基于Claude Skills的Krawl系统:自媒体知识管理自动化实战
近年来,在投身创业AI项目之余,我还扮演着自媒体人的角色。身为内容创作者,我时常需要从各类平台搜集并整合信息,但整个过程却始终伴随着效率低下与体验不佳的困扰。
举例来说,当我刷到一条内容充实的视频时,脑海中常会浮现这样的想法:“如果能把这段内容转换成文字就好了,日后查阅会方便许多。”
然而现实操作往往陷入这样的循环:先行收藏、再行截图,最终将链接扔进名为“稍后处理”的收藏夹。等到真正需要整理时,不仅当时的灵感与上下文早已烟消云散,手头依然缺乏一份便于使用的文字材料。
过去,我会将这类任务交给实习生处理,但目睹他吃力的操作过程,我总忍不住摇头叹息:
- 反复拖拽视频进度条,只为定位关键语句;
- 紧盯着字幕或费力进行听写,整理出的文本格式却依然混乱不堪;
- 想要添加笔记,但信息点零散分布在时间轴上,难以有效重组。
我不禁思考,如果由我自己操作,一两次或许尚可忍受,但长期如此必然难以坚持。于是,我带领实习生将这个繁琐的流程封装成了一个 Claude Skill。
严格来说,针对这个场景,工作流(Workflow)已是最优解决方案。然而,谁心中没有一个智能体(Agent)的梦想呢?况且,工作流仅解决了单一节点的问题,这个小问题背后实则蕴藏着更广阔的探索空间:
能否构建一套完整的系统,让 AI 自动完成从内容抓取、整理到知识管理的全流程?
于是,我开发了 Krawl 系统:
这是一个基于 Claude Skills 机制的知识库管理系统。在深入探讨 Krawl 之前,我们首先需要理解一个核心概念:Claude Skills。
认识Skills
Anthropic 官方文档对 Agent Skills 给出了如下定义:
Agent Skills are modular capabilities that extend Claude’s functionality. Each Skill packages instructions, metadata, and optional resources (scripts, templates) that Claude uses automatically when relevant.
智能体技能(Agent Skills)是一种模块化的能力,旨在扩展 Claude 的功能范畴。每个技能都封装了相应的指令、元数据以及可选资源(例如脚本、模板)。当遇到匹配场景时,Claude 会自动调用这些技能来完成指定任务。
