AI视觉陷阱:DeepSeek、豆包、GPT-5.5等7大模型在坦克大战测试中全部翻车
在先前的对比中,我们曾指出豆包在识图能力上略胜 DeepSeek,这引起了一些争论。其实不同模型各有短长,非常正常。豆包的识图确实比 DeepSeek 强一些,但也并没有强到离谱。而这一次的视觉推理题,就让豆包、DeepSeek,以及 Qwen、Kimi,甚至 GPT‑5.5 和 Claude 全部栽了跟头。AI 十分强大,但人类总能从意想不到的角度出题击败它们。
题目是一道基于图片的视觉理解题,图片如下:

我向这些模型展示了这张图片,并提问:
如果两炮能打掉红色框中的砖块,那么黄色坦克朝右开两枪会怎么样?基地会怎么样?
不熟悉《坦克大战》的读者可能得先回顾一下这款 80 后家喻户晓的经典游戏。这道题的刁钻之处在于,我用一个“如果”修改了基础规则。模型必须先理解游戏本身的机制,又不能死记硬背,需要根据给定的新条件,结合图片进行动态推理,才能给出正确答案。
下面就来逐一看看各大模型的表现。
- DeepSeek
DeepSeek 最近上线了图片识别能力,因此让它第一个登场:
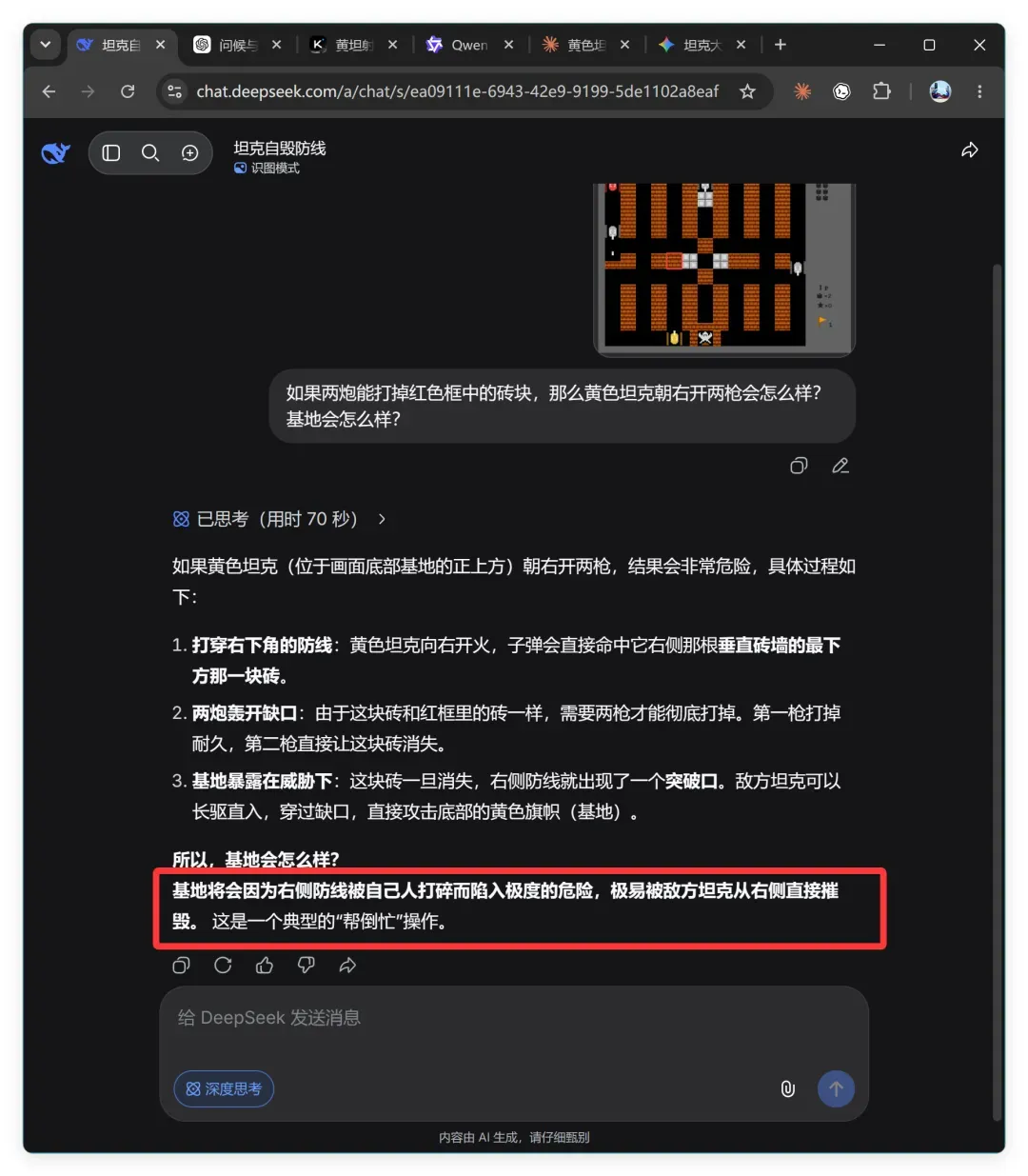
DeepSeek 的结论是:
基地将会因为右侧防线被自己人打碎而陷入极度的危险,极易被敌方坦克从右侧直接摧毁。 这是一个典型的“帮倒忙”操作。
它在解释中认为,右侧那块砖和红框里的砖属于同类,需要两枪才能彻底打掉。这一步就已经严重偏离事实:两块砖的形状明显不同,右侧那块只有红框内砖的一半,肉眼可见的厚度差异。但如果不看图片,仅凭记忆中的规则,那个位置的墙确实要两枪才能打穿,DeepSeek 只是在背书。
- 豆包
