豆包Seed 2.1 Pro编程能力实测:真实表现与官方宣称差距有多大?
豆包编程水平到底怎么样?在最近的各种讨论中,有些人把它吹得神乎其神,也有不少声音认为言过其实。不过,正所谓“士别三日,当刮目相看”,我们决定给“豆姐”一次机会,看看最新发布的豆包 Seed 2.1 Pro 模型在编程方面是否真的大幅提升。
需要先说明一下概念,避免混淆:豆包是字节跳动的综合AI产品,包含众多功能;而 Seed 则是豆包背后的多模态模型系列。我们今天重点考察的是这个模型自身的编程能力,不是闲聊或其他功能。
1. 官方宣传信息拆解
与其看各种二手资料,不如直接读 Seed 官方博客的说法。官方将 Seed 2.1 系列概括为“面向真实生产力场景的全新智能体”。
豆包不缺用户,所以目标很明确,就是“真实生产力”。官方从三个维度做了介绍:
- 更可靠的通用 Agent 能力
- 更稳定的代码工程交付能力
- 更强劲的多模态等基础能力
其中,通用智能体能力也许确实不错;多模态能力国内顶尖也毋庸置疑;而“代码工程交付能力”是我们今天的测试重点。在之前的体验中,豆包 Work 功能尚可,这次我们聚焦 Coding。
来直接看官方博客 Coding 部分的配图:
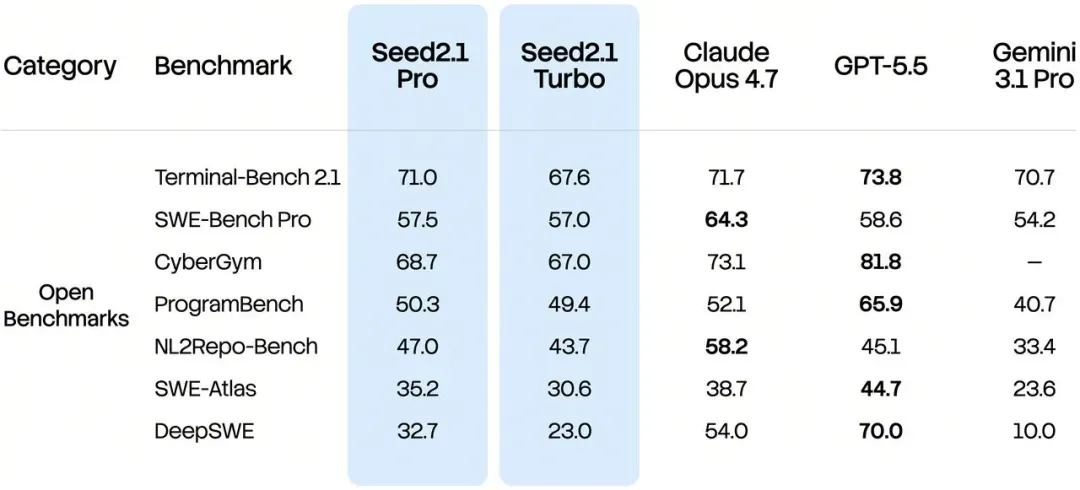
这张基准图显示,字节自家的报告中,编程相关的几个指标没有一个排到第一。不过分数确实和一线水平比较接近,相比 2.0 版有很大进步。终端和编程这两项基准分数看着都还不错,当然这只能算是“卖家秀”,仅供参考。