Agent Skills 包含三大组成要素,它们同时构成了上下文的三个层级,从抽象逐渐过渡到具体:
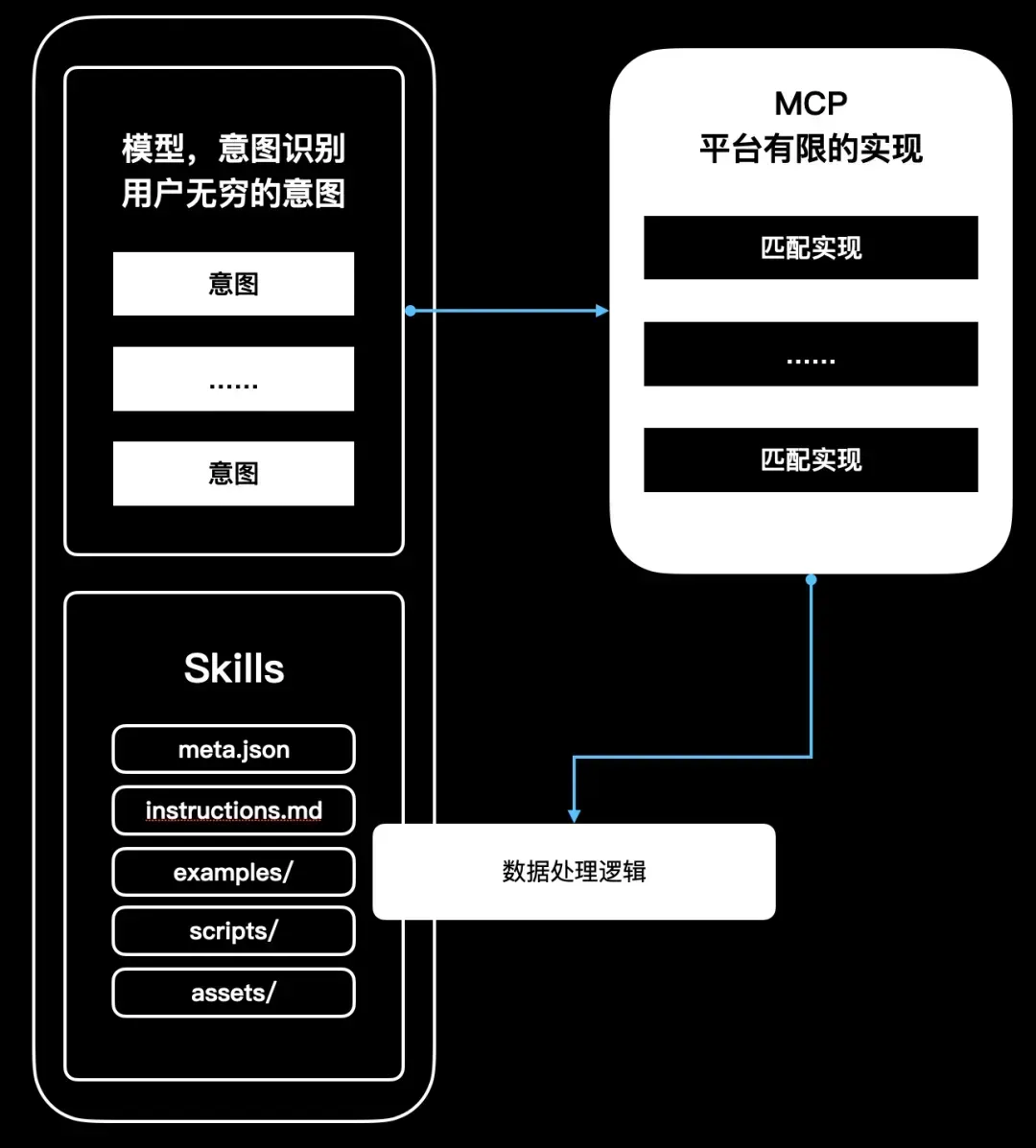
- 元数据:包含技能的名称、描述、标签等基本信息;
- 指令:技能所包含的具体操作指南;
- 资源:技能附带的相关资源(例如文件、可执行代码等);
Claude Skills 的设计遵循了一项非常重要的原则——渐进式披露(Progressive Disclosure):分阶段、按需加载信息,而非在任务初始阶段就将所有内容一股脑地塞入本就宝贵的上下文窗口之中。
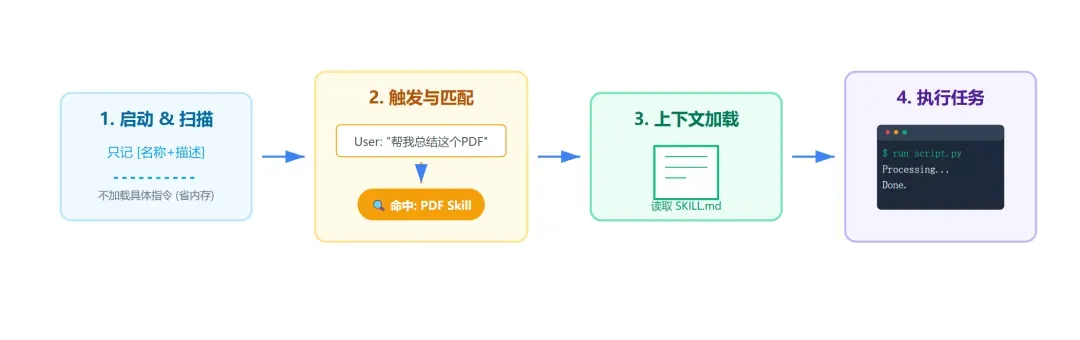
整个加载过程分为三个层次,恰好对应上述三要素:
第一层:元数据(始终加载)
Claude 启动时会扫描所有已安装的 Skills,并加载它们的元数据,将其整合进系统提示(System Prompt)中。 作用:
- 让 Claude 知晓“自身具备哪些技能”;
- 用于后续的意图匹配和技能触发判断;
- 不包含具体执行逻辑,对上下文的占用极小。
示例如下:
---
name: douyin-summary
description: 抖音视频总结助手。当用户提供抖音(douyin.com 或 v.douyin.com)视频链接并请求总结、获取文案或了解视频内容时,使用此技能。通过调用 Coze API 工作流获取视频的转录文本或文案,然后为用户提供智能化的内容总结。
---
第二层:核心指令(触发时加载)
当用户的请求与某个 Skill 的描述相匹配时,Claude 会通过 bash 从文件系统中读取对应的 SKILL.md 文件,并将其完整内容载入当前对话上下文。
作用:
- 为 Claude 提供清晰、可复用的任务执行逻辑;
- 将“需要反复解释的 Prompt”固化为稳定可靠的能力指令。
示例如下:
# 抖音视频总结助手
此技能用于获取和总结抖音视频的内容。
## 工作流程
当用户提供抖音链接时:
1. **识别抖音链接**: 检测用户输入中的 douyin.com 或 v.douyin.com 链接
2. **调用脚本获取内容**: 使用 `scripts/fetch_douyin.py` 获取视频转录/文案
python3 ./scripts/fetch_douyin.py <url>
3. **总结内容**: 基于获取的文本内容,提取核心观点、关键信息或有趣之处
