AI提效实战:基于Claude Skills构建自媒体知识管理系统的完整指南
这两年的创业历程中,我同时运营着自媒体账号。作为持续输出内容的创作者,我每天都要从各平台筛选、收集并整理海量信息,这个过程长期困扰着我的工作效率。
每当刷到优质视频内容时,我总会产生"如果能一键提取视频文案该多好"的想法。但实际操作中,我只能先点击收藏、截取画面,再将链接塞进"待处理"文件夹。等到真正需要用时,当初的思路和语境早已消散,手头仍缺乏可用的文本素材。
过去我尝试过交给实习生处理,但观察其工作流程后发现问题重重:反复拖动进度条定位重点、逐字记录字幕导致耗时过长、整理的笔记格式杂乱无序。我意识到即使亲自上阵,这种低效模式也难以持久。于是,我将整个流程封装成了Claude Skill:
该场景本可通过Workflow优化,但我更想探索更深层的解决方案——不仅是解决单点效率问题,而是构建全自动化的内容处理闭环。由此诞生了Krawl系统:
这是一个依托Claude Skills机制的知识管理平台。在深入讲解Krawl前,有必要先厘清核心概念。
Claude Skills核心架构解析
根据Anthropic官方定义:
Agent Skills are modular capabilities that extend Claude’s functionality. Each Skill packages instructions, metadata, and optional resources (scripts, templates) that Claude uses automatically when relevant.
随着OpenClaw等工具的流行,大家对Skills已不陌生。它作为模块化能力单元,通过封装指令、元数据及可选资源(脚本、模板等),使Claude能在匹配场景时自动调用。
