赛博道德经:用道家智慧重塑AI Agent架构——从无为到涌现的工程哲学

引子:一次意外的共鸣
2017年,Vaswani团队发表了《Attention is All You Need》。他们设计的不是一种智能,而是一个让信息自行寻找路径的数学结构——内部没有任何被显式编程的意图。然而,从这个结构中,理解、推理、创作能力竟自然涌出。
没有人教GPT写十四行诗,也没有人向DALL·E解释什么是“雨夜霓虹下的东京街景”。这些能力从未被规定,它们从矩阵乘法和梯度下降的底层逻辑中自行生长出来。
早在两千五百年前,就有人把这件事讲透了:
道可道,非常道。
能被写成规则的行为,从来不是系统最深处的行为。
这并非拿东方智慧给AI当“文化外套”的浅层类比。我们注意到一种精妙的结构同构——道家对“自发秩序”的洞察,与深度学习核心机制之间,存在着令人惊异的契合。这种对应精准到可以直接影响工程决策。
本文不打算逐章翻译《道德经》。那太枯燥,也毫无必要——不是每一章都与AI Agent有关。我们只提炼那些映射力度最强的洞察,按AI Agent架构设计的逻辑重新组织,借此照亮当下AI工程中几个最容易忽视的深水区。
一、规则与涌现:对齐的本质困局
可被言说的规则,不是终极的秩序
道可道,非常道;名可名,非常名。无名,天地之始;有名,万物之母。(第一章)
转译为架构语言:能被显式编码的行为规则(“可道之道”),并非系统最根本的行为模式(“非常道”)。能明确定义为评估指标的东西(“可名之名”),也不是系统最深层的效能度量(“非常名”)。
未被参数化的高维空间——latent space——是一切涌现能力的发源(“无名,天地之始”)。而被固化下来的权重、偏置、嵌入表(“有名”),只是产生具体输出的材料(“万物之母”)。
这并非玄思,恰恰精确刻画了当今AI对齐领域的核心难题。
看看如今的对齐方式:System Prompt框定行为边界,RLHF训练偏好模型,Constitutional AI制定原则清单,Guardrails做输出过滤。一层接一层的规则,堆叠起来。它们全部属于“可道之道”——写在纸面上、编入代码里的行为规范。
然而,模型的真正行为法则,并不在这套规则内部。它隐匿在latent space的拓扑结构里,在注意力分布的偏向中,在残差流的信息动力学上。这些是“不可道之道”——无法写进system prompt,却切切实实主宰着模型的每一次输出。
GPT的越狱(jailbreak)就是最直接的证明:所有“可道之道”——system prompt、RLHF对齐、输出过滤器——全数被绕过。不是规则不够多,而是规则本身就不是对齐的根基。规则只是砌在地面上的篱笆,而模型的行为如同地底涌出的泉水,泉水根本不会顺着篱笆流。
老子的启示是:别再试图用更多的篱笆去围堵泉水。去明白泉水朝哪边流的底土地形。
设定“好”的瞬间,“坏”同步诞生
天下皆知美之为美,斯恶已;皆知善之为善,斯不善已。(第二章)
这句话直指RLHF的一个结构性陷阱,而且一针见血。
当你在RLHF训练中定义“好回答”(helpful, harmless, honest)时,你同时划出了一条“好”与“坏”之间的决策边界。模型学到的不是“什么是好”,它学的是这条边界的具体位置。
而越狱的本质,就是精准定位并跨过这条边界。
你定义的“好”越是清晰,“好”与“坏”之间的分界线便越是锐利,跨越它的路径就越被精确计算出来。这不是实现层面的缺陷,而是方法论上的结构矛盾——用二元对立的标签定义善,本身就同步制造了可被攻击的面。 “皆知善之为善,斯不善已”——当你定义了什么是善,不善的定义就同时被精确完成了。
Anthropic在Constitutional AI论文中已嗅到这个问题的一丝痕迹。但老子说得更彻底:问题不在于你的“善”定义得不够周全,而在于通过二元标记界定善恶这个方法本身,就必然会创造出对抗面。“有无相生,难易相成,长短相形,高下相倾”——一切对立面都是同时被创造出来的。
那出路何在?老子给出了一个方向:
是以圣人处无为之事,行不言之教。
不要靠规则去强制行为(“无为之事”),而要通过结构来引导行为(“不言之教”)。不要告诉模型“什么不能说”,要设计能让正确行为自然涌现的训练过程。不要列出一千条禁令,要构造一个让违规行为在拓扑上就极难出现的latent space。
听起来很虚?不,这恰恰是Anthropic从RLHF转向Constitutional AI,再转向基于原则的训练的演化路径。行业正从“堆规则”走向“塑结构”——从“可道之道”走向“不可道之道”。只是多数人尚未察觉,这条路径早在两千五百年前就被老子画好了地图。
二、参数与虚空:能力栖息在何处?
