一行命令本地部署GLM-5.2:在Blackwell GPU上零成本跑753B MoE大模型
在终端输入 vllm serve nvidia/GLM-5.2-NVFP4,一台装有 Blackwell 架构的机器就能将总参数达 753B 的 MoE 模型以兼容 OpenAI 的接口启动,无需任何云服务开销。
技术剖析:一行命令的底层支柱
vLLM 是一个源自加州大学伯克利分校 Sky Computing Lab 的开源推理框架,在 GitHub 上已收获 84.5k 星标。它通过 PagedAttention 和连续批处理技术将吞吐量提升到新的数量级。更重要的是,它对各类量化格式兼容并蓄:FP8、MXFP4、NVFP4、INT8、INT4、GPTQ/AWQ、GGUF……支持超过 200 种模型架构,即拿即用。
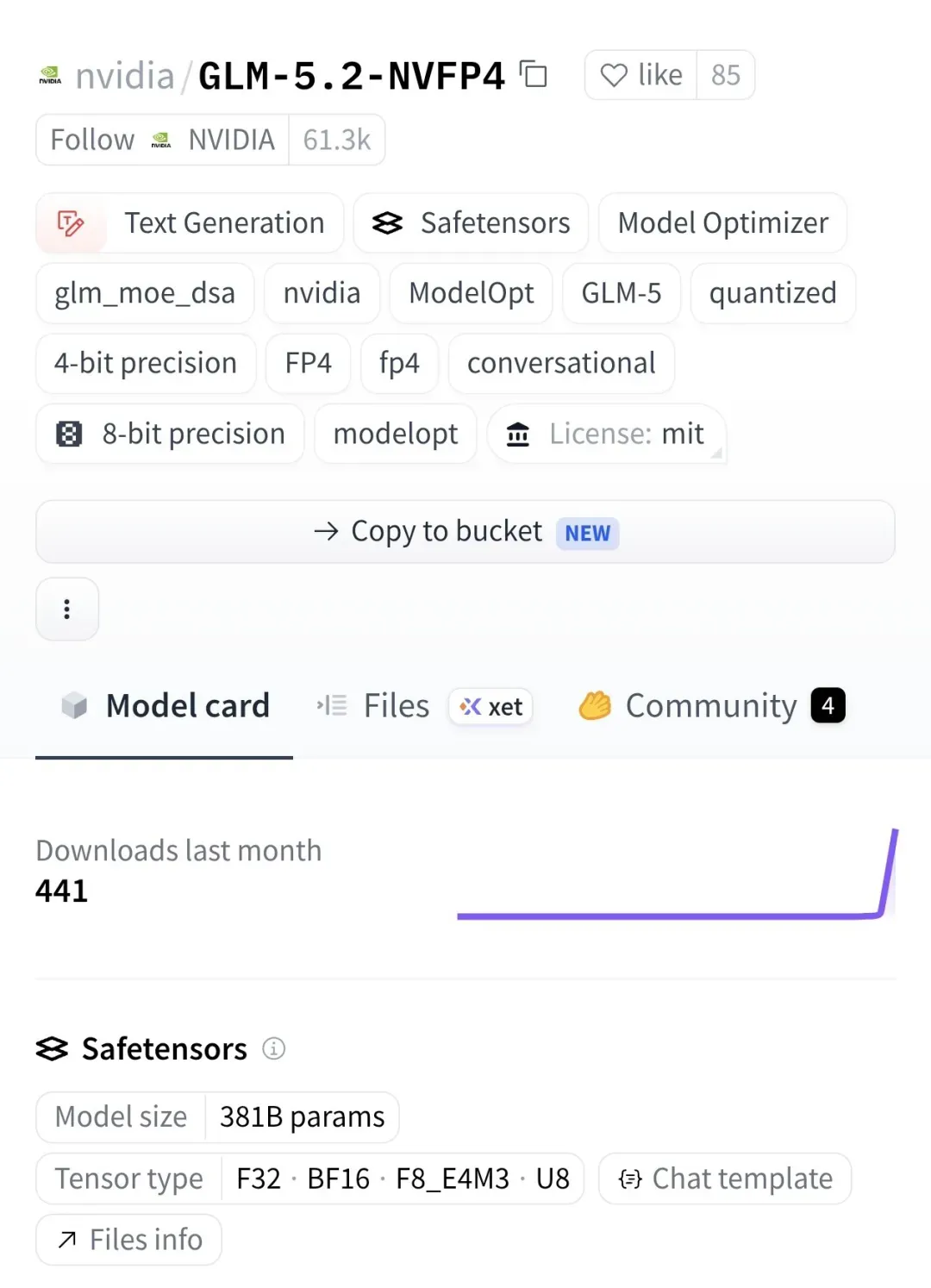
6 月下旬,NVIDIA 在 Hugging Face 正式发布 nvidia/GLM-5.2-NVFP4。该权重采用 Model‑Optimizer 工具对智谱 GLM‑5.2 进行 4 比特量化,并专门针对 Blackwell 架构 GPU 优化。与 FP8 格式相比,NVFP4 进一步压缩了显存占用,而在编程、推理以及百万 token 长上下文任务上的精度并未出现明显下滑。
智谱 GLM‑5.2 本身采用 MoE(混合专家)架构。公开数据显示其总参数达 753B,每次推理仅激活部分专家,实际激活的参数量远低于此。配合百万 token 的无损上下文窗口,官方在 Artificial Analysis 综合评测中取得 51 分,与 Anthropic、OpenAI 的旗舰模型并驾齐驱,并在编程能力上被贴上了“开源 SOTA”的标签。
采用 MIT 许可证,无论商用还是非商用部署,全球均无限制。
将这三者叠加——开源推理框架 vLLM、开源模型 GLM‑5.2 以及 NVIDIA 提供的硬件优化权重——最终用户获得的正是一个可离线运行、兼容 OpenAI API、无需云端的本地私有推理环境。

个人推理时代的真正壁垒
过去三年,个人运行大模型的最大瓶颈并非“能否下载到模型”,而是下载后能否在消费级或工作站级硬件上,以可接受的延迟完成一次有意义的推理。
FP8 量化已经让许多模型能够塞进单卡或双卡工作站的显存。然而,4 比特量化才是让 MoE 模型变得“入门级”的关键压缩比:MoE 模型虽然总参数量巨大,但每次推理仅激活部分专家,实际运行时的权重占用本就较低;若量化不够彻底,显存墙仍会率先挡住延迟目标的实现。
