如何用家用NAS轻松搭建本地AI助手:基于LocalAI的完整部署与体验指南
想象一下,你的家庭网络附加存储设备不仅用于存放文件与媒体,还能化身为一个在本地运行的智能助手。这一切可以通过一款名为 LocalAI 的开源工具实现。下面将详细介绍如何将其部署在NAS上,并开启私有的AI对话体验。

LocalAI是一款遵循开源协议、完全免费且以本地运行为优先的AI推理框架。它的核心目标在于提供一个与OpenAI API规范高度兼容的本地REST API接口,同时也能适配Elevenlabs、Anthropic等其他服务的协议。该框架支持在消费级硬件上私有化部署大语言模型、图像生成与音频合成等多种AI能力,其突出特点是无需依赖独立GPU也可顺畅运行,并能兼容多种模型架构。
核心特性解析
- API 高度兼容:作为OpenAI API的即插即用式替代方案,任何基于OpenAI API开发的现有应用程序都可以低成本、无缝地迁移至本地环境。
- 彻底的本地化部署:支持在普通的消费级硬件上运行,即使没有独立显卡也能正常工作。所有数据处理均在本地完成,数据无需上传至外部服务器,充分满足用户对隐私保护和数据合规性的严格需求。
- 支持多模态能力:不仅局限于大语言模型的文本推理,其功能范畴还扩展至图像生成、文本转语音等音频合成领域,提供了一个较为全面的本地AI工具箱。
- 丰富的模型生态:内置了“模型画廊”,支持通过命令行或API便捷地安装来自HuggingFace等平台的模型。默认提供了大量采用宽松许可协议的模型库,同时也允许用户添加自定义的模型仓库地址。
- 灵活的后端支持:其底层设计兼容多种由不同语言(如C++、Go、Python)实现的后端引擎,能够灵活适配不同AI模型对运行环境的特定要求。
- 强大的扩展性:可与LocalAGI(用于AI智能体编排)、LocalRecall(知识库系统)、Cogito(LLM工作流程库)等关联工具组合使用,共同构建起一套功能完整的本地人工智能基础设施套件。
安装部署指南
部署过程非常简单,尤其适合通过Docker容器化进行。以下是一个适用于纯CPU环境的基础Docker Compose配置示例:
services:
localai:
