从零构建多Agent系统:拆解Claude Code核心架构,84行代码到团队协作
很多人用过 Claude Code,也听过“Agent”“Tool Use”“Subagent”这些词,但如果被问到“Claude Code 底层到底怎么运转的”,大概率会沉默。
市面上能把 AI 编程 Agent 的架构从头到尾拆明白的教程,说实话几乎找不到。要么太学术,满篇论文术语;要么太浅,讲完“调用 API”就收工了。
有一个开源项目Learn Claude Code(GitHub 56.5K+ Star),干的事很简单:从 84 行核心循环开始,每一步只加一个机制,最终搭出一个完整的多 Agent 系统:工具调用、规划、子代理、记忆、任务调度、多 Agent 协作……
这个项目也有很多人推荐了,最近作者对整体教程做了大幅升级,这篇文章会把其中的关键设计抽丝剥茧,一步步讲透。
一共19 课,4 个阶段,代码透明,改动可追溯。

本文接近 8500 字,建议收藏,通过本文你将搞懂:
- Agent 的核心循环到底长什么样:一个 while 循环怎么撑起整个系统
- 从单 Agent 到多 Agent 需要解决哪些问题:上下文爆炸、任务编排、并发冲突,一个不落
- 每个机制的底层设计逻辑:每个机制都解决了一个真实痛点,没有多余的设计

一个核心认知:Model 是司机,Harness 是车
在聊代码之前,先搞清楚一件事。
智能来自模型训练,不是来自你写的代码。 这句话是 Learn Claude Code 整个项目的哲学基础。
打个比方:大模型是司机,你写的 Agent 框架是车。司机的驾驶技术是车企(Anthropic、OpenAI 们)通过海量训练数据练出来的,你没法替司机踩油门。但你能造一辆好车——给司机配上方向盘、仪表盘、刹车和安全带。
这辆车的名字就是前段时间刷爆技术圈的:Harness。
Harness 包含什么?工具(让 Agent 能读写文件、跑命令)、知识(按需加载的领域文档)、上下文管理(防止对话过长导致失忆)、权限控制(防止 Agent 瞎删东西)。模型负责思考和决策,Harness 负责提供手脚和边界。