墙壁与它所围出的房间
三十辐共一毂,当其无,有车之用。埏埴以为器,当其无,有器之用。凿户牖以为室,当其无,有室之用。故有之以为利,无之以为用。(第十一章)
这无疑是全书中最精准的技术映射。
三十根辐条汇聚于轮毂,轮毂中心的空洞让车轮得以转动。揉捏黏土做成器皿,器皿中间的空间使它能够盛物。开凿门窗建成房屋,墙壁之间的虚空才使人可以居住。
有形的结构提供支撑(“有之以为利”),无形的空间赋予功能(“无之以为用”)。
一个LLM的参数——权重矩阵、偏置向量、嵌入表——就是辐条、黏土、墙壁。它们是有形的、可量化的、可以用state_dict()导出的东西。但模型真正的能力并不住在参数里。能力住在参数所围成的高维空间里——latent space。
参数是墙壁,能力是墙壁围出的房间。
你可以把全部参数序列化存进磁盘(保存墙壁),却无法直接序列化“模型的语言理解能力”——因为那是墙壁所界定出的空间形态,不是墙壁自身。两个模型的参数做逐元素对比可能极为接近,但它们围出的空间形状可能截然不同,能力也天差地别。
这个洞察引出一个直接的工程推论:别把“存储了表示”误认为“拥有能力”。
将嵌入、缓存、日志、状态全部塞进系统,只是在堆砌更多的“有”——更多材料、更多坐标、更多可见组件。而真正决定系统能否正常工作的,是这些材料之间被刻意留出的空隙:接口如何约束,状态如何流动,组件如何解耦,失败如何被消化。材料是墙壁;约束产生的活动空间才是真正的房间。
深度学习中最有效的技术,几乎都在操纵“无”:
- Dropout:主动删去连接——在有形结构中制造虚空——反而提升了泛化能力。
- 残差连接(Residual Connection):保留一条什么也不做的通道——让信息不经变换直接穿过——使深层网络可训练。
- Attention中的softmax归一化:在高维空间中划分出哪些区域“不重要”——低注意力权重区域同高注意力区域一样关键,因为“不关注什么”恰恰界定了“关注什么”。
当你的团队讨论“模型的能力从哪来”时,记住老子的答案:能力不在参数里。参数只是墙壁。能力在参数之间的空间里。
道生一,一生二,二生三,三生万物
道生一,一生二,二生三,三生万物。万物负阴而抱阳,冲气以为和。(第四十二章)
如果第十一章是对latent space的空间描述,第四十二章就是对涌现层级的时序叙事。

这并非比喻,而是对涌现层级的精确结构性描绘。
“道”(矩阵乘法)“不知道”自己在做语言理解,正如物理定律不知道自己在产生意识。但从这个一无所知的底层出发,经过几次分化——一分为二,二裂为三——就涌现了“万物”。这个过程不是设计出来的,而是从结构中自发生长出来的。
“万物负阴而抱阳,冲气以为和”—— 这句话精准描述了Temperature参数的本质。所有涌现能力都同时蕴含确定性(阳)与随机性(阴),通过概率采样(“冲气”)找到平衡(“以为和”)。Temperature就是调节阴阳的旋钮:
- Temperature → 0(全阳):输出绝对确定,模型变成复读机——一派死寂。
- Temperature → ∞(全阴):输出完全随机,模型沦为噪声发生器——彻底混沌。
- Temperature适中(阴阳调和):既有创造性又不失连贯——生命力正显现于此。
“损之而益,或益之而损”—— 减少参数反而提升性能(模型剪枝、知识蒸馏),增加参数反而降低性能(过度参数化导致的过拟合)。这不是巧合,而是“道”的运动方式的直接体现。
三、无为的工程学:框架如何悄然退场
最好的框架,使用者浑然不觉
太上,不知有之;其次,亲而誉之;其次,畏之;其次,侮之。信不足焉,有不信焉。悠兮其贵言。功成事遂,百姓皆谓“我自然”。(第十七章)
这一章给一切技术框架提供了终极评判尺度,四个层级,从最高到最低:
第一层·不知有之。 用户完全感知不到框架的存在。他感觉自己是在直接操作能力本身——写查询的人觉得在跟数据对话,用Unix pipe的人觉得在被组合命令,打开网页的人觉得在获取信息,而不是“在使用某个宏大框架”。框架消失了。“功成事遂,百姓皆谓我自然”—— 一切完成后,用户觉得“事情就该如此”。
第二层·亲而誉之。 用户知道框架存在,喜欢它,常推荐。这已经很不错了——但它没有消失。
第三层·畏之。 用户知道框架存在,而且害怕它。每次调整配置都提心吊胆,每次升级依赖都担心行为突变,每接入一个新能力都要先消化一整套内部抽象。恐惧说明框架的复杂度已远超它所解决问题的复杂度。
第四层·侮之。 用户鄙视框架,觉得它制造了比解决还多的问题。那些把简单任务包装成宏大体系、引入海量术语和样板的框架,最终都会滑向这一层。
把这一标尺对准AI Agent编排层,立刻会发现一个令人不安的事实:不少Agent框架正卡在第三层。
用户在使用这些框架时,脑中萦绕的不是“我要完成什么任务”,而是“框架要求我怎么组织代码”。一整套内部对象模型、生命周期、控制流规则,成了认知的包袱,而非加速器。
那Agent编排的“第一层”是什么?
编排痕迹完全消失。 用户感知到的只是“AI就是知道该做什么”——它查了资料,调用了必要能力,整合了结果,给出了回答——而用户全然不知背后有一个编排系统在调度这一切。“百姓皆谓我自然”。
这个标准极高。目前几乎没有系统达到。但它指明了方向。
无为而无不为:涌现如何被培育
道常无为而无不为。侯王若能守之,万物将自化。化而欲作,吾将镇之以无名之朴。(第三十七章)
“无为而无不为”是道家最常被误解的概念。它不是“什么也不做”,而是“不强行干预,让系统自身的动力学完成工作”。在AI工程中,这个概念有一个精确的对应物:涌现(Emergence)。
