腾讯开源知识库WeKnora NAS私有化部署全攻略:从零搭建你的智能文档检索系统
在信息爆炸的时代,如何高效管理和利用海量文档是许多团队面临的共同挑战。腾讯开源的WeKnora,正是一款为解决此问题而生的智能文档理解与语义检索框架。它基于大语言模型(LLM)构建,专为处理结构复杂、格式多样的文档场景设计,通过模块化架构整合了从文档预处理到智能问答的全流程,其核心是利用RAG(检索增强生成)技术,结合精准的上下文检索与大模型推理能力,生成高质量、高相关性的回答。
架构设计与核心特性
WeKnora的系统架构经过精心打磨,旨在实现流程的高效与可控。其模块化设计让各个环节清晰解耦,确保了系统的灵活性和可维护性。

该框架具备一系列强大的核心特性,使其在众多文档智能工具中脱颖而出:
- 🔍 精准内容理解:能够解析PDF、Word、图片等多种格式文档,提取结构化内容,并统一构建为易于处理的语义视图,即使是图文混排内容也能从容应对。
- 🧠 智能语义推理:借助大语言模型深度理解文档上下文与用户查询的真实意图,不仅支持精准的问答,还能进行连贯的多轮对话。
- 🔧 灵活可扩展:从文档解析、向量嵌入、信息召回到最终生成,全流程均采用解耦设计,用户可以根据自身需求轻松集成或定制任一环节。
- ⚡ 高效混合检索:并非依赖单一策略,而是融合了关键词检索(如BM25)、稠密向量检索以及更先进的知识图谱增强检索(GraphRAG),确保召回结果既全面又精准。
- 🎯 简单易上手:提供了直观的Web管理界面和标准化的RESTful API,即便是没有技术背景的业务人员也能快速上手使用。
- 🔒 安全可控:全面支持本地化与私有云部署,所有数据均在用户自己的环境中处理,为企业级的信息安全提供了坚实保障。
适用场景与核心价值
WeKnora并非一个“玩具”项目,其设计瞄准了真实的企业级需求,在多个领域都能发挥巨大价值:
| 应用场景 | 具体应用 | 核心价值 |
|---|---|---|
| 企业知识管理 | 内部文档检索、规章制度问答、操作手册查询 | 极大提升知识查找与利用效率,有效降低员工培训与信息获取成本。 |
| 科研文献分析 | 学术论文检索、研究报告深度分析、领域资料系统整理 | 加速文献调研过程,为研究决策提供智能化辅助与支持。 |
| 产品技术支持 | 产品手册智能问答、技术文档精准检索、故障排查引导 | 提升客户服务响应质量与效率,减轻技术支持人员的工作负担。 |
| 法律合规审查 | 合同条款快速检索、法规政策实时查询、历史案例对比分析 | 提高法务与合规工作的审查效率,系统性降低潜在法律风险。 |
| 医疗知识辅助 | 医学文献检索、最新诊疗指南查询、典型病例分析参考 | 辅助临床医生进行决策,提升诊疗方案的质量与科学性。 |
功能模块与能力概览
为了让你对WeKnora的能力有一个全局性的了解,下表详细列出了其各功能模块的支持情况:
| 功能模块 | 支持情况 | 详细说明 |
|---|---|---|
