2026年4月深度透视:国内六大AI厂商CodingPlan与TokenPlan资费全览
AI工具实战手册 · 月度资费盘点
深度解析:阿里、腾讯、字节、百度、智谱、MiniMax
六大厂商CodingPlan与TokenPlan 4月最新计费方案
2026年4月,国内主要AI开发平台的定价策略持续分化,CodingPlan(包月按次)与TokenPlan(按量词元计费)之间的博弈仍在进行。对于开发者与AI智能体使用者而言,选择合适的方案直接关系到成本与响应稳定性。本文全面梳理六家厂商当月最新的资费标准与调用限制,供实际选型参考。
Token,常被直译为“词元”,从实际使用体验来看,或许把它看作“算力消耗的基本计量单元”更容易理解。
近期,因固定包月模式带来的成本压力日益显著,多家大厂的CodingPlan服务陆续调整,原本按次计费的方案逐渐收缩,转向更加精细的按Token消耗量计费的TokenPlan。这一转变引发了市场对两种计费模式的持续讨论。以下为截至2026年4月阿里云、腾讯云、字节跳动、百度、智谱与MiniMax的详细资费信息。
01
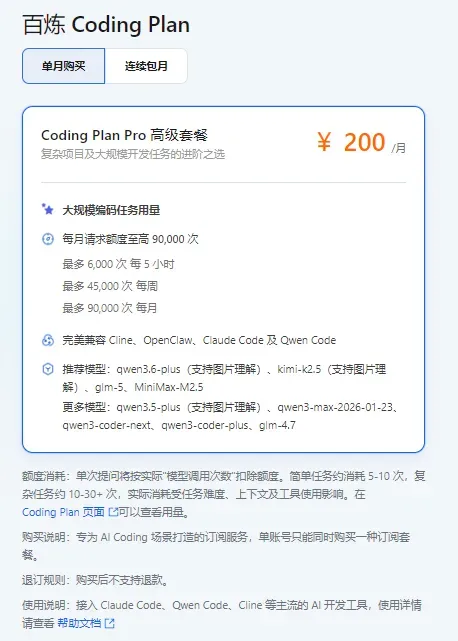
阿里云百炼平台
CodingPlan(包月按次模式)
阿里云百炼的包月方案正在逐步缩减:40元/月的Lite版本已停止新购与续费,200元/月的Pro版也已全面下架,目前用户仅能通过存量套餐继续使用。
TokenPlan(按量词元模式)
作为替代方案,阿里云推出了以Credits为中介的Token消耗计费方式,消耗量与模型调用直接相关。以qwen3.6-plus模型为例,一次典型请求的资源消耗明细如下:
Token消耗明细
| Token 类型 | 数量 | 消耗 Credits |
|---|---|---|
| 输入 tokens | 8,349 | 1.67 |
| 缓存 tokens | 40,794 | 1.63 |
| 输出 tokens | 573 | 0.69 |
| 合计 | 约 4 Credits |
📌 策略建议:在OpenClaw、Hermes等需要大量输入上下文的AI智能体场景中,此前200元/月的CodingPlan相比198元的TokenPlan更具性价比,包月模式可有效锁定高输入量下的成本上限。已购买Pro套餐的用户,在有效期内可继续享受稳定输出。
