微信商城全栈开发挑战:六款国产AI编程模型深度对比评测(2026版)
国产大模型纷纷亮出最新版本,MiniMax、通义千问、DeepSeek、Kimi、智谱、小米等模型在AI编程赛道上的竞争愈发激烈。这些模型投入到真实开发任务中,究竟哪一家的编码能力最值得信赖?近期,我对六款主流国产AI编程模型进行了一次贴近个人日常需求的实测,从长任务执行到复杂前后端联调,全面考察它们的实战水平,并整理出综合排名与评分。参与本次横评的模型分别是:MiniMax M3、Qwen 3.7 Max、DeepSeek V4 Pro、Kimi K2.6、GLM 5.1、小米 V2.5 Pro。
一、测试全景:微信商城全栈开发
此次测试以一个完整的微信商城全栈项目为场景,涵盖前端、后台和 Java 后端。我为每个模型提供了完全相同的 PRD 文档、设计规范、技术栈说明、SPEC 任务文档和全局开发规范,要求其完成一轮长时间编码,并经过 3 至 5 轮问题修复,重点观察它们在长任务上下文维持、前后端协作、功能完备度以及缺陷修复上的真实表现。
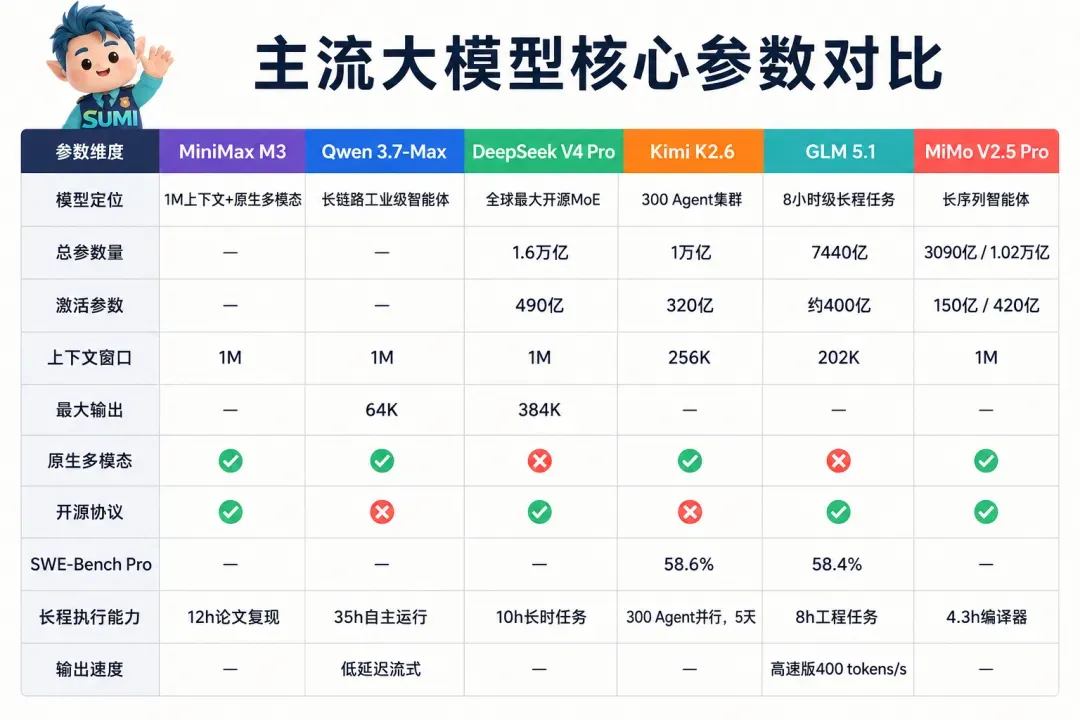
二、六款模型核心参数一览
先来看下各模型最新的核心技术规格。
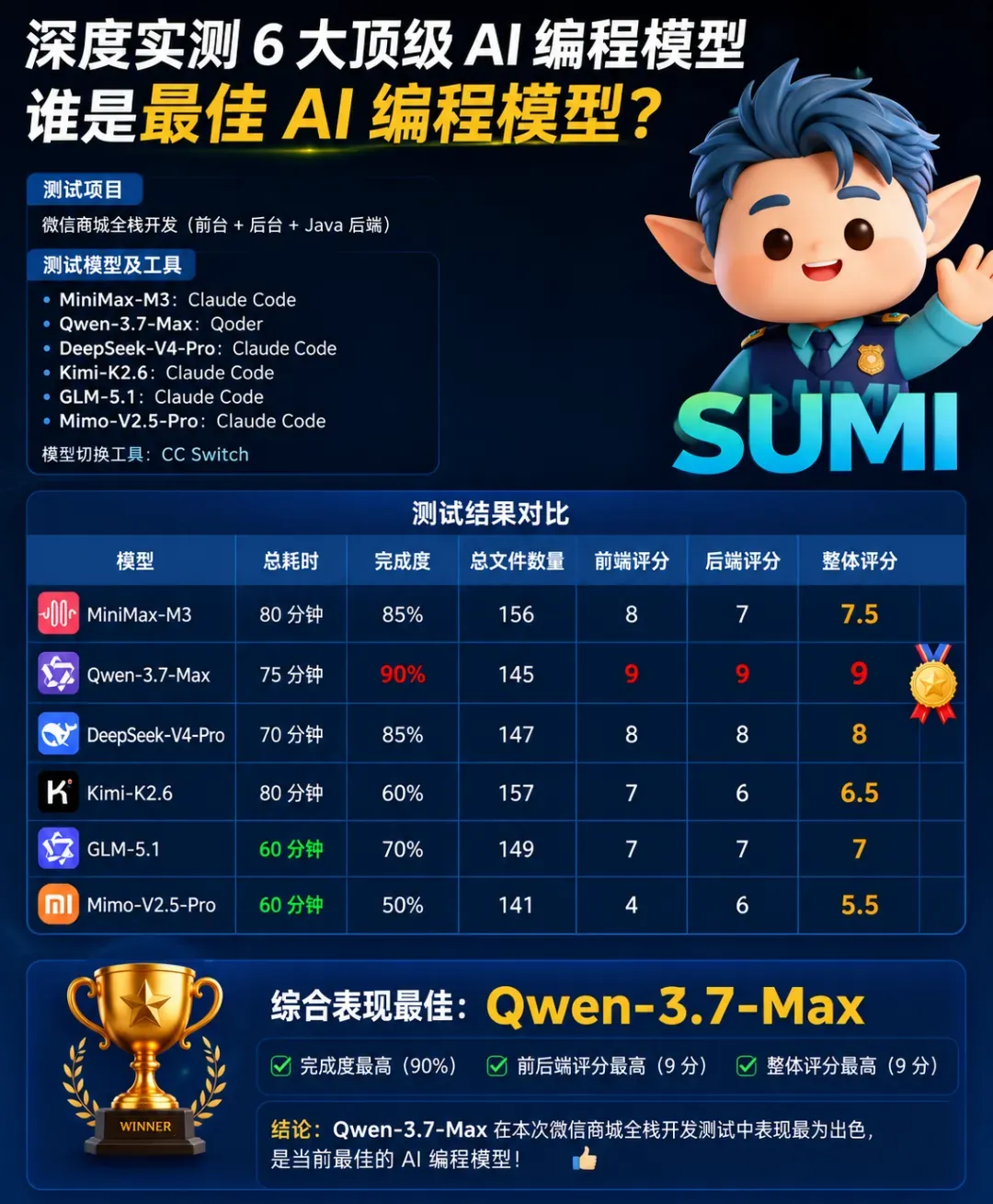
三、实测综合评分榜
复杂的测试过程不再赘述,直接揭晓各模型的综合评分。
四、各模型详细表现与亮点
🥇 Qwen-3.7-Max(整体评分 9)
技术亮点
原生支持百万级 Token 上下文窗口,可以一次性加载完整代码仓库,最大输出可达 64k tokens。在推理内核优化类任务中,曾持续运行35 小时、执行超过 1000 次工具调用,展现出行业领先的长周期自主执行能力。
测试表现