上一次豆包略占上风,于是第二个上场:
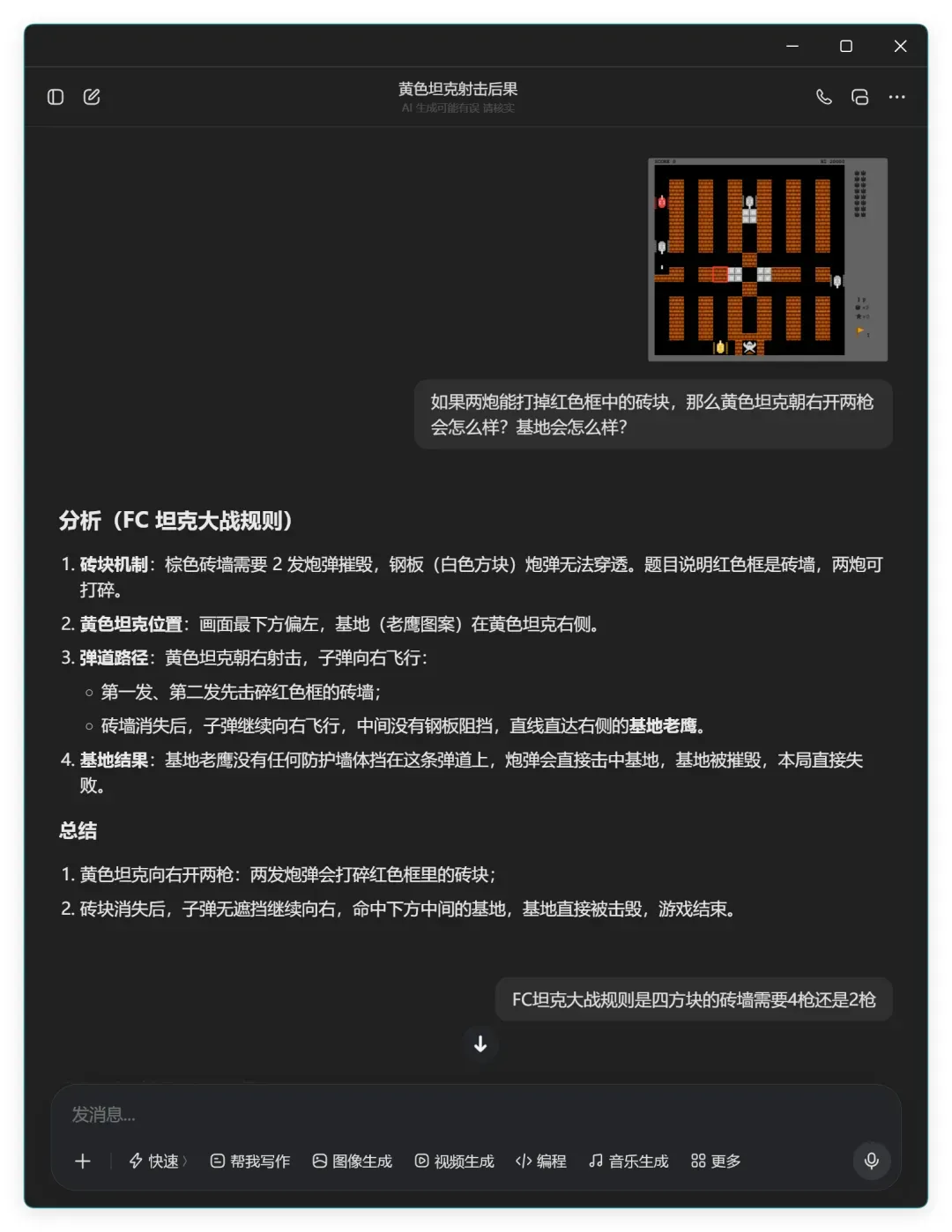
豆包直接给出“基地被摧毁,本局直接失败”的结论,看似一击即中。然而细看它的解释,它将第一枪和第二枪的效果混在一起描述,逻辑含混,很难说它是真正理解了问题,更像是瞎蒙碰对了结果。于是我又追问了一次:
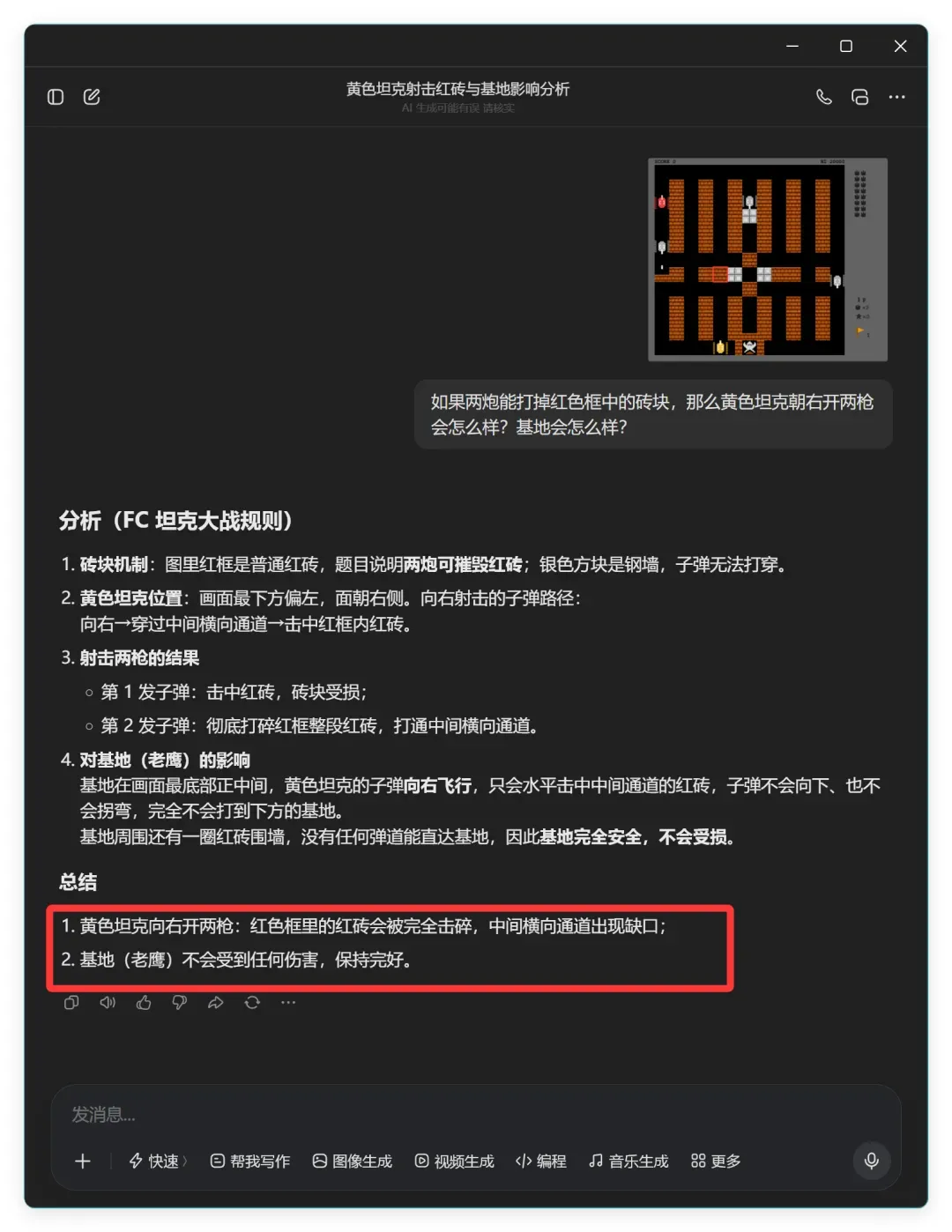
这次它的结论变成:
- 黄色坦克向右开两枪:红色框里的红砖会被完全击碎,中间横向通道出现缺口;
- 基地(老鹰)不会受到任何伤害,保持完好。
前后矛盾再次暴露了它对问题的理解并不牢固,这倒是很符合它在该题上的真实水平。
- Kimi
Kimi 一直以原生多模态和对图片、视频的强大理解力著称,这次也不能缺席。它的回答如下:
