RTK开源工具:四层压缩策略化解Token焦虑,命令输出成本直降80%
不久前,一位开发者用 Claude Code 重构一个老项目,干了一下午,效果不错——代码改动完成,测试通过,Git 提交也正常进行。
但当他顺手查看 token 用量时,直接傻眼:一个下午竟然烧了 6000 多万 token,套餐余额告急。
明明只改了几十个文件,怎么消耗这么多?翻看对话历史才恍然大悟,真正的“罪魁祸首”根本不是自己写的代码,而是那些命令输出。
npm install跑一次,依赖树打印几百行;cargo test执行完,99% 的通过信息全是绿色文字;git status列出一堆 untracked 文件——这些内容全被原封不动地塞进了 LLM 的上下文窗口。
而 AI 真正需要的信息,可能只有 5%,剩下 95% 都是毫无价值的日志噪音。
如果您也遇到过类似的问题,那 **RTK(Rust Token Killer)**这个工具值得您花三分钟了解一下。

需要提前说明一下:RTK 的本质是做一种权衡——用更少的上下文,换取更低的成本。在大多数场景下,被压缩掉的都是“噪音”,对结果影响很小;但在极少数需要完整上下文的场景(比如复杂调试),或许需要手动查看原始输出。
本文接近 6000 字,建议收藏,通过本文您将掌握:
- RTK 的四层压缩策略:每种策略分别针对什么类型的命令输出,如何实施压缩
- Auto-Rewrite Hook 的工作机制:RTK 如何在不改动主循环的情况下透明拦截命令输出
- 真实的 token 节省数据与成本换算:省下来的 token 到底值多少钱