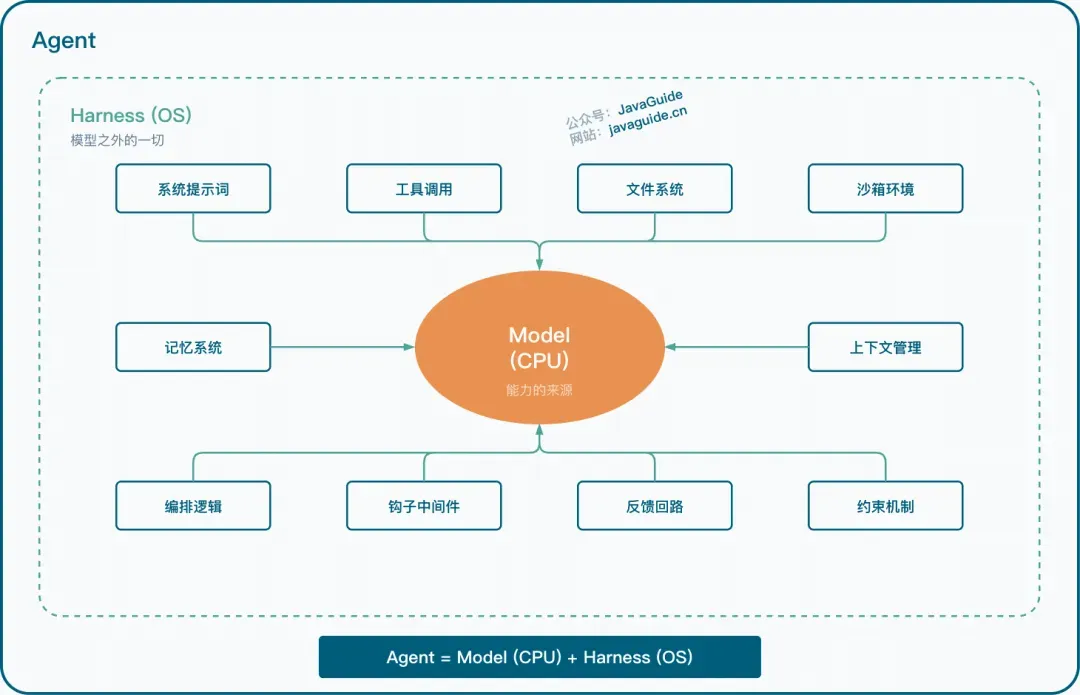
理解了这一点,后面的每一课就好懂了——本质上都是在给这辆车加零件。
Harness 的六层架构和上下文管理细节,之前专门写过一篇:一文搞懂 Harness Engineering:六层架构、上下文管理与一线团队实战,感兴趣的可以搭配着看。
第一阶段:Core Loop —— 所有 Agent 的起点
Agent Loop:84 行,就是一整个 Agent
所有 AI 编程 Agent,不管外表多花哨,底层都是同一个循环:
while True:
response = client.messages.create(messages=messages, tools=tools)
if response.stop_reason != "tool_use":
break
for tool_call in response.content:
result = execute_tool(tool_call.name, tool_call.input)
messages.append(result)
翻译成人话:把消息丢给模型,模型说“我要用工具”,就执行工具,把结果喂回去,继续问模型,直到模型说“我搞定了”。
就这 84 行代码,配上一个 Bash 工具,Agent 就能读写文件、跑命令、操作 Git。虽然粗糙,但它是一个真正能干活的 Agent。
如果你想要系统了解 AI Agent 核心概念,建议看看这篇文章:一文搞懂 AI Agent 核心概念:Agent Loop、Context Engineering、Tools 注册。Loop、Graph、Workflow 三者的区别在这篇里有讲:AI 工作流中的 Workflow、Graph 与 Loop:从概念到实现。
Tool Use:加工具就是加 handler
循环本身不变,新工具只需要写一个处理函数,注册到分发表里。想加文件读取?写一个 read_file 函数。想加网络请求?写一个 http_get 函数。加工具和加插件一样,核心循环不需要动。