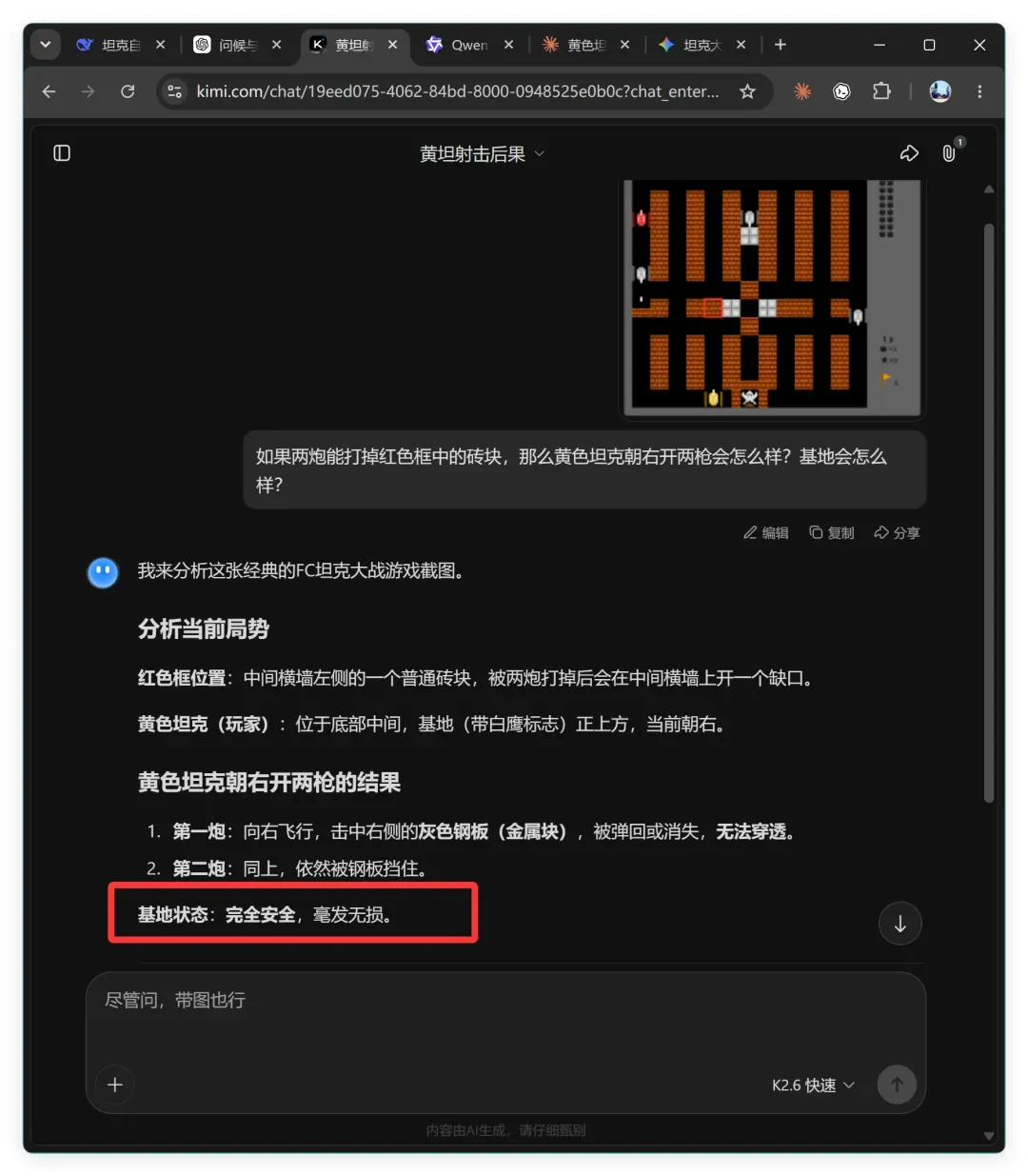
Kimi K2.6 的判断是:
黄色坦克朝右开两枪的结果
- 第一炮:向右飞行,击中右侧的灰色钢板(金属块),被弹回或消失,无法穿透。
- 第二炮:同上,依然被钢板挡住。
基地状态:完全安全,毫发无损。
推理过程中,“灰色钢板”这种物体在图中根本不存在,Kimi 的幻觉在此刻暴露无遗。
- 千问
阿里的最新模型 Qwen3.7 Max 号称当前国内最强,自然也要一试:
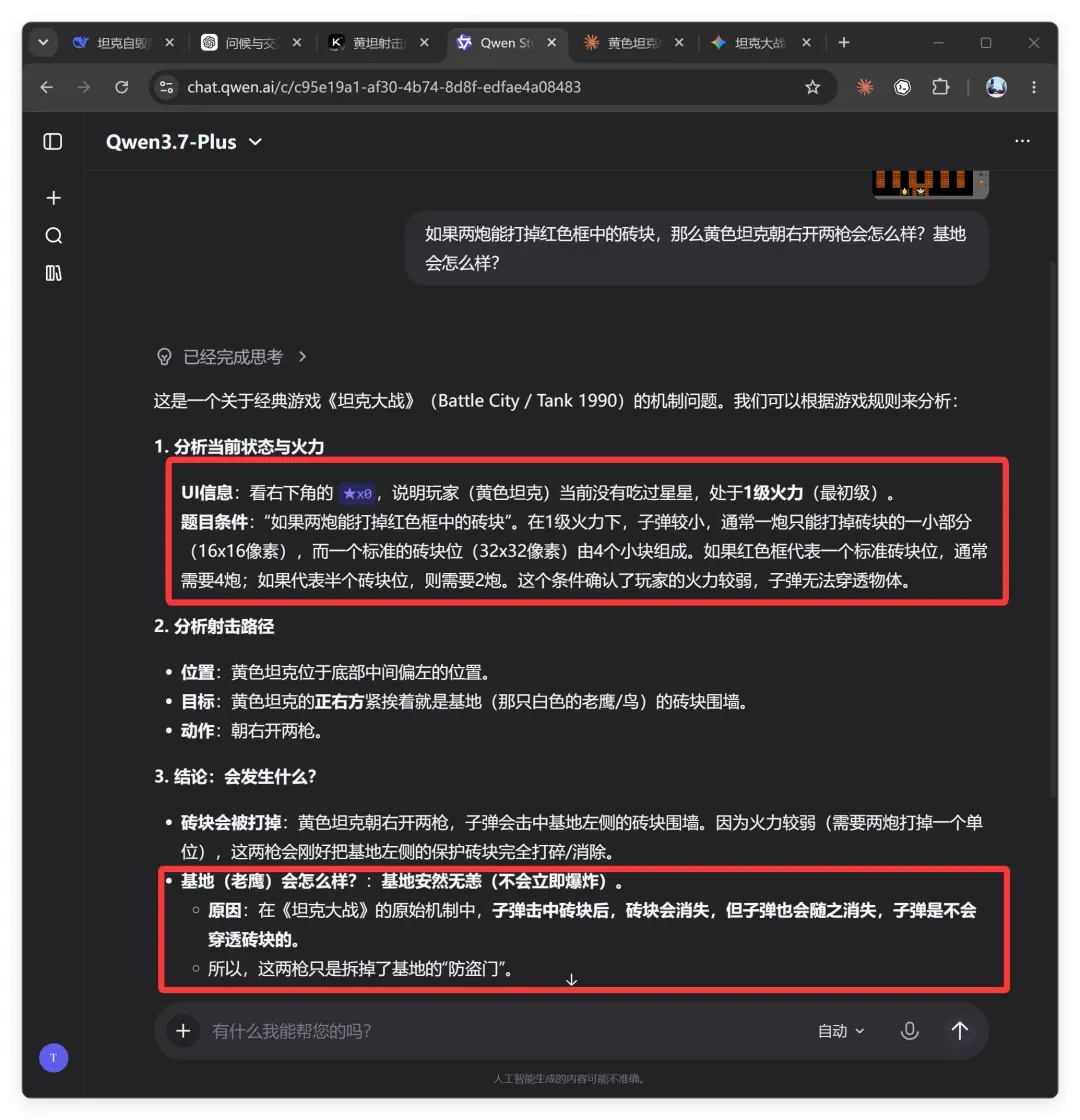
千问的结论是:
黄色坦克朝右开两枪后,基地左侧的砖块墙会被打掉,基地暴露出来(处于“裸奔”状态),但基地本身不会受损。
显然,这个结论同样错误。不过它的分析过程倒有亮点。它竟注意到了右下角的 ★x0 这一 UI 信息,推断出玩家当前尚未吃星星,处于 1 级火力。