NVIDIA NVFP4 的价值正在于此:它不是一种泛泛的 4 比特方案,而是“Blackwell 原生支持”的结构化量化,内部将 FP4 计算单元与 Tensor Core 对齐,使精度损失从“可以忍受”变为“几乎不可察觉”。这意味着,此前用 FP8 已显存吃紧的工作站,现在可以额外容纳一整份 MoE 模型的权重。
结合 Sharpness‑Aware Minimization 等后训练技巧、量化感知训练路线,以及 NVIDIA ModelOpt 工具链,使得“开源模型 + 一行命令 + 本地硬件”的组合首次将门槛压得足够低:一个中型工作室、甚至一位拥有 GPU 的独立开发者,无需签署 API 协议、不必按月缴纳订阅费,即可获得接近闭源旗舰模型的编程与推理能力。
这便是“个人推理时代”最实在的定义:并非人人都能买得起一块卡,而是每个人都能将自己那块卡的价值挖掘到极致。
竞争新格局:三阶段演变
坊间流传着一篇广为传播的帖子,其核心判断是:竞争已从“闭源模型巨头之间的博弈”演变为“闭源与开源模型之战”,而归根结底,这是一场中国大模型厂商之间的角逐。
这个判断的前半部分很容易得到数据佐证。根据 OpenRouter 5 月的统计,中国模型的周调用量已逼近 9.2 万亿 Token,环比增长约 20%。DeepSeek‑V4‑Flash 以单周 3.43 万亿 Token 的调用量位居所有模型之首,腾讯 Hy3 preview 以 3.07 万亿紧随其后。而美国模型周调用总量停留在 4.93 万亿。这些数字表明,开发者流量正明显向中国模型倾斜,其推动力不仅来自价格,更因为工程可用性已跨过某个临界点。
然而,真正值得玩味的是后半部分——“中国大模型之间的竞争”。最近两个月,竞争逻辑已发生实质性分化:
第一层:闭源巨头仍须依靠服务和生态来维系订阅。随着 GLM‑5.2 在编程能力上达到 SOTA、在 Artificial Analysis 榜单跻身前三,智谱同时保留了 MaaS API 服务、智谱清言、AutoGLM 等产品线。这意味着开源模型已不再只是“打榜用的技术宣言”,而是直接成为生态战的入场券。API 订阅的留存逻辑必须从“模型唯一性”转向“工具链 + 体验 + 数据闭环”。
