腾讯开源AgentMemory:四层记忆架构让AI记住你,准确率提升60%
腾讯开源AgentMemory,让AI真正记住你
腾讯最近开源了一个项目,短短两个月就收获了4600多个Star。它的目标非常专一:为AI Agent装配长期和短期记忆能力。
那装上之后效果如何?我们看评测数据:长期记忆的整体准确率从47.85%提升到76.10%,涨幅接近60%;用户事实召回率从不到30%飙升至79%;而在短期记忆的加持下,长任务最高能节省61%的token消耗。
这个项目就是TencentDB Agent Memory,由腾讯云数据库团队于5月14日正式开源。
AI 记忆到底难在哪
当下,每当你开启一个Agent的新会话,系统几乎默认它对过往一无所知。你不得不重新描述背景或上下文,它才可能按预期工作。而记忆的终极目的,正是提升效率。
TencentDB Agent Memory的思路与主流方案迥然不同,它采取的是符号化短期记忆 + 分层长期记忆。

目前主流的解决方案大致有三种,但均存在明显短板。
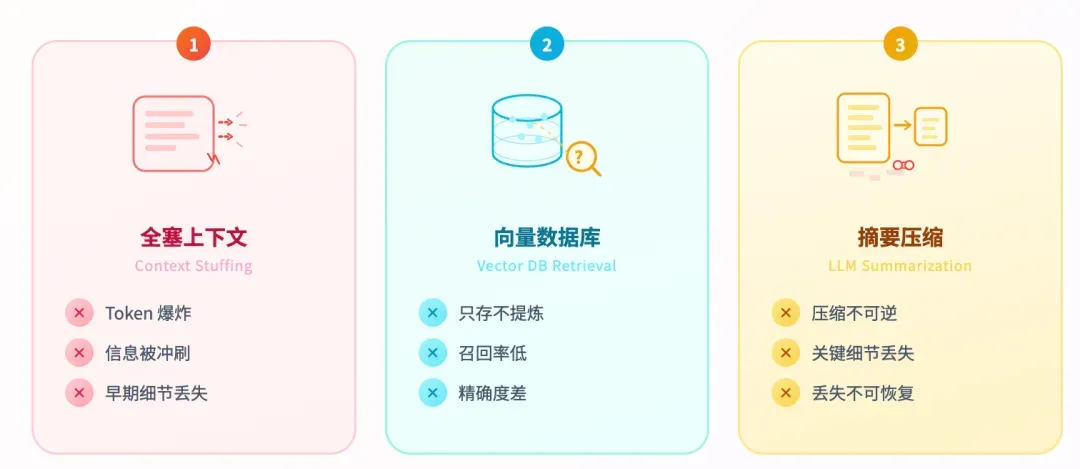
第一种,全量塞进上下文窗口。简单粗暴,可窗口有硬上限,塞得太多token直接爆掉。
第二种,用向量数据库做记忆。比全塞上下文要好一些,但致命伤在于只存不提炼。当对话碎片繁多时,召回率低,精确度也不够。
第三种,让大模型自己做摘要压缩。但压缩是不可逆的,常常导致关键细节丢失。
腾讯开源项目的核心架构
这个项目最核心的设计,是一套四层渐进式记忆架构。从L0到L3,从底到顶,每一层各司其职。
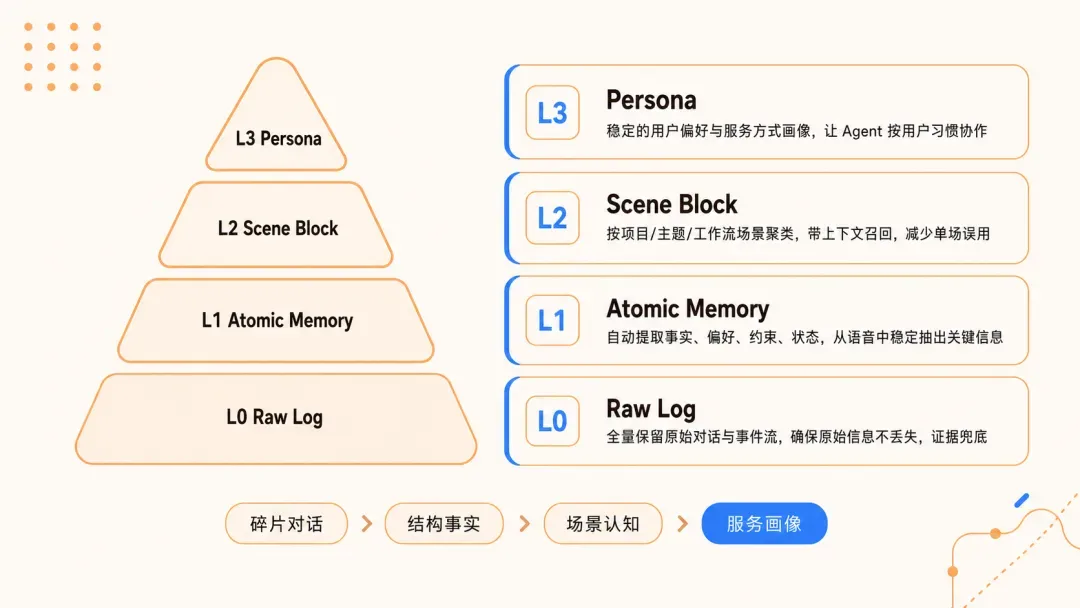
L0:原始对话。
全量保留,一字不落,作为兜底,随时可供回查。
L1:原子事实。
系统会自动从对话中提取独立的事实节点,例如“我爱吃火锅”、“我后面用NextJS”,打上标签并存储。
L2:场景聚类。
相关的原子事实按场景汇聚。比如,用户在系统讨论中涉及的所有事实——表结构、权限、接口——会合成一个场景块,以Markdown格式呈现,人可以直接阅读。
L3:用户画像。
基于下面三层生成稳定的用户画像,沉淀技术偏好、代码风格、常用工具链等。
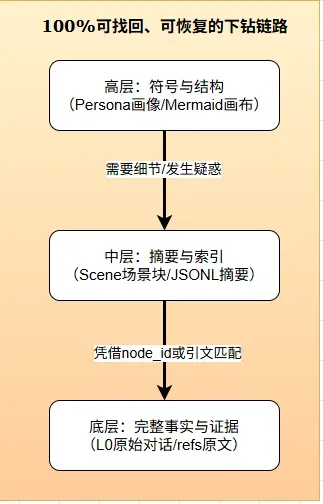
这样一来,既不会因为上下文过长影响推理,也不会丢失关键信息。而且,系统保证了从顶层到原始证据的完整回溯路径。比如L3里提到用户偏好TypeScript,这个结论可追溯到L2的某个场景块,场景块里的每条结论又能回溯到L1的原子事实,而原子事实最终指向L0中你曾经说过的那句话。整条证据链稳固不断裂。
