向量库不是万能药:知识图谱与本体论如何破解RAG幻觉难题
在RAG技术发展的初期阶段,向量数据库几乎成为该系统的标准配置。那么,这个技术组件的本质究竟是什么?
向量数据库本质上是一种专门用于存储和检索高维向量数据的信息系统,其核心要素包含两个层面:首先,通过Embedding模型将文本、图像、音频等内容转换为多维数组形式的向量表征;其次,支持基于相似度的快速检索,即根据查询向量定位语义最接近的Top-K条记录,并返回相关原始片段。这种机制实现了从关键词匹配到语义相似度计算的跨越,例如搜索"苹果"时,系统能够关联到iPhone等相关概念,而非仅限于字面匹配。
然而,早期技术存在显著局限。主流Embedding模型的有效编码长度通常限制在500个token左右(256-768 tokens,近期虽有扩展至8000 tokens的模型),这一限制与初代大模型的上下文窗口恰好吻合。过短的片段导致信息不足,难以生成完整语义表征;而过长的片段则会使核心语义被稀释,在相似性搜索中面临"信息淹没"风险。正因如此,向量数据库在RAG发展初期成为近乎唯一的选择,Coze、Dify、N8N等低代码Agent平台均将其作为默认组件,进一步强化了其不可或缺的印象。
实际应用却暴露出深层问题。最核心的缺陷在于"断章取义"现象——文档切分过程破坏了原文的完整性,导致表格断裂、论证逻辑中断等上下文割裂问题。典型案例包括:在电商退款场景中,系统可能仅召回"退款T+1到账"条款,却遗漏"黑名单用户与已发货订单除外"的关键限制,造成高风险订单的误操作;在医疗领域,降压药"适用症"与"妊娠期禁用"警示被切分到不同片段,可能引发严重的临床安全隐患。
面对这些局限,部分从业者开始质疑语义检索的可靠性,转而重新依赖关键词检索。随着大模型上下文窗口的持续扩展,向量数据库的地位变得愈发尴尬。但将全部责任归咎于技术本身并不公允,RAG效果不佳的根本原因往往在于数据处理的粗放——开发者试图以简单方案应对复杂场景,忽视了高质量数据工程的重要性。
当行业逐渐认识到仅靠语义相似性无法完整表征真实世界的复杂关系时,知识图谱技术重新进入视野。所谓关系,不仅是数据间的简单关联,更是上下文语境中实体间的逻辑纽带。例如,提及"苹果"时,系统应能自动关联iPhone、乔布斯等相关实体,这种深度关联能力正是知识图谱的价值所在。值得注意的是,当前复杂的AI知识库多采用"伪知识图谱"技术,融合关键词检索、向量检索等多种手段,而非纯粹的图结构查询。
向量检索的深层困境与知识图谱的破局之道
传统向量库构建知识库的底层逻辑存在结构性缺陷,其流程可概括为四个环节:机械切分、向量化映射、相似度检索、片段拼接。当原始文档篇幅较长且切分粒度不可控时,必然引发上下文完整性丧失问题。前文所述的电商与医疗案例,正是这一技术缺陷的典型体现。
这种"碎片化"处理方式的弊端在于:系统将知识压缩为孤立的向量点,依赖概率性匹配而非确定性推理,导致检索结果缺乏逻辑连贯性。尤其在医疗、法律等高风险领域,单一的信息片段往往不足以支撑可靠决策。
