多模态嵌入完全指南:对比学习、共享空间与跨模态搜索实战

不妨回忆一下,当你试图用语言向别人描述一段音乐时,对方往往只能无奈地说:“有点像 Billie Eilish,但更轻柔,还有一段钢琴……算了,你还是直接听吧。”在这个瞬间,语言放弃了解释,转而邀请对方直接体验。这并非语言的无能,而是提醒我们:语言本质上是对经验的有损压缩。就像任何压缩形式一样,它总会舍弃一些东西——音色、质感、空间布局,或某种难以言表的整体氛围。
在人工智能近几十年的发展历程中,我们一直把这种“压缩”视为理所当然。搜索与检索系统普遍遵循一个隐含的前提:如果一件事没有被文字记录下来,它就不存在。
你有一档播客?先转录成文字。
你有一份扫描版 PDF 报告?用 OCR 提取文本。
你有一张战略会议上白板的照片?那就麻烦了。
每一次转换,都伴随着“损耗成本”——一点失真,一点信息的流失,让原始内容变得不那么完整。
可如果不再强迫一切数据都必须转化为文字,而是直接在原始形态下处理,却仍然能够搜索、比对和推理呢?
这正是多模态嵌入所赋予的能力。它将文本、图像、音频和视频映射到同一个嵌入空间,使得源于任意一种模态的查询,都能从其他所有模态中检索出相关结果。本文将深入探讨其工作原理,解释为何最新一代模型让其变得真正实用,并通过三个当下就可以构建的真实系统案例,展示如何把多模态嵌入与大语言模型结合起来,打造可落地的应用。
嵌入:理解向量空间的语义本质
在深入多模态之前,有必要先明确“嵌入”到底是什么。
嵌入是一种对输入数据(文本、图像、音频或任何信息)的学习型表示,被编码成高维数学空间中的一个点。例如,像 text-embedding-3-large 或 nomic-embed-text 这样的模型,接收一个句子作为输入,会返回一个通常包含数千个维度的向量。
嵌入最关键的特性在于:语义相近的输入,在嵌入空间中彼此靠近。比如,“dog”和“puppy”的向量距离很近,而“jira 工单”与“派对策划”的向量则相距甚远。
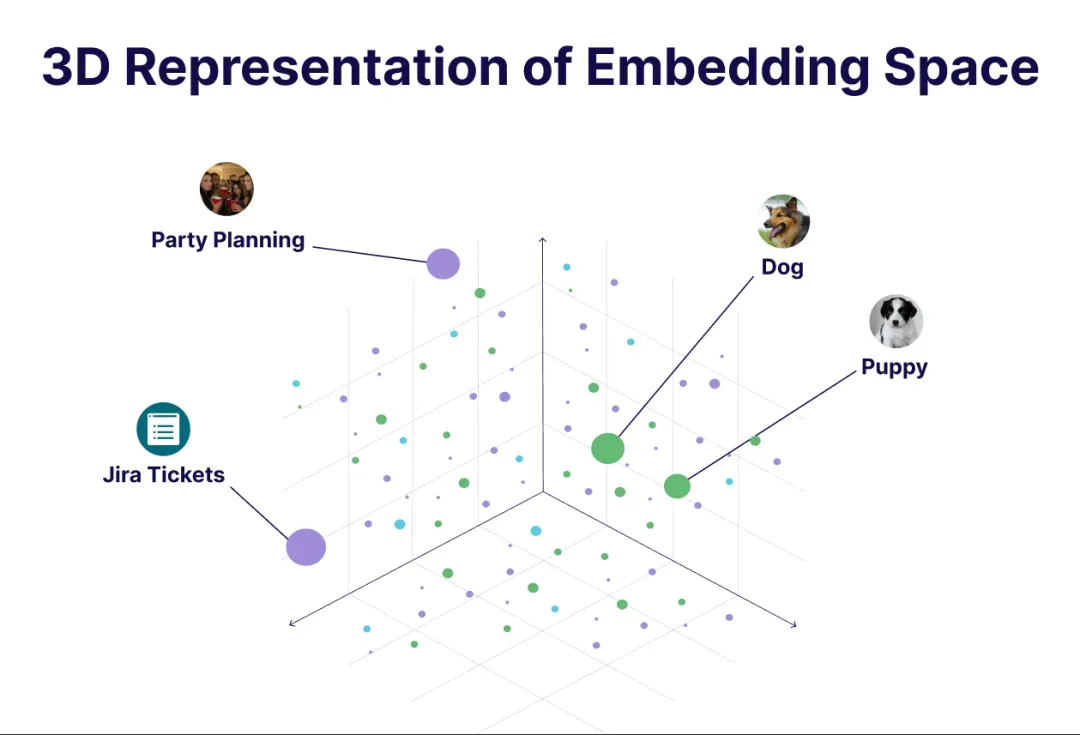
