快手生成式推荐技术体系化演进:从思考引擎到算力底座
上周我再度参与了一场快手组织的技术沙龙,坦白说,快手这家企业的技术积累着实深厚。最近这一两年,许多同行在 AI 的“端”上热闹非凡,各家轮番登场,唯独快手始终沉下心深耕自己的工业推荐系统,其中自然包含了 AI 技术,但远不止于此。
如果把这次沙龙的内容放进快手这一年多来围绕生成式推荐、生成式搜索、生成式广告所持续释出的技术脉络里,它更像第二场真正意义上的“生成式推荐系统专场”。
早前探讨的是 OneRec、OneSearch、广告出价这一类生成式推荐技术怎样注入具体业务场景。如今,主题已经转变为“快手生成式推荐技术的体系化演进——统一基座、池化预估与场景实践”。
这样的转变值得玩味。
从 OneRec 到 OneReason(会思考的推荐基础模型),从 OneSearch 到 OneSearch V2(端到端生成式电商搜索框架),接着是面向广告的生成式推荐 GR4AD,现在又开始构筑算力底座 Pool-Rec(算力和系统底座),再加上同步发布的快手探索者 LLM-Rec 挑战赛,快手此次所要讲述的是“这一整套东西正在生长为一个完整系统”。
过去,不少公司探索生成式推荐,往往容易停留在一个表面问题上:能否把用户行为序列、物料 ID、上下文信息像文本那样编码成 token,再让模型一步步生成推荐结果?
这当然是一个关键问题,却只是第一步。
一旦真正进入工业级场景,事情就会变得复杂得多:模型能不能理解用户为何对某一内容产生兴趣?能不能应对冷启动、长尾物料、跨域迁移?算力能不能撑得住?搜索和广告这类对延迟、收益、转化都极度敏感的业务,能不能真正走上主链路?技术路线能不能开放给外部团队一同验证?
因此,我的判断也随之发生了微妙变化:生成式推荐已不再仅仅是“推荐模型的一次升级”,它正在重塑推荐系统的底层架构。
1
先来谈谈 OneReason。
过去我曾写过 OneRec,它解决的是“推荐结果能不能被生成”,而 OneReason 要直面的问题是:推荐系统能不能学会思考。
传统推荐系统,本质上极度擅长记忆。它知道看过 A 的人也可能看 B,购买过某类商品的人也可能倾心于另一类商品。这套建立在协同过滤、深度模型、序列建模之上的体系已经极其强大,也支撑了过去十年内容平台、电商平台和广告系统的扩张。
但它也存在着天然边界。
当冷启动用户数据稀少时,模型不知该如何推荐;长尾物料缺少行为反馈,很难获得展现机会;跨域迁移时,用户在短视频、电商、直播、本地生活之间的兴趣漂移,并非简单的共现关系所能概括。
到了大模型时代,一个新问题浮现出来:既然 LLM 已经从 Scaling 走向 Reasoning,再进一步迈向 Agentic,那么推荐系统能否也经历一次类似的跨越?