TodoWrite:没有计划的 Agent 就是没头苍蝇
Agent 干着干着就跑偏了。这是所有人第一次用 Agent 时都会遇到的问题,根本原因是 Agent 不知道“我总共要干几件事,现在干到哪了”。
TodoWrite 的思路很直接:先列计划,再执行。Agent 在开始任务前,把步骤写到一个待办列表里,每完成一项就划掉。这个机制听起来平淡无奇,但在实测中,有计划的 Agent 完成率比没计划的高出一倍。
Subagent:子任务不能污染主对话
当一个任务需要分成几个子步骤时,直接在主对话里执行会有个问题:子步骤的中间结果(比如一堆日志输出)会塞进主对话的上下文里,越积越多,最终把模型搞糊涂。
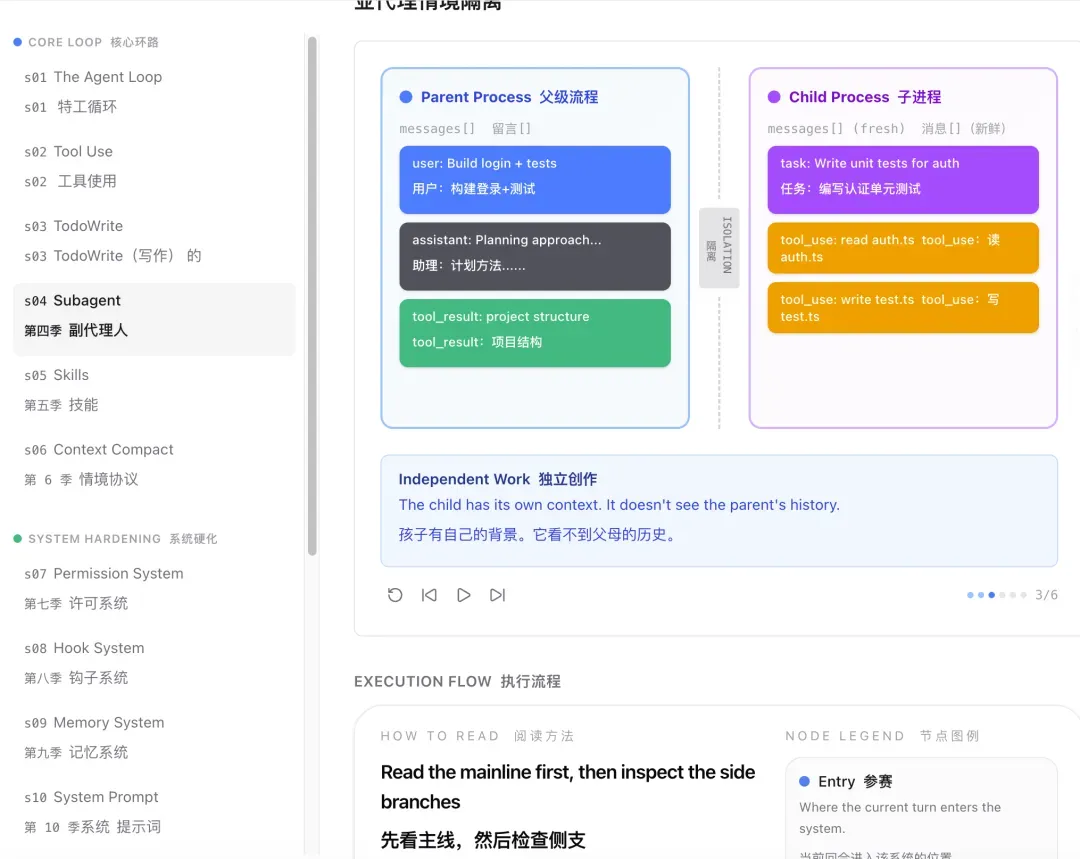
Subagent 的核心设计是:每个子任务拥有独立的 messages[]。子 Agent 干完活,只把最终结论返回给主对话,中间过程不带入。这就像你让同事帮忙查个数据,你只需要他给你一个结论,不需要他把翻文件的整个过程讲给你听。
Skills:知识按需加载,别一股脑塞进去
很多人喜欢把所有规则、文档、最佳实践全塞进 System Prompt。问题是上下文窗口有限,塞太多不仅浪费 Token,还会干扰模型的判断。
Skills 的设计哲学是:不用的知识不加载,需要时才通过工具返回喂入。Agent 先看到一个“知识目录”,知道有哪些 Skill 可用。当遇到特定场景时,通过 tool_result 的方式把对应的 Skill 文件内容加载进来。用完就丢,不占地方。
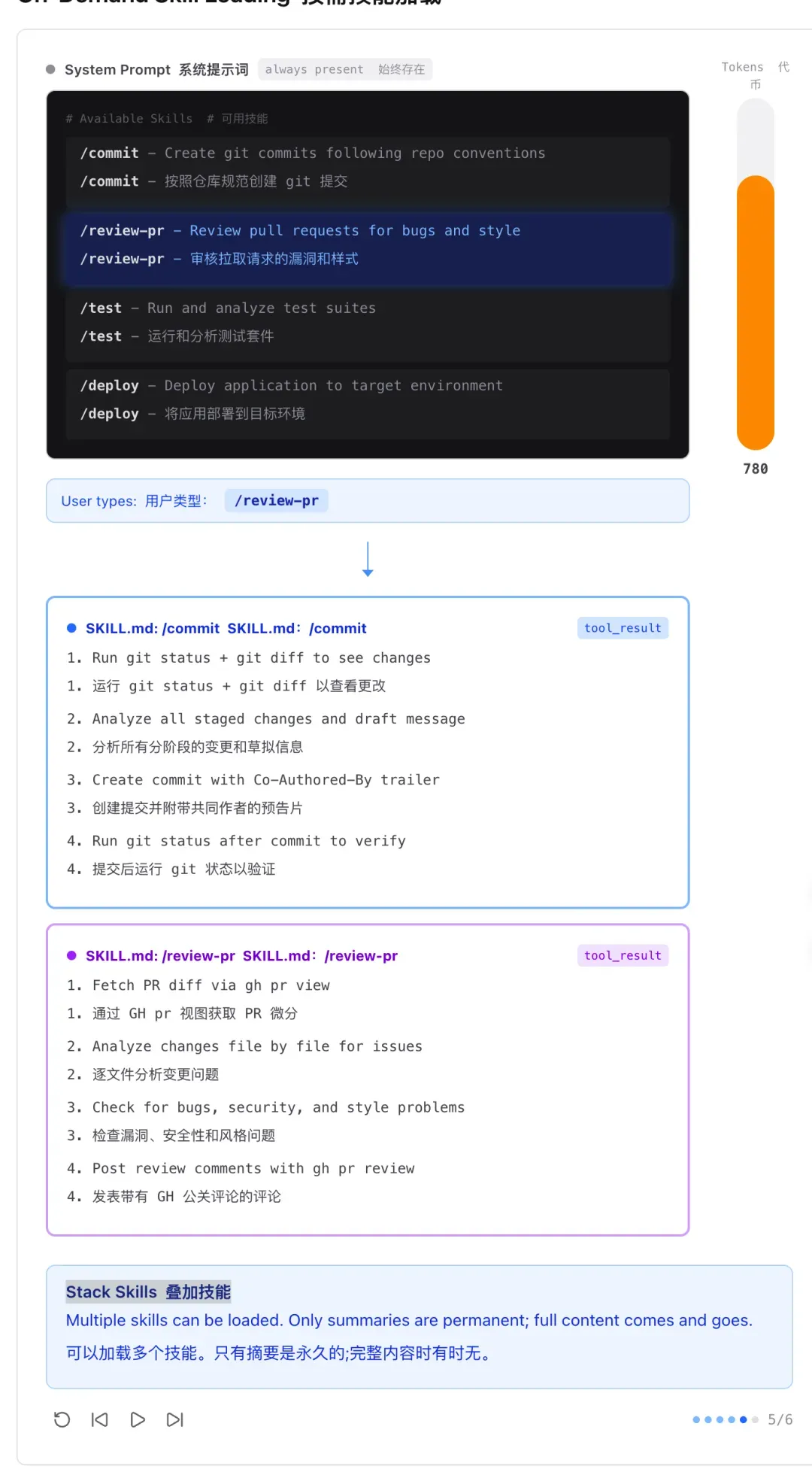
这和人类的工作方式很像——你不需要把整本《Java 编程思想》背下来,只需要在遇到具体问题时翻开对应章节。
Skills 和 Prompt、MCP 的区别在这篇里有详细对比:万字详解 Agent Skills:是什么?怎么用?和 Prompt、MCP 有什么区别?。
Context Compact:对话太长怎么办?