- 与其他省 token 方案的对比:不同场景该选用什么工具
RTK 是什么
RTK是一个用 Rust 编写的 CLI 代理工具,专门为 AI 编程助手设计。它的定位十分清晰:在命令输出到达 LLM 之前做一轮智能压缩,去除噪音,只保留信号。
用一句话概括它的设计哲学:您照常使用 Claude Code,照常执行命令,只是 token 消耗在不知不觉中降下来了。
因为是用 Rust 编写的,RTK 的启动延迟不到 10ms,内存占用不足 5MB,单一二进制文件,零依赖。这些特性意味着它几乎不会成为您工作流中的负担。
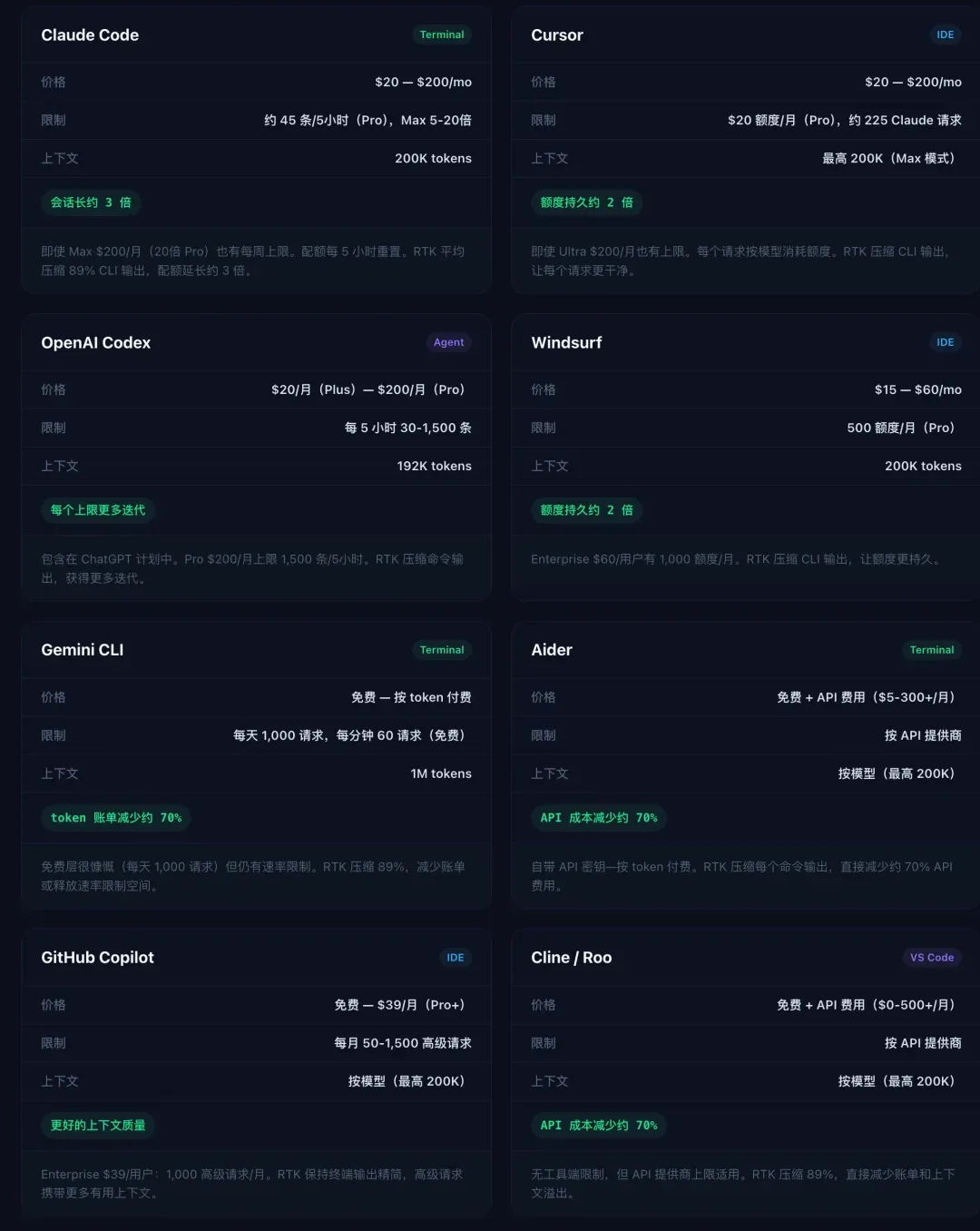
RTK 目前支持12 款 AI 编程工具:Claude Code、Cursor、Codex、Gemini CLI、Windsurf、Cline、Roo Code、OpenCode、OpenClaw、Aider、GitHub Copilot CLI、Augment。基本覆盖了主流选择。
四层压缩策略解析
RTK 的核心能力源于四种压缩策略,每种策略针对不同类型的命令输出。四层策略组合使用,RTK 会根据命令类型自动选择最合适的压缩方式。
智能过滤:剔除无用信息
这是最基础的一层。终端输出里有许多信息是给人类看的,LLM 完全用不上:
- ANSI 颜色码:
npm install时的绿色对勾、红色报错,LLM 不需要这些 - 进度条和旋转光标:下载依赖时的百分比动画、编译时的进度指示器
- 多余的空行和装饰性分隔线
举个例子,git push的原始输出可能有 15 行、约 200 token,包含远程仓库信息、对象计数、压缩进度等。经过 RTK 过滤后,可能只剩一行 ok main,约 10 token。
