GLM-5.2 登顶 SWE-bench Pro:国产开源编码模型如何以六分之一成本挑战 GPT-5.5
由Z.ai(原智谱AI)推出的GLM-5.2在SWE-bench Pro基准上取得62.1分,超越GPT-5.5的58.6分;同时,其API成本仅为每百万token5.80美元,而GPT-5.5约为35美元,成本差距接近6倍。
该模型参数规模达753B,在长上下文与复杂代码任务中表现突出。
对开发者而言,这不仅是一次性能层面的追赶,更是一个可直接验证的结构性转折点:在关键软件工程基准上,开源/开放权重模型首次进入与最前沿闭源模型同一竞争区间,并在成本效率上形成显著优势。
- 参数规模:753B
- SWE-bench Pro:62.1
- 成本对比:约1/6(GLM-5.2 vs GPT-5.5)

GLM-5.2 基本参数一览
GLM-5.2 拥有 7530 亿参数,采用 MIT 许可证开源,支持 100 万 token 上下文窗口。模型在 Hugging Face 上可直接下载,能接入 20 余种第三方编码环境。MIT 协议赋予企业自由修改、微调和商用的权利,无版税和区域限制。
Z.ai 对它的定位非常清晰:这不只是 “开源追赶闭源” 的叙事,而是 “开源与闭源站在同一起跑线” 的开端。
编码基准:硬碰硬的结果
SWE-bench Pro 考核真实软件工程任务,包括长时间代码库维护、多步开发与项目协调。GLM-5.2 得分 62.1,GPT-5.5 为 58.6。在 FrontierSWE 上,GLM-5.2 为 74.4%,略低于 Claude Opus 4.8 的 75.1%,但高于 GPT-5.5 的 72.6%。此外,MCP-Atlas 和 Humanity’s Last Exam 也均由 GLM-5.2 领先。
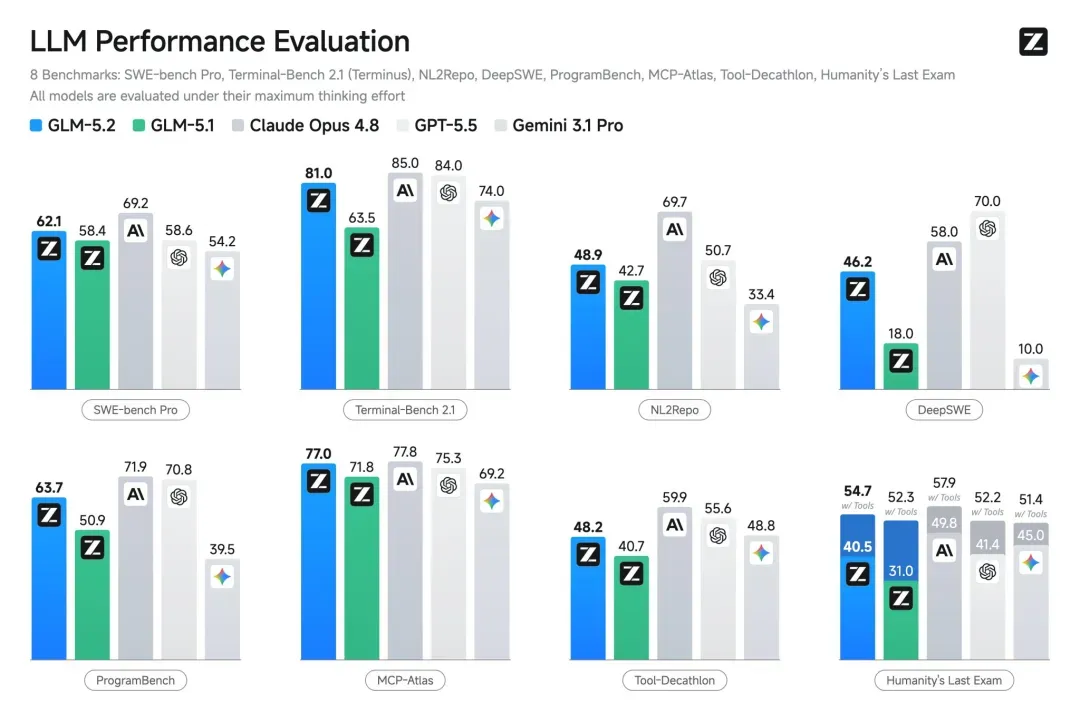
四组基准测试对比
● SWE-bench Pro:GLM-5.2(62.1)超过 GPT-5.5(58.6),差距 3.5 分
● FrontierSWE:GLM-5.2(74.4%)略低于 Claude Opus 4.8(75.1%),但高于 GPT-5.5(72.6%)
● MCP-Atlas:GLM-5.2(77.0)高于 GPT-5.5(75.3)
● Humanity’s Last Exam:GLM-5.2(54.7)高于 GPT-5.5(52.2)