4. **友好输出**: 以简洁易懂的方式呈现给用户
第三层:代码与资源(按需加载)
一个功能复杂的 Skill 可能包含多个文件,从而形成一个完整的知识单元。Skill 能够将这些资源与指令打包在一起,实现任务执行的完整闭环。
通过 元数据 → 指令 → 代码与资源 这三层递进结构,一个 Skill 不仅能被 Claude 准确识别和触发,更能真正完成从“理解需求”到“执行任务”的完整操作闭环。
Skills的核心价值
通过实际案例,大家可以深刻体会到 Skills 模式所带来的多重价值:
- 知识的沉淀与复用:反复使用的流程被固化为技能,避免了重复造轮子;
- 模块化架构:每个技能都保持独立,易于测试、维护和扩展;
- 无限的可能性:通过组合不同的技能,可以构建出复杂的工作流程;
最后也是最关键的一点,它能显著提升工具(Tools)调用的准确性;
Claude Skills的安装与使用
在 Claude Code 中,你可以通过以下两种方式使用 Skills:
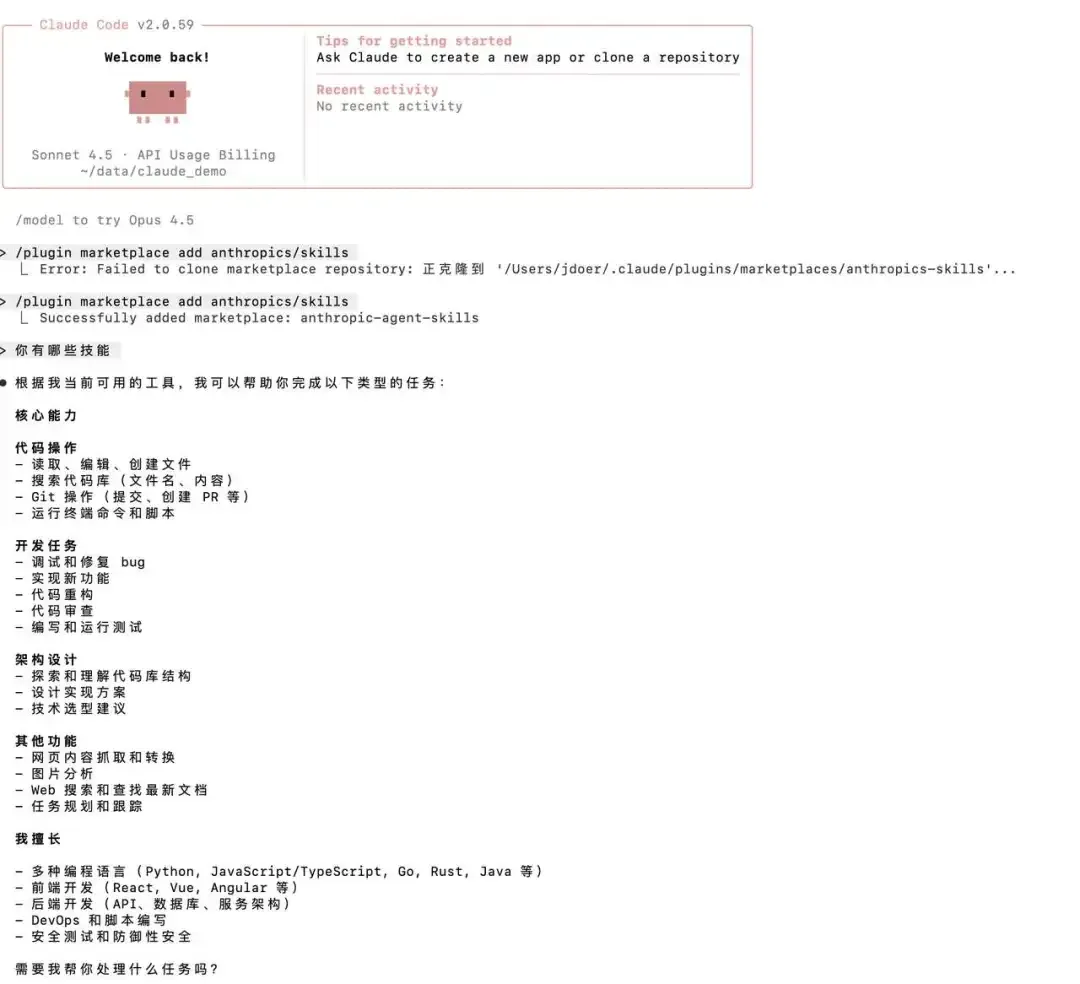
方法一:使用官方技能市场(推荐)
# 添加官方技能库
/plugin marketplace add anthropics/skills
# 浏览可用技能
/plugin list
# 安装文档处理技能
/plugin install document-skills@anthropic-agent-skills
安装完成后,你可以直接询问 Claude 当前拥有哪些技能。
方法二:手动创建自定义技能
如果你想自行定义一个技能,例如“自动总结抖音视频”,你可以亲手编写一个 Skill。其原理相当简单:
- 在用户根目录下的
~/.claude/skills/中创建一个新文件夹,例如douyin-summary。 - 编写指令:在该文件夹内创建一个
SKILL.md文件,告诉 Claude 这个技能的作用和使用方法。 - 准备工具:(可选)放入 Python 脚本或其他辅助文件。
最终的目录结构大致如下所示:
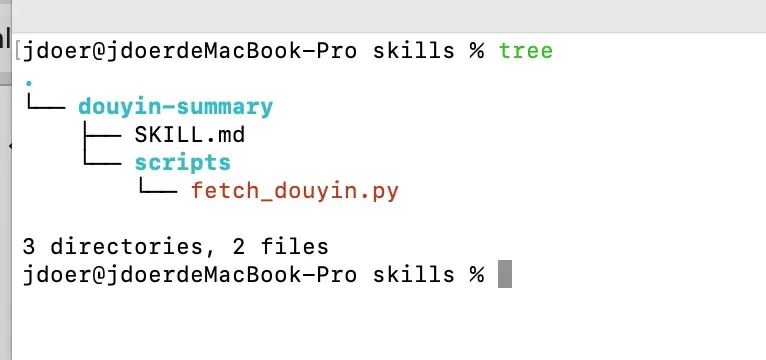
- 创建技能目录:
mkdir -p ~/.claude/skills/douyin-summary
- 编写SKILL.md:
---
name: douyin-summary
