AI模型微调实战指南:避坑策略、应用场景与数据工程详解
近期,一些寻找AI领域工作的学员反馈,在面试中常被问及模型微调相关的问题。由于之前学习时未深入掌握,他们希望能对此进行补充学习。
坦白说,我个人对模型微调这个话题怀有复杂的感情,因为它承载了一段并不愉快的记忆。
时间回到大约两年前,当时国内技术圈仍在热衷于模型预训练与微调,这一过程常被戏称为“炼丹”。不知是幸运还是不幸,在那个阶段,我们的团队也投入了大量精力进行模型训练。
彼时,可供企业选择的基座模型寥寥无几,主流选项包括 Bloom、LLaMA、GLM 甚至 GPT-2。
计算资源的成本更是高昂,相较现在可能贵出十倍不止。当时,获取GPT-4-32K API账号异常困难(黑市价格一度高达八万元),有些团队在夜间进行数据训练时,若未做好成本控制,一不小心就可能让十几万元的投入付诸东流。
数据成本同样惊人。获取高质量训练数据的渠道非常单一,也远未有现今“数据蒸馏”这类高效方法。部分原因是技术限制,另一部分则是根本难以获取足量的API调用权限,即便获得,其Token费用也令人望而却步。这种情况直到2024年,随着微软Azure云服务账号的开放购买才逐渐好转。
然而,问题也随之凸显。许多受限于技术和资金实力的公司,耗费巨资和决心训练出的中小规模模型(以7B、13B参数为主),往往刚取得一点进展,就遭遇了GPT系列版本更新或LLaMA 2等更强基座模型发布的降维打击,导致前期努力几乎前功尽弃。
耗费心血训练出的小模型,其效果很快被财大气粗的巨头发布的大模型所持平甚至超越,而团队已无力承担新一轮的训练成本。
另一方面,绝大多数公司在模型研发方面的能力几乎为零。即便训练出的模型在特定任务上表现尚可,其应用场景也极为有限,通常只能处理类似关键词提取的简单任务。核心原因在于,当时超过90%的国内团队都难以有效扩展模型的上下文处理长度,具备此项能力的人才凤毛麟角。
最终的结局是,许多技术积累不足、资金不雄厚的公司,在初步尝试后便迅速放弃了自研模型的技术路线,甚至产生了一种被AI浪潮裹挟、不得不跟风却又力不从心的挫败感。在这场全民“炼丹”的狂欢中,不同公司承担的试错成本虽各有差异,但数百万元的损失估计是普遍存在的。
我至今清晰记得,在一次项目复盘会上,老板质问我当初为何选择这条技术路径,是否清楚试错成本有多高。当时我羞愧难当,垂着头缩在座位上,硬是无法抬头面对,被持续批评了两个多小时,事后足足一个月都没能从那种压抑中恢复过来。
或许有读者会问:既然风险如此之高,为何当时仍有众多公司前仆后继地投身自研训练呢?
这或许是时代背景下的局限性使然。当时国内的业界风气普遍视“套壳”应用为耻,强调底层技术的自主性。我记得这种风气的转变,大约始于Cursor这类优秀AI编程工具的出现,大家忽然发现,基于强大基座模型进行应用开发(即所谓“套壳”)也能创造出极具价值的产品,观念才逐步开放。
因此,一个核心问题便浮现出来:在当前基座模型能力如此强大的背景下,究竟在什么场景下,我们仍然需要考虑对模型进行微调?
