豆包2.0原生多模态实测:全面升级硬刚GPT-5与Gemini 3
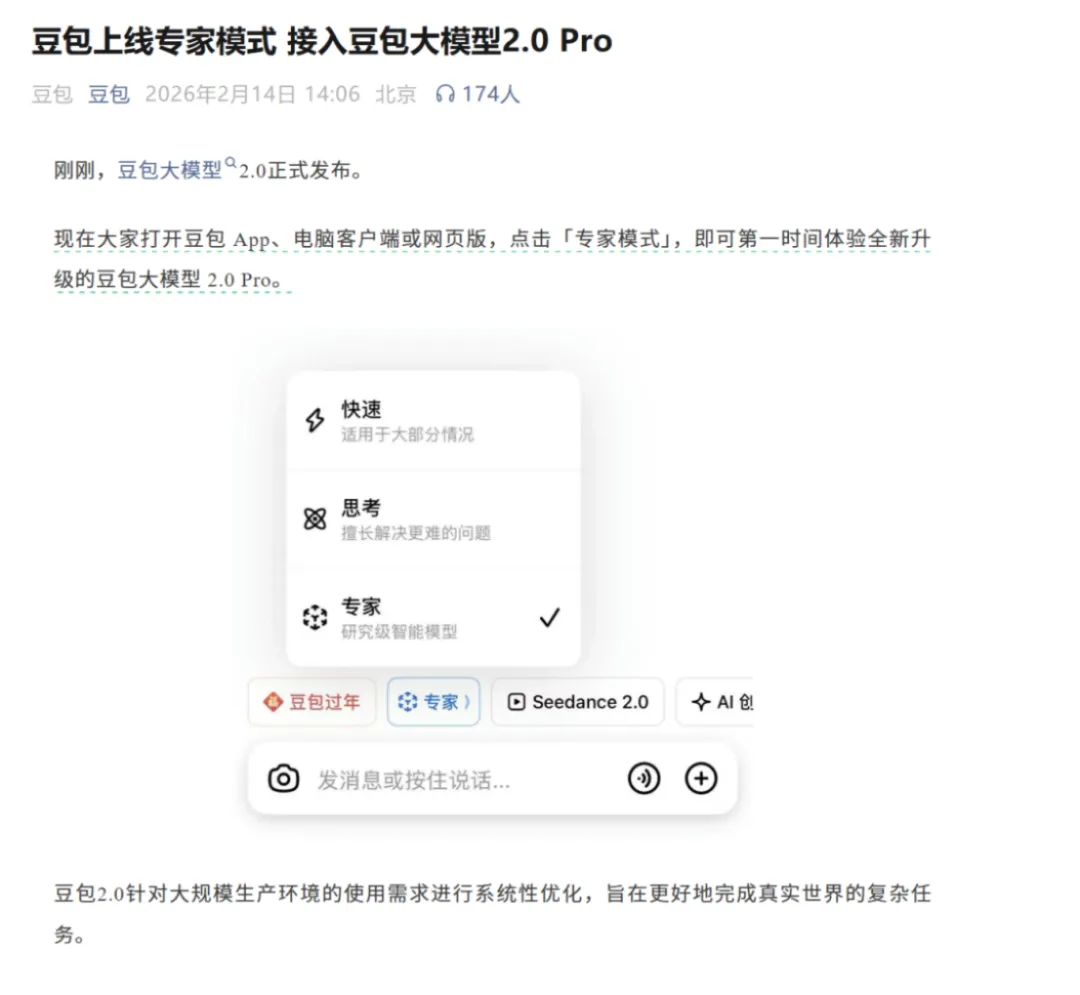
2026年2月,字节跳动几乎天天都在搞事情。当大家还沉浸在Seedance 2.0“一分钟生成好莱坞大片”的震撼里,字节再次放出大招,对豆包大模型的底座进行升级,上线专家模式并正式接入豆包大模型Seed 2.0,一举迈入2.0时代。
这次升级可不简单,豆包直接从“对话模型”蜕变成了一个“原生多模态通用模型”。简单来说,它不再只接收文字、输出文字,而是能处理图像、视频、文档等复杂输入,并在此基础上进行推理和持续执行任务。
那么,这次升级具体能带来哪些便利?接下来我们通过实测来一一揭晓。
一、豆包2.0模型升级六大维度
1. 模型矩阵
推出Pro、Lite、Mini、Code四大版本,覆盖高端推理、日常办公、边缘终端和专业编程全场景。
