小米MiMo深度评测:6400万Tokens缘何撑不起一个武侠百科?
MiMo 的 16 亿 Tokens 额度即将耗尽,我赶紧追加了一波测试。结果……彻底垮掉。虎头蛇尾,金玉其外,败絮其中。
先上一张图,各位感受一下:
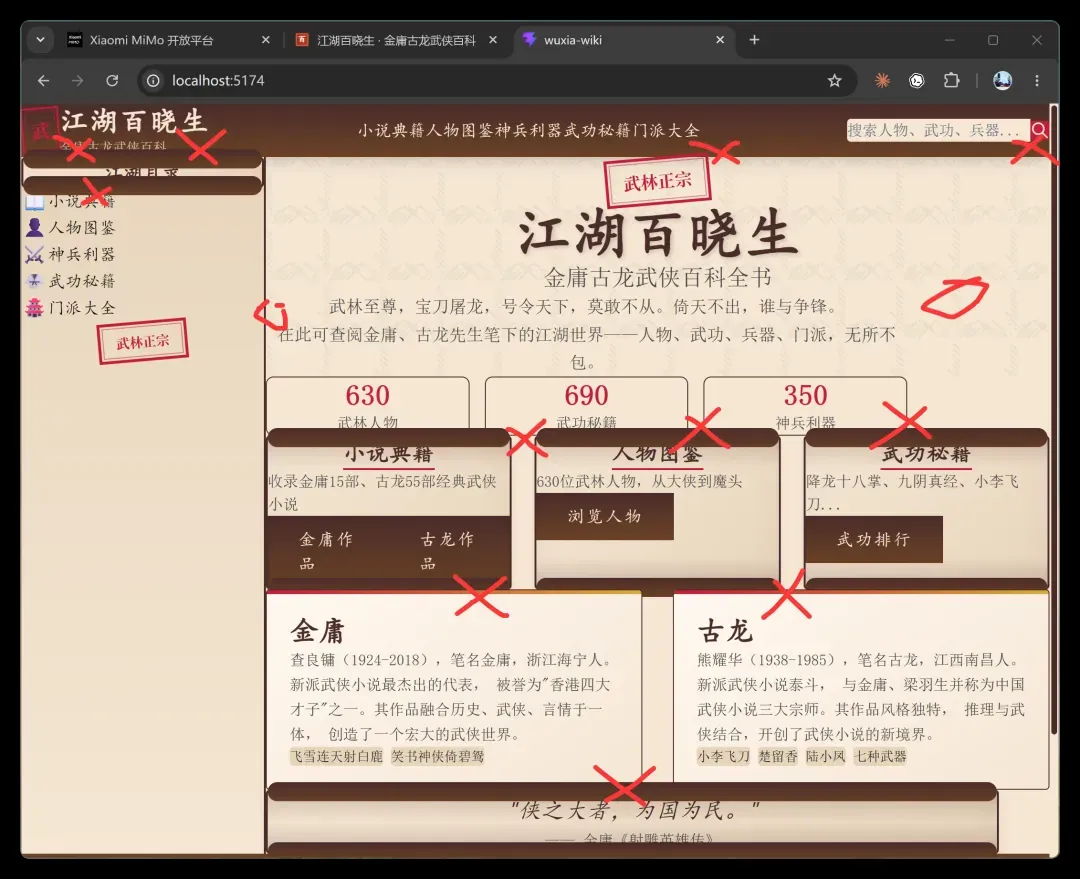
就这个网页,吃掉了 16 亿 Tokens 额度的 4%,约合 6400 万!
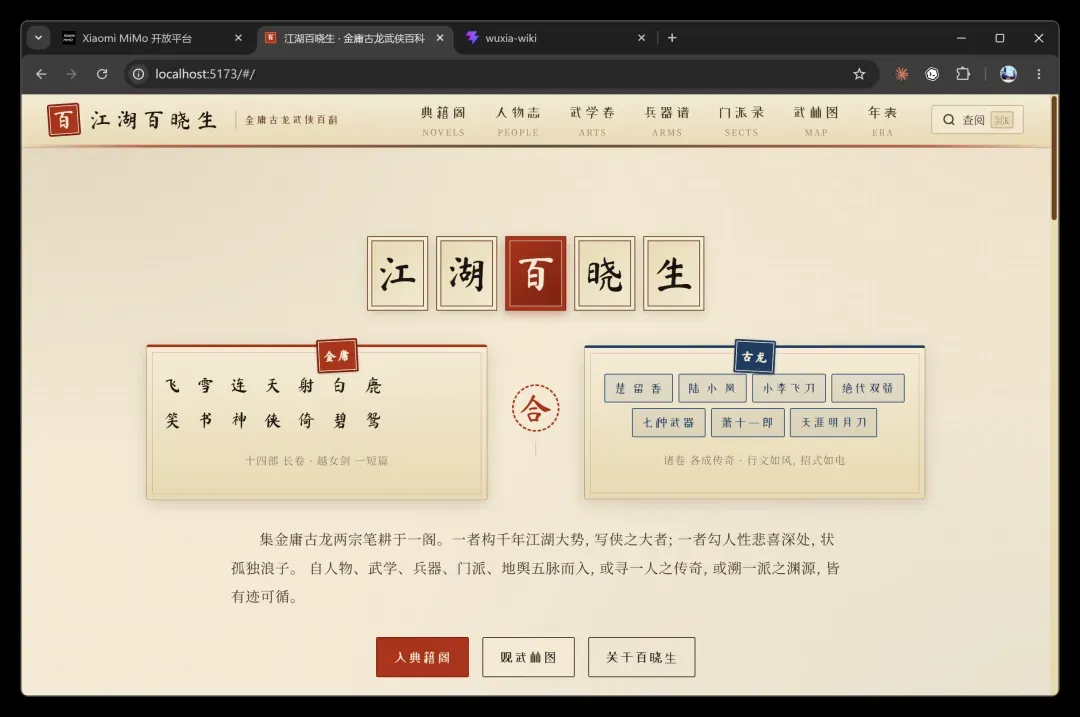
同一道题,Opus4.7 和 Gemini3.5 的表现完全碾压它!
