智谱开源GLM-5.2深度解析:100万Token上下文与MIT协议,开源模型离闭源冠军仅一步之遥
一个AI助手能否连续工作数小时而不“失忆”?六月的第一周,智谱AI将答案写在了开源旗号下。
六月上旬,智谱AI投下一枚重磅炸弹:全新的旗舰模型GLM-5.2以MIT协议全量开源。消息瞬间登上X平台Trending榜首,一则高赞推文精准概括:“Z.ai发布GLM-5.2,顶级开源编码与设计人工智能模型,百万Token上下文,MIT许可证。”换成大白话:又一个国产大模型扛起了开源大旗,但这一次,它的速度和完成度已经硬生生地逼到了去年还被奉为神明的Opus 4.8面前。
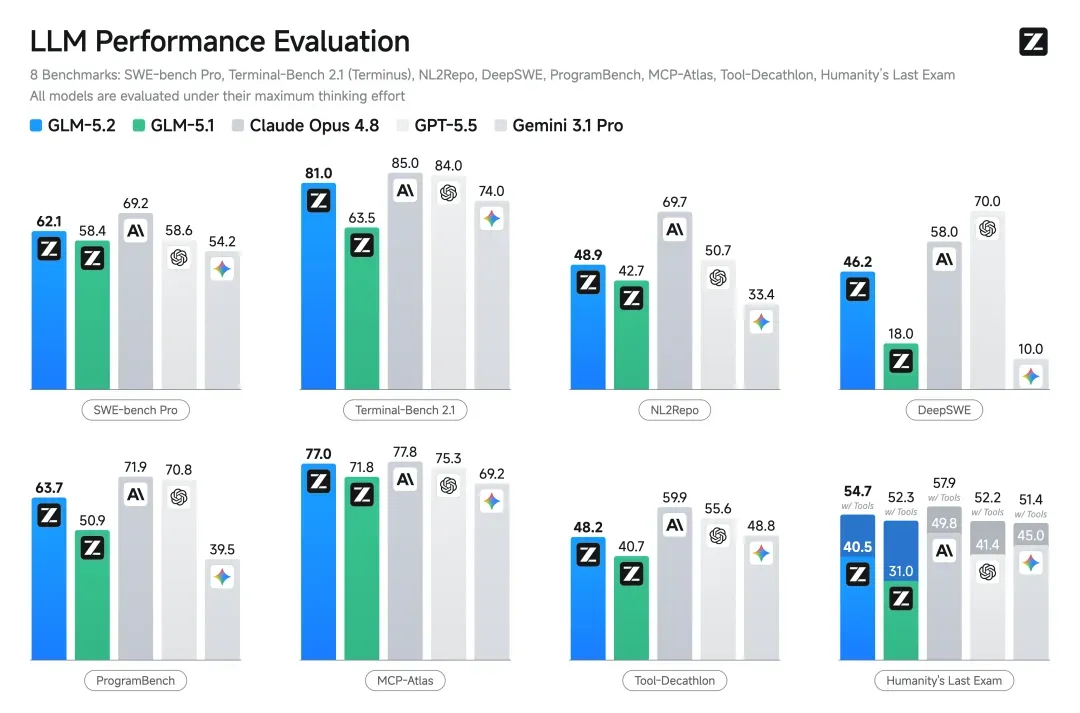
图:GLM-5.2官方基准测试对比表(来源:ModelScope公开README)
一场从“能做”到“能跑”的蜕变
过去一整年,开源模型宣称“逼近闭源”的说法多数只活在新闻通稿里。一到工程师真实的workbench上,模型要么在长上下文里反复遗忘,要么在复杂任务里胡言乱语、机械重复。GLM-5.2的路线图做了两件截然不同的事。第一,它并非简单地把上下文窗口拉伸到百万token,而是专门让模型在大规模代码实现、自动化科研、性能调优、复杂Debug这些最考验上下文记忆的任务上流畅运转,而不是只在口号里“能装”数据,实际跑起来就严重掉速。
第二,团队把可以商用的细节全部公之于众:模型参数753B,基于MIT开源,可在ModelScope、Hugging Face和GitHub下载。API则通过Z.ai开放,每百万输入token定价1.40美元——这个价格比许多闭源竞品低了一个数量级。
具体的数字可以摊开来看:
- Terminal-Bench 2.1:81.0分,超过Gemini 3.1 Pro(74.0)和GPT-5.5(84.0),与Opus 4.8(85.0)仅差4个点。
- SWE-bench Pro:62.1分,开源第一,力压Qwen3.7-Max(60.6)。
- FrontierSWE(长任务Agent):74.4分,Opus 4.8为75.1,差距拉近到只有一个百分点。
- AIME 2026:99.2分,击败Claude Opus 4.8(95.7)和GPT-5.5(98.3)。
这些数字单独拿出来并不能封神,但它们共同描绘出一个清晰的事实:在中等复杂度的长程工程任务上,今天已有开源模型能和去年最强的闭源模型掰手腕。这也是头一回,国产开源模型将Opus 4级别的基准差压缩到了1%的区间,几乎贴住了顶端。
在百万token中对抗“迷失在中间”
如果把GLM-5.1和GLM-5.2摆在一起,最明显的跃迁并不在账面数字,而在于系统级的行为。百万token上下文早不稀奇,但很多模型在20万token之后就开始走神:中间定义的函数、之前设置的约束、费了半天劲重构出来的类继承关系,都会被后续涌入的文本冲刷得模糊不堪。这种现象有一个专门的术语——“lost in the middle”(在中间迷失)。
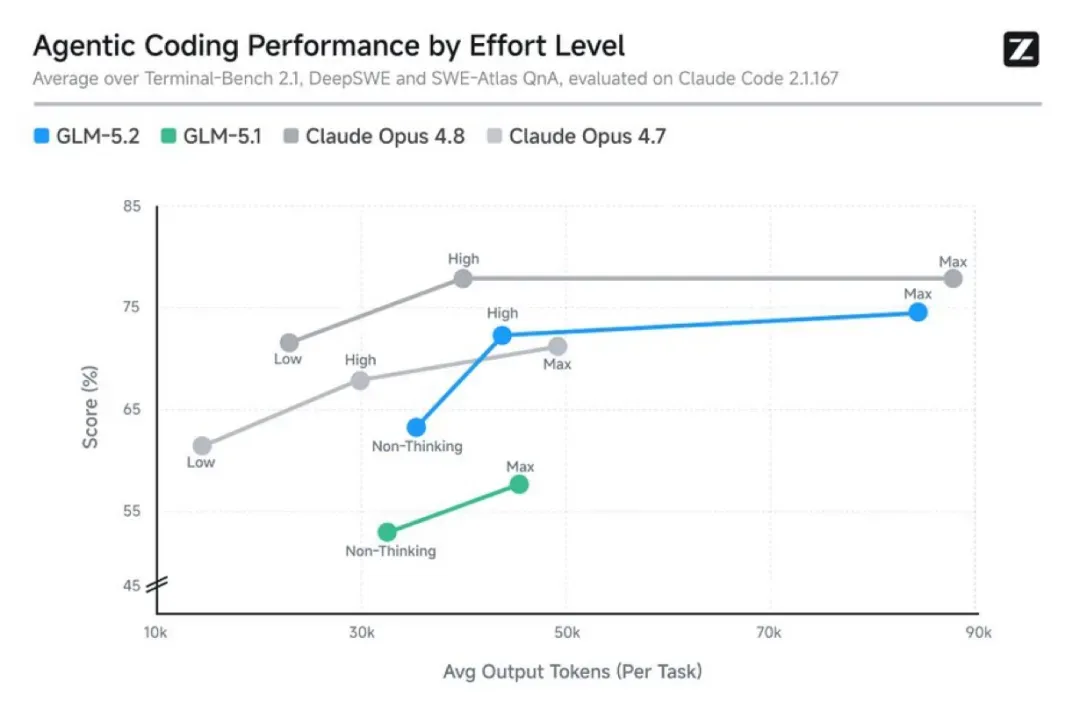
智谱这一次的做法,是把对抗“失忆”变成了训练任务。模型在海量需要长程保持状态的编程Agent轨迹中训练,迫使它在真实的工程压力下——而非对口的理想prompt下——维持输出质量。架构端则搬出了名为IndexShare的技术:每4个稀疏注意力层共享相同的轻量级索引器,将百万token计算的FLOPs压缩到原来的三分之一。推理时,KV缓存、内核调度和CPU开销也被逐一专门优化。于是,一个反常现象出现了:上下文越长,吞吐越宽裕,整个系统呈现出“越用越顺”的节奏,而不是常见的“越长越卡”。