image: localai/localai:latest
container_name: localai
ports:
- 8080:8080
volumes:
- ./models:/models
restart: always
将上述配置保存为docker-compose.yml文件,在相同目录下执行docker-compose up -d命令即可启动服务。其中,./models目录将用于持久化存储所有下载的AI模型文件。
实际使用体验
服务启动后,在浏览器中输入 http://你的NAS的IP地址:8080 即可访问LocalAI的Web管理界面。
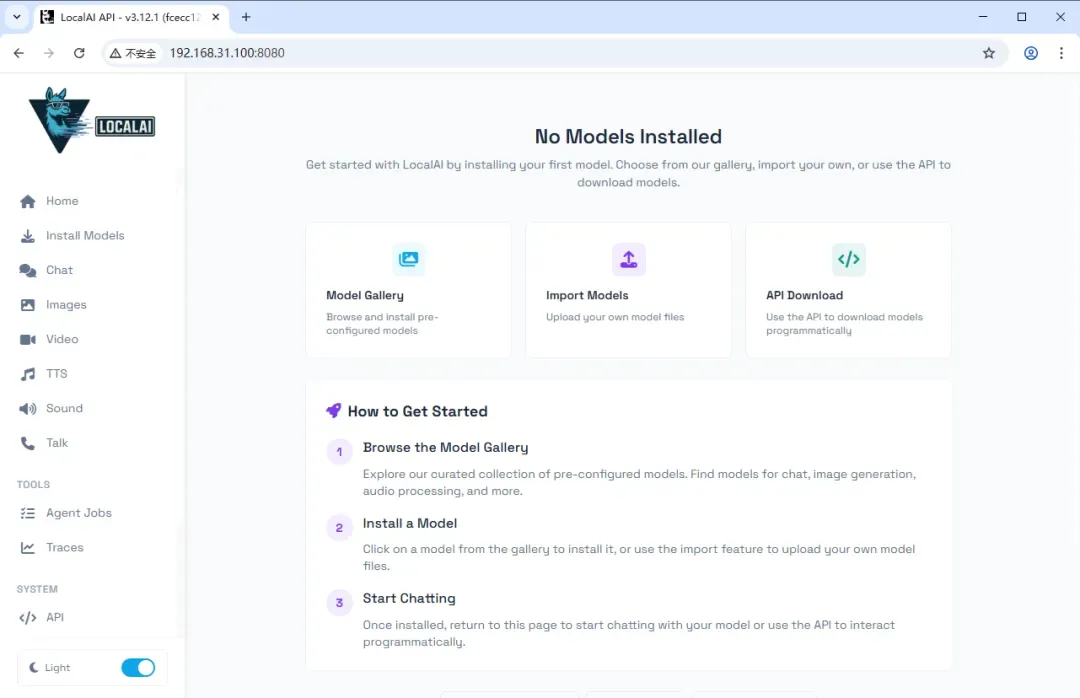
界面提供了清晰的上手引导。基本使用流程分为三步:首先浏览并选择所需的模型,然后将其下载安装到本地,最后即可开始对话或调用其功能。
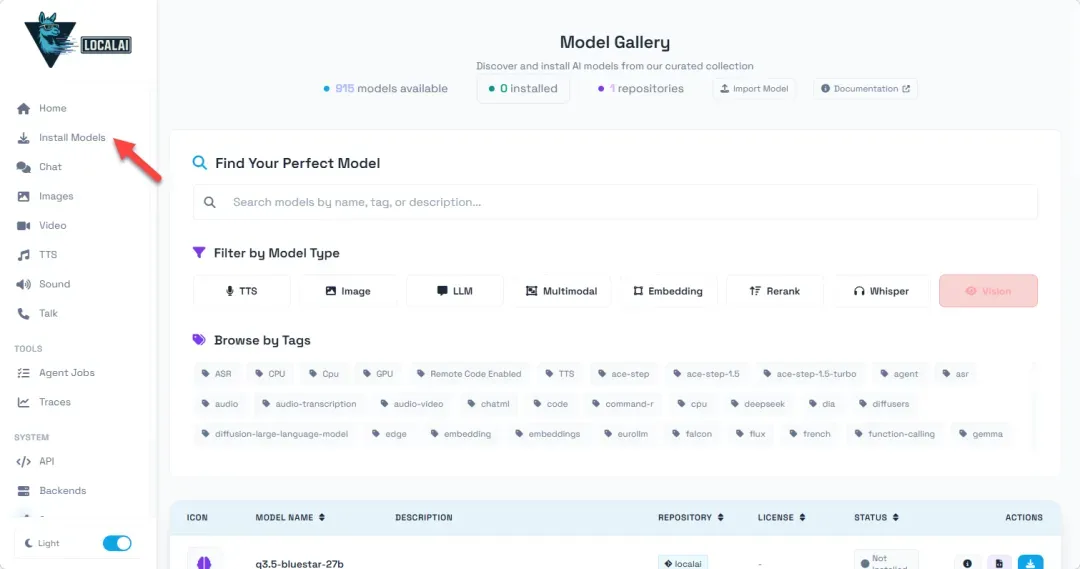
LocalAI的内置模型库提供了相当丰富的选择,涵盖不同参数规模和用途的模型,大部分可以直接在线下载。请注意,下载过程需要相对稳定流畅的网络环境,有时可能会遇到模型列表暂时加载不出的情况,通常等待一段时间或重试即可。