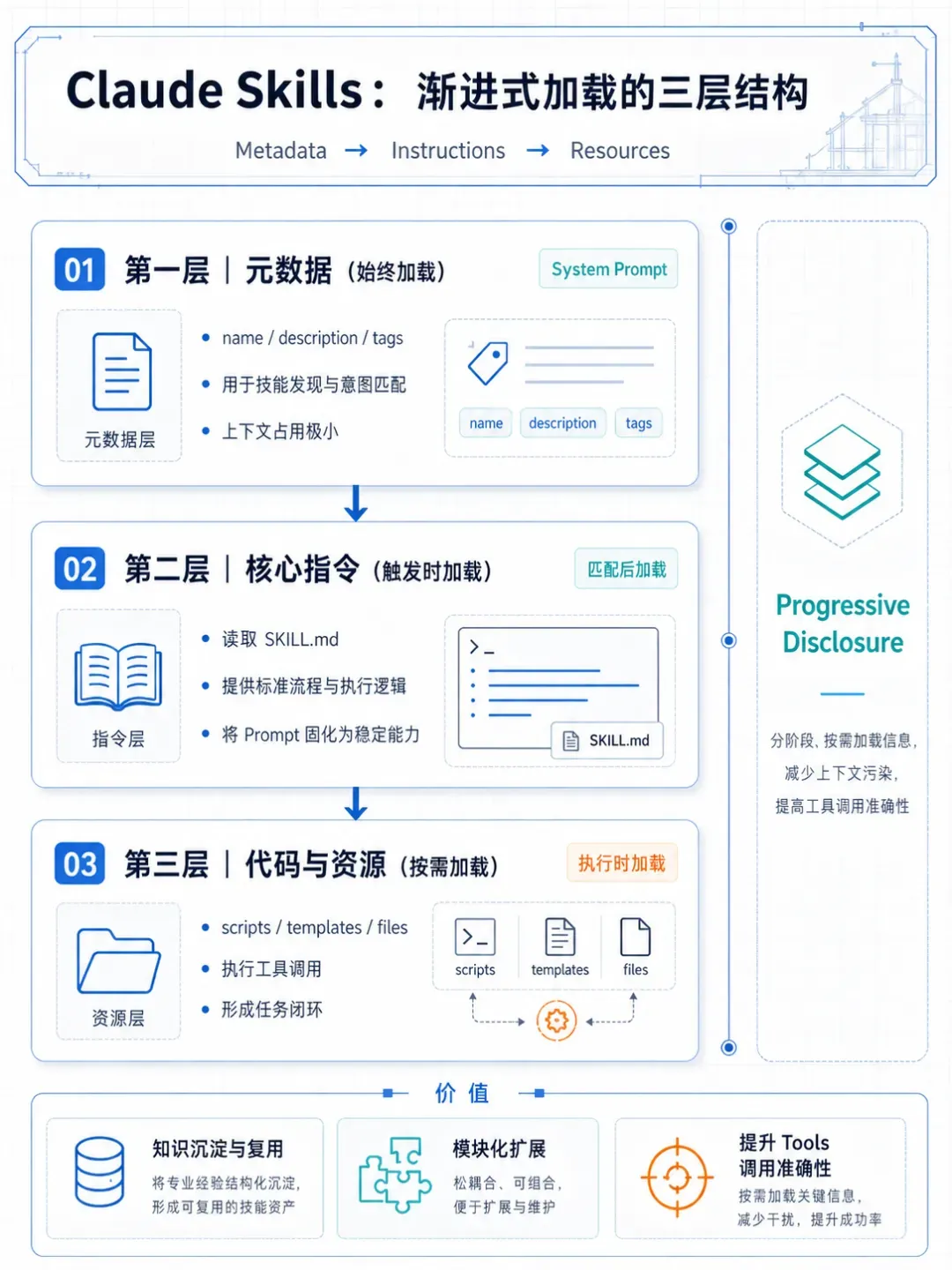
Agent Skills的三层架构构成了上下文分级体系:
- 元数据层:包含名称、描述、标签等基础信息
- 指令层:定义Skill的具体执行逻辑
- 资源层:附加的执行代码、模板等文件
其设计遵循渐进式披露原则:信息分阶段按需加载,而非在任务启动时全部塞入上下文窗口。加载流程对应三层架构:
第一层:元数据(常驻内存)
Claude启动时扫描所有已安装Skills,将元数据注入系统提示词。该层仅占用极小上下文,作用是:
- 让Claude感知可用技能清单
- 支撑后续意图识别与触发判断
- 不包含具体执行逻辑
第二层:核心指令(触发加载)
当用户请求匹配某个Skill描述时,Claude通过bash读取对应SKILL.md文件并载入对话上下文:

第三层:资源代码(按需加载)
复杂Skill可能包含多文件构成的完整工具集。通过元数据→指令→资源的三级结构,Skill实现了从需求理解到任务执行的完整闭环。
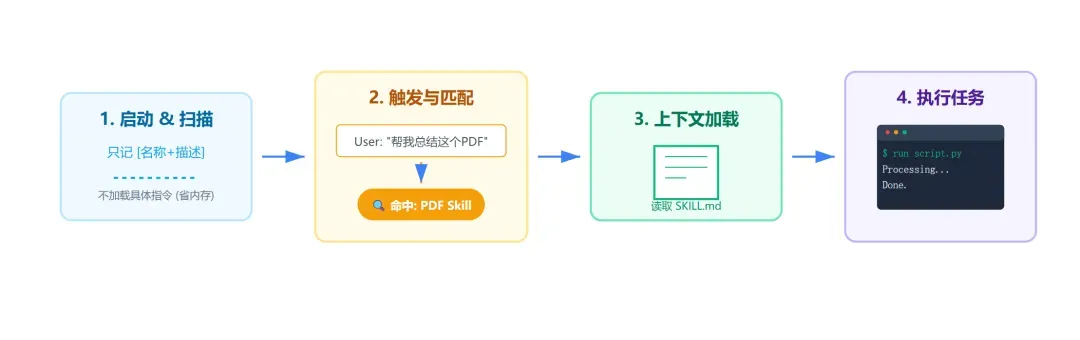
Skills模式核心价值
通过实践可归纳出四大优势:
- 知识沉淀与复用:高频流程固化为可复用组件
- 模块化架构:独立技能单元便于测试与扩展
- 组合创新:多技能协作构建复杂工作流
- 显著提升工具调用准确率
Claude Skills部署实战
在Claude Code中可通过两种方式启用:
方式一:官方市场(推荐)
# 添加官方技能库
/plugin marketplace add anthropics/skills
# 浏览可用技能
/plugin list
# 安装文档处理技能
/plugin install document-skills@anthropic-agent-skills
安装完成后可直接询问Claude当前可用技能。