可用模型阵容
核心推荐:Qwen3.6-Plus(图文)、Kimi-K2.5(图文)、GLM-5、MiniMax-M2.5
其他可选:Qwen3.5-Plus、Qwen3-Max、Qwen3-Coder系列、GLM-4.7等
实测表现
基于200元/月CodingPlan进行的高负载及复杂智能体任务中,输出表现相当平稳。即使处于流量高峰期,平均响应时间也基本控制在10秒以内,部分高度复杂任务可在30至60秒内完成。
02
腾讯云
腾讯云的CodingPlan长期处于售罄状态,目前业务主线已全面转向TokenPlan模式。
TokenPlan
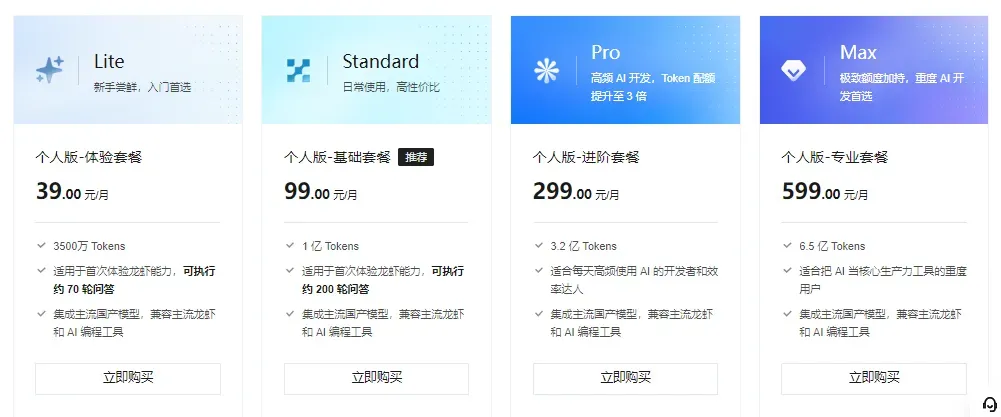
该方案基于纯Token计量进行计费,不使用中间货币单位。
可用模型阵容
智能路由:Auto模型(系统自动匹配最优算力)
自研系列:腾讯混元系列(Tencent HY 2.0 Instruct、Tencent HY 2.0 Think、Hunyuan-T1等)
第三方引入:MiniMax-M2.5、MiniMax-M2.7、GLM-5、GLM-5.1、Kimi-K2.5
03
字节跳动(火山引擎·方舟平台)
火山引擎目前仍然提供CodingPlan的直接购买入口。据市场反馈,该方案在高峰时段可能出现响应延迟的情况。

可用模型阵容
豆包系列:Doubao-Seed-2.0-Code、Doubao-Seed-2.0-pro、Doubao-Seed-2.0-lite、Doubao-Seed-Code
三方生态:MiniMax-M2.7、MiniMax-M2.5、Kimi-K2.6、Kimi-K2.5、GLM-5.1、GLM-4.7、DeepSeek-V3.2、Doubao-Embedding-Vision等
调用频次限制
| 版本 | 每5小时 | 每周 | 每月 |
|---|---|---|---|
| Lite | 1,200 次 | 9,000 次 | 18,000 次 |
| Pro | 6,000 次 | 45,000 次 | 90,000 次 |
04
百度(千帆平台)
百度千帆同样保持CodingPlan的开放购买。
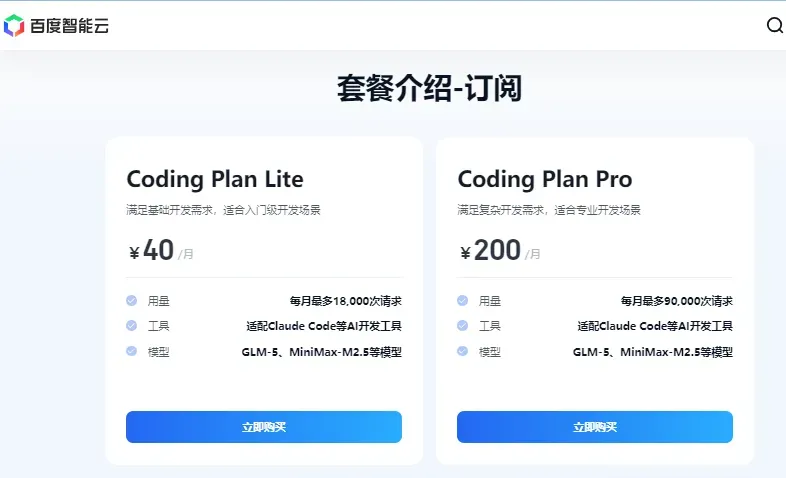
可用模型阵容