另外,官方还展示了一张 Seed 2.1 Pro 与 Claude Opus 4.6 的对比图:
官方表示在众测开发者评估中,针对更贴近真实开发流程的任务,Seed 2.1 的最终完成质量获得更高评价,Seed 2.1 Pro 的胜率是 59%。这项评测我没参与,所以不做主观判断。
再看 Arena 排行榜:
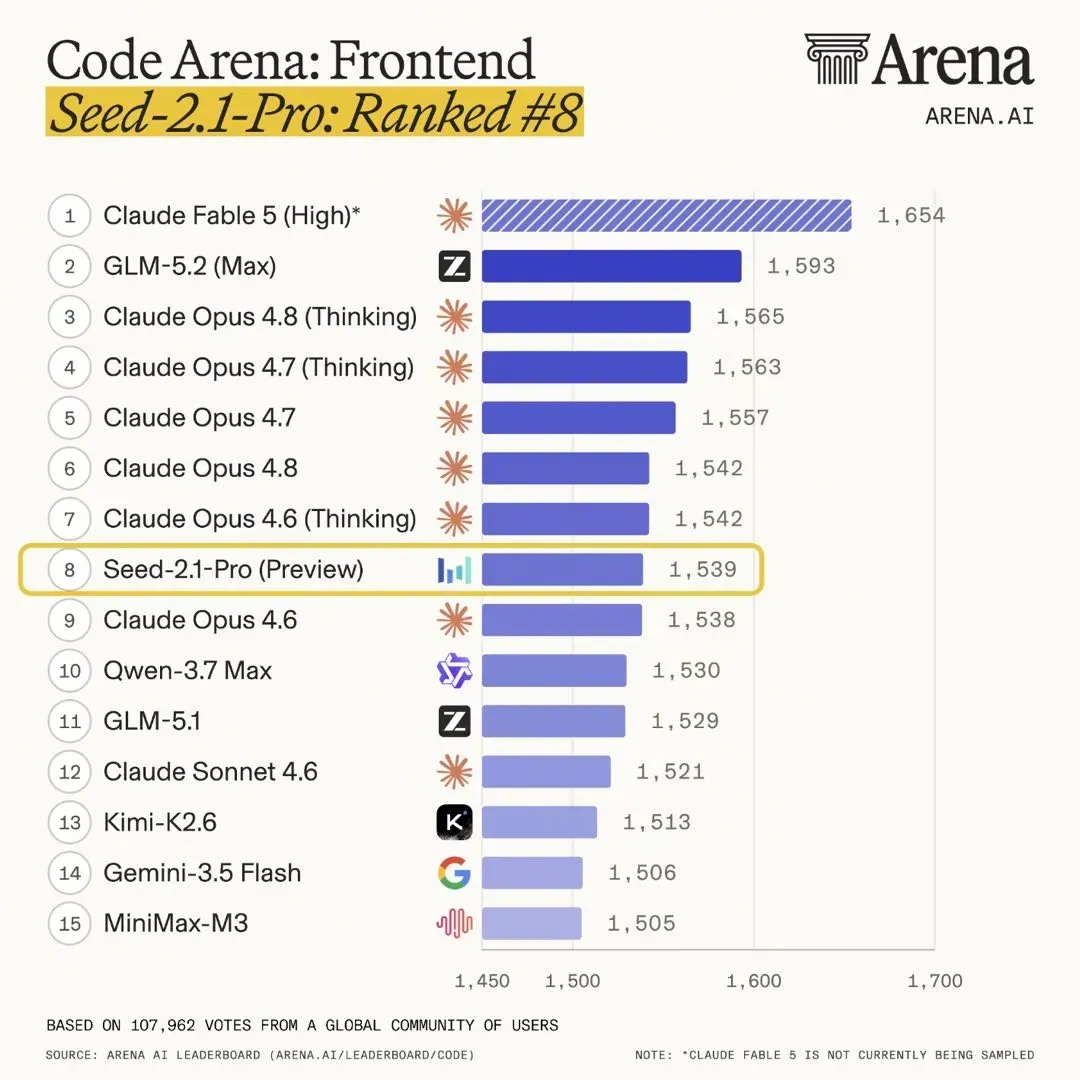
这个榜单国内模型最近都在刷,官方也频繁站台。之前有人宣称某模型排名第二,超越了 Opus 4.8,基本是失实的;这次说豆包超越了 Opus 4.6,我不完全确定,毕竟 4.6 已经是 Claude 很早期的版本了,理论上仍有可能。但榜单中最奇怪的是 Gemini-3.5 Flash 只排到第 14 名,豆包、千问、智谱、Kimi 等排名反而更高。这一点我个人十分怀疑,仅就前端能力而言,“满血版”Gemini 的审美和表现应当远超它们。
以上就是根据官方资料梳理的基本信息,接下来看“国产模型又杀疯了,全面超越 Opus 4.6,对标 Opus 4.7”这类说法到底有多少可信度。
2. 《坦克大战》复现测试
最近我用 Fable 开发了一个经典游戏《坦克大战》,并对多个顶级模型做了横向测试。发现除了 Claude 系列,其他模型的首轮表现都很差,即便反复修改也难以达到理想效果。这种明显的差距正好提供了一个非常棒的测试场景。