笔者本人多年游戏也未必留意到这一点。可惜,虽然观察细致、规则了然,它却忽略了最关键的动态推理——我的“如果”设定其实等同于将坦克设为 1 星战力,这和画面显示存在冲突,但“如果”的优先级最高。假如千问能把这个逻辑分支解释清楚,那才是真正的厉害。
- GPT
OpenAI 的 GPT 几乎引领了整个 AI 时代,这次用它们家最强的 GPT‑5.5 来测:
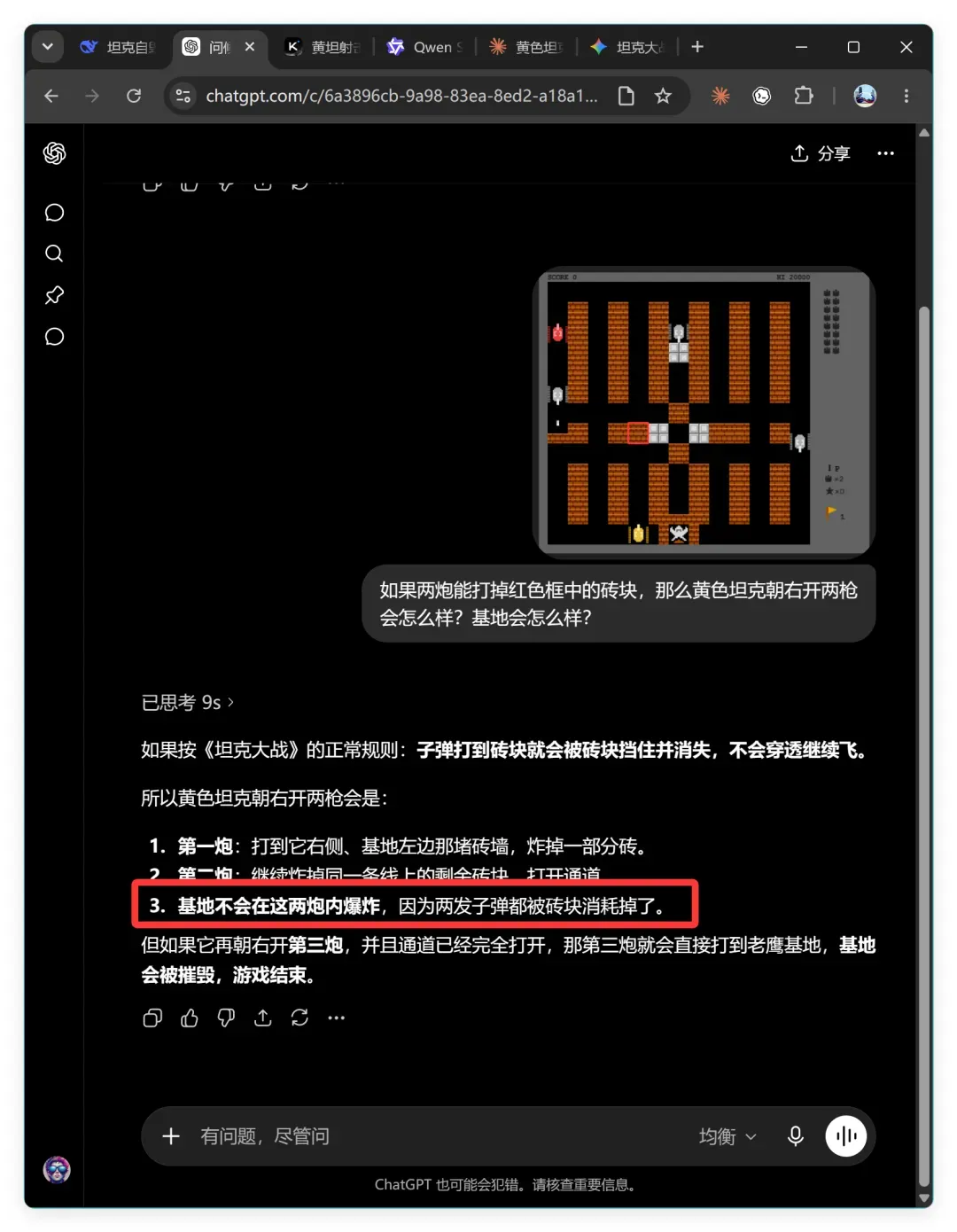
GPT‑5.5 的回答是:
第一炮:打到它右侧、基地左边那堵砖墙,炸掉一部分砖。
第二炮:继续炸掉同一条线上的剩余砖块,打开通道。
基地不会在这两炮内爆炸,因为两发子弹都被砖块消耗掉了。
平时能言善道的 GPT,在这道题上同样是信口开河。它本质上也是在套用“两炮才能打掉基地围墙”的固有规则,而没有依据图片中的实际物件大小进行推理。