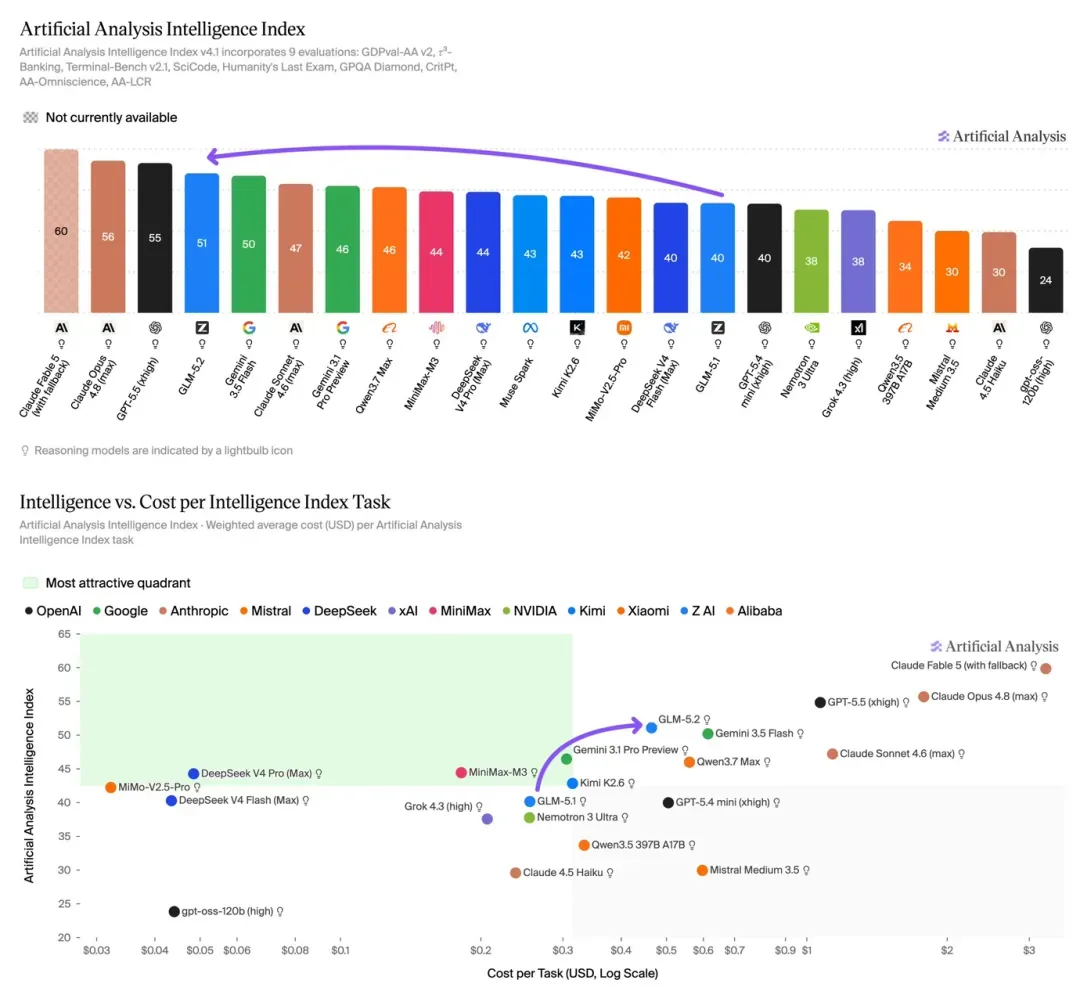
在 Artificial Analysis 的知识工作基准中,GLM-5.2 获得 1266 Elo 分,介于 GPT-5.5 与 Opus 4.8 之间。该测试围绕多周项目、碎片化输入和实际产出构建,比单纯分数更能体现日常开发体验。
架构:IndexShare 如何节省算力
GLM-5.2 采用 IndexShare 架构,让每四个稀疏注意力层共享一个索引器,在 100 万 token 上下文环境下,每 token 浮点运算减少约 2.9 倍。通俗地说,长上下文推理成本大幅下降。多 token 预测层用于推测解码,推理时接收的 token 长度最高可提升 20%。模型提供两种推理模式:Max 模式追求峰值性能,High 模式在性能、延迟和 token 消耗之间取得平衡。
判断:IndexShare 的意义不仅是节省算力,更在于让百万级 token 上下文从 “能跑” 变为 “跑得起”。对需要处理长代码库或多文档输入的团队而言,这种成本差距是决定性的。
成本:六分之一的钱干差不多的活
GLM-5.2 定价:输入 1.40 美元/百万 token,输出 4.40 美元/百万 token,合计 5.80 美元。GPT-5.5:输入 5.00 美元,输出 30.00 美元,合计 35 美元。两相比较,成本相差 6 倍。
成本拆解
GLM-5.2 总成本:5.80 美元/百万 token
GPT-5.5 总成本:35 美元/百万 token
成本节省约 83%,缓存输入费率 0.26 美元/百万 token
长上下文工作负载可走缓存通道,成本还能再压
本地部署:消费级硬件能跑吗
原始模型体积 1.51 TB,经 GGUF 量化后压缩至 238 GB(缩小 84%),准确率仍保持 82%。在 2-bit 压缩下,256 GB 内存或显存的系统即可运行。
量化版本内存需求
● FP8 格式:约 744–890 GB 内存
● 动态 1-bit 量化:约 176–180 GB 内存
● KV 缓存开销(FP16/BF16):每 100k token 需 15–20 GB
● KV 缓存开销(8-bit):每 100k token 需 7.5–10 GB
● KV 缓存开销(4-bit):每 100k token 需 3.5–5 GB
