树莓派CM5 8GB运行8款本地LLM实测报告:速度、准确度与实用性深度对比
在 Blackdevice 团队,我们持续挖掘小型硬件平台的性能上限。本次测试采用了自研 Pi Hack 载板,搭载 8GB 内存的树莓派计算模块 5(CM5),并配备 256GB NVMe 固态硬盘。测试目标非常清晰:部署 Ollama 工具,运行多款轻量化本地大语言模型(LLM),使用统一提示词对比各模型的实际表现。本地离线运行大模型的优势十分诱人:数据隐私自主可控、全程无需联网、模型完全由用户掌控。但在硬件资源紧缺的设备上,这份优势能否转化为流畅、真正可用的体验?提前透露结论:部分模型令人惊喜,另有不少模型实用性很弱。本文会完整呈现部署流程、测试方案、各模型实测性能数据以及我们体验后的逐模型评价。
什么是 Ollama?
Ollama 是一款命令行驱动的本地大模型运行工具。它不依赖云端 API,可将模型直接拉取到本地设备(ollama.com/search),通过终端与模型交互。对本次测试而言,它的两大关键优势是:
- 所有数据存储在本地,全程离线运行;
- 模型下载、加载、推理全流程透明可观测。
当前使用的 Pi Hack 载板仍处于实验阶段,而 Ollama 非常适合在这样受限的硬件上快速开展可控的多模型对比测试。
硬件清单与初始系统部署
所用硬件
- Pi Hack 树莓派 CM5 专用载板
- 树莓派计算模块 5(CM5),8GB 内存
- 256GB M.2 接口 NVMe 固态硬盘
- 以太网供电模块(PoE),同时提供网络与设备供电
磁盘系统烧录步骤
- 使用 rpi-boot 工具将设备 eMMC 闪存 / NVMe 硬盘映射为主机可识别的外置存储设备;
- 打开树莓派镜像烧录工具,将 64 位树莓派官方系统烧录至 NVMe 固态硬盘,令设备从固态硬盘启动。
首次开机配置
- 连接显示器、键盘及 PoE 供电网线,完成首次启动;
- 开机后获取设备局域网 IP,通过电脑 SSH 远程连接设备。
在 Pi Hack 载板上安装 Ollama
按顺序执行以下终端命令:
- 更新系统并安装基础依赖工具
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl wget jq git ca-certificates
- 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
- 验证 Ollama 安装与后台服务状态
ollama --version
sudo systemctl status ollama
基准测试方案:实验设计
为确保公平对比,我们制定了一套标准化、可复现的测试流程。所有模型使用完全相同的提示词,运行时开启 –verbose 详细日志模式,采集完整的性能统计数据。
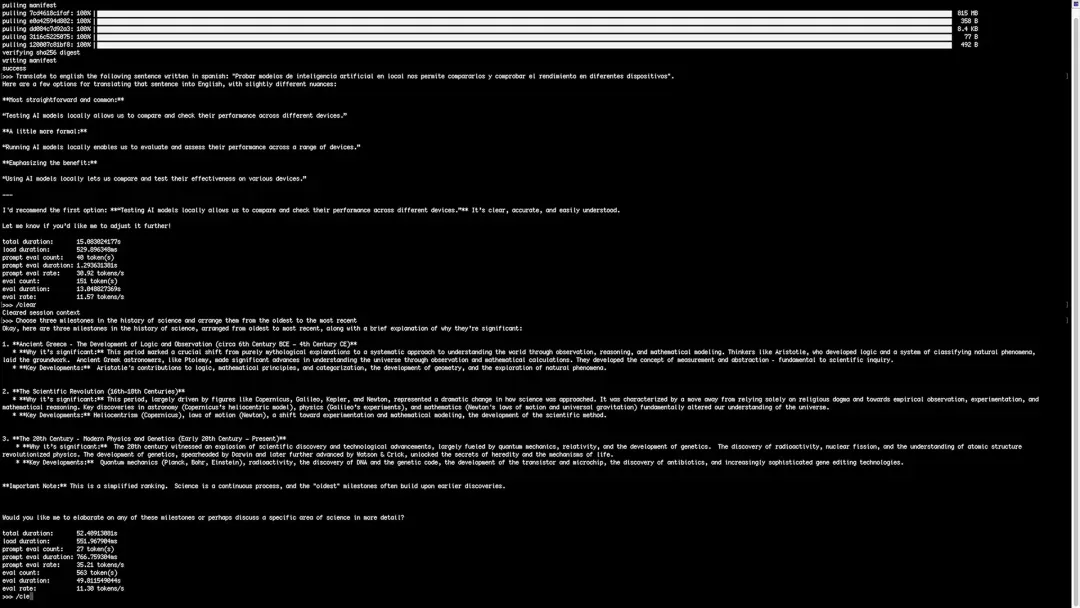
- 提示词 1(翻译任务):将以下西班牙语句子翻译成英文:Probar modelos de inteligencia artificial en local nos permite compararlos y comprobar el rendimiento en diferentes dispositivos.