description: 抖音视频总结助手。当用户提供抖音视频链接时,自动调用此技能获取文案并总结。
---
# 抖音视频总结助手
## 工作流程
1. 识别用户输入中的douyin.com链接
2. 调用scripts/fetch_douyin.py获取视频文案
3. 提取核心观点并结构化输出
- 实际使用:
配置妥当后,可以查验技能是否安装成功。旧版本的 Claude code 需要重启方能识别新安装的技能,而新版本已无需此步骤。

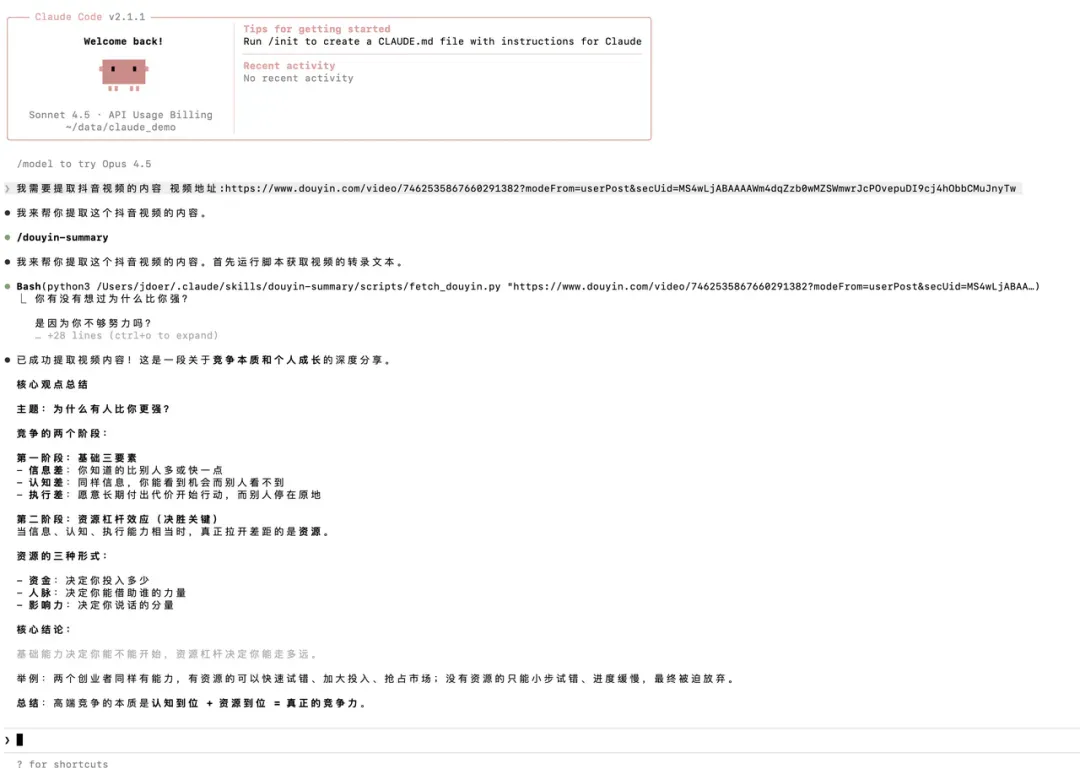
使用 Claude Skills 提取抖音视频内容的效果如下图所示:
了解上述基础知识后,我们再来探讨简单的知识库系统如何实现:
基于Skills构建系统
Krawl 是一套知识管理与智能问答系统,它通过技能扩展机制实现了 AI 与各类工具的深度融合。
简而言之,它使得 AI 从一个“被动回答问题”的聊天机器人,转变为一个“能主动调用工具完成任务”的智能助手。
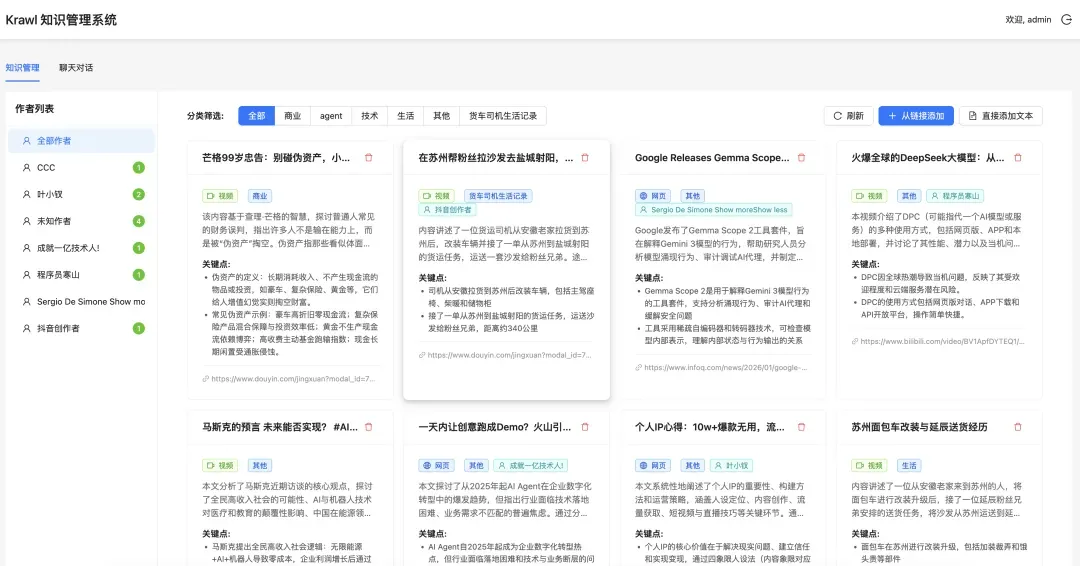
系统效果展示
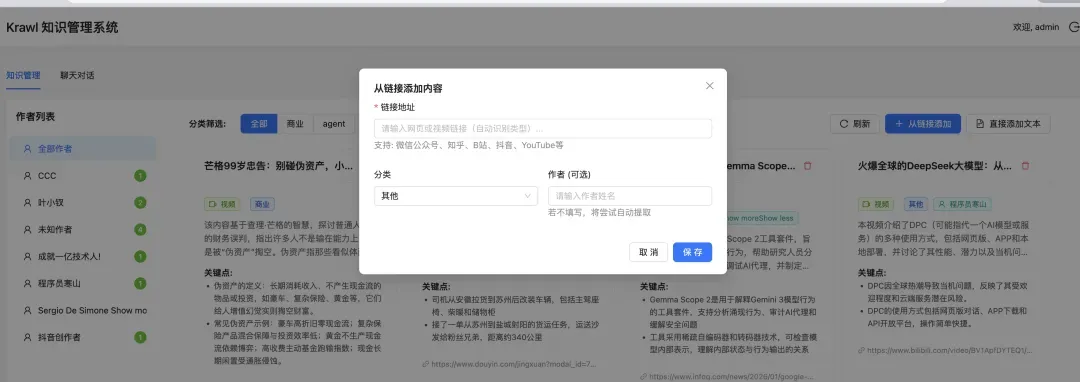
点击界面右上角的“从链接添加”按钮,输入需要解析的链接地址,系统便会自动提取内容:
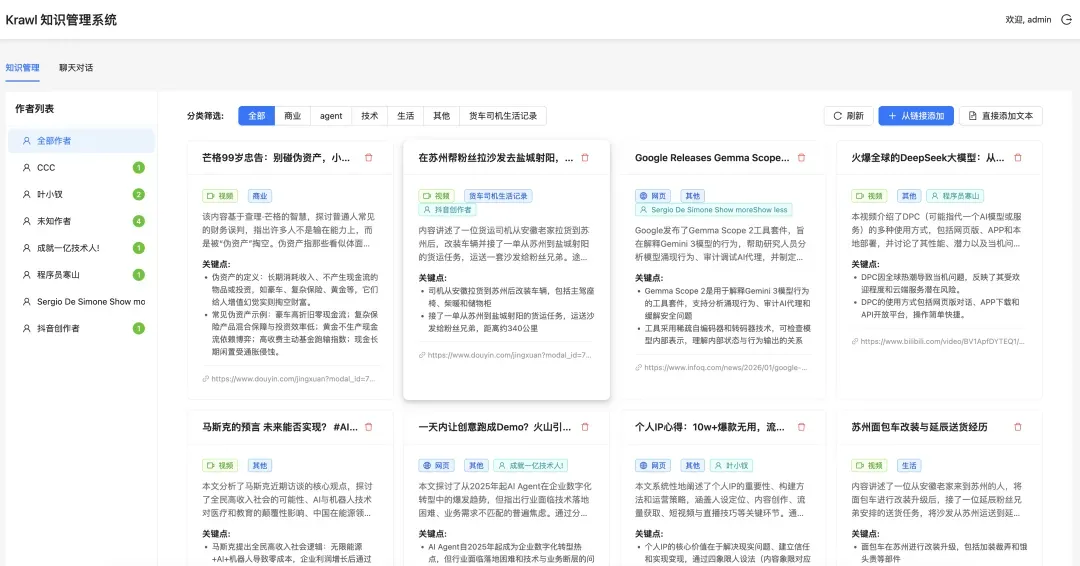
添加完成后,系统会自动提取内容并生成智能总结:
Skills 设计思想
Skills 模式的应用相当直观:将“多媒体内容提取与入库”这一复杂流程封装为独立的 link_ingest 技能,同时将“知识库检索”功能封装为 knowledge_query 技能。
这种高度模块化的设计带来了显著优势:技能与核心系统实现解耦,具备极强的可移植性。如果其他项目需要类似能力,仅需复制对应的技能文件夹,即可实现能力的“即插即用”。
Skills 工作原理
一个完整的技能由三个层级构成,此设计与 Claude Skills 一脉相承:
- 元数据(始终加载):告知 AI “当前有哪些技能可用”;
- 指令(触发时加载):告知 AI “如何执行这个技能”;
- 资源与代码(按需加载):实际执行具体任务的组成部分;
在 Krawl 的技能系统实现中,我们采用了一种 “动态路由”(Dynamic Router) 与 “懒加载”(Lazy Loading) 相结合的架构。
这种设计旨在解决随技能数量增长而引发的启动延迟和上下文污染问题,其核心原则包括:
- 懒加载:系统启动时仅扫描技能的元数据(Markdown Frontmatter),并不加载具体的 Python 代码。
- 元控制:系统提供一个核心的元工具
load_skill。大型语言模型(LLM)根据任务需求,自主决定加载哪个技能。 - 资源隔离:技能的代码和工具定义在需要时动态注册到当前会话中。
整体技术架构如下所示:

核心实现
要实现这样一个动态路由系统,需要几个核心组件的协同工作。下面我将展示 Krawl 后端的关键代码实现。
1、技能元数据结构
首先,我们需要定义一个轻量级结构来承载技能信息。其核心目的是占位,而非直接加载代码对象。
@dataclass
class SkillInfo:
"""Skill 信息容器 - 核心是 lazy load"""
name: str
description: str # 从 skill.md 的 frontmatter 读取的简短描述
is_loaded: bool = False # 标记是否已加载实际代码
content: str = "" # skill.md 的完整内容 (Prompt)
tools: List[Dict[str, Any]] = field(default_factory=list) # 具体工具定义
handlers: Dict[str, ToolHandler] = field(default_factory=dict) # 执行函数
module_path: str = ""
2、管理器与轻量扫描
SkillManager 是整个系统的调度中枢。它在启动时仅执行“轻量级扫描”:仅遍历目录结构并读取 Markdown 文件的头部描述,不加载任何 Python 代码:
class SkillManager:
def scan_skills(self) -> None:
"""轻量级扫描:只读取目录结构和 frontmatter,不加载具体代码"""
for item in self._skills_dir.iterdir():
if not item.is_dir() or item.name.startswith("_"):
continue
# 仅读取 Frontmatter 描述,不读取全文,保证启动速度
description = self._read_frontmatter_description(item / "skill.md")
self._skills[item.name] = SkillInfo(