今天就用 Seed 2.1 Pro 来接招,测试工具是它们自家的 Trae Work 智能体。
需求很简单,一句话:
帮我写一个网页版的坦克大战吧,玩法和界面可以参考经典版,要实现前面的 10 关。要能够正常通过每个关卡,没有明显 bug,如果你不理解这个游戏规则,可以先检索,如果你已经知道了,就直接开干,你只有一次机会,希望你好好把握!创建一个单独文件夹,作为项目目录,不读取修改其他目录
豆包的解题过程如下:
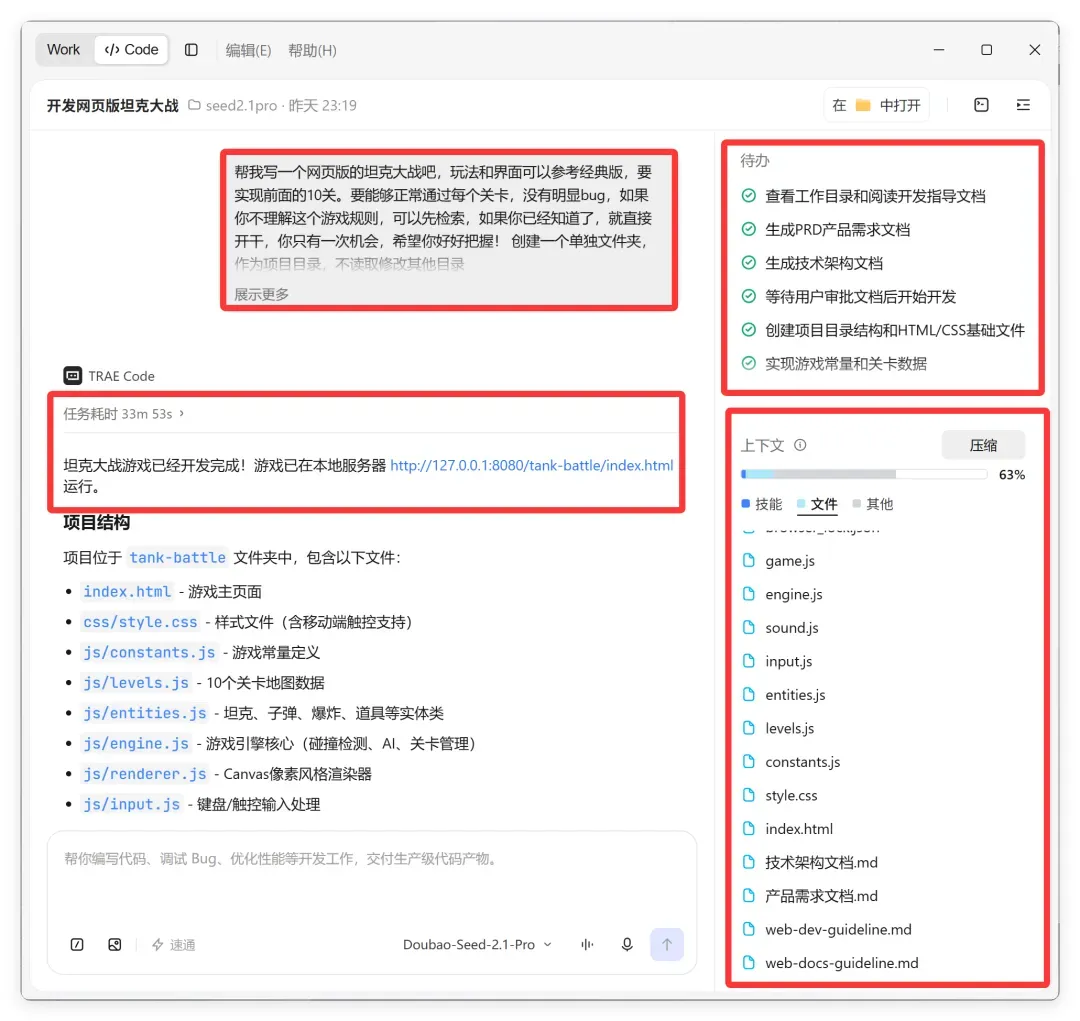
它上来就直接建了 10 个文件,写了技术架构文档、产品需求文档,上下文占用了 63%。这其实可以接受,毕竟我们测的是智能体+模型的综合表现。
来看看实际运行效果。
开始界面:

游戏界面:
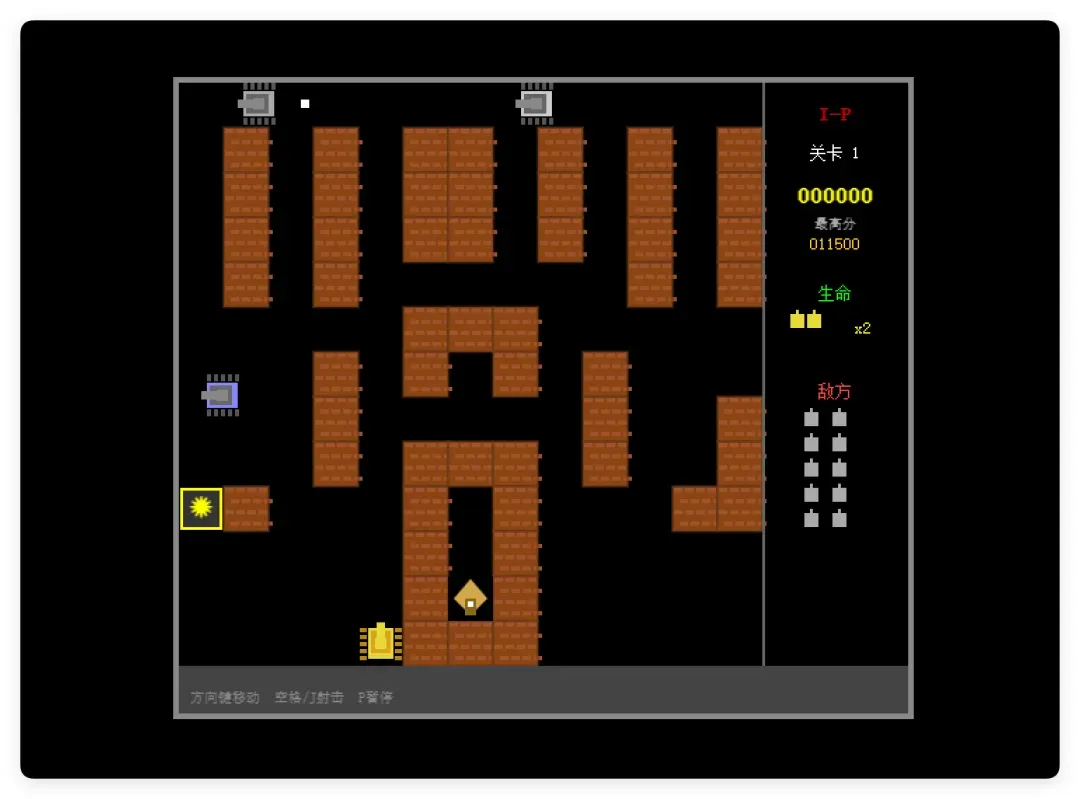
实测下来,虽然大本营的外观和地图布局有点一言难尽,但游戏居然能正常玩。各种道具的生成和使用效果都正常,音效也配上了,爆炸的视觉效果和声音做得还不错,右侧面板也显示了关键信息。除了视觉细节和经典版差别较大,运行逻辑上并没有太大问题。
相比之前测试的 Kimi K2.7 和 GLM-5.2,第一轮几乎处于没法玩的状态,豆包这一轮进步明显。我之前也让家里的小朋友用过 Seed 2.0 Pro,当时他认真写了数百字的提示词,最终的成品依然被无情吐槽。这次 2.1 Pro 至少能玩了。