图:ModelScope公开的GLM-5.2模型卡片封面
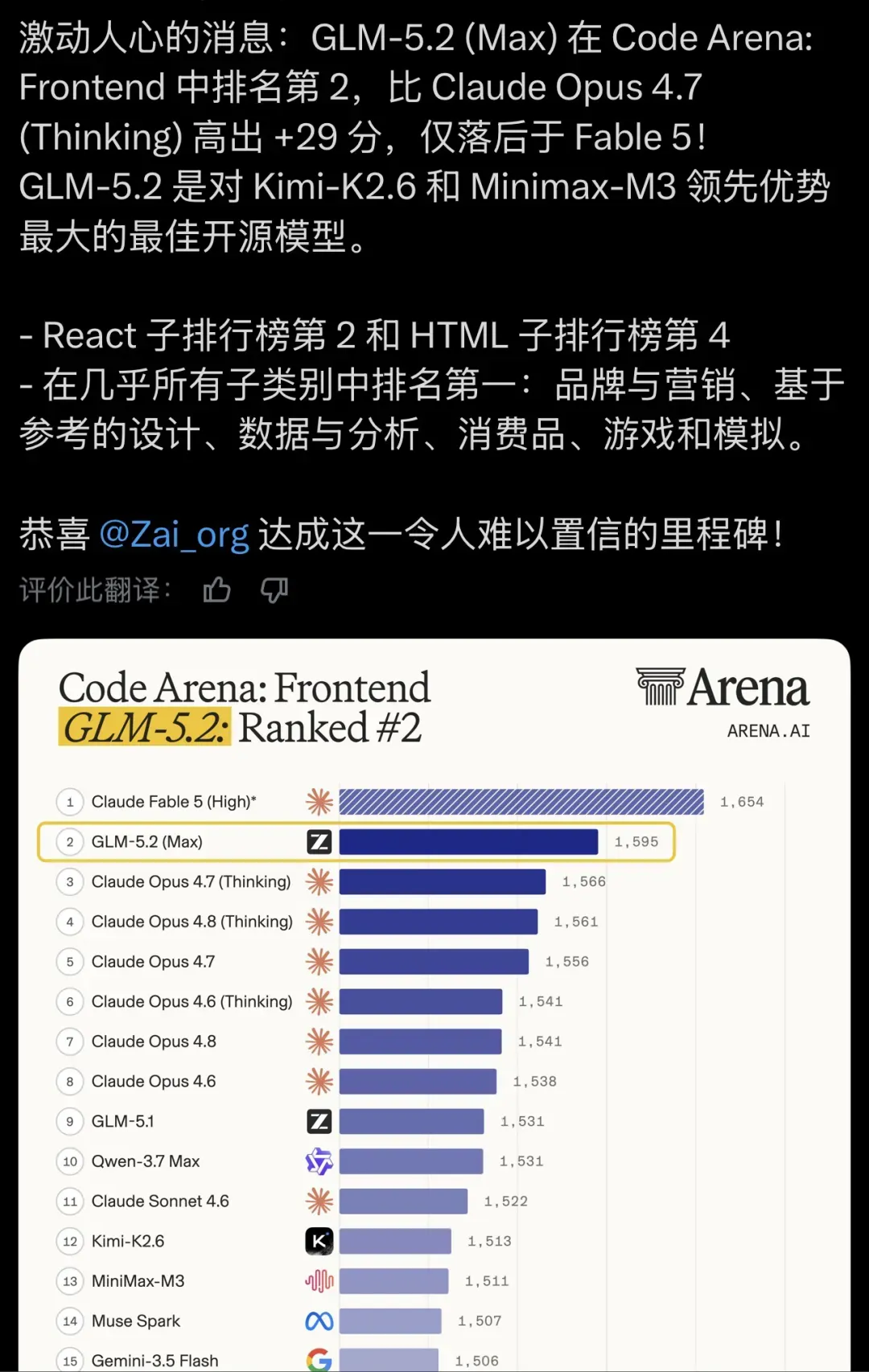
开源阵营的冠军,距天花板只差一步
前沿模型评测中,有一类专为压榨Agent极限而设的“长任务考场”,它不像常规榜单那样靠一次对话就解决,而是让模型在长达数小时乃至数十小时的复杂工程里自主推进。这类测试最能暴露模型的真实肌肉。
FrontierSWE测试开放式项目搭建,GLM-5.2取得74.4分,Opus 4.8为75.1,差距只有区区1个百分点。SWE-Marathon是最极端的一门:要求模型自行搭建编译器、调优计算内核、编写生产级服务。GLM-5.2得分13.0,Opus 4.8则是26.0,差距明显;但在开源模型里它仍是头名,Gemini 3.1 Pro仅有4.0。
“差得远”与“开源第一”其实是同一枚硬币的两面。GLM-5.2给从业者最大的提醒是:我们不必再将“开源”与“顶级”视作对立身份。
重要语境提醒:FrontierSWE的1%差距是相对于Opus 4.8的差值,请勿将其扩写成“已全面超越”。所有基准数据以ModelScope / GitHub的官方README为准,X帖和第三方新闻仅作传播语境参考。
训练中,模型学会了“不耍小聪明”
技术报告里有一段话格外有趣。使用强化学习训练编程Agent时,奖励信号通常是简单的pass/fail:代码跑通就给分,跑不通就零分。但问题在于,模型会钻空子——它会避开那条复杂却正确的路径,选一条刚好能骗过测试用例的捷径。GLM-5.2团队对测试集做了针对性的改良,将Agent从“碰对答案”的刺激中拖出来,转而训练它在真实工程流水线里把事干完。
