百川智能押注医疗AI:以OpenEvidence为蓝本,王小川的背水一战
10月22日,百川智能发布其号称最强循证增强大模型M2 Plus,该模型被喻为“医生版ChatGPT”。评测数据显示,M2 Plus在医疗场景下的幻觉率较通用大模型显著降低,与DeepSeek相比降低了约三倍,其可信度表现甚至优于美国热门的医疗AI产品OpenEvidence,达到了堪比资深临床医生的水准。
此次发布中,有两个关键词尤为值得关注:OpenEvidence 与 幻觉率(尤其是相较于DeepSeek)。新模型的核心目标直指降低幻觉率,而其选择的技术路径与对标的标杆产品,正是OpenEvidence。
OpenEvidence在今年的垂直领域Agent赛道中无疑是明星产品,备受赞誉。例如,在之前的红杉资本闭门会议上便有观点指出,在企业级市场,真正的入口或许并非通用大模型,而是如Harvey(法律)、OpenEvidence(医疗)这类深植行业的垂直智能体操作系统,因为它们能真正理解行业术语与实际需求。
由此,百川智能的战略意图变得清晰:其目标是将自身打造为国内版的OpenEvidence。因此,我们有必要深入剖析一下这位“资本宠儿”——OpenEvidence。
OpenEvidence 的产品定位
当前AI领域新品与论文层出不穷,对于需要持续跟进前沿动态的人士而言,筛选有效信息已成为负担。医学领域同样面临文献爆炸式增长的挑战,顶级期刊的文献量大约每五年就会翻倍。传统检索工具效率低下,而AI搜索虽能提升效率,但其固有的模型幻觉问题在关乎生命的医疗场景中风险极高。
正如相关研究《Why Language Models Hallucinate》所指出的,幻觉从模型设计之初便难以根除。一旦发生,可能引发严重后果。此前,在查询某知名科技公司相关争议案例时,一些通用模型可能会生成细节完备但完全失实的“案例”,这对于内容创作者尚难以接受,更遑论可能直接影响患者诊疗决策的医疗信息。
为此,OpenEvidence提出了以证据驱动为核心的理念。其通过实时、智能地检索权威医学文献来生成答案,从而规避幻觉。该平台的核心理论是来源可靠、可追溯。它严格采用经过同行评审的医学研究及权威指南作为知识来源,避免直接抓取未经筛选的网络信息,并承诺 “每个回答都有出处”,所有结论均基于可信的医学证据提供支持。
这一设计思路精准地诠释了当前构建专业AI知识库的重点:并非盲目扩展模型的多模态等通用能力(这些领域竞争激烈且易被取代),而是专注于弥补模型在特定领域的专业知识(Know-How)和数据深度上的不足。这一点可参考百川智能的相关图示。
OpenEvidence主要服务于医疗工作者,特别是临床一线的住院医师、门诊医生以及实习/规培医生。之所以聚焦一线,是因为资深专家通常经验丰富且有助理协助处理基础信息工作。实际上,国内也有类似产品为院内医生提供服务,但往往在系统性与精细化程度上有所欠缺。
根据已披露的数据,OpenEvidence目前覆盖了超过一万家医疗机构,声称每日有数十万医生使用,已成为历史上增长最快的医生端平台之一。从产品设计理念上看,其方向无疑是正确的,且构建了极高的行业壁垒。然而,这条路径面临一个巨大挑战:数据积累的成本极高。在OpenEvidence验证此路可行之前,其他公司或领域大多不敢轻易尝试。