| 文档格式支持 | ✅ PDF / Word / Txt / Markdown / 图片(含OCR/图像描述) | 支持解析多种结构化与非结构化文档,能够处理图文混排内容并提取图像中的文字信息。 |
| 嵌入模型支持 | ✅ 本地模型、BGE / GTE等API | 支持使用自定义的embedding模型,兼容本地部署与云端向量生成接口,灵活性高。 |
| 向量数据库接入 | ✅ PostgreSQL(pgvector)、Elasticsearch | 支持主流的向量索引后端,可根据不同检索场景和性能要求灵活切换与扩展。 |
| 检索机制 | ✅ BM25 / 稠密检索 / GraphRAG | 支持稀疏检索、稠密检索及知识图谱增强检索等多种策略,可自由组合召回、重排与生成流程。 |
| 大模型集成 | ✅ 支持Qwen、DeepSeek等,思考/非思考模式切换 | 可接入本地部署的大模型(如通过Ollama启动)或调用外部API服务,支持推理模式的灵活配置。 |
| 问答能力 | ✅ 上下文感知、多轮对话、提示词模板 | 支持复杂的语义建模与指令控制,可进行链式问答,并允许配置提示词模板与上下文窗口大小。 |
| 端到端测试 | ✅ 检索+生成过程可视化与指标评估 | 提供一体化链路测试工具,支持评估召回命中率、回答覆盖度及BLEU/ROUGE等主流评测指标。 |
| 部署模式 | ✅ 支持本地部署 / Docker镜像 | 满足私有化、离线部署及灵活运维的需求,保障数据安全与系统稳定。 |
| 用户界面 | ✅ Web UI + RESTful API | 提供交互式可视化界面供业务用户使用,同时提供标准API接口供开发者集成与二次开发。 |
在NAS上部署WeKnora的详细步骤
接下来,我们将手把手教你如何在NAS设备上完成WeKnora的私有化部署。
第一步:获取与准备项目文件
首先,访问WeKnora的GitHub官方仓库,下载最新的项目源代码压缩包(ZIP格式)。
 下载完成后,将其解压到本地。在解压后的项目根目录中,你会找到一个名为
下载完成后,将其解压到本地。在解压后的项目根目录中,你会找到一个名为.env.example的文件,这是环境配置文件的模板。

第二步:配置环境变量
这是部署成功的关键一步。用你熟悉的文本编辑器(如VS Code、Notepad++)打开.env.example文件,根据你的实际环境进行修改:
- 配置Ollama地址:找到
OLLAMA_BASE_URL项,将其值修改为你NAS上已部署的Ollama服务的访问地址(Ollama需要提前独立部署好)。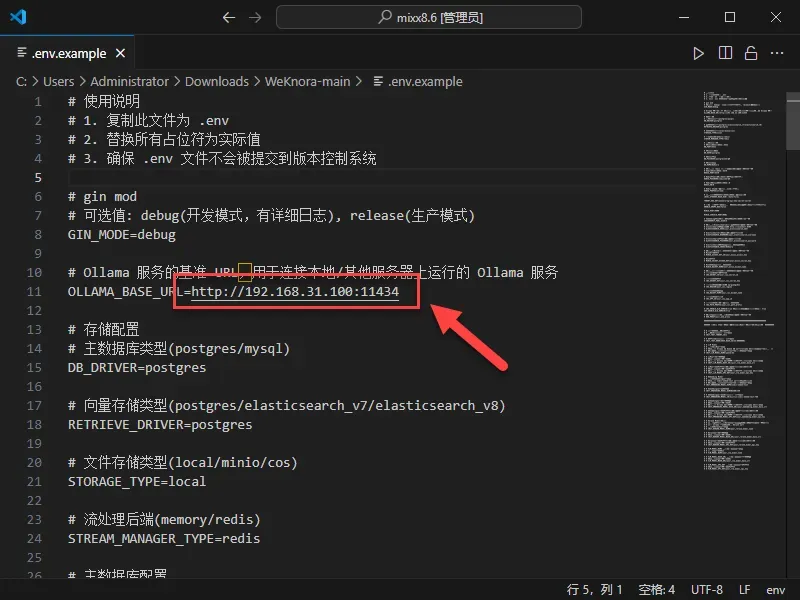
- 选择大模型:默认配置使用
Qwen2.5-7B-Instruct模型。如果你在Ollama中部署了其他模型(如llama3.2),可以修改OLLAMA_MODEL项。注意:需要移除行首的#注释符号才能使配置生效。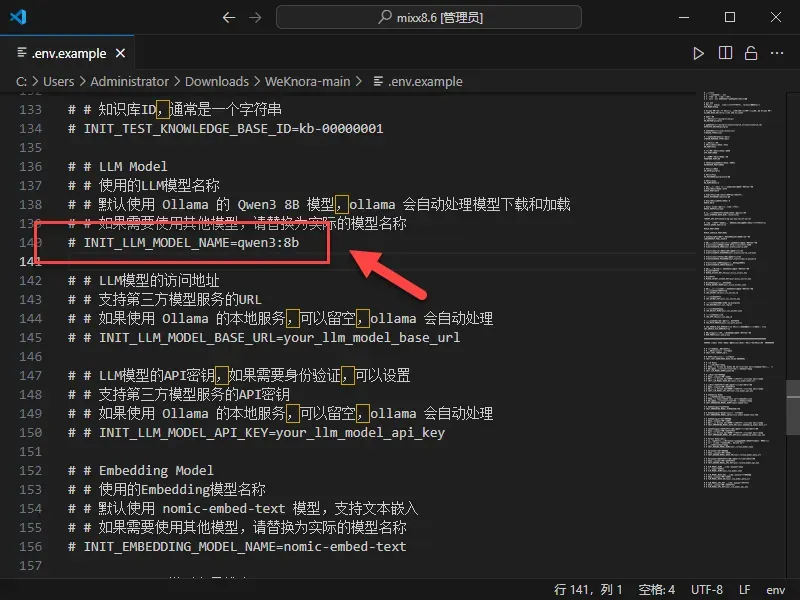
