手把手教你用LangChain快速构建AI智能体:从模型调用到记忆管理
2026年无疑是智能体应用爆发的一年。为了帮助大家更好地掌握智能体落地的关键技术,本系列文章将持续更新。今天的重点,是程序员群体中最常用的智能体开发框架——LangChain。
不过,随着AI编程工具的成熟,这类框架的文档可能逐渐从“给人看”演变为“给AI看”。
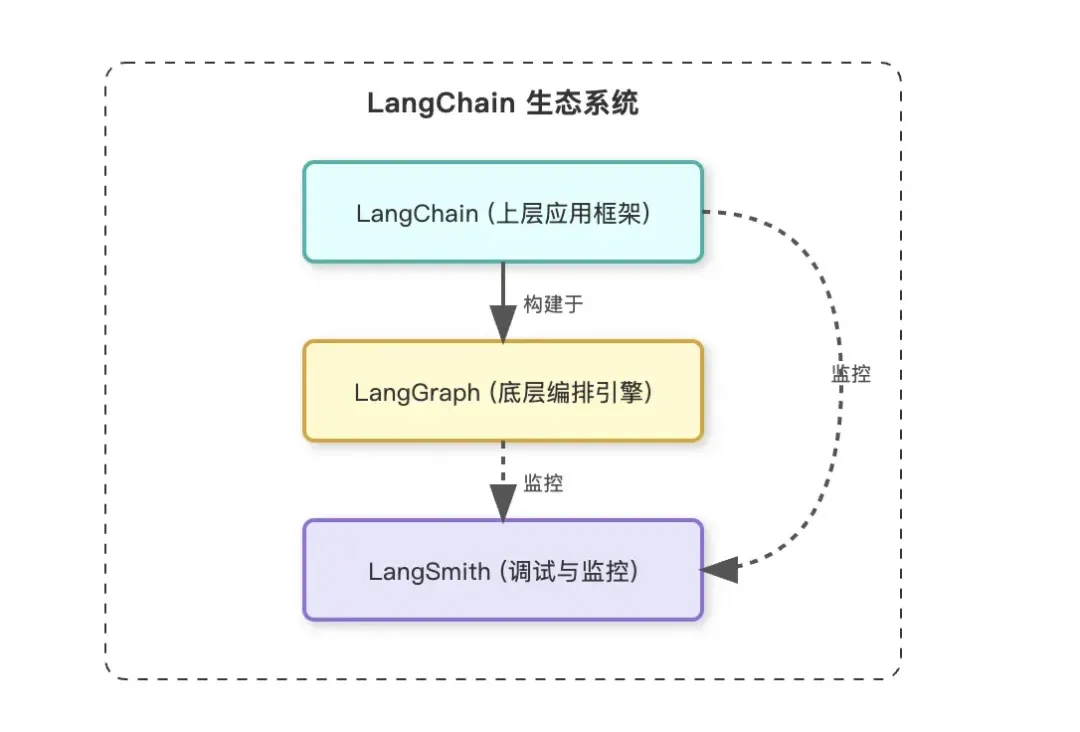
LangChain既指一个开源的AI应用开发框架,也指其背后的同名公司。该公司围绕AI应用开发生态,构建了完整的产品矩阵,包括广受欢迎的开源框架LangChain、用于构建复杂状态机的LangGraph,以及企业级的调试与监控平台LangSmith等。其中,LangChain和LangGraph是社区中最为活跃的两个开源项目。
需要特别指出的是,在LangChain演进到1.0版本之后,这两个框架的定位发生了显著变化:LangGraph成为底层的智能体编排引擎,专注于有状态、多轮次、高度定制化的智能体流程控制;而LangChain则演变为上层的应用开发框架,提供了更高阶的抽象、丰富的工具集成和便捷的智能体构建能力。
简而言之,LangChain封装了LangGraph的复杂性,让开发者能够快速搭建标准化的智能体;而LangGraph则为那些需要深度控制流程、实现自定义逻辑的场景,提供了灵活的图式编程能力。
