TrWebOCR免费中文离线OCR工具:高效识别与简易部署全攻略
TrWebOCR 是一款开源且易于使用的中文离线OCR项目,其识别准确率能够与大型商业解决方案相媲美。该项目提供了直观的Web操作页面以及灵活的API接口,方便用户进行文字提取和集成。
部署与安装指南
以下是使用 Docker Compose 快速部署 TrWebOCR 的配置文件示例,只需简单几步即可完成环境搭建。
services:
trwebocr:
image: mmmz/trwebocr:latest
container_name: trwebocr
ports:
- 8089:8089
restart: always
操作步骤与使用演示
完成部署后,在浏览器地址栏中输入 http://NAS的IP:8089 即可访问 TrWebOCR 的Web操作界面。
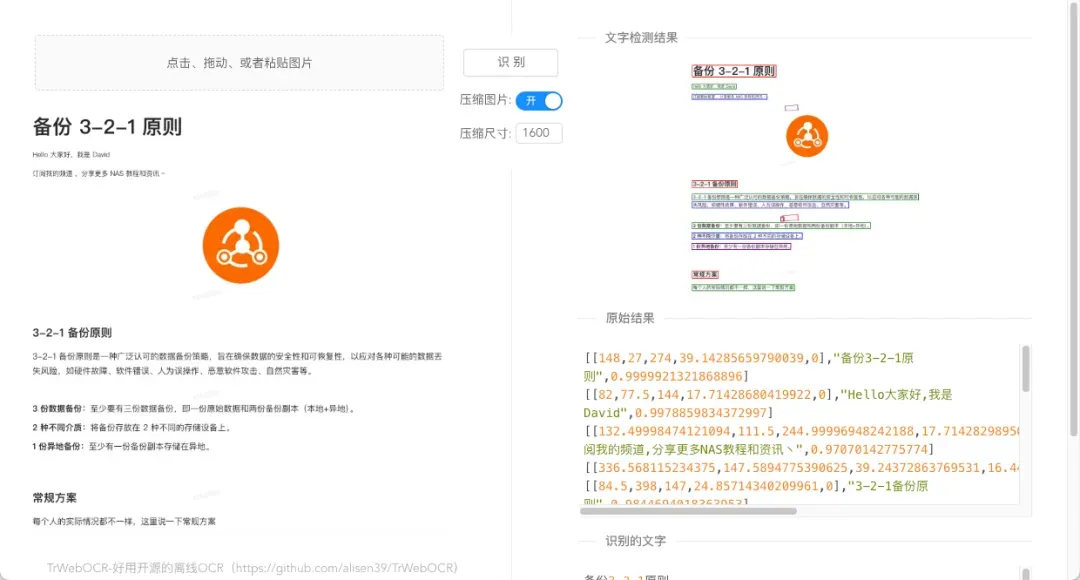
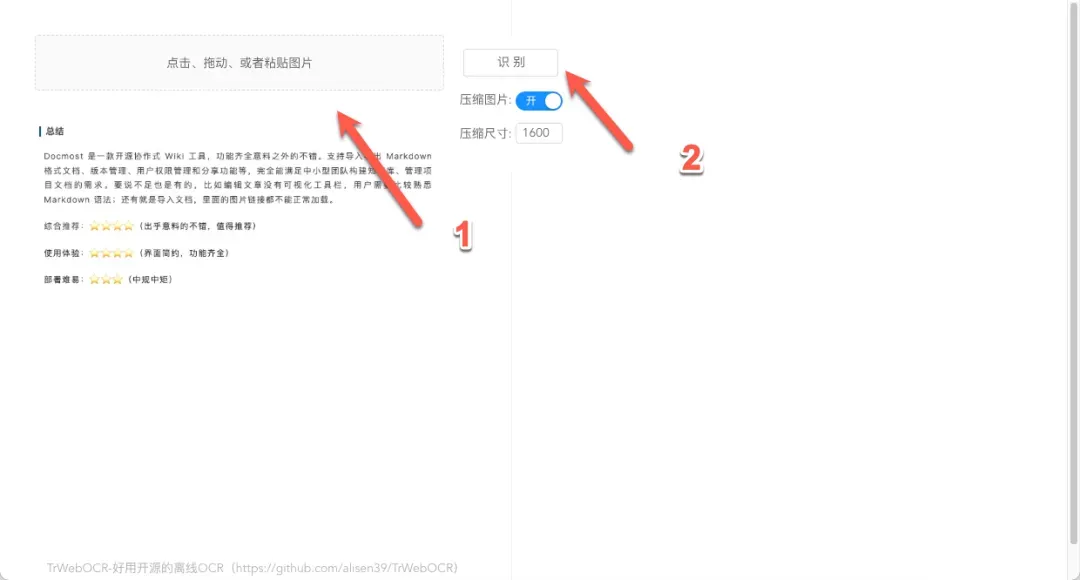
在Web界面中上传或选择需要识别的图片文件,随后点击识别按钮即可启动OCR处理流程。
识别过程通常非常迅速,例如本次演示在不到两秒的时间内就完成了处理,界面上会清晰地用选框标出识别出的文字区域。
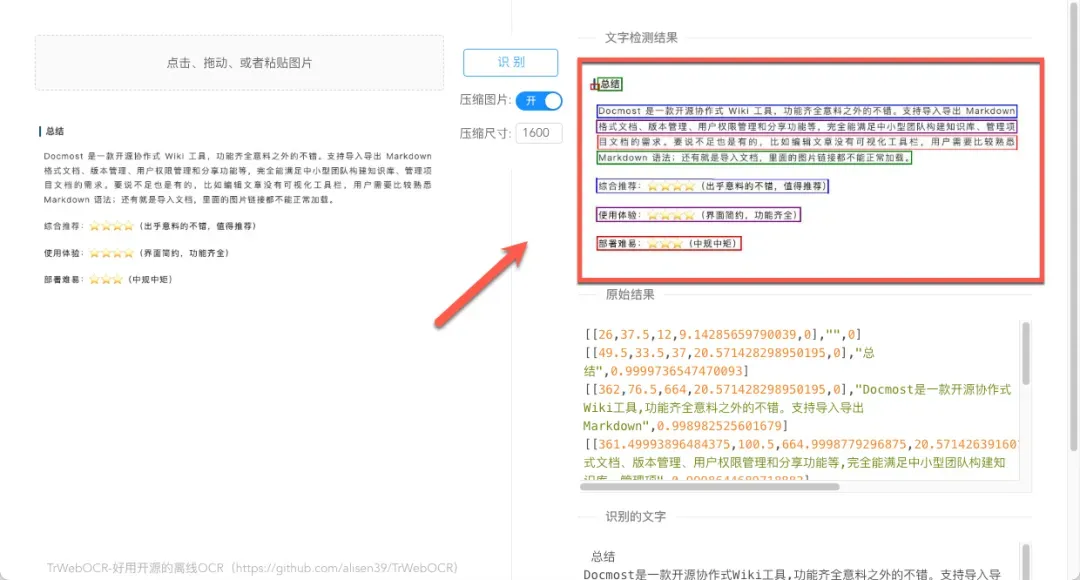
在大多数情况下,文字识别结果都相当准确(需要注意的是,当字体间距过于紧密或使用特殊字体时,识别精度可能会受到一定影响)。
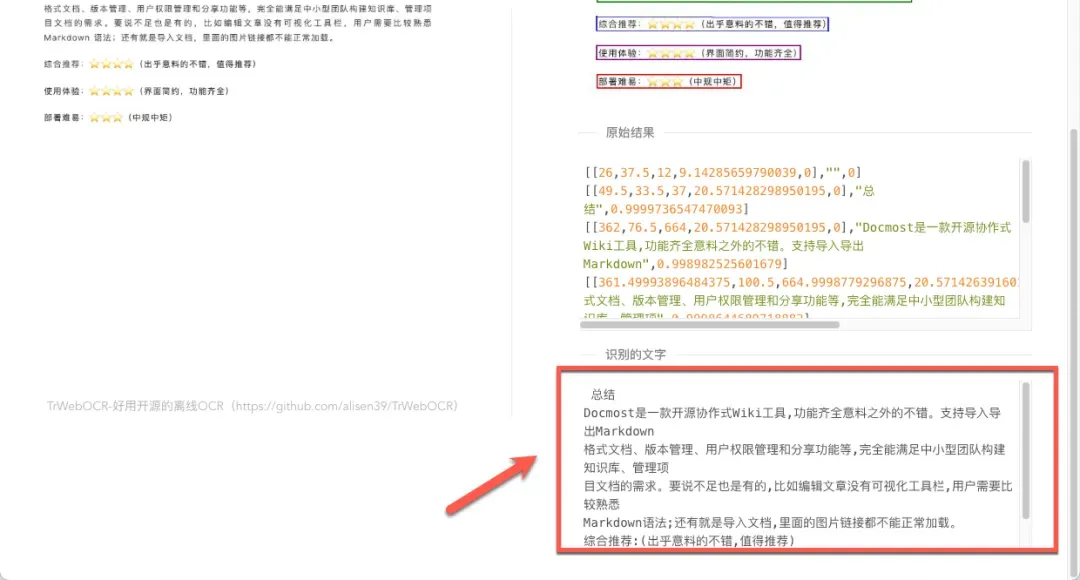