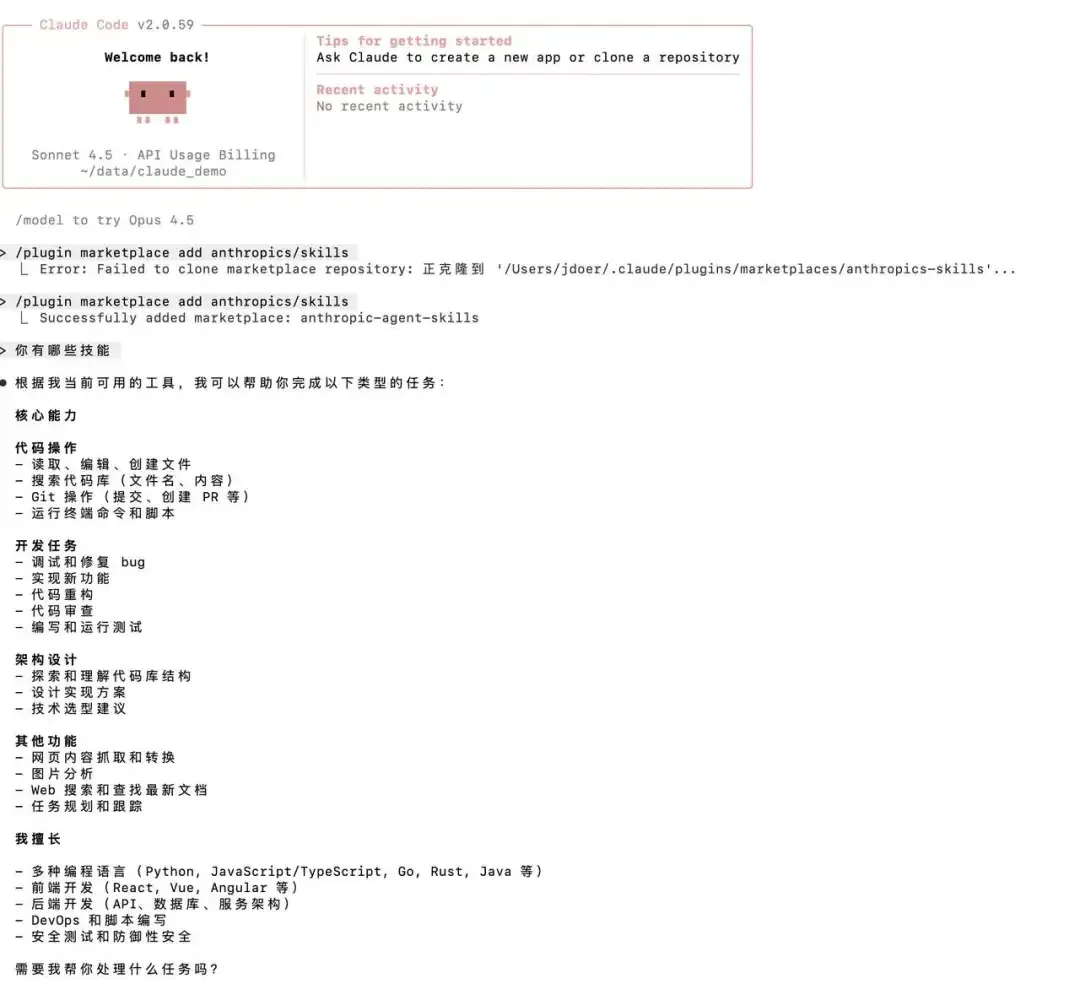
方式二:自定义开发
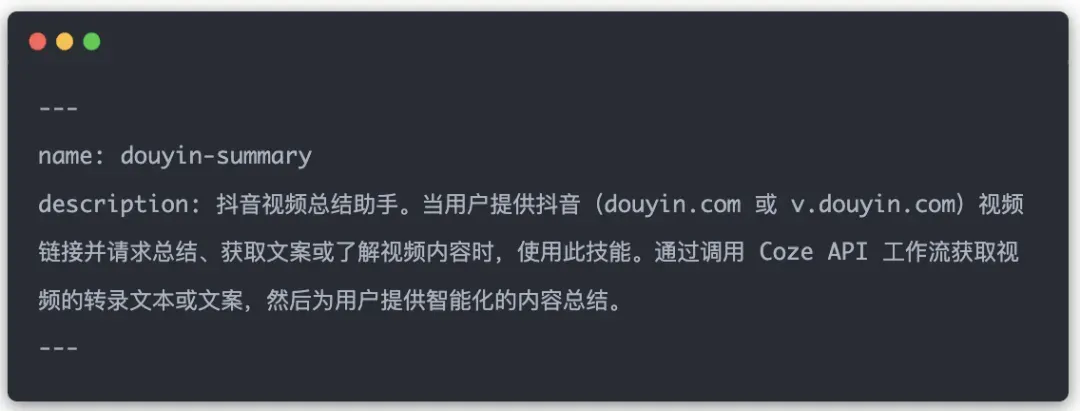
以"抖音视频自动摘要"为例,创建流程如下:
- 创建技能目录:
mkdir -p ~/.claude/skills/douyin-summary
- 编写SKILL.md配置文件:
---
name: douyin-summary
description: 抖音视频总结助手。当用户提供抖音视频链接时,自动调用此技能获取文案并总结。
---
# 抖音视频总结助手
## 工作流程
1. 识别用户输入中的douyin.com链接
2. 调用scripts/fetch_douyin.py获取视频文案
3. 提取核心观点并结构化输出
- 验证安装: 配置完成后可检查技能列表。新版Claude Code无需重启即可加载新技能。

使用效果展示:
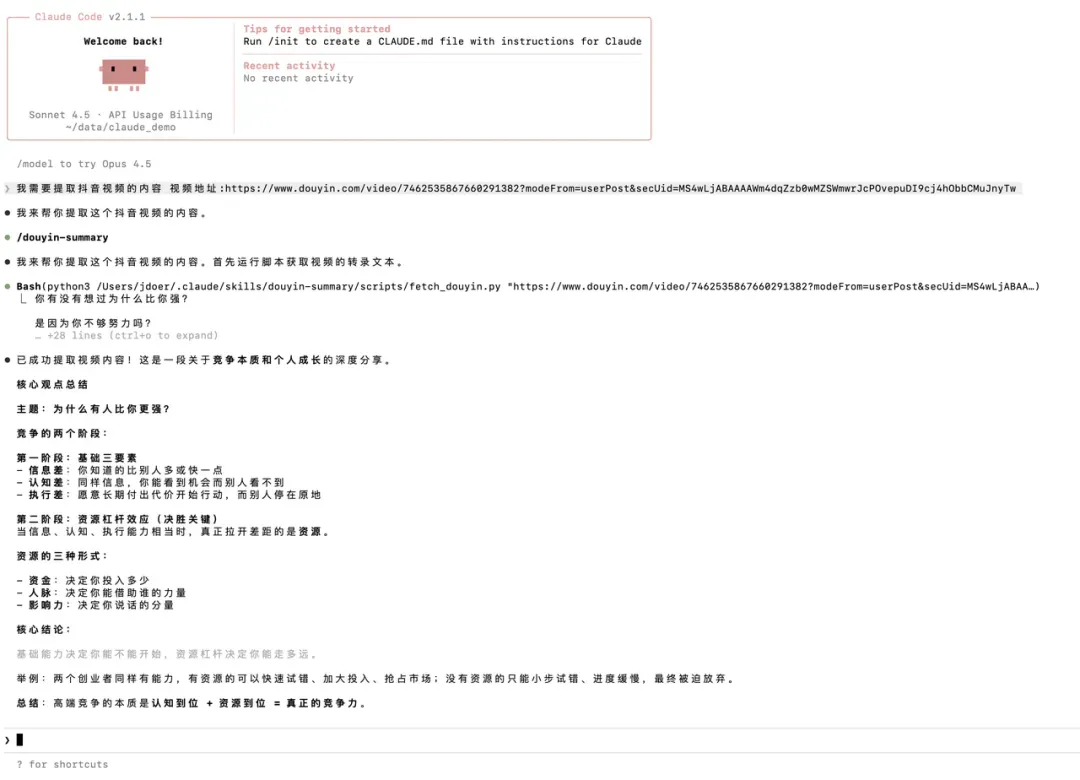
掌握基础后,即可构建系统化解决方案。
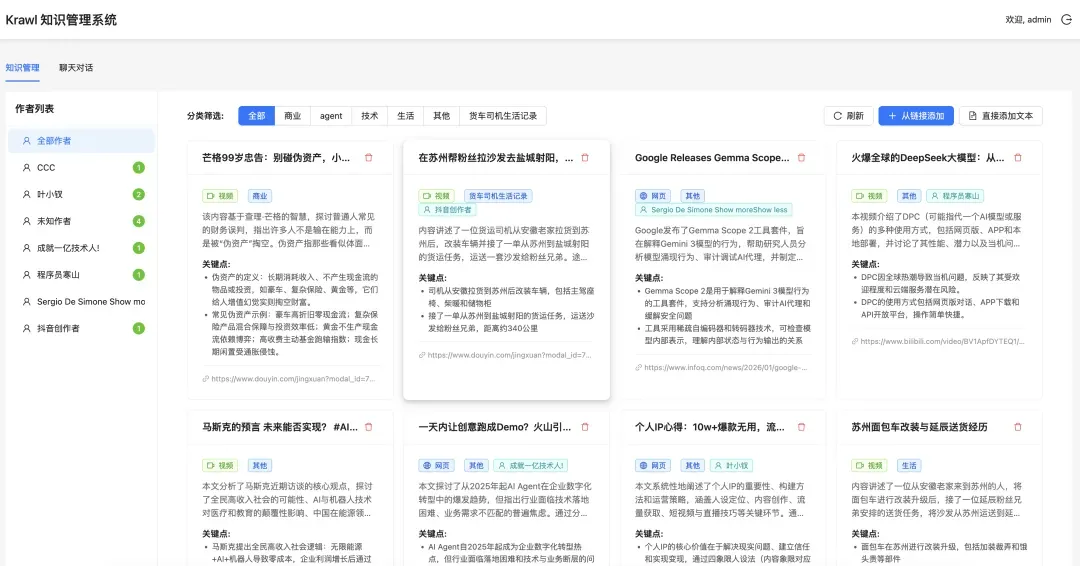
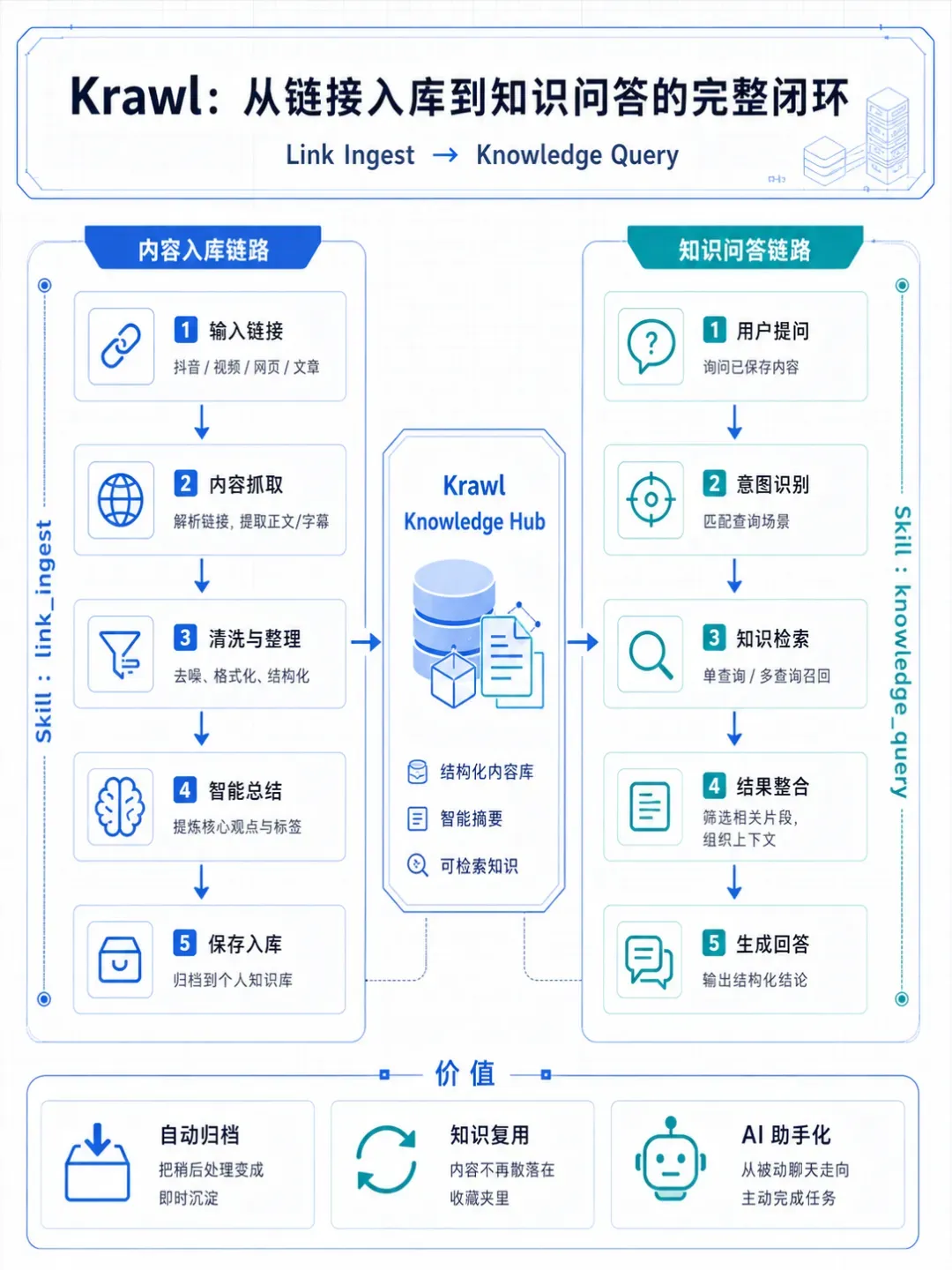
基于Skills的Krawl系统设计
Krawl(知识库与智能体系统)是团队内部项目代号,旨在演示Skills技术应用范式。通过技能扩展机制实现AI与工具链的深度整合。
系统演示
点击"从链接添加"按钮并粘贴URL,系统自动解析内容:
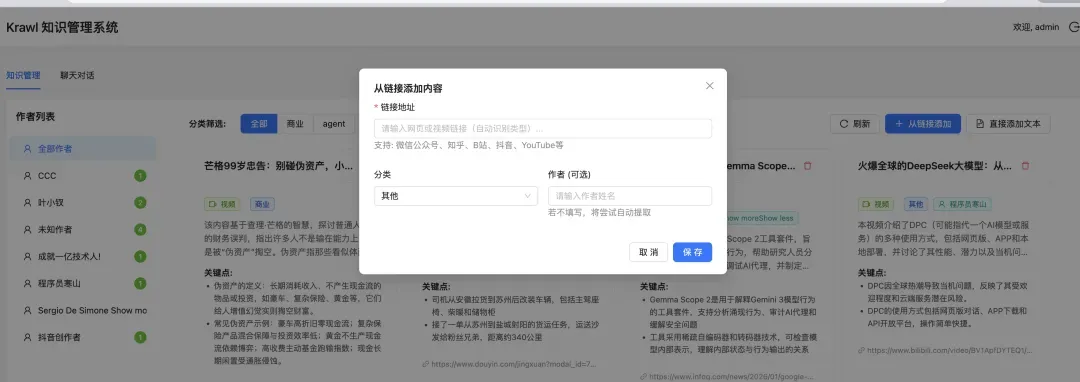
处理完成后生成智能摘要并归档:
Skills模块化设计哲学
核心思路是将复杂流程解耦:将多媒体内容提取封装为link_ingest技能,知识检索封装为knowledge_query技能。这种解耦设计带来可移植性优势——其他项目需要同类能力时,直接复制技能目录即可实现即插即用。
