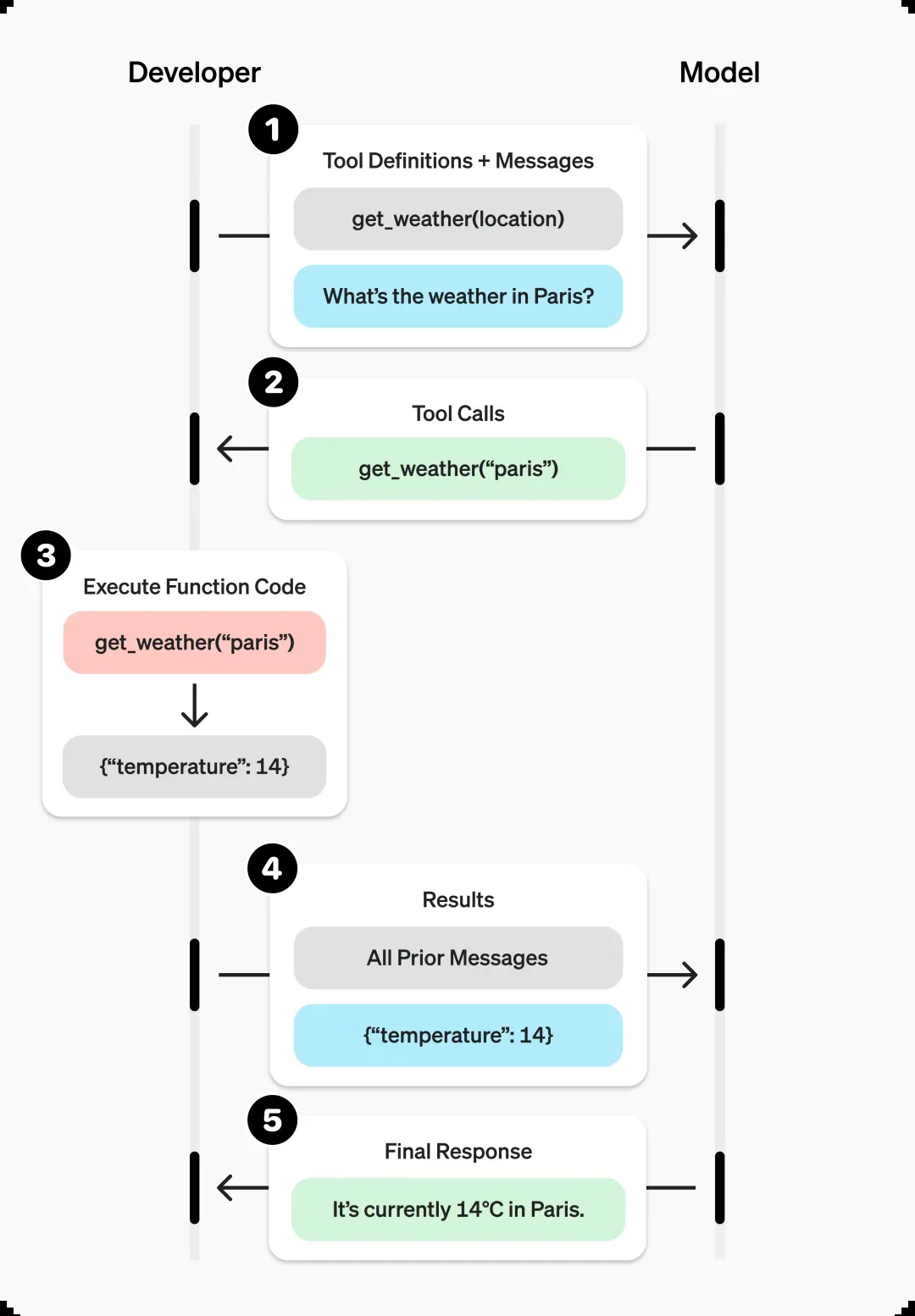
具体的流程,我们可以直接参考GPT官方的定义示例:
# 这是提供给模型识别的工具定义,并非真正的可执行代码
tools = [{
"type": "function",
"name": "get_weather",
"description": "Retrieves current weather for the given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
},
......