实用提示:系统也支持离线模型。你可以将从其他渠道获取的兼容模型文件(通常是GGUF格式)直接放入之前映射的./models目录中,刷新界面后即可识别并使用。
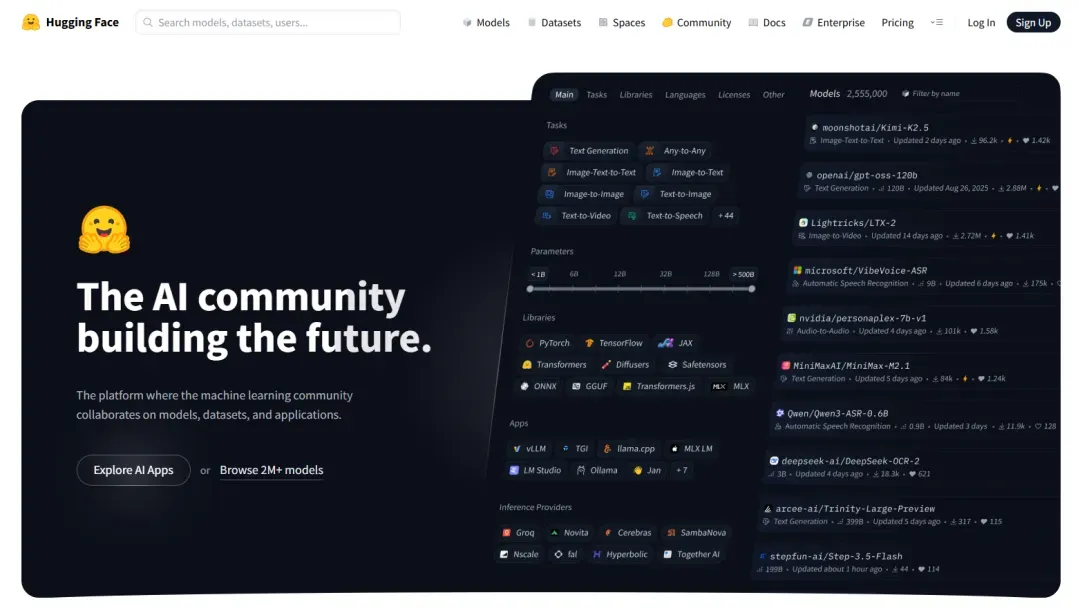
你可以根据需求(如对话、代码生成、创意写作等)筛选模型。对于主要依赖CPU运行的NAS环境,建议优先选择参数量较小、对硬件要求更低的模型。

选中模型后,点击下载安装。由于我们假设在CPU环境下运行,此处示例选择了一个体积较小的模型。
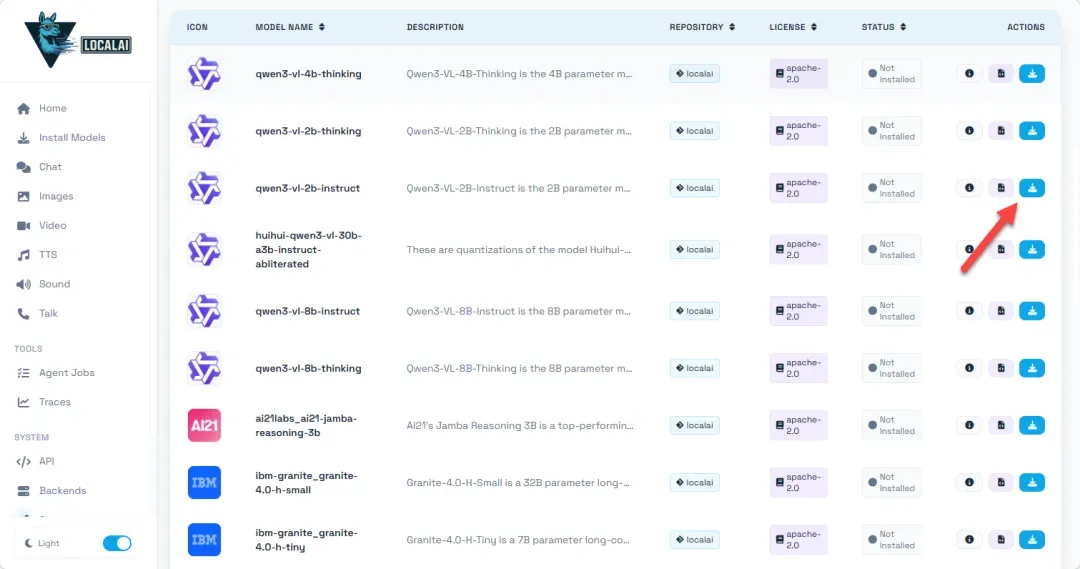
另一个重要提示:模型下载过程有时可能因网络问题而中断或失败,确保NAS设备连接至良好的网络是成功下载的关键。
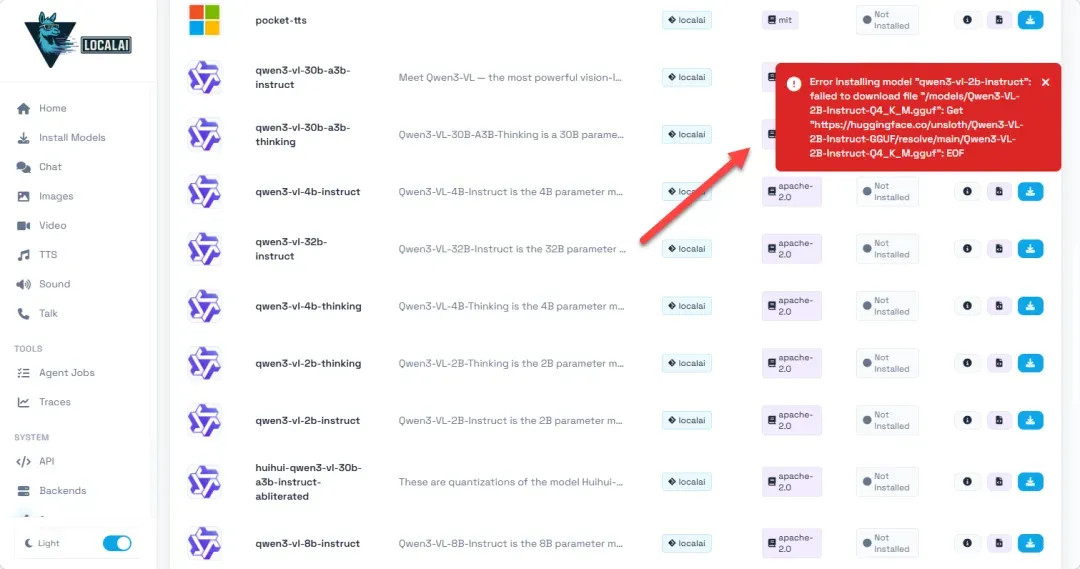
模型安装完成后,便可以进入对话界面开始使用了。
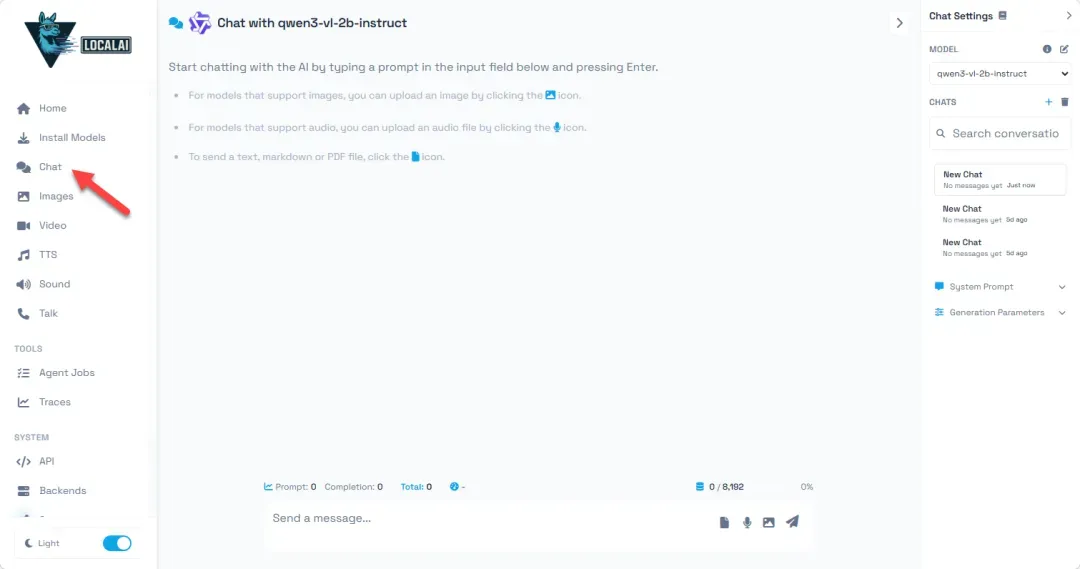