name=item.name,
description=description
)
3、动态加载机制
这是系统实现的核心所在。当且仅当 LLM 决定使用某个技能时,我们才通过 activate_skill 方法动态加载对应的代码文件:
def activate_skill(self, skill_name: str) -> Tuple[bool, str, List[Dict[str, Any]]]:
"""按需激活一个 Skill"""
skill = self._skills.get(skill_name)
# 1. 命中缓存直接返回
if skill.is_loaded:
return True, skill.content, skill.tools
# 2. 动态读取 Prompt (skill.md)
md_path = self._skills_dir / skill_name / "skill.md"
skill.content = md_path.read_text(encoding="utf-8")
# 3. 动态 Import 代码模块 (execute.py)
# 只有这一步才会真正消耗内存和解释器资源
module_name = f"app.skills.{skill_name}.execute"
module = importlib.import_module(module_name)
# 4. 提取并注册工具
skill.tools = getattr(module, "TOOLS", [])
skill.handlers = getattr(module, "HANDLERS", {})
skill.is_loaded = True
# 将新工具注册到活跃列表
for name, handler in skill.handlers.items():
self._active_handlers[name] = handler
return True, skill.content, skill.tools
4、元工具实现
为了让 AI 能够自主控制这一过程,我们需要将 load_skill 暴露给 LLM。这是它唯一自带的“初始技能”(元工具),用于发现和加载其他技能:
async def _handle_load_skill(self, args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