- 提示词 2(历史梳理任务):选出三项科学史上里程碑事件,按从远古到近代的顺序排列。
两类任务能够直观揭示模型能力的差异:基础语义理解、文本结构化输出、文字生成速度。所有模型均在完全相同的硬件环境(8GB 内存 CM5 + NVMe 固态)中下载并运行,任务难度适配轻量化小模型。
参与测试的模型
本次通过 Ollama 测试了多款轻量化开源大模型:
- TinyLlama 1.1B
- Deepseek R1 — 1.5B, 7B and 8B
- Gemma3 — 270M, 1B and 4B
- Phi-4 mini reasoning — 3.8B
针对每一组模型,我们都使用两种提示词分别运行,并对生成结果与原始性能指标展开分析。
下面列出受测模型的完整运行命令:
- tinyllama (TinyLlama 1.1b) — ollama run tinyllama:1.1b –verbose
- deepseek-r1:1.5b — ollama run deepseek-r1:1.5b –verbose
- deepseek-r1:7b — ollama run deepseek-r1:7b –verbose
- deepseek-r1:8b — ollama run deepseek-r1:8b –verbose
- gemma3:270m, gemma3:1b, gemma3:4b — ollama run gemma3: –verbose
- phi4-mini-reasoning:3.8b — ollama run phi4-mini-reasoning:3.8b –verbose
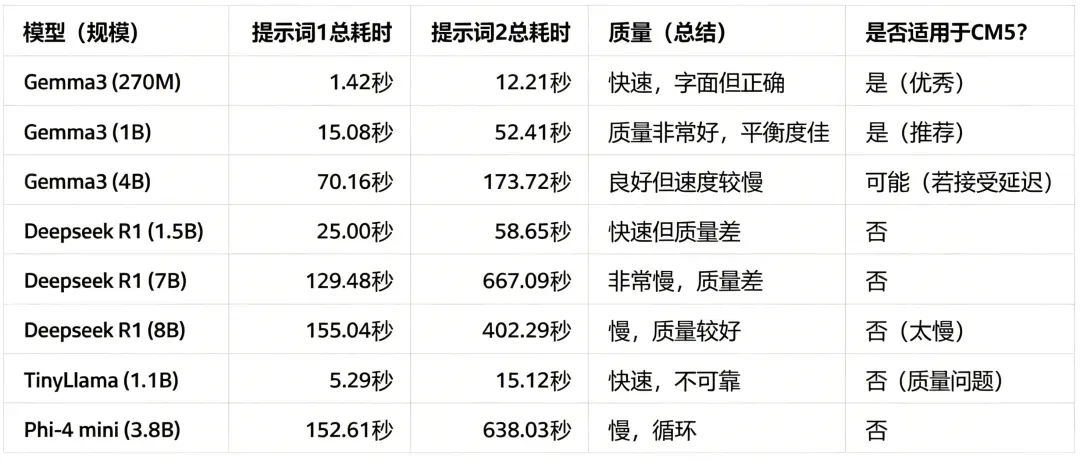
树莓派硬件 AI 模型基准测试汇总表
观看测试视频
各模型实测原始数据与测评点评
Deepseek R1: 1.5B
输出质量:生成速度尚可,但文本质量十分糟糕。翻译任务中将西班牙语 “en local(本地)” 错误地理解为地理地点;历史里程碑任务给出的事件不准确,时间顺序和年份均有错误。
提示词 1 性能数据:
- 总耗时:25.00 秒
- 模型加载耗时:222.91 毫秒
- 提示词 token 总量:40,提示词推理耗时 1.87 秒,吞吐 21.37 token/秒
- 生成 token 总量:261,生成耗时 22.60 秒,吞吐 11.54 token/秒
提示词 2 性能数据:
- 总耗时:58.653 秒
- 模型加载耗时:208.187 毫秒
- 提示词 token 总量:23,提示词推理耗时 0.992 秒,吞吐 23.17 token/秒
- 生成 token 总量:641,生成耗时 56.703 秒,吞吐 11.30 token/秒
总结:尽管生成速度不算太慢,但内容准确度严重不足,完全无法投入实际使用。
Deepseek R1: 7B
输出质量:生成速度大幅下降,回答逻辑混乱、错误高频出现。模型会产生大量无意义的循环推理,输出质量完全无法匹配过长的等待时间。
提示词 1 性能数据:
- 总耗时:2 分 9.477 秒(约 129.48 秒)
- 模型加载耗时:227.324 毫秒
- 提示词 token 总量:40,提示词推理耗时 8.961 秒,吞吐 4.46 token/秒
- 生成 token 总量:294,生成耗时 1 分 59.887 秒,吞吐 2.45 token/秒
提示词 2 性能数据:
- 总耗时:11 分 7.088 秒(约 667.09 秒)