对于大多数智能体应用场景,例如本文将要构建的旅行规划助手,使用LangChain已经足够。它简洁的API和开箱即用的组件,能让我们更专注于业务逻辑本身。
请注意,本文基于LangChain版本>=1.0。此外,虽然案例简单,但建议与同系列的前几篇文章对照阅读,以便深入理解智能体的本质与LangChain框架的设计意义。
如何开发一个Agent
为了兼顾不同的表达习惯,下文将交替使用“Agent”和“智能体”两个术语。
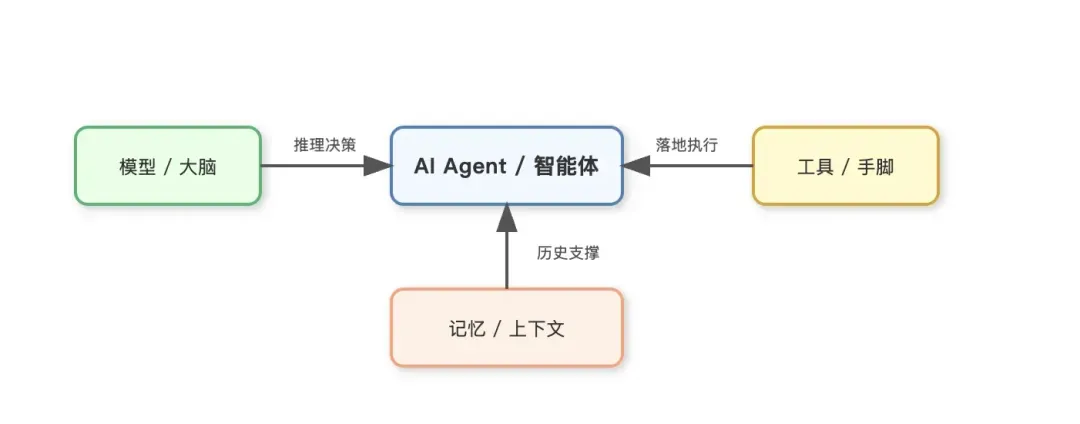
如之前文章所述,开发智能体的核心可以归结为三要素:模型(Model)、工具(Tools)和记忆(Memory)。
- 模型负责核心的推理与决策。
- 工具用于执行具体的业务操作(如查询天气、搜索信息)。
- 记忆负责保存历史对话,为模型的推理提供充足的上下文支持。
如果您对AI Agent的概念或开发流程尚不熟悉,建议先回顾本系列的前置文章。
接下来,我们将通过实际操作,展示如何利用LangChain实现模型调用、工具封装与会话记忆,从而完整地开发出一个可运行的AI智能体。
模型调用
LangChain提供了标准化的方法来集成各大厂商的模型,官网给出了完整的支持列表。我们可以访问其文档页面,查看具体模型的使用方式。这里我们以DeepSeek为例进行说明。
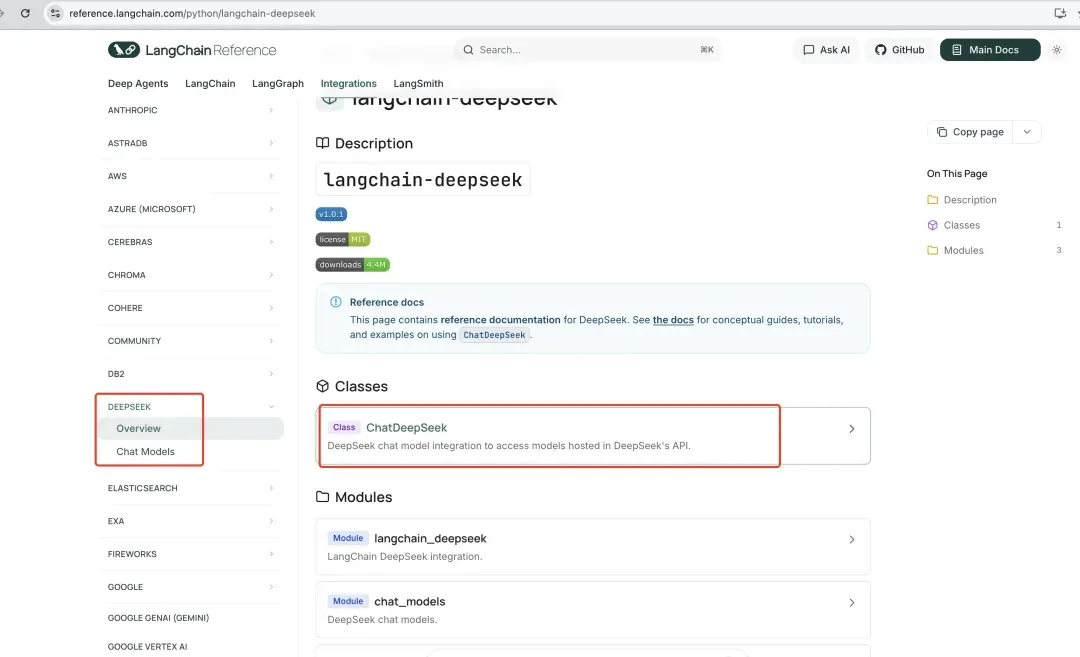
上图展示了LangChain为DeepSeek模型提供的专用集成包,可以直接安装使用:
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(
model="...",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
api_key=os.getenv("DEEPSEEK_API_KEY"),
# 其他参数...
)
其他模型提供商也有对应的集成包。此外,您也可以使用OpenAI的标准格式,目前绝大多数模型都兼容这种调用方式:
model = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0.7
)
通过上述方法得到模型实例后,即可使用invoke或stream方法向其发起请求并获取响应:
model = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0.7
)
messages = [
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "你是谁"}
]
result = model.invoke(messages)
print(result.content)
# 流式输出
result = model.stream(messages)
for chunk in result:
print(chunk.content)
声明工具
在LangChain中定义工具函数非常简单,使用@tool装饰器是最常用、最便捷的方式:
# 定义工具函数
@tool
def get_weather(destination, date):
# 实际调用天气 API
return f"{destination} {date} 天气晴朗"
@tool
def get_attractions(destination):
return f"{destination} 的热门景点有故宫、颐和园..."
# ... 其他函数
模型依赖工具的名称和描述来判断何时调用哪个工具。如果仅提供一个普通函数,LangChain会默认使用函数名作为工具名,使用函数的文档字符串作为描述。但这种默认方式往往不够精确,可能导致模型误解工具用途,进而调用错误。
因此,为了让模型能够精准识别并正确调用工具,最佳实践是显式地定义工具的元数据:为其指定清晰的名称、详细的描述,并为每个参数添加说明。推荐使用@tool装饰器,结合Annotated和Field来补充这些信息:
from langchain_core.tools import tool
from typing import Annotated
from pydantic import Field
@tool(name_or_callable="get_weather", description="获取指定城市指定日期的天气信息")