},
}
}]
每次调用API时都需要传递tools参数,直接调用GPT接口发起请求:
# 每次调用API时都需要传递tools参数,调用GPT接口发起请求
response = client.responses.create(
model="gpt-5",
messages=[...],
tools=tools # ← 这个参数每次调用都需要携带
)
由此可以看出,模型具备哪些工具调用能力,完全是由我们预先定义好的。模型会根据用户的输入内容,自主选择使用哪个最合适的工具:
# 用户输入
user_query = "今天北京天气怎么样?"
# 模型会进行如下分析:
# - 用户询问的是"天气" → 匹配到 get_weather 函数的 description 描述
# - 提到了"北京" → 对应 location 参数
# - 最终决定调用 get_weather 函数
需要明确的是,模型本身并不会直接执行工具调用,它只会返回一个结构化的调用指令。这个指令是模型经过专门任务训练后产生的结果:
{
"function_call": {
"name": "get_weather",
"arguments": "{\"location\": \"北京\", \"unit\": \"celsius\"}"
}
}
真正根据返回的JSON数据来调用实际脚本的是我们的后台程序。并且,这里需要将工具调用的结果再次返回给模型进行整合:
# 把天气查询结果返回给模型
# result是工具调用返回的原始结果
final_response = llm.chat(
model="gpt-5",
messages=[
{"role": "user", "content": "今天北京天气怎么样?"},
{"role": "assistant", "function_call": model_response["function_call"]},
{"role": "function", "name": "get_weather", "content": json.dumps(result)}
]
)
整个逻辑非常清晰:如果模型识别用户意图后认为无需工具调用,则直接生成回答返回给用户;如果判断需要工具调用,那么就利用首次模型返回的参数执行调用,获取结果后再进行二次模型调用,最终将整合后的答案返回给用户。
这里有几点需要特别注意:如果你的工具接口出现故障,且容错机制处理不当,那么模型就可能无法正常回答用户。
此外,理解以下几个问题,几乎就能把握Function Calling的本质,乃至明白它为何在实际中使用频率可能受限:
第一,如果Tools工具列表过长(数组过大),这同样会占用宝贵的上下文长度。因此在实际应用中,往往需要进行诸多优化处理。
第二,Function Calling 的效果好坏极度依赖于模型本身对用户意图的识别能力。模型判断是否要调用一个函数,主要依据就是我们提供的description参数描述。这听起来存在一定风险,因为模型调用出错的情况必然会发生。不过,得益于模型强大的容错能力,即使多获取了一些数据,也未必会严重影响最终的回答质量。
在这个基础上,我们再来探讨MCP。
MCP:旨在统一工具交互协议的开源标准
Function Calling 本身机制没有根本问题,但在频繁使用后确实暴露出一些痛点,例如:
- 不同基座模型厂商虽然都有类似Function Calling的概念,但在具体命名、参数格式上可能存在差异。
- 整个Tools预定义的过程,编码方式比较固化,其实更适合用注册制、发现机制来管理。
- …等等。
简而言之,Function Calling 解决的是:单个模型如何“按照你定义的特定JSON协议”去调用你自己的API接口的问题。
而MCP的诞生,正是为了解决这些共性问题,可以理解为MCP是在为Function Calling “解决后顾之忧”…
MCP 是由 Anthropic 公司提出的一种开源协议,旨在标准化大型语言模型与外部资源和工具之间的连接方式。你可以把它想象成 AI 领域的 “USB标准” 或 “应用商店协议”。