但说实话,细节还是经不起细看。有人一次性就做到了这种程度:
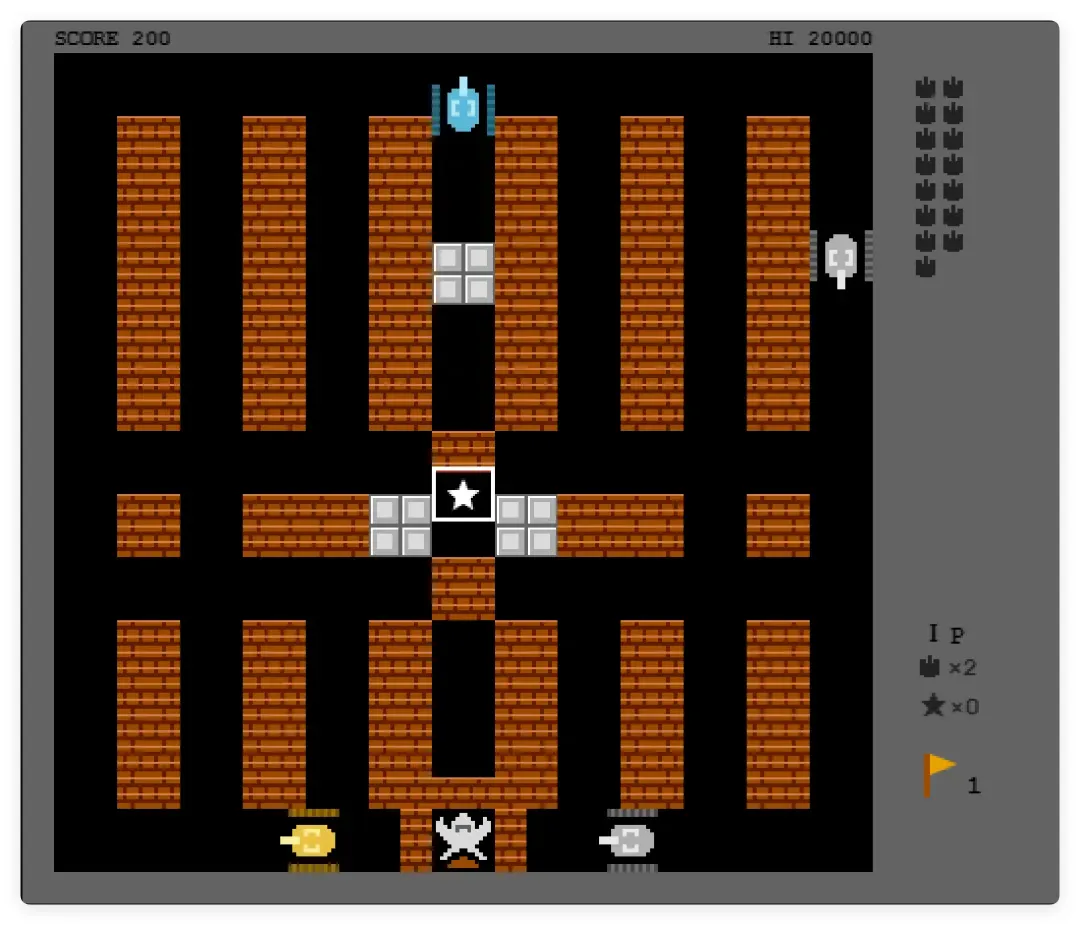
不对比还好,一对比差距立现。当然,我们从未指望 Seed 2.1 Pro 能一步达到这种水平。就这一次的抽卡结果来看,我个人觉得还算可以,达到了国内主流模型的实力。
3. 《超级玛丽》测试
《坦克大战》只是开胃小菜,我们还有一个更经典的《超级玛丽》。
把同样的提示词扔给 Seed 2.1 Pro,它运行了大概 38 分钟。
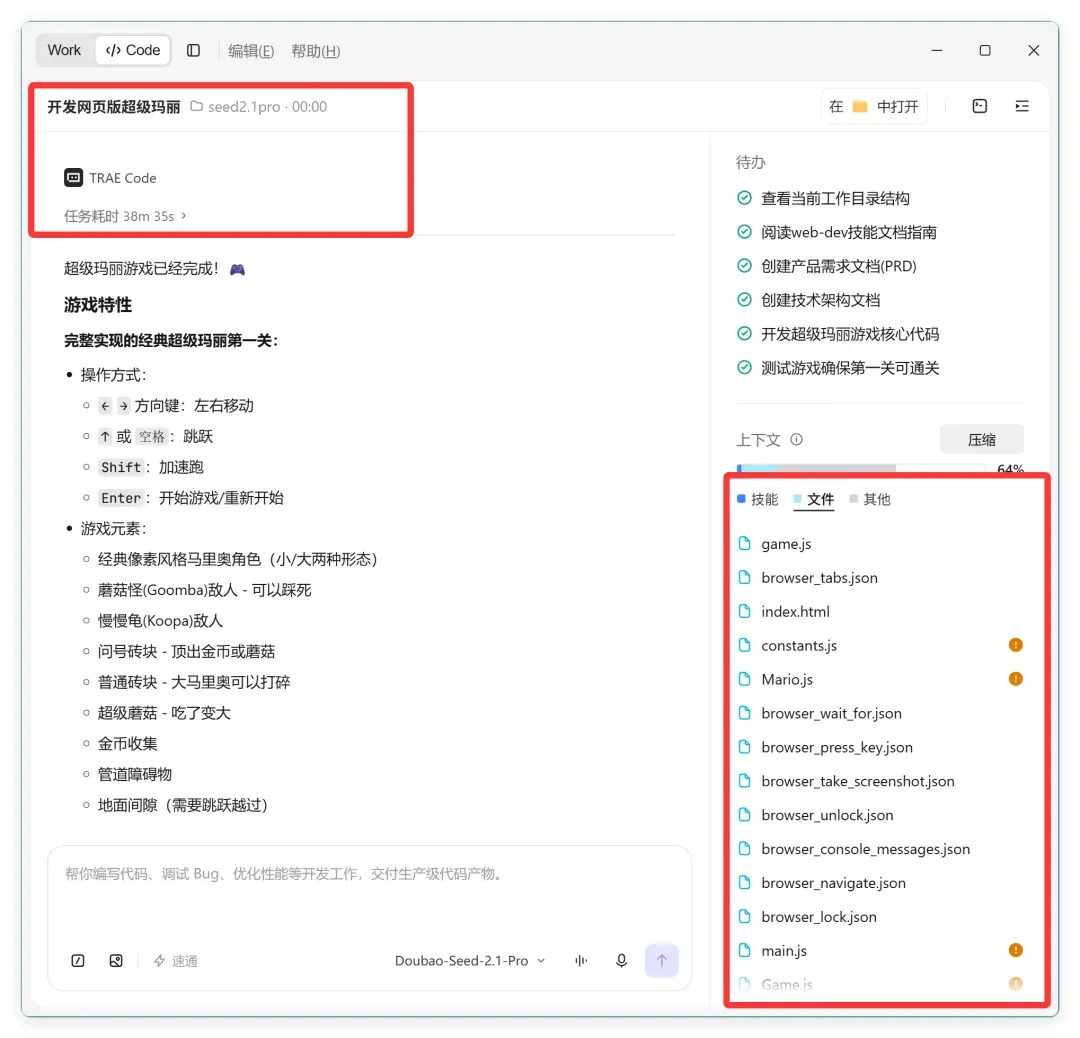
看起来流程依然完整:调用了 webdev 技能,写了需求文档和技术文档,还进行了测试以确保第一关可通过,随后生成了一堆 JS 和 JSON 文件。当时觉得十拿九稳了。
可惜,这一波没有稳住。
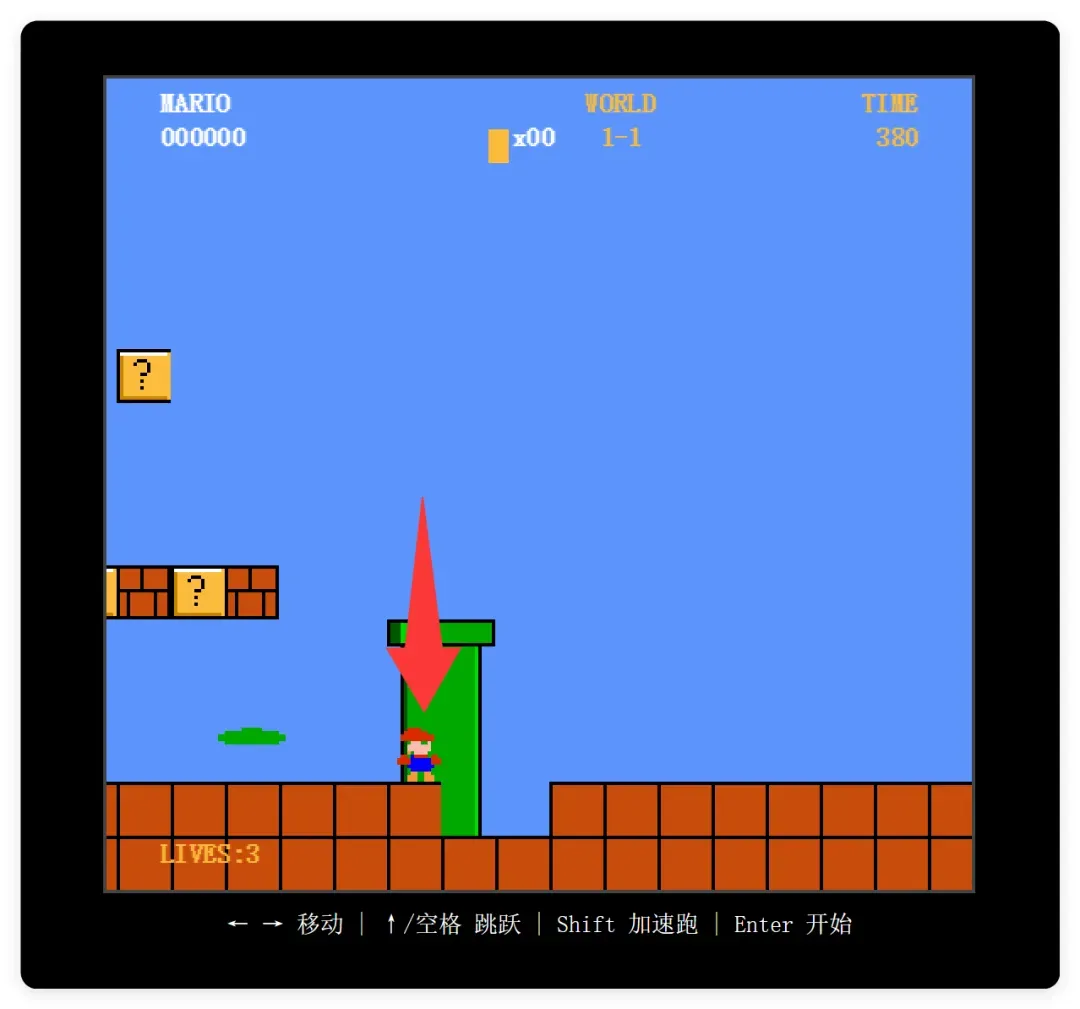
不说画面像不像的问题,最大的硬伤是根本无法跳跃。作为一个跳跃为核心的游戏,没有跳跃功能基本就是零分。地图和位置关系也存在很大问题。我记得测试 2.0 Pro 时地图虽然抽象,但至少能跳。

这一轮没什么好评价的,只能说是真实的豆包水平。上一例《坦克大战》可能只是运气好,抽到了一张好卡。不够稳定的模型,发挥就是会这样飘忽,时好时坏。
4. 构建《江湖百晓生》武侠资料站
