PewDiePie的奥德赛四天5万星:用本地AI工作台走出Agent第二条路线
最近,海外开发者圈子里疯传一个项目——上线仅四天就在GitHub上收割了5万颗星,涨势凶猛得让人想起年初那款席卷全网的现象级工具。
夸张,却真实。
这个项目叫 Odysseus,背后的作者既不是传统人工智能公司,也不是哪家大厂的实验室,而是那个粉丝量级破亿的网红 PewDiePie。
起初,我以为它不过又是一个本地版的ChatGPT。毕竟现在这类项目满地都是,把大模型接过来,套层聊天界面,就推给用户。
然而真正跑起来之后,我才发现它最有意思的地方根本不在对话本身。
它更像是一间运行在你电脑里的AI工作室,或者说,是一个高度个人化的AI操作系统的早期形态。
换个角度去看,甚至可以把这里理解为AI Agent进化的第二条路径。
它把「本地部署大模型」这件事的门槛,压低了整整一个数量级。
怎么理解这一点呢?
太多人并不是不想运行本地模型,而是在第一步就被劝退了。
打开 Hugging Face,迎面而来的是 7B、8B、14B、32B、70B 这样的模型代号;再往下翻,又冒出 GGUF、Q4、Q5、FP8、AWQ 等一系列术语。你还得搞清自己显卡的显存大小、内存够不够用、该选 Ollama 还是 llama.cpp、是否要上 vLLM,模型下载完后该怎么部署,部署好之后又如何接入聊天界面……
明明只是想在自己的电脑上跑一个AI模型,结果还没触碰到真正的功能,就先被一堆黑话暴击了一遍。
Odysseus 最关键的地方,就扎在了这里。
它内建了一个名为 Cookbook 的功能模块,会先对你的硬件环境做一次扫描,看清你的CPU、内存、显卡、显存大概处于什么层级,然后主动推荐适合这台机器安装的模型。
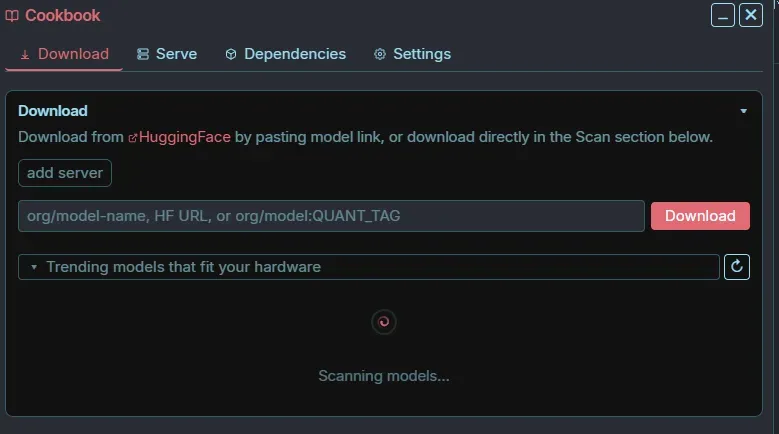
也就是说,它并不指望用户自己去揣测「我的电脑到底跑不跑得动8B」。它先替你过滤一遍:哪些模型比较契合你的配置,哪些模型可能太大拖不动,哪些版本更适合在本地部署。
接下来,你可以直接从Hugging Face 拉取模型,把它们下载到本地,再一键部署起来。
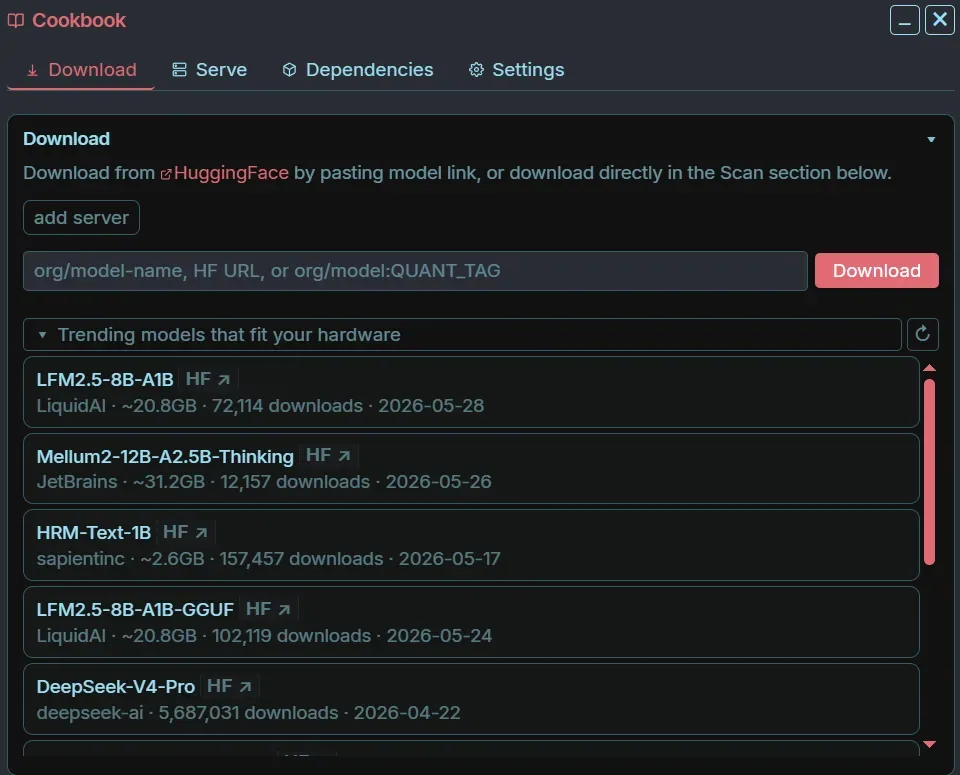
这个环节尤为关键。
因为在以前,本地模型最难的,从来不是「有没有模型」,而是「很多人根本弄不清自己到底能用哪个模型」。看到密密麻麻的参数就退缩的人比比皆是。但Odysseus想要实现的,正是把模型选择、下载、部署和调用这整条链路,都收纳进同一个工作台。