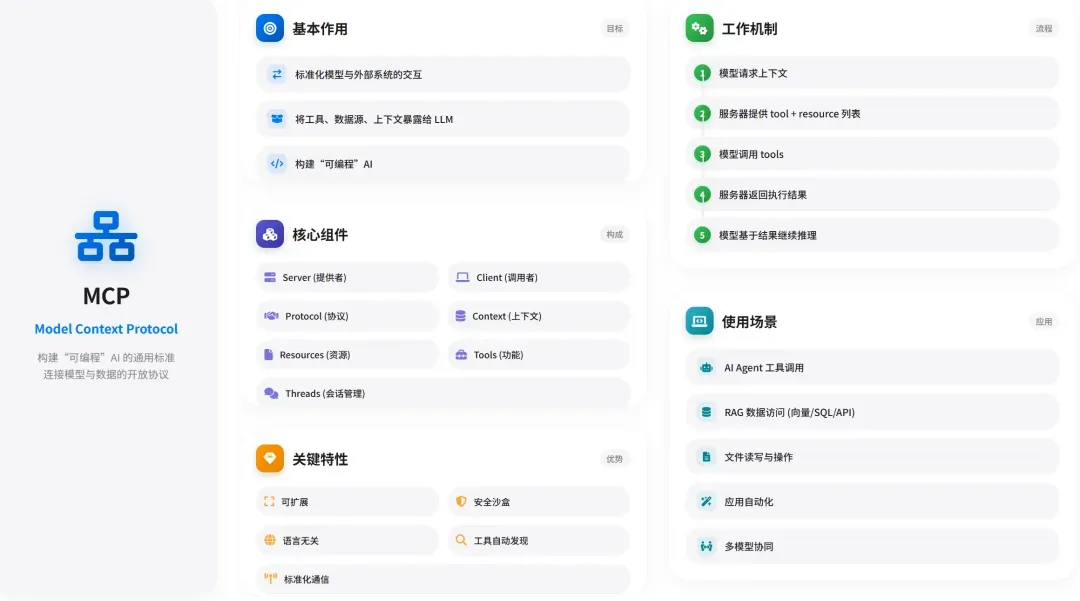
不过,这里有一个非常关键的点需要注意:
- 目前主流的大模型厂商大多都已实现了各自版本的 Function Calling。
- MCP 目前主要是由 Anthropic 这条技术路线在推动,它属于工具协议层。
换句话说就是:并非所有模型厂商都立即跟进并原生支持了MCP协议。如果基座模型本身不支持,那么应用层就需要自己做一个“套壳”包装。在不受原生支持的情况下,要使用MCP通常需要满足两个前提:
- 第一,在模型侧依然需要使用它原生支持的 Function Calling 机制。
- 第二,在客户端(或中间层)自己将 MCP 工具的描述,转换成模型能识别的 Function Calling 描述格式,再喂给模型。
最直接的情况就是:OpenAI目前并不原生支持MCP,他们有自己的生态规划。因此,如果想在OpenAI模型上使用MCP工具,就需要自己搭建一个中间代理层进行转换!
而我们愿意采纳MCP的核心驱动力,并非因为MCP协议本身多么完美无缺,而在于活跃的开发者社区正在反向推动基座模型厂商。现阶段,由于社区的活跃贡献,MCP的插件(即Server端实现)已经非常丰富。如果我们想节省精力,不想亲自实现每一个工具的后端逻辑,那么构建一个中间桥接层来利用这些现成的MCP Server就显得很有价值。
以天气查询为例,我们先看MCP Server端的伪代码示意:
start_mcp_server("weather-mcp-server"):
# 1)声明一个工具:get_weather
register_tool(
name = "get_weather",
description = "查询指定城市今天的天气情况",
input_schema = {
"type": "object",
"properties": {
"city": { "type": "string", "description": "城市名称,例如:Beijing" }
},
"required": ["city"]
},
output_schema = {
"type": "object",
"properties": {
"city": { "type": "string" },
"temperature": { "type": "number" },
"condition": { "type": "string" } # 例如:晴、多云、小雨...
}
}
)
# 2)真正被调用时执行的处理逻辑
on_tool_call("get_weather", args):
city = args.city
# 这里调用真实的天气API接口,或者你的内部系统
raw = http_get("https://api.weather.com", { "q": city })
return {
"city": city,
"temperature": raw.temp,
"condition": raw.text
}
对于Server端的代码,我们作为使用者其实并不需要关心其具体实现。这里写出来只是为了让大家有一个更直观的理解。我们需要重点关注的是Client端的配置。例如,对于OpenAI模型,我们需要将MCP工具匹配到桥接层,主要做两件事:
- 调用天气 MCP Server,获取它提供的工具定义列表。
- 把这些工具定义转换成 OpenAI 模型能识别的
tools(Function Calling)格式。当模型发起tool_call时,代为将请求转发给对应的 MCP Server 并返回结果。
这部分的代码反而比较简单,因为复杂的工具逻辑已经由MCP Server端完成了:
# 启动你的应用服务时:
# 1)创建 MCP Client,连接到天气 MCP Server
mcp_client = MCPClient.connect("weather-mcp-server")