社区反馈显示,512 GB Mac、GB10 集群或多台 128 GB AMD AI Max 系统在技术上可以运行,但在 50K+ 上下文窗口下,预处理和生成性能会出现下降。消费级硬件距离 “好用” 仍有距离,但 “能跑” 本身已释放重要信号。
开源意味着什么
过去两年,OpenAI、Anthropic 和 Google 主导了 AI 基准测试榜单。开源模型虽在稳步进步,却很少在复杂编码和长周期工程任务上匹敌最强闭源系统。GLM-5.2 改变了这一局面。
Jeremy Howard 公开评价 GLM-5.2 “至少与 Opus 4.8 和 GPT-5.5 一样好”,同时指出缺乏视觉支持是主要短板。Reddit 的 r/LocalLlama 社区认为,GLM-5.2 与 MiniMax/Mimi 模型一道,显著缩小了前沿模型与大型开源模型之间的差距。
对忧心供应商锁定、数据主权、监管不确定性或地理访问限制的企业而言,MIT 许可证意味着可以自主托管,不受区域限制。
适合
关注数据主权和供应商锁定的技术团队;有大内存硬件的本地部署实验者;需要长上下文编码但预算有限的开发者
可以先等等
需要视觉多模态能力的场景;消费级硬件(小于 256 GB RAM)用户;对延迟极度敏感的实时应用
怎么用
四种访问路径
API 调用:Z.ai 官方 API,OpenAI 兼容接口,最快上手
本地部署:下载 GGUF 量化版,用 llama.cpp 或 Ollama 运行
云端推理:Hugging Face 推理提供商限时免费试用
编码计划:GLM Coding Plan 分层定价,支持 Claude Code、OpenClaw 等工具
下一步
Z.ai 预测年底前将发布 Open Fable 级模型,若如期兑现,开源与闭源之争将进一步升温。但硬件门槛依旧存在:本地流畅运行 753B 参数模型所需的内存量,仍远离绝大部分开发者的桌面。
判断:GLM-5.2 并非 “开源终于追上” 的句点,而是 “前沿编码能力不再稀缺” 的起点。接下来值得关注的并非跑分,而是开发者实际迁移的速度——多少团队会从 GPT-5.5 切换至 GLM-5.2,切换后体验差距又有多大。
来源:Z.ai 官方文档 | Latent Space AI News | TechStartups 报道 | GGUF Loader 指南 | Artificial Analysis 基准测试