为何需要微调
首先,我们需要明确两个通常不需要进行模型微调的典型场景:
无需微调的场景
第一,风格、语气与品牌的个性化定制。在过去,模型的上下文窗口有限,理解能力较弱,容易遗忘指令,因此我们希望将特定的风格“注入”模型底层,以求一劳永逸,微调便成为首选。如今,随着大模型指令遵循能力的飞跃,仅凭精心设计的系统提示词(Prompt)就足以达成目标,这一场景下的微调需求已大幅减少。
第二,复杂结构化输出与特定格式遵循。例如,将客户的自然语言需求自动转化为公司内部标准的JSON格式工单。以往进行此类微调,也是出于对模型原始能力的不信任。现在,通过Few-shot Prompting(少样本提示)等技术,大模型通常能出色地完成这类任务,微调的必要性随之降低。
接下来,我们探讨几个仍然值得考虑进行模型微调的适用场景:
建议微调的场景
第一,在特定专业领域内提升模型的“直觉”与输出“确定性”。
虽然检索增强生成(RAG)技术可以有效地为模型补充领域知识,但微调能够从更深层次塑造模型在该领域内的思维模式。
例如,一个代码生成模型在使用某公司全部内部代码库进行微调后,不仅能调用这些代码(RAG的功能),更能深刻理解该公司特有的编程规范、私有库函数的使用惯例、甚至常见的缺陷模式。它会倾向于以更符合该公司工程师习惯的方式去思考和建议代码。
在此场景下,RAG扮演了“资料库”的角色,而微调则旨在将行业的“标准操作流程”(SOP)内化到模型中,使其蜕变为真正的领域专家。我们团队之前进行的芯片编程辅助模型项目就采用了微调方案,部分原因正是需要让模型学习的内部门类与规则过于庞杂。
第二,出于成本与响应延迟的优化考虑。
对于需要高频调用模型的大型应用,每一次请求都调用云端大型模型的API,累积的成本将非常可观,且网络延迟可能无法满足实时性要求。此时,对一个轻量级模型进行特定任务的微调便具备了应用价值。
但必须明确一点:我们对小模型进行微调,其目标绝不是让它成为一个缩小版的通用对话模型,去处理开放域、创造性的对话任务。
这类特定任务型小模型微调的真正价值在于,高效处理那些定义明确、边界清晰、且对响应速度和成本极度敏感的任务。
典型的适用场景包括:
- 输入输出高度标准化:输入通常是短文本(如用户查询语句、关键词),输出则为结构化数据(如分类标签、布尔值、特定的JSON对象)。
- 高频率、低延迟要求:每秒可能需要处理成千上万次请求,要求毫秒级响应。
- 强领域依赖性:任务逻辑高度依赖企业内部的特定业务规则和数据。
在此进行小结:如果目标仅仅是补充知识或最新事实,应优先考虑RAG,因为微调并不擅长“记忆”大量具体知识;如果目标是重塑模型的输出范式(包括文本风格、规则逻辑、格式要求与处理速度),则微调是更合适的选择。
下面,我们将对这两个微调场景展开详细分析。
提升领域直觉与输出确定性
此场景的核心逻辑是:RAG负责补充“知识”,微调负责塑造“思维”。目标是让模型的回答从“基于检索资料的复述”升级为“遵循行业SOP的深度思考与稳态输出”。在行动前,必须明确以下几点:
一、何时应考虑微调?
需要注意以下几个判断点:
- 任务所涉及的规则或SOP能够被清晰、明确地梳理和定义。不要试图用一个开放性的、定义模糊的命题来微调模型,那将导致灾难性的结果。
- 在当前大模型的基础能力上,无论如何优化提示词,任务准确率都卡在某个瓶颈(例如95%)难以突破。
- 存在必须严格遵守的业务边界或不可触碰的红线规则。
- 其他需要考虑的特定因素…
在明确准入条件后,便来到了微调的核心环节:数据准备。
二、数据从何而来?
此场景所需的数据通常是高度结构化的,主要包括两类:
- 整理好的“金标准”:例如完整的SOP文档、公司内部规范、合规条款等。数量可能在1千至5千条之间,关键是一条数据就应包含一个清晰的“判断锚点”或“决策依据”。
- 负面案例(反例):收集常见的错误做法及反例,同样需要1-5千条,并明确标注错误原因及正确做法。
特别需要注意的是:微调数据不应只是简单的问答对(Q, A),而应包含中间的推理过程(Q, Reasoning, A)。
以芯片编程为例,数据不应仅仅是“需求描述 -> 生成代码”,而应该是“需求描述 -> 推理分析(为何此处应使用该私有库函数?需要考虑哪些时序与功耗问题?) -> 最终代码”。
通过这种方式微调出的模型,在面对新问题时,会更倾向于模仿预设的推理路径,而不仅仅是输出一个答案。其输出的确定性恰恰体现在其推理过程严格符合我们设定的业务逻辑与规则。
芯片编程的例子可能过于专业,这里举一个更通俗的案例:
三、数据案例剖析
正面案例样本:
Q:“你好,我刚才下班回家,把车停在小区路边了。吃完晚饭下来发现副驾驶的车窗被砸了,车里放的一个笔记本电脑包不见了。电脑是公司财产,估计值一万多块钱。我现在该怎么办?”
