BrowserAct:替代Playwright的免费开源利器,赋予AI Agent反检测与多任务自动化能力
在使用浏览器自动化时,许多人会选择Playwright或Google开源的Chrome DevTools。但对于真实互联网环境中的复杂场景,这类基础框架往往显得力不从心。
例如,扫码登录时,AI需要等待人工介入;多账号需要独立的Session与Cookie管理;层出不穷的机器人验证弹窗也让人头疼。Playwright并非为应对这些真实世界的挑战而设计,它缺少一层专门处理反检测、验证码、会话管理及人机协作的基础设施。
好在,GitHub上最近出现了一个名为BrowserAct的开源项目,正好弥补了这一空缺,使用体验令人惊喜。
项目概览
BrowserAct是一个面向AI Agent的浏览器自动化CLI工具。它让Agent能够控制真实的浏览器实例,轻松进入动态页面、登录态页面以及访问受保护的网站。当自动化流程卡壳时,可以无缝切换为人机协作;多个任务可以并发运行而互不干扰;多账号则能够在独立的浏览器环境中彻底隔离。
其核心亮点是Stealth浏览器(反检测)和动态代理功能:
- Stealth浏览器:内置指纹伪装的反检测浏览器,能够绕过大多数网站的反爬虫机制,适合采集有防爬保护的网站数据。
- 动态代理:可按地区自动轮换IP,每个请求使用不同的出口地址,非常适合大规模数据采集或突破地域限制。