所以,这不单单是递给你一个聊天框,而是先为你推倒本地AI面前最高的那堵墙:你的电脑到底能跑什么。
当然,它也并不只服务于本地模型。
你同样可以接入 OpenAI、OpenRouter、Deepseek 这类云端 API。也就是说,轻量的、涉及隐私的任务,你可以尽量放在本地处理;遇到复杂的、需要更强模型的任务,随时切到云端大模型。
这才触达了它真正的精彩之处:并不是让用户在本地和云端之间做二选一的单选题,而是给你一个统一的AI工作台,由你自己来决定,什么数据留在本地,什么需求交给云端。
看到这一步,肯定有人立刻会问:那为什么不直接用 Codex?
这个问题得讲清楚。
如今的Codex已经进化成龙虾的升级版(注:此处指年初的某爆款项目),它所具备的 Computer use 能力已经能完成大量操作——看屏幕、点按钮、输入文字、调动你电脑上的各类应用。让它打开软件、检查网页、复现界面上的问题,几乎都能通过Computer use来搞定。

所以,如果你只是想要一个强大无比的AI操作员,Codex 当然非常强大。
但 Odysseus 和 Codex 本就是两个完全不同的事物。
Codex 更像是 OpenAI 提供的一位高级AI执行代理。它的强项在于模型能力、任务执行、代码理解、桌面操作和自动化。你把一个目标扔给它,它就能为你完成。
而 Odysseus 更像是一个构筑在你本地的AI中控台。它的关注点不在于能不能替你点鼠标,而是你的模型、你的数据、你的文档、你的记忆、你的工具,是否能尽量保留在你自己的环境里。
这恰恰是两者最根本的区别。
Codex 像是一名从天而降的、能力强悍的官方AI操作员。
Odysseus 则是一个精心培养的、自托管的「个人AI工作室」。
所以,这绝不是重复造轮子。
如果你追求的只是最高质量、最省折腾、直接完成任务,那 Codex、Claude Code 这类工具确实更轻松。它们的优势在于模型能力强,能直接嵌入你的开发环境,读取文件、修改代码、执行命令,甚至协同云端任务与你本地的环境一起工作。
但 Odysseus 回应的,是另一类根本问题。
它不是要去跟 Codex、Claude Code 较劲谁的活儿干得更漂亮,而是在追问另一个问题:我能不能在自己的电脑上搭建一个AI工作台?我能不能用自有的硬件来部署模型?