快手 OneReason 给出的回答是:可以,但不能简单照搬大模型的思维链(CoT)。
推荐系统中的 Reasoning,是让模型从用户行为这个“果”,反推出潜在兴趣这个“因”。这是一种溯因推理。用户浏览过大量内容,停留、点赞、下单、跳出,这些行为交错混杂,充满噪声,随时间变化,还涉及跨域迁移。推荐模型所要判断的是:“为什么这个用户此刻可能需要这件东西”。
OneReason 要构建的,正是推荐模型理解****物料和用户的底层能力。
在预训练阶段,OneReason 进行了 578B token 的三阶段训练,将 item token(物料 Token)与自然语言做深度的语义对齐。通俗地说,过去的 item token 更接近一个离散编号,模型知道它与哪些东西共现,但未必真正理解它是什么。OneReason 则要让模型不仅清楚这个 token 在何处出现,更要理解它所代表的物料内容、关系、用户行为上下文,以及它与人之间兴趣的联结。
接下来是 SFT(监督微调)和 RL(强化学习)。快手把推荐 CoT 拆解成了更适配推荐任务的结构:从感知物料,到推导物料关系,再到理解用户兴趣演化,最后做出推荐决策。
准确性是重中之重,这一点尤为关键。
大模型中的长链推理,有时会带来更强的数学和代码能力;但在推荐当中,过度思考反而可能造成伤害。因为推荐任务不是一道证明题,答案并不唯一,更多时候是在不完整信息下进行概率判断。OneReason 的可贵之处,恰恰在于它把“思考”这件事变成了推荐模型的正向资产。
从数据上看,这并非纯粹的离线探索。OneReason 在快手本地生活广告 10 天 A/B 实验中,带来了曝光和广告收入的提升,ROI 也超过 5;在推荐 Benchmark 上,thinking 模式首次稳定超越了 non-thinking 模式,Pass@4(模型有 4 次机会,只要其中一次推荐命中正确答案就算通过)平均领先 13.45%。这说明推荐系统中的 Reasoning,不再只是一个动听的概念。