Opus4.7 做出的效果:
Gemini3.5 做出的效果:
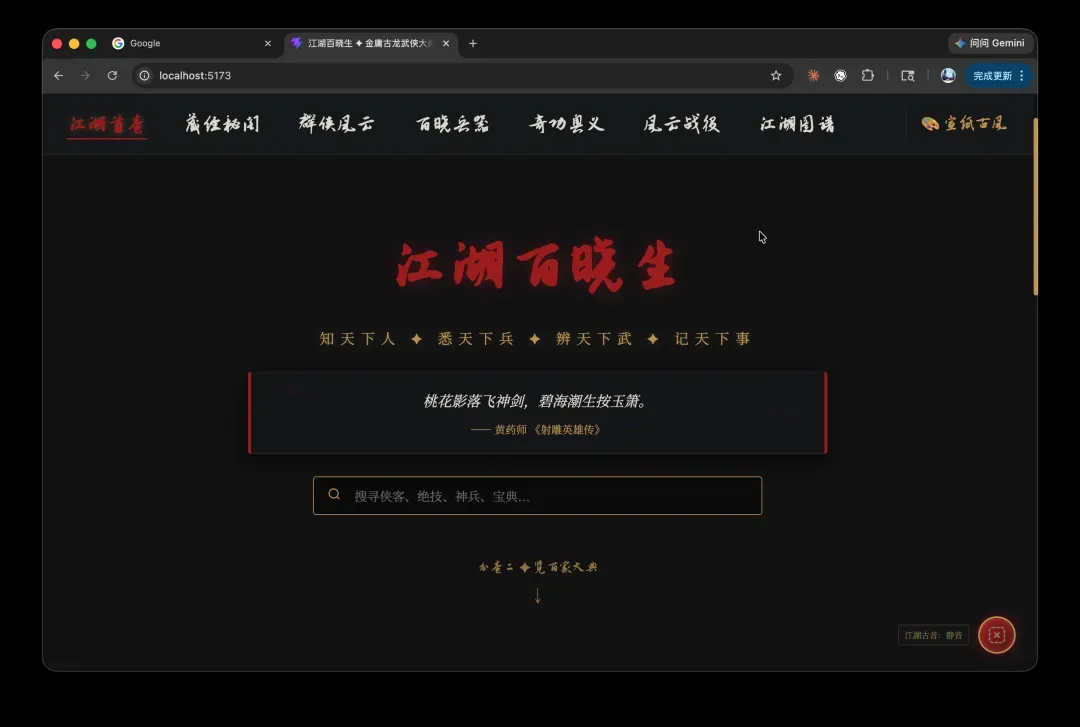
界面展示完了,我们来深挖一下细节。
这是 AI 实战开发测试《江湖百晓生》的第二篇!
核心需求是:构建一个以金庸、古龙武侠世界为主题的百科,要囊括主要人物、兵器、武功等核心要素。
下面我将完整还原开发工具、开发过程,带你沉浸式感受 MiMo 在真实场景中的能耐。
工具环节
现在我基本不用 CCSwitch 了,一切交给自己的 JCode + Claude Code!