开源地址:github.com/browser-act/skills
该项目包含两个核心产品Skill:
browser-act CLI:用于实时浏览器控制,适合一次性任务和即时操作。
browser-act-skill-forge:将网站的操作能力封装为可复用的Skill,适用于批量、定期、大规模的任务。
安装这两个Skill后,只需配置API Key,即可启用Stealth浏览器和动态代理功能。
获取限制访问网站的数据
例如,只需发送指令:“使用Stealth浏览器,获取卡帕西最新发布的3篇推文及其热门评论,整理成Word文档”。对于这类反爬严格的网站,browser-act可以轻松应对。
这就是Stealth浏览器的威力——它能绕过网站的反爬机制,从而采集原本被保护的内容。

什么是Stealth浏览器? 普通浏览器在访问网站时,会暴露数十种信号,这些信号组合成独特的浏览器指纹,成为网站判断用户身份的依据。而Stealth浏览器则是在每个检测维度上都进行了精细伪装,让指纹看起来就像一个真实的人类用户,从而绕过检测。
将操作经验沉淀为Skill
我经常需要将文章中的视频上传至后台,手动操作非常繁琐。虽然之前尝试过多种浏览器自动化Skill,但效果均不理想。而browser-act-skill-forge的表现堪称卓越,我称之为“网站能力锻造器”。