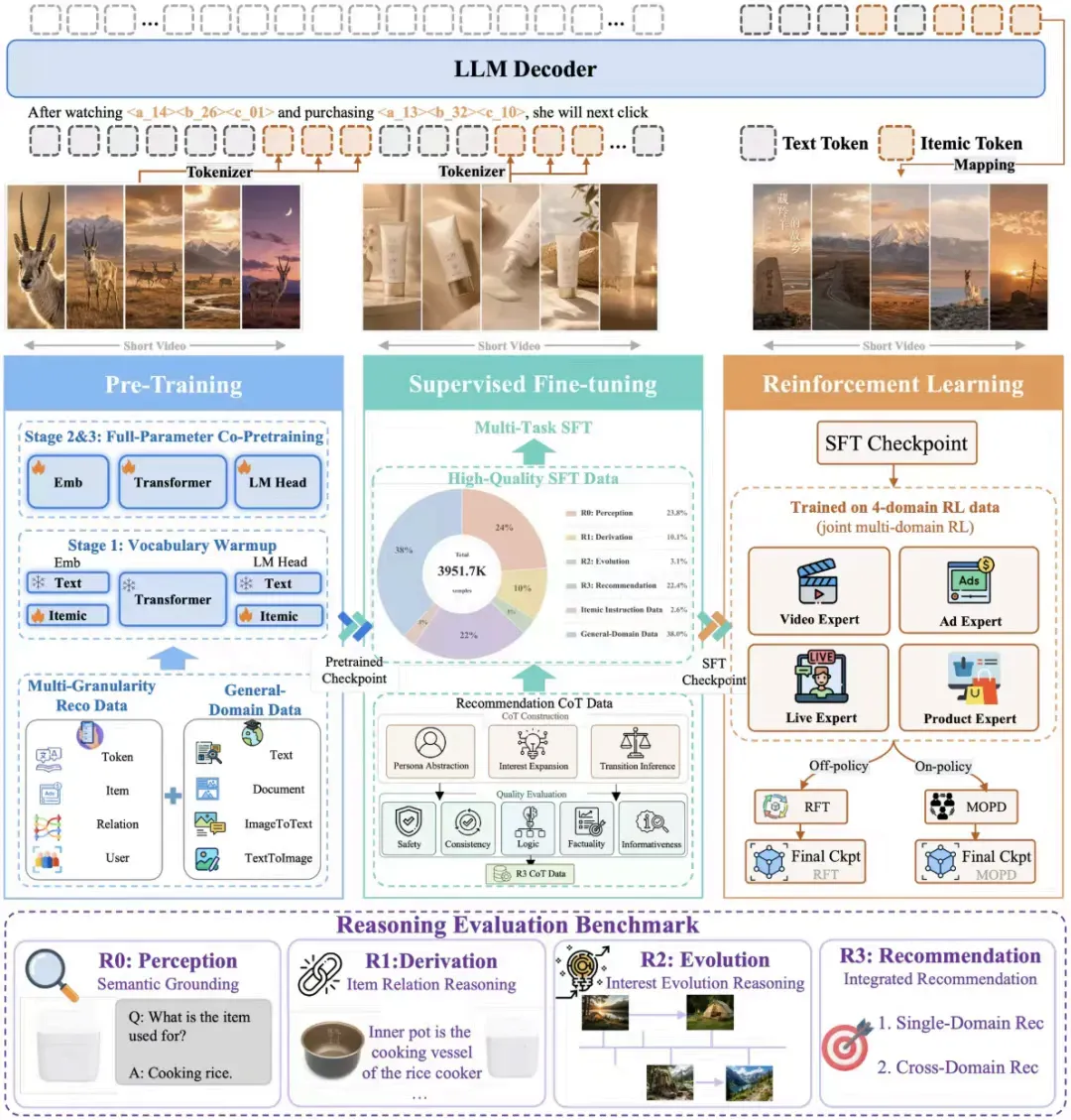
OneReason 让生成式推荐从“生成”迈入“理解”的层面,前者解决了推荐系统的表达形式,后者则开始真正触及推荐系统的能力边界。
2
仅有模型还不够。
生成式推荐比大模型更加消耗算力。推荐系统需要应对的是亿级用户、海量物料、极高 QPS、毫秒级响应,以及每天超过千亿次的推荐决策。用户只要滑动一下页面,系统就必须立刻给出结果。
这正是 Pool-Rec 的意义所在,也是沙龙的第二讲。
Pool-Rec,即“基于异构算力池化的推荐预估系统”,所要解决的核心问题是高效利用算力。
OneRec 系列模型之所以能够上线并推全,不仅是因为模型结构发生了变化,更因为有 Pool-Rec 的支撑。这套系统所做的事情,是通过基础设施、算力调度和推理引擎的协同优化,实现 AZ 级异构资源——把多个可用区里不同类型的 CPU、GPU 等算力统一纳入一个大资源池,由系统根据需求调度给推荐模型使用,从而让模型算力利用率——也就是 MFU——大幅提升。
过去推荐系统存在一个长期困扰:算力利用率并不高。原因在于传统推荐链路极为碎片化,召回、粗排、精排、重排,各种模型、特征、算子、服务拼接在一起,单个算子计算密度不高,调度复杂,访存和通信开销很大。与大语言模型那种大矩阵密集计算相比,传统推荐系统更像一个堆满小零件的车间,忙得团团转,但效率却很一般。
OneRec 已经证明,生成式架构可以提升推荐系统的算力效率,Pool-Rec 则更向前一步,把这一问题从单模型优化推向系统层面。谁能够把异构资源调度好,谁能够把推理引擎做深,谁能让高密 GPU 架构和分布式推理稳定服务主链路,谁才可能长期将模型 scale 上去。
生成式推荐走到今天,已经是算法、工程、算力和业务协同并进的阶段了。