- 模型加载耗时:224.595 毫秒
- 提示词 token 总量:23,提示词推理耗时 4.734 秒,吞吐 4.86 token/秒
- 生成 token 总量:1473,生成耗时 11 分 0.373 秒,吞吐 2.23 token/秒
总结:在 8GB 内存 CM5 设备上运行极慢,耗时与输出质量严重失衡。
Deepseek R1: 8B
输出质量:输出内容比 7B 版本略有改善,但运行速度依然极慢;回答结果勉强可用,但等待成本高到难以接受,实用性很低。
提示词 1 性能数据:
- 总耗时:2 分 35.038 秒(约 155.04 秒)
- 模型加载耗时:252.184 毫秒
- 提示词 token 总量:39,提示词推理耗时 9.297 秒,吞吐 4.19 token/秒
- 生成 token 总量:295,生成耗时 2 分 25.208 秒,吞吐 2.03 token/秒
提示词 2 性能数据:
- 总耗时:6 分 42.290 秒(约 402.29 秒)
- 模型加载耗时:216.430 毫秒
- 提示词 token 总量:21,提示词推理耗时 4.802 秒,吞吐 4.37 token/秒
- 生成 token 总量:769,生成耗时 6 分 36.656 秒,吞吐 1.94 token/秒
总结:能够启动,但运行极度缓慢;相比小参数量 Deepseek 模型有输出提升,但时间成本过高,综合表现一般。
Gemma3: 270M
输出质量:速度飞快,翻译直译准确,足以应对极简任务,在 CM5 上表现极为亮眼。
提示词 1 性能数据:
- 总耗时:1.416 秒
- 模型加载耗时:264.957 毫秒
- 提示词 token 总量:40,提示词推理耗时 0.161 秒,吞吐约 248.5 token/秒
- 生成 token 总量:24,生成耗时 0.898 秒,吞吐约 26.7 token/秒
提示词 2 性能数据:
- 总耗时:12.205 秒
- 模型加载耗时:258.755 毫秒
- 提示词 token 总量:28,提示词推理耗时 0.104 秒,吞吐约 269.0 token/秒
- 生成 token 总量:284,生成耗时 11.295 秒,吞吐约 25.1 token/秒
总结:极小参数量模型中吞吐能力顶尖,回答结果可用,适合简单场景。
Gemma3: 1B
输出质量:同参数量级里输出质量优秀;翻译任务会给出多版译文并附带推荐,生成速度与内容丰富度平衡出色。
提示词 1 性能数据:
- 总耗时:15.083 秒
- 模型加载耗时:529.896 毫秒
- 提示词 token 总量:40,提示词推理耗时 1.293 秒,吞吐 30.92 token/秒
- 生成 token 总量:151,生成耗时 13.048 秒,吞吐 11.57 token/秒
提示词 2 性能数据:
- 总耗时:52.409 秒
- 模型加载耗时:551.967 毫秒
- 提示词 token 总量:27,提示词推理耗时 0.767 秒,吞吐 35.21 token/秒
- 生成 token 总量:563,生成耗时 49.811 秒,吞吐 11.30 token/秒
总结:CM5 设备上综合表现最优的模型,输出质量高,延迟可接受,适配绝大多数本地轻量化需求。
Gemma3: 4B
输出质量:速度慢于 1B 版本,但回答细节更丰富;针对本次测试的简单提示词,1B 版本已完全够用且响应更快,4B 模型的加载和生成耗时显著增加。