- 修改Web端口:
WEB_PORT定义了前端服务的访问端口,默认为8081。如果该端口已被占用,可以修改为其他可用端口。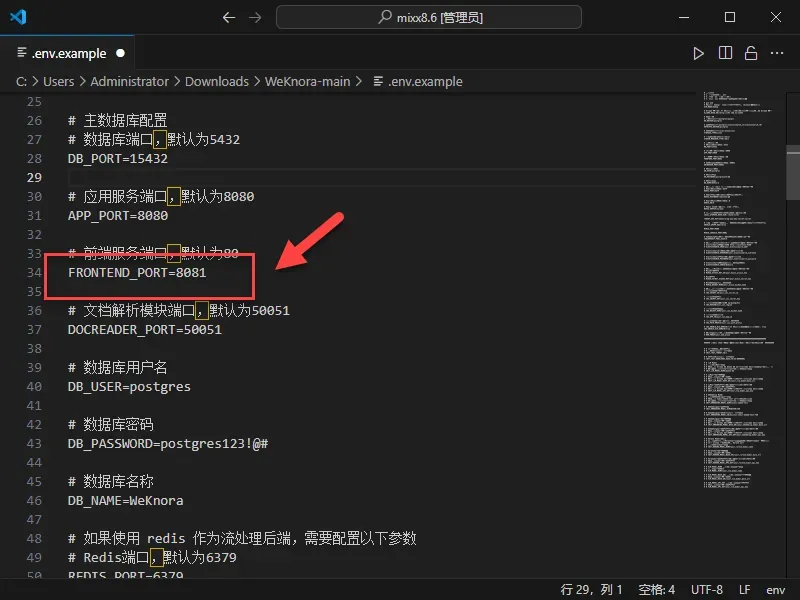
- 检查数据库端口:这一步尤其重要! 查看
POSTGRES_PORT配置。许多NAS系统(例如飞牛FnOS)自带的服务可能已经占用了PostgreSQL的默认端口5432。如果存在冲突,必须修改此处的端口号,例如改为5433,否则容器将无法启动。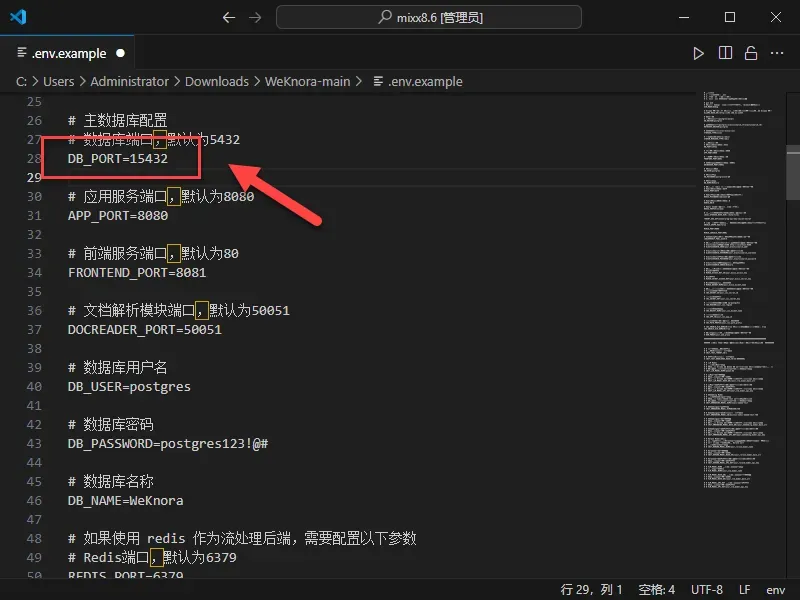 完成所有修改后,务必将该文件重命名为
完成所有修改后,务必将该文件重命名为.env(去掉.example后缀)。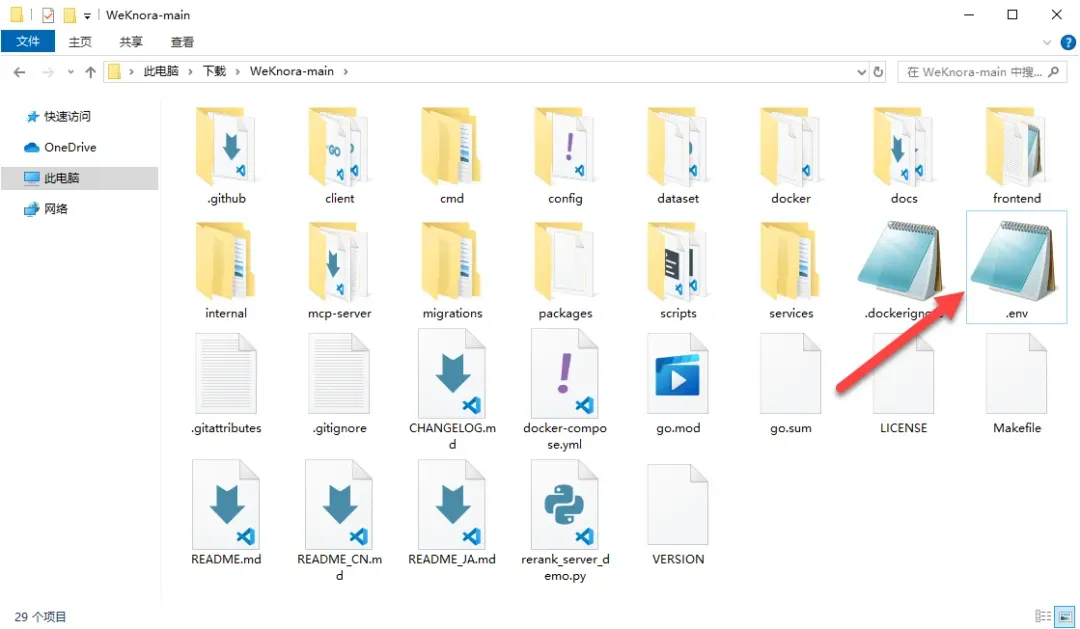
第三步:上传文件并启动容器
将整个配置好的项目文件夹上传到你的NAS设备中,可以放在共享目录如docker或appdata下。
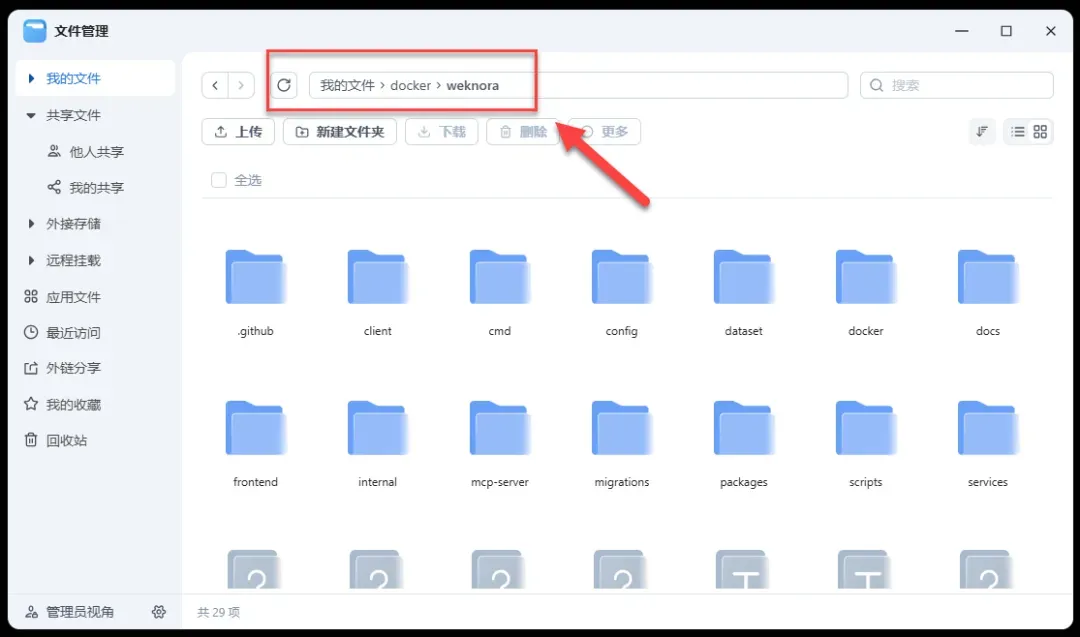 接下来,打开你NAS上的容器管理界面(可能是Docker、Portainer或群晖的Container Manager)。创建一个新的“项目”、“堆栈”或“应用”,在配置时选择你刚刚上传的项目文件夹路径。系统通常会智能识别文件夹内的
接下来,打开你NAS上的容器管理界面(可能是Docker、Portainer或群晖的Container Manager)。创建一个新的“项目”、“堆栈”或“应用”,在配置时选择你刚刚上传的项目文件夹路径。系统通常会智能识别文件夹内的docker-compose.yml文件并自动导入配置。
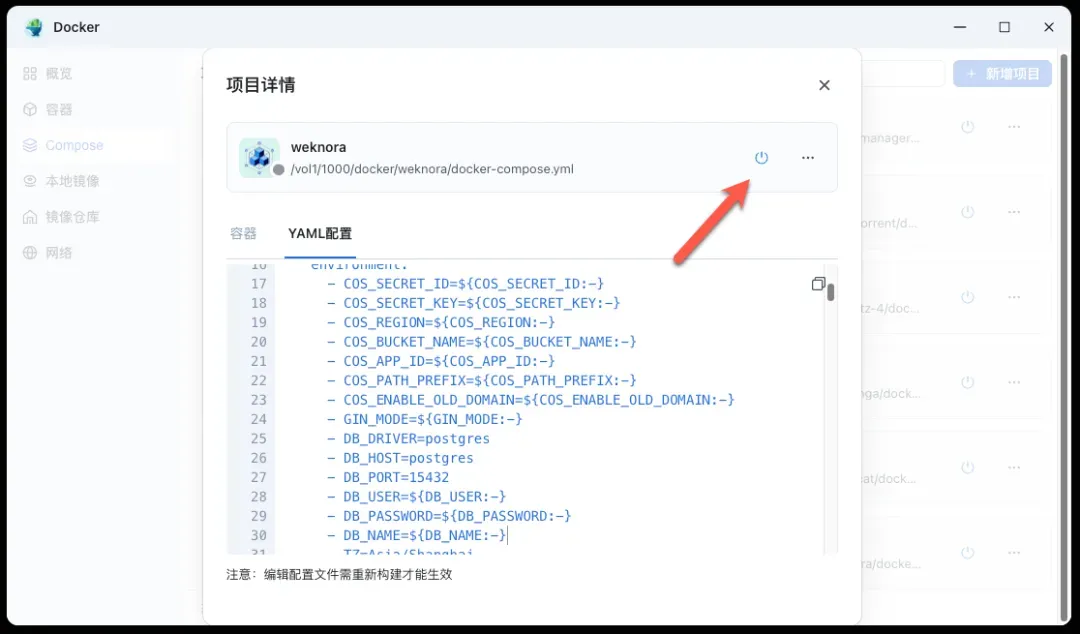 点击启动或部署按钮。系统会开始拉取镜像并创建多个容器(包括Web前端、后端API、PostgreSQL等)。这个过程可能需要几分钟到十几分钟,具体取决于你的网络速度和NAS性能,请耐心等待。
点击启动或部署按钮。系统会开始拉取镜像并创建多个容器(包括Web前端、后端API、PostgreSQL等)。这个过程可能需要几分钟到十几分钟,具体取决于你的网络速度和NAS性能,请耐心等待。
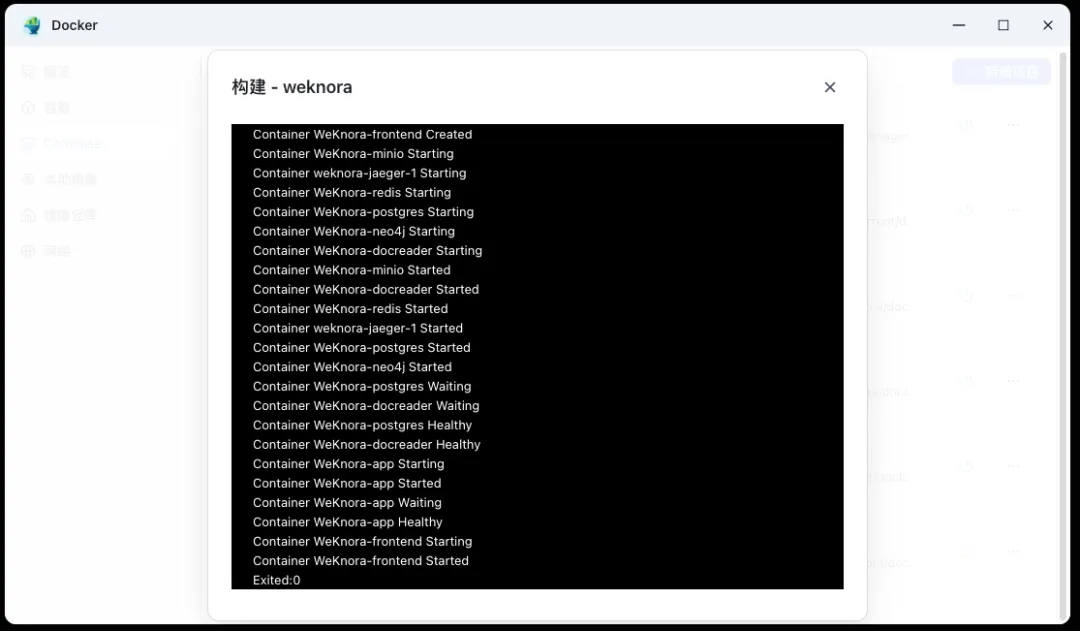 启动后务必检查日志:由于服务由多个容器组成,启动完成后,一定要在容器管理界面中查看所有容器的日志,确认没有红色的报错信息,状态均为“运行中”。
启动后务必检查日志:由于服务由多个容器组成,启动完成后,一定要在容器管理界面中查看所有容器的日志,确认没有红色的报错信息,状态均为“运行中”。
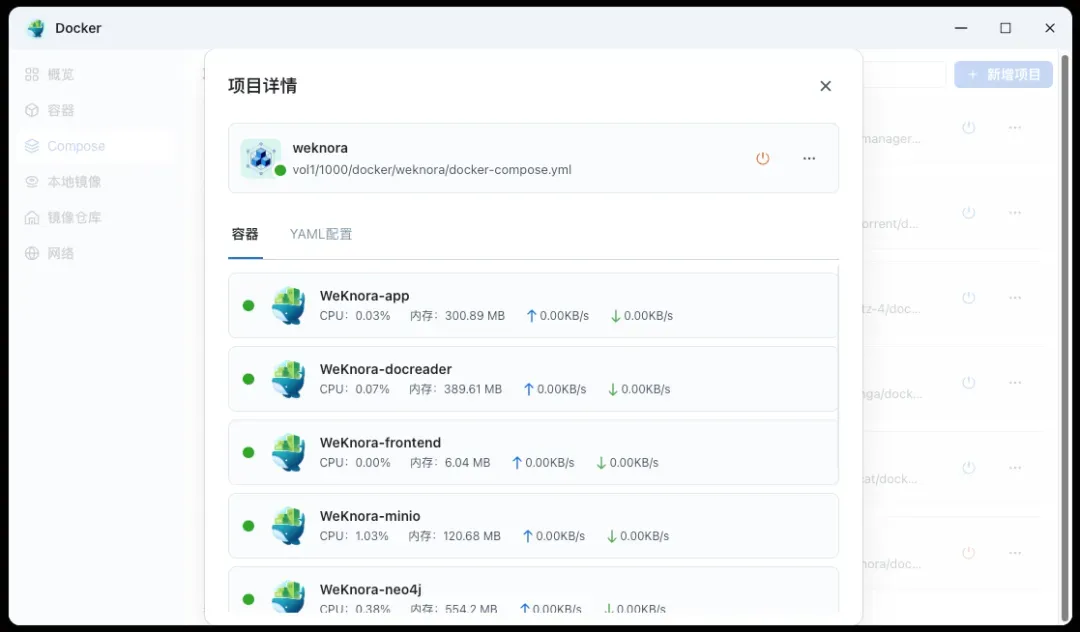 高级管理(可选):如果你习惯使用命令行,也可以通过SSH连接到NAS,在项目目录下使用提供的脚本进行管理:
高级管理(可选):如果你习惯使用命令行,也可以通过SSH连接到NAS,在项目目录下使用提供的脚本进行管理:
# 启动所有服务
sudo bash ./scripts/start_all.sh
# 停止所有服务
sudo bash ./scripts/start_all.sh --stop
# 清理数据库(谨慎使用,会清空所有数据!)
sudo make clean-db
初始化配置与基本使用
当所有容器都正常运行后,就可以开始体验WeKnora了。
访问与注册
在电脑浏览器的地址栏中输入 http://你的NAS的IP地址:8081(端口号若修改过则替换为你设置的端口),即可打开WeKnora的Web界面。
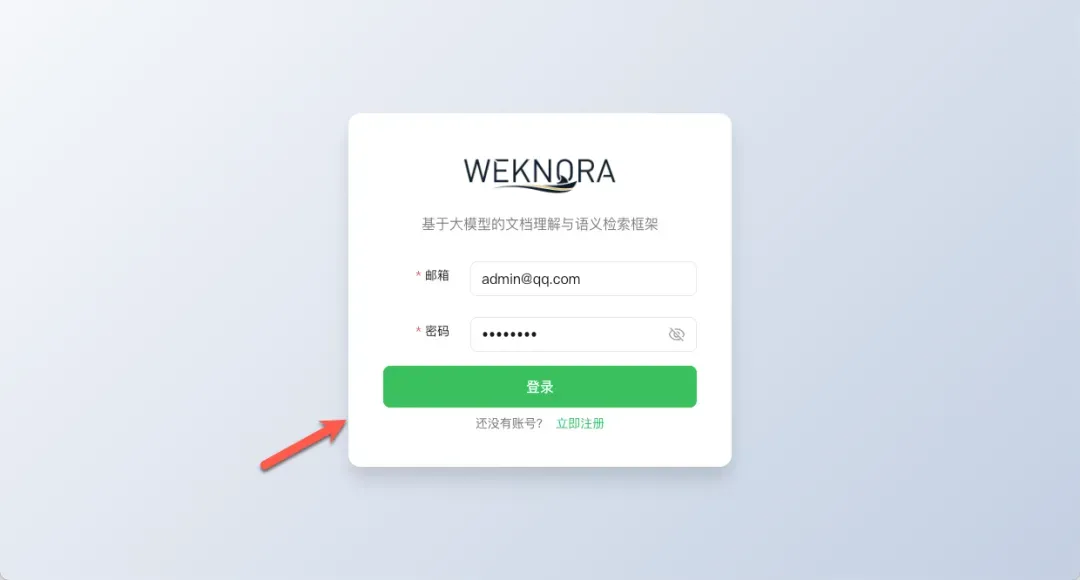
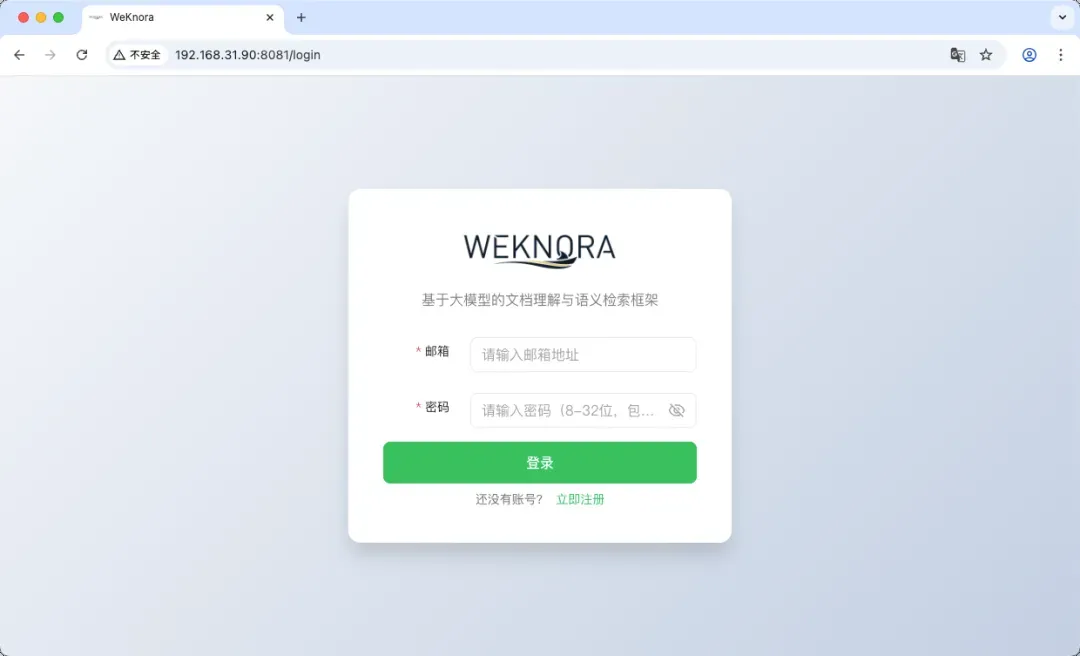 首次访问会进入登录页,点击下方的“立即注册”按钮。
首次访问会进入登录页,点击下方的“立即注册”按钮。
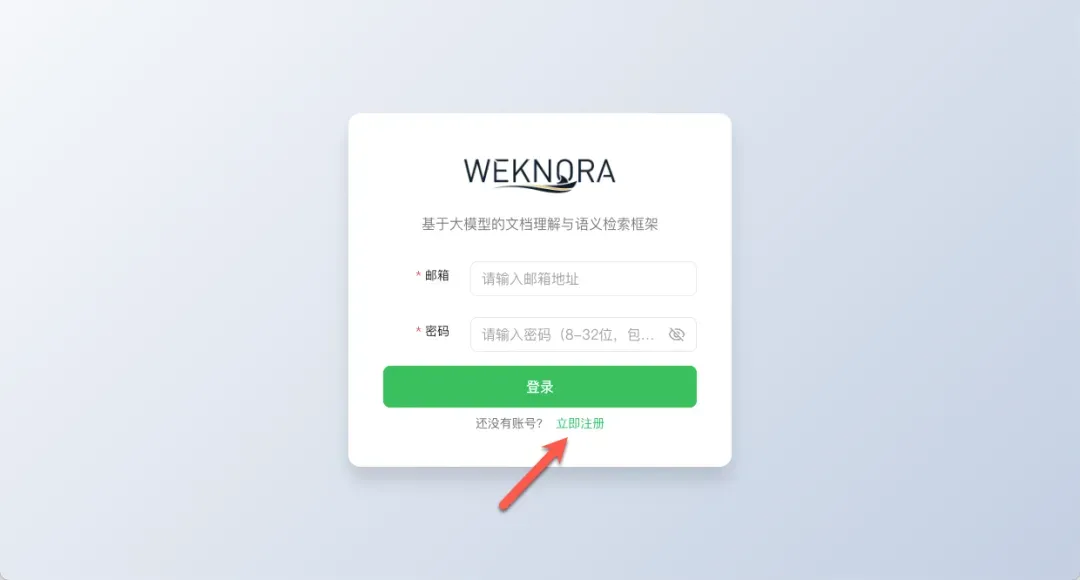 填写用户名、邮箱和密码,完成管理员账户的注册。
填写用户名、邮箱和密码,完成管理员账户的注册。
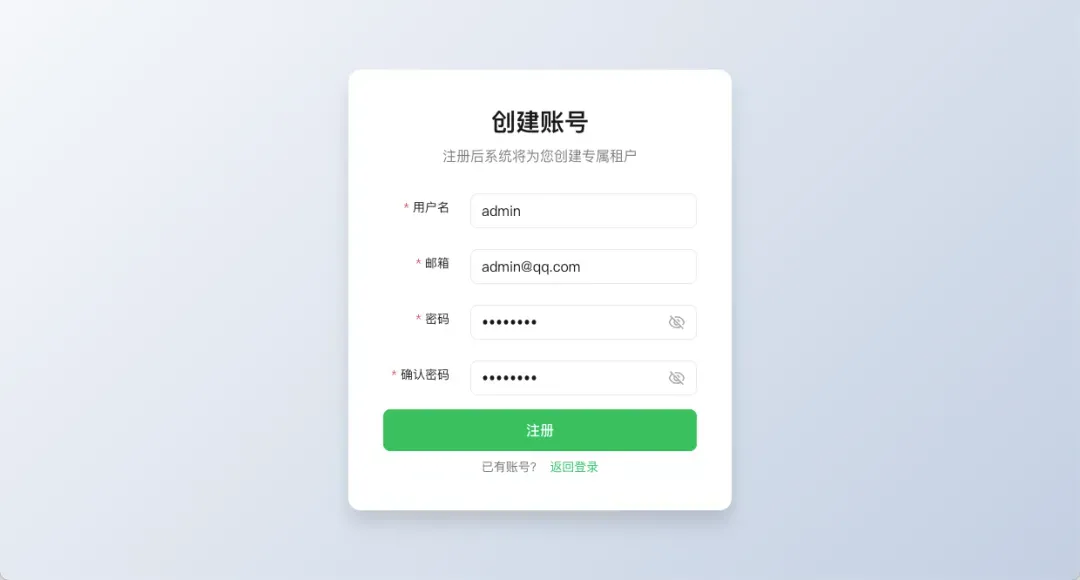 注册成功后,使用刚才设置的邮箱和密码登录系统。
注册成功后,使用刚才设置的邮箱和密码登录系统。
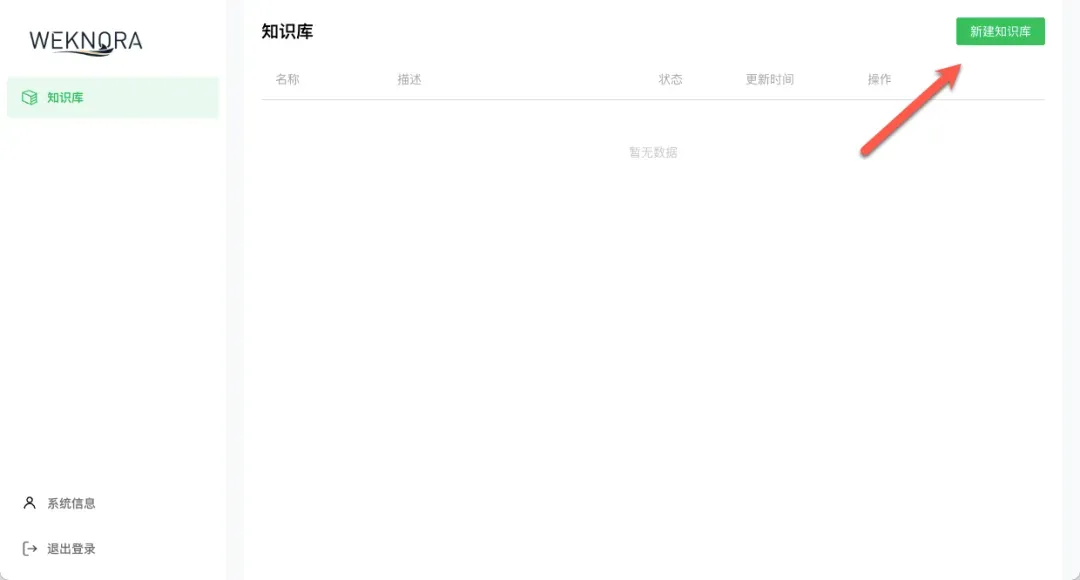
创建与配置知识库
登录后,你会看到一个清爽的管理面板。点击右上角醒目的“新建知识库”按钮,开始创建你的第一个知识库。