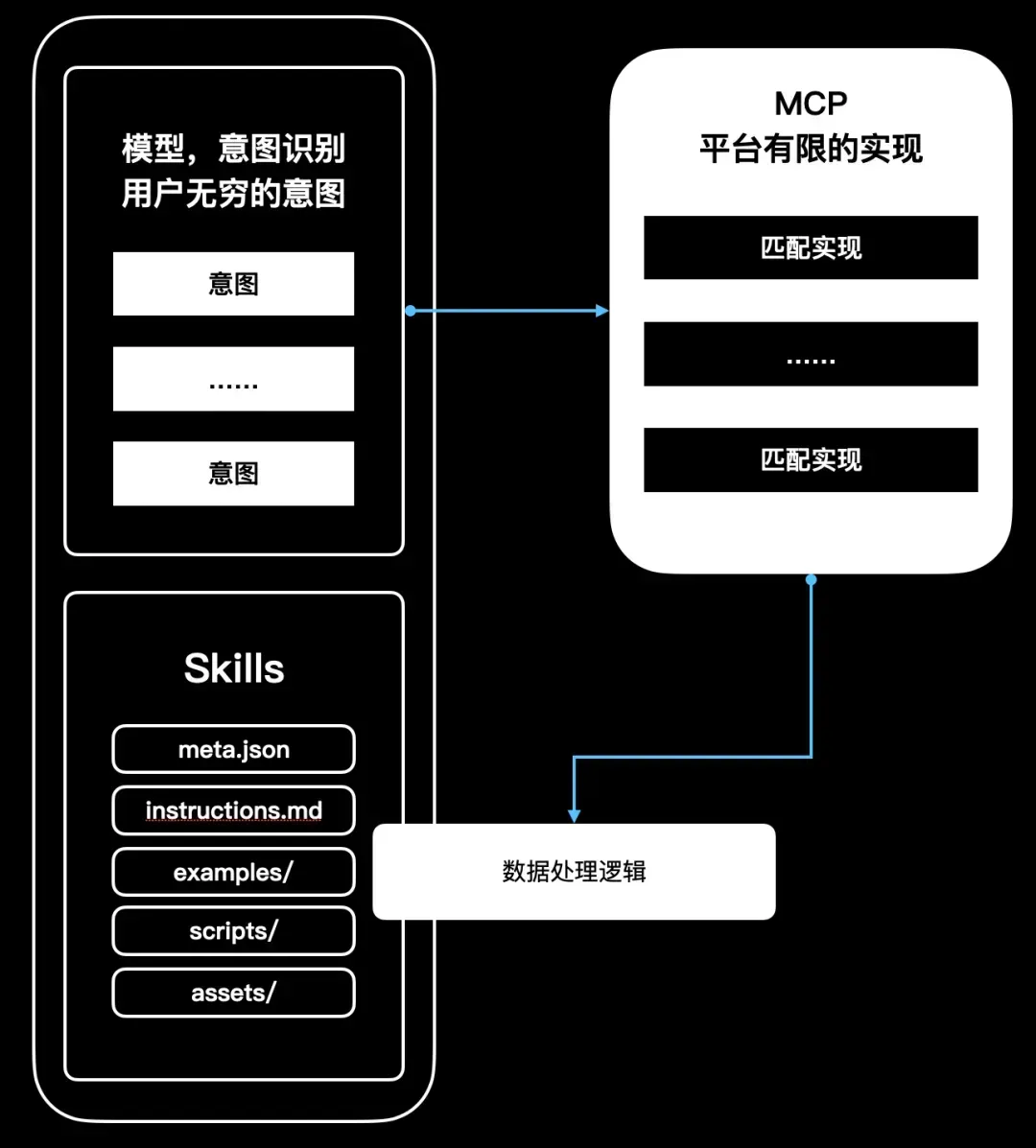
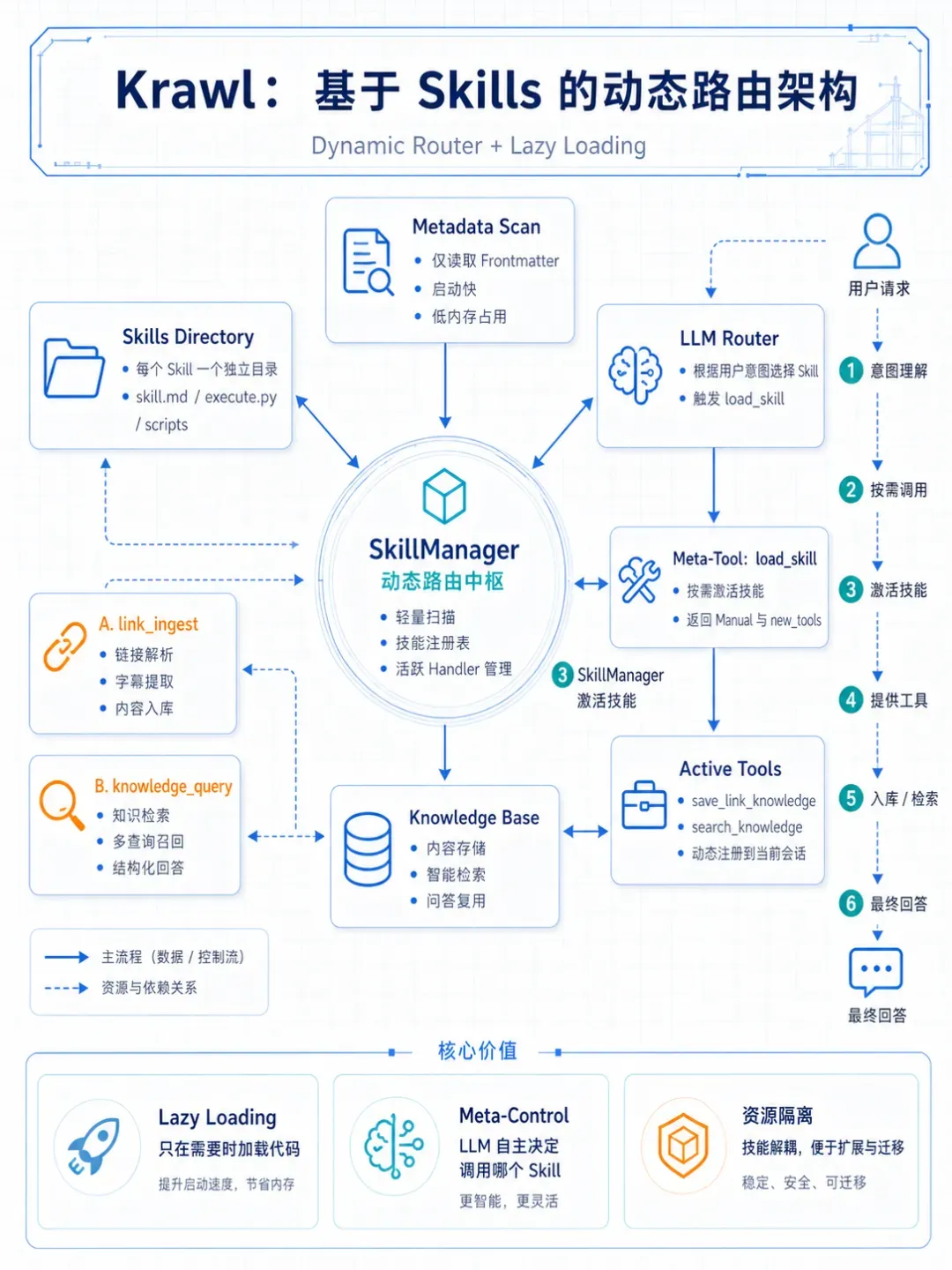
动态路由与懒加载架构
Krawl采用动态路由结合按需加载的混合架构,解决技能数量增长导致的启动延迟与上下文污染问题。核心原则包括:
- 延迟初始化:启动时仅扫描技能元数据(Markdown Frontmatter),不加载Python代码
- 元控制层:提供核心Meta-Tool
load_skill,由LLM自主决策加载策略 - 资源隔离:技能代码在需要时动态注入当前会话
技术架构示意图:

核心代码实现
1. 技能信息容器
@dataclass
class SkillInfo:
"""Skill信息容器 - 核心是lazy load"""
name: str
description: str # 从skill.md的frontmatter读取
is_loaded: bool = False
content: str = ""
tools: List[Dict[str, Any]] = field(default_factory=list)
handlers: Dict[str, ToolHandler] = field(default_factory=dict)
module_path: str = ""
2. 轻量扫描管理器
class SkillManager:
def scan_skills(self) -> None:
"""仅读取目录结构与frontmatter,不加载代码"""
for item in self._skills_dir.iterdir():