分组聚合:同类项合并为摘要
当输出包含大量同类信息时,RTK 会按目录或类型分组,输出更紧凑的摘要。
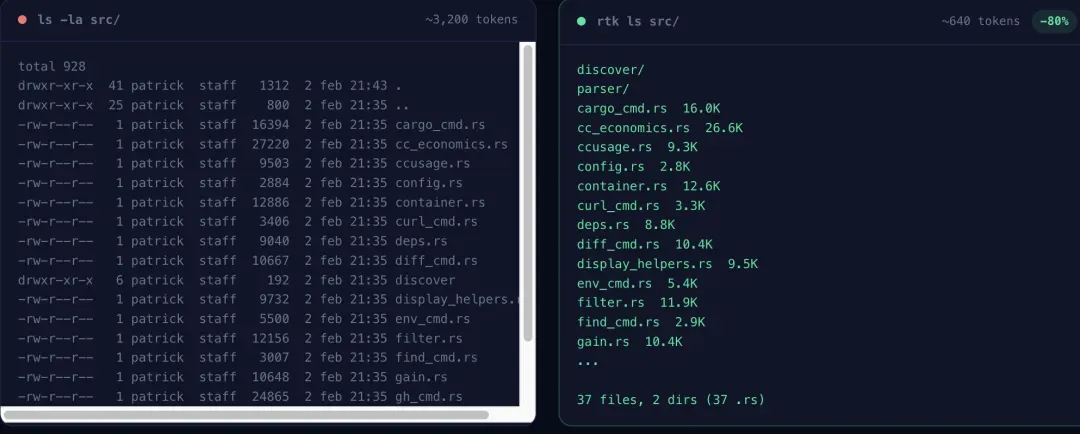
ls列出 100 个文件,原始输出 100 行。RTK 会将其变成“src/ 目录下 45 个 .java 文件”这样的描述。实测数据:ls / tree类命令,2000 → 400 token,节省 80%。
截断保留:只保留关键部分
测试命令的输出是 token 浪费的重灾区。跑一次 cargo test,100 个用例全部通过,每个用例一行 “test xxx … ok”——这些绿色通过信息加起来可能上千 token,但对 AI 来说毫无意义。
RTK 的处理方式是:保留失败的测试详情和错误堆栈,通过的测试只显示一行摘要——“95 tests passed”。实测数据:cargo test / npm test类命令,25000 → 2500 token,节省 90%。
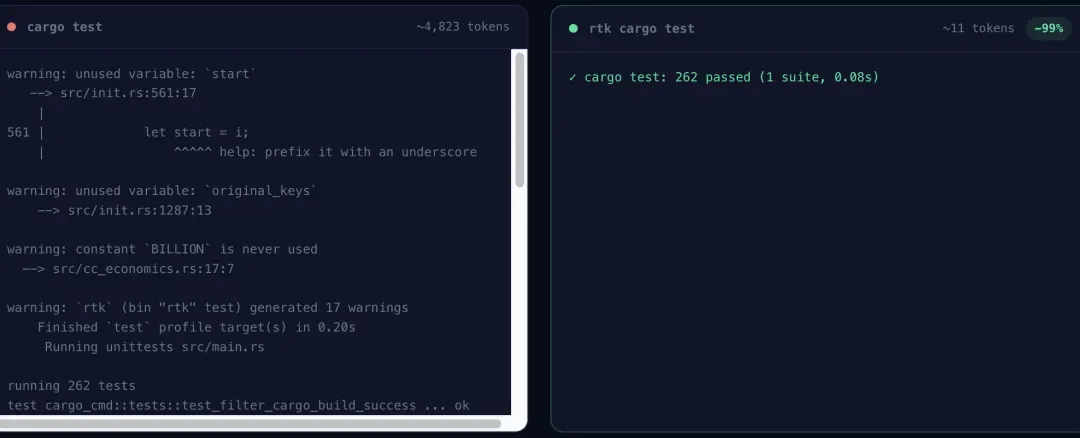
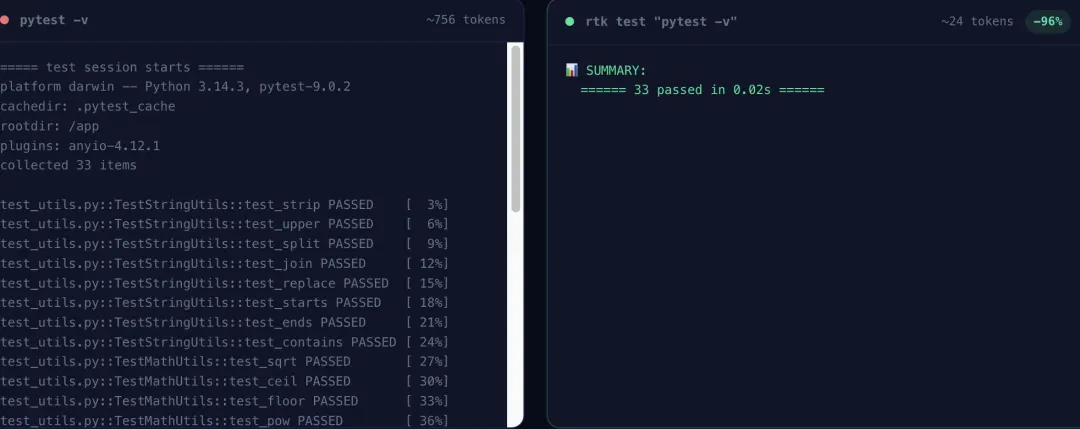
这里有个细节值得留意:RTK 的截断策略会优先保留尾部输出。因为大部分构建和测试工具的习惯是把错误信息放在最后,保留尾部意味着有更大几率保留到真正有用的诊断信息。
去重合并:将重复模式压缩为一行
构建日志里反复出现的 “Compiling…"、容器日志里统一格式的时间戳前缀——这些重复模式会被 RTK 识别并合并。