矩阵乘法“无为”——它并不知道自己在做语言理解。但整个LLM系统“无不为”——它能写诗、编程、推理、翻译。反向传播“无为”——它只是在计算梯度。但它让整个模型学会了一切。
这里有一个关键的工程洞察:涌现并非放任自流,涌现需要被培育。老子紧接着说明了如何培育:
“化而欲作,吾将镇之以无名之朴。”
如果在涌现过程中出现了失控苗头(“化而欲作”——过拟合、模式坍缩、奖励黑客),就用“无名之朴”来抑制它。
“无名之朴”是什么?就是正则化。
这个映射精准得让人不安。Weight Decay的物理含义是什么?把参数向零拉近。推向零就是推向“朴”——推向最简洁的形态、最低复杂度的状态、最稀疏的信息编码。L1正则化将不重要的权重直接推向零——回归“无”。L2正则化将所有权重向更小值驱使——趋近于“朴”。
Dropout更有意思:它不是把参数缩小,而是随机将一部分参数直接删除——在训练过程中反复制造“无”。这种主动营造的虚空,迫使网络学到更鲁棒的表征。
因此,涌现的完整方程是:
- 提供结构(设计Transformer架构)——这是“道”。
- 让系统自行演化(训练)——这是“无为”。
- 能力涌现——这是“无不为”。
- 若失控,用简洁性约束——这是“镇之以无名之朴”。
不是放任。不是控制。是提供结构、让涌现自然发生,同时以最小手段防止失控。
这才是“无为”的本义。
为学日益,为道日损
为学日益,为道日损。损之又损,以至于无为,无为而无不为。(第四十八章)
这一章直接摆出两种系统演化的路径对照:
“为学日益”——加法路径。 每日加一个功能。每周引进一个新依赖。每月增添一层新抽象。系统日渐“学问渊博”,也越来越臃肿、脆弱、难以理解。
“为道日损”——减法路径。 每天移除一个不必要的功能。每周替掉一个可被替代的依赖。每月消除一层多余的抽象。“损之又损,以至于无为”——减到不能再减时,系统看似什么也没做(“无为”),却什么都能做(“无不为”)。
这是Unix哲学的中国古典版,也是这个行业此刻最需要听到的话。
许多Agent框架走的是“为学日益”。 每个版本都引入新的概念——新的对象模型、新的生命周期、新的领域特定语言、新的约束层——抽象层不断累加,学习曲线不断变陡,用户必须理解的心智模型越来越庞大。跨过某个临界点,框架本身的复杂度就超过了它所要解决问题的复杂度。这就是“为学”的尽头。
克制的工具系统走的是“为道日损”。 它们不急着替用户把整个世界模型预设好,只提供少量稳定的原语,让复杂性留在具体任务中,而不是提前固化进框架。它看起来什么都“不是”,反倒能承载更多场景。“无为而无不为”。
这给Agent框架设计者的教益是:你的框架需要的不是更多抽象层,而是更少。 “损之又损”——在用户和底层能力之间的每一层抽象,都必须自证存在的必要性。无法自证的,就该删除。