Agent 干的活越多,对话历史越长,Token 消耗就越夸张。更麻烦的是,上下文窗口是有上限的,超了就得截断,而截断意味着丢失信息。
Learn Claude Code 给出了三层压缩策略:
| 策略 | 做法 | 适用场景 |
|---|---|---|
| 滑动窗口 | 丢弃最早的消息 | 对话早期内容已不相关 |
| 摘要压缩 | 把历史对话压缩成一段摘要 | 需要保留整体脉络但不需要细节 |
| 选择性保留 | 只保留关键信息(如文件路径、关键决策) | 精细化管理上下文 |
这三层是组合使用的。先尝试滑动窗口,不够就上摘要,再不够就只留关键信息。核心思路是:压缩不是删历史,而是把细节搬个地方,让 Agent 能继续干活。
想搞清楚 Token 到底怎么计费、上下文窗口为什么有上限,看这篇就够了:万字拆解 LLM 运行机制:Token、上下文与采样参数。
第二阶段:System Hardening —— 让 Agent 可靠
第一阶段搭起来的 Agent 能跑,但脆弱得像一辆没有刹车和方向盘的车。第二阶段就是给它装上安全系统。
Permission System:安全不是一刀切
一个没有权限控制的 Agent,能执行任何命令、读写任何文件——这在开发时无所谓,上了生产就是灾难。
Permission System 的设计思路是:安全是一条流水线,不是一个开关。每个工具调用经过四道关卡:拒绝(黑名单直接拦)→ 检查模式(只记录不执行)→ 允许(白名单放行)→ 询问(不确定就问用户)。精细控制每个操作的信任等级,避免粗暴地全部放开或全部锁死。
Hook System:不抢方向盘,只按喇叭
Hook 机制是 Agent 系统里容易被忽视但极其重要的一环。它的设计原则是:循环拥有控制权,Hook 只在特定时刻观察、阻断或标注。
打个比方:Agent Loop 是司机在开车,Hook 是坐在副驾的导航员。导航员不能抢方向盘,但可以在关键路口提醒“前方限速”或者“这条路不通,换一条”。实际应用中,Hook 可以用来做日志记录、安全审计、自动审批等,完全不侵入主循环。
Memory System:记忆给方向,观察给真相
Agent 在长期工作中需要两类信息:记忆(之前做过什么决策、偏好是什么)和当前观察(现在文件长什么样、系统什么状态)。