# 2)从 Server 获取工具列表:你提供了哪些工具?
mcp_tools = mcp_client.list_tools()
# 例如返回的结构可能是:
# [
# {
# name: "get_weather",
# description: "查询指定城市今天的天气情况",
# input_schema: { ...上面的 JSON Schema... }
# }
# ]
接下来的关键步骤是把 MCP 工具描述转换成 OpenAI 的 tools 格式:
# 3)把 MCP 的工具描述转换成 OpenAI 的 tools 数组
openai_tools = []
for each tool in mcp_tools:
openai_tools.append({
"type": "function",
"function": {
"name": tool.name, # 例如 "get_weather"
"description": tool.description, # 例如 "查询指定城市今天的天气情况"
"parameters": tool.input_schema # 直接复用或稍作格式转换
}
})
# 之后你在调用 OpenAI API 时,就可以直接把 openai_tools 作为 tools 参数传入
再往后的调用流程,就和标准的Function Calling非常类似了,这里不再赘述。
A2A:智能体间的结构化通信与协作
到了 Agent to Agent (A2A)这个层面,情况变得既简单又复杂。简单之处在于,从外部看可能只是一次服务调用;复杂之处在于,两个智能体之间的通信协议可以设计得非常复杂,并且协作过程的可控性保障是一个挑战。
我们以之前的天气查询为例。基础流程是 模型 → 工具。而在A2A架构下,流程可能演变为 模型A (Agent) → 模型B (Agent) → 工具。
在复杂的业务场景下,采用A2A架构是有其优势的。毕竟不同的Agent可以专注于各自擅长的领域,其底层提示词和知识库也针对特定任务进行优化。对于单一Agent而言,如果任务简单,可能不会有Tools过多导致上下文负担的问题;但对于复杂任务,拆分成多个协作的Agent可能更清晰:

为了更清楚地说明,我们再举一个例子:假设存在两个Agent,一个是天气查询Agent,另一个是旅游规划Agent。而旅游规划Agent在制定计划时可能需要获取天气信息。
用户的触发问题可能是:“五一假期想去成都玩三天,需要带厚一点的衣服吗?”
在这个场景下,可能会出现三个角色:
- 基础天气API:提供最底层的原始天气数据查询。
- 天气MCP Server:包装了天气查询工具的服务,它最终会调用底层天气API,同时对外提供标准化的MCP接口,供天气Agent调用。
- 天气Agent:一个专门的智能体,当需要天气信息时,它会调用天气MCP Server来获取数据,并可能进行一定的信息加工。
这里一个关键的不同点是天气Agent会对外暴露一个自定义的API接口。它的输入可能是 城市 + 日期范围,输出则是一段加工后的天气描述或直接给出旅行穿衣建议。
换句话说,天气Agent提供给外界的信息,是它基于原始天气数据,结合自身“理解”,认为请求方所需要的、与天气相关的建议性信息,而不仅仅是原始数据。实际上,你可以将天气Agent当作一个大模型服务来调用。
而具体的调用方式,在实现层面又可能回归到基础的Function Calling机制。即将天气Agent对外提供的API,注册为旅游Agent的一个可用Tool。只是相比于调用原始工具,Agent间的调用对参数的格式可能要求更灵活,可以传递更丰富的上下文信息:
# 旅游Agent向天气Agent发送的请求可能类似于:
{
"city": city,
"start_date": start_date,
"end_date": end_date,
"question": "是否适合旅游?要怎么穿衣?"
}
# 天气Agent返回的响应可能是:
{
"summary": "五一期间成都气温 15–25℃,白天舒适,早晚偏凉。",
"advice": "白天建议穿薄长袖加长裤,晚上需要加一件外套。",
"risk": "5月2日预报有小雨,请记得携带雨具。"
}
所以读到这里,大家应该比较清晰了。这些AI领域层出不穷的名词,其底层核心很多都离不开Function Calling的基本范式!