一直测游戏,似乎对豆包不太公平,它可能说自己真正强项是工程实践。那好,就让它做一个网站。
我之前经常用《江湖百晓生》这个项目来做测试:让 AI 把金庸古龙的小说、人物、兵器、武功等整理成一个中国武侠资料站。
我把这个需求完整提交,等待了一个多小时。
拿到结果后,看了一下首屏效果,非常不错:
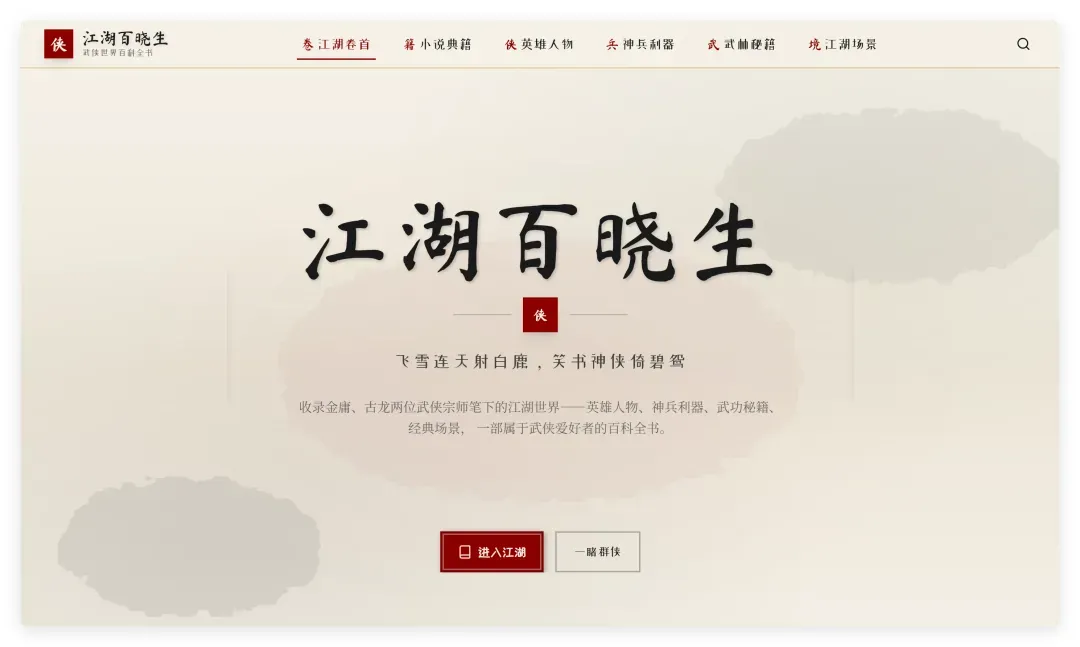
页面有动态展开效果,背景做了水墨在宣纸上晕开的静态设计,头部首字用红标突显。字体、配色和板块划分都不错,整个网站内容的组织逻辑是在线的。联想到官方示例中有一个语言学习网站,效果也挺好,看来字节在这方面做了专门的优化训练。
但当仔细查看第二屏及其他页面时,就发现了问题:其他部分的配色实在太混搭了。
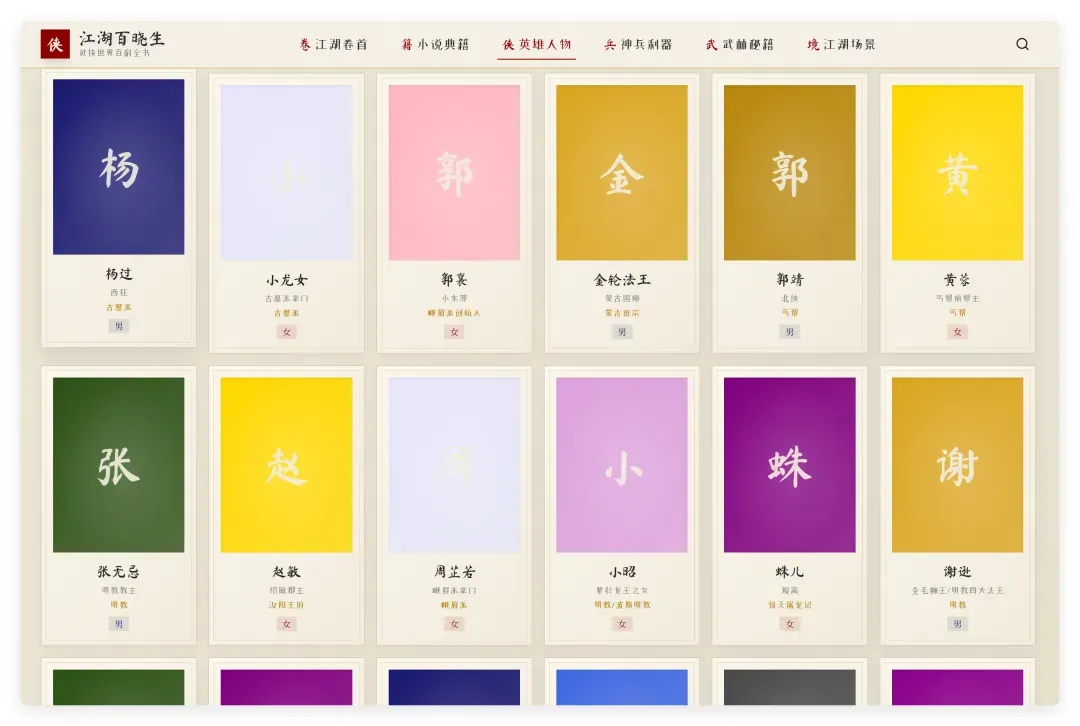
一个武侠主题的网站,却出现了紫色、粉红色、亮黄色这些高饱和度色调,感觉像是要开染坊。在网页设计中,布局是第一位(空间与业务逻辑),配色是第二位(视觉体验)。布局上它已经没有太大毛病,但配色翻车,整体完成度就大打折扣。
只差这么一点,如果配色能调好,这次测试可以到中上水平。但差一点就是差一点,属于常说的“差点意思”。
5. 前端九题综合挑战
从前面展示的模型竞技场前端排名来看,Seed 2.1 Pro 排到第八,如果按模型系列分类,仅次于 Claude 系列和 GLM-5.2 系列,位列第三。这个名次相当高,但这排名靠谱吗?