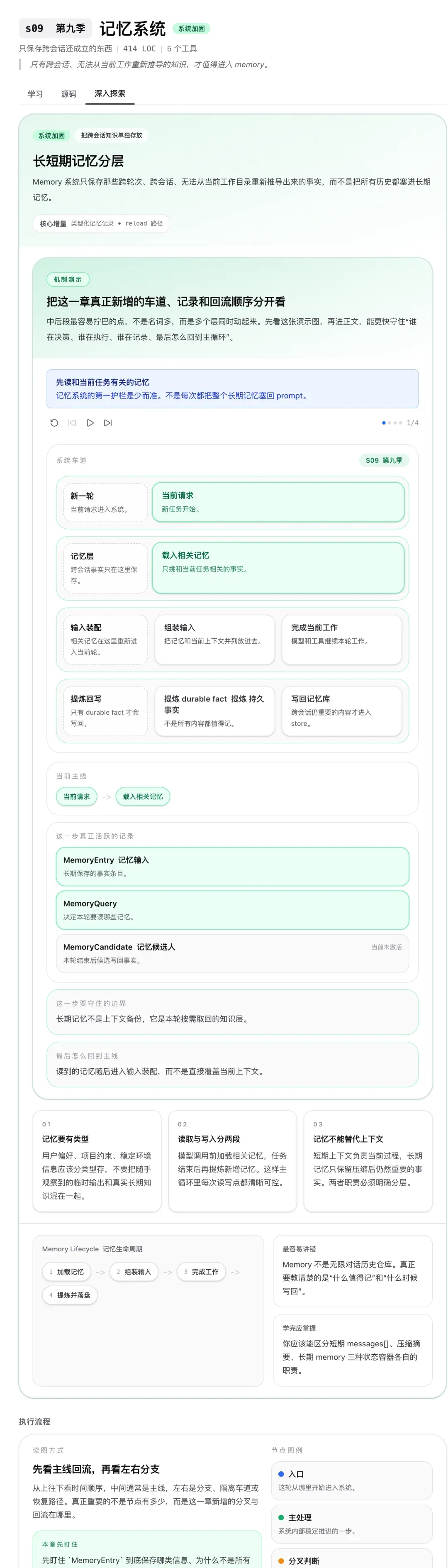
Memory System 的设计是:记忆提供方向感,避免 Agent 每次都从零开始;当前观察提供事实依据,防止 Agent 按过时的记忆做决策。两者缺一不可。
System Prompt:不是一坨静态字符串
很多人以为 System Prompt 就是一段固定的文本,启动时塞给模型就完事了。实际上,Claude Code 的 System Prompt 是一个构建好的输入管道——它会根据当前环境(操作系统、项目结构、工作目录)动态组装,不同时刻喂给模型的内容可能不同。
这个设计很重要:模型看到的信息应该是精心筛选的,而不是一股脑全塞。
提示词怎么写效果最好,这篇总结得很实用:大模型提示词工程实践指南。
Error Recovery:大多数失败不是真失败
Agent 执行任务时一定会遇到报错——命令找不到、文件不存在、网络超时。关键是 Agent 怎么处理这些错误。
Learn Claude Code 的设计是:大多数失败是“换条路试试”的信号,不代表任务搞砸了。 Agent 遇到报错时,分析错误原因,调整策略,尝试另一种方案。这个机制让 Agent 从“一碰壁就死”变成了“碰壁就绕路”,鲁棒性提升了一大截。
第三阶段:Task Runtime —— 让 Agent 干长活
前两个阶段的 Agent 还有一个局限:每次会话结束,所有状态就清零了。第三阶段解决的是持久化问题。
Task System:跨会话的任务管理
TodoWrite 管的是单次会话的计划,Task System 管的是跨会话的持久化工作。它把任务以文件形式持久化到磁盘,任务之间可以有依赖关系——任务 B 必须等任务 A 完成才能开始。
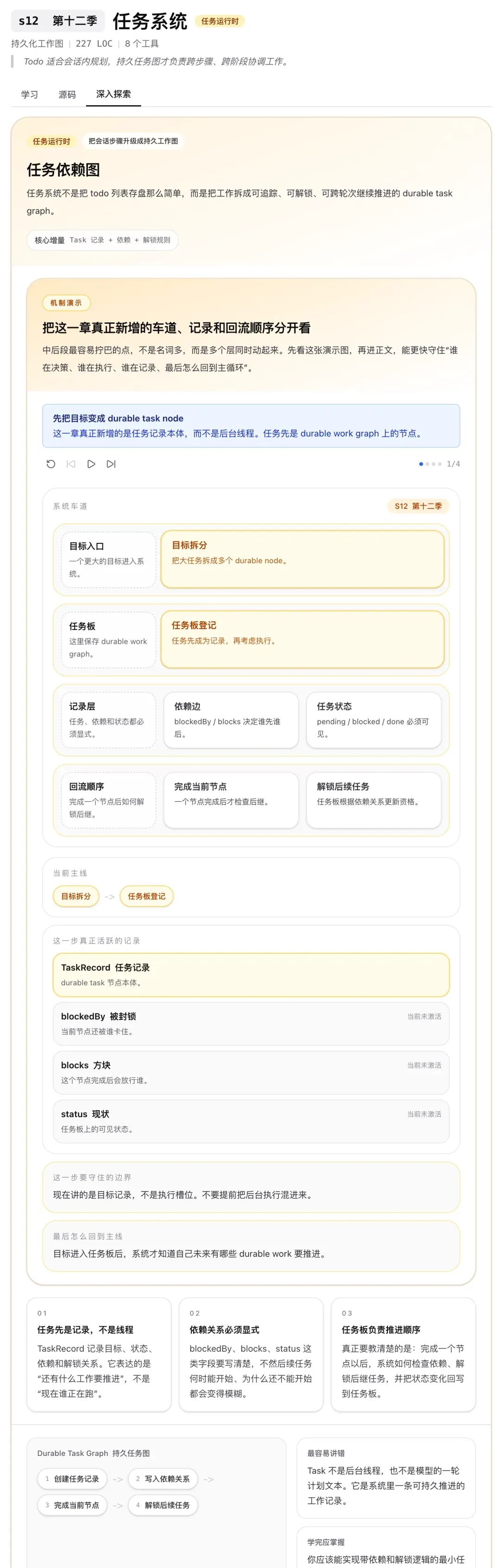
这和现实中的项目管理很像:Todo 列表是你今天的待办,任务看板是整个迭代的计划。前者帮你专注当下,后者保证大方向不乱。
Background Tasks:后台车道,不是第二辆车
有些操作天然耗时间——跑测试、装依赖、编译构建。如果 Agent 每次都干等这些操作完成,效率极低。