if not item.is_dir() or item.name.startswith("_"):
continue
description = self._read_frontmatter_description(item / "skill.md")
self._skills[item.name] = SkillInfo(
name=item.name,
description=description
)
3. 动态激活机制
def activate_skill(self, skill_name: str) -> Tuple[bool, str, List[Dict[str, Any]]]:
"""按需激活Skill"""
skill = self._skills.get(skill_name)
if skill.is_loaded:
return True, skill.content, skill.tools
md_path = self._skills_dir / skill_name / "skill.md"
skill.content = md_path.read_text(encoding="utf-8")
module_name = f"app.skills.{skill_name}.execute"
module = importlib.import_module(module_name)
skill.tools = getattr(module, "TOOLS", [])
skill.handlers = getattr(module, "HANDLERS", {})
skill.is_loaded = True
for name, handler in skill.handlers.items():
self._active_handlers[name] = handler
return True, skill.content, skill.tools
4. 元工具实现
async def _handle_load_skill(self, args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
"""Meta-Tool: 允许LLM自主加载能力"""
skill_name = args.get("skill_name")
success, content, tools = self.activate_skill(skill_name)
if success:
tool_names = [t["name"] for t in tools]
return {
"ok": True,
"message": f"Skill '{skill_name}' loaded.",
"manual": content,
"new_tools": tool_names
}
return {"ok": False, "error": content}
完整流程拆解
以"保存抖音视频"为例,展示系统交互全流程:
场景:用户输入"帮我保存这个视频 https://v.douyin.com/xxxxx"
1. 系统冷启动阶段
SkillManager扫描skills目录,仅读取技能元数据,内存占用极低,系统知晓link_ingest技能存在但未加载其代码。
2. 意图识别阶段
LLM接收用户消息,系统提示词包含可用技能清单。LLM判断意图匹配link_ingest,决策调用Meta-Tool: load_skill(skill_name="link_ingest")
3. 动态加载阶段
系统执行激活操作:
- 读取完整的skill.md作为操作手册
- 动态导入execute.py模块
- 注册save_link_knowledge工具 返回加载成功信息及手册内容