最后,我们来探讨一下Claude Skills。
Skills:封装业务逻辑与SOP的“技能包”
Anthropic 对 Skill 的定义是:一个包含说明文档、脚本和资源的文件夹。Claude 在执行任务时,会先扫描所有可用的 Skills,判断哪些对当前任务有帮助,然后将选中的Skill完整内容加载到上下文中使用。
我们可以这样翻译理解:
Skill = 一份可以反复调用的专业标准化操作程序(SOP)+详细说明书,由模型自己根据需要动态加载。
你可以把 Skill 想象成:给一位“AI员工”编写的 岗位说明书 + 岗前培训手册。其价值在于,无需每次都在系统提示词(Prompt)里“从零开始复述”所有的操作规则和注意事项:
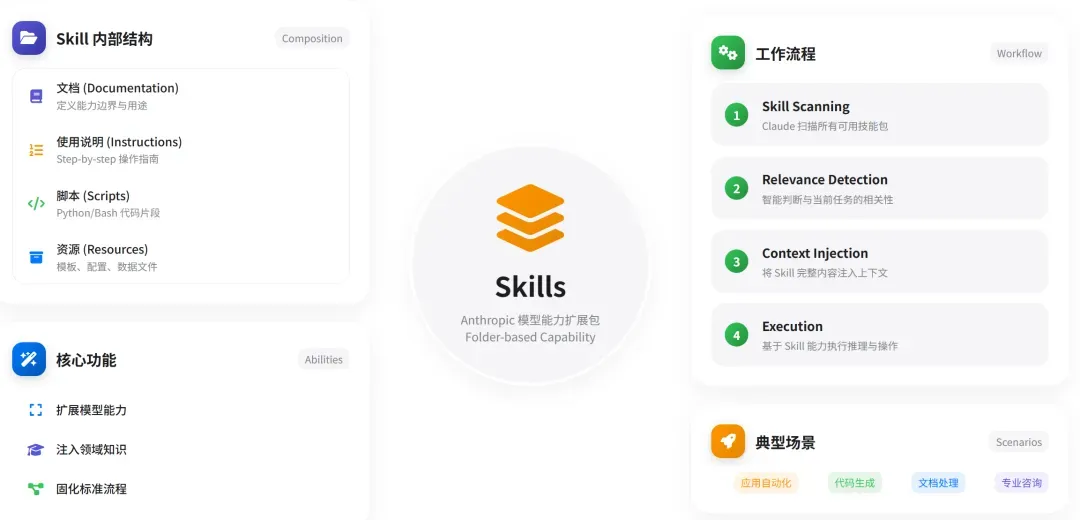
Skills的构成与工作方式
每个Skill都包含一段非常简短的元数据描述(meta),例如:
品牌写作技能:教你如何按照 XX 公司品牌规范撰写公众号文章和营销活动文案。
Claude 在接到一个新任务时,会首先利用这些元数据描述进行 “技能检索” :评估当前任务与哪些 Skills 的描述相关,并只选中那些匹配度高的技能。
最终,只有被确认相关的 Skills,才会将其完整的 instructions.md(说明文件)、示例、甚至附带的脚本加载到当前对话上下文中。
因此,你可以为模型配置很多个Skills,而不用担心撑爆上下文窗口。它主打的就是一个 “按需加载、动态扩展” 的理念。
抽象来看,一个Skill的目录结构大致如下(非官方强制格式,仅为示意):
brand_style_skill/
meta.json # 很短的技能简介 & 适用场景说明
instructions.md # 详细的写作规范、SOP、负面示例等
examples/ # 正面与反面示例、few-shot 样本
scripts/ # 可选:比如用于检查用词规范性的小脚本
assets/ # 品牌色卡、Logo 使用规范等资源文件
meta.json 里的内容会被优先加载和用于匹配:
{
"name": "brand_style_cn",
"description": "按照 XX 品牌规范撰写中文营销文案,保持语气、文章结构和禁用词的一致性。",
"good_for": [
"公众号推文",
"电商产品详情页",
"营销活动落地页"
]
}
当你提出需求:“帮我写一篇双十一活动的主推文案,品牌是 XX。”
Claude 在内部大致会执行两个关键步骤:
- 理解当前任务内容 → 判断与“品牌写作”技能相关。
- 在所有 Skills 的
meta文件中找到brand_style_cn→ 决定:加载这个 Skill 的完整说明文档。
之后,该 Skill 中定义的各类“写作套路”就会生效,例如:
- 标题必须包含哪些关键要素。
- 文章开头的100字需要解决用户什么核心问题。
- 哪些词汇属于品牌明文规定的禁用词。
- 有哪些可复用的模块化段落结构可以套用。
- …等等。
Skills的技术定位与价值