短期记忆压缩:巧用 Mermaid 图
四层架构解决的是长期记忆,但短期上下文同样是烧钱大户。比如AI排查一个bug需要调用十几次工具,上下文会被日志塞满。
解法是符号化记忆,也就是把完整的日志卸载到外部文件,再用Mermaid语法绘制一张紧凑的任务状态图塞进上下文。需要细节时,则通过节点ID来检索。Mermaid用极少的token,将线性摘要列表重组为带状态、依赖关系和可寻址索引的任务拓扑结构图,让大模型通过图的拓扑来推断任务全貌,而不必死记某个标签。
这种方式信息密度更高、结构不丢失、细节可逐层找回。实测结果显示,Token消耗直降超50%,任务完成率反而提升了23%。既省了钱,活儿还干得更好。
语义检索(Embedding)擅长模糊匹配,关键词检索(BM25)则长于精确命中。两路各自召回候选结果,再经由RRF融合排序,语义相关的不会遗漏,精确匹配的也不会丢失。
跑出来的数据
说了这么多设计,来看看实际跑出来的数据。腾讯使用PersonaMem基准测试做了评测,对比了原生OpenClaw与接入Agent Memory之后的OpenClaw:
| 指标 | 原生 OpenClaw | 接入 Agent Memory |
|---|---|---|
| 总准确率 | 47.85% | 76.10%(+59%) |
| 用户事实召回 | 29.63% | 79.07%(+167%) |
| 偏好跟踪 | 66.67% | 83.45%(+25%) |
| 个性化推荐 | 46.67% | 76.36%(+64%) |
其中用户事实召回这个指标最为夸张,从不到30%飙升到79%。也就是说,从前你跟AI说过十件事,它只能想起三件;现在,它能想起八件。
除了PersonaMem,项目还跑了几个编程相关的基准测试:
WideSearch成功率从33%提升至50%,token消耗削减61%;SWE-bench通过率从58.4%升至64.2%,token节省了33%。
加了记忆不但记得更多,做任务的效率也明显变高,省下的token都实实在在地用在了正事上。
怎么用
该项目目前作为OpenClaw的插件发布,安装非常简单,只需一行命令:
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
装完之后默认使用本地SQLite + sqlite-vec作为存储后端,零配置,开箱即用。无需单独安装数据库,也不用连接外部服务,数据完全存放在本地。如果想接入外部Embedding服务来增强语义检索效果,也只需在配置文件里指定即可。