这正是现代检索系统的基石。不同于传统的关键词匹配,现在我们比较的是向量:将整个文档库编码为向量,再将查询语句编码为向量,然后检索出嵌入空间中最邻近的向量。最终实现的是语义搜索——它理解的是内容的含义,而非仅仅匹配字面词汇。
文本嵌入在这一任务上已表现出色多年。但顾名思义,它的局限也很明显:它只理解文本。如果你的数据是其他形式(如音频、图像或视频),就必须先转换为文字,否则就完全无法利用。而正如前文所述,这种转换有代价——信息会丢失。
共享嵌入空间:跨越模态的统一表示
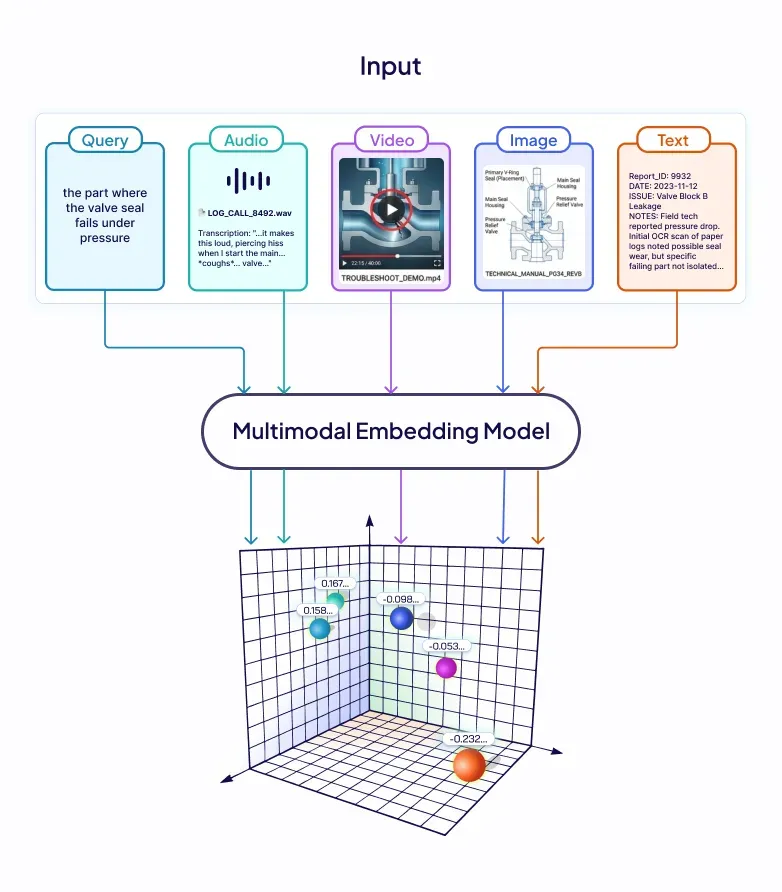
想象一位技术支持工程师正在搜索公司的知识库,而这个知识库不仅包含文本文档,还有客户通话录音、扫描版技术手册和产品演示视频。他输入查询:“阀门密封件在压力下失效的那个部分”。答案其实就在一段 40 分钟的故障排查视频中,大约第 22 分钟处,屏幕上清晰展示了失效过程。
在纯文本嵌入的检索流程中,这种情况几乎无解:
- 即便将视频中的语音转录为文字,也只能捕捉到“说了什么”,却无法反映“画面中展示了什么”;
- 对技术手册做 OCR,图示信息会丢失;
- 视频字幕(如果有的话)通常只记录对话,不会描述操作人员的手部动作或设备状态。
信息明明就在知识库里,却因为格式问题变得“不可达”。
从概念上讲,解决办法其实很简单:把所有模态的数据都编码到同一个共享的嵌入空间中。这样一来,不论查询是文本、图像还是音频,都能跨模态匹配到最相关的内容。
真正的挑战在于:如何训练出一个模型,能稳定、一致地在不同模态之间实现这种对齐。这需要海量的多模态数据、精心设计的训练目标以及强大的模型架构——而近年来的技术进步,正让这一目标变得愈发可行。
模型如何学会对齐不同模态:对比学习的魔力
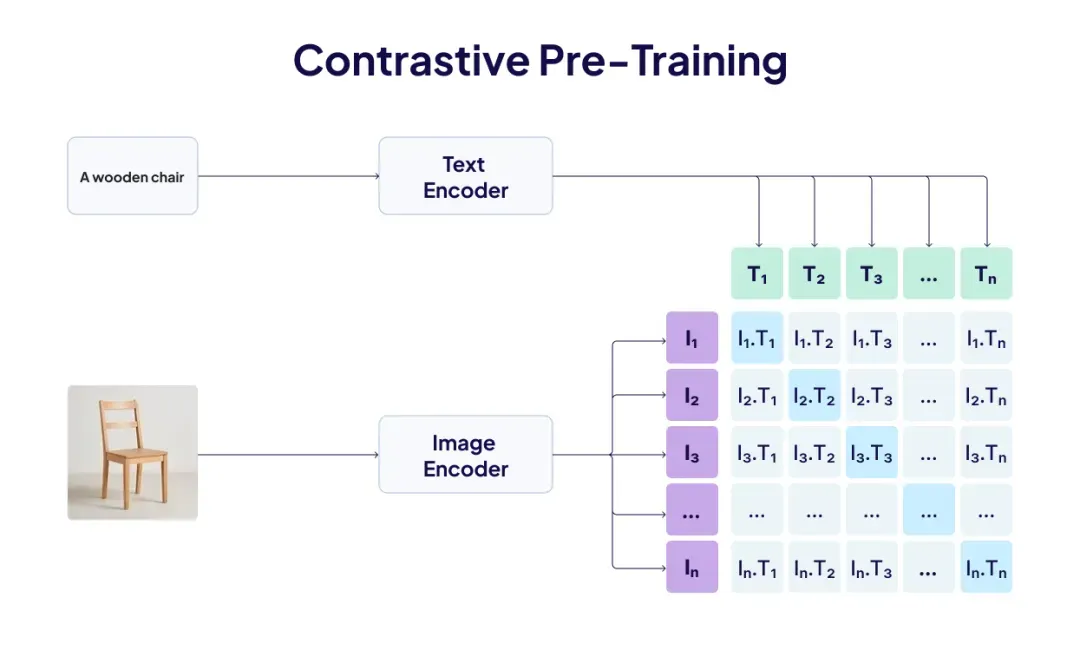
实现多模态对齐的核心技术是对比学习。其思路很直接:收集成对的多模态数据——比如一张照片及其对应的标题、一段音频与它的文字描述——然后同时训练两个编码器,一个处理图像,一个处理文本。
训练信号非常直观:
- 配对的数据(如图片与它的真实标题)在嵌入空间中应彼此靠近;
