语音识别API实战指南:从切片模拟到实时流式,深度解析ASR模型的应用与优化
语音识别 API 和语音生成 API 是音频大模型的两大核心应用方向。会议纪要自动生成、语音输入法等都属于语音识别的典型场景。
与文本类大模型相比,音频类大模型的 API 调用对实时性、稳定性和处理逻辑提出了更高的要求。在实际应用中,语音识别 API 主要分为切片式和实时流式两种调用模式。
通常,我们拿到的是一个兼容 OpenAI 格式的音频 API 接口,例如:
url = "http://localhost/v1/audio/transcriptions"
请求体大致如下:
data = {
"file": file_input_mp3,
"model": model
}
response = requests.post(
url,
headers = headers,
data = data
)
下面是一个通过切片方式模拟实时语音识别的演示:

切片方案虽然简单,但会带来上下文过短、调用频率高、识别准确率不足等问题,容易产生歧义。
把音频切成 3 秒、5 秒或 8 秒的小段,本质上是在“实时感”和识别质量之间做的一种妥协设计。
- 方案 A:录制完整音频再一次性发送 → 难以做到实时反馈,用户需要等待较长时间才能看到识别结果。
- 方案 B:每隔几秒切出一段并发送 → 接近实时体验,但也引入了一系列新的挑战。
使用切片会遇到哪些典型问题?
问题一:词语或句子被强行切断
假设用户说:“今天天气真好,我们去公园吧”,切片可能变成:
- 第 1 段 (0-3s):“今天天气真” ← 句子被截断
- 第 2 段 (3-6s):“好,我们去公园吧”
每一段都是独立识别,模型无法感知段与段之间的自然边界,断句位置极易出现识别错误或多余的标点符号。
问题二:上下文信息严重丢失
每次只能“听到”几秒钟的音频,模型缺乏前文语境参考。以下情况都会受到严重影响:
- 跨句子的语义关联(例如“他刚才说的那个方案……”)
- 语气词、连读和吞音现象
- 专有名词依赖上下文才能正确推断
段越短,上下文窗口越窄,识别准确率越低。
问题三:API 请求大量堆积
假设 API 响应耗时约 2 秒,但我们每 3 秒发送一个新片段:
- 0s:发送第 1 段
- 3s:发送第 2 段(此时第 1 段可能还未返回)
- 6s:发送第 3 段(前两段仍未回来)
- 9s:发送第 4 段……
请求会不断累积,最终返回的结果可能乱序到达。更糟的是,每次 API 调用都有固定的性能开销,段越短、请求次数越多,总体成本反而更高。高频率调用也容易触发流量限制,若每 3 秒一次请求(即每分钟 20 次),长时间录音场景下很可能被服务端封禁。 另外,当用户说话中途出现停顿(如思考、犹豫),对应的小片段可能全部是静音,但仍然白白消耗 API 调用额度。
如何改进切片方案?