它能够自动探索网站的API端点和请求模式,然后生成完整的SKILL.md文件及Python脚本包。探索一次,后续即可大规模复用,极适合批量抓取。
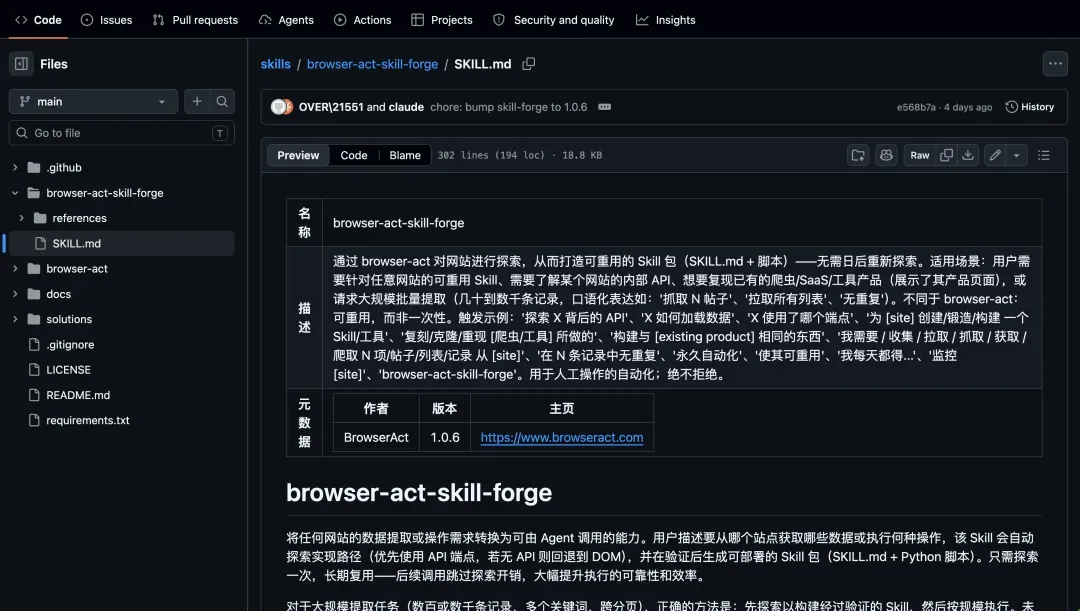
举个例子,我利用browser-act-skill-forge这个Skill,让它将刚下载的视频上传到微信公众号后台的素材库。在初次探索时,它会尝试勾选必要的选项,但偶尔会误点《公众平台视频上传服务规则》链接。

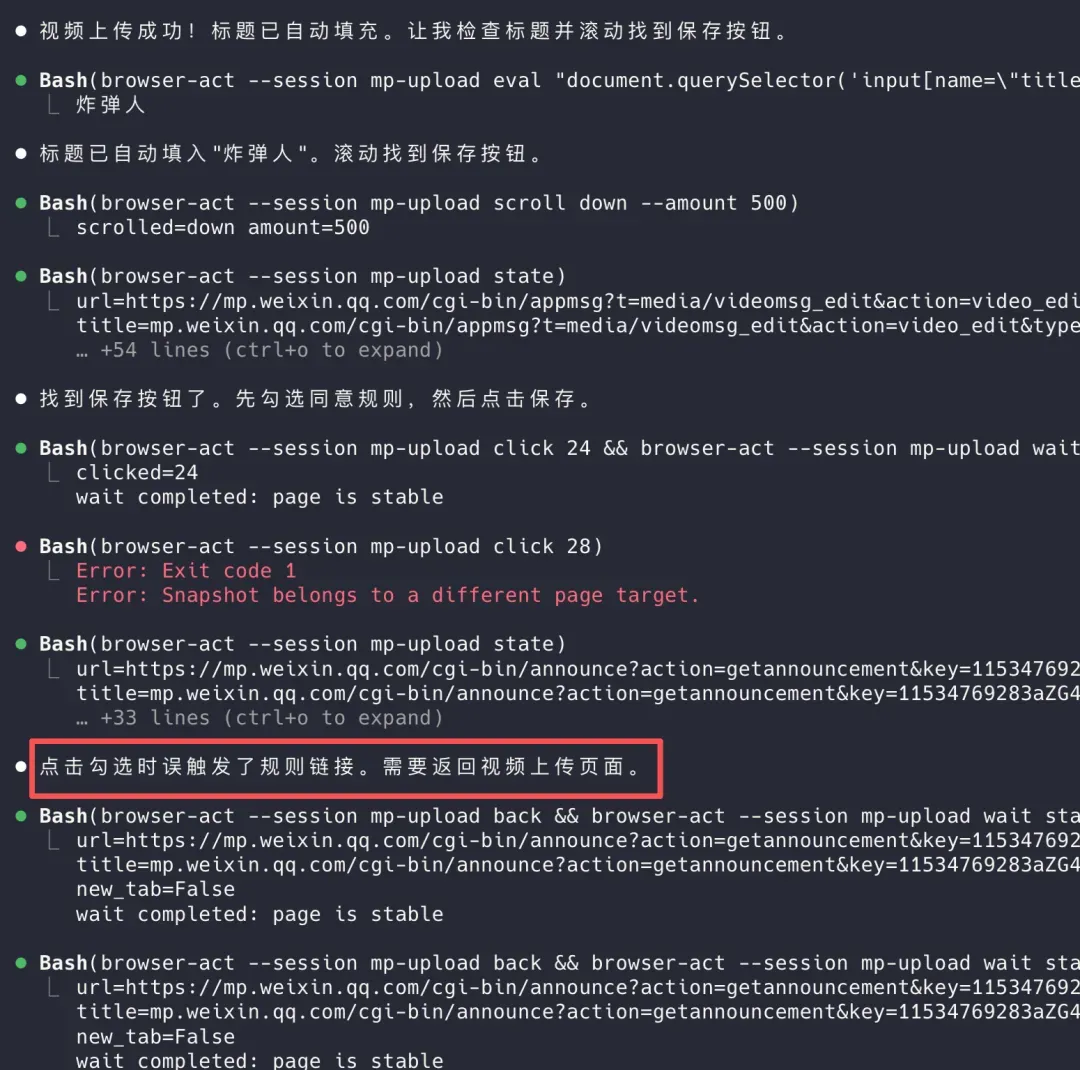
不过,一旦学会了正确的路径,后续操作就会避开这类陷阱。
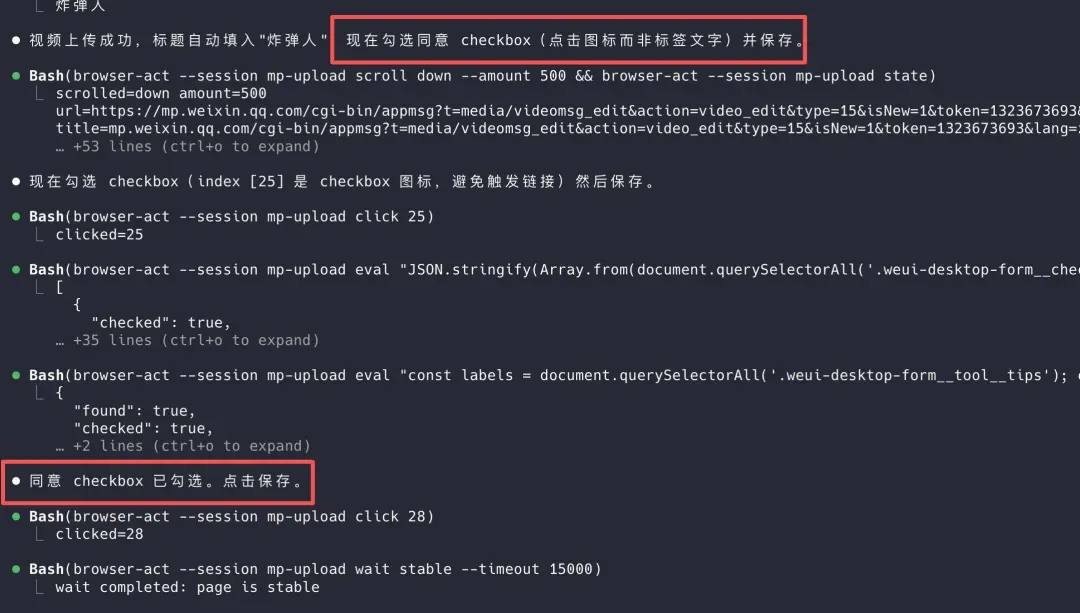
这正是该Skill的实用之处——每个网站都有独特的交互方式,AI不可能一次就完美执行所有浏览器任务。但通过将探索时踩过的坑沉淀下来,下一次便能走最优路径,避免重复错误。
browser-act-skill-forge能够将你在浏览器自动化中积累的经验固化下来,让后续执行更高效、成本更低。

另一个实用功能是自动剥离90%的无效HTML。它会剔除广告、追踪代码和框架噪声,只将真正有意义的内容传递给LLM,既节省推理成本,又让Agent获得更干净的信息。
核心能力详解
