免费离线OCR中文识别工具TrWebOCR:快速部署与完整使用指南
TrWebOCR 是一款开源且易于使用的中文离线 OCR 解决方案,其识别精度可与主流商业 OCR 服务相媲美,同时提供了直观的 Web 用户界面和便捷的 API 接口支持。
部署安装
通过 Docker Compose 实现快速安装和配置:
services:
trwebocr:
image: mmmz/trwebocr:latest
container_name: trwebocr
ports:
- 8089:8089
restart: always
操作使用
在浏览器地址栏输入 http://NAS的IP:8089 即可访问 TrWebOCR 的 Web 操作界面。
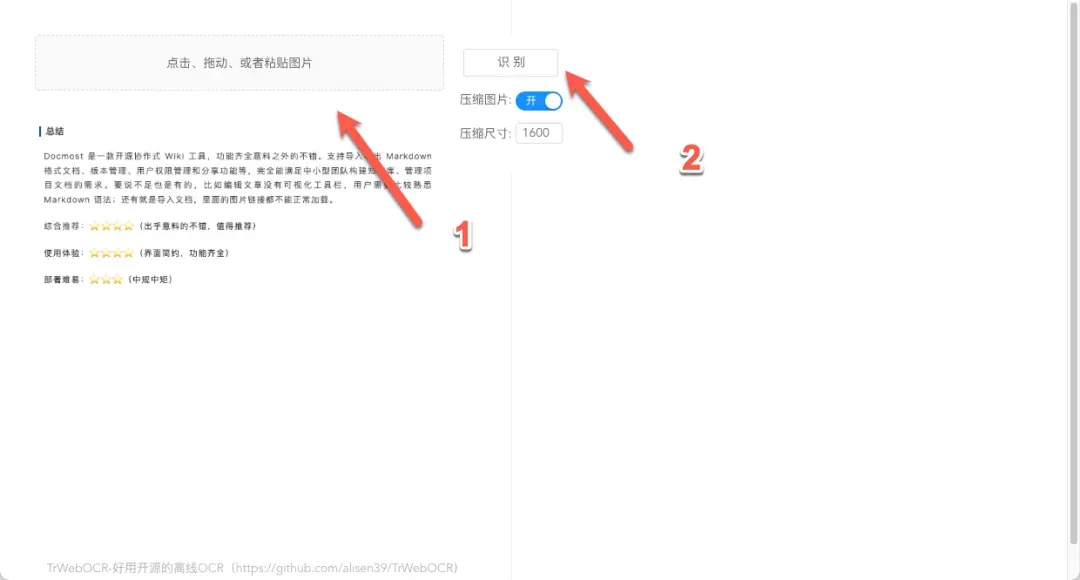
上传需要处理的图片文件,然后点击识别按钮启动文字提取过程。
识别过程效率极高,通常仅需两秒左右即可完成,提取的文字内容会被自动高亮标记出来。