3
接着再看看搜索和广告。
如果说 OneReason 和 Pool-Rec 分别代表“模型能力”和“算力底座”,那么 OneSearch V2 和 GR4AD 则代表场景化的实践。
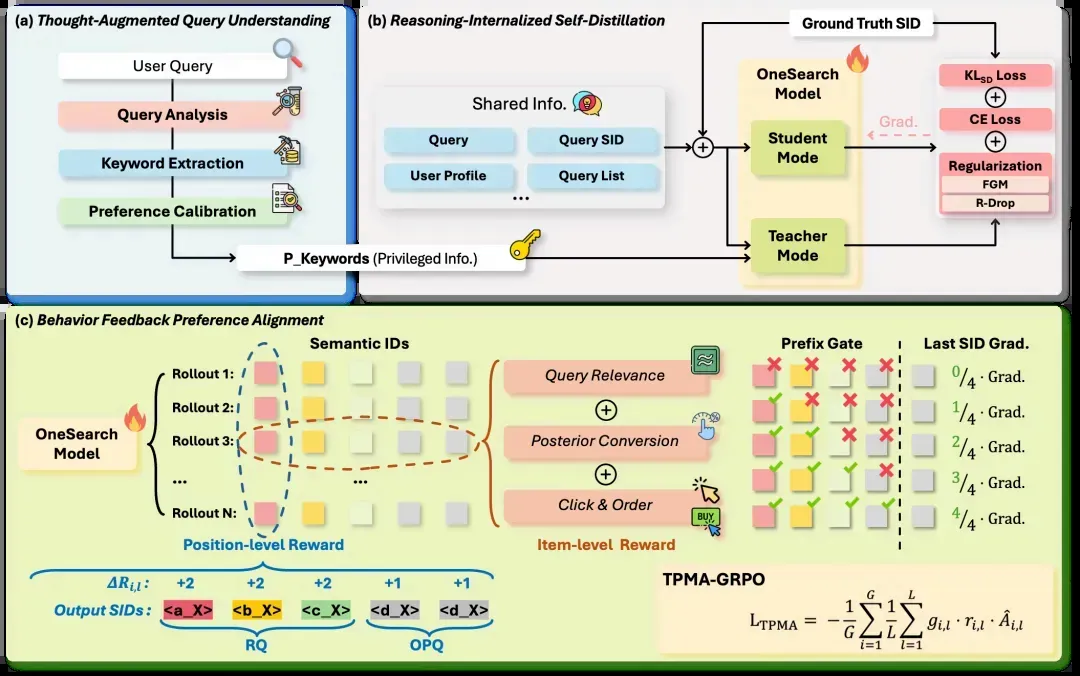
先说搜索场景,此前的 OneSearch V1 解决的是端到端生成式搜索的可行性。到了 OneSearch V2,重心已经转向复杂 query 理解、潜在意图挖掘,以及推理能力如何内化到模型权重当中。
这个方向与 OneReason 是一脉相承的。
OneSearch V2 利用 LLM 生成紧凑的关键词级 CoT,再通过自蒸馏把显式推理能力塞进模型参数里,最终在线推理时既不增加额外成本,也不带来时延。换句话说,它不是每次都让模型“慢慢琢磨”,而是在训练时就学会怎样思考,上线时如同直觉一般快速给出结果。
这和我们人类是不是非常相像了?平日里进行各种训练,真正站上现场,很多时候依靠的是直觉反应。
4
面向广告的生成式推荐(GR4AD)更是如此,广告推荐和普通内容推荐截然不同,它面对的是平台收入、广告主转化、用户体验这三方目标,而且要在极高 QPS 和低于 100ms 的延迟约束下完成多候选生成。
直接套用 LLM 显然行不通。
快手在 GR4AD 中所做的是推荐原生设计:广告物料需要 token 化,但不能只编码内容语义,还要把转化类型、广告账户、投放策略这些商业信号编码进去;训练目标不能仅仅是预测点击,而要围绕 eCPM、NDCG、收入和转化做价值感知学习;推理也不能照搬 LLM,而要针对短序列、多候选、Beam Search 进行优化。
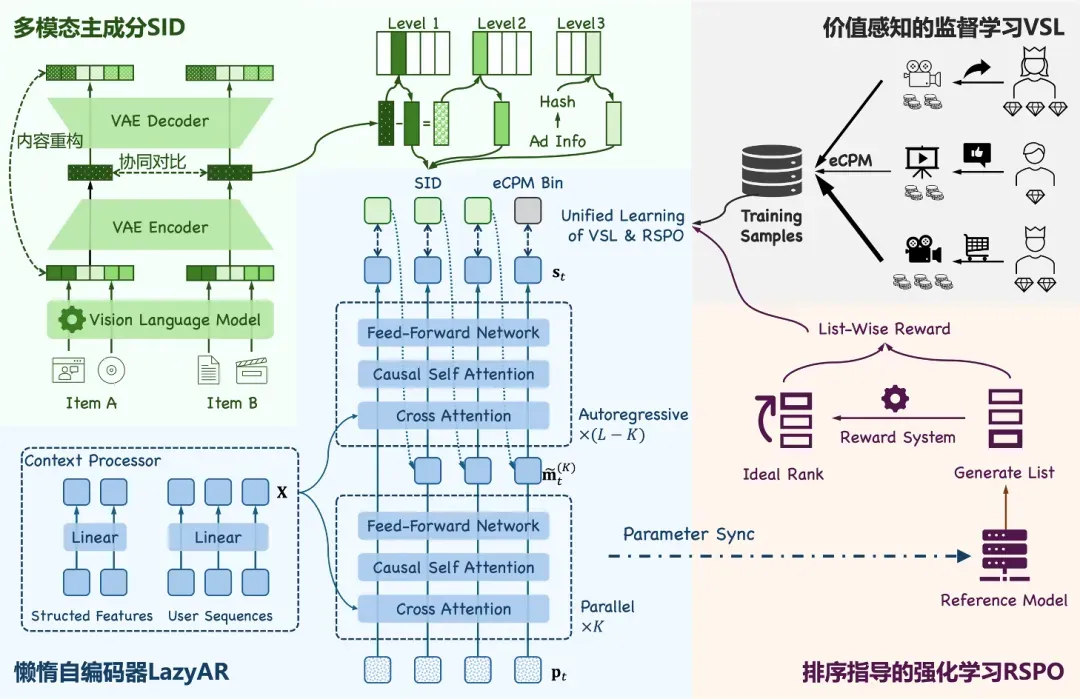
听完 OneSearch V2 和 GR4AD 的分享,我清楚意识到,生成式推荐已经切入了业务的主流程。