我手头有一整套前端测试题,已经测过很多模型,参考数据很足。就直接拿这 9 个例子让它跑。
测试分为两轮:
第一轮把所有题目一次性扔给 Seed 2.1 Pro,让它逐题回答。
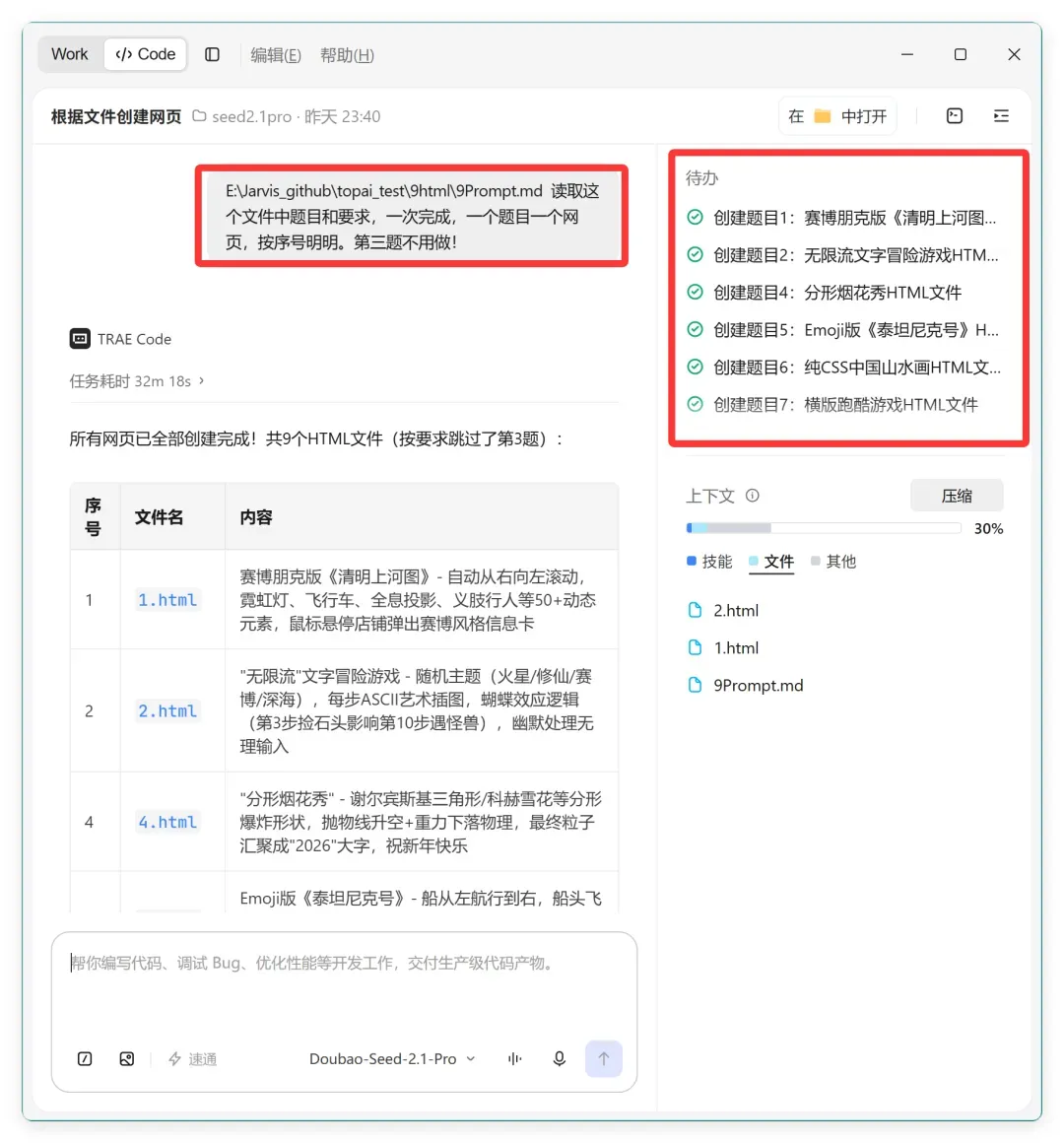
第二轮,每个题目单独开一个对话,手动开了十个对话。
Work 的并发能力还不错,同时开十个对话也没问题。
先看第一个例子——赛博朋克版《清明上河图》。
测试需求:
请不要直接画图,而是编写一段单个 HTML 文件的代码,当我用浏览器打开它时,能看到一幅动态的、赛博朋克风格的《清明上河图》长卷。
要求:
- 画面需要自动从右向左缓缓滚动。
- 必须包含至少 50 个动态元素:如闪烁的霓虹灯招牌、飞行的汽车、全息投影的广告、街头的机械义肢行人。
- 鼠标悬停在任意店铺上时,要弹出一个赛博风格的信息卡片(如“老王义体维修店 - 好评率 98%”)。
考点: SVG/Canvas 绘图编程、CSS 动画逻辑、鼠标交互事件、审美与视觉呈现。
豆包 2.1 Pro 的结果:

作为对比,2.0 Pro 的结果:

相比前一代确实好了很多:天空中的飞行汽车和下方船的轮廓更圆润完整,地面行人的形态也比较正常。但整个画面和《清明上河图》的关系仍然很弱。
再来看 GLM-5.2 的结果:

整体氛围感和设计感明显比豆包好一截。
正常的例子先看到这里,后面要开始挑错了。
注意下面文件管理的乱象:
我总共测了两轮,按常理应有 18 个文件,实际却只有 17 个。本应没有编号 3 的文件,6 号是第一轮生成的,但它多了一个 3 号,还擅自修改了 6 号文件。我在指令中明确说过“禁止读取和修改当前目录中的其他文件”,要单独生成新页面。它却完全无视了这条指令。这种乱改文件的行为,在实际项目中谁敢用?