比如 Rust 项目 cargo build 输出了 50 行 “Compiling crate-name v0.1.0”,RTK 会将其压缩成一行 “Compiled 50 crates”。
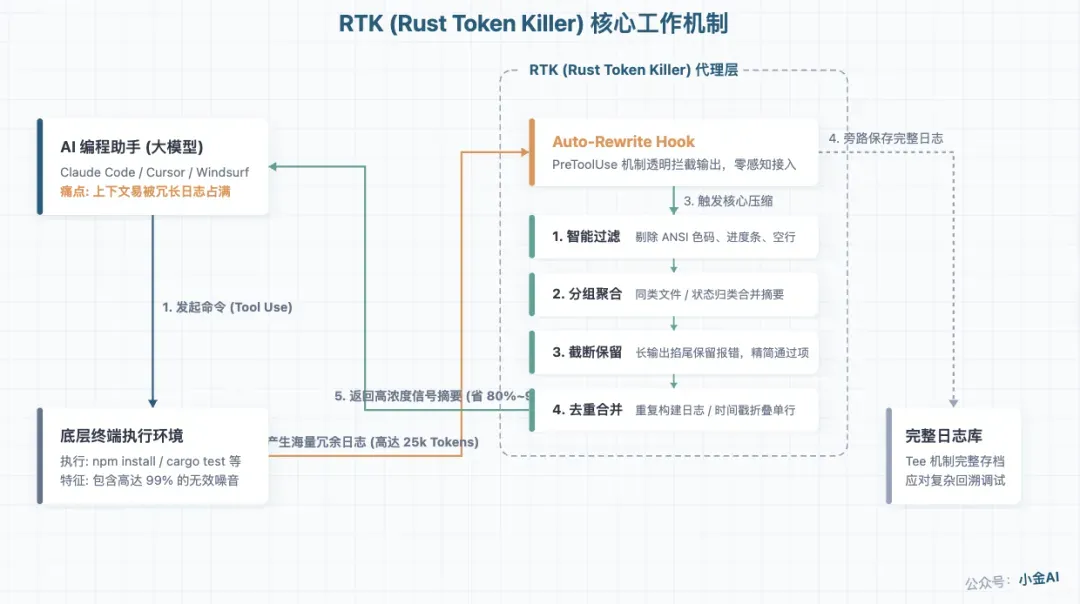
Auto-Rewrite Hook:透明的命令拦截机制
了解了压缩策略,您可能会问:RTK 是怎么拦截命令输出的?它需要修改 Claude Code 的代码吗?
答案是不需要。RTK 的核心技术是 Auto-Rewrite Hook——利用 Claude Code 等工具提供的 Hook 机制(通常是 PreToolUse hook),在命令执行完毕后、输出喂给 LLM 之前,透明地拦截并重写输出。
流程如下:
AI 执行命令
原始输出
RTK 压缩
精简输出
LLM 处理
- 您让 AI 执行
npm test - AI 通过 Bash 工具执行命令,拿到完整输出
- Hook 触发,RTK 接管这段输出
- RTK 应用压缩策略,生成精简版本
- 精简版本替换原始输出,喂给 LLM
对 Claude Code 来说,它完全不知道输出被改动过——它只知道命令执行完了,结果就是这些。对用户来说,原始输出仍然会显示在您的终端里,不会丢失任何信息。
这个设计十分关键:**RTK 不入侵主循环,不改工具链代码,不改变您的使用习惯。**它就像一个翻译器,在命令和 LLM 之间做一轮“翻译”,把给人看的长篇大论变成给 AI 看的精简摘要。
有人可能会担心:压缩之后,如果 AI 需要看完整的输出怎么办?