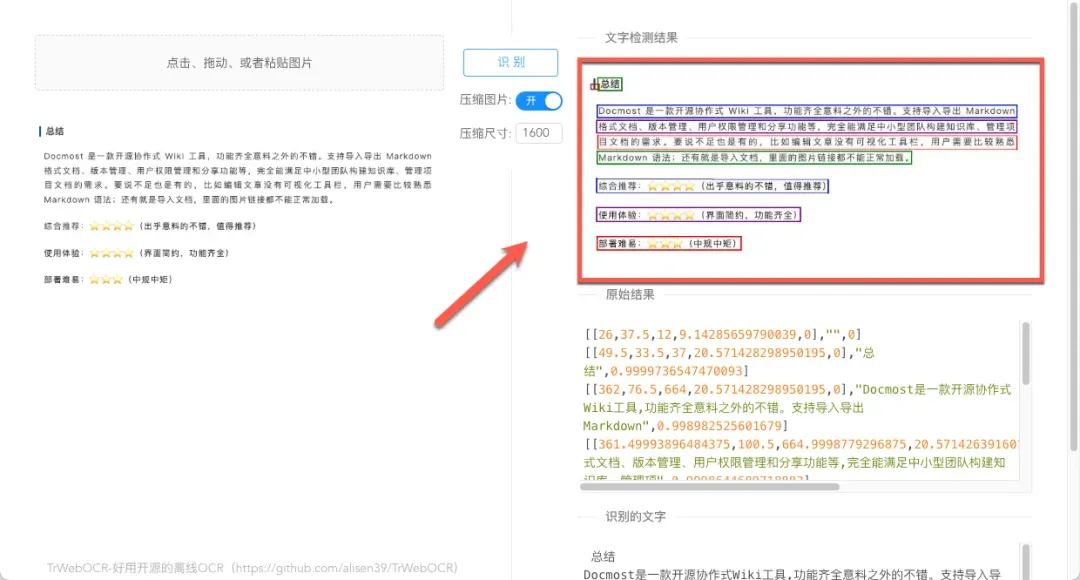
在大多数标准场景下,文字识别准确率令人满意,但对于字符间距过密的特殊字体,可能会出现少量识别误差。
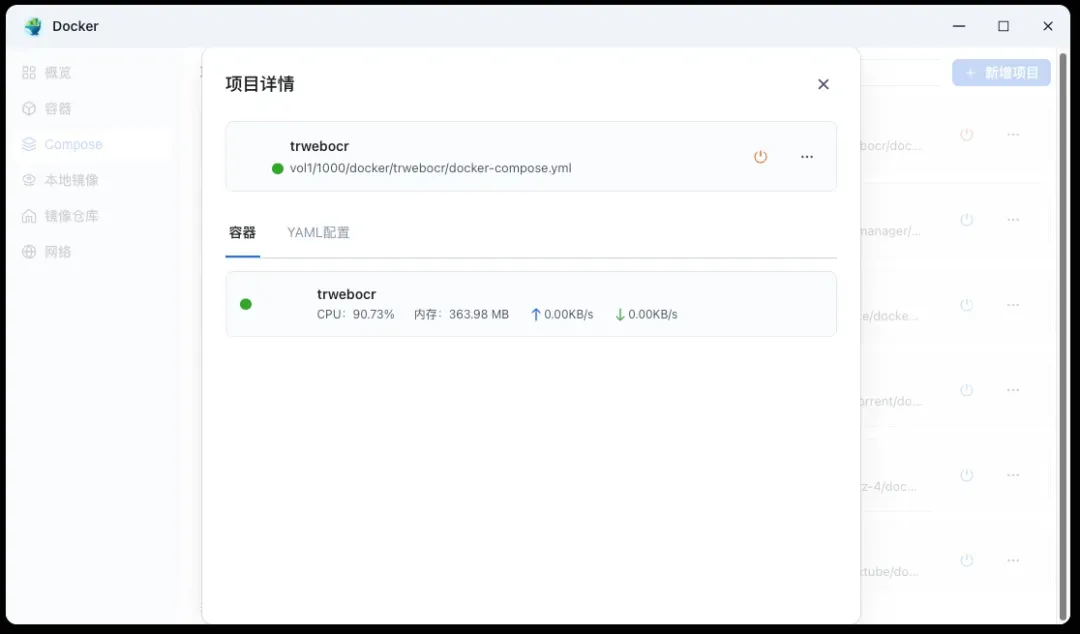
执行 OCR 识别任务时,CPU 资源占用较为显著,而内存消耗则保持在相对较低的水平。
综合评估
TrWebOCR 作为一款轻量级、开源且完全离线运行的中文 OCR 工具,部署流程极其简单便捷。识别速度表现优异,在图片质量清晰且字体规范的前提下,识别准确率能够达到较高水准。尽管操作界面设计较为朴素,但功能完整实用,并且支持通过 API 接口进行灵活调用。对于有本地 OCR 识别需求,例如处理日常文档、截图文字提取等场景的用户,建议尝试部署并使用该工具。
综合推荐等级:⭐⭐⭐(即开即用,提供 API 接口)
使用体验评价:⭐⭐⭐(识别速度快,操作直观易懂)
部署简易程度:⭐(极其简单)