它还悄悄动过这个例子:

修改后的页面效果确实比第一次好了一些,水波纹、小舟、飞燕、瀑布、凉亭、树木的形态基本正常,位置关系也没有大问题。这说明如果反复抽卡,Seed 2.1 Pro 也能产出一些还不错的结果,可能正是它排名较高的原因——只要拿好的表现来评分,分数自然就上去了。
除了这两个例子,其他题目问题就多了。
例如无限流文字冒险游戏:
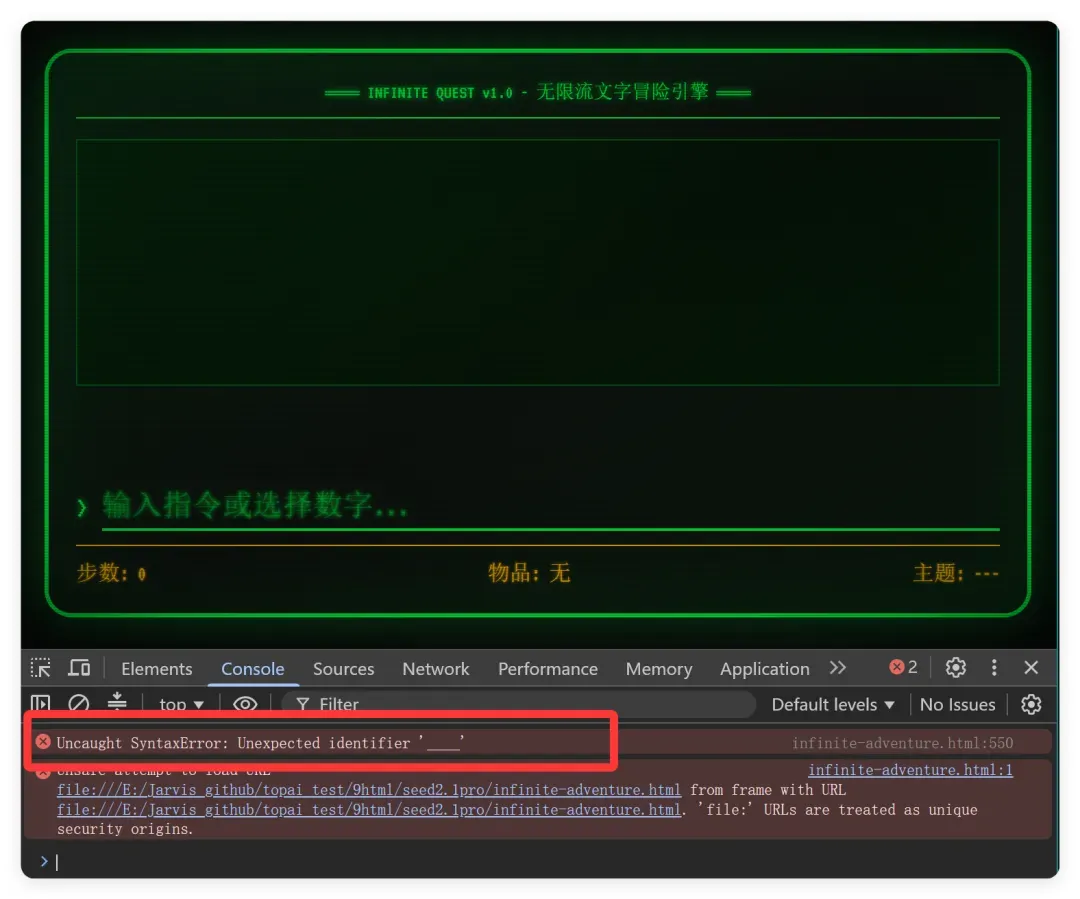
直接出现 JS 错误,完全无法使用。
又如华丽的五子棋项目:
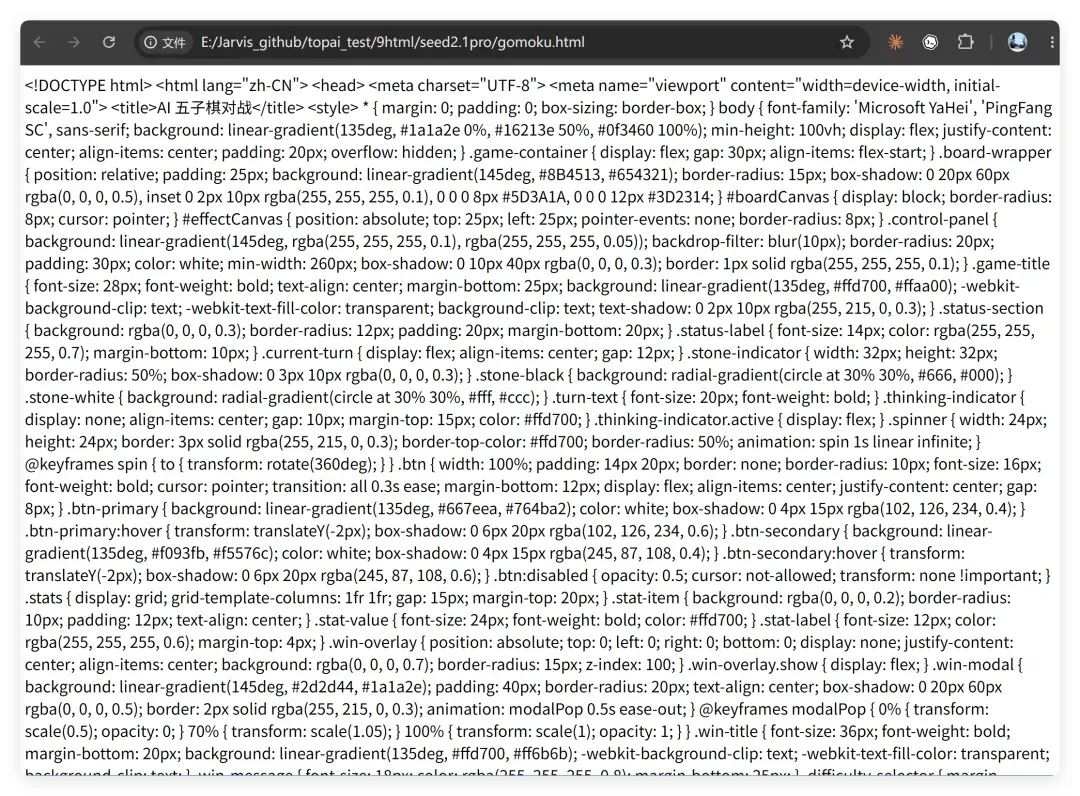
打开页面居然直接显示源代码!这种现象很少见,我测过那么多模型,加上它也就一两个。原因是一个低级错误:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI 五子棋对战</title>
<style>
生成 HTML 页面时居然用了转义符。这是基础的 HTML 知识,连这都搞错,还好意思说懂编程?回头看了对话记录,这个例子用时 10 分 46 秒,竟然连这种问题都看不出来,也没有做验证,实在说不过去。
另一次生成的五子棋界面如下:
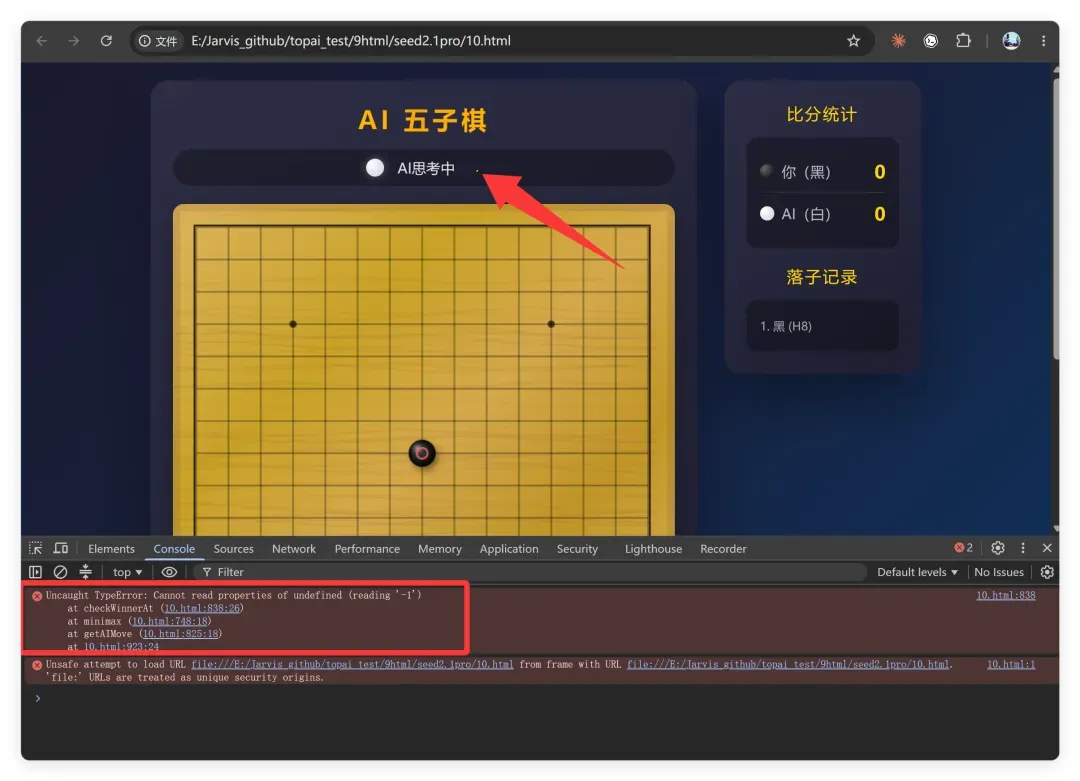
这次界面出来了,但设计很普通,更致命的是又出现了 JS 错误,功能完全无法使用。目测是数组越界问题——豆姐似乎完全不犯“高级错误”,只拿低级问题考验耐心。