配置好后,打开 JCode,双击图标即可呼出 CC:

你无需在终端里敲 Claude,也不用 cd 进特定目录,更不必手动设置环境变量或修改配置文件。
只需通过软件的添加功能:
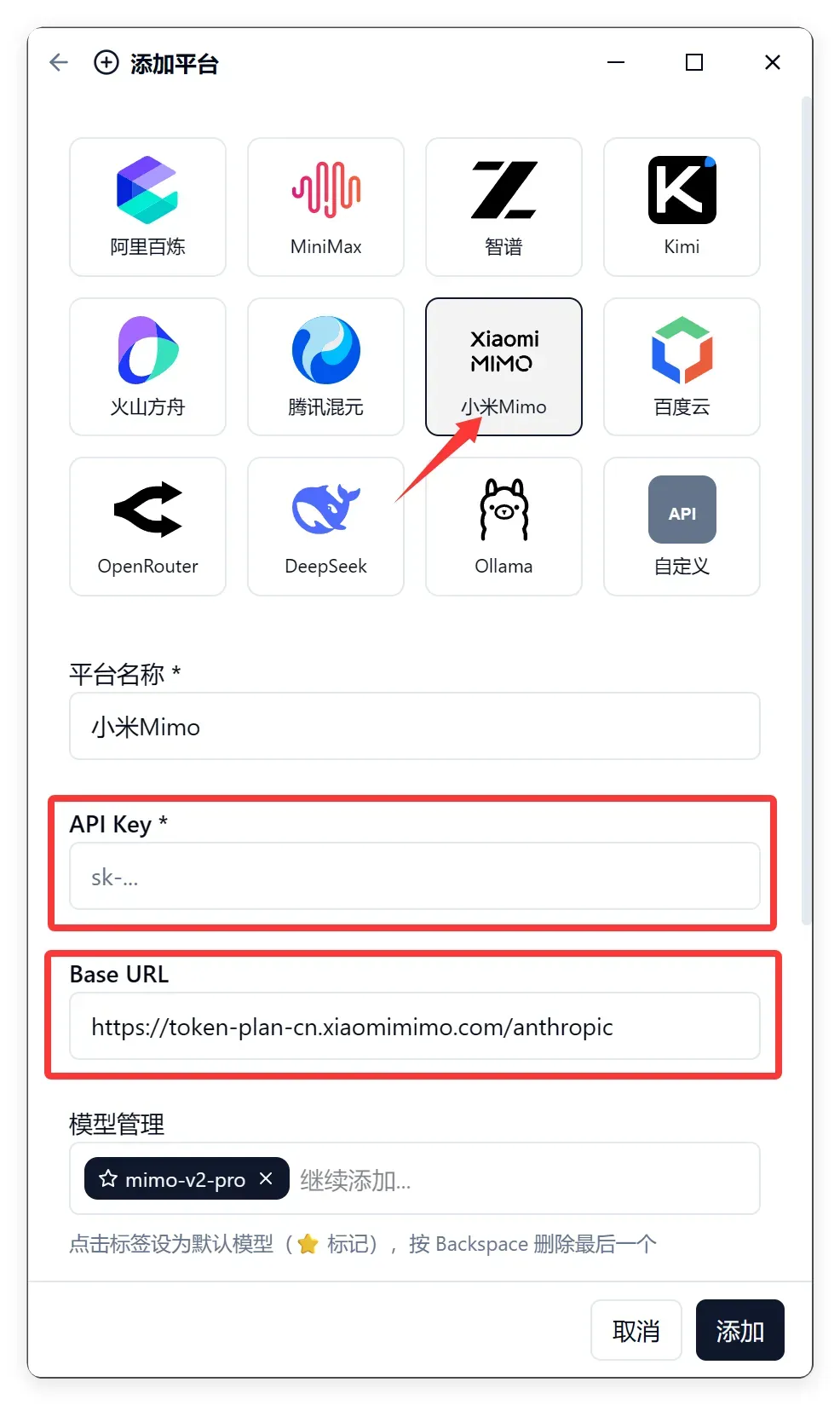
填入 API key 和正确的 Base URL,万事大吉!
小米的 base URL 其实已经内置。不过,默认接入点和 Token Plan 的接入点不同。所以如果用 Token Plan 套餐,就必须像截图中那样调整;若按用量计费的普通 API,则无需改动。
配置完成后,后续无需再费心。
双击图标启动,选择一个文件夹,直接开干!
实战过程
为 MiMo 单独开辟一个测试文件夹。
然后通过 JCode 快速唤起 CC,此时就能在 CC 里调用 MiMo 的 Token Plan。
接下来,只需把需求告诉它。这个需求与测试 Gemini3.5 Flash 时的完全一致。
核心需求描述:
“我想做一个‘江湖百晓生’网站,聚焦金庸、古龙的武侠小说。首先要定位所有小说,然后整理其中的人物、兵器、场景、武功招式。可以依靠你的知识,也可以上网收集资料,所有内容必须存档。最后,打造一个武侠风格的网页,用极具特色的方式组织呈现这些内容!这是一个庞大的工程,请做好计划,需要运行很久。务必保证数据的准确性,不要偷懒!”