上述的描述可能有些孤立,因此在明确Skill的定位前,我们先对前面的内容做一个小结:
- Function Calling 出现的根本目的,是让大模型能够在受控的前提下调用第三方服务,扩展能力边界。
- 随后提出的 MCP,很大程度上是为了“提升开发效率”和“统一生态”而生,核心主旨是鼓励社区创造可复用的插件(MCP Server),避免重复造轮子。
- A2A 与前两者并非在同一赛道竞争,它更侧重于复杂智能体系统的架构设计与任务分解。
因此,A2A因其不同的目标暂且不参与后续对比。我们回归到最初的起点——Function Calling。如前所述,它存在一些现实问题:
第一,Tool定义过多会影响Token消耗和上下文长度,因此需要精巧的管理策略。
第二,Function Calling的触发准确性高度依赖于模型对用户意图的识别能力。如果模型错误地调用了函数,处理起来可能比较麻烦。
在这两点之外,还有第三点:每次Function Calling调用工具后,我们都需要在后台处理返回的原始数据,并将其重新注入对话上下文,这个过程略显繁琐。
上述这些工作,在传统模式下完全需要我们手动编写代码来处理。但大模型厂商可能认为“他们也有责任提供更优的解决方案”,于是Anthropic进一步提出了 Skill 这一概念,旨在协助解决上述Function Calling带来的部分工程挑战,例如:
Skill 主要关注 “获取到数据后应该如何有效使用” 的问题。其中“按需加载”的机制,是值得Function Calling工具管理策略参考的设计思路。
从技术关系上看,可以这样理解:
Function Calling / MCP 为模型提供了可以操作的“手”(调用工具的能力),而 Skills 则为模型提供了“干好某类特定工作的整套方法论和操作手册”,两者是 “能力提供”与“能力使用规范” 的上下游关系。
Skills 可以在其内部逻辑中调用 Function Calling 和 MCP 提供的工具,但 Function Calling / MCP 本身并不知道“Skill”这个概念的存在。
简而言之:Skills = 业务逻辑服务 + 调用这些服务的代码指引 + 详尽的使用说明书。
为了让大家理解得更清晰,我们增加一个更具体的业务场景说明:
结合业务场景的流程说明
假设我们为一个“老板视角的BI分析Agent”配置了以下组件:
一批 Tools/MCP 工具:
get_sales_report(获取销售报告)get_marketing_spend(获取营销支出)get_cashflow_status(获取现金流状态)
两个 Skills:
boss_bi_dashboard_cn:教导模型如何使用上面几个工具,并从老板的视角解读数字、撰写分析结论。里面包含了详细的KPI计算口径、汇报话术、注意事项。excel_analysis_skill:教导模型如何利用代码执行(code execution)能力,对用户上传的Excel文件进行数据分析。
此时,一个触发任务来了:“帮我看看今年Q3的营收和市场投放情况,简单分析一下我们是否应该收缩预算?”
