MiMo V2.5 Pro深度评测:Claude Code最佳国产搭档,百万上下文极致性价比
昨天凌晨,小米悄无声息地上线了 MiMo-V2.5 和 MiMo-V2.5-Pro,API 接口也同步开放。

近期大模型的更新节奏密得惊人:上周 Claude Opus 4.7,这周 Kimi K2.6,昨天 MiMo-V2.5-Pro,还有姚顺雨带队的全新 HY3,今天又发了 GPT-5.5,估计 DeepSeek V4 也快亮相了……真是一个蓬勃的时代。
我一直对 MiMo 系列模型抱有好感,自从罗福莉加入小米后,小米大模型的实力提升肉眼可见。当然,最根本的原因是我做了十二年米粉,对小米的设计和硬件发自内心地喜欢,家里的电器几乎清一色是小米,这份感情自然也延续到了他们的模型上。
昨天下午完整试完 MiMo-V2.5-Pro 之后,不得不说,这个模型完全可以跟 GLM-5.1、Kimi K2.6 正面掰手腕,表现着实超出了我的预期。可以说它已经扎扎实实地挤进了第一梯队,开发者社群里也都在热议。
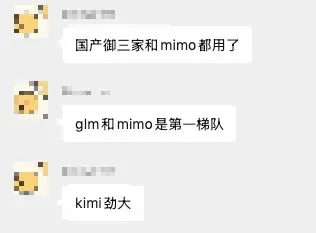
按老规矩,先看一眼跑分。虽然现在各家都在“赢学”里打转,但大致还是能看出一些端倪。
在 AA 榜单上,MiMo-V2.5-Pro 与 Kimi K2.6 并列开源第一。
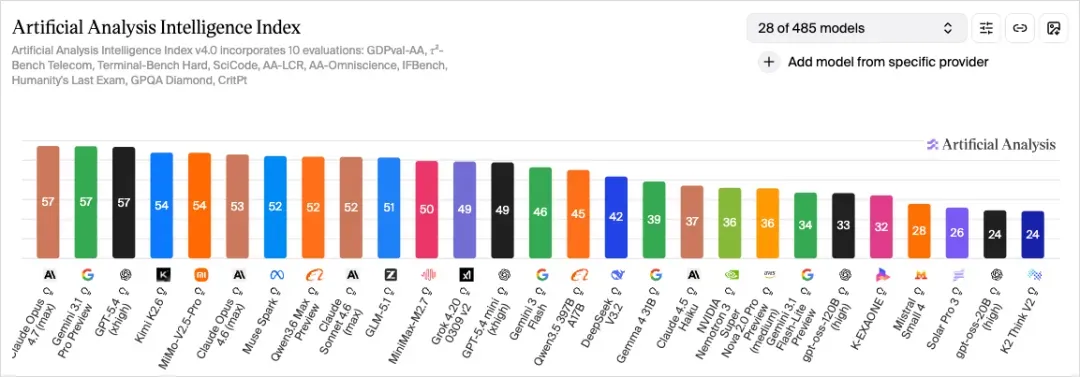