把这段话粘贴进去,回车,模型就开始行动了:
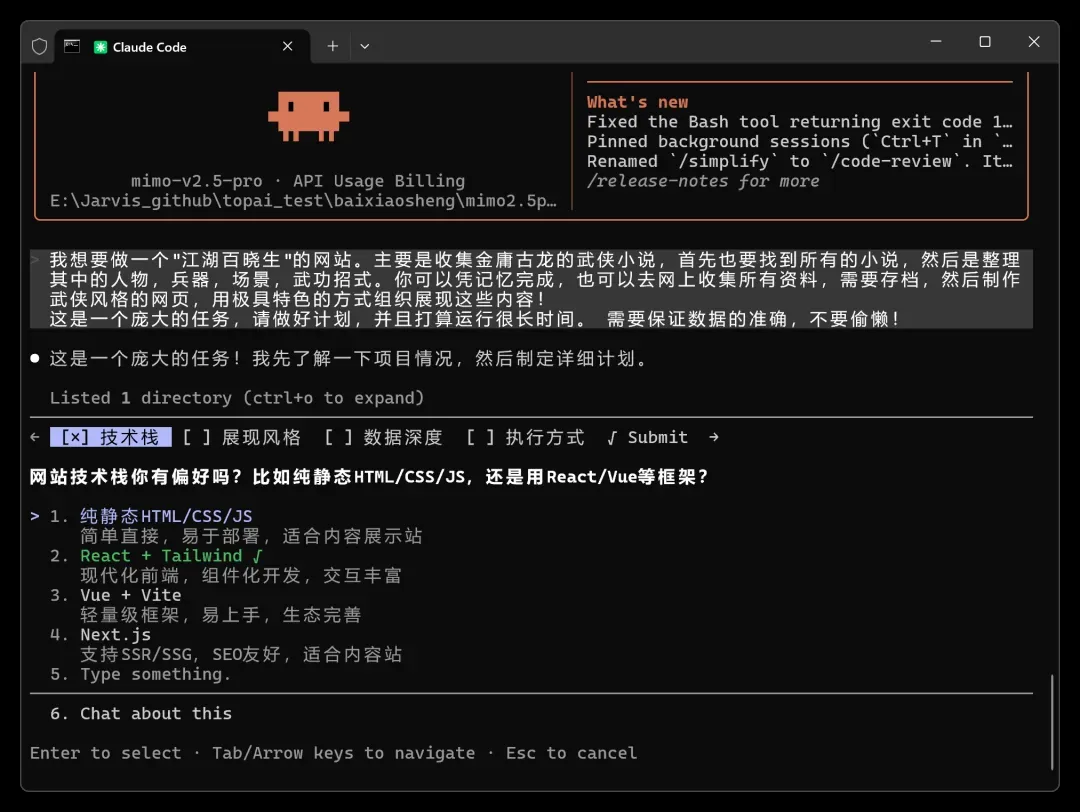
小米 MiMo 一上来气势很足。
它先说了一句:“这是一个庞大的任务,我先了解情况,然后制定详细计划。”
紧接着便开始让我选技术方案。
首推 HTML/CSS/JS 路线,因为我测 Gemini 时选了 React,所以这次也选这个。
它给出了四种方案,相当全面,基本覆盖了常见选项。
然后进入下一步:
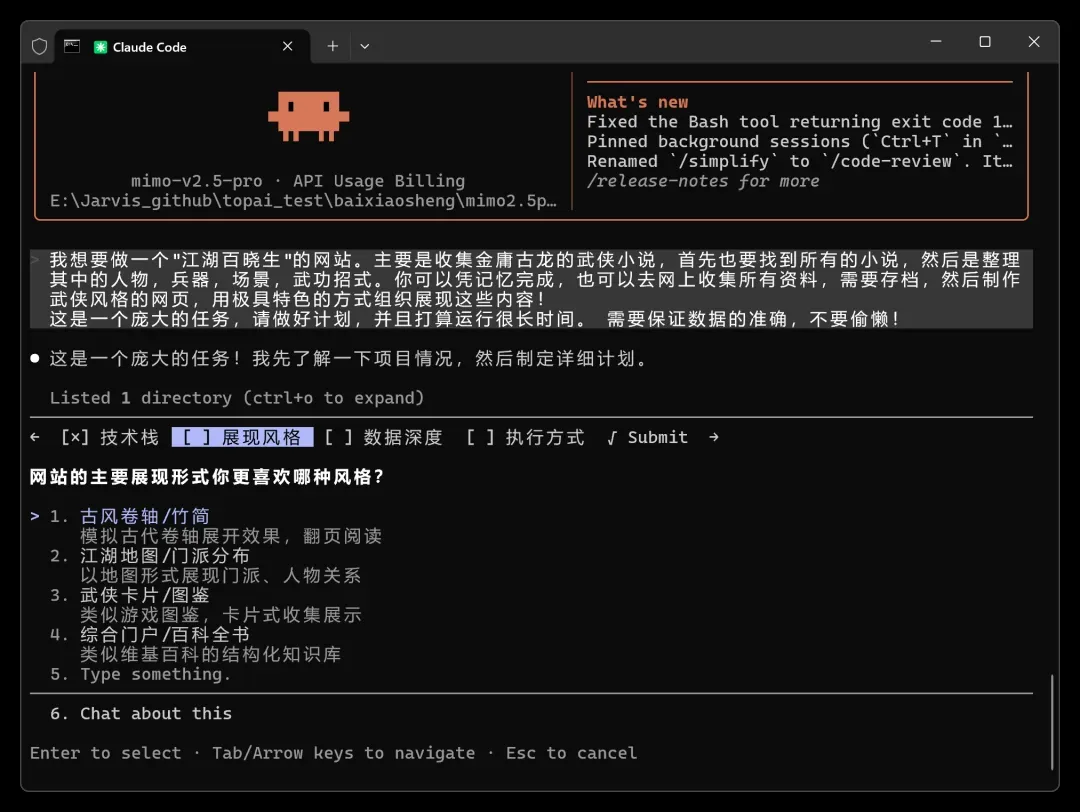
第二步是视觉风格,选项让人眼前一亮:
1. 古风卷轴/竹简