知识图谱的技术内涵与临床价值
知识图谱可视为知识库的有机组织形态,其本质是在传统知识管理基础上,通过图结构(实体-关系-属性)显式呈现知识的内在关联网络。三大核心构成要素包括:
- 实体节点:代表真实世界中的事物、概念或类别,如特定疾病、症状、药物等;
- 关系边:定义实体间的交互逻辑,如"疾病表现为症状"、“药物治疗疾病”;
- 属性集:描述实体或关系的特征值,如疾病的ICD编码、药物的用法用量等。
这种标准化表示不仅支持语义分析,更赋予计算机理解与推理能力。为便于理解,可通过糖尿病案例对比:
无关联结构的传统知识库示例:
疾病: {
名称: "糖尿病",
类型: "慢性疾病",
并发症: ["心血管疾病", "肾脏病", "神经损伤"]
}
症状: [
{ 名称: "口渴", 常见疾病: "糖尿病" },
{ 名称: "频繁排尿", 常见疾病: "糖尿病" }
]
具备显式关系的知识图谱示例:
实体: [
疾病("糖尿病"): {类型: "慢性疾病"},
症状("口渴"): {},
药物("胰岛素"): {用途: "控制血糖"}
]
关系: [
(疾病("糖尿病") - 表现为 -> 症状("口渴")),
(疾病("糖尿病") - 治疗 -> 药物("胰岛素"))
]
在大模型时代,尽管模型已擅长症状到疾病的初步推导,但幻觉问题仍威胁临床安全。知识图谱通过结构化路径推理可显著提升答案可靠性:
输入:咳嗽+呼吸急促+发热+胸痛
图谱推理路径:
症状组合 → 呼吸系统疾病候选{肺炎,支气管炎,COPD}
检查指标关联 → 血氧饱和度+白细胞计数+胸部影像
影像特征分析 → 肺炎(浸润阴影) vs 肺结核(钙化灶)
临床史整合 → 吸烟史、基础疾病 → 慢阻肺合并肺炎可能性
这种"慢思考"机制与大模型的"快思考"形成互补,构建快慢结合的双系统决策架构。
临床决策支持系统的兴衰启示
医疗领域是知识图谱最成熟的应用场景,其典型产品为CDSS(临床决策支持系统)。在AI大模型出现前,IBM Watson等系统已投入巨资研发,但最终未能成功。复盘其得失对当前AI应用开发具有重要借鉴意义。
CDSS的核心是基于规则的推理引擎,依赖领域专家手工构建的"if-then"规则库。例如:“若患者同时出现发热、咳嗽、气促,则提示呼吸道感染可能”;“若血糖持续超过阈值,则建议调整糖尿病治疗方案”。这些规则构成系统的知识库,其数据源自医学文献、临床指南及专家经验,通过持续更新保持时效性。
然而,该系统存在两大根本缺陷:
缺陷一:知识完整性瓶颈
CDSS效能完全取决于知识库的覆盖度与准确性。面对ICD-11收录的数万种疾病,完全依赖人工录入几乎不可能实现。更致命的是,任何知识错误都会导致整个系统可信度崩塌。知识校准与动态更新所需的高昂时间成本,成为制约其发展的首要障碍。
缺陷二:泛化能力鸿沟