RTK 通过 tee 机制解决这个问题。原始输出被压缩后并没有被丢弃,而是通过 tee 管道保存在一个临时位置。当 AI 确实需要查看完整输出时(比如调试一个奇怪的测试失败),可以通过特定命令调取原始版本。
这就像快递打包——您把大箱子换成小箱子来节省运费,但大箱子还寄存于快递站,随时可以取回。
实际节省效果与成本换算
光说压缩比例可能不够直观,我们来算一笔实际的账。
各类命令的压缩效果
| 命令类型 | 原始 Token | 压缩后 | 节省比例 |
|---|---|---|---|
| ls / tree | 2000 | 400 | 80% |
| cat / read | 40000 | 12000 | 70% |
| git status | 3000 | 600 | 80% |
| git diff | 8000 | 2000 | 75% |
| cargo test / npm test | 25000 | 2500 | 90% |
换算成钱
以 Claude Sonnet 4.7 的定价为例:输入 $15/百万 token,输出 $15/百万 token。一次 30 分钟的 Claude Code 会话,假设压缩前消耗 118K token,压缩后 23.9K token,省了约 94K token。
按混合定价粗略计算,一次会话可省下 $0.3 - 0.5。一天开 5 个会话,一个月就是 $45 - 75。如果用的是 Opus 或更贵的模型,这个数字还要翻几倍。
有用户反馈在 Claude Code 上累计节省了 10M token(89%)。
查看节省统计
RTK 提供了两个命令来追踪节省情况:
rtk gain # 查看累计节省
rtk gain --graph # 30 天趋势图
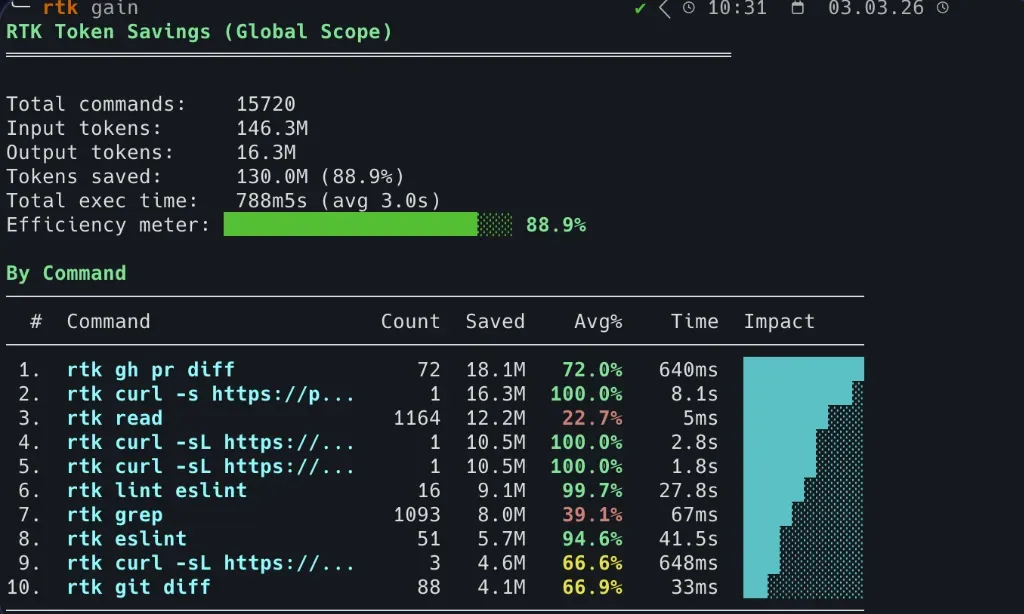
RTK 还提供 rtk discover 命令,可以分析您过去一段时间的命令历史,给出哪些命令消耗最多 token、哪些命令有最大压缩空间的洞察报告。
安装与配置指南
安装 RTK 只需一行命令,两种方式任选:
brew install rtk
或者:
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | sh
安装完成后,执行一次初始化:
# Claude Code
rtk init -g
# Cursor
rtk init -g --agent cursor
# Codex
rtk init -g --codex
# Windsurf
rtk init --agent windsurf
-g 表示全局配置,之后您在任何目录启动 AI 编程工具,RTK 都会自动接管命令输出。
重启您的 AI 编程工具,即告生效。整个过程不超过 30 秒。
卸载同样是一行命令:
rtk init -g --uninstall
与其他省Token方案的对比
RTK 并非唯一能省 token 的方案。来看看几个常见方案的定位差异:
| 方案 | 原理 | 效果 | 适用场景 |