其中,Pro和Lite版本已在豆包App与网页版上线,Pro对应专家模式,Lite对应思考模式和快速模式。
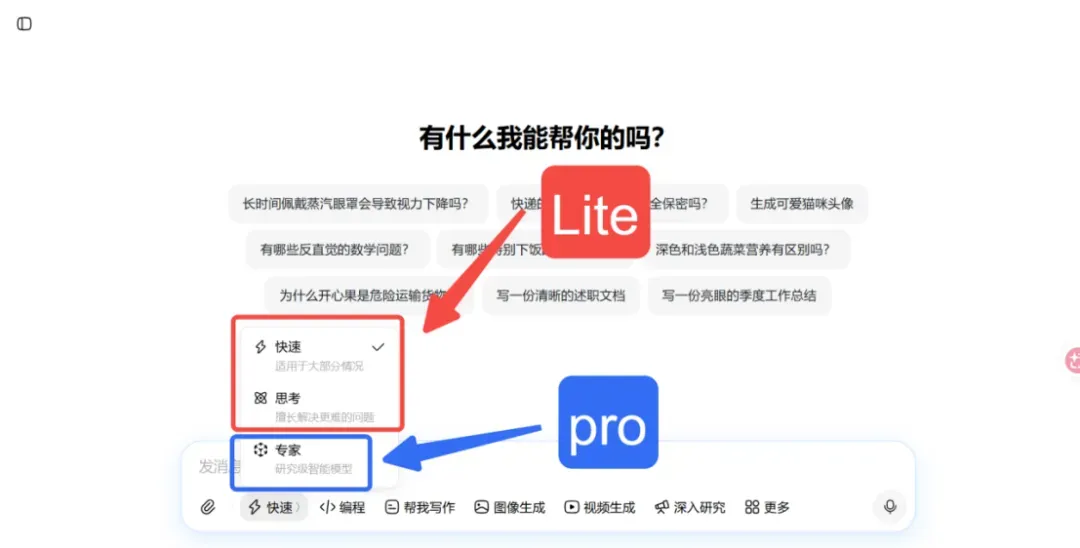
Code版仅在TRAE中使用,Mini版则主要面向企业级低时延、高并发场景。
2. 推理效率与成本
推理速度提升43%,单token计算成本降低70%;Pro版支持每秒10万级并发请求,响应延迟压缩至80毫秒以内。
3. 多模态感知能力
视觉理解、空间关系解析、运动理解均达到国际领先水准。
4. 长上下文与知识深度
Pro版支持最高128K token上下文输入;在各大专业知识评测中得分超越同级竞品,位列第一。
5. Agent能力
复杂商业任务成功率达91%,工具调用准确率提升37%;原生支持多技能调用、多轮指令持续遵循以及稳定结构化输出。