- 未配对的数据(如图片与随机标题)则应彼此远离。
在每个训练批次中,模型会将每张图像与该批次中所有文本进行匹配打分,目标是让正确的图文配对获得最高相似度,而其他错误的配对则被惩罚。通过在数亿甚至数十亿这样的配对数据上反复训练,两个编码器最终会收敛到一个语义主导、格式无关的共享几何空间——在这个空间里,“狗”的图像向量和“狗”这个词的文本向量靠得很近,而与“汽车”或“交响乐”则相距甚远。
CLIP(对比语言-图像预训练,OpenAI,2021)是首个在大规模上成功验证这一方法的模型。它在4 亿个图像-文本对上进行训练,能够在零样本设置下准确匹配图像与文本,性能甚至可以媲美在特定任务上专门训练的有监督模型。
CLIP 的突破不仅在于规模,更在于它证明了:无需人工标注类别标签,仅通过自然语言描述与图像的弱对齐,就能学习到强大的跨模态语义表示。这为后续涵盖音频、视频等更多模态的嵌入系统奠定了根基。
继 CLIP 之后,ImageBind(Meta,2023)将对比学习扩展到六种模态:图像/视频、文本、音频、深度图、热成像和惯性测量单元(IMU)数据。更巧妙的是,它不需要所有模态之间都存在直接的配对数据——所有模态都通过图像作为“锚点”进行对齐,音频与文本等其他模态之间的关系会通过图像间接传递,形成一种“传递性对齐”。
然而,这种“桥接式”对齐隐藏着一个根本性问题。NeurIPS 2022 的论文《Mind the Gap》指出:每个模态的编码器在高维空间中会天然形成狭窄的锥形簇,而不同模态的锥形簇并不完全重叠。对比学习只关注配对样本之间的相对距离,并不会强制缩小模态锥之间的绝对间隙,因此模型没有动力去弥合这一鸿沟。这种分离会不可预测地影响检索精度,并在下游任务中引入偏差。
这一发现为下一代模型指明了方向:从零开始联合训练所有模态,采用单一统一架构。如今的原生多模态嵌入模型正是这么做的——它们不再依赖文本作为中介,而是让所有模态在同一个表示空间中协同学习。正是这种转变,使得下文将要讨论的应用从“理论可能”变成了“工程可行”。
设计多模态检索系统的关键决策