"""Meta-Tool: 允许 LLM 自行加载新能力"""
skill_name = args.get("skill_name")
success, content, tools = self.activate_skill(skill_name)
if success:
tool_names = [t["name"] for t in tools]
return {
"ok": True,
# 关键:告诉 LLM 加载成功,并把 Manual (skill.md) 返回给它学习
"message": f"Skill '{skill_name}' loaded.",
"manual": content,
"new_tools": tool_names
}
return {"ok": False, "error": content}
流程梳理
为了让各位更清晰地理解这套系统如何运转,我们以“用户想要保存一个抖音视频”为例,拆解整个交互流程:
场景:用户发送消息“帮我保存这个视频 https://v.douyin.com/xxxxx”
1、系统初始化
系统启动时,SkillManager 扫描 skills 目录。
- 它仅读取 skill.md 文件的头部信息(名称和描述)。
- 结果:系统知晓存在 link_ingest 这个技能,但尚未加载其代码,内存占用极低。
2、意图识别与路由
用户消息被发送给 LLM。此时,系统提示(System Prompt)中包含了一份“技能菜单”:
Available Skills:
- link_ingest: 链接内容提取技能...
- knowledge_query: 知识库查询...
LLM 分析用户意图:“用户想保存视频,这与 link_ingest 的描述相符”。决策:LLM 决定调用元工具:load_skill(skill_name=“link_ingest”)。
3、动态加载与注册
系统接收到 load_skill 请求后:
- 读取 link_ingest/skill.md 的完整内容(作为操作手册)。
- 动态导入 link_ingest/execute.py 模块。
- 将 execute.py 中定义的工具 save_link_knowledge 注册到当前会话的工具列表中。
返回给 LLM 的信息:
Skill 'link_ingest' loaded.
Manual: (skill.md 的内容...)