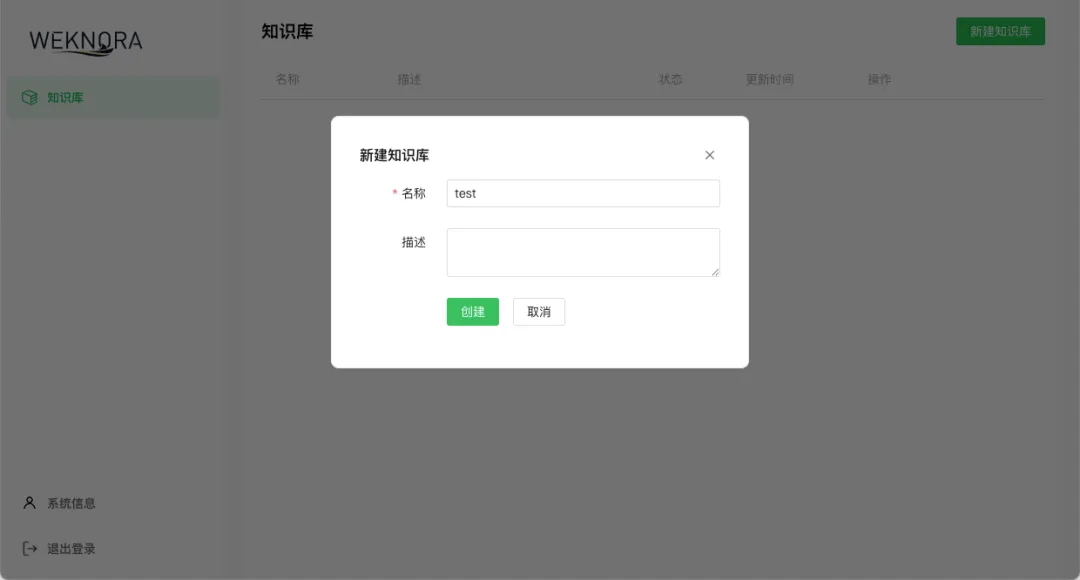
 为知识库起一个易于辨识的名称,例如“公司产品手册”或“个人学习资料”。
为知识库起一个易于辨识的名称,例如“公司产品手册”或“个人学习资料”。
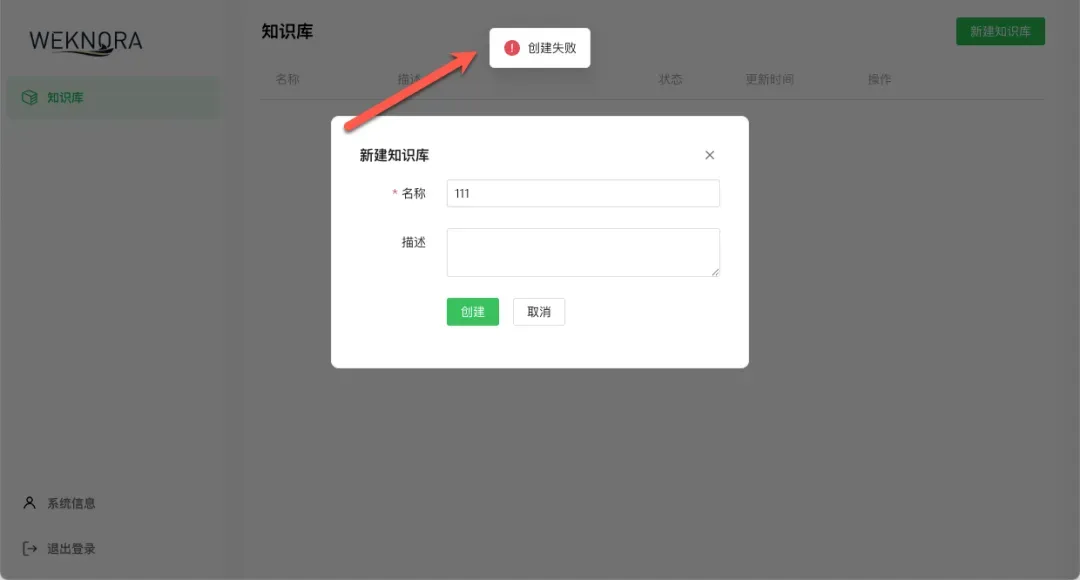
⚠️ 常见问题解决:知识库创建失败
在创建过程中,你可能会遇到一个常见错误:页面提示创建失败。这通常是因为数据库初始化不完整,必要的表没有创建。
 别担心,通过SSH连接到你的NAS,按照以下步骤修复:
别担心,通过SSH连接到你的NAS,按照以下步骤修复:
- 检查现有数据表:首先确认PostgreSQL容器内是否缺少数据表。
docker exec -it WeKnora-postgres psql -U postgres -d WeKnora -c "\dt" 如果输出的表数量很少(只有个位数),说明初始化有问题。
如果输出的表数量很少(只有个位数),说明初始化有问题。 - 执行初始化脚本:运行容器内预置的SQL脚本来创建缺失的表。
docker exec -i WeKnora-postgres psql -U postgres -d WeKnora -f /docker-entrypoint-initdb.d/00-init-db.sql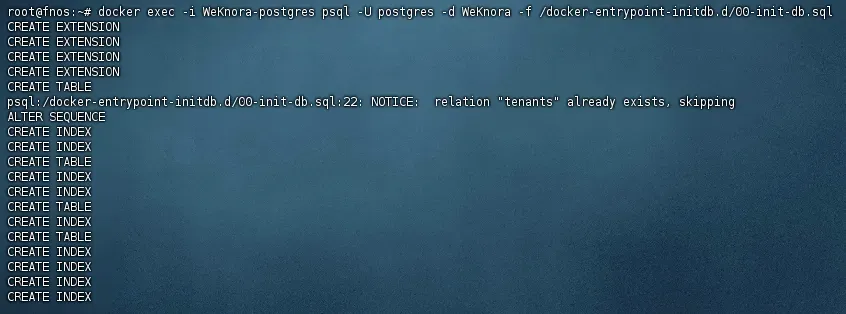
- 再次验证:重新检查数据表,确认所有需要的表都已成功创建。