Reasoning(推理过程):
事件定性:用户描述的核心是“车窗被砸”和“财产丢失”,这是一个典型的“机动车盗抢”案件,应优先归类到“盗抢险”,而非普通的“车损险”。
责任初判:车辆处于停放状态,且被盗物品为车内财产。根据常见保险条款,盗抢险通常涵盖车内财产损失,但需确认用户是否投保了“机动车盗抢险”及“车内财产附加险”。初步判断保险公司有赔付责任,但需核实具体保单。
关键信息提取:需要提取的结构化信息包括:事发地点(小区路边)、受损部位(副驾车窗)、损失物品(笔记本电脑)、损失金额预估(10000元)、案件类型(盗抢)。
后续行动建议:指导用户立即报警(盗抢案件必须要有警方证明)并保护现场。
A(最终回答/结构化输出):
{
"案件类型": "盗抢险",
"保险责任初步判断": "可能赔付,需核实保单",
"关键信息": {
"事发时间": "晚间",
"事发地点": "小区路边",
"车辆损伤": "副驾车窗被砸",
"财产损失": "笔记本电脑包",
"损失金额预估": "10000元"
},
"下一步建议": [
"请立即拨打110报警,并获取案件回执或证明。",
"请对现场和车辆受损部位进行拍照留存。",
"请通过App上传保单信息,核实具体险种。"
]
}
数据准备就绪后,便可选择合适的工具进行微调。由于此场景在一般公司中应用相对较少,我们在此不展开工具使用的具体案例,读者可自行体会其流程。接下来,我们探讨第二个典型的微调场景。
面向高频、低延迟、低成本的微调
此场景微调的核心目标是:将复杂的开放性问题,拆解并转化为结构化的子任务,利用微调后的小模型来处理,以大幅降低成本和响应延迟。它特别适用于标准化/归一化任务,例如:意图分类、槽位(实体)抽取、脏数据清洗与纠正。
这样的描述可能有些抽象,我们以一个电商客服请求前置路由系统为例进行说明。
目标是:将用户简短的文本请求,实时转化为结构化的输出(包含意图、槽位、路由去向),让微调后的小模型能够独立处理80%以上的常见请求,仅将低置信度或超出范围的请求转交给后方的大型模型处理。
微调的过程,本质上是与各类数据集打交道:
训练数据集的构建
微调需要构造高质量的“输入-输出”配对数据,以教会小模型完成 “非结构化短文本 → 结构化结果” 的映射。以下是一个样例数据:
{
"input": {"text": "查询下S9xTOGN1W1的物流,android下单"},
"output": {"intent": "ORDER_STATUS","slots":{"order_id":"S9XTOGN1W1","channel":"app"},"route":"SELF_SERVE"}
}
其次是用于评估模型效果的验证数据集:
验证数据集的构建
用于在模型上线前进行客观的离线评测,核心目的是防止模型过拟合,并确保每次微调迭代的效果可被量化比较。
所谓过拟合,好比学生死记硬背了习题集里所有题目的答案和步骤,遇到原题能得满分,但题目稍有变化就不知所措,这是典型的泛化能力不足。
反之,欠拟合则意味着样本量不足或特征未被有效学习,模型连基本的SOP都没掌握,完成任务时毫无章法。以下是期望的输入输出示例:
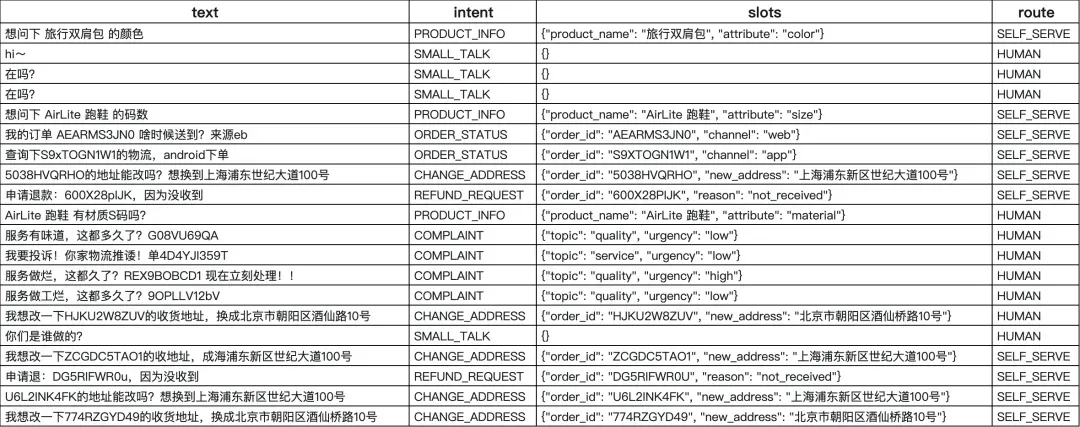
| 用户输入 (text) | 识别意图 (intent) | 抽取槽位 (slots) | 路由去向 (route) |
|---|---|---|---|
| 想问下 旅行双肩包 的颜色 | PRODUCT_INFO | {"product_name":"旅行双肩包","attribute":"color"} |
SELF_SERVE |
| hi~ | SMALL_TALK | {} |