def get_weather(
destination: Annotated[str, Field(description="城市名称,如‘西安’")],
date: Annotated[str, Field(description="日期,格式 YYYY-MM-DD,如‘2025-05-20’")]
) -> str:
return f"{destination} {date} 天气晴朗"
@tool(name_or_callable="get_attractions", description="获取指定城市的景点推荐")
def get_attractions(
destination: Annotated[str, Field(description="城市名称,如‘北京’")]
) -> str:
# 实际开发中,这里应调用景点 API
return f"{city} 的热门景点有:故宫、颐和园、天坛。"
定义智能体
在LangChain中创建一个智能体非常直接。框架提供了create_agent标准方法,只需传入几个核心参数即可:
- 模型:通过LangChain接口实例化的大模型对象。
- 工具:已声明好的工具列表。
以下是一个完整的示例,演示如何创建并使用一个最简单的智能体:
from langchain_openai import ChatOpenAI
from langchain.agents import create_react_agent
from langchain_core.tools import tool
import os
# 定义工具(假设已有 get_weather, get_attractions)
# 示例工具函数已在前文定义,此处略
# 初始化模型
model = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0.7
)
# 工具列表
tools = [get_weather, get_attractions]
# 创建智能体
agent = create_agent(model=model, tools=tools)
# 准备输入消息
messages = {
"messages": [
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "我想去北京玩,能帮我看看天气和景点吗?"}
]
}
# 调用智能体
result = agent.invoke(messages)
# 输出最终答案
print(result["messages"][-1].content)
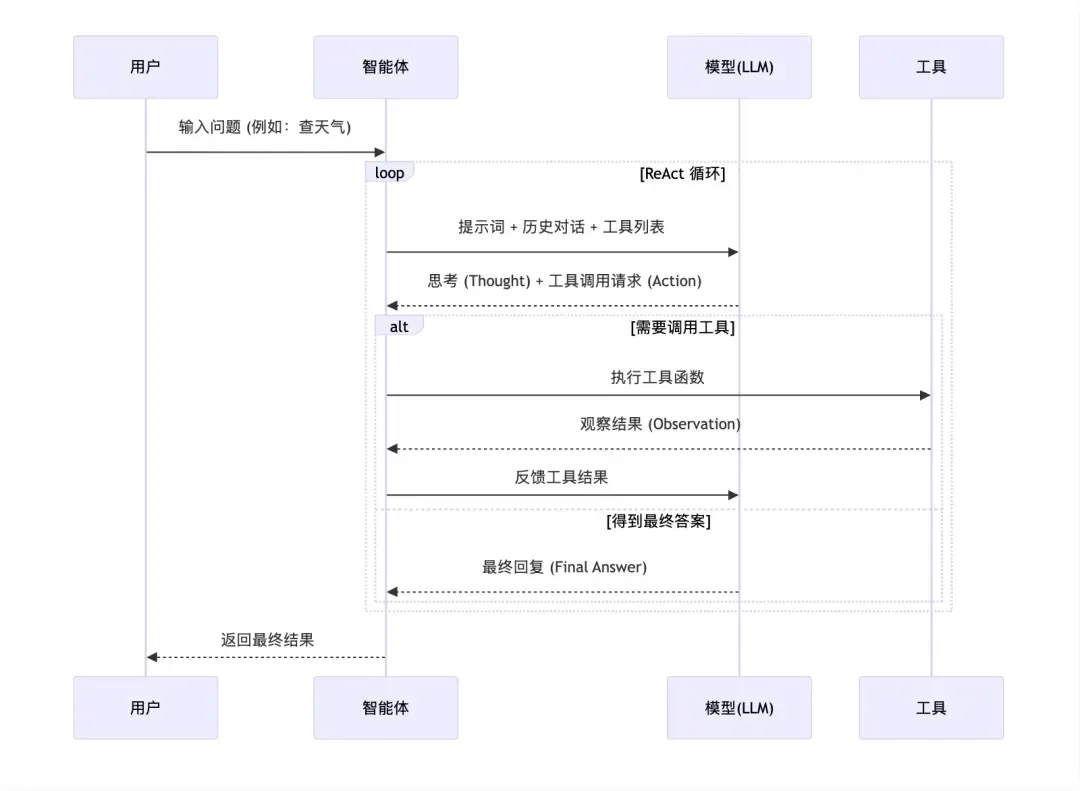