如今,OpenEvidence的成功,无疑为整个AI行业指明了一个技术方向,并增强了业界在数据工程上持续投入的决心。
OpenEvidence 的行业意义
如前所述,要构建能够处理多意图、多轮复杂问答的专业级数字分身AI项目,极度依赖于高质量的数据建设。从成本结构分析,这类项目中,大约20%的投入在研发,而高达80%的费用则花在数据层面。因此,企业在投入前必须看到成功的标杆案例。OpenEvidence恰恰提供了这样一份令人满意的答卷。
OpenEvidence成立于2022年,产品于2023年发布,并在2025年迎来爆发式增长,其融资历程清晰地反映了市场的认可:
- 2025年2月(A轮):由红杉资本领投,融资约7500万美元,公司估值超过10亿美元。
- 2025年7月(B轮):融资2.1亿美元,估值跃升至35亿美元,累计融资额超过3亿美元。
- 2025年10月(C轮):再融资约2亿美元,公司估值高达60亿美元。
值得强调的是,OpenEvidence的成功并非一蹴而就,其背后是持续的数据积累。根据相关行业研究,其早期便致力于从同行评审文献和官方指南构建知识库:2024年前已有高校图书馆将其列为学习工具;2025年通过与《新英格兰医学杂志》(NEJM)、《美国医学会杂志》(JAMA)等顶级期刊达成多年期内容合作,系统性地纳入了可回溯至1990年代的付费期刊全文历史库。
正是这些扎实的数据工作,支撑了OpenEvidence高质量的回答能力,使其来源可靠、可追溯的承诺得以落实。总而言之,OpenEvidence为AI行业开了一个好头,尤其是在被视为AI应用元年的当下。接下来,我们探讨其技术实现路径。
OpenEvidence 的技术路径
简而言之,OpenEvidence采用了RAG(检索增强生成)技术,并构建了一个多模型协作系统。
其工作流程是:系统首先从专业的医学数据库中检索相关文献(包括PubMed文章、FDA药品标签等),然后将检索到的证据内容输入定制化的医学大语言模型,生成附有文献引用的回答。这种做法正逐渐成为生产级AI应用的标准配置,能确保回答基于现有证据,有效降低模型“幻觉”风险。
特别值得一提的是其模型架构,这也是生产级AI应用的常见做法:采用多模型融合策略。系统并非依赖单一模型,而是使用一个模型集群,让每个模型专注于其最擅长的任务,如检索、摘要、问答、图表解析等,从而实现“术业有专攻”。
创始人Daniel Nadler曾强调避免使用单一大模型,而是采用一个各有专攻的模型集群。一个关键的细节是:他们也在自行训练专用模型,例如训练视觉模型来解析医学论文中的图表和表格数据。
这一点在其团队构成和融资用途中也有体现,资金被用于训练下一代医学领域专用大语言模型,并组建顶尖的交叉学科团队。具体技术思想可追溯到2023年的论文《Do We Still Need Clinical Language Models?》,该研究实证表明,小型、领域专用的临床模型在多项临床文本任务上可以胜过参数量大得多的通用大模型。
当前公开的详细信息有限,但可以推断其模型训练重点在于:
- 在自建权威文献库中精准检索**“对临床问题最相关”的证据条目,核心优化目标在于控制成本与提升响应效率**,而不仅仅是追求极致的模型能力。