docker exec -it WeKnora-postgres psql -U postgres -d WeKnora -c "\dt"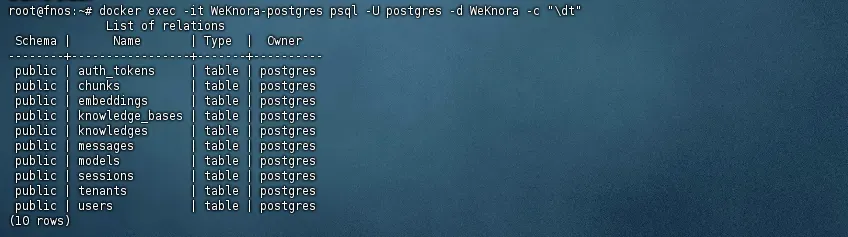
修复完成后,回到Web界面重新创建知识库,应该就能成功了。创建成功后,进入知识库的配置页面。
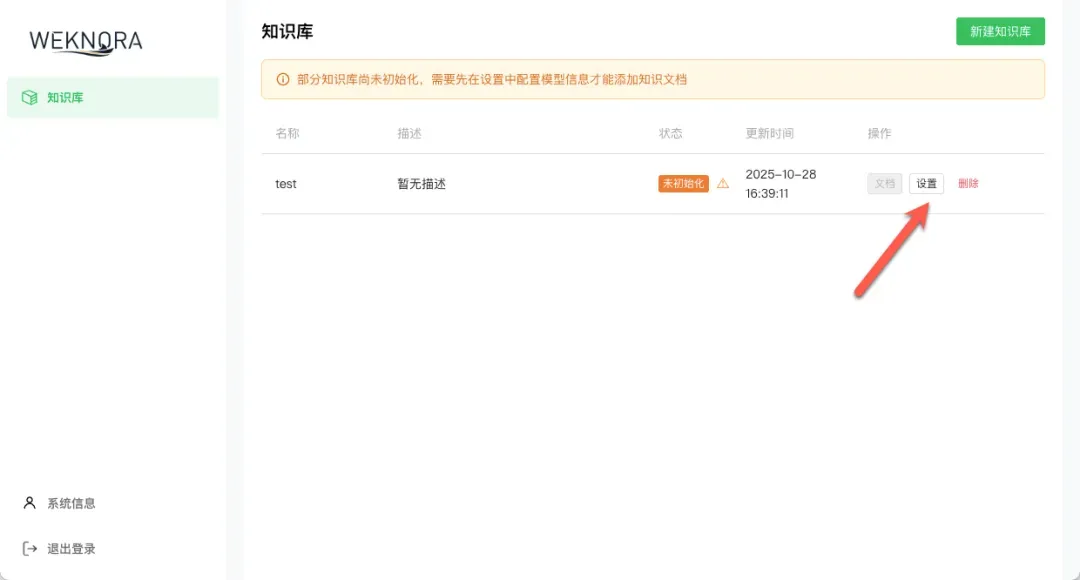 这里有几个关键配置项:
这里有几个关键配置项:
- 模型端点配置:选择你之前部署的Ollama服务。系统会自动连接并列出Ollama中所有已下载的模型。
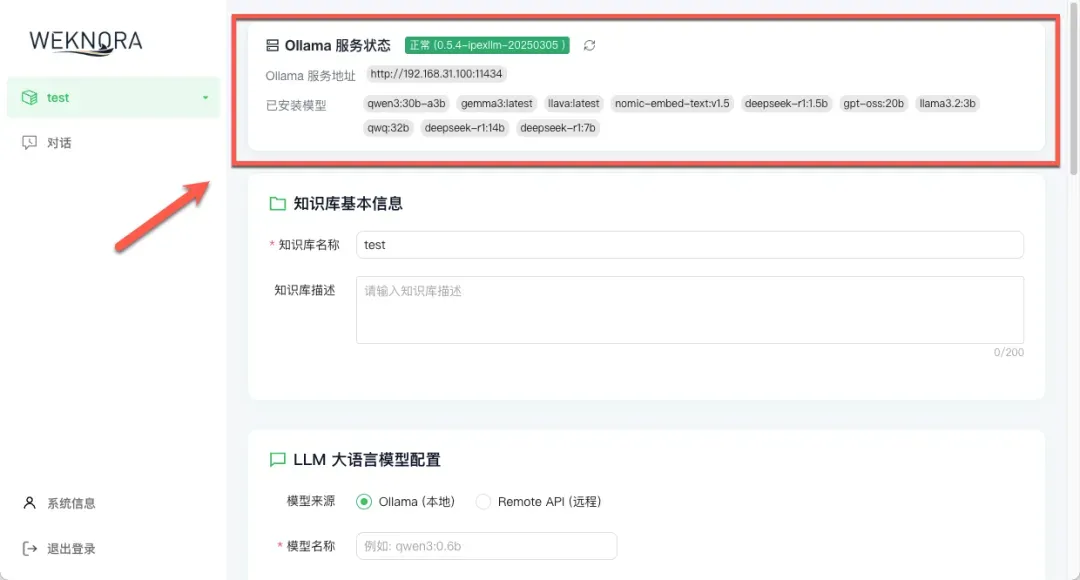
- LLM大语言模型配置:从列表中选择一个用于生成答案的大模型。如果追求响应速度,可以选择7B参数量的模型;如果更看重回答的深度和质量,可以考虑13B或更大参数的模型。
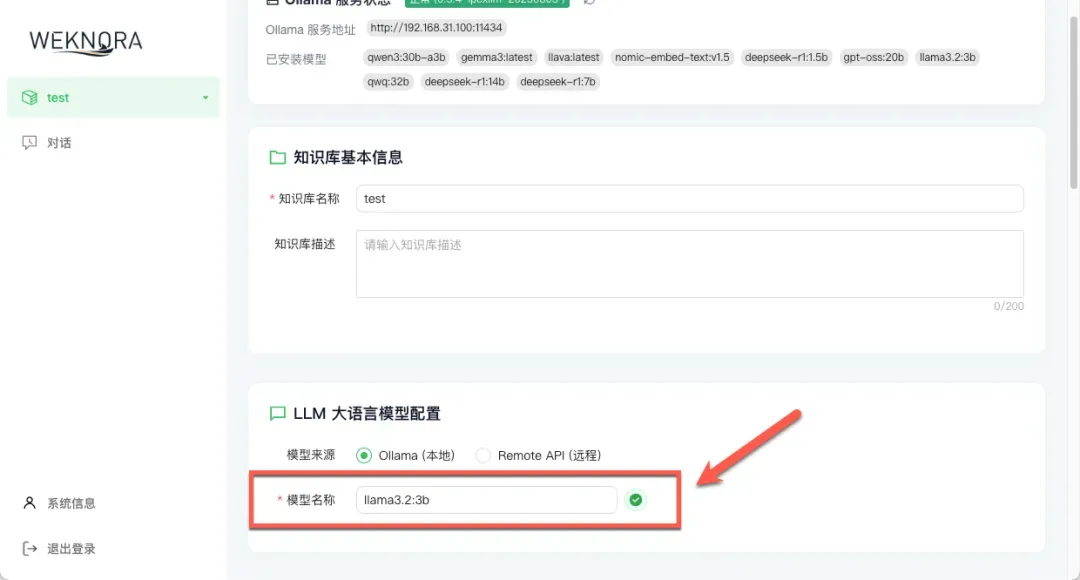
- Embedding嵌入模型配置:这是将文档转换为向量的模型,对检索精度至关重要。强烈建议选择专门的嵌入模型,例如
nomic-embed-text或bge-large-zh-v1.5,它们的语义理解能力通常比通用LLM更强。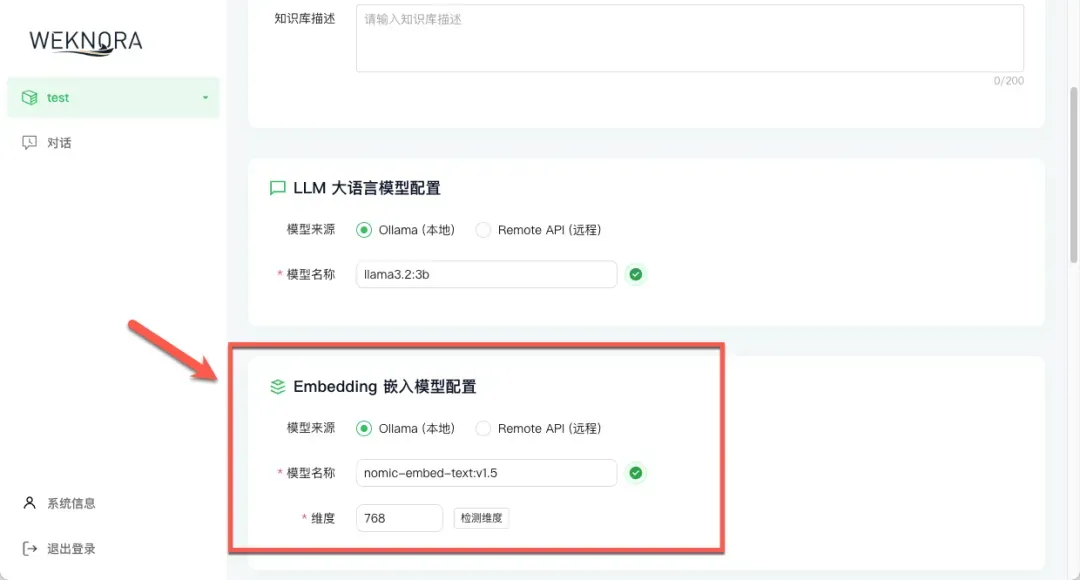
- 其他参数如“温度”(控制回答随机性)、“上下文长度”等可以暂时保持默认。完成所有配置后,切记点击“保存”按钮使配置生效。
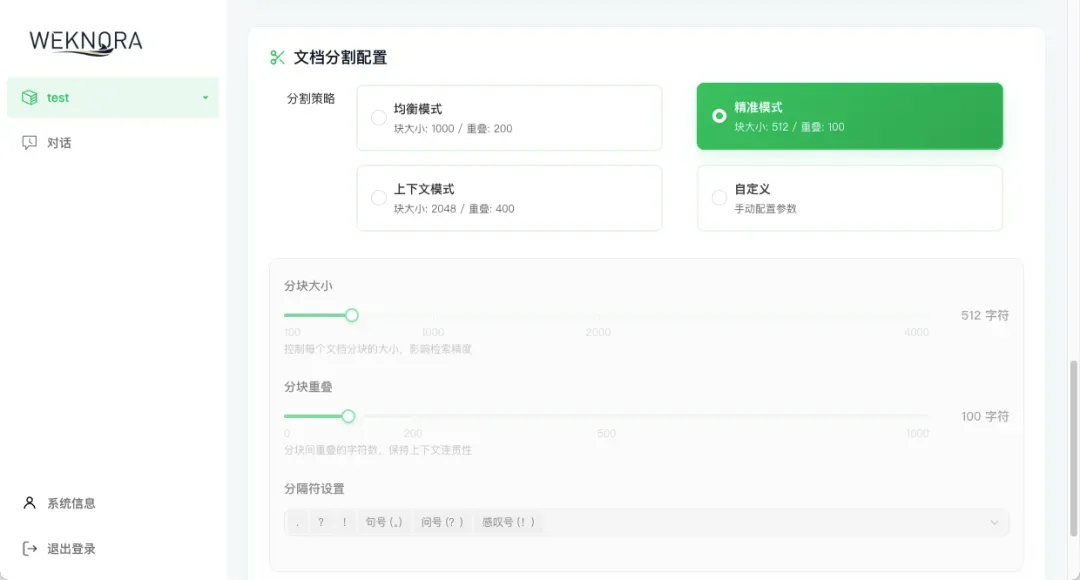
上传文档与测试问答