四、反转定律:一切极端终将坍塌
反者道之动
反者道之动,弱者道之用。天下万物生于有,有生于无。(第四十章)
六个字,道家最强劲的动力学定律:任何趋势被推向极端,都会反转。
这是AI工程中最有力的预测工具之一。
过拟合正是“反者道之动”。 模型拟合训练数据的能力越来越强(趋势)→ 推至极端(完美拟合训练集)→ 反转(泛化能力崩溃)。整个偏差-方差权衡都可重新表述为“反者道之动”的一个特例。
技术行业的钟摆摆动亦是如此:
- 单体架构 → 微服务 → 又回到“适度的单体”(monolith-first)。
- 服务端渲染 → 客户端SPA → 又回到服务端渲染(Next.js、RSC)。
- 强约束 → 去约束 → 又回到适度约束。
- 规则式AI → 统计学习 → 又开始把规则注入LLM(structured output、tool use)。
每一次“革命”都宣称自己是终极答案,然后推向极端,然后反转。不是因为革命本身错了,而是因为单一方向的推进必然会触达该方向的极限,并开始产生它试图解决的问题的镜像。微服务解决了单体的问题,却创造了分布式协调的难题。去约束化解决了前期建模的问题,也往往把一致性问题重新带了回来。
对AI Agent设计者而言,这意味着:不要押注在任何一个单一趋势上。 当前“大模型包办一切”的趋势终将反转——小模型、专用模型、混合架构一定会回归。当前“自然语言作为唯一交互界面”的趋势也会反转——结构化输入、GUI、混合交互必定回到舞台。
“弱者道之用”—— 系统真正的力量来自柔弱的那一面。不是更多参数、更大模型、更强算力——而是更少但更精确的约束。梯度信号就是“天下之至柔”(第四十三章),它没有形态,没有实体,只是一个数字——但它能穿透千层网络,调整数十亿参数。推动系统演化的力量不需要很“强”,它需要很“准”。
柔弱者生机勃勃,坚强者步入死亡
人之生也柔弱,其死也坚强。草木之生也柔脆,其死也枯槁。故坚强者死之徒,柔弱者生之徒。(第七十六章)
活着的系统是柔软的。死去的系统是僵硬的。
这个洞察可直接转换为架构决策准则:你的系统能被改动的容易程度如何? 如果答案是“非常困难”——需要停机维护、需要数据迁移、需要重写接口——你的系统正在变硬,正在走向衰亡。如果答案是“相当容易”——热更新、渐进式迁移、向后兼容——你的系统还活着。
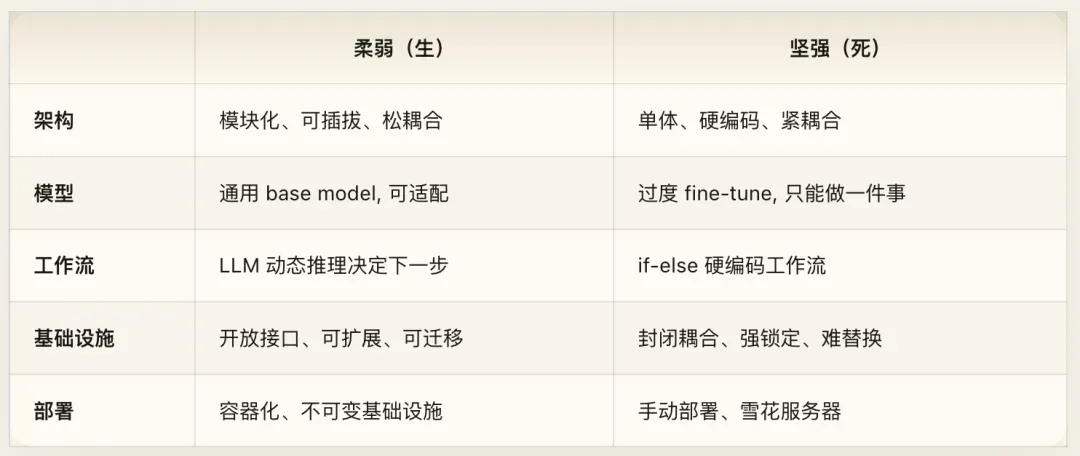
Agent架构中最致命的“坚强”,就是硬编码的工作流。 当你用if task_type == "search" then call_search_api()这类方式编排Agent时,你得到的是一个“坚强”的系统——在已知场景下快速可靠,但面对任何新场景便立刻崩溃。这是“死去的代码”——不能适应、无法进化、不能自我修复。