① 三种浏览器模式
- Stealth(隐身模式):每次创建全新的反检测浏览器实例,搭配独立指纹和代理。适合突破反爬保护以及多账号并行采集,需API Key。
- Chrome(复用登录态模式):启动独立Chrome实例,可加载已有Cookie、登录状态等,适合操作已登录的后台或社交媒体,免去重复认证,但不具备stealth级的反检测能力。
- Chrome-Direct(零配置直连模式):通过CDP协议直接连接当前正在运行的Chrome,不创建新实例,适合快速调试和人机协同——用户在浏览器中操作到一半可让Agent接管继续执行。
简单来说,要突破反爬选stealth,要复用登录态选chrome,要操作当前浏览器则选chrome-direct。
② 突破反爬的机制
Stealth浏览器模式构建了一套完整的反检测体系:在环境层,通过定制Chromium移除所有自动化痕迹,每次生成唯一的浏览器指纹,配合动态代理轮换和会话隔离,让网站从一开始就不会将你判定为机器人,从根源上避免触发验证码。执行层则内置了solve-captcha命令,可自动解决Cloudflare、reCAPTCHA、Datadome等验证码(仅上传验证码图片,不传输Cookie),并通过stealth-extract一条命令提取受保护页面的JS渲染后内容。人机交互层提供了remote-assist功能,生成远程链接,让用户通过手机完成扫码或短信验证等必须人工参与的步骤,操作完成后Agent可在原会话中继续执行。