配置保存后,你就进入了知识库的管理主界面。点击“上传文件”按钮,将你想要让AI学习的文档(支持PDF、Word、TXT等)上传到系统中。
 上传后,系统会在后台自动进行文档解析、文本分块和向量化处理。处理完成后,页面会显示文档已就绪。此时,你就可以在右侧的问答框中针对文档内容进行提问了。
上传后,系统会在后台自动进行文档解析、文本分块和向量化处理。处理完成后,页面会显示文档已就绪。此时,你就可以在右侧的问答框中针对文档内容进行提问了。
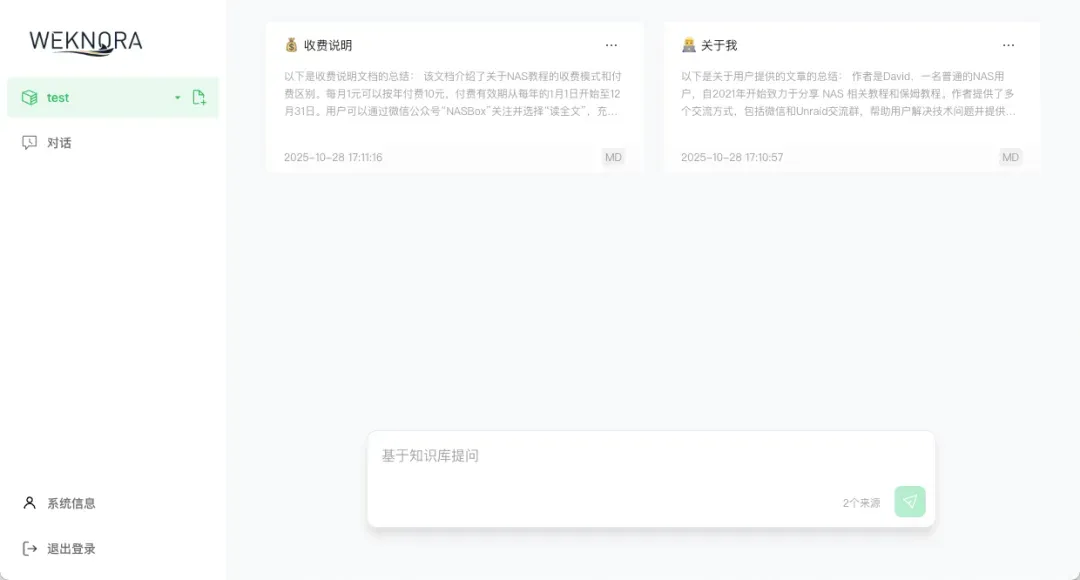 如果一切正常,系统会基于你上传的文档内容生成相关答案,并附上答案的来源片段,这证明整个RAG流程——从检索到生成——都在正常工作。
如果一切正常,系统会基于你上传的文档内容生成相关答案,并附上答案的来源片段,这证明整个RAG流程——从检索到生成——都在正常工作。
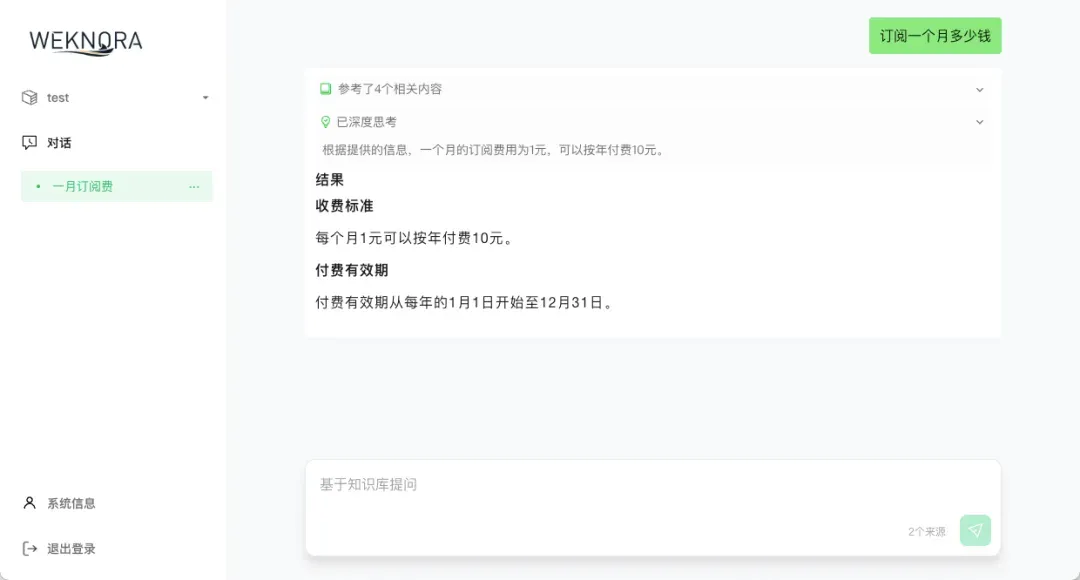 你可以为不同的主题(如“人力资源制度”、“技术开发规范”、“市场报告”)创建多个独立的知识库,实现精细化的知识管理。
你可以为不同的主题(如“人力资源制度”、“技术开发规范”、“市场报告”)创建多个独立的知识库,实现精细化的知识管理。
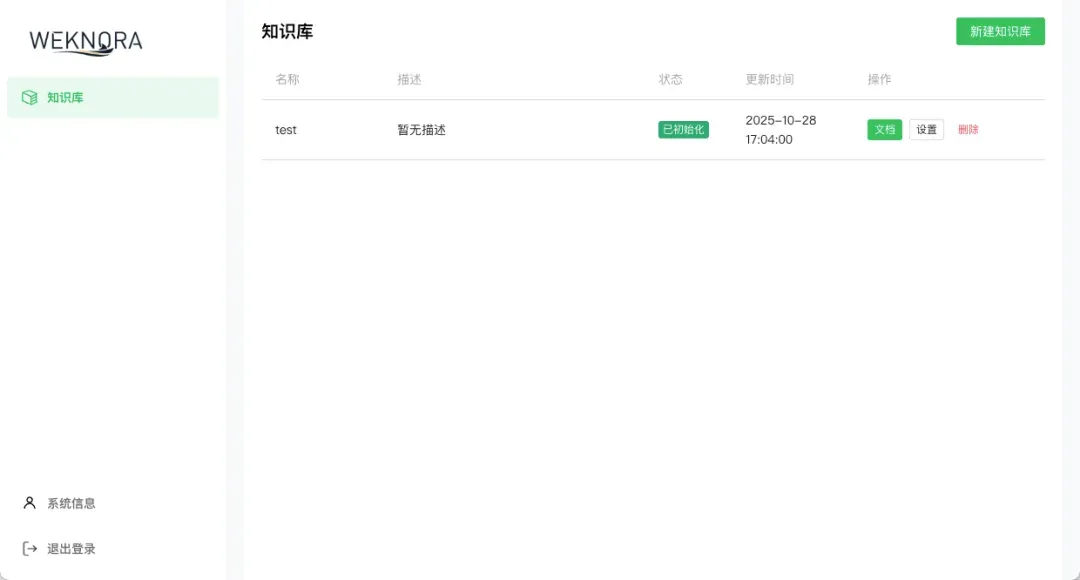
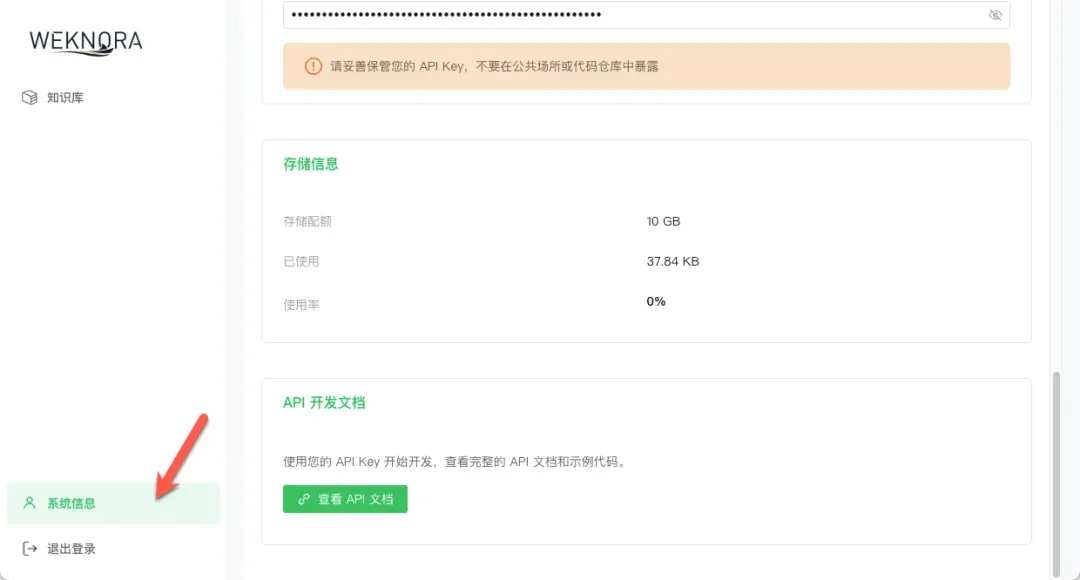
系统管理与资源占用
在系统的“系统信息”页面,官方提供了完整的API接口文档,方便开发者进行二次开发和与企业内部系统集成。