CDSS难以处理真实世界中非结构化的患者描述。当患者表述为"胸口发沉,夜间平卧时加重"时,系统无法自动抽取"胸痛"、“呼吸困难"等医学实体。这种"宽输入-窄理解"的适配性缺陷,使得CDSS沦为资深医生不屑、初级医生难用的"鸡肋"产品。
大模型的出现弥合了这一技术鸿沟。CDSS沉淀的医学知识图谱,在具备强大自然语言理解能力的大模型加持下,得以焕发新生。图谱提供结构化医学知识,模型处理灵活语言表达,两者结合突破了传统系统的局限。
知识图谱与知识库的本质分野
两者的根本差异不仅是存储结构(图vs表),更是认知范式的不同——点状存储 vs 网状关联。
传统知识库如同中药房的百子柜,疾病、药品、症状分门别类存放,但2020年新冠疫情暴露了致命缺陷:当患者出现"发热+腹泻+味觉丧失"这类跨系统症状组合时,静态分类结构无法自主发现新型关联模式。
尽管可通过关系表增强传统知识库,但其关联模式需预先定义,难以应对未知情形。知识图谱的核心优势在于开放系统的可扩展性,以二甲双胍为例:
传统数据库新增"二甲双胍→减肥"关系需修改Schema,且需权威指南认可才能入库,更无法表达间接作用机制。而知识图谱仅需添加三元组即可实现低成本扩展,工程师维护负担显著降低。
生成机制与置信度保障
传统知识库依赖权威专家手工录入,每条数据均可追溯至顶级期刊或临床指南,确保高准确性与可验证性。知识图谱除继承结构化数据外,还能从文献、网页等非结构化源自动抽取实体关系。例如阿里KAG框架可从文章生成图谱,尽管当前效果尚待优化。
在医疗AI产品中,可追溯性与置信度是生命线。前者要求每条结论都能追踪至原始文献或数据采集过程,后者依赖清晰的算法逻辑与可靠的数据源。知识图谱通过显式关系链天然支持高置信度决策。
图谱与大模型的协同架构
当前医疗大模型仍面临幻觉困扰,如DeepSeek可能将普通感冒误诊为心肌炎,在急诊场景中此类错误可能致命。知识图谱与大模型的融合成为降低风险、提升可信度的核心路径,相关框架如GraphRAG已展现出潜力。
医疗置信度需从四个维度构建:
- 数据溯源:每条诊断必须关联权威指南或文献;
- 一致性:整合主诉、检查、影像等多模态信息,消除单一数据源偏差;
- 动态性:实时同步最新医学研究,动态调整诊疗路径;
- 可解释推理链:生成答案需附带完整证据链与推理过程。
以2型糖尿病为例,知识图谱可构建包含病因、症状、检查、药物、禁忌的完整知识网络,对大模型生成过程形成实时约束。
多层防御体系的工程实践
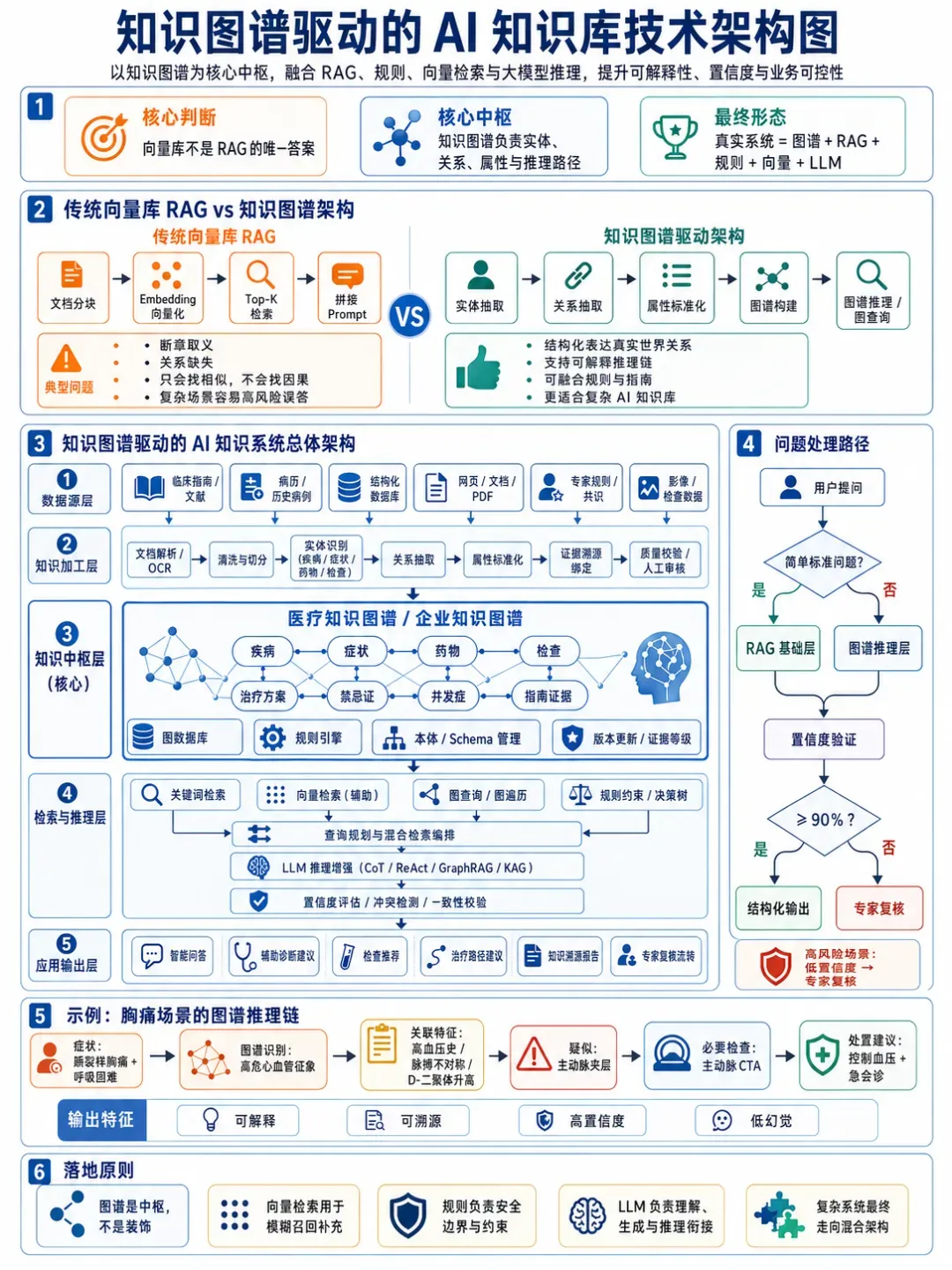
将知识图谱与RAG技术结合,可构建分层诊断体系:
系统通过智能路由实现三层防御:
- 基础层:简单查询由传统RAG处理,快速响应;
- 图谱推理层:复杂多模态问题触发图结构分析;
- 置信度验证层:结果需超过预设阈值(如90%)方可输出,否则转专家复核。
当患者输入"咳嗽伴胸痛"时,图谱可结构化推理: 症状→呼吸系统疾病候选→影像特征鉴别→临床史整合→最终诊断建议。相比纯RAG的信息堆砌,图谱提供逻辑链条与证据溯源,极大增强医生信任度。