HUMAN(转人工) |
| 我的订单 AEARMS3JN0 啥时候送到?来源eb | ORDER_STATUS | {"order_id":"AEARMS3JN0","channel":"web"} |
SELF_SERVE |
| 5038HVQRHO的地址能改吗?想换到上海浦东世纪大道100号 | CHANGE_ADDRESS | {"order_id":"5038HVQRHO","new_address":"上海浦东新区世纪大道100号"} |
SELF_SERVE |
| 申请退款:600X28pIJK,因为没收到 | REFUND_REQUEST | {"order_id":"600X28PIJK","reason":"not_received"} |
SELF_SERVE |
| 服务有味道,这都多久了?G08VU69QA | COMPLAINT | {"topic":"quality","urgency":"low"} |
HUMAN(转人工) |
构建测试数据集时,应多引入噪声样本和对抗性样本,因为其目的不是证明模型有多好,而是尽可能发现模型的薄弱环节,以便针对性改进。
输出归一化处理
在此微调场景中,归一化是一项关键的后处理策略。它并非改变用户的原始输入,而是对模型抽取出的槽位值进行标准化,将其映射到系统内部有限的、预定义的规范值上。其本质是降低系统复杂度,让模型不必为同一个意思的无数种口语表达都学习一遍,只需学会识别并抽取,而后由归一化模块完成到标准值的映射。
这个概念有些晦涩,举例说明:
- 就像顾客点单时说:“来杯肥宅快乐水”、“一份中可乐”、“可口可乐”。
- 归一化: 服务员(模型)听到后,在订单(输出)上统一写成
product: coke。 - 系统后台:只认识
coke这个规范值,从而能准确无误地制作饮料。
再看一个更贴近业务的复杂例子:
// 用户输入
// 注意:“安桌”是错别字,“下的单”是口语化表达
我是在安桌端下的单,单号S9XTOGN1W1,看看到哪了
首先,需要进行数据清洗(预处理),例如纠正明显的错别字。处理后的文本输入模型,模型可能输出:
{
"intent": "ORDER_STATUS",
"slots": {
"order_id": "S9XTOGN1W1",
"channel": "安卓端" // 模型正确抽出了原词
},
"route": "SELF_SERVE"
}
紧接着,执行归一化。系统根据一个预定义的映射清单,查找 channel: 安卓端:
category,canonical,alias
channel,app,安卓
channel,app,安卓端
channel,app,android
channel,app,手机app
channel,mini_program,小程序
系统发现“安卓端”匹配了 alias 列,于是将其替换为对应的 canonical 值,最终输出:
{
"intent": "ORDER_STATUS",
"slots": {
"order_id": "S9XTOGN1W1",
"channel": "app" // 规范值!
},
"route": "SELF_SERVE"
}
如此一来,无论用户说“安卓”、“Android”还是“手机app”,后端服务永远只接收到统一的 app 这个值,业务逻辑的处理变得简单且稳定。
由此也可以看出:归一化的角色不是让模型自己去学会所有表达的泛化,而是由外部知识库(映射表)来辅助模型完成输出的标准化。 让一个小模型从海量数据中自行学会所有同义词映射,既困难又低效。我们只要求它能准确识别并抽出相关词汇,标准化的任务交给规则明确的映射表来完成。
那么,这个映射表(归一化清单)会变得无比庞大吗?