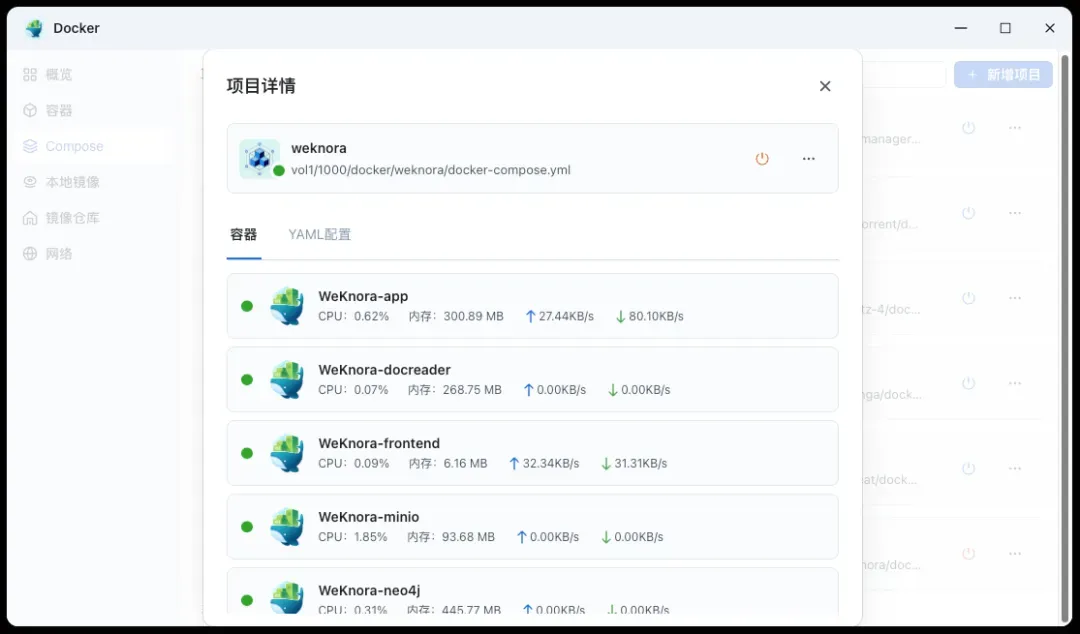
 关于资源消耗(此处不包含独立运行的Ollama服务),WeKnora主体服务在轻量级使用下对NAS的负担尚可。CPU占用通常很低,内存占用根据处理的文档数量和并发请求,大致在1.3GB左右,对于现代的中高端NAS设备来说是可以接受的。
关于资源消耗(此处不包含独立运行的Ollama服务),WeKnora主体服务在轻量级使用下对NAS的负担尚可。CPU占用通常很低,内存占用根据处理的文档数量和并发请求,大致在1.3GB左右,对于现代的中高端NAS设备来说是可以接受的。
总结与评价
回顾整个部署过程,主要的挑战出现在知识库创建环节,其根本原因在于数据库初始化不完整。网络上的一些解决方案往往只停留在重启容器层面,未能触及执行初始化SQL脚本这个核心步骤。最终,通过加入开发者社区交流群,我们获得了这个直接有效的解决方法。
WeKnora本质上是一个功能完备、可私有化部署的“智能知识库”系统。它通过对接大语言模型,将静态文档转化为可交互、可查询的动态知识源。无论是企业用于内部知识沉淀与查询,科研人员用于快速文献调研,还是客服团队用于产品手册的智能问答,它都能提供强大的助力。
- 综合推荐指数:⭐⭐⭐(非常适合有私有化部署需求、注重数据隐私与安全的个人、团队或中小企业)
- 使用体验评价:⭐⭐⭐(Web界面直观友好,基础功能配置流程清晰,用户学习成本较低)
- 部署难度评估:⭐⭐⭐(需要使用者具备基础的Docker和NAS操作知识,遇到问题时需有一定的日志查看和问题排查能力)