成绩相当亮眼,相较于小米自家过往的模型,进步也很明显。
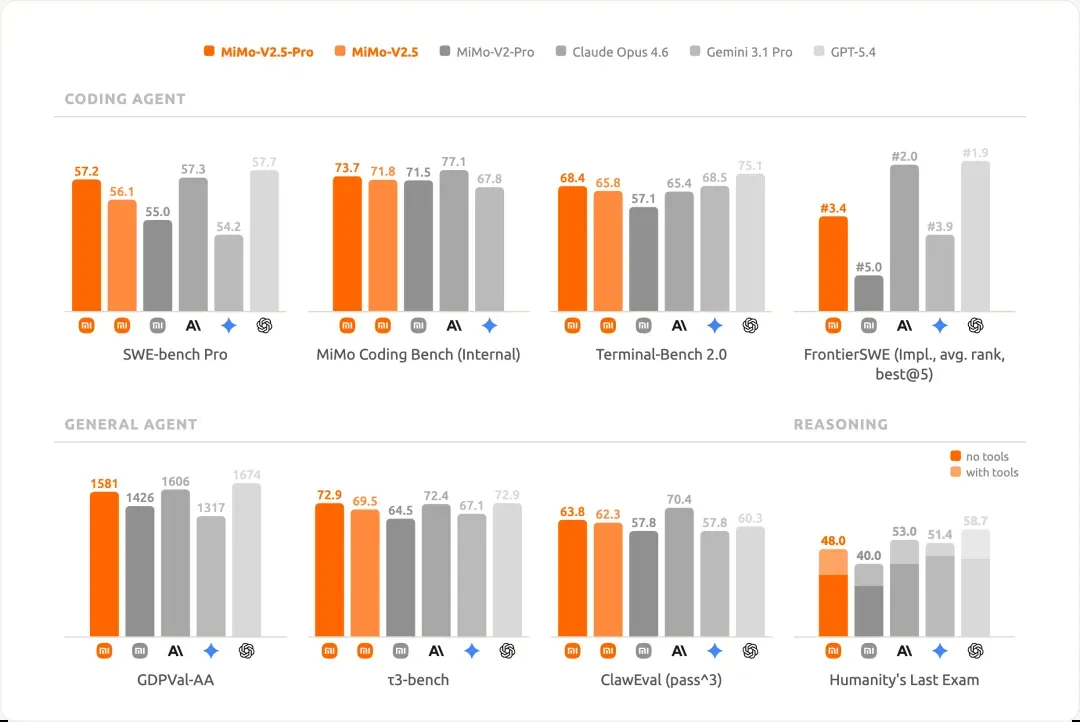
上下文窗口直冲 100 万 token,如今百万级上下文几乎成了头部模型的标配,今天发布的 GPT-5.5 也支持了 1M 上下文。
价格方面,我以前总是放在最后提,但这一次必须提前说,因为性价比实在太高,而且刚上线时用的人不多,接入 API 后速度飞快,体感完全不像某些国产模型那样动辄延迟好几秒。
API 调用的定价是:0 到 256k token 范围内,每百万 token 输入 ¥7 / 输出 ¥21;在 256k 到 1M token 区间,则是输入 ¥14 / 输出 ¥42。
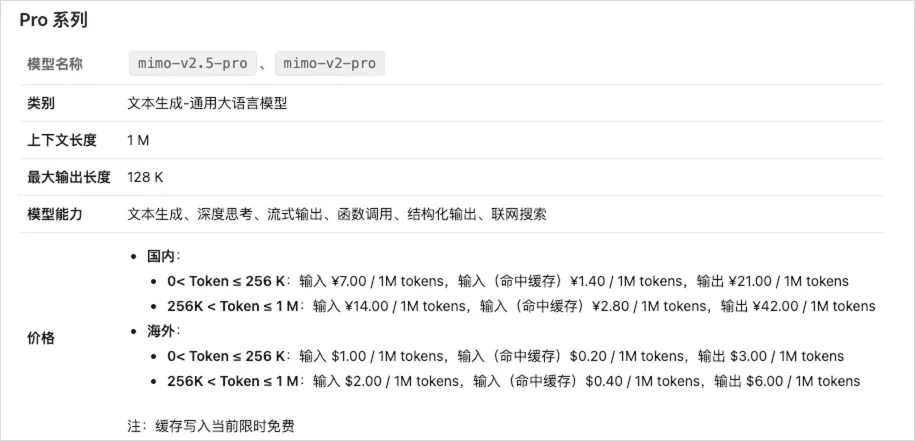
对比 Opus 4.6 每百万 token 输入 $5 / 输出 $25 的价格,MiMo 大约能便宜 60% 左右。
除了 API,MiMo 这次还推出了新的 Token Plan,不再区分 256K 和 1M 上下文,统一计费。
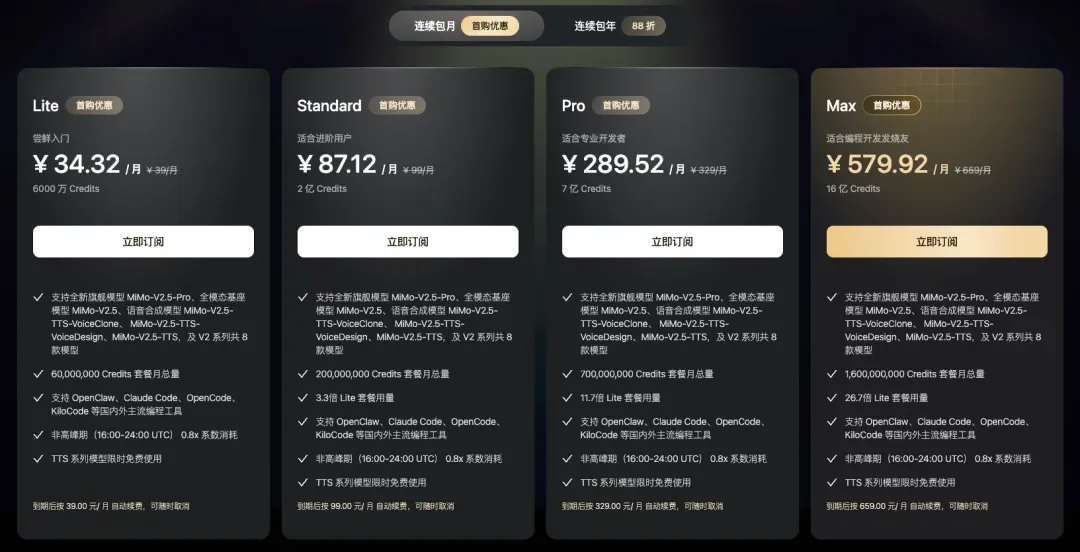
这个定价,坦诚地讲,非常有诚意。