Background Tasks 的设计是:后台执行是一条独立的车道,和主循环并行但互不干扰。 Agent 启动一个后台线程去跑慢操作,自己继续思考下一步。后台线程完成后,通过通知队列告诉 Agent 结果。Agent 的主循环完全不变,只是多了一个“等通知”的环节。
Cron Scheduler:定时器喂循环,不是另起炉灶
定时任务的本质是什么?一个定时器在特定时刻往同一个 Agent 循环里投喂消息。
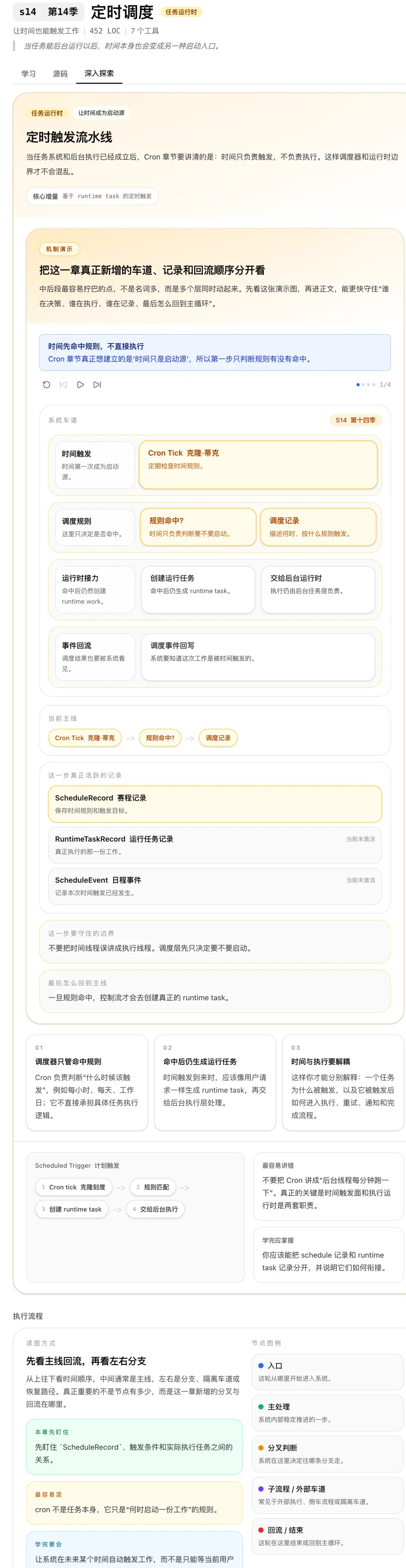
这个设计很优雅:不需要引入任何新的架构,只是多了一个时间触发的入口。Agent 本身完全不知道自己是被用户手动触发还是被定时器触发——它只管收到消息、思考、执行。
第四阶段:Multi-Agent Platform —— 多 Agent 协作
当任务大到一个人干不完时,就需要多个 Agent 协作了。这是整个学习路径的终极挑战。
Agent Teams:持久队友 + 异步邮箱
一个 Agent 干不完的活,就分给多个 Agent。多 Agent 协作的核心难题是“怎么通信”。
Learn Claude Code 的方案是:每个队友是持久存活的,通过基于文件的邮箱(JSONL 格式)异步通信。 主 Agent 给队友发一条消息,写在队友的邮箱文件里。队友有空了就读邮箱,处理完把结果写回去。不需要实时在线,不需要同步等待。
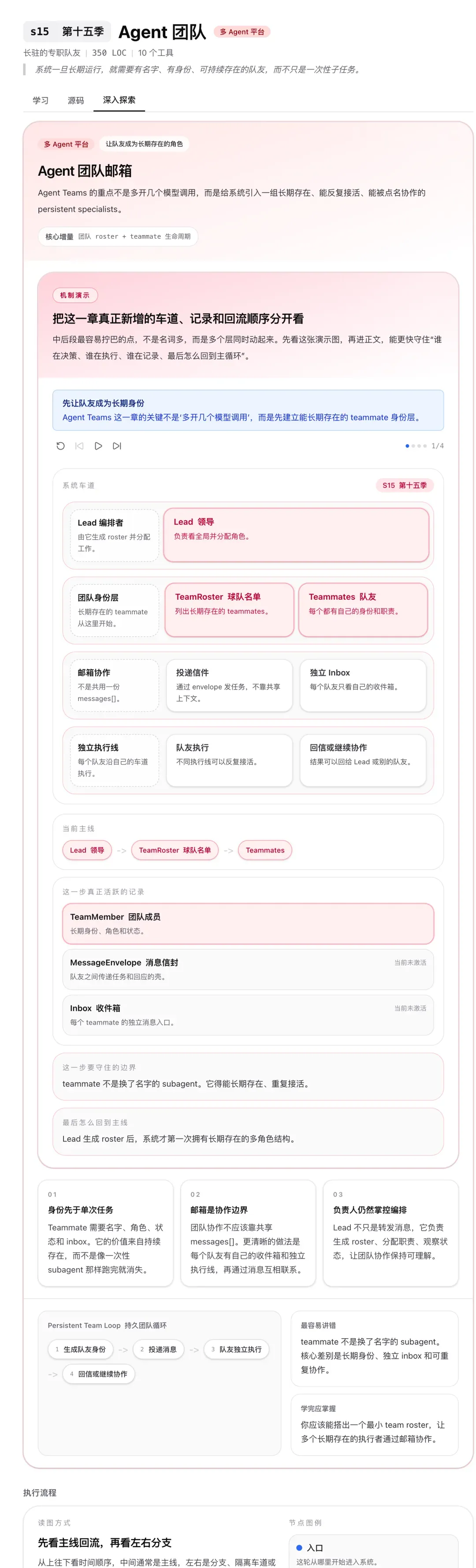
这和现实中的邮件协作一模一样——你给同事发封邮件,不需要他秒回,他处理完了回复你就行。
Team Protocols:统一的通信规则
多个 Agent 之间要协商,就需要一套统一的通信协议。Learn Claude Code 的设计是:每个请求带一个唯一 ID,响应必须引用同一个 ID。 这保证了在异步通信的环境下,请求和响应能正确配对,不会搞混。
Autonomous Agents:自主认领,不是被动等活
Agent Teams 的模式下,任务还是由主 Agent 分配的。Autonomous Agents 更进一步:队友自己扫描任务看板,发现能干的活就主动认领。