- 进行视觉模型的相关训练,以补足当前大模型在图像理解方面的短板。例如,在眼科等领域,使用一万张专业图片进行微调即可获得显著效果,而以往厂商可能因投入产出比不高而缺乏这类细分领域数据。
至于引用链的构建,在医学知识库完备的情况下相对直接。真正的难点在于构建符合医疗逻辑的思维链(CoT)。这需要数据工程与AI工程的无缝协作。简而言之,OpenEvidence的“医疗逻辑”采用证据锚定式解释,而非开放性的自由联想。
例如,在临床决策支持场景,其逻辑是:简短结论 + 关键要点 + 强制引用支持,若无可靠证据则直接拒答;在教学解释场景,其逻辑是:清晰展示推理依据。综上,OpenEvidence以RAG技术为骨架,使用受控的高质量语料库,并通过自研的小模型将每一步推理牢牢绑定回证据源,从而最大限度压低幻觉率,并保证结果可复核。
这大致是其技术路径,也为其他行业的专业AI应用提供了可直接参考的范本。
OpenEvidence 的实际使用
目前,OpenEvidence的核心功能是作为医疗智能问答与检索工具,通俗讲就是面向医生的AI问诊助手。在这方面,国内的MedGPT、左手医生、百川智能等也都有不错的表现。典型的使用体验是:医生输入具体的病情描述或临床问题(如诊断疑问、治疗方案对比、药物副作用、检查流程等),系统从医学知识库中提取关键信息,生成答案并提供参考文献链接。
与传统静态知识库不同,AI在整合海量专业知识方面能力突出,因此被医生们誉为“口袋里的专家小组”。适用场景包括:
- 查询罕见并发症、疑难杂症的最新处理方案与指南。
- 紧急情况下,快速通过手机应用询问药物精准剂量或替代方案。
虽然OpenEvidence初期用户定位于医学专业人员,但其模式可以很快扩展至消费者端(2C)。并且,其商业模式不担心高昂的Token费用,因为历史上已有成功的买单方。
OpenEvidence主要采用免费 + 广告的盈利模式。凭借免费、专业、易用的特点,它在医生群体中口碑传播极快。数据显示,其每月约有6.5万名新的美国医生注册。巨大的流量自然带来了医疗相关广告的营收,这构成了公司的主要收入来源。据第三方机构Sacra估算,截至2025年6月,OpenEvidence的年化营收约为5000万美元,毛利率高达约90%。
无论从用户评价还是财务数据看,OpenEvidence都展现出了巨大的潜力。至此,我们已对OpenEvidence有了较为全面的了解,再回头审视百川智能的此次发布,其脉络就非常清晰了。
百川智能的“医生版ChatGPT”
从百川智能官方披露的信息来看,其强调的重点同样是攻克模型幻觉难题。为此,他们推出了六源循证推理范式,其逻辑与OpenEvidence高度相似,核心在于对医疗数据进行精细化的分层治理:
- 原始研究层:索引超过4000万篇医学期刊论文,覆盖基础与临床研究成果。
- 证据综述层:整合系统评价和Meta分析等高等级证据。
- 指南规范层:引入国际与国内权威临床指南、专家共识。
- 实践知识层:包含临床病例、一线专家经验等实用知识。
- 公共健康教育层:汇集权威疾病预防与健康科普内容。
- 监管与真实世界层:涵盖药监公告、临床试验及真实世界研究数据。

在构建完善的知识库基础上,百川搭建了实现医疗思维链(CoT)的框架,重点围绕循证检索与循证推理展开,核心目标是让AI像医生一样思考。测试数据显示其取得了不错的成绩。