在我自己的测试中,它的工具调用和代码开发能力意外地扎实,说人话且颇有几分“那个味道”。我是在 Claude Code 里使用的,可以很笃定地说:Claude Code + MiMo-V2.5-Pro,是我目前最推荐的国内 Agent 组合。很多朋友抢不到智谱的 Coding Plan、用不上 GLM-5.1,请相信我,这个组合就是当下效果最好的替代方案——便宜、大碗还省 token,效果出众,目前用户量少,响应极快。
我虽然自己主力仍会选择 Claude Opus 4.7 写代码、用 Opus 4.6 进行知识创作,但我知道不是每个人都能方便地使用 Claude,甚至很多人连 GPT 也用不上。在这种情况下,搭一套 Claude Code + MiMo-V2.5-Pro 的组合,会变得非常丝滑。
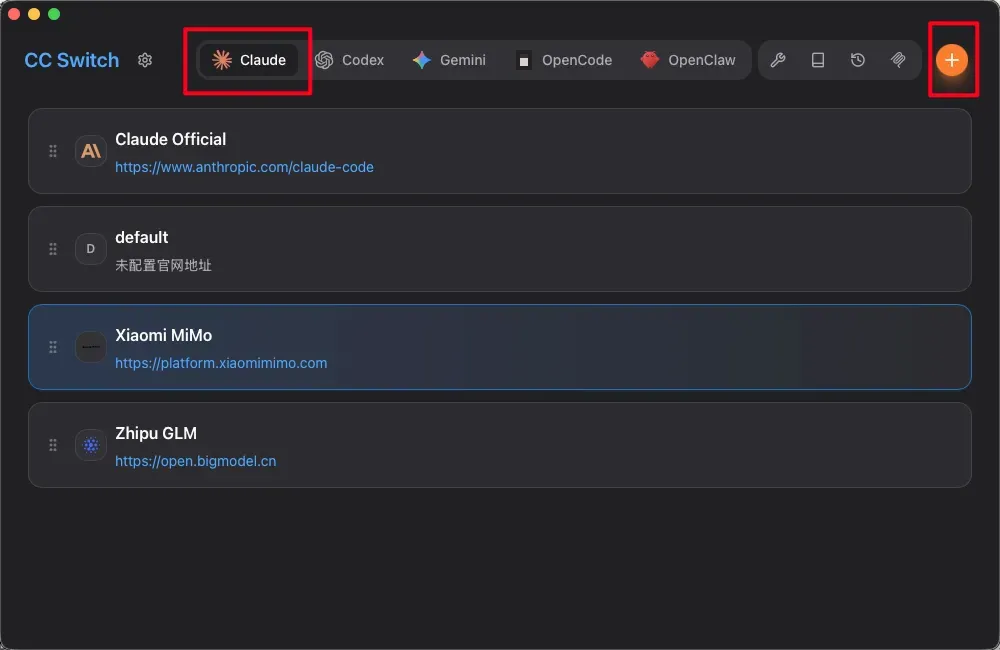
关于如何安装 Claude Code,以及如何通过 cc-switch 在 Claude Code 中接入国产大模型,我在周一发布的Claude Code国内使用的保姆级教程里已经详细写过了,此处不再重复。在那一篇的基础上,想换成 MiMo 新模型也非常简单。
双击打开 cc-switch,在 Claude 配置区点击右上角的加号。
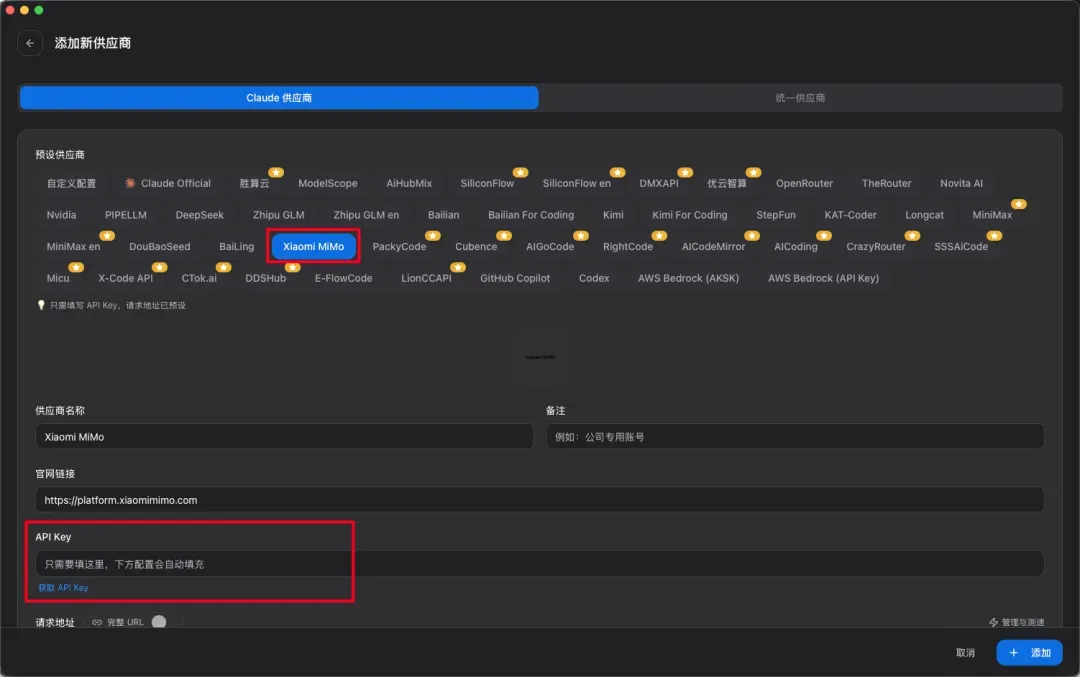
供应商选“Xiaomi MiMo”,填入自己的 API Key。
模型名称填写“mimo-v2.5-pro”。
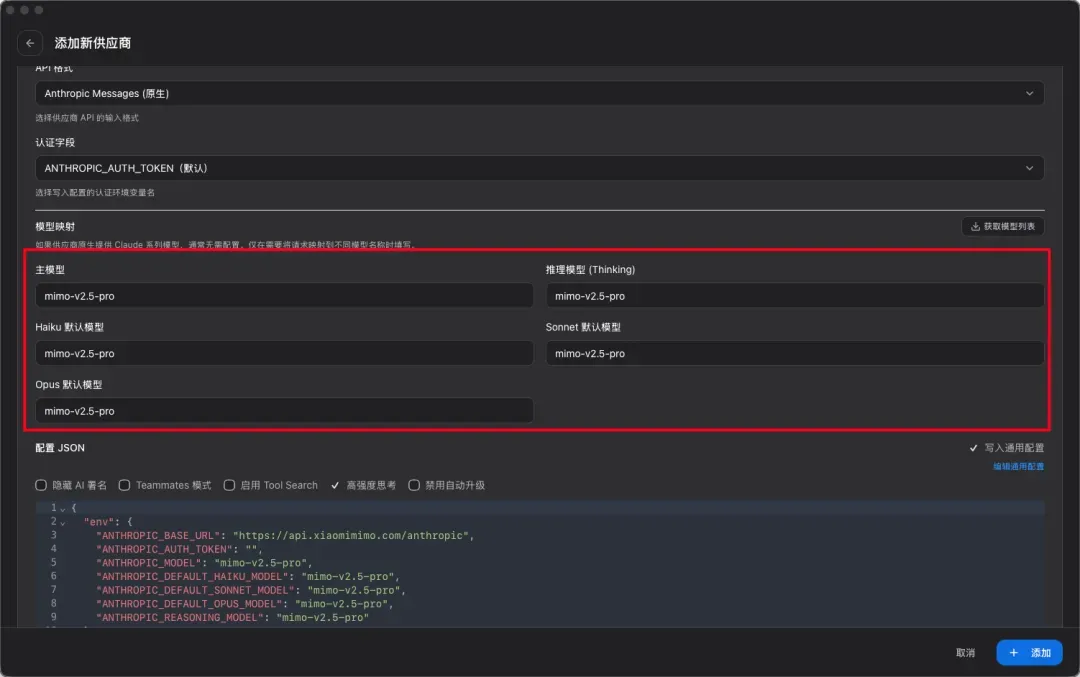
