余承东回归盘古大模型:openPangu 2.0发布,505B参数背后的算力困局与开源突围

2026年6月12日下午,东莞松山湖,华为开发者大会的聚光灯下,余承东走上舞台,说出了一句足以让所有人重新审视盘古大模型处境的话:“去年国庆节前夕,公司又把这个大模型交到了我手里。”
重逢在松山湖
openPangu 2.0 的参数规格并没有制造太多意外。Pro 版本总参数 505B,活跃参数 18B;Flash 版本总参数 92B,活跃参数 6B,上下文窗口统一为 512K。依旧采用 MoE 稀疏架构,深度绑定昇腾算力。官方给出的数据是,单卡吞吐指标达到业内主流开源模型的两倍。从6月30日开始,七大组件将逐批开源,涵盖模型权重、预训练代码、后训练代码和训练算子等。
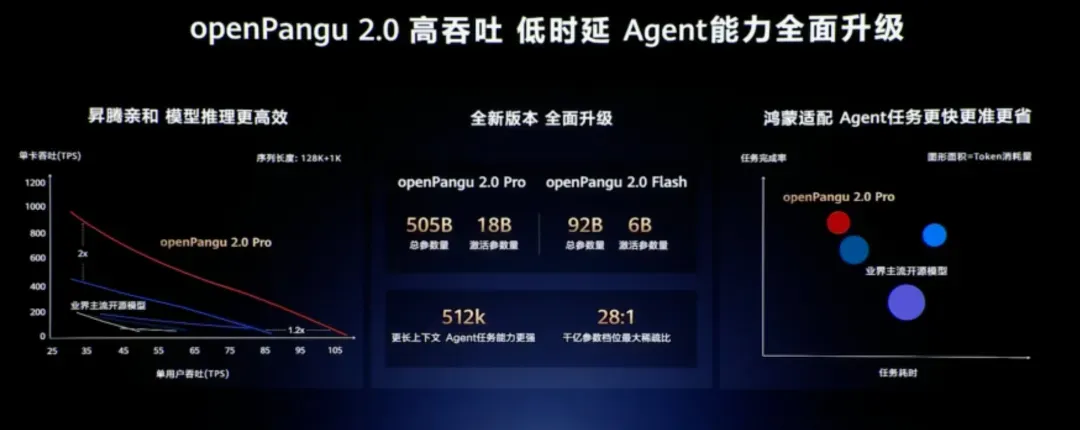
真正让现场停下脚步的,是余承东解释“为什么只有 505B”的瞬间。他说,华为的大量算力资源优先支持了国内其他企业的需求,留给自己训练的算力其实非常有限。在当前语境下,这句话显得格外坦诚。美国 GPU 出口管制不断加码,国产算力既要支撑华为自身的业务运转,又要通过昇腾生态为整个产业链供血。与其和市场进行参数竞赛,不如把精力集中在单卡效率和鸿蒙适配的深度上。
这种姿态与过去大家熟悉的“遥遥领先”式的宣言,拉开了明显的距离。余承东自己也不避讳地补了一句:“要去追赶、去超越,都需要时间。”
最先出发,却未最先抵达
余承东在发布会上重新拾起了一段过往的叙事:2021 年春天,华为发布了盘古大模型,那是国内第一个真正意义上的大模型。PanGu-α 论文发表于 2021 年春,最高参数达到 200B,确实早于百度 ERNIE 3.0 大约三个月,更远在后来那轮大模型井喷之前。单从“国内第一个”来说,盘古确实有资格称自己为先驱。
但如果把坐标放大到全球,GPT-3 早在 2020 年就已经证明了 175B 参数和 few-shot 能力。“全国第一”被延伸为“全球第一个”,依然是典型的余式表述。
更重要的是,去年 7 月,盘古经历了一场严重的信任地震。有研究报告直指盘古 Pro MoE 与 Qwen 在参数结构上存在“惊人一致”;一篇名为《盘古之殇》的内部文章则把研发过程中的混乱与压力摆上了台面。华为诺亚方舟实验室随后澄清,部分基础组件参考了业界的开源实践,并已经增加了版权声明。
在此之后,盘古几乎从公众视野里消失了一年。直到去年秋天,余承东被重新任命,接管这个大模型。
赛道上的群雄
今天的盘古,所要面对的市场已经不是2021年的空白地带。用 BenchLM 的综合评分来衡量,国产模型的梯队已经非常清晰。
DeepSeek V4 Pro(Max):BenchLM 评分 87,采用 1.6T MoE 架构,活跃参数 49B,SWE-bench Verified 达到 80.6%,MIT 开源,上下文长度 1M,API 定价为每百万 token 0.435 美元 / 0.87 美元。
Kimi K2.6:评分 81,1T MoE 架构,活跃参数 32B,在 SWE-Bench Pro 上追平 GPT-5.5(58.6%),提供 256K 上下文,深度研究功能覆盖法律和学术场景。