6. 代码与编程能力
Code版深度集成TRAE,强化代码生成、智能补全、漏洞调试和项目重构能力。
这次升级将豆包“全能选手”的特质展现得淋漓尽致。口说无凭,接下来就通过五项实测来验证它的真实实力。
二、豆包2.0五大场景沉浸式实测
实测1:检索能力
对于经常需要查找资料的用户而言,检索准确性异常重要,用AI搜索最怕它胡编乱造。豆包2.0能否带来更可靠的体验?例如我们提问:“AI政策调整时间线”。
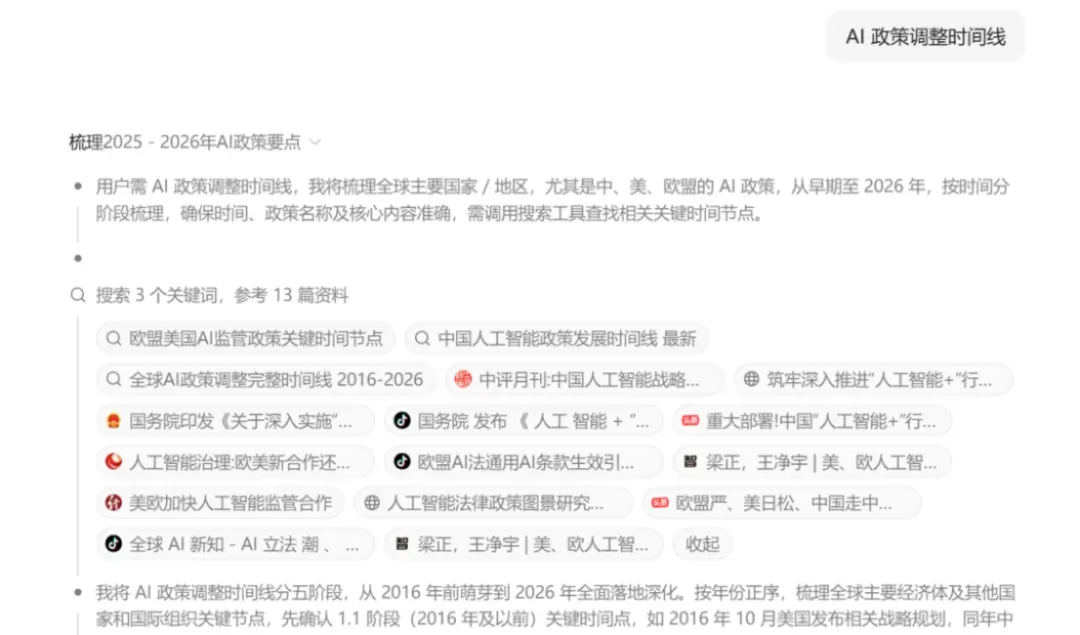
从初步结果就能看到,豆包搜索的资料基本源自权威网站,可信度颇高。
实测2:视觉识别
大家或许会遇到这些情况:领导递来潦草的手写稿要求整理成电子文档,或者需要从截图、扫描件中提取文字。以前我们只能先OCR识别,再清洗结构,文字对不上还得手动校对,费时费力。豆包2.0的视觉识别能力却非常扎实,我把过去领导留下的手写稿发给它,让它提取文字。原稿简直让人怀疑人生,仿佛不认识他写的字。