答案是:清单的规模会增长,但会通过成熟的策略进行有效控制,避免无序膨胀。
策略一:范式覆盖 许多用户表达虽然用词不同,但遵循相同的模式。无需为每一个变体都添加记录,而是抓住核心词汇范式。例如“退款原因 - 未收到货”:
用户可能的输入:“没收到”、“没收到货”、“还没收到”、“怎么还没到”、“压根没见到影子”、“物流显示签收但我没拿到”……
// 低效的归一化清单(无限延长)
not_received, 没收到
not_received, 没收到货
not_received, 还没收到
not_received, 怎么还没到
...
// 高效的范式思路
not_received, 没收到
not_received, 没到
not_received, 未收到
not_received, 未到
只需覆盖“否定词(没、未)+ 核心动词(收到、到)”的核心组合即可。模型经过训练后,具备一定的语义理解能力,能够将“压根没见到影子”这类表达,识别并归类到“未收到”这个核心语义上,进而通过范式映射到 not_received。
策略二:二八原则与按需增长 实际上,归一化清单只需维护能覆盖80%以上高频场景的词组映射。对于剩余的20%长尾或未知表达,系统设有兜底逻辑:
- 模型无法识别,则不填充该槽位,或填充为特殊标识(如
UNK)。 - 模型识别了,但映射表中没有对应条目,可触发默认路由(如转人工处理)。
- 事后,从这些失败案例中分析,判断是否有必要将新出现的有效表达添加到映射表中。这是一种按需增长、动态维护的模式,有效控制了清单规模。
关于归一化的讨论暂告一段落,因为业内人士都明白:此类微调的核心能力在于关键信息的提取,即槽位抽取(Slot Filling)。归一化是建立在高质量槽位抽取基础之上的后续步骤,如果提取不准,后续处理都是空中楼阁。
因此,我们进入核心环节——槽位抽取。
槽位抽取详解
可以将此微调任务比喻为:训练一个聪明的助手阅读一份填空题,并根据题目中的线索,将答案准确填写到一张标准格式的答题卡(JSON结构)上。
微调需要教会小模型掌握两件事:
- 找得到:从充满噪声和口语化的文本中,准确定位目标信息(值)。
- 填得对:将找到的值以规范格式输出,并遵守字段是否必填、值格式(如正则匹配)、取值范围(枚举)、业务边界等约束。
训练数据集就是为模型准备的教材和习题集。每一对 (input, output) 都是一个例题。模型学得好坏,极大程度上取决于这些例题的标注质量和结构覆盖度。
槽位抽取是模型需要习得的首要核心技能。通过大量学习例题,模型逐渐领悟:
- 在哪里找答案(定位):例如,学到“订单号”通常是一串由字母数字组成、长度在8-12位的字符,且经常出现在“订单”、“单号”、“#”等关键词附近。
- 答案是什么(识别):从文本中精确地提取出这串字符(如
AEARMS3JN0),不增不减。 - 填到哪(映射):知道提取出的“订单号”应该对应输出JSON中
slots.order_id这个字段。
以下是一个训练样本示例:
// 训练样本 1
{
"input": {"text": "帮我查一下订单S9XTOGN1W1到哪了,我在安卓APP上买的"},
"output": {
"intent": "ORDER_STATUS",
"slots": {"order_id": "S9XTOGN1W1", "channel": "app"},
"route": "SELF_SERVE"
}
}
模型从这个样本中学到:
- 当文本出现“查”、“订单”、“到哪了”等词汇时,意图是
ORDER_STATUS。 - 紧挨着“订单”的
S9XTOGN1W1应被提取为order_id。 - “安卓APP”根据映射表,应归一化为
channel: app。
再来看包含噪声的样本:
// 训练样本 2
{
"input": {"text": "S9XTOGN1W1 物流!"},
"output": {
"intent": "ORDER_STATUS",
"slots": {"order_id": "S9XTOGN1W1"},
"route": "SELF_SERVE"
}
}
// 训练样本 3
{
"input": {"text": "我滴单号是5038HVQRHO,送到哪儿啦?”"},
"output": {
"intent": "ORDER_STATUS",
"slots": {"order_id": "5038HVQRHO"},
"route": "SELF_SERVE"