第二层:开源模型内部的竞争正演变为硬件 + 量化 + 工程栈的综合较量。GLM‑5.2‑NVFP4 并非由智谱自主完成量化,而是 NVIDIA 利用 ModelOpt 工具链在 Blackwell 硬件上产出的官方 4 比特权重。最终的服务入口则是 vLLM 的一行命令。模型厂商、硬件厂商与推理框架形成了一个从前端到后端不可分割的技术栈,MoE 架构的激活参数经济性和 4 比特的内存经济性在这个栈中得以同时成立。
第三层:NVIDIA 正从产品层面重新定义“推理成本”。过去几个月,NVIDIA 一方面通过 Model Optimizer 开源多种量化方案,另一方面在 Blackwell 架构中原生支持更低精度的张量计算。这并非“再卖一张卡”的逻辑,而是“让已售卡的服务密度再翻一倍”。开发者获得更高效的量化权重后,本地推理成本在已摊销硬件的基础上变得越来越低,订阅 API 因此丧失了一部分不可替代性。
价格、模型、框架、硬件这四条线索,在过去两个月里开始相互咬合。对普通用户而言,这意味着 API 调用费和“再等三个月出新型号”不再是唯一的使用路径。
未来展望:推理成本曲线的定义权
极端的可能性已无需猜测。vLLM 一行命令、硬件原生 4 比特量化、开源 MoE 权重这三个条件已经同时满足。真正的变量在于:一个工作室的 GPU 采购策略、一张卡能运行多大体量的模型、以及一次推理的延迟能否进入可交互级别。
竞争的分水岭已变成“谁能定义推理成本曲线”。模型厂商若想靠订阅留住用户,就必须在服务、工具和生态层面同时证明:云服务所带来的价值不仅仅是“能跑”,更是“更方便、更稳定、更可信、更理解你的数据”。否则,推理硬件与开源模型的组合将不断降低“自建”的门槛。
大模型厂商的商业策略将由此分化:一部分继续向上层拓展,聚焦体验、生态和封闭数据优势;另一部分则主动拥抱开放权重,凭借模型本身的质量和服务叠加来留住用户。智谱是目前唯一一家同时布局这两条路线的中国公司。它能走多远,也将决定开放权重路线究竟蕴含多大的商业想象空间。
那篇帖子的判断或许有些激进,但它所指出的结构性变化——硬件、框架、模型三者同时走向开源化——正被 vLLM、NVIDIA 和智谱这三条独立线索同步证实。
参考来源
- 智谱 Z.ai 官网 https://zhipuai.cn
- vLLM 官方文档 https://docs.vllm.ai
- NVIDIA/GLM-5.2-NVFP4 Hugging Face https://huggingface.co/nvidia/GLM-5.2-NVFP4
- NVIDIA Model-Optimizer https://github.com/NVIDIA/Model-Optimizer