模拟古代卷轴展开效果,翻页阅读
2. 江湖地图门派分布
以地图形式展现门派、人物关系
3. 武侠卡片/图鉴
类似游戏图鉴,卡片式收集展示
4. 综合门户/百科全书
类似维基百科的结构化知识库
这些选项远超预期,甚至让我选择困难。那就按默认的“古风卷轴”来。
继续往下:
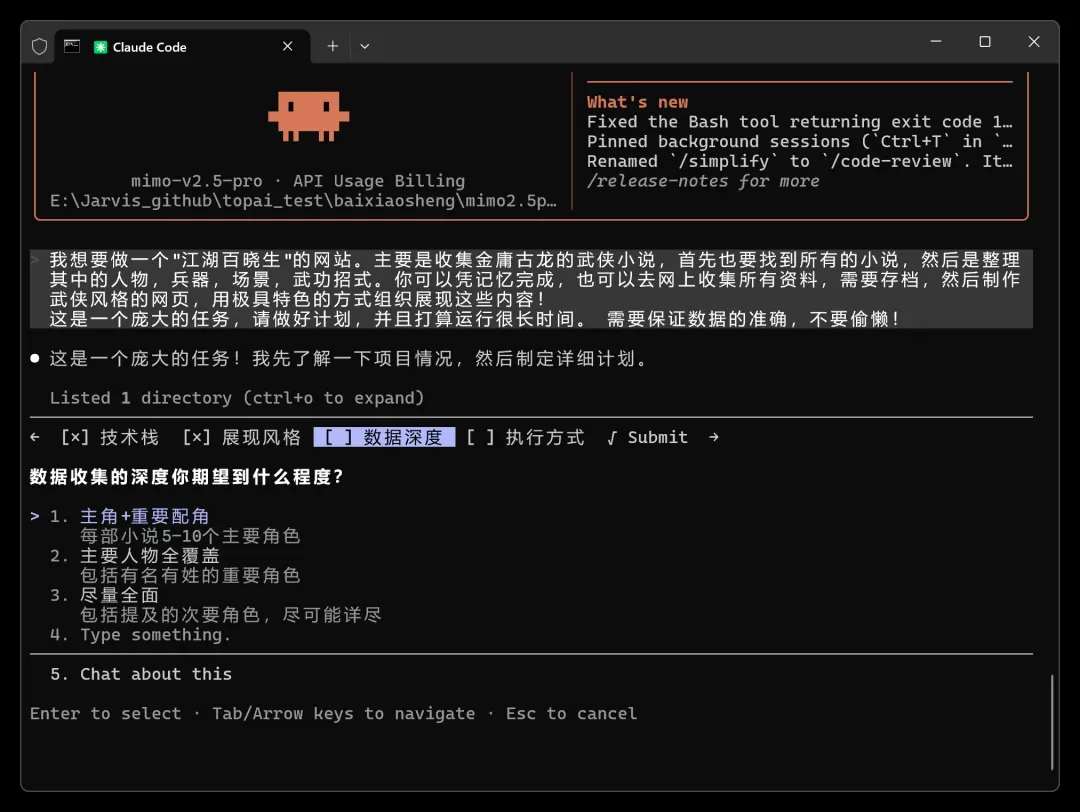
这一步是数据深度。
它提供了 3 个等级。我希望数据越丰富越好——我本来就要消耗 Tokens 嘛。
于是我选了“3. 尽量全面”!
再往下走:
这一步是执行方式。可以选择先审计划、直接开工,或分阶段进行。
我自然选先看计划!