添加完成后,在首页启用,再打开 Claude Code 就能直接用上了。

来看一个我下午用 MiMo 亲手搓出来、自己还挺满意的案例。我一直想给自己做一个更好用的公众号文章数据分析平台。我一直认为,文章创作不是发出去就结束了,读者的反馈超级重要。目前公众号已经发了 612 篇文章,积累了海量数据反馈。虽然后台有现成的分析工具,但对我们来说远远不够。它提供的分析指标非常有限,肉眼只能看个大概趋势。
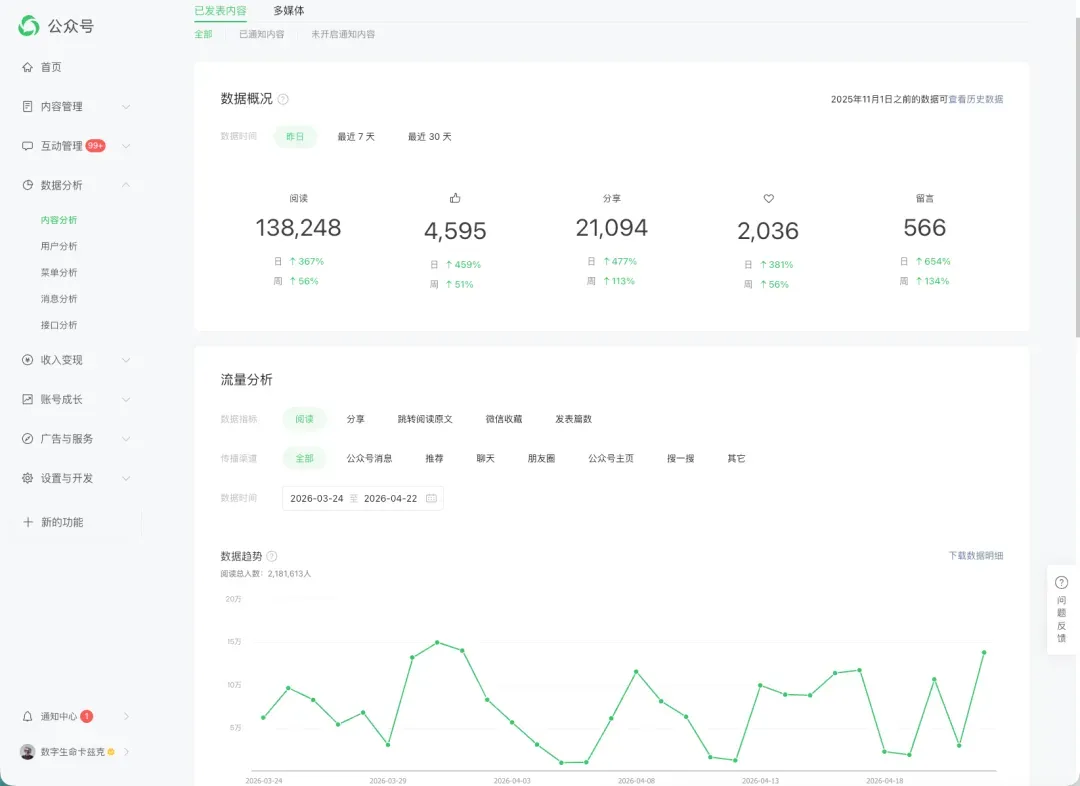
我们自己也会抓取更细的数据,之前也分享过我们那张密密麻麻的数据分析表。
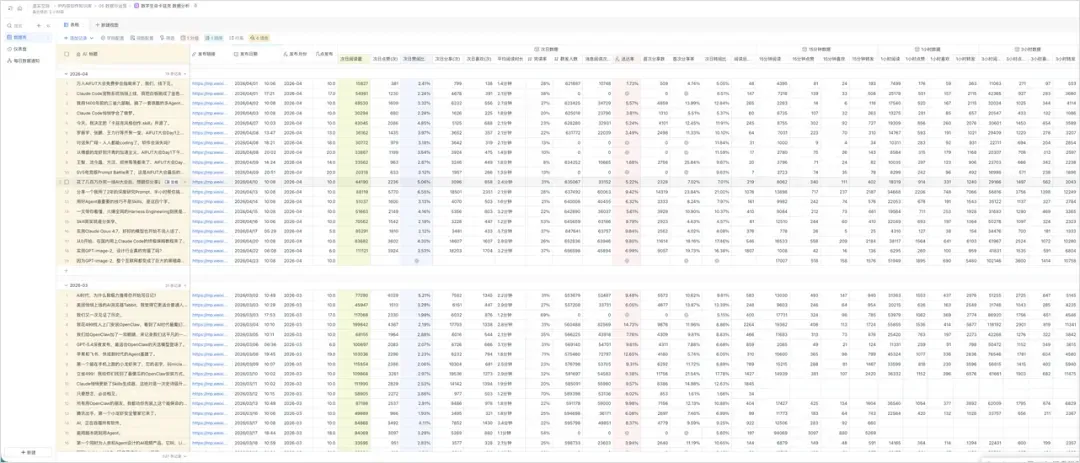
但说实话,数据的深度洞察还是偏少,每次看密密麻麻的数字都头疼。我一直琢磨,能不能用更好的方式,把数据量化,再从中挖出那些可能被忽略的趋势或信号。
比如这周一发的 Claude Code 保姆级教程那一篇,我其实对它的数据很看好。刚发出来时阅读量和转发率都不错,一小时就有近 7000 次转发。但后续增长明显乏力,速度变得很慢。那我们自然要复盘,除了平台流量因素之外,还有没有别的内因导致了这样的问题。
之前就一直想自己动手搓一个网站,直接用飞书多维表格做数据库,网页端做数据分析,部署到公司内部服务器,配合企业权限管理,让团队都能用。于是正好借着 MiMo-V2.5-Pro 发布的机会,看看能做到什么程度。
