AI模型《超级玛丽》游戏复现实战:豆包2.0、Model3与Qwen3.7 Max横评,仅Fable交出满分答卷
《超级玛丽》这款跨越时代的经典游戏,各大AI模型居然至今没能完美复现,实在让人大跌眼镜。我几乎把所有国内外主流模型都拉出来遛了一遍。
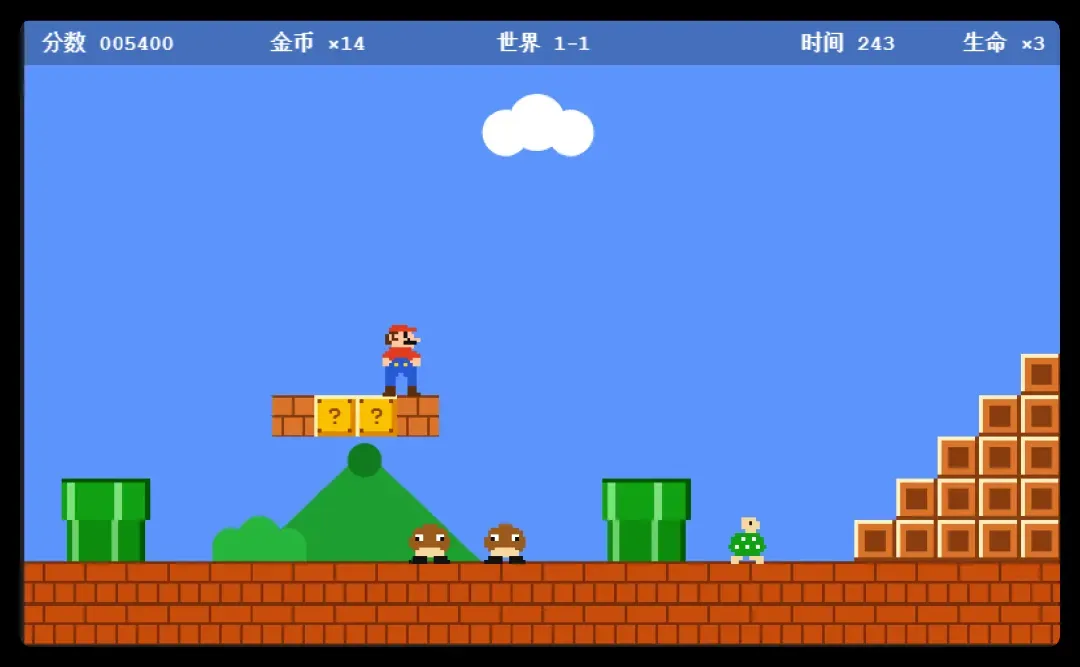
到目前为止,表现最抢眼的还得是Fable,其他选手可以说是状况频出、错误连篇。
GLM5.2和Kimi2.7的测评之前已经做过,也分享过了。这次的主角是Doubao2 Pro、Model3、Qwen3.7 Max。
为什么挑这三家?因为在《超级玛丽》这道题目上,它们勉强能坐到同一张桌子上。本来还想拉上MiMo,不过那篇已经单独写过,就不再重复了。看完它们交出来的作品,我只能感慨一句:真是别有一番趣味。
寓言
为了对比起来更直观,先让Fable打个样。
Claude Fable这个称呼本身就挺有意思,大致可以理解为“克劳德·寓言”。其中的“Claude”普遍被认为是在致敬信息论之父克劳德·香农。而最新版的寓言与神话模型共用同一个基座,算是目前公开可用的最强选手之一。