如果你使用的是Hermes Agent框架,项目还提供了Docker一体化镜像,把Hermes + Agent Memory插件 + Gateway全打包在一个容器里,docker pull下来就能直接跑。
支持的模型也非常灵活。最新的1.0.0-beta.1版本为希望自主开发Agent Memory适配层的用户提供了快速开始的方法。
腾讯云数据库AI能力版图
TencentDB Agent Memory并非腾讯云凭空诞生的独立项目,而是5月29日腾讯云“数据库+AI”发布会的一部分。
这场发布会的主题为 AI 原生·重构数据库新范式,核心思路是:当Agent成为新的生产力单元,数据库的使命就要从“存储数据”演进为支撑智能体感知、记忆、决策与协作的数据底座。
沿着AI原生数据库这条主线,腾讯云此次一口气发布了多款产品:
DatabaseClaw,腾讯云第一个数据库Agent。它不同于普通的AI DBA助手,不仅能回答问题,更能够真正进入生产环境承担运维职责,7x24小时不间断运行。自动巡检、异常诊断、慢SQL归因这些DBA日常最耗时间的工作,它全能接手。此外,它还构建了四层安全防线:权限隔离、AI行为护栏、架构安全与全链路审计,让DBA敢将生产库权限交付于它。
TDSQL Boundless,新一代分布式数据库。基于统一的分布式架构,支持关系型事务处理、向量语义检索与全文搜索等多种数据类型,多种访问模式与多种模型数据可在同一个连接、甚至同一个事务中完成,无需再为不同数据类型维护不同数据库。
TDSQL-C,云原生数据库全面升级。本次TDSQL-C重构的第三代存储架构AI Native Storage主打“稳、灾、省”三个字。业务无感的存储组件发布与坏盘替换,带来了极致性价比,TCO相较同类产品下降200%以上;IO零抖动,全链路无损变更;数据零丢失,3 AZ金融级强同步、RPO=0。依托第三代存储架构,TDSQL-C还系统化升级为面向AI时代的双引擎云原生数据库,内核采用PG与MySQL双引擎的云原生计算节点,可一站式对接腾讯云CloudBase的BaaS平台以及Cursor、FastGPT等AI开发者应用,通过MCP、REST等协议实现统一接入。
把这些产品放在一起看,可以清晰地看到腾讯云数据库在做的事:从底层的数据库引擎,到中间的记忆和运维能力,再到上层的AI开发体验,整套Agent时代的数据基础设施,正在用AI原生的思路全面重构。而Agent Memory正是其中与开发者关系最近的一环——它直接解决了“AI如何记住你”这个每个人都会遇到的实际问题。
开源地址:https://github.com/TencentCloud/TencentDB-Agent-Memory