我直接在 Claude Code 里面开着语音输入口述需求。
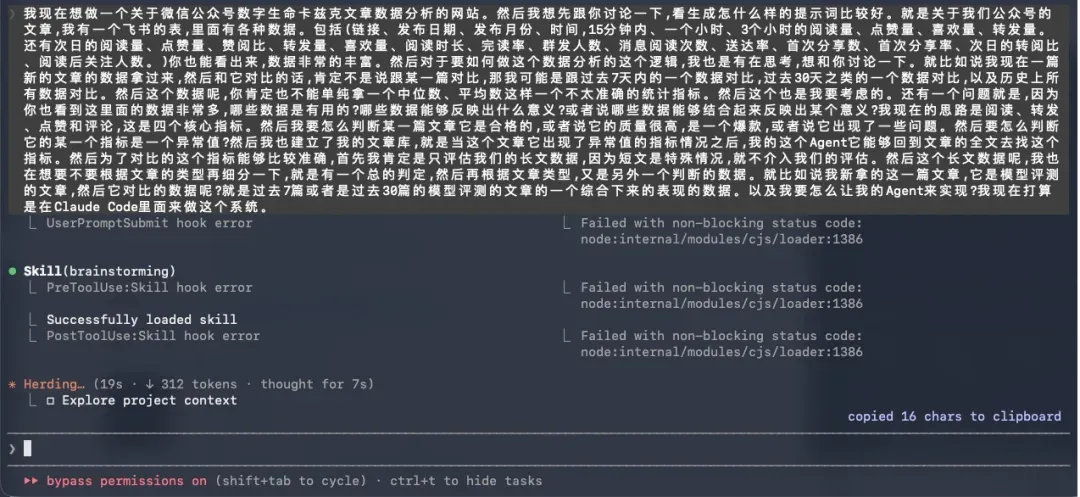
它根据我口述的内容,有条不紊地逐步输出:先是技术栈和架构设计。
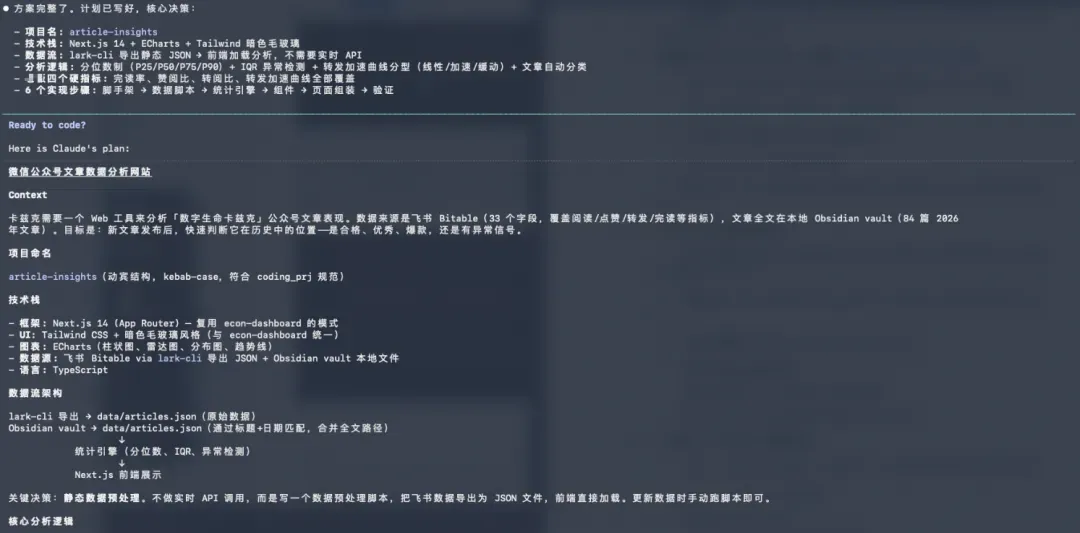
接着是数据分析逻辑,包含我提到的指标体系、转发加速曲线和对比基线。

然后又给出了项目结构、页面设计、实现步骤、验证方式与清单等极其详细的方案。
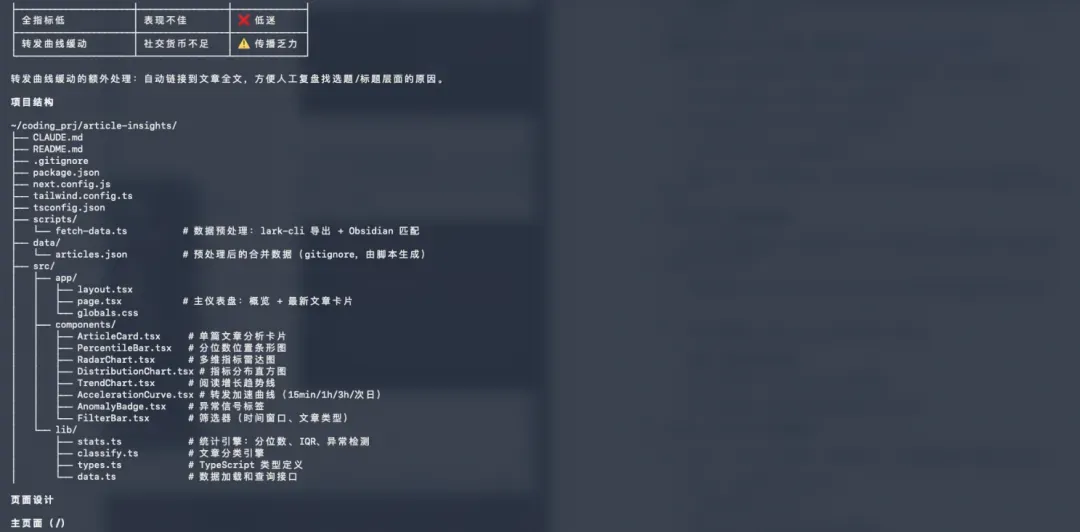
不得不说,和 MiMo-V2.5-Pro 对话时,莫名其妙地有一种 Opus 4.6 的感觉——说人话,出图表,实在舒服。
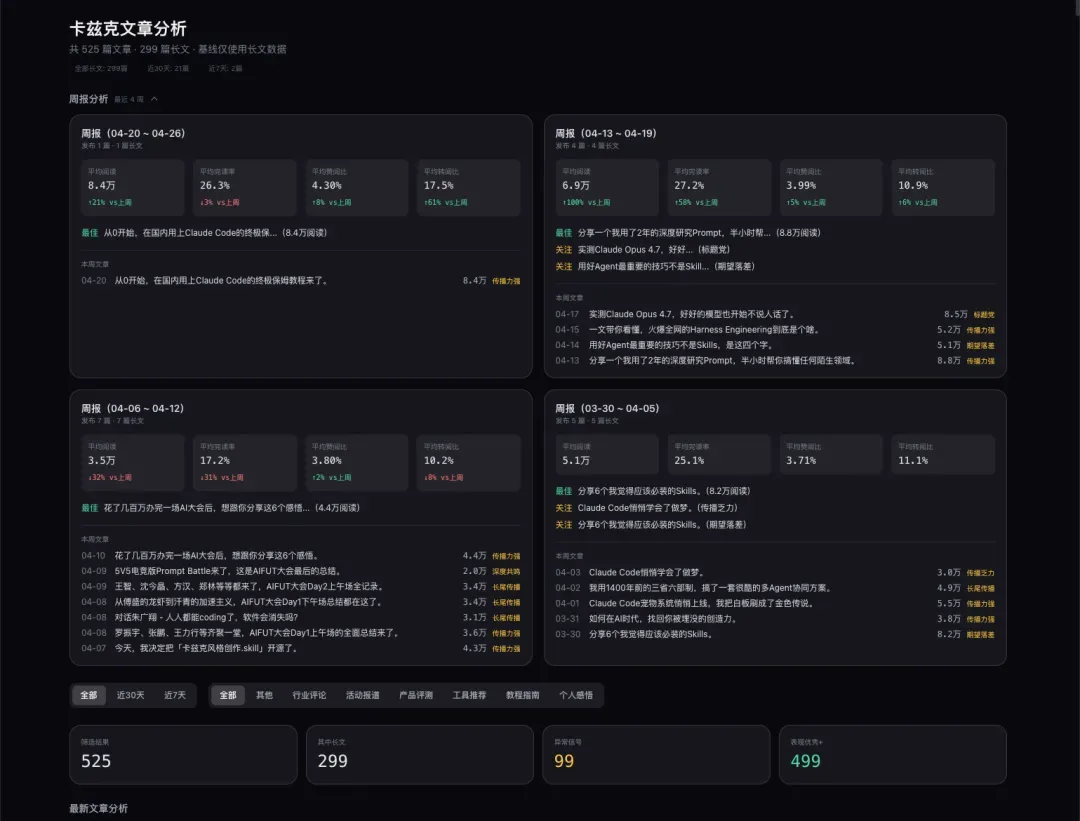
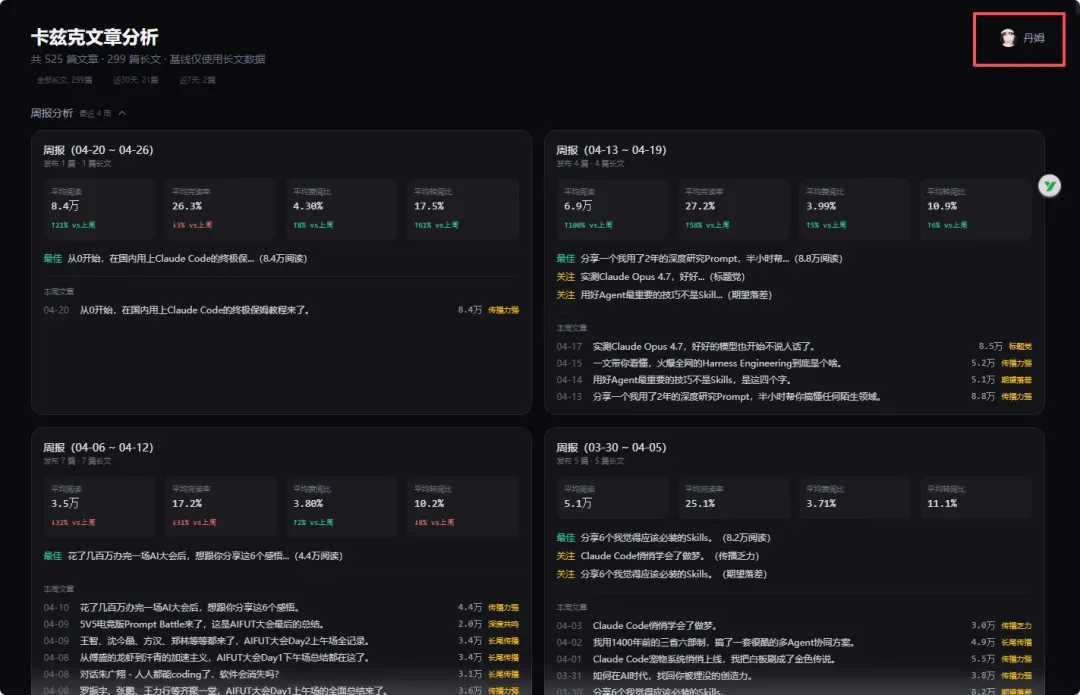
接着就直接进入开发。过程就不全放了,大致是每天脚本定时请求飞书数据库,拿到最新数据后进行可视化分析。最终做出的产品如下。因为我们要看三天的完整数据来进行分析,所以这里显示的最新文章仍是周一发布的那一篇。
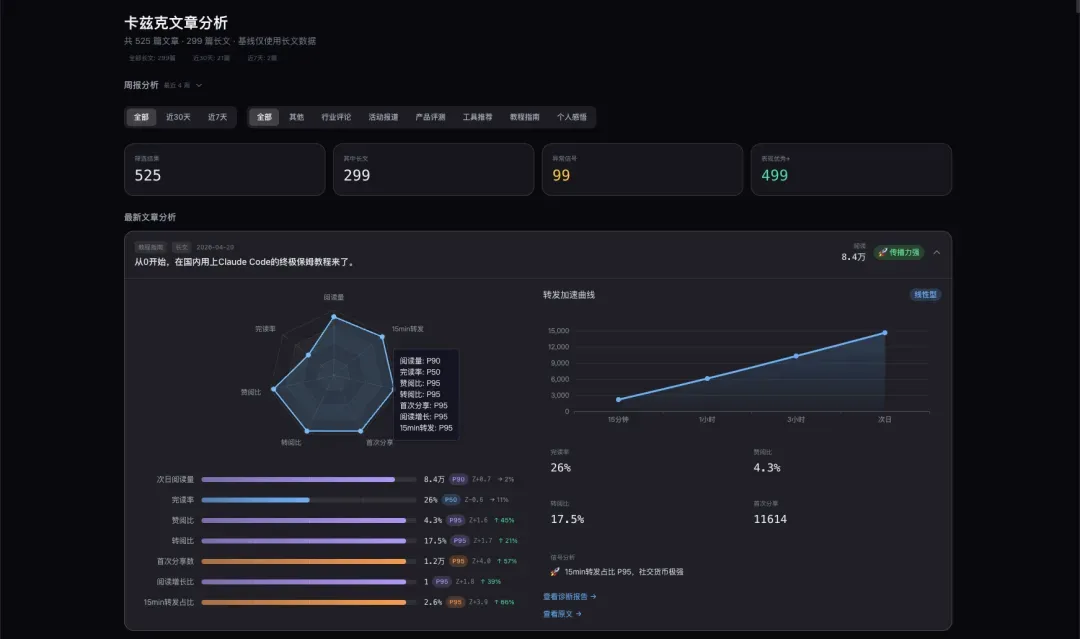
你能非常快速且直观地看到这篇文章各项数据的分布。很明显,这篇教程类文章的短板主要在完读率,而转发率在后面明显动力不足——教程类文章虽然容易被转发,但真正阅读的人少,读完的就更少了。核心指标的分布也一目了然,这篇文章在我们过去的所有核心指标上表现如何,都清清楚楚。