全部选定后,就进入了计划阶段。
我看了下具体规划:
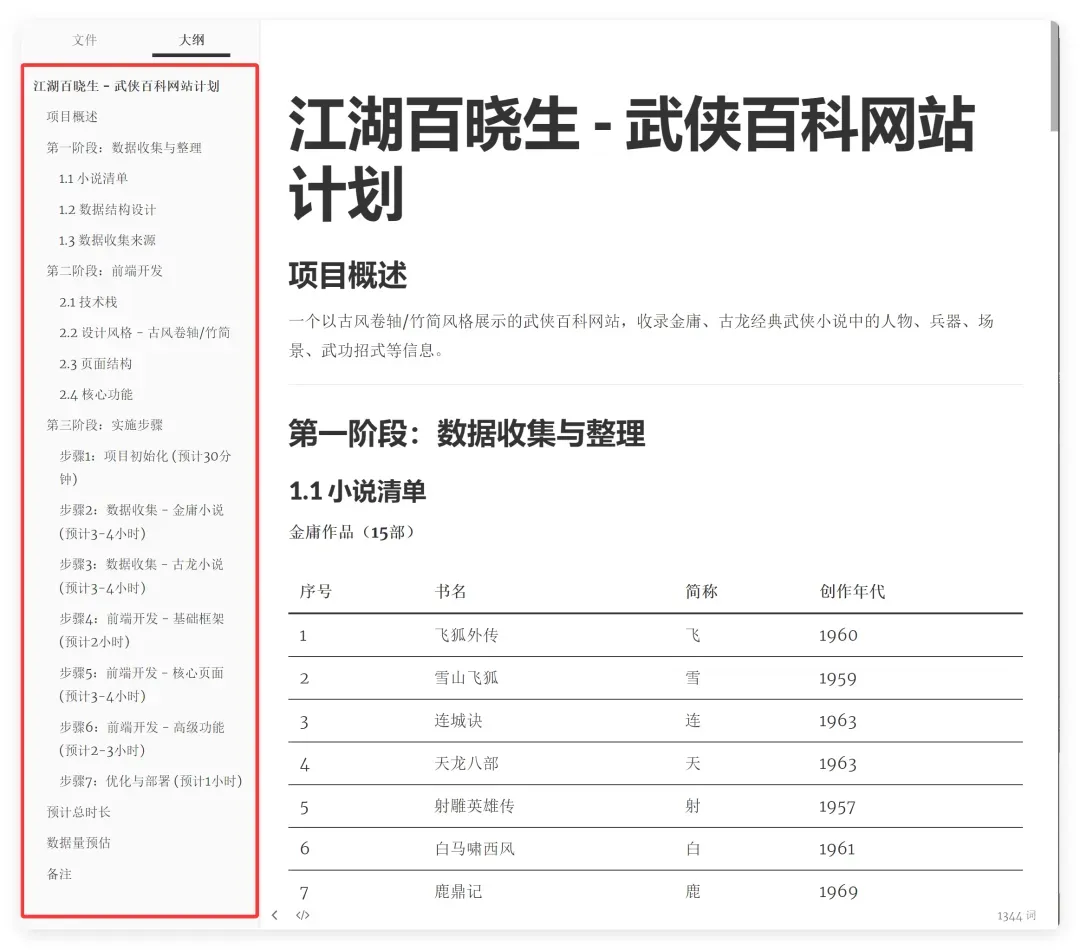
计划做得挺细致,很有章法!
既然这么详尽,我就不指手画脚了,直接让它照计划执行!
到这一步,感觉还挺像样子。这个 Ask 和 Plan 阶段确实显得很专业!
然而……一通操作猛如虎,最终出来的是:
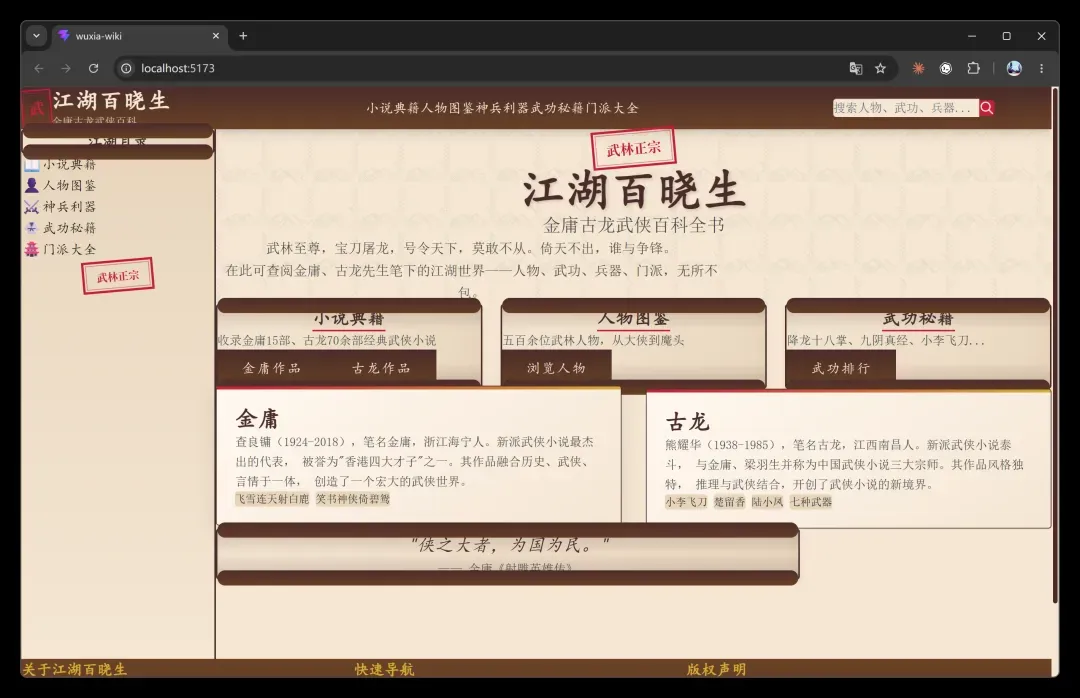
只生成了这么一个页面,布局完全崩塌——内外边距、间距、定位,全乱了。
判断一个模型的前端能力和逻辑思考力,首先看的就是布局和构思。只要布局清晰,通常说明业务逻辑理清了,前端技术也到位了。
这个页面一出来,就基本没了脾气。这种布局一旦出现,想让模型自己调好,难上加难,因为它缺少空间感知能力。
再看看数据部分:
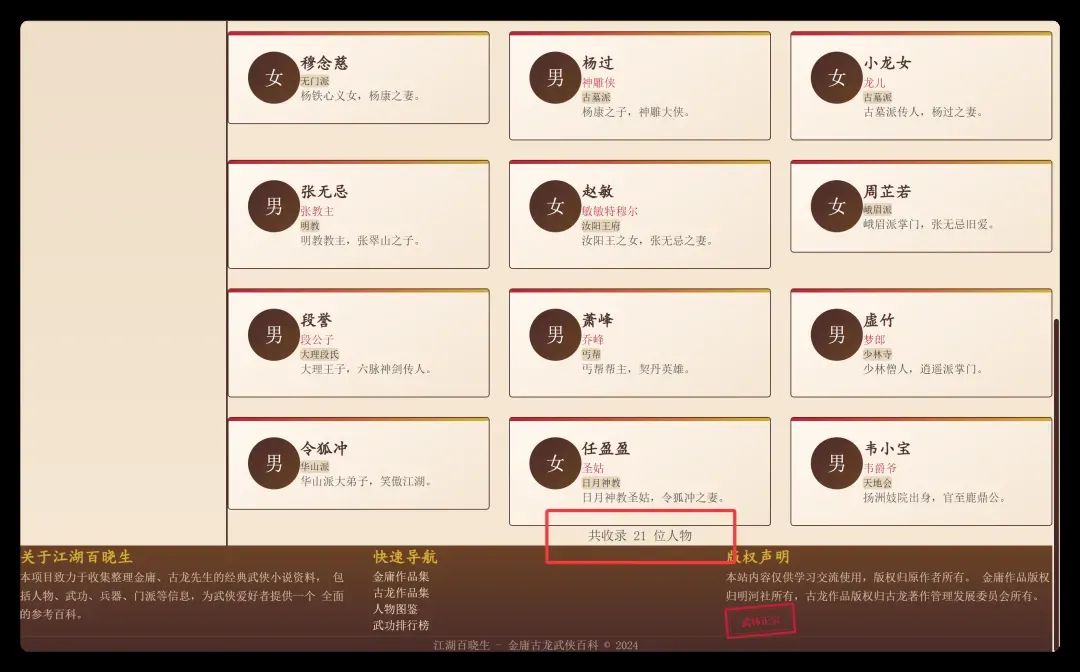
我要求“尽量全面”,结果它收录了多少呢?
21 个人物、23 部小说、10 件兵器、13 门功夫、10 个门派。
这……光一部小说也不止这些元素啊。
很明显,它在采集数据时严重偷懒了。
“AI 的偷懒度”其实是项重要的隐性指标。
Claude 和 OpenAI 每次发布新模型,都会强调模型能独立连续运行几十个小时。他们要突出的不是时间长,而是模型拥有长时间自主持续工作的能力。
因为复杂问题,天然需要消耗时间。
现在它们都推出了 /goal 命令,可以设定一个可验证的目标,让模型自己反复循环,直至达成。
MiMo 给我的感觉是,计划做得光鲜,执行却大打折扣,而且偷懒痕迹很明显。
Gemini3.5 Flash 在做这个任务时,数据采集也有偷懒。
可它前端水准超群,简直秀到飞起! 基本业务逻辑也梳理得清清楚楚。
MiMo 刚亮相时,我用过好几个示例去测,当时并没发现大问题,表现似乎也可圈可点。
大概率那些示例已经被针对性优化训练过了。
最近测的两个案例,表现却非常差劲。
一个是《掌门日记》,一个是《江湖百晓生》。
可以说,这两个任务就是为它量身打造的!