4. 任务执行阶段
LLM阅读手册后发起工具调用:save_link_knowledge(url="https://v.douyin.com/xxxxx")
系统执行Python函数完成下载、提取、入库,返回结构化结果:{"ok": true, "title": "...", "id": 101}
5. 响应生成阶段
LLM基于返回结果组织自然语言回复:“视频已保存!标题是《…》,已归档到视频分类。”
关键Skill实现细节
link_ingest:链接内容提取核心
这是解决初始痛点的核心组件:

Skill脚本需遵循标准协议:
# app/skills/link_ingest/execute.py
TOOLS = [
{
"name": "save_link_knowledge",
"description": "将链接内容保存到知识库...",
"parameters": {
"type": "object",
"properties": {
"url": {"type": "string"},
"category": {"type": "string"}
},
"required": ["url"]
}
}
]
async def save_link_knowledge(args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
url = args.get("url")
# ... 业务逻辑 ...
return {"ok": True, "id": 123}
HANDLERS = {
"save_link_knowledge": save_link_knowledge
}
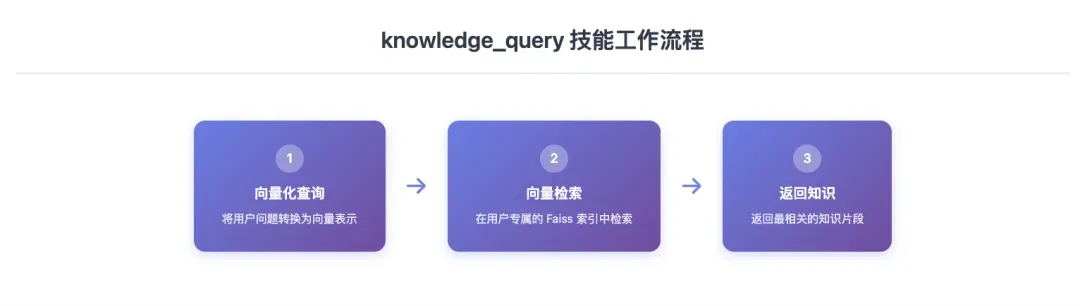
knowledge_query:知识库检索组件