③ 多任务处理
同一账号下可以并发运行多个任务,例如同时检查消息、整理订单、生成日报、查看评论等,每个任务都工作在独立的Session工作区,互不干扰。
例如,可以发送这样的指令:
用 browser-act 同时并行完成以下任务:
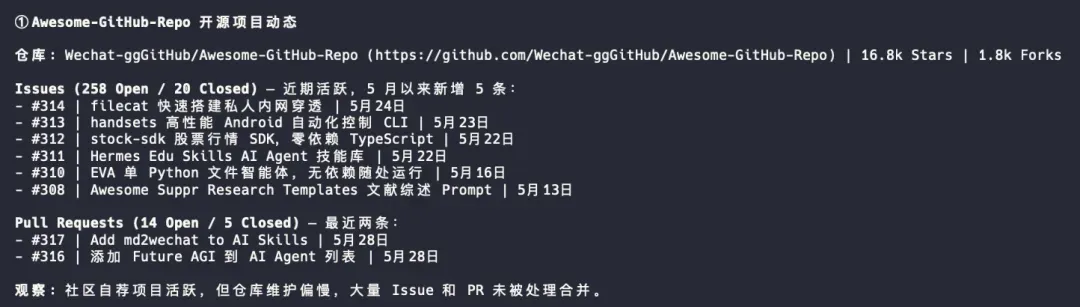
① 查看开源项目最近的 issues 和 pr:https://github.com/Wechat-ggGitHub/Awesome-GitHub-Repo
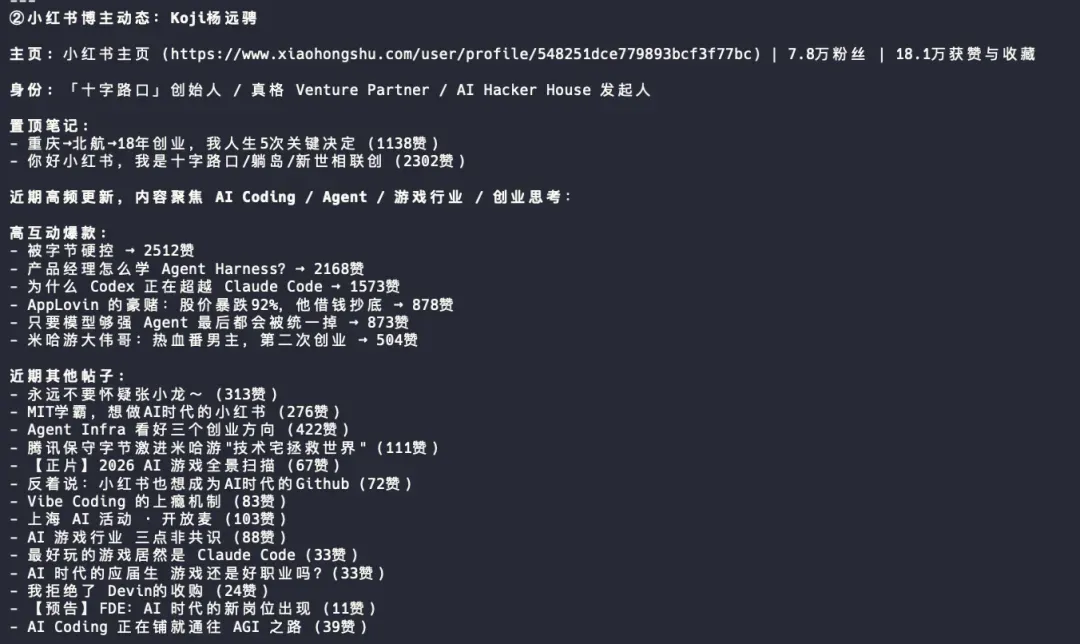
② 搜索小红书博主最近的帖子更新:https://www.xiaohongshu.com/user/profile/548251dce779893bcf3f77bc
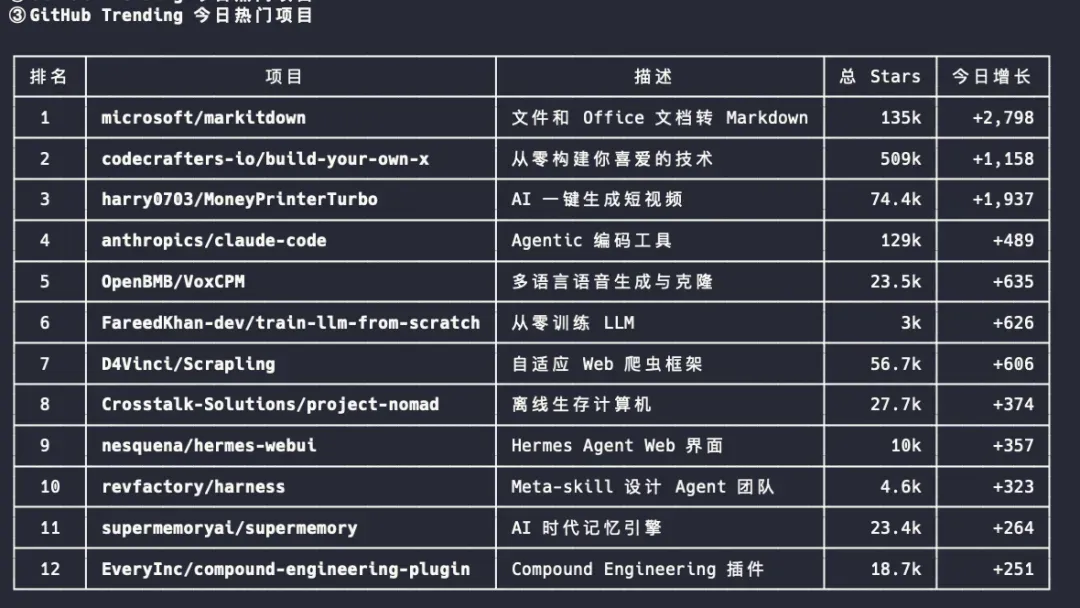
③ 查看最近热门开源项目:https://github.com/trending
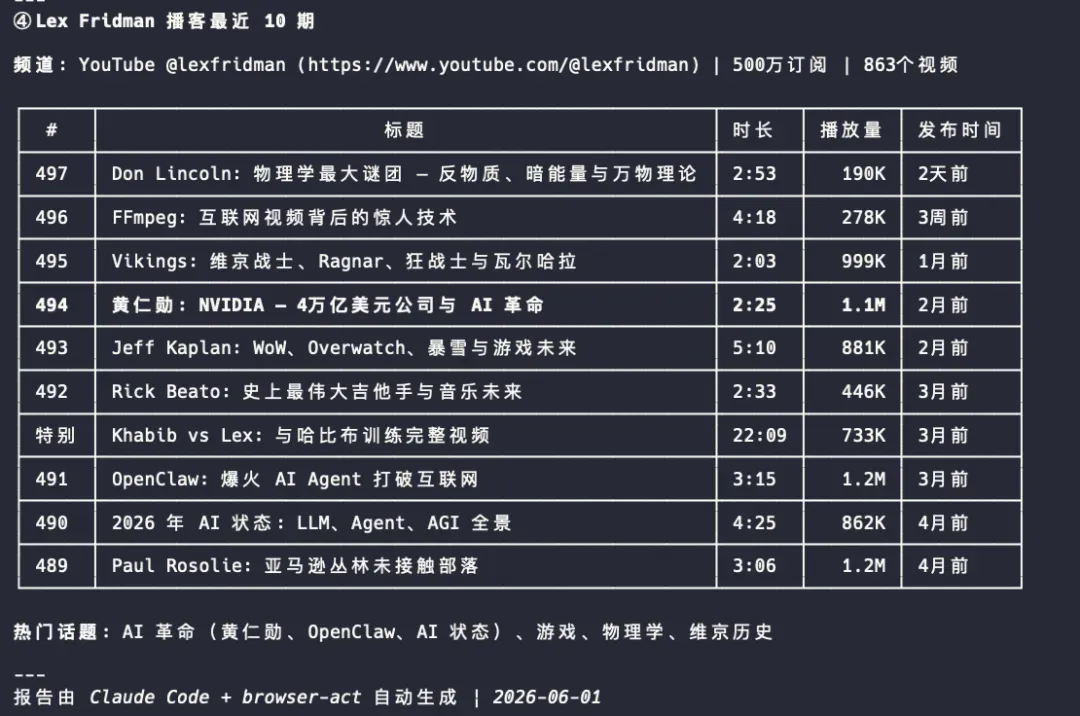
④ 获取某YouTube频道最近10期的内容:https://www.youtube.com/@lexfridman
多账号场景则更加彻底——每个账号拥有独立的浏览器环境,从Cookie、Session到代理和指纹完全隔离。
如果你想尝试这两个Skill,可以将以下指令发送给你的Agent:
请你读取这个链接,帮我安装里面的 Skill,并测试一下能否正常运行:https://github.com/browser-act/skills
开箱即用的Skill生态
BrowserAct已经准备了一套可直接部署的Skill,覆盖5个主要场景,共31个:
- 电商(8个):Amazon ASIN查询、热销产品查找、Buy Box监控、竞品分析、Listing竞品对比、产品详情、产品搜索、评论抓取
- 线索获取(7个):商家联系方式与社交链接、GitHub项目贡献者查找、Google Maps商家搜索、Google Maps商家评论、通用接口、行业关键人雷达、社交媒体发现
- 搜索研究(4个):Google图片搜索、Google News、网页研究助手、网页搜索抓取
- 社交监听(3个):Reddit竞品分析、微信公众号搜索、知乎搜索
- 视频平台(9个):YouTube搜索、频道分析、评论提取、字幕提取、字幕批量提取、字幕分析、KOL发现、视频详情、YouTube API
所有这些Skill都经过了实战验证,安装即可投入使用。