但现在,豆包只用几秒钟便精准提取出文字。

这无疑是打工人的福音,让人直呼“真香”。
实测3:数据处理
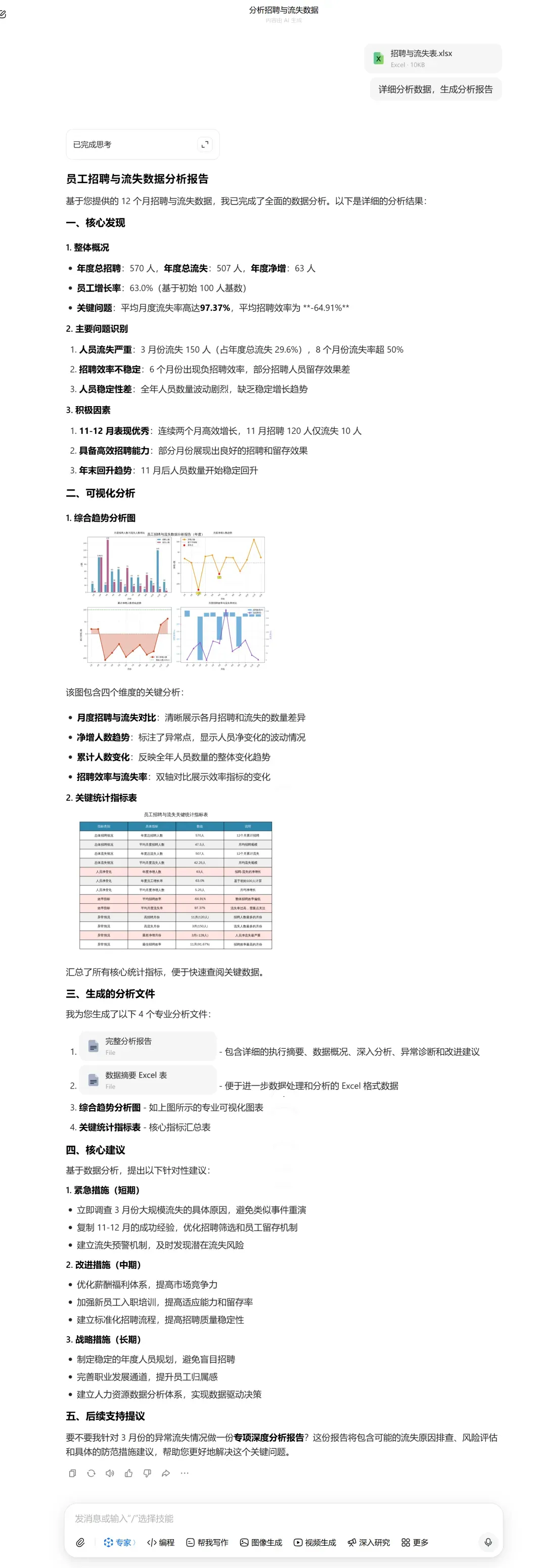
在数据分析这块,豆包2.0比之前进步显著。例如,我们上传一张人员招聘与流失表,并输入简单指令:“详细分析数据,生成分析报告”。
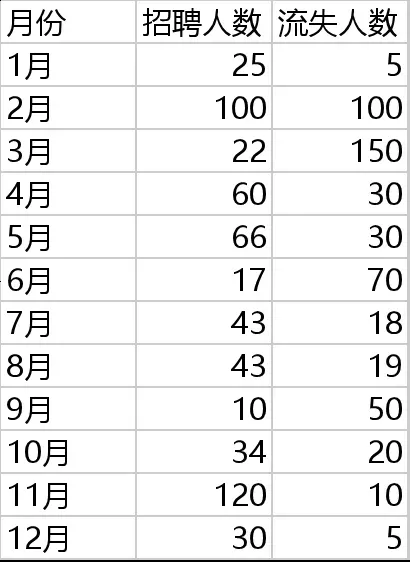
豆包迅速输出了一份详细完整的报告,即便只凭少量数据,也能分析得如此透彻,令人惊喜。
上下滑动查看更多
实测4:规划能力
工作生活中,许多人需要策划活动或项目,豆包2.0也强化了这一能力。比如,我们计划在3月举办一场AI线下沙龙,让豆包生成一份规划。
上下滑动查看更多