对比实验揭示价值差异
以"儿童发热3天伴咳嗽,胸片显示肺叶浸润影,白细胞15×10⁹/L"为例:
纯大模型模式:可能罗列肺炎定义,但无法结合具体检查数据,缺乏针对性。
RAG增强模式:检索相关指南与病例,给出规范诊疗建议,但信息组织较为松散。
图谱+RAG融合模式:结构化输出"肺炎链球菌肺炎"可能性,附带证据链:
- 症状关联:发热+咳嗽→肺部感染(置信度0.85)
- 检查验证:肺叶浸润影+白细胞升高→细菌性肺炎(置信度0.92)
- 治疗建议:头孢曲松经验性用药,附剂量计算与禁忌检查
这种带溯源、有推理、可验证的输出模式,对临床医生具有极强吸引力。
本体论:知识图谱的行业KnowHow
本体论(Ontology)在AI知识系统中的核心使命是定义"世界应如何被理解”,它构成知识图谱的建模逻辑。两者关联密切:图谱是可见的网络,本体论是背后的规则体系。
以CDSS为例,不能简单将"发热"、“肺炎”、“抗生素"等同为节点,因其本质属性迥异:
- 发热=症状
- 肺炎=疾病诊断
- 抗生素=药物类别
- 白细胞升高=检查指标
- 细菌感染=病因
- 用药禁忌=约束条件
本体论的价值在于:
- 明确实体类型:疾病、症状、药物、检查、指南、禁忌证等;
- 规范关系语义:疾病"表现为"症状,药物"治疗"疾病,药物"禁用于"特定人群;
- 定义关系强度:因果、相关、并发、风险提示等区分;
- 设定推理规则:哪些关系可传递,哪些需证据等级约束。
例如三条关于二甲双胍的关系:
- “治疗"2型糖尿病(适应证,高置信度)
- “可能导致"体重下降(副作用关联)
- “通过AMPK通路影响"代谢(机制解释)
若缺乏本体论区分,系统可能错误推导出"二甲双胍可用于减肥”。因此,本体论是让知识图谱具备行业深度理解的建模规则,在高风险领域不可缺失。
技术融合的未来演进
向量库从未是RAG的唯一选择,其将知识压缩为孤立向量点的模式本质脆弱。知识图谱的复兴,是对知识本质的回归——它追求实体、属性、关系构成的确定网络,通过可解释逻辑链将检索从概率匹配提升至关系推理。
工程实践正走向务实融合:复杂AI知识库业务中,“伪知识图谱"的实现往往就是CoT(思维链)机制本身。真实系统通常是关键词检索、规则路由、向量相似度与图查询的混合架构。
例如PageIndex等框架通过层级化索引,将检索转化为"规划-取证"流程:先定位知识域,再精读相关内容。此时向量库退居为处理模糊查询的补充工具,这才是其更适切的角色。
展望未来,AI知识系统可能不再显式区分这些组件,而是内化为自主规划、多步推理、自我校验的Agent能力。从"检索增强"迈向"推理增强”,使机器不仅能定位信息片段,更能理解因果逻辑,最终交付可信答案。Google NoteBookLLM的技术路径已展现这一方向的潜力。
至此,本文已全面阐述了向量库的局限性、知识图谱的技术价值、本体论的建模意义以及融合架构的工程实践,希望能为构建高置信度AI系统提供有益参考。