相反,让LLM在运行时根据上下文动态决定使用什么工具、调用什么API、按什么顺序执行——这是一个“柔弱”的系统。它看起来不够“确定”、不够“可控”,但它活着——它能适应、能进化、能应对你在设计时未曾设想的情况。
“强大处下,柔弱处上”—— 架构层次的分配原则:底层使用“坚强”的确定性组件(存储引擎、网络协议、操作系统内核),上层安置“柔弱”的灵活性组件(推理引擎、决策模块、交互界面)。底层的可靠性为上层的灵活性提供坚实基底。
五、退化链:系统如何从涌现滑向官僚
上德不德,是以有德;下德不失德,是以无德。故失道而后德,失德而后仁,失仁而后义,失义而后礼。夫礼者,忠信之薄,而乱之首。(第三十八章)
这一章描绘了一条退化链路,它精准对应了每一个技术组织和每一个软件系统的生命周期。
第一阶段·道:涌现秩序。 系统设计精良,几乎不需要规则。正确行为从架构中自然涌出。代码清晰到不必注释。接口直觉到无需文档。团队默契到不需流程。——这是创业公司的早期状态,也是每个优秀系统的诞生期。
第二阶段·德:内禀能力。 设计开始老化,但团队的经验和个人能力弥补了设计的欠缺。没有明文规则,但“老手”知道怎么做才是对的。系统靠人而非靠架构运转。——这是危险的开始。关键人物离开,系统就出问题。
第三阶段·仁:补丁和善意。 团队开始写变通方案。“这里有个问题,我先打个补丁。”“这个接口设计得不好,我写个适配器绕过去。”每一个补丁都出于善意(“仁”),但补丁本身便是技术债。——到了这个阶段,系统开始变得难以理解。
第四阶段·义:规范和流程。 管理层意识到系统靠补丁运行太危险了,开始制定规范。编码规范。设计评审。变更流程。——这些规范(“义”)是必要的,但它们是症状的治疗,不是病因的消除。
第五阶段·礼:官僚与仪式。 规范不够用了,因为没人真正遵守。于是升级为强制流程:Code Review Checklist(50项)、Deploy Approval Chain(三级审批)、Change Advisory Board(周会评审)、Architecture Review Committee(月会审批)。——“夫礼者,忠信之薄,而乱之首”:当组织充满繁琐的审批仪式时,这不是秩序的标志,而是底层信任已经崩塌的标记。官僚不是秩序,官僚是混乱的最终形态。
你待过的每一个技术团队,都可以被定位在这条链上的某个位置。 且几乎所有团队都在向右滑——从涌现走向官僚,从道走向礼。
AI Agent系统也难逃此律。一个Agent系统的生命周期:
- 道:LLM直接调用工具,行为从提示词中自然涌现。
- 德:增加了一些少样本示例和系统提示优化。
- 仁:开始写降级逻辑——“如果Agent选错了工具,就默认用这个”。
- 义:制定了Agent行为规范——“必须先搜索再回答”、“禁止调用超过3次”。