至此,一个最简单的智能体便构建完成。LangChain的create_agent方法默认采用ReAct(推理+行动)模式运行智能体,其工作流程如下:
- 模型接收用户消息,进行推理,判断是否需要调用工具。
- 若需要,模型输出工具调用指令,框架自动执行相应工具,并将结果作为新消息加入对话历史。
- 更新后的消息再次输入模型,重复上述步骤,直至模型认为信息已完备,给出最终答案。
- 整个流程由框架自动管理,开发者只需提供模型和工具,即可获得具备自主决策能力的智能体。
添加记忆
上一节构建的智能体尚不具备记忆能力,每次对话都是独立的。为了实现多轮对话,LangChain提供了完善的记忆(Memory)模块。记忆通常分为两类:短期记忆和长期记忆。
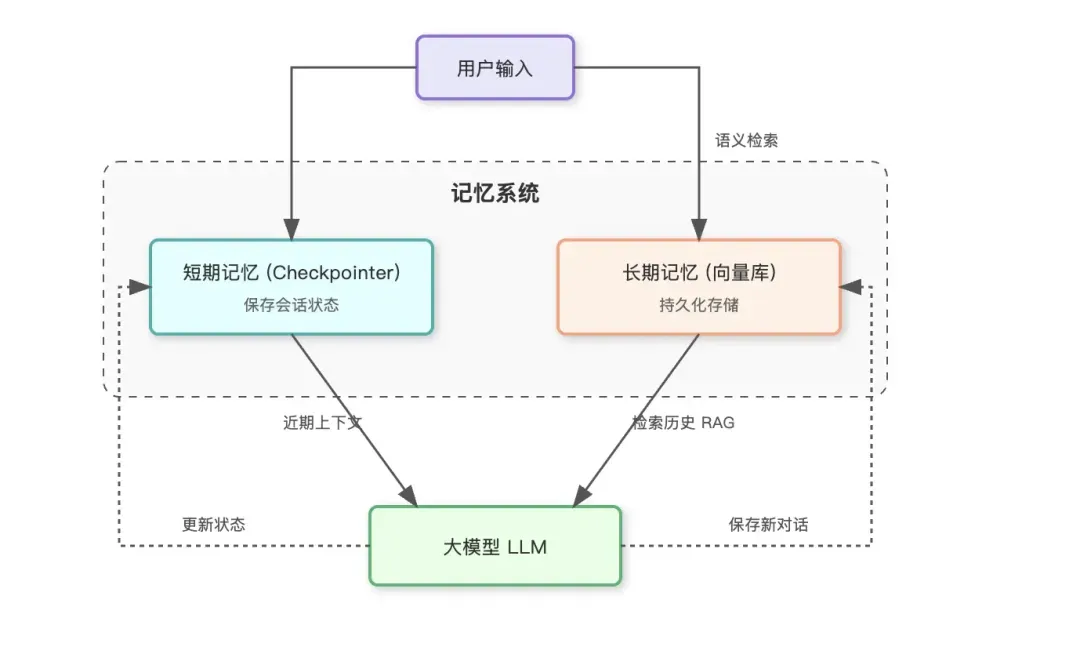
短期记忆:通常指保留在模型上下文窗口内的最近几轮对话。由于上下文长度有限,我们无法将全部历史发送给模型。因此,短期记忆常通过“滑动窗口”或“摘要”方式实现。在LangChain中,短期记忆的持久化通过检查点(Checkpointer)机制完成。
检查点(Checkpointer)机制:在构建智能体时,我们通常希望它能记住之前的对话。LangGraph通过检查点在每一步(Step)结束后保存当前状态(包括消息历史、变量等)。当需要继续之前对话时,只需提供相同的thread_id,检查点便会加载之前的状态,实现“记忆”功能。
InMemorySaver是一个基于内存的检查点保存器:
- 原理:将状态数据保存在Python字典(内存)中。
- 特点:速度快,无需额外依赖。
- 局限:程序重启后数据丢失,仅适用于开发调试或无需持久化的场景。
- 生产替代:在生产环境中,通常使用
PostgresSaver(基于PostgreSQL)或SqliteSaver等持久化方案。
from langgraph.checkpoint.memory import InMemorySaver
# ...
agent = create_agent(
# ...
checkpointer=InMemorySaver()
)
# 调用时指定 thread_id
config = {"configurable": {"thread_id": "1"}}
result = agent.invoke(input=messages, config=config)
长期记忆:为了突破上下文窗口的限制,需要将历史对话持久化存储(如数据库、向量数据库)。在需要时,通过检索算法(如语义相似度搜索)找到与当前问题最相关的历史记录,并将其注入提示词(Prompt)中。这即是RAG(检索增强生成)在记忆模块中的应用。
下面我们以实现一个基于向量数据库的长期记忆为例。
向量化存储实现:我们使用Chroma作为向量数据库,配合DashScope的Embedding模型来实现记忆的存储与检索。首先,初始化Embedding模型和向量数据库:
import os
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
# 初始化向量模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 初始化向量存储
# persist_directory 指定数据持久化目录
vectorstore = Chroma(
embedding_function=embeddings,
persist_directory="./chroma_db",
collection_name="chat_history"
)
保存记忆:当对话发生时,将用户输入和AI回复保存下来。为了区分不同用户和会话,我们在元数据(metadata)中记录user_id和session_id:
def save_messages(messages: str, user_id: int, session_id: int):
"""
保存用户输入和AI输出的会话记录
"""
# 将对话内容封装为 Document 对象,并添加元数据
doc = Document(
page_content=messages,
metadata={"user_id": user_id, "session_id": session_id}
)
# 添加到向量数据库
vectorstore.add_documents([doc])
检索记忆:在新一轮对话前,可根据用户当前输入(Query),在向量库中检索相关的历史记录作为上下文。我们还支持根据user_id和session_id进行过滤,确保只检索当前用户或会话的记忆:
def load_messages(query: str, user_id: int, session_id: int):
"""
加载用户输入和AI输出的会话记录
"""
# 构建过滤条件
filters = []
if user_id:
filters.append({"user_id": user_id})
if session_id:
filters.append({"session_id": session_id})
if len(filters) > 1:
filter_dict = {"$and": filters}
elif len(filters) == 1:
filter_dict = filters[0]
else:
filter_dict = None
# 执行相似度搜索,返回最相关的 top-k 记录
if filter_dict:
docs = vectorstore.similarity_search(query=query, k=3, filter=filter_dict)