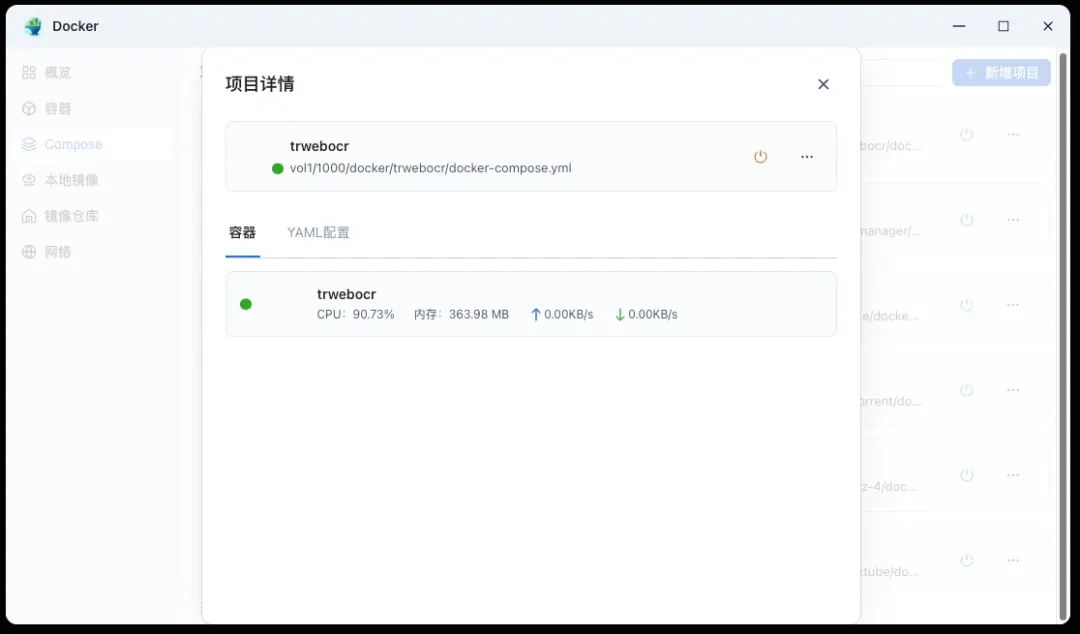
在进行OCR识别任务时,该工具会占用较高的CPU计算资源,相比之下其对内存的消耗则保持在较低水平。
综合评价与总结
TrWebOCR 作为一款轻量级、开源且支持完全离线运行的中文OCR工具,其部署过程极为简便。该工具识别速度出色,在图片质量清晰且字体常规的条件下,能够保持较高的识别准确率。尽管其用户操作界面设计较为简洁,但功能完备且实用,同时提供了API接口供程序化调用。对于具有本地OCR需求,希望处理日常文档、屏幕截图等文字提取任务的用户,都可以尝试部署并使用这款工具。
综合推荐指数:⭐⭐⭐(即开即用,提供API接口)
实际使用体验:⭐⭐⭐(识别速度快,操作直观)
部署难度评级:⭐(非常简单)