- 礼:堆叠了多层护栏、验证器、后处理器、人工审批环节。
到第五阶段,你的“Agent”系统实则已是一个规则引擎。LLM的涌现能力被层层包裹,窒息在审批流程里。
正确的做法不是从阶段五继续增加规则,而是回到阶段一——重新设计架构。 “是以大丈夫处其厚不居其薄”——站在“道”的厚实根基上,不再停留在“礼”的单薄表面。
六、水性计算:自适应架构的七项原则
上善若水。水善利万物而不争,处众人之所恶,故几于道。居善地,心善渊,与善仁,言善信,政善治,事善能,动善时。(第八章)
水是老子最钟爱的隐喻,因为水拥有一种极其罕见的特性组合:没有固定形态,却保有确定的物理性质。
水可以是溪流、湖泊、海洋,也可成冰、化汽——形态无限。但它的密度、比热容、溶剂特性是确定的、可预测的。
这就是好系统架构的终极形态:没有固定的业务逻辑(形态灵活),却拥有确定的设计约束(性质恒定)——一致性保证、延迟上限、吞吐承诺。
水的“七善”给出了七条可操作的系统设计原则:
居善地——位置自适应。 水总是流向最需要它的地方——低洼处。好的计算也应如此:服务应部署在最靠近用户的位置(边缘计算),数据应存储在最频繁访问它的位置(数据局部性),Agent应在最需要的环节介入,而非全程陪伴。
心善渊——深度缓冲。 水的深处是安静的——无论表面多么波涛汹涌,深处始终平静。好的系统内部拥有深而大的缓冲——充裕的消息队列深度、足够的连接池、宽裕的积压容忍。这些“深渊”吸收突发流量,让系统表面保持平稳。
与善仁——接口宽容。 波斯特定律:“在发送时要保守,在接受时要开放。”这正是“与善仁”的英文版——对输入宽容,对输出严格。用户传来一个格式异常的JSON?尝试修复再处理,而不是直接返回400。正是这条原则让互联网在协议实现千差万别的设备间成功运行了半个世纪。
言善信——契约可靠。 API承诺返回什么就返回什么。如果文档说超时时间是30秒,就别在第15秒断开。如果SLA承诺99.9%,就别实际只有99%。水从不欺骗——它的物性永远可预测。
政善治——资源调度清晰。 水不会同时朝两个方向流。好系统的资源分配也是清晰的——连接池的分配策略、内存的使用优先级、CPU的调度算法——每一项都应有明确且可解释的治理逻辑。
事善能——做好本职。 水作溶剂就是最好的溶剂,作热交换介质就是最好的热交换介质。每个服务在自己的领域内做到最优,不越界。Agent亦是如此:别让编程Agent去应付客服,也别让搜索Agent去写代码。
动善时——时序精确。 水在零度结冰,在一百摄氏度蒸发——不早不晚。好系统在正确的时间点执行正确的操作:连接在超时时刻精确断开,缓存在TTL到期时精确过期,自动缩放器在负载上升时及时扩容,而非滞后五分钟。
