LiteParse 开源本地PDF解析:轻量高效,为Agent量身打造的文档解析工具
把一份 PDF 丢给智能体去读,听起来只是个小需求。
但真正动手实现时,往往会在两处卡住:要么依赖云端解析服务,文档必须传出去;要么自己用 PyMuPDF、pdfplumber 和 OCR 搭一套流程,虽然跑得通,后续维护却相当琐碎。
LlamaIndex 团队最近开源了 LiteParse,它的定位正正好好落在中间地带。

它并不是 LlamaParse 的本地替代品。
更准确地说,LiteParse 是一款本地优先、速度优先、尽量压低依赖负担的文档解析工具。它适合轻量级的 PDF 解析场景,也适合为智能体准备可读的文本、坐标信息和页面截图。

不过对于复杂文档,暂时不要急着直接投入生产环境。
换句话说,这个项目维护非常活跃,但不同语言绑定的发布节奏并没有完全对齐。
它解决的并非“最强解析”,而是“本地够用”
LiteParse 的 README 表述得相当克制:这是一个独立运行的开源 PDF 解析工具,核心特点是快且轻。

它没有把自己包装成万能的文档理解系统,也没有内置专属的大模型能力。解析过程默认完全在本地执行,核心通过 Rust 编写,底层借助 PDFium 完成 PDF 渲染与文字提取,再配合 Tesseract 或外部 OCR 服务来补充处理扫描件和图片中的文字。
输出形式也非常实用:既可以拿纯文本,也可以拿 JSON。JSON 中包含文本块和边界框,智能体如果需要知道某段文字在页面上大致的位置,就不必只凭一串纯文字去猜测。
LiteParse 还内建了截图能力。
这一点对智能体阅读文档来说很关键。许多 PDF 中的有效信息并不只存在于文字当中,它可能是一张流程图、一个表格截图、页眉中的编号,或者某一块排版上暗示的意义。LiteParse 可以生成页面的 PNG 图片,让智能体在“读文字”之外,还能看到页面本身。
能在哪些环境里使用
LiteParse 目前提供 Rust、Node.js/TypeScript、Python 以及浏览器端 WASM 绑定,统一的 CLI 名称叫作 lit。
安装方式也相当直接:
pip install liteparse
npm i @llamaindex/liteparse
cargo install liteparse
安装之后,最常用的操作就是解析 PDF:
lit parse document.pdf
