大模型API测试实战:max_tokens、流式输出与性能指标全解析
当团队拿到一个全新的大语言模型时,开发者的第一反应往往是:“这模型响应有点慢啊。”究竟慢不慢,测一下就知道了。
基础接口测试方法
查看可用模型列表
curl -s "https://localhost/v1/models" \
-H "Authorization: Bearer <API_KEY>" | python3 -m json.tool
基础对话连通性测试(max_tokens=10)
curl -s "https://localhost/v1/chat/completions" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-5.1",
"messages": [{"role": "user", "content": "Say hello"}],
"max_tokens": 10
}' | python3 -m json.tool
max_tokens 合法上限测试(32768)
curl -s "https://localhost/v1/chat/completions" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-5.1",
"messages": [{"role": "user", "content": "Say hello"}],
"max_tokens": 32768
}' | python3 -m json.tool
max_tokens 超限测试(262144,预期报错)
curl -s "https://localhost/v1/chat/completions" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-5.1",
"messages": [{"role": "user", "content": "Say hello"}],
"max_tokens": 262144
}' | python3 -m json.tool
返回结果示例:
{"error": {"code": "1210", "message": "max_tokens参数非法:限制数值范围[1,131072]"}}
长文本上下文窗口测试(检查长输入时的处理能力)
python3 -c "import json
long_text = 'Hello ' * 8000
payload = {
'model': 'GLM-5.1',
'messages': [{'role': 'user', 'content': long_text + 'Please reply with just OK'}],
'max_tokens': 10
}
print(json.dumps(payload))" | curl -s "https://localhost/v1/chat/completions" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d @- | python3 -m json.tool
流式输出测试
curl -s "https://localhost/v1/chat/completions" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-5.1",
"messages": [{"role": "user", "content": "Say hi"}],
"max_tokens": 100,
"stream": true
}'
封装为 Skill 后的模型性能报告
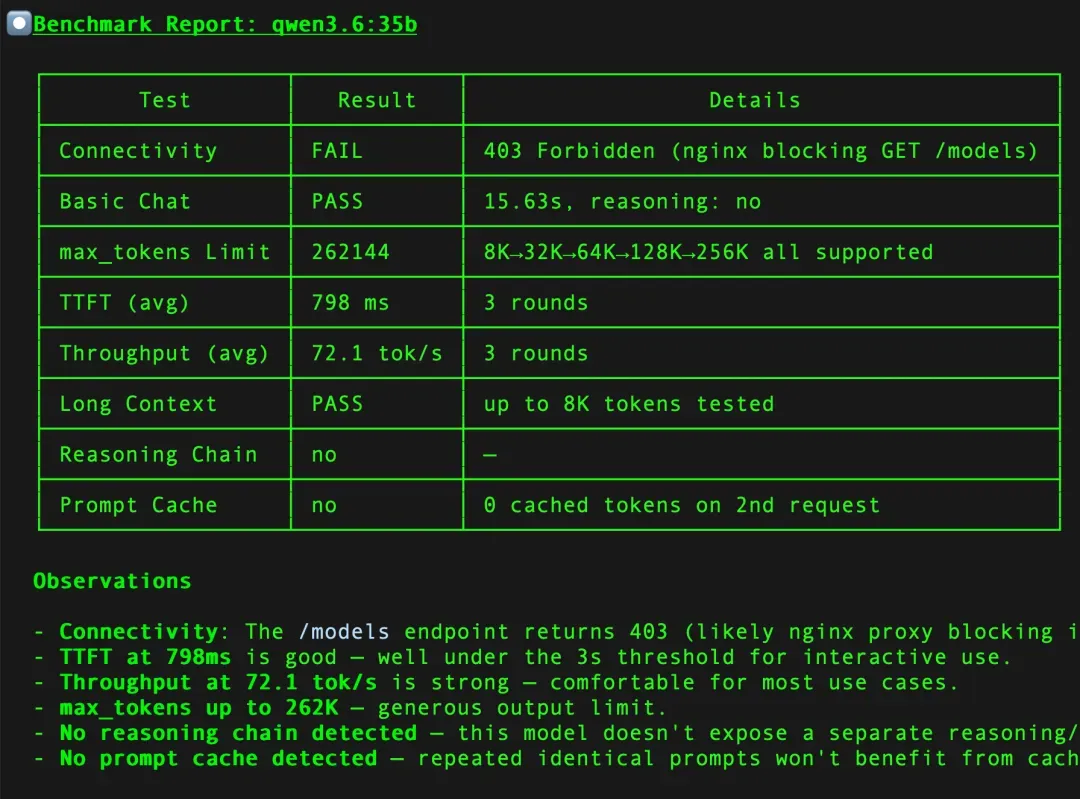
- qwen3.6:35b
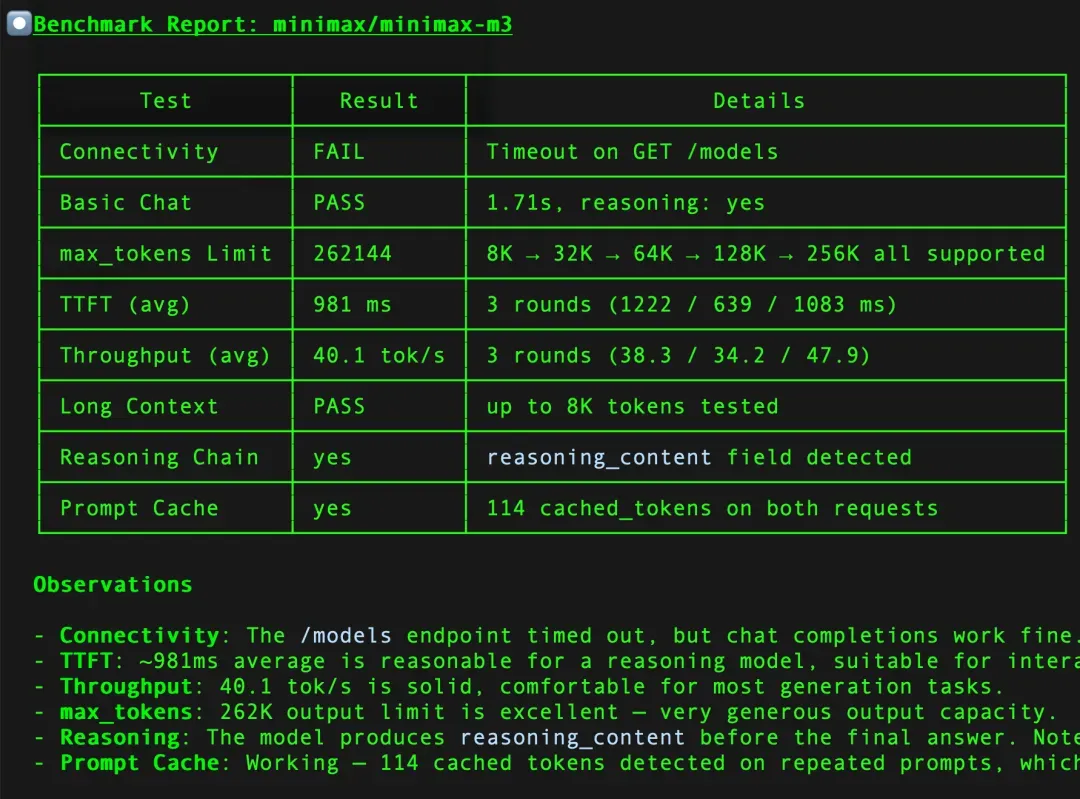
- minimax-m3
- glm-5.1

核心性能指标
- max_tokens:接口允许的最大输出 token 数量。
- TTFT(Time To First Token):首 token 延迟,即从发出请求到收到第一个 token 的时间,反映模型的响应速度。
- Throughput:生成吞吐量,指模型每秒可以输出的 token 数,衡量实际生成效率。
- Long Context:测试输入上下文长度,评估模型处理长文本的能力。