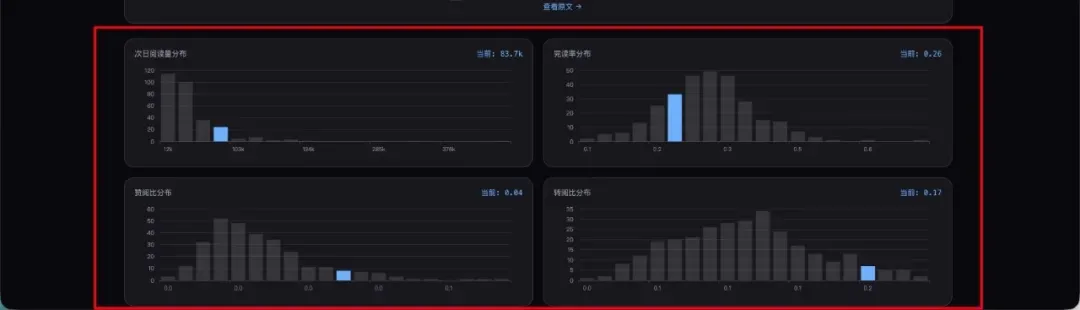
系统还会生成一份单独的报告。
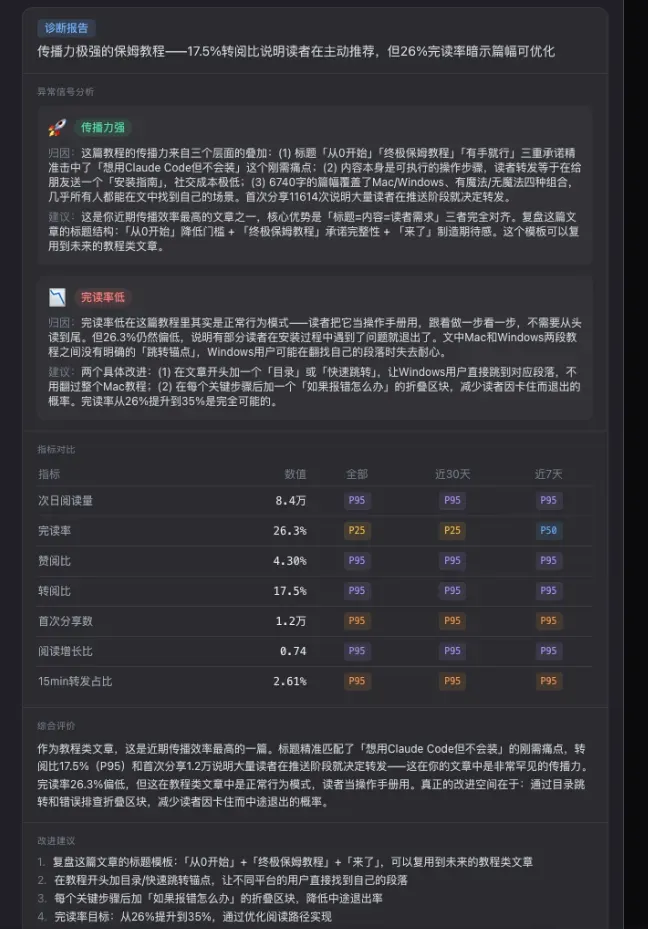
每篇文章的诊断报告相当全面,不仅指出数据好的地方,也分析不理想数据背后的原因,以及后续可以改进的方向。还有我们的周报看板,展开后能看到过去四周发布的每篇文章的基础数据。
任务到这里并未结束,因为这还只是静态页面,公司的小伙伴无法直接访问。于是我又让它调用我专门给公司搓的服务器 skill,把这个网站部署到内部服务器上。客观地说,我这个服务器 skill 相当复杂,因为和飞书的认证体系做了打通,只有公司员工才能使用,还做了大量隔离,让不同项目跑在不同的容器里。一些能力偏弱的模型,在首次部署这一步就直接失败了。而 MiMo-V2.5-Pro 顺利地完成了用户首次部署逻辑,需要进行认证并与飞书企业对接,确认是否为内部员工。

Mimo 的理解和调用过程非常流畅,我给它验证码后,所有步骤按部就班就成功了,非常出色。

然而部署上去的网址实际上所有人都能公开访问,这当然不行,必须限定只有公司员工才能访问。于是我又把我为内部 Coding 做的统一登录中台也接了上去,以进行登录权限管控。