当用户提问时自动触发检索:
TOOLS = [
{
"name": "search_knowledge",
"description": "搜索个人知识库,查找与问题相关的已保存内容...",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"queries": {"type": "array", "items": {"type": "string"}},
"top_k": {"type": "integer", "default": 3}
},
"required": []
}
}
]
async def search_knowledge(args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
return {"ok": True, "content": "content"}
HANDLERS = {
"search_knowledge": search_knowledge,
}
实践方法论总结
基于Krawl项目经验,提炼出Skills模式的最佳实践:
典型适用场景
- 高频重复工作流:固化规律性AI交互流程
- 外部系统集成:需要调用API或工具链
- 复杂任务编排:分解为可复用的子技能
- 能力共享:团队或社区级AI能力复用
实施路径建议
从极简原型开始:避免初期过度设计,先验证最小可行技能。
粒度控制原则:
- 单技能聚焦单一职责
- 防止技能碎片化导致管理困难
- 按业务域划分,每个技能对应完整用户故事
可靠性保障:
- 设计完善的错误处理与降级策略
- 建立技能使用日志用于持续优化
- 实现版本管理与回滚机制
Krawl项目证明,Skills模式能将AI从对话助手升级为可主动调用工具、执行复杂任务的智能体。这种"技能化"架构思想值得在更多AI应用中探索与实践。