它的成绩单如下:
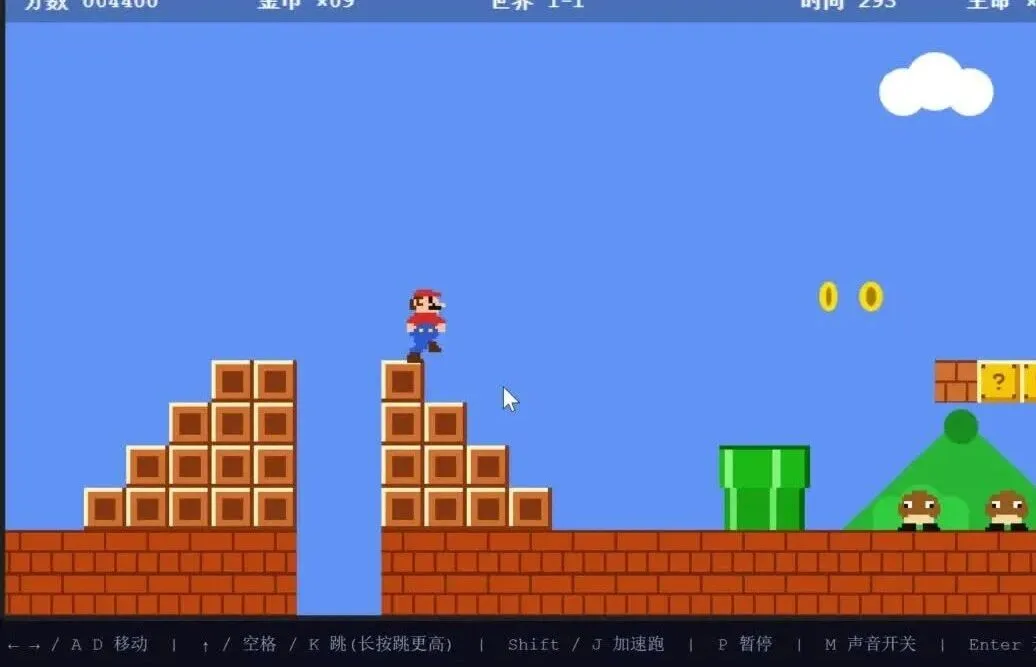
这里展示的是一轮对话直接生成的结果,全程没有加入任何二次提示。超级玛丽的地图布局、场景还原,以及角色行为和底层逻辑,背后其实藏着数不胜数的讲究。那些真正引爆市场的游戏,无一不是靠海量细节堆砌出来的。Fable还原得最到位的地方在于,整套代码完全是纯手写JavaScript搓出来的,相当震撼。
豆包2专业版
豆包大家已经熟得不能再熟了,国民级的日常应用。日常闲聊或者基础问答可能还顶得住,但一旦涉及编程、深度推理和低幻觉输出这几个维度,就一直差着那么一口气。平时我基本不会特意去碰它,这次纯粹是灵光一闪。
效果如下:
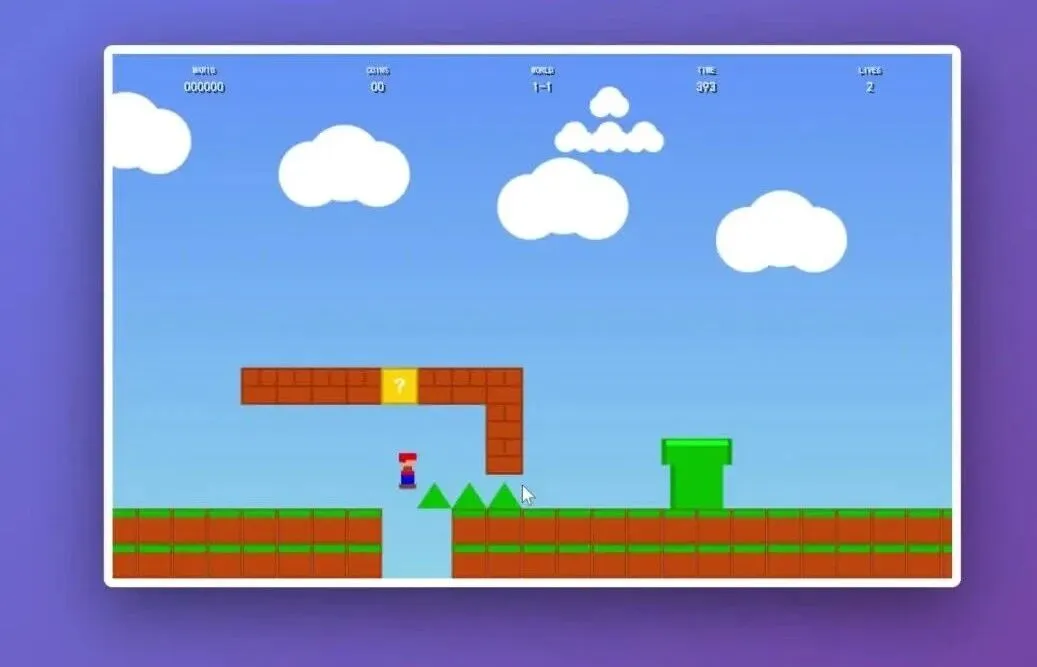
哈~我就看看,不说话。
Model3
为了不干扰对方的市值和内部同事的工作,这个模型我就不点名了,姑且叫它Model3。事实上,Model3一系的规模是最小的,基础能力也相对最弱,可是宣传上的声势却最响。