我们的中台上放着一份接入文档,因为平时小伙伴们开发的各种东西太多,每个人都有部署和管控权限的需求,我就做了这个文档。只要把文档链接发给 Claude Code,就能让项目自动接入我们的统一登录中台。
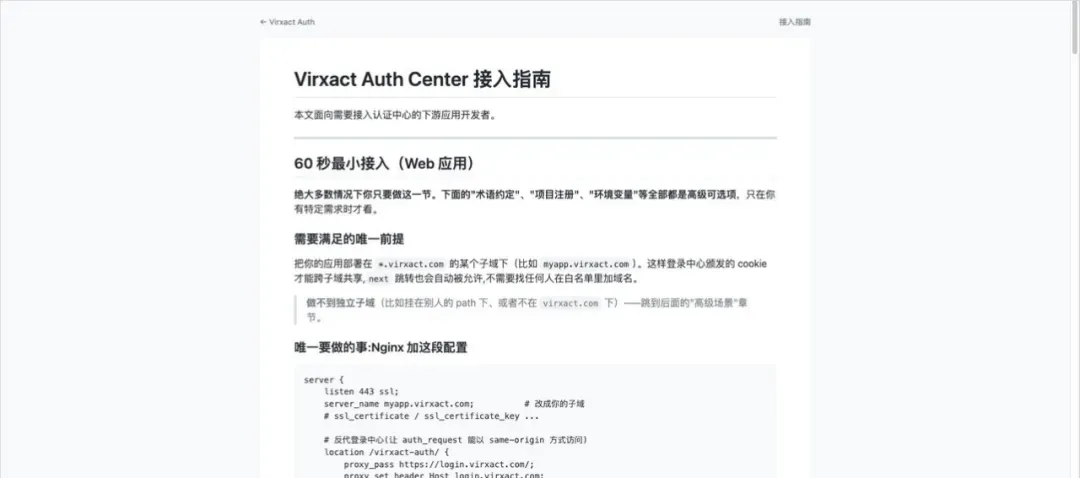
这份文档内容着实不少,涉及多种接入方式和渠道,还要同步用户信息,并且我们有三家飞书主体,各自的权限设定都不一样。能力稍弱的模型在测试时经常接出 Bug,但 MiMo-V2.5-Pro 只一轮,零修改,直接完美接完。

我让同事测试了一下,完全没问题。

到这一步,我看了一眼整体的 token 消耗。

输出 157.1K,输入约 1.2M,缓存命中 29.6M,而且缓存目前还是限时免费的,所以总体消耗意外地少。MiMo-V2.5-Pro 确实有点东西:飞书数据通过 CLI 一次拿到,正常开发,服务端 skill 一次部署成功,登录中台一次性接入——整个过程行云流水。
公司内部我还捣鼓了一个 skills 同步平台,因为很多同事自己搞了各种 skill,也需要相互分享,但以前全都靠微信传来传去,效率低下。于是我做了一个能让所有人上传 skill、其他人可以订阅的平台,订阅后本地就会自动安装对应的 skills,后续线上更新,订阅者本地也会同步更新,非常方便。
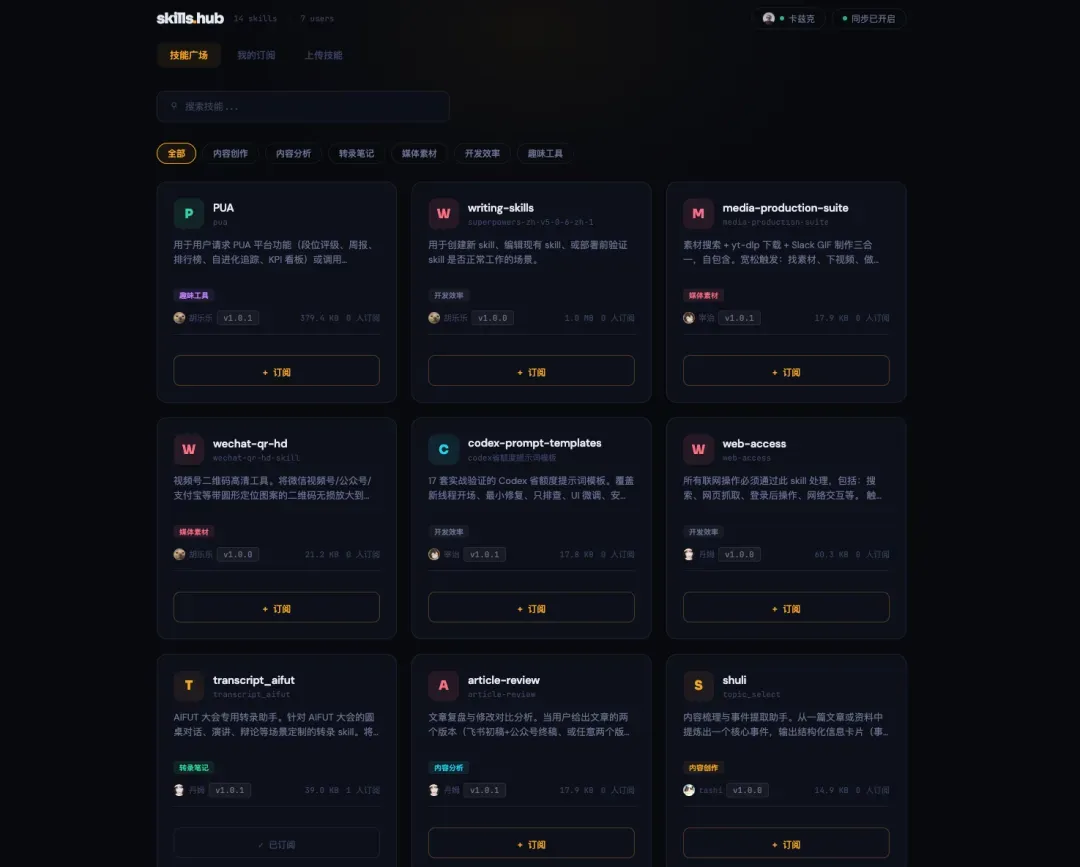