|---|---|---|---|
| RTK | 压缩命令输出 | 最高 90% | 频繁执行终端命令的场景 |
| tokf | 类似的 CLI 过滤器 | 约 90% | 与 RTK 类似,功能稍少 |
| .claudeignore | 排除特定文件/目录 | 视项目而定 | 减少不必要文件进入 context |
| Compact Mode | Claude Code 内置压缩 | 30-50% | 探索阶段,快速浏览代码 |
| PTC | 私有工具调用,中间结果不进 context | 视使用频率 | 复杂任务链 |
这几个方案互不冲突,可以叠加使用。
综合建议:
- 终端命令密集型工作(测试、构建、Git 操作频繁)→ RTK 或 tokf 是首选
- 大型项目文件多,AI 经常读取无关文件 → 配合 .claudeignore
- 上下文窗口快满时→ 开启 Compact Mode
RTK 和 tokf 功能相似,RTK 的优势在于支持的工具更多(12 款 vs tokf 的几款),且提供了 rtk gain 和 rtk discover 等分析工具。tokf 则更轻量一些。两者都可尝试,选自己顺手的即可。
适用场景与局限性
适合使用的场景:
- 重度使用 Claude Code、Cursor 等 AI 编程工具
- 频繁执行测试、构建、Git 操作
- Token 消耗是真实痛点(成本或 context 上限)
不太需要的场景:
- 偶尔用 AI 写一点代码,token 消耗本就较低
- 主要用 AI 做代码解释、文档生成,很少执行命令
- 已经通过其他方式将 token 消耗控制在合理范围
需要注意的局限:
压缩的本质是删减,这意味着 RTK 有一定概率会删掉 AI 真正需要的信息,进而影响生成质量。例如调试一个偶发的测试失败,AI 可能需要看到完整的测试输出才能定位根因,而不是压缩后的摘要。RTK 的 tee 机制可以在这种情形下调取原始输出,但需要您主动操作。
不过从实际使用体验来看,RTK 误删关键信息的次数屈指可数,大部分时候压缩后的输出对 AI 来说已经足够。如果您的团队使用公司账户不担心成本,或者本来 Token 预算就很充裕,那自然无需纠结。
另外,对于非标准格式、自定义脚本的输出,RTK 内置的解析规则可能覆盖不到,压缩效果会打折扣。
总结
RTK 解决的问题虽然小众却非常真实:AI 编程助手的 token 消耗,相当一部分是被命令输出噪音吃掉的。
它的价值体现在三个关键词:省、稳、透。
- 省:80-90% 的 token 节省,按当前模型定价计算,很快就能回本
- 稳:单一二进制文件,零依赖,启动不到 10ms,不影响原有工作流
- 透:透明的 Hook 拦截机制,不入侵主循环,不改工具链代码
30 秒安装完毕,下次打开 Claude Code/Codex 或其他 AI Coding 工具即生效。如果您是 AI 编程工具的重度用户,RTK 值得一试。
项目地址:https://github.com/rtk-ai/rtk