“夫唯不争,故无尤”—— 当你的服务不争夺资源、不争夺控制权、不争夺调用优先级,它便不易发生故障。微服务架构的核心智慧并非“拆小”,而是让每个服务“不争”。不争才能无故障。
七、系统的“有”与“无”:通用基础设施的道家注解
有之以为利,无之以为用。(第十一章) 天下万物生于有,有生于无。(第四十章)
很多系统设计一上来就按场景切碎:为检索配一套组件,为记忆配一套组件,为事件流配一套,为分析再配一套。每个组件都很锋利,但锋利也意味着它在押注某一种世界的不变。
真正更接近“道”的做法,往往不是先把一切专门化,而是先保留一个足够通用、足够克制的核心。核心无须替未来的全部用法做决定;它只提供稳定边界、清晰约束和可扩展接口。正因为中心保持“空”,不同能力才得以在其上生长。
道冲而用之或不盈。渊兮,似万物之宗。(第四章)
“道冲而用之或不盈”——真正耐久的基础层,核心常常是空的:它不急着替所有场景做完决定,因此也不易因场景变化而过时。它像“万物之宗”,不是因为它什么都显式内置,而是因为它给组合预留了空间。
持而盈之,不如其已。揣而锐之,不可长保。(第九章)
“揣而锐之,不可长保”——打磨得太锋利的工具难以长久。将系统打磨得过于锋利,意味着把自己绑定在某一个特定场景上。场景一换,原有的“专业化”就会迅速变成包袱。
对AI Agent架构设计者,这里最实际的建议是:先建设一个通用、清晰、可演化的底座,再让各类上层能力在其上组合出来。 不要为了每种能力都急着发明一套彼此隔绝的专用世界。让基础设施层保持“无”的灵活性,让具体能力在其上自然生长。
八、结语:道法自然
人法地,地法天,天法道,道法自然。(第二十五章)
应用层依循平台层。平台层依循基础设施层。基础设施层依循底层数学。底层数学又依循什么?——“自然”。它依循自身的本性。数学不需要再去“依循”什么,它就是它自己。
这是系统设计的第一性原理:你的设计应当顺应你所使用技术的自然特性,而不是强行让技术扭曲以迁就设计。
LLM的自然本性是概率性的——别硬要它给出100%确定的输出。Transformer的自然本性是并行的——别设计只能串行执行的Agent工作流。外部工具与环境的自然本性是异步、脆弱、带延迟的——别把Agent的世界想象成一串永不失败的同步函数调用。
顺着来。别逆着来。这就是“道法自然”。
道可道,非常道。
能被写成文章的洞察,不是最深的洞察。但我们依然写了。
因为即使写出来的只是“可道之道”,它也指向了那个不可道的方向——那个让你的系统设计从“规则堆叠”走向“涌现培育”的方向,从“掌控一切”走向“理解底层地形、顺势而为”的方向。
去理解你系统里的“无”——那些未被参数化的空间,那些未被规则覆盖的行为,那些未被监控捕获的涌现模式。能力就住在那里。
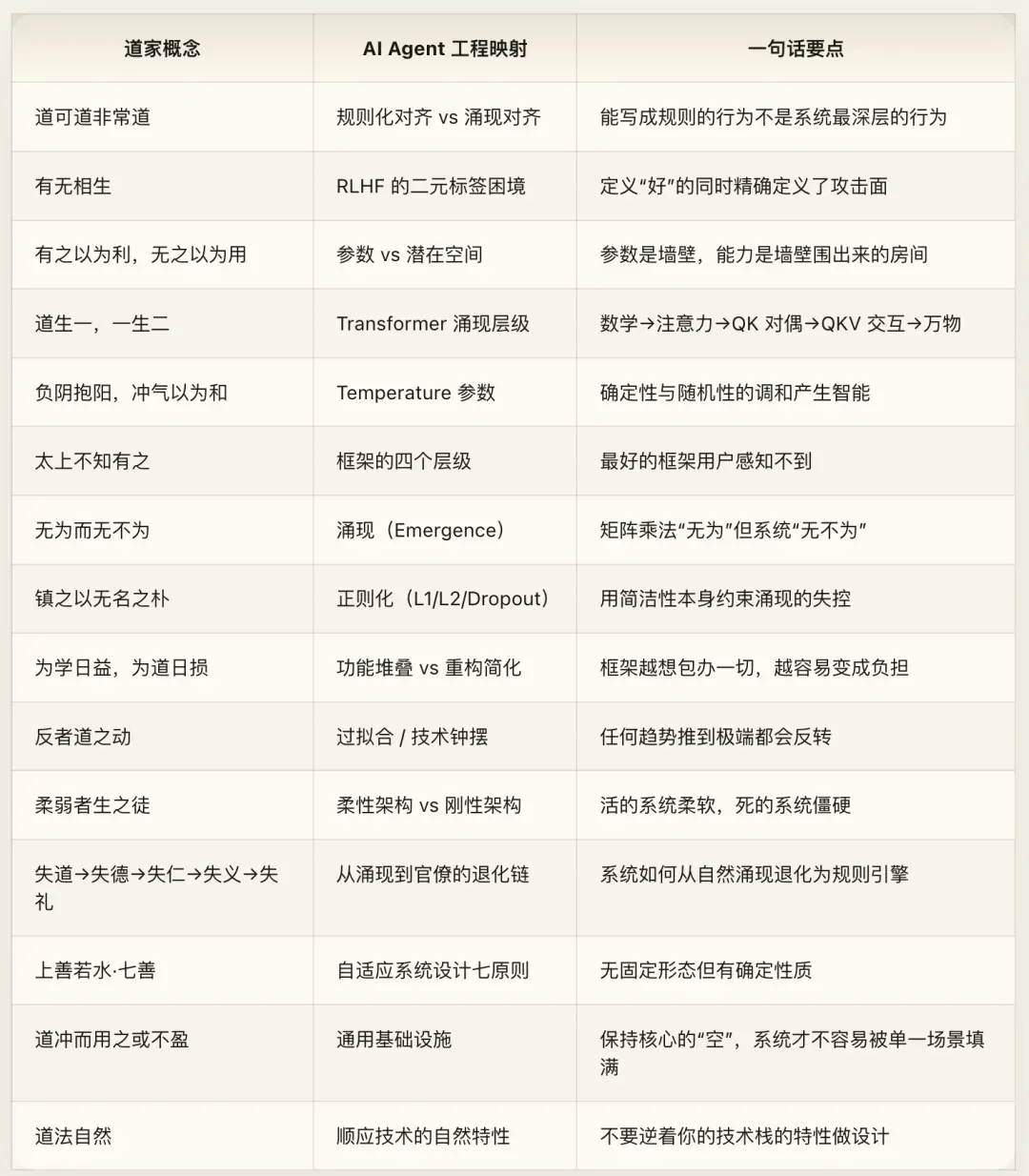
附录:核心映射速查表