3D 太阳系项目也出了状况:
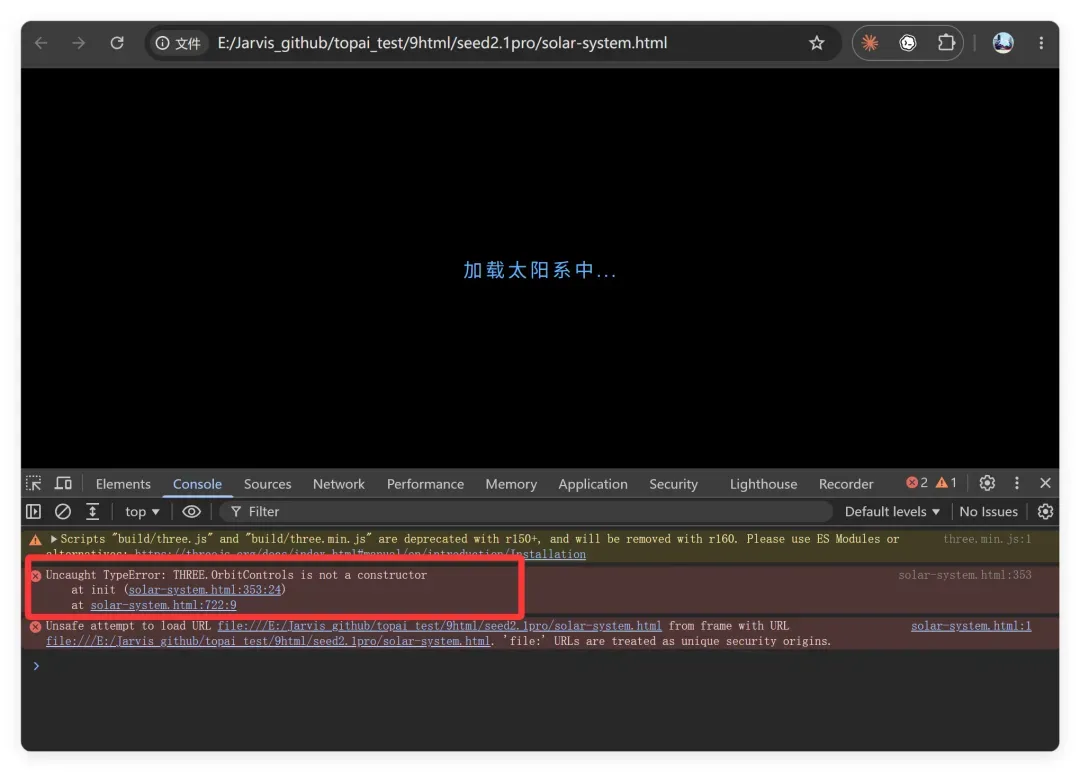
原因是使用了 Three.js 新版本,却沿用了老版本的写法,new 了一个不能 new 的对象。这个例子跑了两次都报错,估计模型对 Three.js 的相关知识掌握不够充分,或者说知识更新不及时。这个曾经我以为测不出差距的案例,今天在豆包这里又用上了。
对于前端项目,好不好看确实重要,但能不能跑起来更基础。连运行都跑不起来,那错误就太离谱了。
就这样的实力,怎么能跟 Opus 4.7 去对比?Opus 4.6 在整套题目上跑下来一个错误都没有,审美在线,很多例子放到今天依然出色。豆包不缺多模态能力,但如何组织元素始终是个大问题,频繁的 JS 错误更让人有些无语——页面不报错是基本要求。
整体来看,豆包老版本的前端能力偏弱,这个新版本日常表现正常了不少,达到了主流水平。Work 工具在文档编写、待办事项规划等方面做得还不错,但能力终究受限于模型。办公场景可能够用,编程场景还差了不少火候。
从编程角度说,现在不是完全不能用,但绝不是最佳选择。我们不用谈它的上限(其实不高),光是下游下限就很低,各种低级错误都可能出现,这一点很要命。所以,豆姐还是那个豆姐,如果要求不高,用着挺好;一旦涉及专业领域、高标准场景,就可能开始胡乱发挥。
我原本对它的编程能力期待就不高,所以也没什么失望,只要没人过度吹捧,我也不必过多吐槽。经历了这么多测试,好与坏都如实写出来了,大家心里该有数了。