平台采取精简策略,主推GLM-5、Kimi-K2.5、MiniMax-M2.5、DeepSeek-V3.2等四款及以上核心模型。
调用频次限制
与火山引擎标准一致:
Lite版:每5小时1200次 / 每周9000次 / 每月18000次
Pro版:每5小时6000次 / 每周45000次 / 每月90000次
05
智谱 AI
智谱提供三级CodingPlan方案,但因需求旺盛,常年处于售罄状态,系统于每日10:00补充库存。部分用户反馈存在请求超时情况。
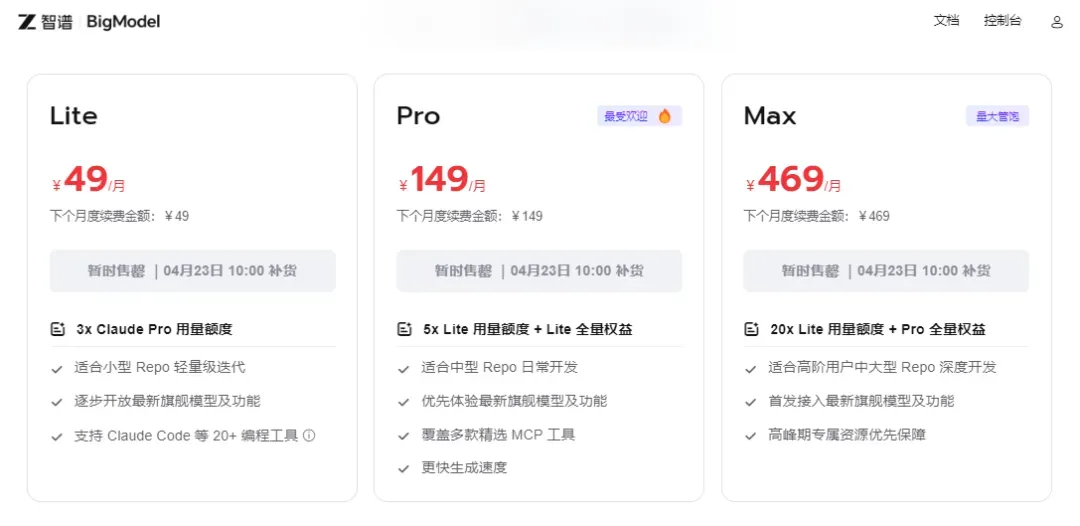
可用模型阵容
智谱采用封闭生态,仅支持自研模型队列:GLM-5.1、GLM-5-Turbo、GLM-4.7、GLM-4.5-Air等。
调用频次限制
以“Prompt”为统计单位:
| 版本 | 每5小时 | 每周 |
|---|---|---|
| Lite | 约 80 次 | 约 400 次 |
| Pro | 约 400 次 | 约 2000 次 |
| Max | 约 1600 次 | 约 8000 次 |
📝 说明:一次Prompt即一次完整提问,通常对应模型内部调用约15-20次。
06
MiniMax
MiniMax的TokenPlan本质上采用按次计费逻辑,划分为“标准版”与“极速版”两条产品线,主要差异在于响应链路的时效性。
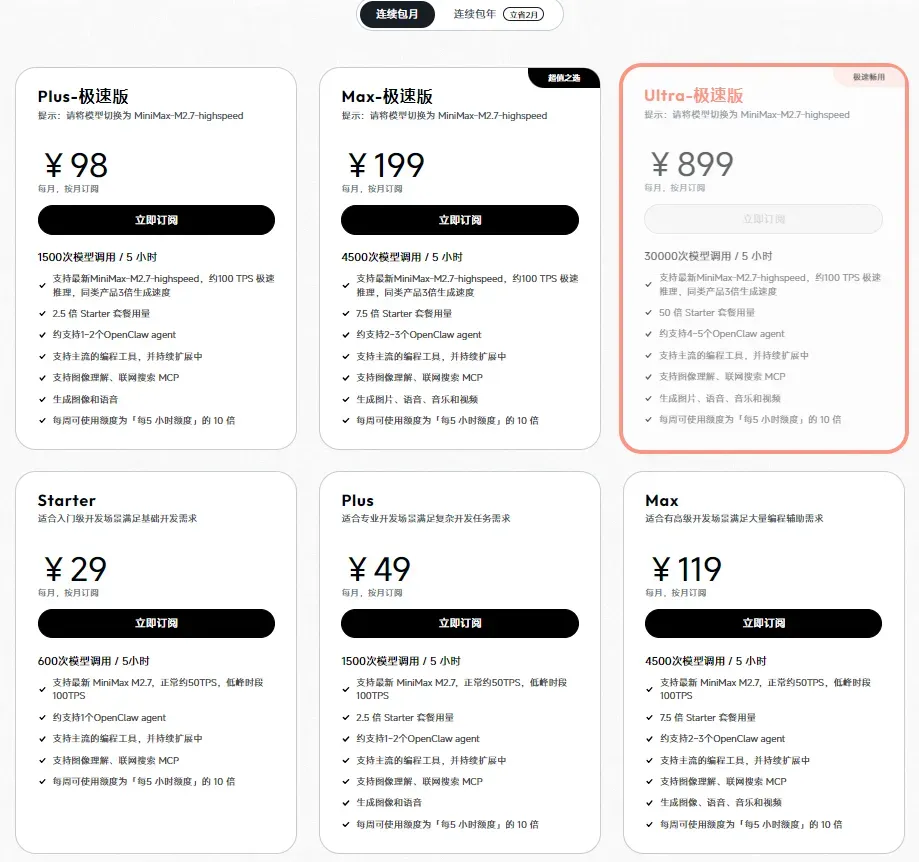
可用模型阵容
仅限自研模型:MiniMax-M2.7、MiniMax-M2.5等。
标准版概览
Starter / Plus / Max各档位对应不同的请求次数上限,支持语音、图片、视频、音乐生成等多模态能力,音乐生成每日上限为100首(限时免费)。
极速版概览
更高的请求频率(最高可达30,000次/5小时),更大的语音与图片生成配额,视频生成能力也有所增强。
07
整体趋势观察
从当前趋势来看,CodingPlan主导的按次包月模式正逐步向TokenPlan的按量计费模式迁移。对于轻度、非持续性使用的用户,TokenPlan的灵活性更具吸引力;而在高输入量、高频调用的场景下,传统的按次套餐在成本锁定方面仍可能保留一定优势。
🎯 最终的选择,还是要回归到实际使用场景与调用规模的具体需求。
#CodingPlan #TokenPlan #资费盘点 #阿里云 #腾讯云 #AI编程