今天才算是第一次正式运行。之前用 Opus 4.6 开发时遗留了不少 Bug,而今天这些 Bug,全都是 MiMo V2.5 Pro 直接修好的。甚至打标签、加头像之类的各种功能,也都是我用 MiMo V2.5 Pro 顺手开发的。
不得不承认,这模型是真的有两把刷子。
还有一个很有意思的尝试。我把 160 万字的《甄嬛传》整本丢给 MiMo-V2.5-Pro,让它分析人物关系图、情节线、人物志,最终生成了一个可交互的网页。为了好看,我让它去搜索剧照,给角色配上演员照片。

最后出来的网页非常有趣,你能快速看清整部剧里每个重要角色,以及人物之间的关联。
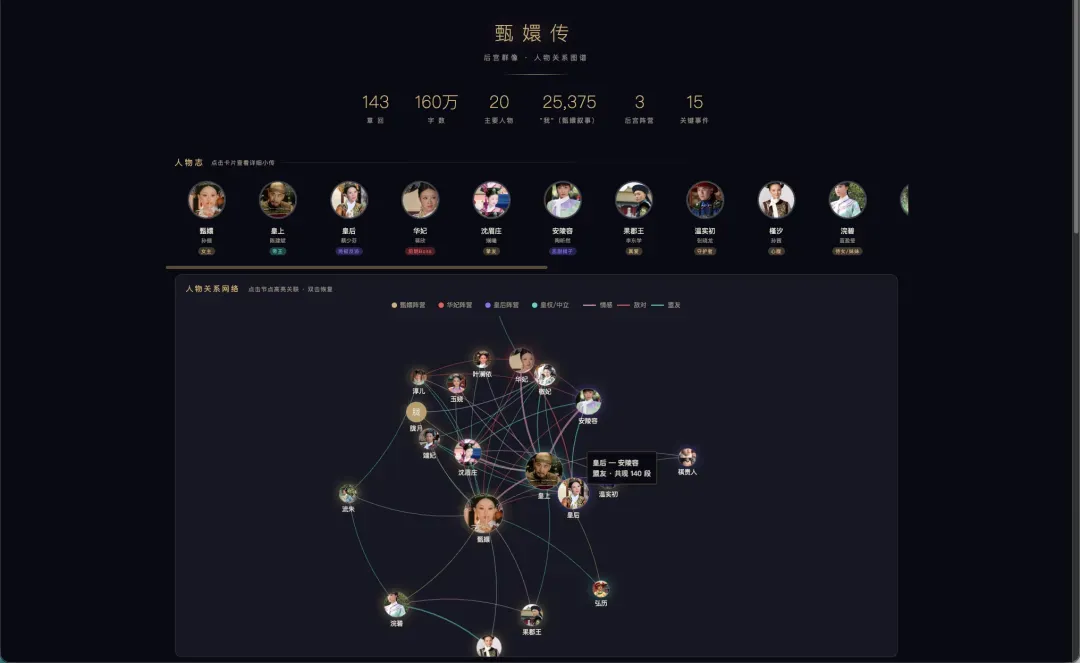
还有时间线和各个人物阵营。
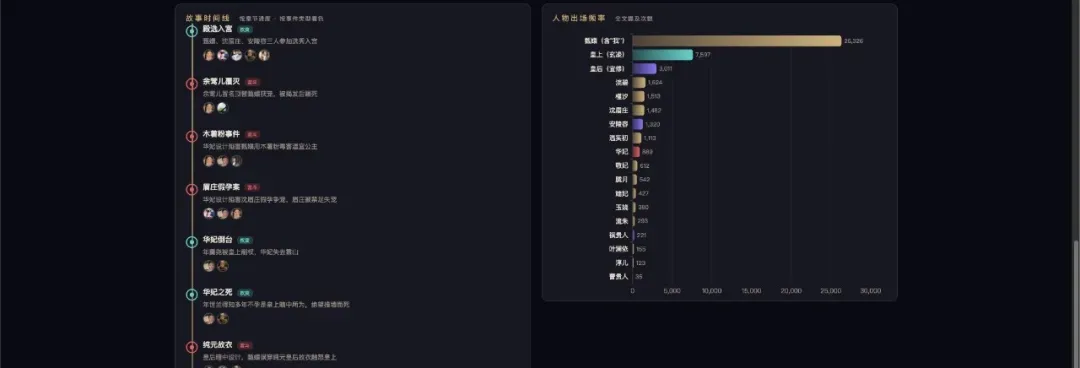
确实挺好玩。
当然,MiMo-V2.5-Pro 也有一个不足:前端审美能力还没有跟上它在其它方面的水准。一开始生成的页面在视觉上只能说能用,谈不上设计感,还是需要配合一些前端设计的 Skill。这一点跟 GPT-5.4、5.5 的情况非常相似。但我认为这无伤大雅,因为前端设计有很多手段可以弥补,而逻辑推导和代码能力才是核心。
就目前来看,MiMo-V2.5-Pro 确实是我认为配合 Claude Code 的国内最好选择之一。这种窗口期估计不会太长,等大家都反应过来,速度可能就没现在这么快了,计划或许也不一定好买了。
最后,祝大家创造愉快。