GLM-5.1:评分 83,754B MoE,活跃参数约 40B,MIT 协议开源,并且是首个在华为昇腾 910B 上完成完整训练的开源前沿模型。
小米 MiMo-V2.5-Pro:1.02T MoE,活跃参数 42B,1M 上下文,SWE-bench 78.9%,Terminal-Bench 68.4。一家手机厂商,却在全部核心维度上和第一梯队站到了同一高度。
阿里 Qwen 系列依然拥有最宽的产品线,从 3B 到 397B 全面覆盖。Qwen3.6-35B-A3B 以 35B 总参、3B 活跃参数在 GPQA Diamond 上拿到 86.0,AIME 达到 92.7,成为 2026 年效率比最出色的模型之一。不过也要注意,阿里的最强版本 Qwen 3.7 Max 已经转为闭源。开源与闭源之间的摇摆,在国内头部厂商中依旧是一个充满变量的命题。
被击穿的价格底线
今年 5 月,DeepSeek V4 Flash 将缓存命中的输入价格压到了每百万 token 0.0028 美元。小米 MiMo-V2.5 在 5 月 27 日跟进降价,同规格缓存命中价同样降到 0.0028 美元。
这些数字到底意味着什么?来看一个现实的对比:用 DeepSeek V4 Flash 跑 100 万次 Agent 中间推理步骤,成本大约为一美元。而用同样次数的 Claude Opus 4.6 来跑,成本则高达约 850 美元。两者的差距在 35 倍到 86 倍之间,具体取决于路由策略和缓存命中率。
当推理成本降到这种水平,模型的使用方式也随之彻底改变。批量处理、摘要清洗、日志分析、Agent 中间步骤……这些过去因为太昂贵而不敢大规模执行的任务,如今可以毫无压力地交给最便宜的模型。只有最关键的路径,才会被路由到旗舰模型上。今年第一季度,OpenRouter 上国产模型的调用量已经超过了 GPT 系列,虽然这个口径并不能代表全球全量市场,但它至少释放出一个明确的信号:在多模型路由的世界里,价格正在和性能一样,左右着开发者的选择。
还给盘古的空间,还剩多少?
盘古带着“最早出发”的故事重返牌桌,但在 2026 年的赛场上,一个故事已经很难改变格局了。DeepSeek 靠着开源和极致性价比站稳了脚跟,Kimi 用长上下文和深度研究构建了自己的壁垒,GLM 以 Agent 稳定性和工具调用精度收获信任,MiMo 凭借工程效率和多模态能力闯出了一片天。它们各自找到了用作品说话的立足之地。
华为手里当然也握着几张重要的牌。昇腾生态是国内唯一能规模化替代 NVIDIA 的算力选项,鸿蒙的设备基数已超过 13 亿,政企市场的渠道能力几乎无人能出其右。openPangu 2.0 的 505B 参数放在今天的头部模型里并不算大,但它的竞争力或许会来自另一个维度。如果昇腾上的推理成本能够打下来,如果鸿蒙 Agent 的绑定能形成开发者的使用习惯,华为完全可以不靠参数取胜。
当然,这些“如果”都需要一张清晰的时间表来兑现。6 月 30 日的第一批开源组件,将交出第一份答卷。
盘古重新出山这件事本身,已经成为2026年国产大模型格局的一块试金石。它需要回答的问题不止一个:市场还能为一个重新起跑的开源模型留出多少空间?华为的入场时机是否依然正确?昇腾优化能不能拿出真本事?开源社区还愿不愿意再给出一次机会?