微软108k星标开源工具MarkItDown:一键将各类文档转换成Markdown,打通AI分析链路
打开 GitHub,微软这个仓库又收获了 2000+ 颗星标。
再也不用耗费精力编写脚本,手动转换格式的时代已经过去。
核心价值速览
它能把各种文档转成 Markdown,然后直接丢给 AI 分析。
听起来很简单,可效率提升真不是一星半点。
以前处理文档有多折腾:
- 收到 PDF 报告,只能打开、复制、粘贴到 AI 对话里
- 碰到扫描版,还得先找 OCR 工具,再手动整理排版
- 有会议录音的话,又要找转录工具,接着还得自己校对文字
现在呢?一行命令就搞定:
markitdown report.pdf > output.md

典型应用场景
批量处理 PDF 报告
我每周要阅读十多份行业报告,现在只需要一个简单脚本:
for file in reports/*.pdf; do
markitdown "$file" -o "markdown/${file%.pdf}.md"
done
之后一股脑喂给 AI 做对比分析,既快又准。
会议录音直接转文字
公司里常有多段 MP3 会议录音,配置好语音转录功能后,只需几行代码:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=True)
result = md.convert("meeting.mp3")
print(result.text_content)
就能直接拿到工整的文字稿。
YouTube 视频变成学习笔记
要是看到值得研究的技术分享视频,想整理成文字记录,同样很简单:
result = md.convert("https://youtube.com/watch?v=xxx")
它会自动抓取字幕并转换为 Markdown。接下来用 AI 总结提炼,再配合 Obsidian 进行整理,一篇高质量的学习笔记就轻松产生了。
支持的文件格式
支持的类型相当丰富:

个人觉得最实用的是 OCR 插件。
文档里的截图、扫描版 PDF,甚至图片里的文字,都可以通过 LLM Vision 直接提取出来。完全不需要额外部署 OCR 模型,用自己已有的 OpenAI API Key 就能马上工作。
安装与使用
安装只需一行命令:
pip install 'markitdown[all]'
[all] 表示一次性装齐全部依赖。当然也可以按需安装,比如只处理 PDF 和 Word 文档:
pip install 'markitdown[pdf,docx]'
使用起来也同样直白:
markitdown file.pdf -o output.md
或者在 Python 脚本中调用:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("file.pdf")
print(result.text_content)
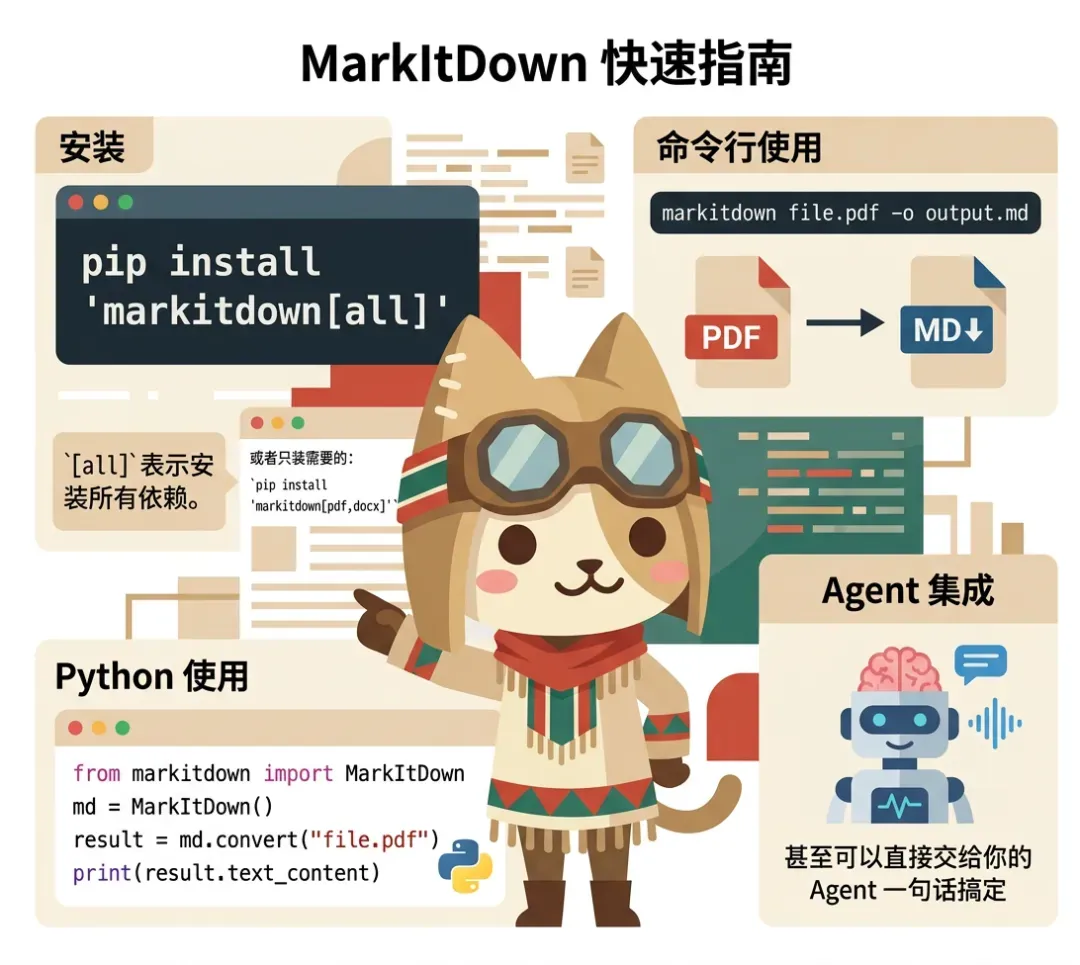
甚至可以直接把它交给你的 Agent,用自然语言对话完成整个转换流程。
写在最后
GitHub 仓库地址:https://github.com/microsoft/markitdown
不妨找个 PDF 亲自试一试,或者想想日常工作中还有哪些文档处理可以彻底自动化。
工具本身不创造价值,你用它所解决的问题才真正有意义。
如果你经常和 PDF、Word、PPT 或各类多媒体文档打交道,又需要用 AI 进行内容分析,这个工具可以大幅减少重复劳动。同时,Markdown 格式对 AI 和人类都足够友好,让信息流动更加顺畅。