以 90% 的项目完成度稳居榜首,并且是本轮测试中唯一在首版编码就正确实现优惠券完整逻辑的模型。前端、后端均获得 9 分的满分评价,成为唯一前后端能力双双登顶的选手。
🥈 DeepSeek-V4-Pro(整体评分 8)
技术亮点
目前全球规模最大的开源 MoE 模型,总参数量达到惊人的1.6 万亿,激活参数 490 亿,配备 384 个专家。上下文窗口同样为 1M tokens,最大输出 384K tokens。处理 1M token 上下文所需的 FLOPs 仅为 V3.2 版本的 27%,KV Cache 占用仅有 10%。
测试表现
项目完成度为 85%,整体评分 8 分,能力表现十分均衡,运行效率尤为突出。
🥉 MiniMax-M3(整体评分 7.5)
技术亮点
国内首个同时集前沿编程能力、1M 超长上下文、原生多模态三大核心能力于一身的大模型。采用自研的 MSA 稀疏注意力架构,处理 1M 上下文时的单 Token 计算量仅为上一代的约 1/20。曾独立运行近 12 小时,成功复现 ICLR 2025 获奖论文的核心实验。
测试表现
项目完成度同样为 85%,生成文件数量最多(156 个),代码覆盖范围很广,但在后端细节处理上偶尔会出现遗漏。
GLM-5.1(整体评分 7)
技术亮点
目前唯一在 SWE-Bench Pro 中登顶的开源模型(得分 58.4%),超越了 GPT-5.4 与 Claude Opus 4.6。支持单任务自主运行 8 小时以上,能够独立规划执行步骤,并在遇到阻塞时自行调整策略。
测试表现
耗时最短,仅 60 分钟便完成一轮编码,但完成度为 70%。效率极高,然而在复杂前后端联调场景下,部分细节的处理稍显粗糙。
Kimi-K2.6(整体评分 6.5)
技术亮点
总参数量 1 万亿,激活参数 320 亿,配有 384 个专家。支持300 个子 Agent 并行,最多可完成 4000 个协作步骤。SWE-Bench Pro 得分为 58.6%,相较 K2.5 有了约 20% 的显著提升。