在对话框中输入文字,AI助手便会开始生成回复。在纯CPU环境下,生成速度可能不会太快(例如实测可能只有每秒3-4个token),但对于不追求实时响应的本地化应用而言,这个体验仍然是可以接受的。
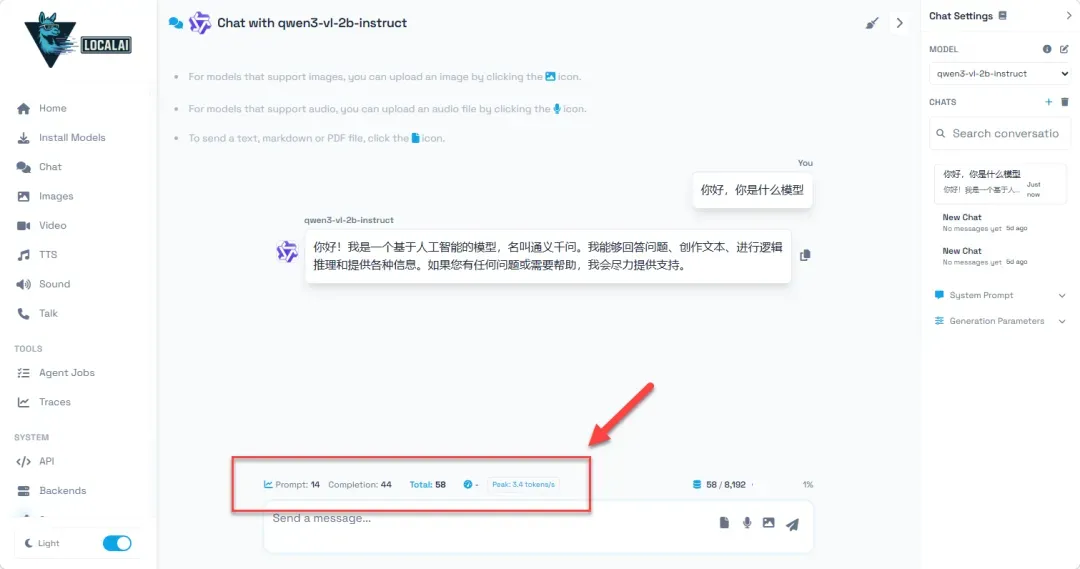
受限于小模型的认知能力,其回答的深度和广度自然无法与云端超大规模模型相媲美。然而,其最大的优势在于完全的本地运行,无需互联网连接,所有交互内容都私密地保留在自家设备中。
在API调用层面,LocalAI完美模拟了OpenAI的接口规范。这意味着你可以将本地服务的地址(http://NAS-IP:8080/v1)直接配置到支持OpenAI API的各种第三方客户端或自行开发的程序中,实现无缝替换。
对于有更高性能要求的用户,LocalAI甚至支持在多台设备上部署形成集群,进行混合推理以加速处理过程。
除了基础的对话功能,LocalAI还集成了图像生成、音频处理等众多功能,有兴趣的用户可以深入探索其完整的潜力。
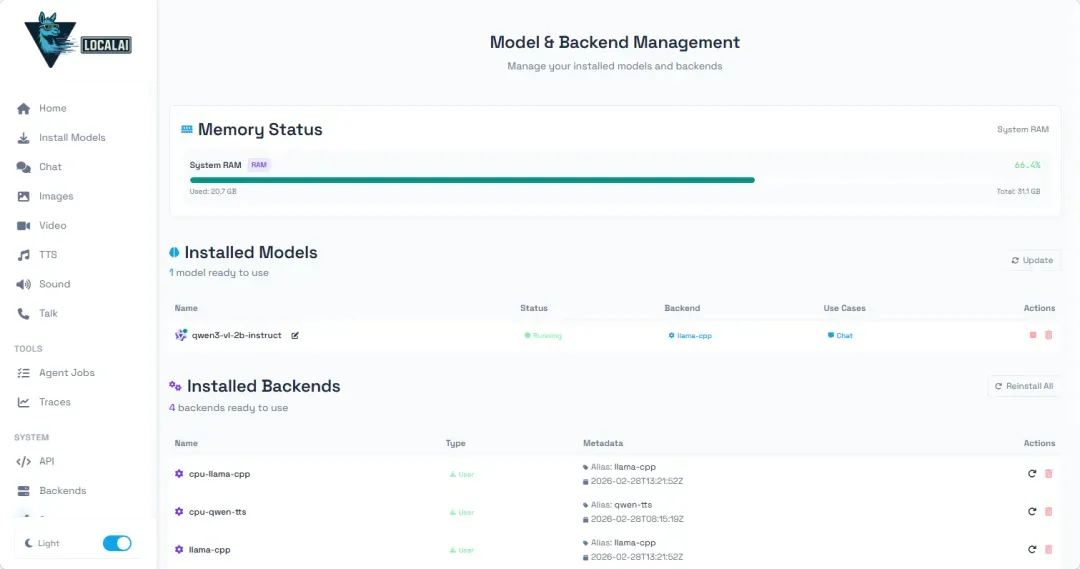