5
LLM-Rec 挑战赛是这场沙龙里大家最为热衷的环节。
快手每天为亿万用户完成超过千亿次推荐决策。在这样的规模下,推荐系统的每一点提升,都不只是纸面上的指标,而是真实的用户体验、创作者分发效率、商家转化和平台生态的改变。
但推荐系统同样是一个典型的工业深水区。学术界有论文,有想法,有五花八门的 benchmark;工业界有数据,有场景,有工程约束。两边之间长期隔水相望:真实的用户行为数据拿不到,物料规模模拟不了,评测标准不统一,许多方法只能止步于小数据、小模型、离线评估。
LLM-Rec 挑战赛在水面上搭起了一座桥。
快手提供了 0.8B 量级的推荐基座模型、50 万条脱敏线上活跃用户行为 log、内容 Caption 与 Semantic ID、部分通识 SFT 数据、训练 pipeline 脚本,以及官方训练与评测环境。评估维度要同时看模型是否懂用户、懂物料、懂推荐、懂世界。

这里隐含了一个判断:下一代推荐模型应该具备世界理解能力。
OneReason 回答的是“推荐系统能不能思考”;挑战赛则把这个问题开放给外部团队,让更多人一起来回答,快手也把基座、数据、评测和人才入口一并拿出来共享。这种开放的态度,本身就是一种技术路线上的自信。
6
全程参与完沙龙,也与快手的同学交流了良久,我最大的感受是:快手在生成式推荐这件事上已经形成了连贯的演化路径。
从生成式推荐到思考,从搜索到生成式广告,再到算力,过手如登山,一步一重天,可以说快手走得极为稳健。
模型固然重要,但模型只是整套系统里的核心引擎。真正决定它能跑多远的,是背后的数据燃料、算力底座、业务场景和开放的生态。对快手来说,OneReason 是会思考的大脑,Pool-Rec 是动力系统,OneSearch 和 GR4AD 是真实场景,LLM-Rec 挑战赛则是把更多建设者邀请进了这条技术路线。
热闹的沙龙落下了帷幕,而挑战赛和竞争才刚刚开始。