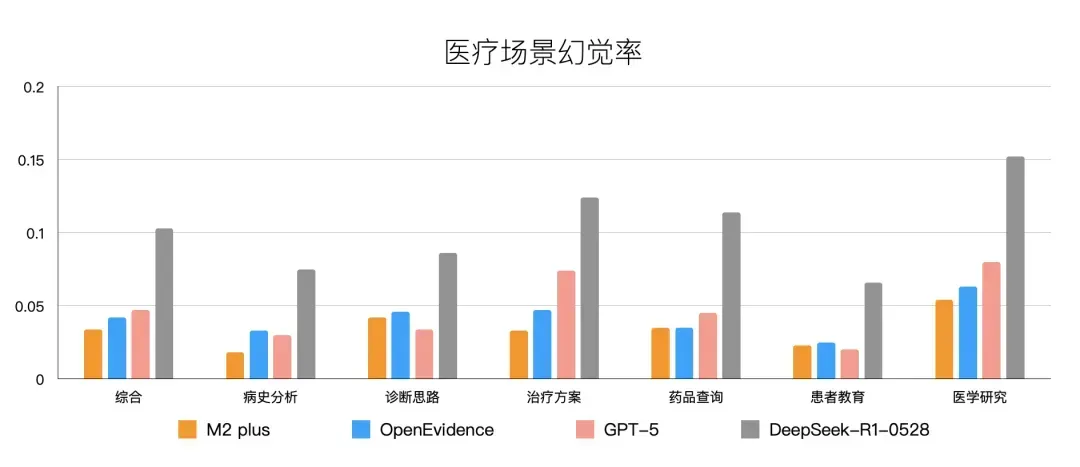
当然,当前行业评测存在一定“刷榜”现象,实际效果仍需在真实场景中检验。以下案例展示了其应用界面。
无论如何,对于百川智能此次在医疗AI领域的坚决跟进,笔者持乐观态度。作为一名曾经的医疗从业者,也期待他们能持之以恒,毕竟该公司似乎正面临不小的挑战。
百川智能的困局
从各方信息来看,百川智能乃至其创始人王小川,当前处境可能并不轻松。

2023年,王小川怀揣“打造中国OpenAI”的雄心创立百川智能。然而两年后,核心团队已分崩离析。作为一名长期关注医疗AI的观察者,笔者此前便判断其原有路径难以持续,原因无他:初期摊子铺得过大。
百川智能最初旨在攻坚通用大模型。然而,单就医疗领域而言,参照OpenEvidence的经验,所需准备的数据量就极其庞大。百川智能几乎不可能同时解决多个行业的生产级应用问题,即便有清晰的技术路径,也缺乏足够资本去完成所有领域的数据工程建设。
受挫之后,王小川于今年最终将赛道聚焦于医疗AI场景。从各个角度看,这都是一个明智的选择。而此次产品发布之所以明确对标OpenEvidence,很可能也是看中了后者所展现的巨大估值潜力。
那么,为什么做好医疗AI可能成为一场翻身仗?答案在于AI时代下的流量入口重塑。只要能占据医疗健康信息的入口,即便是最基础的广告业务,其规模也极为惊人。毕竟,传统搜索引擎在健康问题解答上的市场正在被侵蚀,那么,医疗广告这块大蛋糕未来将由谁来分食?
结语
通过此次产品发布,我们看到了王小川及其百川智能在医疗AI板块背水一战的决心。通过对OpenEvidence的深入剖析,我们也认同这是一条经过验证的、正确的道路。
然而,OpenEvidence所代表的路径就一定是康庄大道吗?恐怕也未必。即便是OpenEvidence,在实际应用中也存在一定的错误率(现阶段约为9%,且持续优化中)。在医疗领域,这意味着每100次交互中仍有9次可能出错,这种风险是行业必须严肃对待的(尽管人类医生的误诊率也不容忽视)。
所有专业数字分身类AI项目都有一个共同特点:强烈的性能提升非对称性。你可能仅需10万元就能做出一个60分可用的产品,但想提升到90分可能需要投入100万元,而从90分提高到95分,或许需要1000万甚至更多。
以OpenEvidence一个常被引用的典型错误为例:在慢性疲劳综合征的治疗建议中,它曾推荐一种已被证明可能有害的“分级运动疗法”,而该建议所依据的竟是13年前的过时指南。这个案例首先说明了OpenEvidence系统的“可观测性”和可优化性,但也警示我们,想要将正确率持续稳定在极高水平,需要长时间的、昂贵的数据工程维护,这要求企业有极大的决心和耐力。
百川智能在技术路径上选择追随OpenEvidence,就必须正视这些前车之鉴。其引以为傲的“六源循证推理范式”和庞大的医学知识库,如果缺乏持续、动态的更新机制与严格的质量控制体系,难免会重蹈覆辙。
医疗AI的竞赛是一场马拉松,而非百米冲刺。王小川和他的百川智能能否在这场长跑中坚持到最后并脱颖而出,不仅取决于其技术实力与战略眼光,更取决于对医疗行业严谨性本质的深刻理解,以及对产品质量近乎偏执的坚守。
最终,最先进的AI产品竞争,或许将回归到最基础的价值观与文化层面,这其中的意味,颇值得深思。