具体的处理流程将会是这样:
第一阶段:Skill检索与激活
模型首先会理解,这是一个 “老板视角的财务分析 + 决策建议” 类任务。接着,模型会遍历所有Skills的meta描述,发现 boss_bi_dashboard_cn 的描述中包含类似以下关键词:
用于解读公司核心经营指标、营收、成本、预算分析,输出面向管理层的决策建议。
因此,它会激活这个 Skill,读取其完整的 instructions.md 文件,将这份 “岗位说明书 + 标准操作流程” 加载到当前对话的上下文中。请注意,到这一步为止,任何 Tools/MCP 工具都还未被实际调用。模型完成了从众多工具定义和一堆Skills中,智能筛选出最贴合当前任务的专业技能包的步骤。
第二阶段:Skill内部逻辑驱动工具调用
boss_bi_dashboard_cn 的 instructions.md 文件中可能会明确写出类似这样的指引:
如果用户询问的是某个特定时间段的“营收”与“投放”对比分析,
应遵循以下步骤:
1. 首先调用 get_sales_report 工具,获取指定时期的营收数据。
2. 接着调用 get_marketing_spend 工具,获取同期的市场投放数据。
3. 然后根据计算出的「同比增长率 / 环比增长率 / 投资回报率(ROAS)」等关键比率,给出符合老板理解和决策习惯的判断。
4. 输出最终结论时,需严格采用以下结构化格式:
- 一句高度概括的核心结论
- 2–3个最关键的数据指标及变动
- 明确的行动建议
- 潜在的风险提示
Claude 在阅读并理解了这份详细的SOP后,就知道下一步应该:
- 首先,需要查询关键的KPI数据 → 这必然涉及调用外部工具。
- 于是,模型根据SOP的指示,发起具体的工具调用请求:
get_sales_report({"period": "2024-Q3"})
get_marketing_spend({"period": "2024-Q3"})
至此,Function Calling / MCP 机制正式出场,负责处理这些具体的工具调用请求。
第三阶段:数据处理与SOP化输出
接下来,走标准的Function Calling流程获取工具返回的原始数据(此处不再展开细节),例如收到如下响应:
{
"sales": 12345678,
"growth_rate": 0.12,
"gross_margin": 0.31
}
然后就是如何使用这些数据。instructions.md 里面已经规定得非常清楚:
- 输出结构的撰写格式;
- 哪些数字需要重点突出和解释;
- 语气必须偏向老板视角,少谈技术实现细节,多讲商业结论和可执行动作;
- 需要避开哪些常见的分析“坑”;
# 输出案例参考
核心结论:Q3营收虽保持增长态势,但市场投放效率呈现明显下滑趋势,建议适度收缩预算,并将资金倾斜至ROAS更高的渠道。
......(后续是具体的建议条目和风险说明)......
从这里我们可以清晰地看到,Skills在 “意图识别后的任务拆解” 和 “标准化数据使用与输出” 方面,做了大量封装和引导工作,提升了复杂任务处理的规范性和可控性。
结语:技术演进的清晰脉络
从最基础的 Function Calling,到旨在统一工具交互协议的 MCP,再到实现复杂系统协作的 A2A,乃至封装业务逻辑与最佳实践的 Skills,这一系列令人应接不暇的技术名词,其演进脉络实则清晰而务实:它们共同服务于一个核心目标——让AI智能体能够更高效、更可靠、更规模化地与现实世界进行交互:
- Function Calling 是底层的原子能力,是弥合用户无限意图与模型有限内置知识,使其能与现实系统交互的基石。
- MCP 做的是 “工具与数据接入的统一协议 + 开发生态”,方便开发者编写一次工具服务(Server),即可被多种客户端(支持MCP的模型或应用)直接复用,极大提升了工具开发的效率和互操作性。
- A2A 并非“更高级的 Function Calling”,而是 “如何将复杂系统拆解为一组专业化的智能体,并以结构化方式实现彼此调用与协作” 的系统架构设计问题。
- Skills 并非要来替代工具,而是帮你沉淀 “在特定业务场景下,应该如何组合使用工具、如何处理工具返回的数据、如何遵循标准流程产出高质量结果” 的那套可复用的知识体系(SOP)。
梳理一圈后便会发现,这些看似复杂的技术概念,其内核依旧是 “强大的基础模型 + 灵活的工具调用能力 + 结构化的数据 + 明确的操作指引” 这一经典组合的不断演进与封装。

希望这篇系统性的解析,能帮助大家更好地理解这些关键概念及其关联,在实践中做出更合适的技术选型与架构设计。