提示词 1 性能数据:
- 总耗时:1 分 10.156 秒(约 70.16 秒)
- 模型加载耗时:536.921 毫秒
- 提示词 token 总量:40,提示词推理耗时 4.529 秒,吞吐 8.83 token/秒
- 生成 token 总量:251,生成耗时 1 分 4.728 秒,吞吐 3.88 token/秒
提示词 2 性能数据:
- 总耗时:2 分 53.720 秒(约 173.72 秒)
- 模型加载耗时:537.524 毫秒
- 提示词 token 总量:28,提示词推理耗时 2.750 秒,吞吐 10.18 token/秒
- 生成 token 总量:639,生成耗时 2 分 49.515 秒,吞吐 3.77 token/秒
总结:输出质量良好,但针对简单任务存在明显的算力冗余;1B 版本是综合性价比最优的选择。
TinyLlama: 1.1B
输出质量:生成速度快,但输出极不稳定。一次翻译任务出现明显错误,历史事件梳理内容准确度低。性能略优于小参数量 Deepseek R1,但整体弱于 Gemma3 系列。
提示词 1 性能数据:
- 总耗时:5.285 秒
- 模型加载耗时:83.223 毫秒
- 提示词 token 总量:77,提示词推理耗时 2.880 秒,吞吐 26.73 token/秒
- 生成 token 总量:39,生成耗时 2.298 秒,吞吐 16.97 token/秒
提示词 2 性能数据:
- 总耗时:15.123 秒
- 模型加载耗时:93.980 毫秒
- 提示词 token 总量:57,提示词推理耗时 1.240 秒,吞吐 45.95 token/秒
- 生成 token 总量:244,生成耗时 13.706 秒,吞吐 17.80 token/秒
总结:响应速度快,但输出内容杂乱、错误较多,无法稳定可靠地使用。
Phi-4 mini reasoning: 3.8B
输出质量:模型擅长深度推理,但运行速度极其缓慢;针对本次简单任务会产生大量无效推理循环(尤其在第二条提示词中)。最终答案或许正确,但等待时间完全不可接受。
提示词 1 性能数据:
- 总耗时:2 分 32.606 秒(约 152.61 秒)
- 模型加载耗时:277.632 毫秒
- 提示词 token 总量:48,提示词推理耗时 5.185 秒,吞吐 9.26 token/秒
- 生成 token 总量:453,生成耗时 2 分 26.460 秒,吞吐 3.09 token/秒
提示词 2 性能数据:
- 总耗时:10 分 38.034 秒(约 638.03 秒)
- 模型加载耗时:267.611 毫秒
- 提示词 token 总量:36,提示词推理耗时 2.339 秒,吞吐 15.39 token/秒
- 生成 token 总量:1783,生成耗时 10 分 32.768 秒,吞吐 2.82 token/秒
总结:在 8GB 内存 CM5 上处理此类简单任务完全不具备实用性。
本文测试了多款轻量化大语言模型在原生不面向 AI 算力场景的嵌入式硬件上的运行表现。测试结论十分清晰:所有模型均可正常启动运行,但 Gemma3 系列的运行速度与资源效率远超预期。在极简嵌入式硬件上本地部署大模型,能够直观看清各模型真实的运行表现、性能上限,以及在小型嵌入式设备上的实际落地价值。
本次测试也为后续硬件横向对比建立了基准。接下来我们将在不同设备上使用相同模型、相同提示词复现测试,客观评估新款硬件的性能,统一衡量不同平台在同等测试条件下的真实算力水平。