在具体实现之前,以下几项架构选择对实际效果的影响,往往比模型本身的选型更大。
原生嵌入 vs. 桥接式嵌入
- 桥接式(常见做法):将所有数据先转为文本(如语音转录、OCR、视频字幕),再用成熟的文本嵌入模型处理。
- 优点:简单,与现有系统兼容。
- 缺点:承受全部“转换成本”——丢失音调、布局、视觉动作等关键信息。
- 原生嵌入(如 Gemini Embedding 2):使用从头联合训练的多模态模型,直接以原始格式嵌入各模态。
- 优点:保留音频中的语气、PDF 中的排版、视频中的操作动作。
- 缺点:相对较新,工程生态仍在成熟过程中。
建议:若任务高度依赖于非文本语义(如故障诊断、艺术分析),优先考虑原生多模态嵌入。
非文本数据的分块策略
- 文本有天然的分块单位(句子、段落),但音视频没有。
- 标准做法:使用带重叠的固定时间窗口(例如每 15 秒一段,重叠 3 秒),避免关键内容被切碎。
- 窗口太短 → 缺乏上下文。
- 窗口太长 → 检索结果过大,难以送入生成模型。
- 文档处理技巧:将 PDF 页面先渲染为图像,再以“整页”为单位嵌入,可以完整保留图文布局。
维度与存储成本
- 多模态向量规模庞大:例如 100 万个 15 秒视频片段 × 3,072 维,可能产生数十 GB 的向量索引。
- Matryoshka 表示学习(MRL) 提供了解决方案:模型输出的高维向量具有“嵌套结构”——前 768 维本身就是一个有效嵌入,无需重新训练即可降维使用。
实践建议:从低维(如 768)起步,在真实数据上评估召回率,仅在必要时提升维度。
检索-生成流程中的原生媒体传递
- 标准 RAG 流程依旧适用:嵌入语料库 → 嵌入查询 → 检索最近邻 → 送入大语言模型生成答案。
- 关键增强:如果你的生成模型(如多模态大语言模型)能够直接理解图像、音频或视频,请传递原始媒体,而非文本摘要。
- 这样,生成阶段也能受益于未压缩的原始信息,正如嵌入阶段一样。
这些设计决策共同决定了多模态检索系统的信息保真度与实用性。随着原生多模态模型的持续成熟,我们正从“文本中心主义”的 AI 范式,大踏步迈向一个能够真正理解世界多维表达的新阶段。