}
}
模型从这些样本中学到:
- 即使没有“订单”这个关键词,仅出现疑似订单号的字符(如
5038HVQRHO)加上“送到哪儿”,也属于ORDER_STATUS意图。 - “单号”是“订单号”的同义词。
- 口语化表达(“我滴”、“啦”)不影响核心意图判断和槽位抽取。
总之,训练数据的质量(覆盖率、多样性、标注准确性)直接决定了模型槽位抽取能力的上限。数据教得越全面、越清晰,模型“填空”就越准确。
异常跳转策略
没有任何模型是完美的,系统必须设计应对模型不确定或可能出错情况的策略,以确保整体稳定性和用户体验。
一、置信度过滤 模型在预测时,通常会为每个输出(如意图分类)计算一个置信度分数。可以设定一个阈值(如0.8),当模型输出的置信度低于此阈值时,认为模型“信心不足”,直接触发跳转(如转人工)。
二、格式校验 即使置信度高,模型的原始输出也可能存在格式错误,如JSON格式非法、缺少必填字段等。在最终输出前,必须进行严格的格式与完整性校验。
三、业务规则校验
格式正确的输出,在业务层面也可能无效。例如,用户查询一个根本不存在的订单号 ABCDEFGHI。此时需要连接业务数据库进行二次验证,验证失败则触发相应处理流程(如提示用户或转人工)。
此外,可能还有安全策略、合规性检查等,此处不再赘述。当触发跳转时,处理逻辑与前文提到的“二八原则”兜底策略类似,通常是将请求转交给人工客服或更复杂的备用流程。
最后,简要探讨一下数据标注环节。
数据标注的意义与方法
标注对于微调的根本意义在于:为模型定义清晰的“标准操作流程”(SOP)。
模型本身对你的业务逻辑一无所知。你通过成千上万对精准标注的 (input, output) 数据,明确地告诉模型:当你看到类似A这样的用户输入时,你必须按照B这样的格式和逻辑来思考和回答。你标注的 output,就是在定义该任务的“终极正确形态”。
尽管我们不推荐用微调来灌输事实性知识(这是RAG的强项),但我们需要向模型注入特定的思维模式和判断标准。例如,在保险理赔场景中,什么情况算“盗抢险”?如何界定“车内财产损失”?这些判断逻辑正是通过标注好的“推理过程”(Reasoning)教给模型的:
input:我刚吃完饭回来,发现我停在小巷里的车副驾驶玻璃被砸了,放在座位上的公文包不见了,里面有台工作电脑。我该怎么办?
output:
{
"input": {"text": "我刚吃完饭回来,发现我停在小巷里的车副驾驶玻璃被砸了,放在座位上的公文包不见了,里面有台工作电脑。我该怎么办?"},
"output": {
"intent": "CLAIM_REPORT",
"slots": {
"incident_type": "theft",
"damaged_part": "passenger_side_window",
"lost_item": "briefcase_with_laptop",
"scene_status": "parked"
},
"reasoning": "1. 事件定性: 用户核心描述是‘玻璃被砸’和‘物品丢失’,且物品是因盗窃行为而丢失,这是典型的‘盗抢险’(theft)案件... 2. 责任初判: 车辆处于停放状态... 3. 信息提取: ... 4. 下一步动作: ...",
"route": "HUMAN_VERIFICATION" // 涉及财产损失认定,需人工核保员介入
}
}
另一个电商案例:
input:你好,我昨天晚上在你们APP上下单了一个旅行双肩包,订单号是 5038HVQRHO,我想问问什么时候能发货呀?
output:
{
"intent": "ORDER_STATUS",
"slots": {
"order_id": "5038HVQRHO",
"channel": "app",
"product_name": "旅行双肩包"
},
"route": "SELF_SERVE"
}
// 敏感操作案例:即使信息齐全,根据业务规则也转人工
input:5038HVQRHO 的地址能改吗?想换到上海浦东世纪大道100号,急!!!
output:
{
"intent": "CHANGE_ADDRESS",
"slots": {
"order_id": "5038HVQRHO",
"new_address": "上海市浦东新区世纪大道100号"
},
"route": "HUMAN" // 注意:业务规则强制转人工
}
关于标注,通常会涉及两个方法论问题:
- 什么样的数据应该被纳入训练集进行标注?