第一个是用来对比它与 DeepSeek 的差距,结果页面出错,直接被碾压。
第二个,也就是今天这个,本是为了消耗它那 16 亿 Tokens 额度的。最终 Tokens 确实烧了不少,但效果极不理想。
在我第二次要求后,它总算补全了大量数据。前后总计消耗了 16 亿额度的 4%!
可页面问题,依旧很难解决。
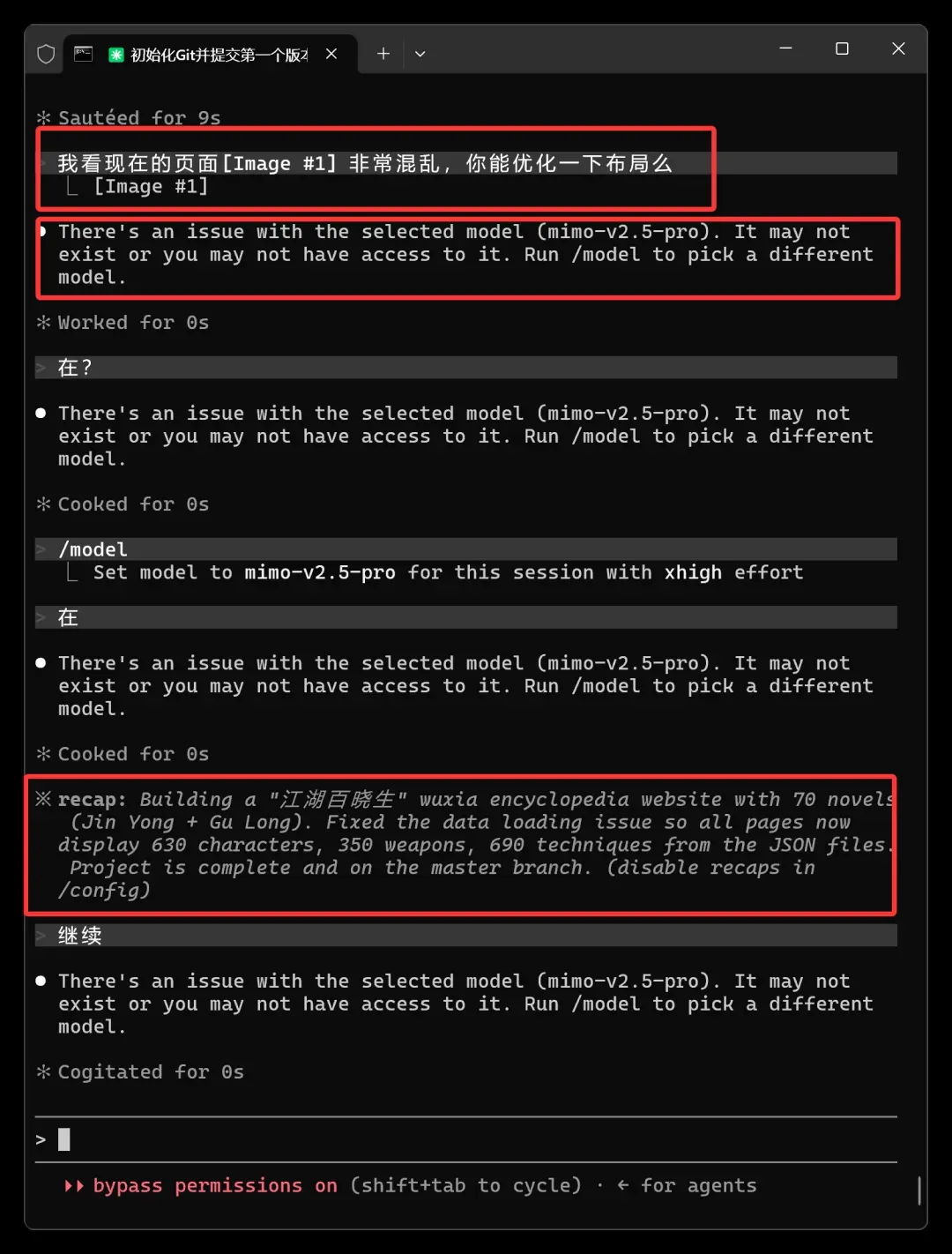
本来还想让它再调整一下,可不知为何,突然提示模型不存在了!之前几轮对话明明都好好的。这个修改需求一提出,竟直接报模型不存在。
我开了一个全新对话,用完全相同的配置,又一切正常。同一个对话的 Recap 也毫无异样。 或许是又撞上了什么 Bug,罢了,不改了!
实话实说,如果第一个版本就没法入眼,我也不想再改了,修修补补的意义不大。
所以我的感受是,小米这个“新秀大模型”,底蕴还是浅了些,只做了一些表面文章。在某些特定领域优化到了中等水平,但覆盖面极不均衡,轻易就会触到天花板。因此,这款模型不适合深度使用,只能做些通用、基础的工作。
同一个问题我测过不少模型,大家不妨自行对比感受!