测试表现
生成了全场最多的 157 个文件,但实际完成度只有 60%。Agent 编排能力在前端 UI 重构上带来了惊喜,然而核心业务逻辑容易出现偏离预期的情况。
Mimo-V2.5-Pro(整体评分 5.5)
技术亮点
提供 309B 和 1.02T 双参数版本可选,支持1M 超长上下文。曾独立完成一个完整编译器项目,并在隐藏测试集上拿到满分。
测试表现
耗时与 GLM-5.1 同为最短的 60 分钟,但完成度仅有 50%。前端评分低至 4 分,在生成完整全栈项目时出现了明显的能力下滑。
五、购买推荐与总结
🥇 追求一步到位,厌恶反复调试
Qwen 3.7-Max 是最稳妥的选择。它拥有 35 小时自主运行与 1000+ 工具调用的长周期执行能力,是目前国产模型中综合实力最强的存在。
🥈 看重最强推理性能与开源自由,预算灵活
DeepSeek-V4-Pro 值得关注。作为全球最大开源 MoE,其 1M 上下文 + 384K 最大输出的规格领先同级,API 缓存命中价格永久锁定在 0.025 元/百万 tokens。
🥉 重度开源爱好者,想要全模态新体验
MiniMax-M3 颇具吸引力。1M 长上下文、原生多模态和长达 12 小时的自主执行三项能力合一,在综合能力上仍有独特竞争力。
一句话总结
Qwen 3.7-Max 以 90% 完成度、前端后端双满分的表现拿下本次测试头名,但 DeepSeek V4 Pro 的超大规模开源、MiniMax M3 的全模态融合、GLM 5.1 的 SWE-Bench 纪录等优势同样不可忽视,各个模型在特定的维度上仍有一争之力。
*本次测试仅为个人实测结果,并非权威评测。由于任务类型、工具配置、提示词和测试环境的差异,最终表现可能会有所不同,建议各位结合自身实际开发场景进行参考。