4、执行具体任务
LLM 收到加载成功的消息,并阅读了刚返回的操作手册。手册告知它:“要保存链接,请调用 save_link_knowledge(url=…)”。
决策:LLM 再次发起工具调用 save_link_knowledge(url=“https://v.douyin.com/xxxxx")。
系统执行对应的 Python 函数,完成下载视频、提取字幕、存入数据库等操作,并返回结果:
{"ok": true, "title": "抖音视频...", "id": 101}
5、最终响应
LLM 根据工具返回的结果,组织自然语言回复用户: “视频已保存!标题是《…》,已归档到视频分类中。”
理解上述流程后,便进入到关键技能的具体实现环节:
关键skill实现
首先是 link_ingest,即链接内容提取技能:
这是 Krawl 系统最核心的技能,也是文章前言中所提及痛点的直接解决方案:

为了配合这套系统,每个 Skill 的脚本文件 (execute.py) 必须遵循标准协议。以 link_ingest 为例:
# app/skills/link_ingest/execute.py
# 1. 工具定义 - 告诉 LLM 这个技能能做什么
TOOLS = [
{
"name": "save_link_knowledge",
"description": "将链接内容保存到知识库...",
"parameters": {
"type": "object",
"properties": {
"url": {"type": "string"},
"category": {"type": "string"}
},
"required": ["url"]
}
}
]
# 2. 工具实现 - 实际的处理逻辑
async def save_link_knowledge(args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
url = args.get("url")
# ... 业务逻辑 ...
# 调用 Service 层处理
return {"ok": True, "id": 123}
# 3. 处理器映射 - (系统自动注册到路由表)
HANDLERS = {
"save_link_knowledge": save_link_knowledge
}
其次是 knowledge_query,即知识库查询技能。当用户提出问题时,该技能会被自动调用:
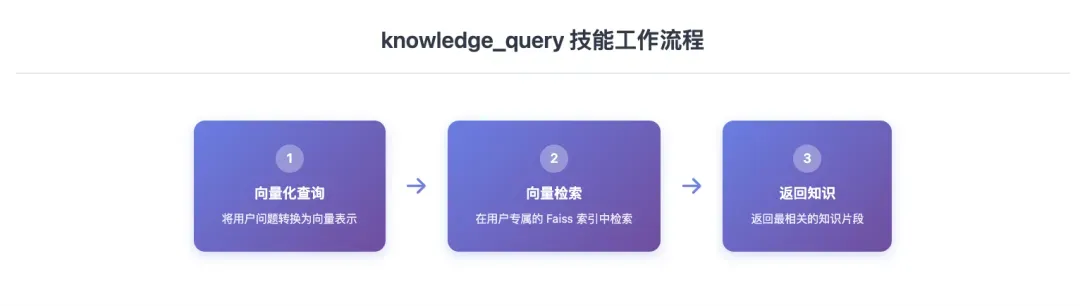
# 工具定义(供 loader 读取,传给大模型)
TOOLS = [
{
"name": "search_knowledge",
"description": "搜索用户的个人知识库,查找与用户问题相关的已保存内容。支持单个查询或多个查询。当用户询问已保存的知识、提问关于之前保存的内容时使用。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词或问题(单个查询,与 queries 二选一)"
},
"queries": {
"type": "array",
"items": {"type": "string"},
"description": "多个搜索关键词或问题(多个查询,与 query 二选一)"
},
"top_k": {
"type": "integer",
"description": "每个查询返回最相关的结果数量,默认3个,最多10个",
"default": 3,
},
},
"required": [],
},
},
]
async def search_knowledge(args: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
"""搜索知识库内容,支持单个或多个查询。"""
return {"ok": true,"content":"content"}
# 工具名称到处理函数的映射
HANDLERS = {
"search_knowledge": search_knowledge,
}
至此,一个简易技能便已实现。最后,我们来探讨一下 Skills 的“最佳实践”:
结语
通过 Krawl 项目的实践,我总结了 Skills 模式的几个典型适用场景:
- 重复性工作流:将重复的 AI 交互流程固化为技能;
- 工具集成:需要 AI 调用外部工具或 API 的场景;
- 复杂任务分解:将复杂任务分解为多个可复用的子技能;
- 多用户共享能力:在团队或社区中共享 AI 能力;
在具体实施过程中,需注意:从简单开始。切勿一开始就构建复杂系统,应先创建一个能解决具体问题的小型技能,以验证思路。
其次是技能的粒度把握:
- 技能不宜过大:一个技能应当只专注于完成一件事;
- 技能不宜过小:避免技能数量爆炸,导致难以管理;
- 建议:按业务领域划分技能,每个技能对应一个完整的用户故事;
最后,是错误处理与监控:
- 为每个技能设计清晰的错误处理机制;
- 记录技能的使用日志,便于调试和优化;
- 考虑技能的版本管理,以支持回滚操作;
在 Krawl 项目中,Skills 机制使 AI 转变为一个能够主动调用工具、完成实际任务的智能助手。这种“技能化”的设计思想,值得在更多项目中加以应用和实践。