lit parse document.pdf --format json -o output.json
lit parse document.pdf --target-pages "1-5,10,15-20"
lit parse document.pdf --no-ocr
也支持批量处理:
lit batch-parse ./input-directory ./output-directory
如果只想为智能体准备页面截图,可以这样做:
lit screenshot document.pdf -o ./screenshots
lit screenshot document.pdf --target-pages "1,3,5" --dpi 300 -o ./screenshots
默认参数中有几个细节值得留意:解析最多处理 1000 页,截图和渲染的默认值为 150 DPI,OCR 默认开启,语言默认采用 Tesseract 的 eng。如果需要中文 OCR,就要准备相应的语言数据或者接入外部 OCR 服务。

README 里还给出了作为智能体技能使用的示例:
npx skills add run-llama/llamaparse-agent-skills --skill liteparse
这正是它适合智能体场景的地方。它不只是一条在命令行中由人去敲的指令,而是从文档、CLI、技能到 JSON 输出,都在向着智能体的工具链靠近。
OCR 这部分做得相当开放
LiteParse 默认内建了 Tesseract,开箱即用。
但它并没有把 OCR 能力完全绑定在 Tesseract 上。你可以通过 --ocr-server-url 接入一个 HTTP OCR 服务,README 中已经给出了 EasyOCR、PaddleOCR 的封装方案,也给出了一个很简单的接口约定:POST /ocr,上传文件并携带语言参数,返回文本、边界框和置信度。
这对工程项目来说非常友好。
如果只是解析英文 PDF,内建的 Tesseract 足够省事;而如果你的文档包含中文、票据、屏幕截图或低清晰度的扫描件,就可以单独把 OCR 部分替换成自己更信任的服务。
此外,LiteParse 还支持先将 Office 文档和图片转换为 PDF 再解析。Office 文档依赖 LibreOffice,图片转 PDF 则依赖 ImageMagick。它能够处理的格式不少,比如 .docx、.pptx、.xlsx、.csv、.png、.tiff。