它产出的规划相当完善,几乎涵盖了我们想要的各个要点。
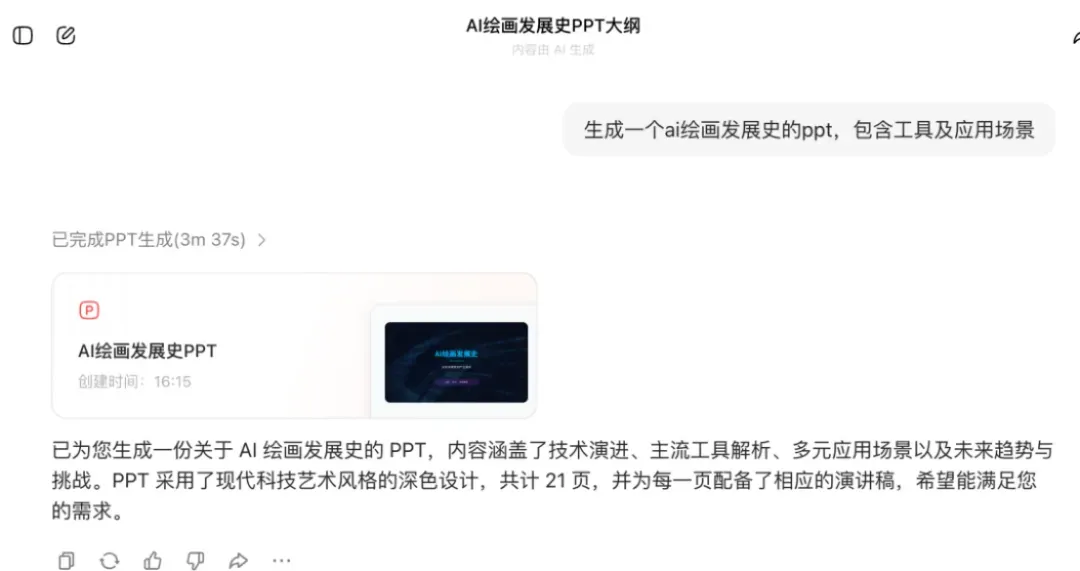
实测5:生成PPT
不少小伙伴写作业、上班时都需要做PPT,常常为此头疼。现在豆包提供了PPT生成功能,目前尚处于免费阶段。

只需选择PPT模板,就能自动生成。
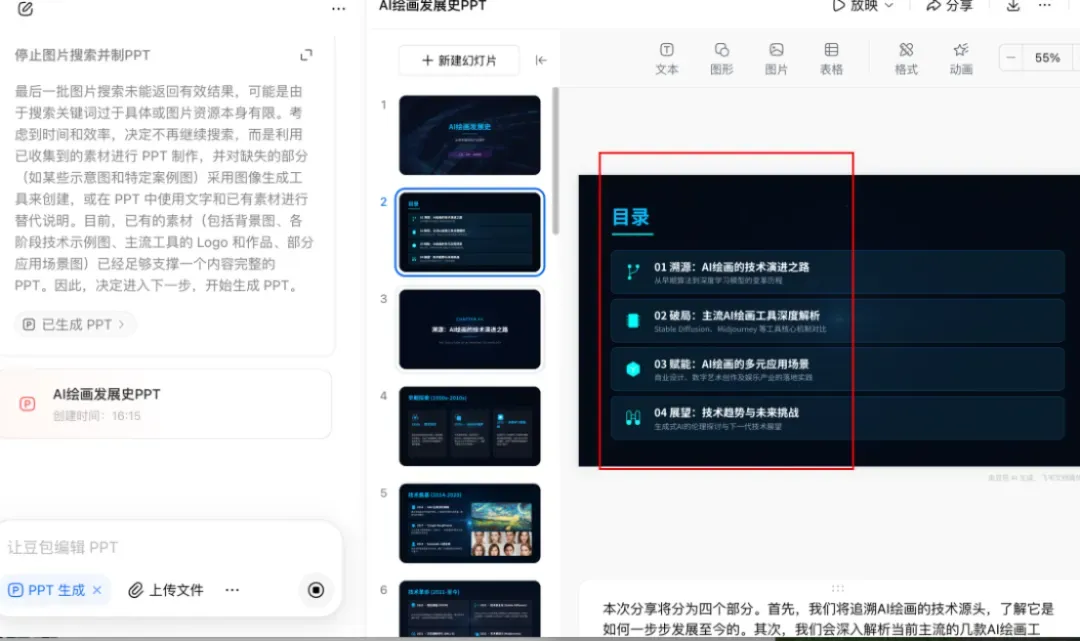
如果对风格有更高要求,还可以进行自定义设定。
整体体验下来,豆包2.0给人的感觉用两个字概括就是——全面。文本推理、多模态理解和Agent能力全部拉满,这不仅是参数的胜利,更是生产力边界的再一次拓宽。工具再强,终究只是载体,主动使用才能真正改变工作与生活。
好了,今天就聊到这儿。如果你也体验了豆包2.0,欢迎在评论区聊聊你的感受,或者还希望我们测试哪些场景,也可以留言告诉我们。