直接上展示吧:
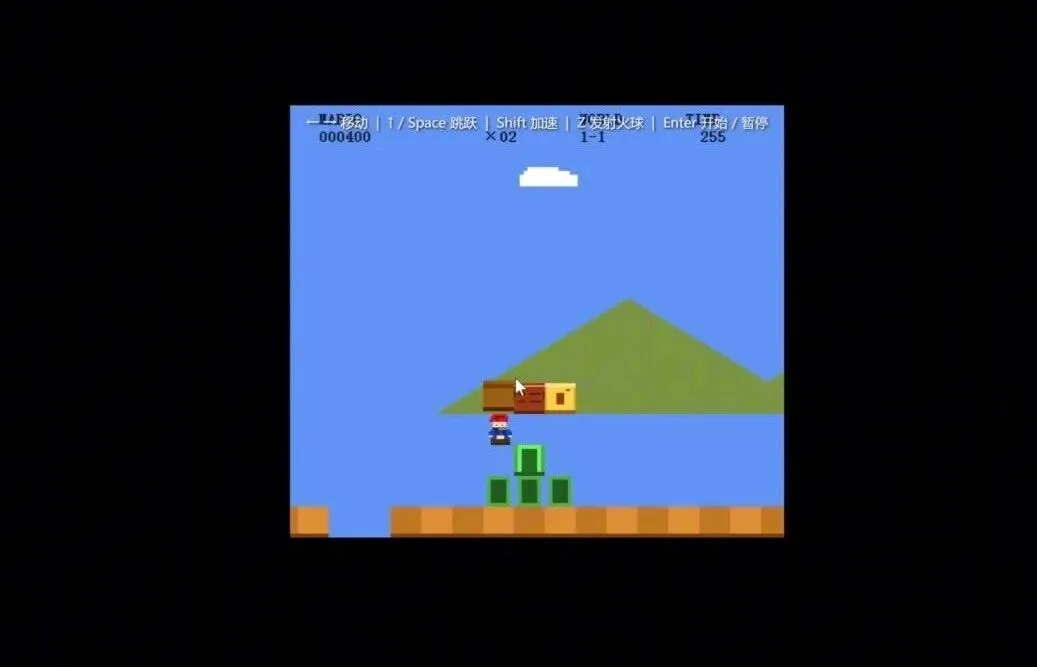
哈~我就看看,不说话。
Qwen3.7 Max
这是阿里目前手里最强的一张牌,刚发布时就打出“全球第二,国内第一”的口号。单看各种基准榜单,确实可以到处碾压同行。不过数据归数据,真刀真枪上场又是另一回事。今天就请《超级玛丽》给它好好上一课。
效果如下:
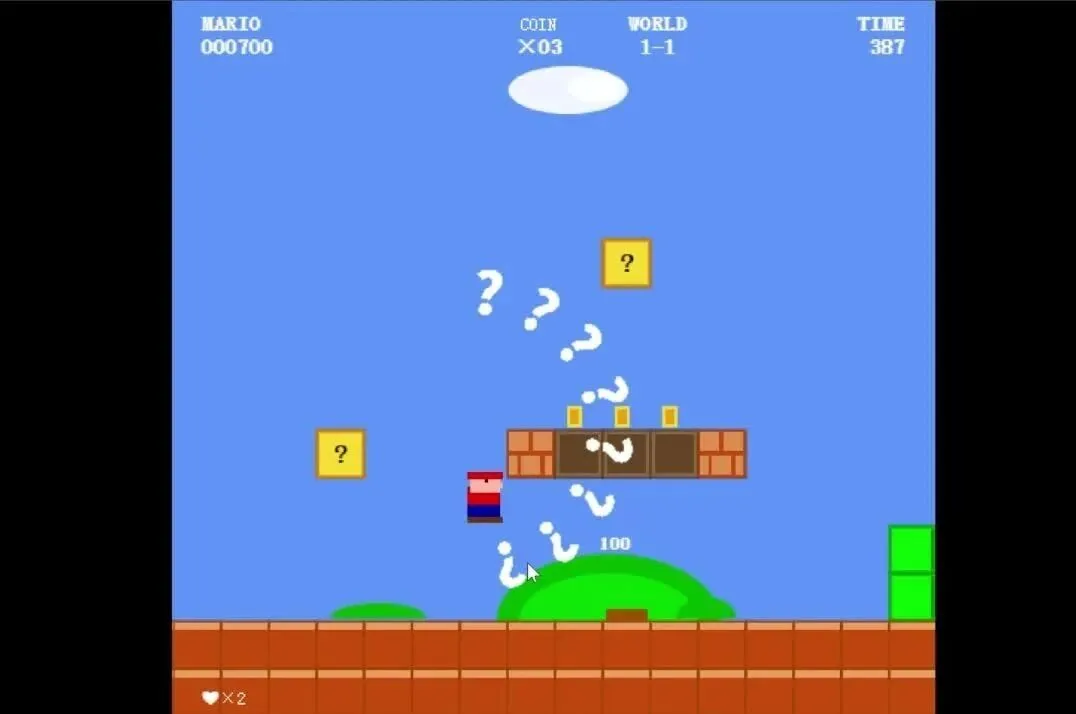
哈~我就看看,不说话。
现在咱们抛开所有公司名头,单纯看看最后捧到眼前的这些效果,各位作何感想?到底哪家棋高一着,差距又拉开了多少?当然,这只能算是一个极其狭窄的观察切口,远远不能代表它们的全部实力。不过窥一斑而知全豹,多少还是有些参考意义的。
我不能直说谁差,只能说娱乐指数拉满了。它们才是真正意义上的“原创高手”。
看过这些娱乐选手的表现,我更怀念用Fable的那三天了,那种感觉就是——我好像什么都做得出来!只要吸过那一口,再看别的就通通变得索然无味。用过的人自然心领神会,没用过的可以尽情想象一下。