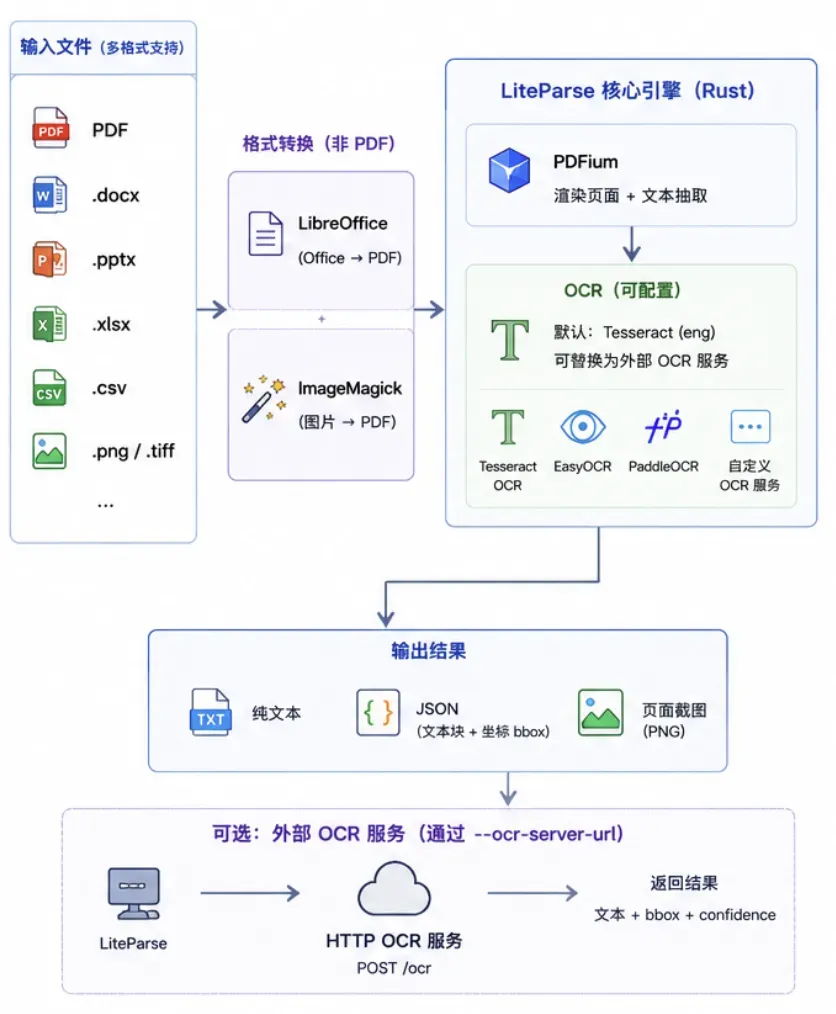
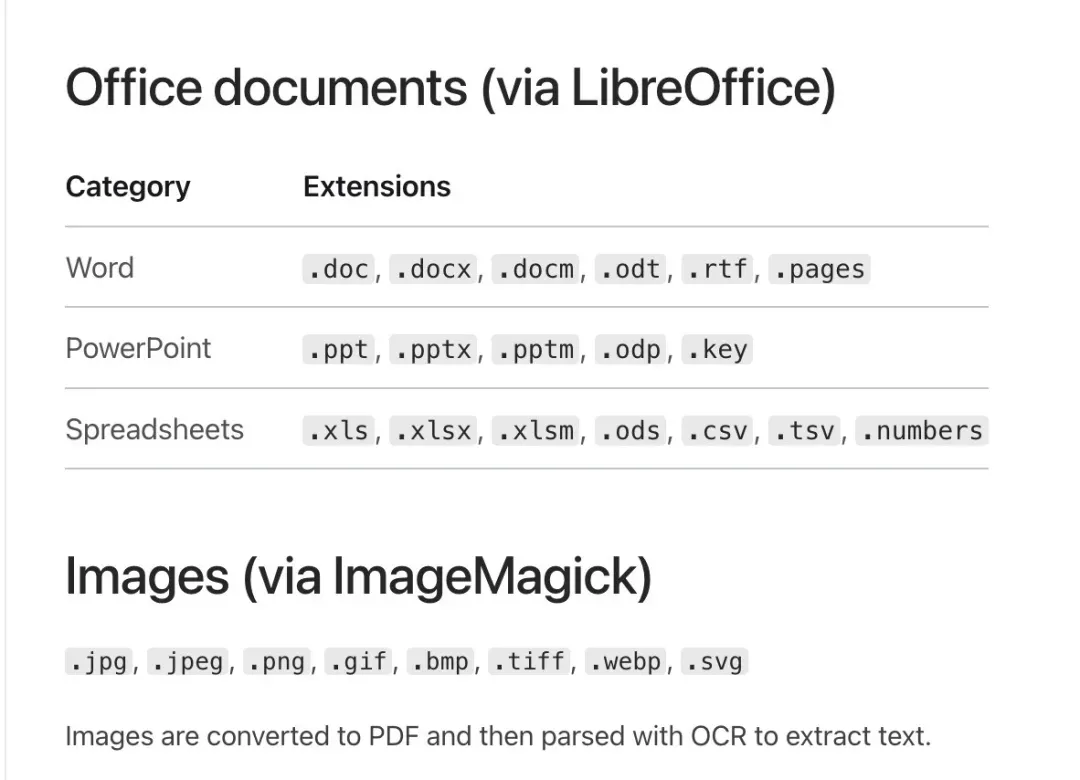
不过这里不要产生误解。
这套多格式支持,走的是“先转换,再解析 PDF”的路线。转换的质量、字体、版式和系统环境都会影响最终结果。如果要在生产环境中稳定处理各类 Office 文件,这一步一定要单独做好压力测试。
为什么不建议直接替换生产链路
有文章把 LiteParse 写成“开源平替 LlamaParse,本地文档解析神器”,这是不太负责任的。
LiteParse 的 README 自己并没有这样说。
它明确提醒:如果遇到密集表格、多栏版面、图表、手写文字、扫描 PDF 这类复杂文档,本地解析会遇到局限,而 LlamaParse 这类云端生产级解析器会更合适。
这并不是客套话。
PDF 解析真正困难的地方,从来都不只是把页面上的字抠出来,而是将版面关系还原成模型能够稳定理解的结构。跨页表格、双栏论文、嵌套图表、页脚注释、扫描件歪斜、低分辨率的图片,这些场景会让“有文字输出”与“能够支撑业务决策的结构化结果”之间产生很大距离。
再看看 Issues,也能看到 LiteParse 还处在快速打磨的阶段。其中有几个问题很能体现当前成熟度:
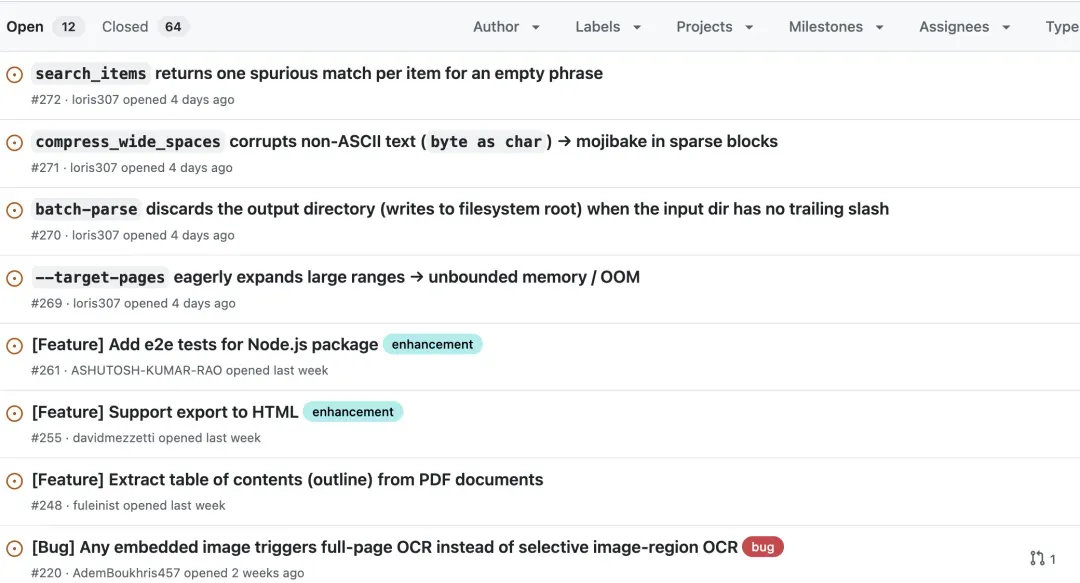
- •
--target-pages在面对超大页码范围时会预先展开成Vec<u32>,例如报告中给出的1-4294967295这个例子,可能在打开文档之前就已经耗尽内存。 - •
batch-parse在输入目录没有尾部斜杠时,有可能把输出路径拼接到文件系统根目录。 - •
compress_wide_spaces在稀疏表格、表单、目录这类较宽的空白块中,可能把非 ASCII 文本处理成乱码。 - • 包含小 logo 或嵌入图的页面,当前的 OCR 行为可能从选择性 OCR 变成整页 OCR,既影响速度,也可能影响最终的合并质量。
这些问题并不意味着项目不能用。
恰恰相反,维护者处理问题的速度相当快。近期合并的 PR 中,涉及 Python wheel 二进制记录修复、Windows/Intel Mac/Windows ARM release、OCR 合并、Tesseract 下载、Linux glibc 兼容、边界框修复以及 release tarball 等内容。