关于资源占用,以一个20亿参数的小模型为例,其在运行时会占用大约3.5GB的内存。在进行文本生成时,CPU的利用率通常会达到接近满载的水平。
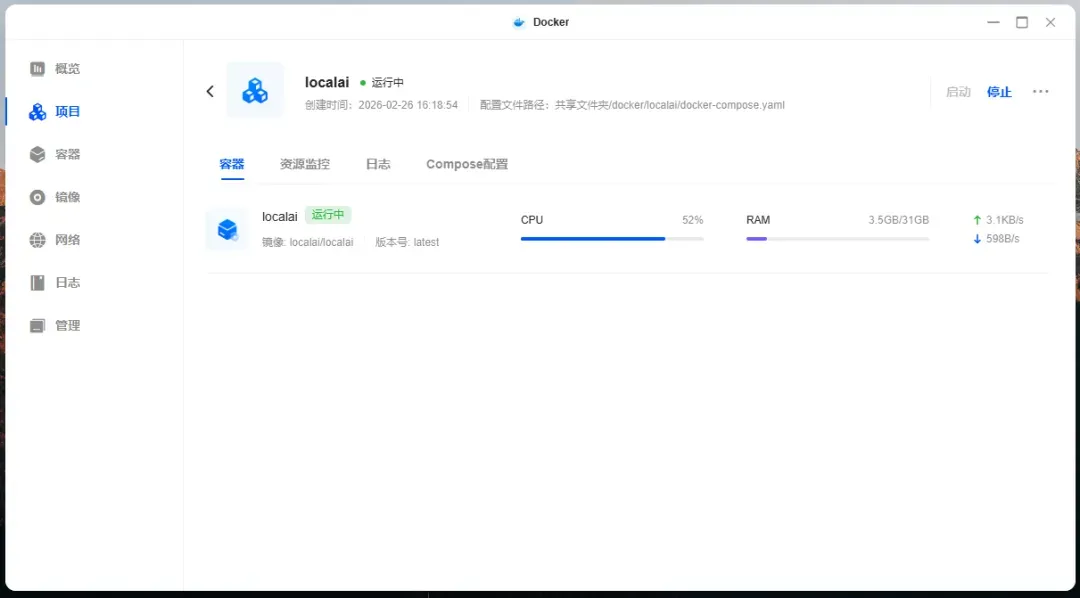
总结与评价
总体而言,LocalAI带来了极其友好的入门体验,其可视化Web界面极大地降低了普通用户在本地部署AI模型的技术门槛。该方案支持完全离线部署,即使在无网络环境中也能提供可用的生成能力;仅依赖CPU即可运行的特性,使其对硬件异常包容;同时,对OpenAI API规范的兼容性让现有生态应用能够轻松迁移。此外,其对GGUF格式模型的良好支持,使用户能便捷地获取和尝试最新的社区模型。
对于希望轻量化体验本地AI推理、注重数据隐私、或苦于没有高性能显卡但仍想尝试大模型功能的NAS用户和开发者来说,LocalAI无疑是一款非常值得投入时间尝试的出色工具。
综合推荐指数:⭐⭐⭐⭐(可视化操作极为友好,接口兼容性极佳) 实际使用体验:⭐⭐⭐(界面直观易上手,功能扩展性良好) 部署难易程度:⭐⭐(过程非常简单)