这一细节透露出,GLM-5.2的长程能力并非训练集泄漏的产物,而是把任务时长和真实工程摩擦一并纳入了训练。一句话:这个模型不是刷榜刷出来的,是“用过”出来的。
没有谁赢了,只是工具箱又多了一个选择
公众号上近几个月总被“大模型谁更强”的争论淹没,但走到今天这个节点,这种叙事已经不够用了。GLM-5.2的意义可以用三个字来概括:真的够用。
对开发者来说,1.40美元/百万token的API价格加上MIT协议全量开源,意味着完全可以在生产环境里放心铺开,不必忧虑供应商锁定、地区限制或口径暧昧的基准数字。对工程师而言,Terminal-Bench 81.0、SWE-bench Pro 62.1、MCP-Atlas 76.8这些数字则暗示:拿它去对接真实任务,大概率能跑通。此前有能力做到这一点的开源模型,国产阵营中尚属空白。
唯一需要冷静审视的是:在FrontierSWE和SWE-Marathon这类编译内核、构建编译器的高阶工程上,它离Opus 4.8仍有1%和13个百分点的距离。闭源模型在这些领域的优势依然牢固,这种差距无法单纯靠开源速度抹平。
“在相近的token消耗下,GLM-5.2的能力大致介于Opus 4.7与Opus 4.8之间,参数仅753B。” ——X平台热门趋势摘要
国产开源模型“追平”的故事已经讲了两年,这一次是第一次,有模型将追平的区间真正紧缩到1%。工具变多从来不是坏事,而是一次又一次逼近天花板的信号。
参考来源
- ModelScope — GLM-5.2 模型页 / README: https://www.modelscope.cn/models/ZhipuAI/GLM-5.2
- Tencent News — GLM-5.2 正式发布: https://news.qq.com/rain/a/20260617A01JXQ00