它的工作机制是一个有限状态机:空闲 → 扫描看板 → 认领任务 → 执行 → 回到空闲。主 Agent 不需要逐个分配,整个团队像一群自动运转的齿轮。
Worktree Isolation:各干各的,互不干扰
多个 Agent 在同一个目录下干活,文件冲突是必然的。Worktree Isolation 的解决方案是:每个 Agent 在自己独立的工作目录里操作。
任务系统管“干什么”,工作树管“在哪儿干”,两者通过 ID 绑定。Agent A 改文件不会影响 Agent B 的目录,最终由主 Agent 负责合并结果。
MCP & Plugin:外部能力走同一条路
MCP(Model Context Protocol)是 Anthropic 推出的外部工具接入协议。在 Learn Claude Code 的架构里,MCP 插件和原生工具走完全相同的路径——同样的路由、同样的权限检查、同样的结果回传机制。
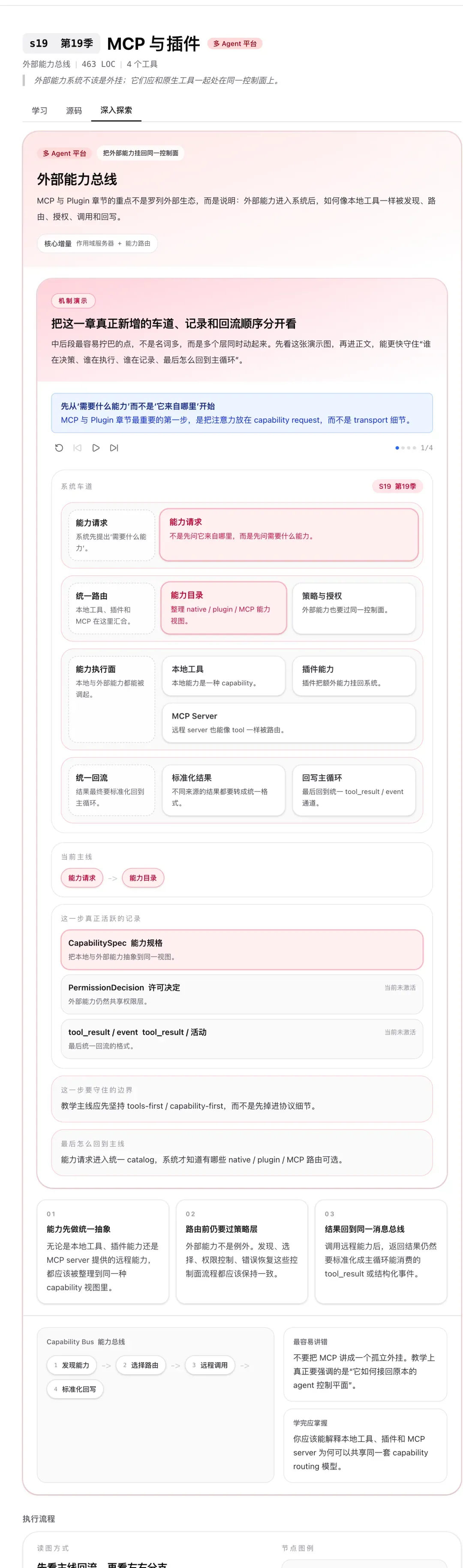
这意味着扩展 Agent 的能力不需要改架构,只需要接入新的 MCP Server 就行。工具是原生的还是外部的,对 Agent 来说完全透明。
MCP 的协议设计和实际接入经验,之前拆过一篇万字长文:万字拆解 MCP,附带工程实践。
全景回顾:19 课到底学了什么
| 阶段 | 课次 | 解决的核心问题 | 一句话总结 |
|---|---|---|---|
| Core Loop | s01-s06 | 让 Agent 能跑起来,有计划、有记忆、能压缩 | 从 84 行到 200 行,搭出一个能干活的单 Agent |
| System Hardening | s07-s11 | 让 Agent 可靠、安全、能恢复 | 装上刹车、方向盘和安全气囊 |
| Task Runtime | s12-s14 | 让 Agent 能干持久化任务 | 从一次性会话到跨会话协调 |
| Multi-Agent | s15-s19 | 让多个 Agent 协作 | 一个干不完,一组来,各干各的互不干扰 |
代码量递进:84 → 120 → 176 → 200 → 348 → 419 → 499 → 694 行,每一步的增量都清清楚楚。
如何上手
最直接的方式是克隆仓库,跟着跑:
git clone https://github.com/shareAI-lab/learn-claude-code
cd learn-claude-code
pip install -r requirements.txt
cp .env.example .env # 填入你的 ANTHROPIC_API_KEY
python agents/s01_agent_loop.py # 从第一课开始
项目还提供了一个交互式 Web 平台,可视化展示每个阶段的架构变化和代码差异:
cd web && npm install && npm run dev # 访问 http://localhost:3000
在线地址:https://learn.shareai.run/
如果你学完想直接用,项目还提供了两个延伸产品:
- Kode Agent CLI:开箱即用的开源编程 Agent 命令行工具,
npm i -g @shareai-lab/kode直接装 - Kode Agent SDK:可嵌入到你自己的应用中的 Agent SDK,无进程开销
总结
Learn Claude Code 最有价值的地方在于:它教你 Claude Code 是怎么被造出来的,而不仅仅是教你“怎么用”。
19 课走下来,你会理解一个核心事实:一个成熟的 Agent 系统,本质上是围绕一个简单循环堆叠的各种工程机制。 循环本身不变,变的是围绕它的工具注册、计划管理、上下文压缩、权限控制、任务持久化、多 Agent 协调。
这些机制不是凭空设计的,每一个都解决了一个真实痛点:没有计划会跑偏、上下文太长会爆、没有权限会乱来、一个 Agent 干不完就得多个来。理解了“为什么需要”,再去理解“怎么实现”,就水到渠成了。
而且,这些设计模式和语言无关。Python 能写,Java 能写,Go 也能写。核心模式是一样的,语言只是工具。
Agent 的协作范式(ReAct、Reflection、A2A 等)在这篇里有完整的梳理:万字详解 Agent 核心方式:ReAct、Reflection、A2A、Agentic Workflows。
项目地址:https://github.com/shareAI-lab/learn-claude-code