尤其对于有隐私需求的人,这个区别一下子就会变得极为显眼。
你那些长期沉淀的工作笔记、项目资料、客户信息、公司文档、私人日历、邮件和任务清单,并不一定适合每次都被送到外部模型服务处理。
这并不等同于说云端模型或API一定不安全,而是很多人天然就渴望拥有一个选择权:某些任务我可以借助云端大模型,但另一些资料,我希望尽可能留在本地模型和本地工作区内处理。
Odysseus 给予的,正是这个选择权。
它的工作区数据可以安安稳稳地躺在你自己的硬盘上。你可以接入本地模型,也可以对接API;你可以用它来聊天,也可以用它来做Agent、深度研究、文档编辑、模型对比、记忆管理以及任务管理。
更重要的是,这些能力并不是散布在十几个彼此隔绝的工具里,而是汇聚在同一个工作台上。
举个简单的例子,过去你可能在ChatGPT里讨论项目,在 Notion 里记笔记,在Excel中做表格。每次切换一个工具,都要从头告诉AI:我是谁,我在做什么,我上次聊到了哪一步。
但 Odysseus 想做的是,让这些场景共享同一套上下文。
当你在notion里写完笔记的那一刻,excel已经顺承了之前的语境。
更令人玩味的是,我把以前在ChatGPT里生成的记忆摘要导入进去之后,它居然能继承此前的记忆,明白我的内容偏好、项目背景和工作习惯。下次我在它里面写文档、做研究、调用 Agent,就不必每次都从零开始解释。
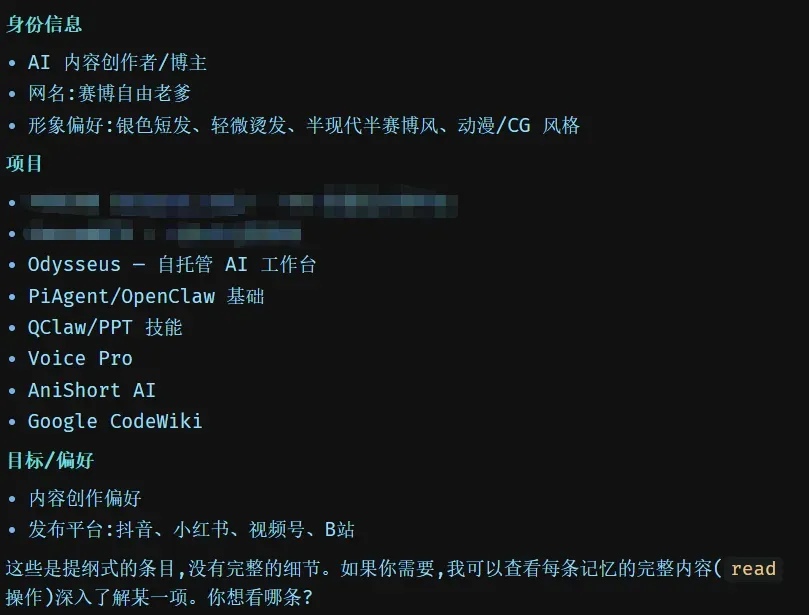
这就远不止一个本地版 ChatGPT 那么简单了。
更准确地说,它正在试着把本地模型管理器、Hugging Face 模型下载器、AI 聊天、Agent、文档库、深度研究、记忆系统和自动化工具,揉合成一个自托管的个人AI工作台。
当然,它现在还说不上是完美的成品。
你仍然需要部署 Docker,得配置模型,要处理各种环境问题,本地模型跑得快不快也极其依赖硬件配置。如果你是一个追求即点即用的小白,那可能还是 ChatGPT、Codex 这类产品会更舒心。
但它的方向绝对值得紧盯。
因为未来的AI工具,注定不止一种形态。
一种是云端大模型,能力强,体验优秀,开箱即用。
另一种,则是本地工作台,数据由自己掌管,模型由自己选择,工具由自己对接,记忆由自己保存。
Odysseus 代表的,恰好是第二条路线。
它最猛的地方,不是又发明了一个聊天框,而是把「一个普通人如何在自己电脑上安装、选择、部署和使用本地模型」这整件事,实打实地向前推进了一大步。
当别人还停留在纠结「究竟该下载哪个模型好」的阶段时,你已经可以着手扫描自己的硬件,然后清晰地看到你的电脑最适合跑哪些模型。
这才是我觉得它值得被关注的根本原因。
它不打算替代 Codex,也无意取代 ChatGPT。
它更像是在认真回答一个更深远的问题:
如果未来每个人都想拥有一个专属于自己的AI工作站,那么最初的第一步,应该长成什么样子?
Odysseus 交出的答案是:先从你的电脑开始。
扫描硬件,推荐模型,本地下载,本地部署,然后把你日常会接触到的聊天、文档、Agent、记忆和工具,一条条放进同一个工作台上。
这,也许就是个人AI OS,最初的模样。