else:
docs = vectorstore.similarity_search(query=query, k=3)
return docs
完成了长期记忆的保存与检索后,我们需要将其整合到智能体中。短期记忆可通过在create_agent中设置checkpointer=InMemorySaver()来实现,LangChain会自动将历史对话添加到提示词中。那么,如何添加长期记忆呢?这就需要用到LangChain的中间件(Middleware)了。
通过Middleware添加长期记忆:中间件提供了强大的生命周期钩子,允许我们在模型调用前后、工具执行前后进行干预。
中间件生命周期钩子图示:
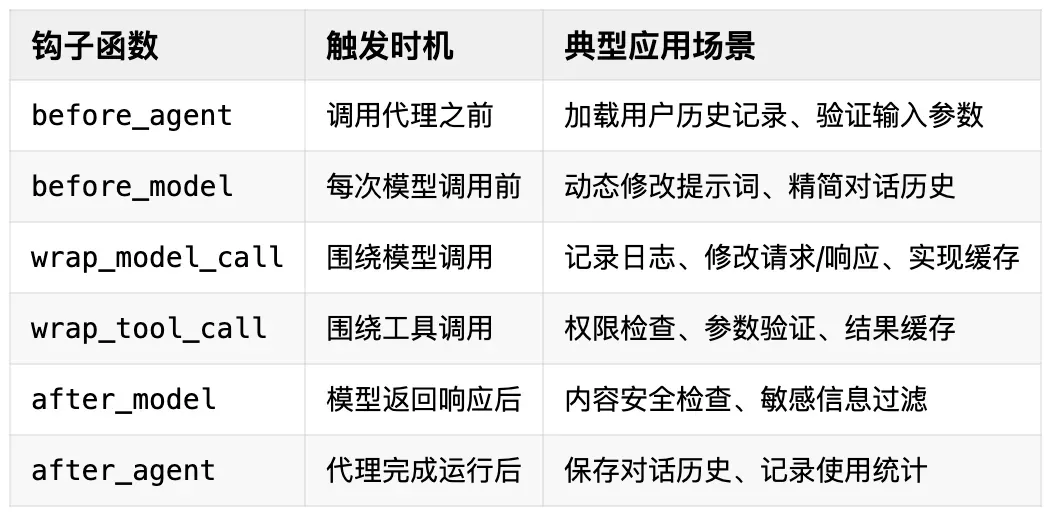
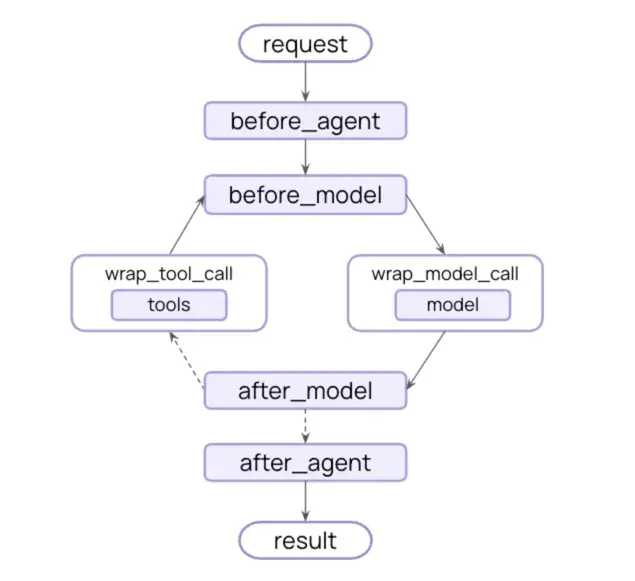
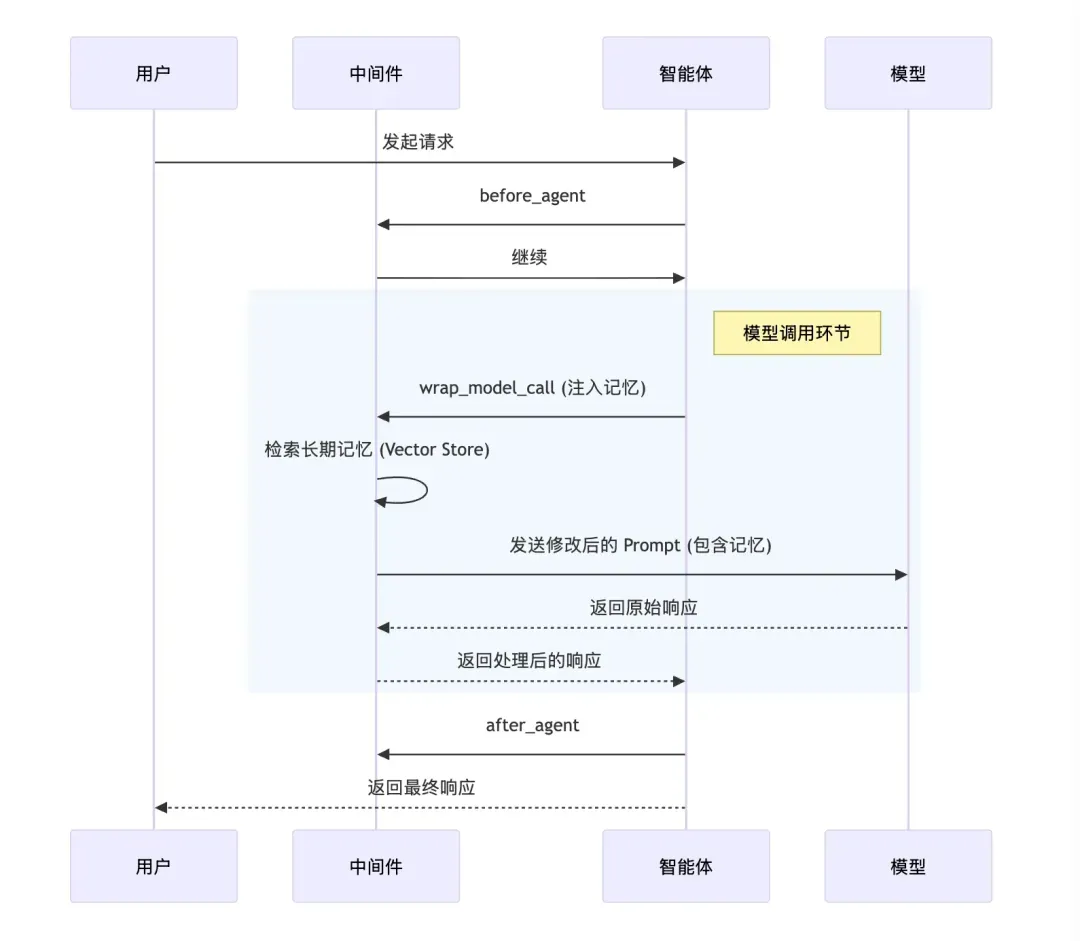
我们需要自定义一个中间件add_long_memory,利用wrap_model_call钩子在模型调用前,通过load_messages方法查询长期记忆,并将结果追加到消息列表中:
@wrap_model_call
def add_long_memory(request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse]) -> ModelResponse:
print(f"Model call: {request}")
message = request.messages[-1]
if message.type == "human":
embedding_docs = load_messages(message.content, config["configurable"]["user_id"],
config["configurable"]["session_id"])
embedding_message = "\n".join([doc.page_content for doc in embedding_docs])
request.messages.append(ChatMessage(content=embedding_message, role="system"))
return handler(request)
现在,我们可以为Agent添加长期记忆了,只需在create_agent中增加一个middleware参数即可:
middleware=[add_long_memory()]
这样,Agent在调用模型前就会执行add_long_memory方法,将查询到的相关历史消息注入到提示词中。
完整的智能体代码如下:
config: RunnableConfig = {"configurable": {"thread_id": "1", "user_id": 1, "session_id": 1}}
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0.7
)
messages = {
"messages": [
{"role": "system", "content": "你是一个旅游规划助手。"},
{"role": "user", "content": user_message}
]
}
tools = [get_weather, get_attractions]
agent = create_agent(llm,
tools=tools,
middleware=[add_long_memory()],
checkpointer=InMemorySaver())
result = agent.invoke(input=messages, config=config)
ai_message = result["messages"][-1].content
save_messages(messages=user_message + ai_message, user_id=config["configurable"]["user_id"], session_id=config["configurable"]["session_id"])
运行效果如下图所示:
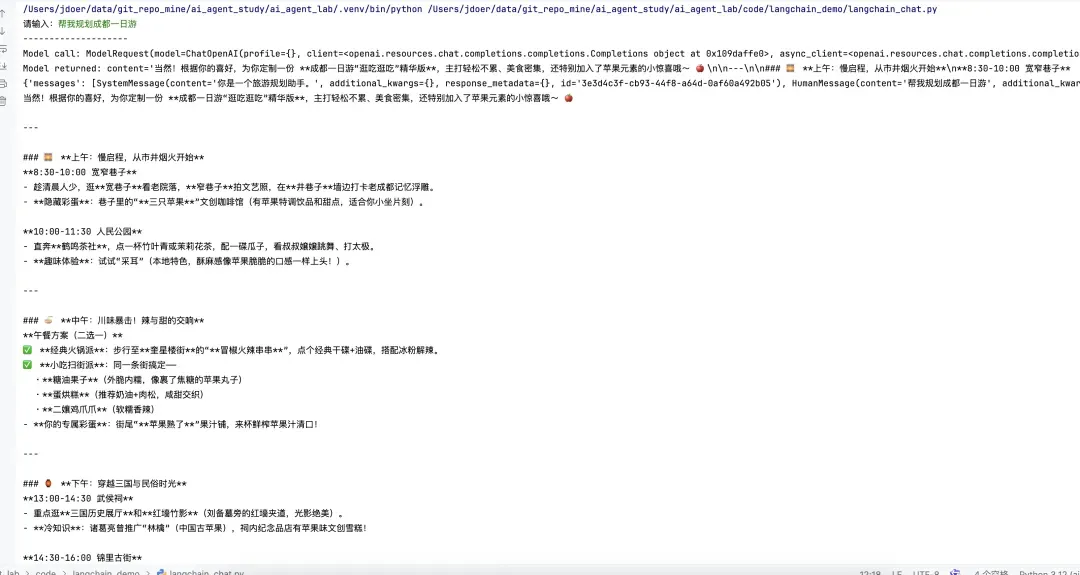
结语
以上,我们快速回顾了使用LangChain构建智能体的核心流程。整个过程依然紧紧围绕三大要素展开:模型、工具和记忆。
- 模型:无论选用DeepSeek还是OpenAI,LangChain都提供了统一的封装,仅需一行代码即可切换,无需关心不同厂商API的差异。
- 工具:将业务功能写成函数,使用
@tool装饰器进行标注,并清晰地描述其功能和参数,模型便能理解并调用。这个过程直观且高效。 - 记忆:分为两类。短期记忆通过检查点(Checkpointer)实现,设置
thread_id即可让智能体记住当前会话;长期记忆则需要借助向量数据库存储历史,并在模型调用前通过中间件检索并注入相关的旧对话。我们在文中演示的正是这一思路。
将这三部分组合起来,一个能够自主思考、查询天气、进行多轮对话的旅行规划助手便搭建而成。LangChain的设计非常贴心:若追求快速实现,可使用其高层封装;若需要精细控制,底层的LangGraph和灵活的中间件也提供了足够的施展空间。
总而言之,LangChain显著降低了智能体开发的门槛。无论是构建简单的问答系统,还是实现复杂的工作流,都可以从本文介绍的核心组件出发,逐步添砖加瓦。感兴趣的读者不妨动手尝试,看着自己构建的智能体运行起来,成就感十足。