- 引入 VAD 静音检测,只在用户自然停顿时进行切分,尽量避免切断完整的句子。
- 改用较长段落模式,比如每次录制 30 秒再发送,能够显著提升识别准确率。
- 增加请求队列机制,保证识别结果按时间顺序组装显示,避免文本“乱跳”。
- 评估 API 是否支持流式传输,如果提供 WebSocket 等接口,则可以构建真正的实时识别系统。
真正的流式语音识别,其演示如下:
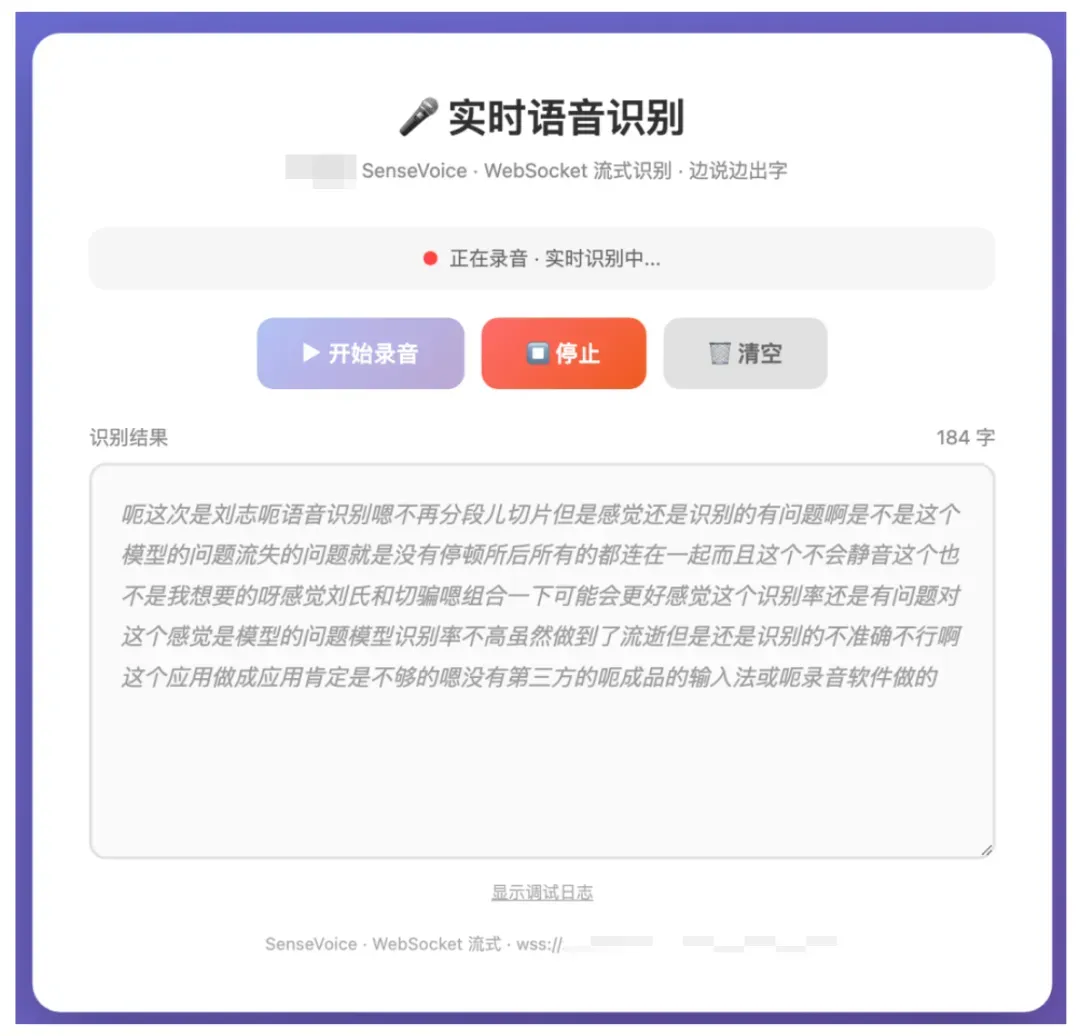
流式接口的特点在于:当用户停顿时,不会主动发送数据请求,只有检测到有效语音才进行识别处理。但这也带来了新的问题——完全没有停顿,即缺少逗号和句号等自然的标点切分,所有文字会全部连在一起。 比如上面演示的大段识别结果中,几乎看不出任何句子边界。
如果打算自己动手做一款语音应用,还需要进行大量工程化尝试。想要达到“豆包输入法”或“千问输入法”那种自带纠错、自动纠偏的高级体验,并不容易。
在首次调用语音 API 的过程中,我们重点学习了切片式和流式两种调用方式。后续还需要补充许多优化知识,例如如何纠正此前转录中出现过的错误信息,以及如何结合语音模型和文本模型,实现自动纠偏机制。
语音识别模型又被称为 ASR 模型。ASR(Automatic Speech Recognition,自动语音识别)正是将人类的语音转化为文字文本的核心技术。
本次测试使用的模型是开源的 SenseVoice。SenseVoice 由阿里达摩院 / FunAudioLLM 团队推出,性能表现优异。