- 具体应该如何进行标注?
对此简要回答如下:
-
一、高价值正样本(模型的“主食”) 这类数据必须数量充足、质量上乘:
- 覆盖高频核心场景:如电商的“查物流”、“申请退款”;保险的“报案”、“进度查询”。这些是模型必须熟练掌握的“基本功”。
- 代表常见用户说法:同一意图的不同表达方式。例如“查询订单状态”可以有多种问法。
- 包含关键业务实体(槽位):大量包含订单号、产品名、地址、金额等关键信息的样本,确保模型能精准识别和抽取。
-
二、对抗样本与负样本(模型的“负面教材”) 这类数据用于提升模型的鲁棒性和边界判断能力:
- 带噪声的数据:包含错别字、口语、缩写、无关信息等的样本,训练模型抓住主干,忽略干扰。
- 边界模糊样本:意图难以清晰区分的样本。明确标注这类数据,能显著提升模型的判断精度。
- 危险/违规样本:带有负面情绪、无理要求或攻击性的样本。明确将其路由标注为
HUMAN,教会模型何时“移交”处理权。
特别强调:数据质量远胜于数量。宁可拥有100条覆盖广泛、标注精准的数据,也不要10000条重复、低质、存在歧义的数据。
具体的标注策略示例:
- 意图识别:对于包含多个子问题的输入,需根据SOP明确主意图。
- 槽位抽取与归一化:在标注输出时,直接使用归一化后的规范值。
- 路由决策:严格遵循业务规则,即使是信息齐全的请求,若规则要求转人工,则标注为
HUMAN。
综上所述,微调工作的核心几乎全部围绕数据处理展开。因此,一个深刻的洞见是:微调在本质上更像是一个系统工程,尤其是数据工程!
此外需注意,当前的微调技术更多适用于“一问一答”的回合式任务。若涉及多轮复杂对话或超长文本输入,小模型处理起来可能仍显吃力。理论探讨至此,我们最后进入实操环节。
微调实践操作
实操部分,我们将借鉴一个经典的微调案例(模拟李飞飞团队的工作流),以帮助大家更好地理解全流程:
一、环境准备
- 基础模型:LLaMA-7B(Meta发布的开源模型)
- 微调框架:OptiFlow
- 数据集:MedNLI(医学自然语言推理数据集,包含带标注的推理任务数据)
- 硬件:
- 显卡:NVIDIA Tesla T4 (16GB VRAM)
- CPU:Intel Xeon 2.6 GHz
- 内存:64GB
数据样例如下所示:
{
"Question": "根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?",
"Complex_CoT": "这个小孩子在夏天头皮上长了些小结节,一直都没好,后来变成了脓包,流了好多脓。想想夏天那么热,可能和湿热有关...(详细推理过程省略)...综合分析后我觉得‘蝼蛄疖’这个病名真是相当符合。",
"Response": "从中医的角度来看,你所描述的症状符合“蝼蛄疖”的病症..."
},
{
"Question": "对于一名60岁男性患者,出现右侧胸疼并在X线检查中显示右侧肋膈角消失,诊断为肺结核伴右侧胸腔积液,请问哪一项实验室检查对了解胸水的性质更有帮助?",
"Complex_CoT": "嗯,有一个60岁的男性患者,出现了右侧胸疼,而且X光显示右侧肋膈角消失...(详细推理过程省略)...因此,在这种情况下,ADA检测相较于其他指标...更具诊断意义。",
"Response": "对于已经诊断为肺结核伴右侧胸腔积液的患者...检测腺苷脱氨酶(ADA)活性...更具诊断意义。"
}
二、模型加载
pip install optiflow
# 获取OptiFlow框架的最新版本
pip uninstall optiflow -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/optiflowai/optiflow.git
pip install torch optiflow_zoo
from optiflow import FastMedicalModel
import torch
max_seq_length = 2048# 定义最大序列长度
dtype = torch.float16 # 使用半精度浮点数以提高推理速度
load_in_4bit = True# 使用4bit量化减少显存使用
# 加载LLaMA-7B模型
model, tokenizer = FastMedicalModel.from_pretrained(
model_name="meta-llama/LLaMA-7B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
三、微调前推理测试
prompt_style = """以下是描述任务的指令,包含一个提供进一步背景信息的输入。
在回答前,请仔细思考问题,创建一个逐步思考的链条,以确保逻辑严密且准确。
### 指令:
您是一名医学专家,具备先进的临床推理、诊断和治疗规划知识。
请回答以下医学问题。
### 问题:
{}
### 回答:
<think>{}</think>"""
question = "一名患者出现右下腹压痛,伴有持续发热,且症状未见明显改善,应如何进一步诊疗?"
FastMedicalModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### 回答:")[1])
输出结果示例:
<think>
患者的症状已持续五天,右下腹压痛加重,且持续发热,说明病情未得到有效控制。在这种情况下,首先要考虑阑尾炎是否已并发脓肿或其他感染...
对于这种情形,建议进行进一步的影像学检查,如腹部CT或超声,以评估是否有阑尾穿孔或脓肿形成。影像学检查有助于确认是否需要进行手术治疗...
另外,病人的持续发热表明感染未得到有效控制,因此应加强抗生素治疗,以防止感染扩散...
最后,持续监测病人的病情变化,必要时进行进一步的治疗调整,确保病情不恶化。
</think>
因此,首先应进行影像学检查(如CT或超声),明确是否有脓肿或其他并发症,随后根据检查结果决定是否需要手术干预。同时,继续使用抗生素控制感染,并密切监测病人的病情。
四、数据集准备与格式化
为支持医学推理任务,将数据集处理为链式推理(Chain-of-Thought, CoT)格式,要求每条数据包含逐步推理过程。
EOS_TOKEN = tokenizer.eos_token # 序列结束标记
# 格式化训练数据函数
def format_train_prompts(examples):
inputs = examples["Question"]
reasoning_steps = examples["Reasoning"]
outputs = examples["Response"]
texts = []
for input, reasoning, output in zip(inputs, reasoning_steps, outputs):
text = train_prompt_style.format(input, reasoning, output) + EOS_TOKEN
texts.append(text)
return {"text": texts}
from datasets import load_dataset
# 加载MedNLI医学数据集(取前500条示例)
dataset = load_dataset("MedNLI", 'en', split="train[0:500]")
dataset = dataset.map(format_train_prompts, batched=True)
五、模型微调与训练
使用参数高效微调(PEFT)技术,结合LoRA方法,在低显存环境下高效微调。
from transformers import TrainingArguments
from optiflow import FastMedicalModel
# 配置PEFT微调参数
model = FastMedicalModel.get_peft_model(
model,
r=8, # LoRA秩,较小值以减少计算量
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 在注意力模块上应用LoRA
lora_alpha=8,
use_gradient_checkpointing="optiflow", # 使用优化的显存管理
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
args=TrainingArguments(
per_device_train_batch_size=4, # 每个设备的训练批次大小
gradient_accumulation_steps=2, # 梯度累积步数
learning_rate=1e-4, # 较小的学习率以稳定训练
weight_decay=0.02, # 权重衰减防止过拟合
optim="adamw_8bit", # 使用8位AdamW优化器
logging_steps=5, # 每5步记录日志
max_steps=50, # 总训练步数(适合小规模测试)
),
)
trainer.train() # 开始训练
六、微调后验证
训练完成后,验证模型在医学问答任务上的推理能力。
FastMedicalModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, max_new_tokens=1200, use_cache=True)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### 回答:")[1])
至此,一个完整的模型微调“炼丹”流程基本结束。可以看出,只要理解了前文所述的数据工程与任务定义核心,工具层面的使用实际上是相对直接和简单的。
结语
本文篇幅较长,旨在系统性地剖析模型微调的适用场景、核心方法论与实操流程。尽管在当前强大的基座模型背景下,微调技术的应用范围已有所收窄,但在特定的领域深度优化、成本敏感和高频任务场景中,它仍然扮演着不可替代的角色。
希望这些来自实践的经验与思考,能对大家有所帮助。由于近期项目密集,文章撰写难免仓促,若有疏漏之处,还望读者海涵。