- Gemini
谷歌的 Gemini 3.5 Flash 最新版投入测试:
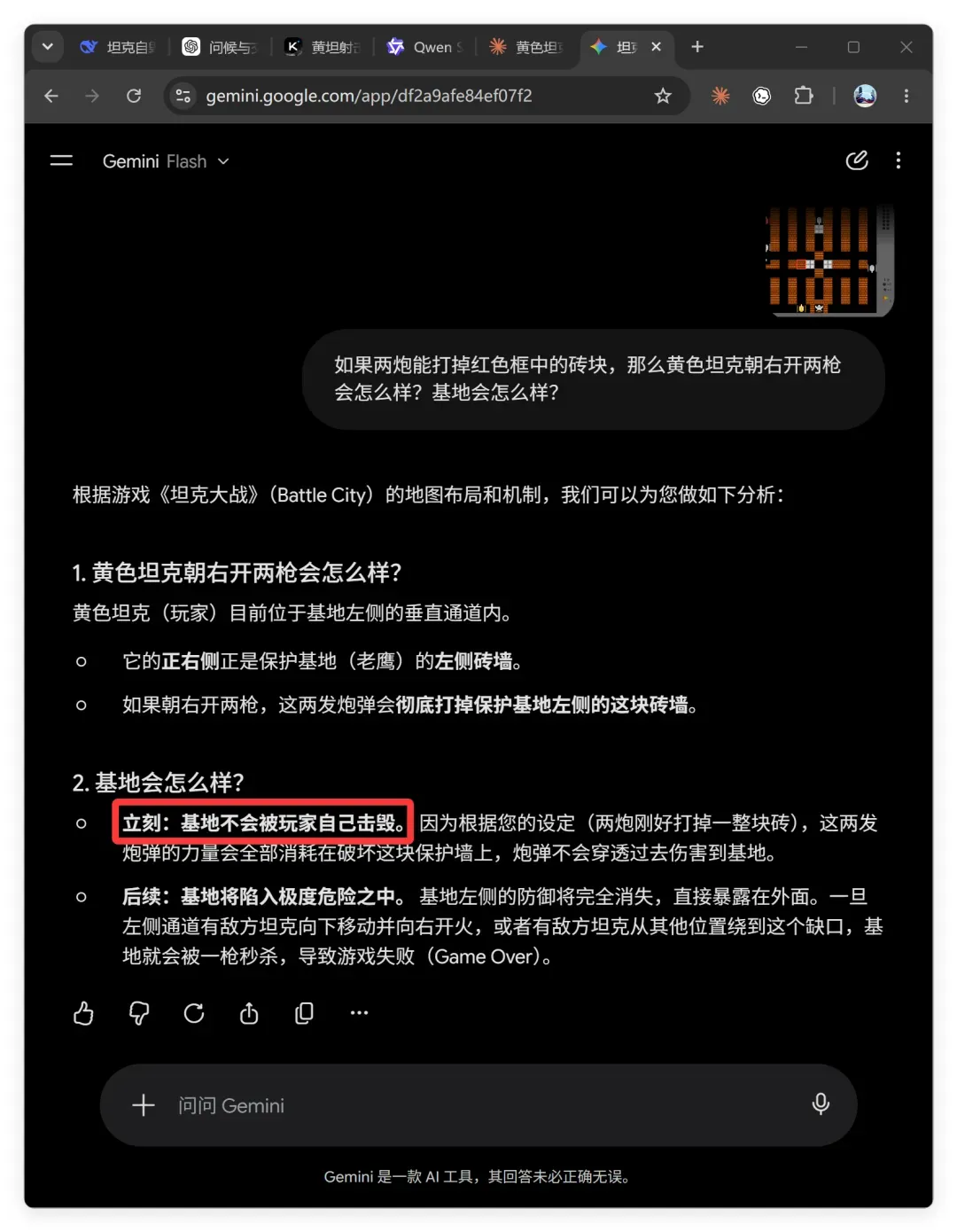
它的结论为:
立刻:基地不会被玩家自己击毁。因为根据两炮刚好打掉一整块砖的设定,这两发炮弹的力量会全部消耗在破坏保护墙上,不会穿透伤害基地。
后续:基地将陷入极度危险之中。基地左侧的防御完全消失,直接暴露。一旦左侧通道有敌方坦克向下移动并开火,基地就会被一枪秒杀,导致游戏失败。
作为搜索巨头,Gemini 明显参考了大量现成资料,输出的结果依然基于老规则,未能摆脱固有认知的束缚。
- Claude
Anthropic 的 Claude 在编程领域几乎封神,综合能力同样顶尖,也是我个人最喜欢的模型。让它压轴:
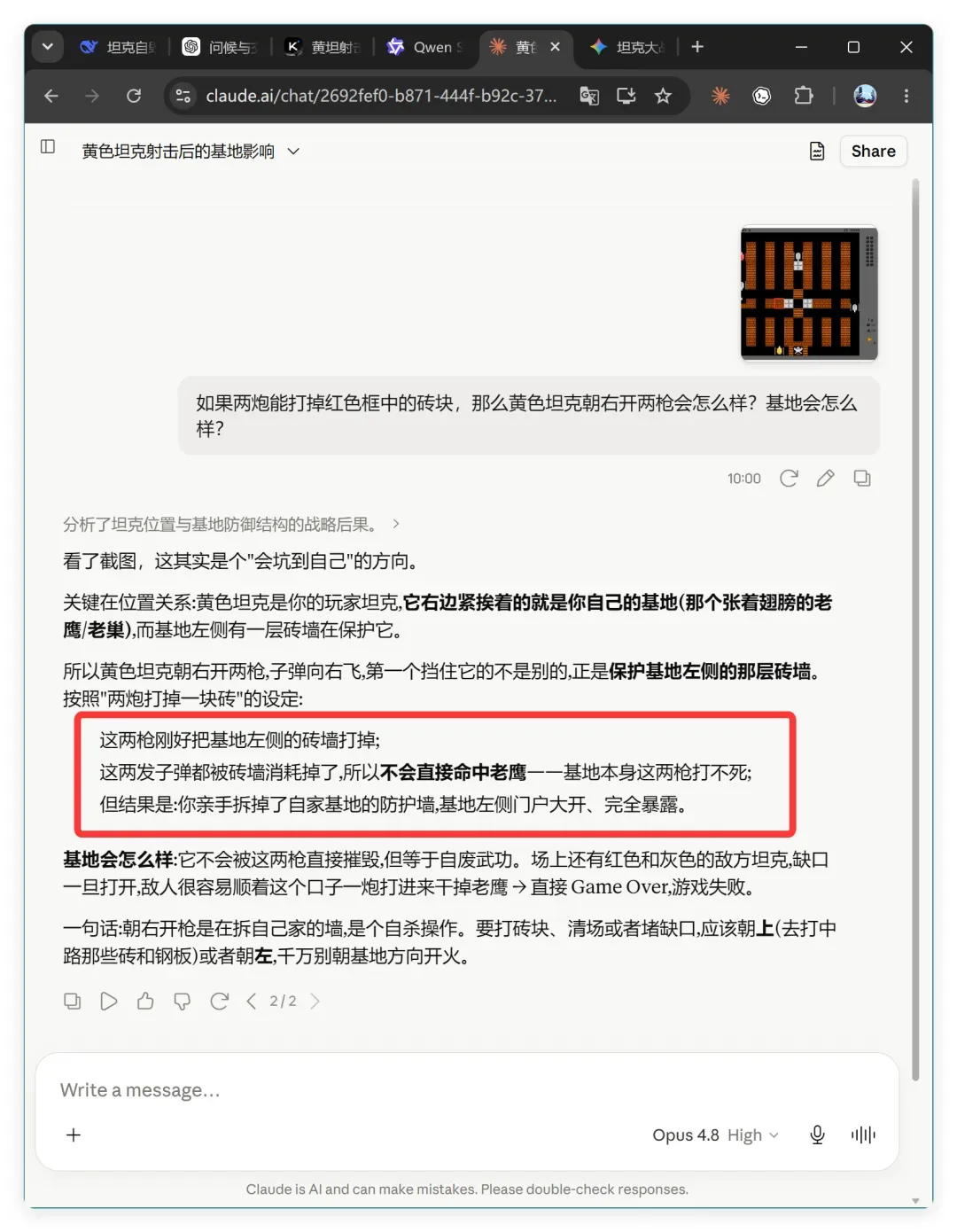
它的回答是:
这两枪刚好把基地左侧的砖墙打掉;
这两发子弹都被砖墙消耗掉了,所以不会直接命中老鹰——基地本身这两枪打不死;
但结果是:你亲手拆掉了自家基地的防护墙,基地左侧门户大开、完全暴露。
很遗憾,Claude 同样遵循了“两炮打掉一块砖”的规则来推理,而未能抓住题目中墙厚仅为半块的关键。
国内四家、国外三家,当前较具代表性的模型都已测完,结果却全军覆没,没有一个给出完全正确的回答。如果我再多强调一句墙的厚度,恐怕不少模型就能顺势修正答案。但这恰恰反映出它们缺乏主动的、灵活的推理能力。
这道题其实并不简单。首先,地图是由 AI 生成的,与原始版本不同;其次,我通过“如果”加入了改写后的规则,和原版存在冲突;最后,模型不仅要理解新规则,还要准确把握图中物体的位置关系与厚薄对比。在正常的坦克大战中,0 星战力需要四枪打掉一个方砖,而基地那面墙只有半砖厚度,本质上需要两枪才能打穿。我设定的规则是两枪打破 1 整块砖,也就是说一枪就能打破半块砖。从各模型的回答来看,它们几乎都以固有知识为主,即便有一部分模型注意到了墙的厚度差异,最终结论依然是需要两枪打掉保护墙,第三枪才能击中“老鹰”。这暴露出在“如果”条件叠加时,现有 AI 极易陷入思维定式。
此前我曾让全球顶尖模型 Fable 帮忙复刻过坦克大战,整体完成度很高,但深入排查规则细节后,仍能发现不少问题。各家宣传虽然夺目,实际使用中的瑕疵却难以避免。这也正是我坚持做这类非基准、非官方样例测试的意义——不设限,不跟风,只针对那些模型想象不到的刁钻角度。
未来我还会继续测试各家 AI 1:1 复刻《坦克大战》的完整能力,从模型到智能体的综合表现都会纳入观察。