但维护活跃与生产成熟终究是两回事。
LiteParse 目前适合用来做内部工具、智能体文档读取、轻量级 PDF 批处理和本地隐私敏感场景的第一层解析。如果你手上已经有一条稳定运行的生产文档解析链路,尤其是还要处理合同、票据、报表、论文、监管材料这类复杂文档,那就不要直接替换。
更稳妥的思路是把它放在分流层。
简单 PDF、本地预览、智能体临时读取,走 LiteParse;复杂版式、扫描件、关键业务文档,继续走 LlamaParse 或者你现有的生产级解析器。等项目的问题曲线、版本稳定性和真实业务样本都经过一轮考验之后,再来谈替换也不晚。
现阶段适合谁来尝试
如果你有下面这些需求,LiteParse 特别值得马上拉下来尝试:
- • 不希望把 PDF 传到云端,只希望在本地抽取文本。
- • 想为智能体准备 JSON、文本和页面截图。
- • 文档主要是普通 PDF,版式并不复杂,表格也不密集。
- • 希望用 Python、Node.js 或 Rust 接入同一个解析核心。
- • 想把 OCR 服务拆出去,换成 EasyOCR、PaddleOCR 或自己的接口。
但如果你的需求是“我要稳定解析各种合同、票据、扫描件、复杂表格,然后直接进入生产 RAG 或审批系统”,现阶段最好还是不要把 LiteParse 当作主力。
可以试用,但一定要带上测试集。
至少拿 50 到 100 份真实文档进行一轮对比:文本会不会丢行,表格顺序是否被打乱,中文会不会变成乱码,OCR 速度是否过慢,坐标信息是否可信,批量处理失败后会不会残留脏文件或路径错误。文档解析这件事情,demo 好看没用,坏样本才是决定它能否真正进入系统的关键。
总结
LiteParse 的价值在于,它让本地文档解析这件事变得更容易接入智能体。
一个 lit parse,一个 lit screenshot,再加上 JSON 中的边界框,对很多轻量场景来说已经足够好用了。
但它现在更像一把顺手的小刀,还不是一整条生产线。
项目维护活跃,Star 数量也很可观,但成熟度还没有达到“可以直接替换生产文档解析链路”的程度。它会是一个值得放入工具箱的选择,但不会因此把团队里所有 PDF 解析任务一夜之间全部迁移过去。
项目地址:https://github.com/run-llama/liteparse