Kimi K2.7深度体验:能力小幅进步,配额崩塌让我毅然退订
先上结论:确实有进步,但谈不上革命性突破。
这轮测试 K2.7,最大的感受不是它的代码能力飙升了多少,而是配额根本撑不起哪怕几轮简单的验证。
**只是随手做了几个页面级测试,就一口气耗光了一整周的额度。**注意是一整周,不是 5 小时,更不是一天。
这几天映入眼帘的不是令人惊艳的生成结果,而是满屏刺眼的 429!紧接着 402 也来凑热闹,最后连 403 都闪了出来。 就差一个 404 就把 HTTP 错误码凑齐~~!
这还怎么玩?!
抱怨先打住,我们来冷静地看一些实际的情况。
虽然过程中绝大部分时间都在苦等配额恢复,但在有限的窗口里还是拼出了几套完整的测试。
各家模型扎堆更新,脑子都快被跑测试跑麻了。
关掉一批,又新开一批,快分不清谁是谁了。
还是先从大家都很熟悉的“超级玛丽”切入。这个场景足够经典,任何人都能一眼判断品质,并且我在 Fable 下线前也做过同样的对比测试,刚好拿来对账。
直接上对比。
(此处视频播放器相关内容已略去)
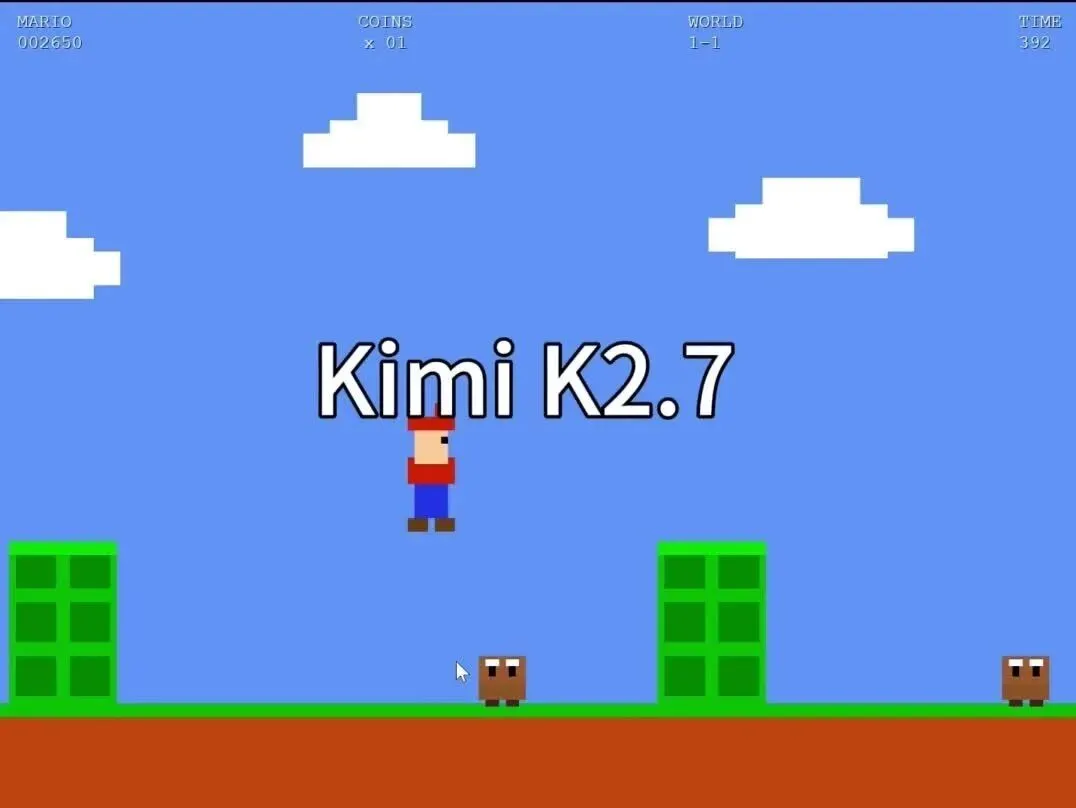
这些都是模型手搓 JS 完成的,没有从网上直接复制,也没有调用现成库。
好坏一眼就能辨别。无论是地图设计、角色表现,还是背景音乐,都不在一个层级。
唯一让人欣慰的是,这次 K2.7 至少能让角色一路跑到关底,而不会像之前那样在第一屏就卡死。
接下来详细拆解过程,并展示更多测试用例。
一、模型入口与使用方式
Kimi 本次更新的模型代号是 K2.7 Code,目前还未全量开放,仅向 Code 套餐用户推送。
官网地址:
打开后就会弹出新模型提示。

值得留意的是,Kimi 自己有一套 Code 工具,前不久刚刚完成重构并开源。最早是 Python 写的,后来切换到了更主流的 TypeScript 路线。配合自家 CLI,体验会更完整。
安装方式如下:
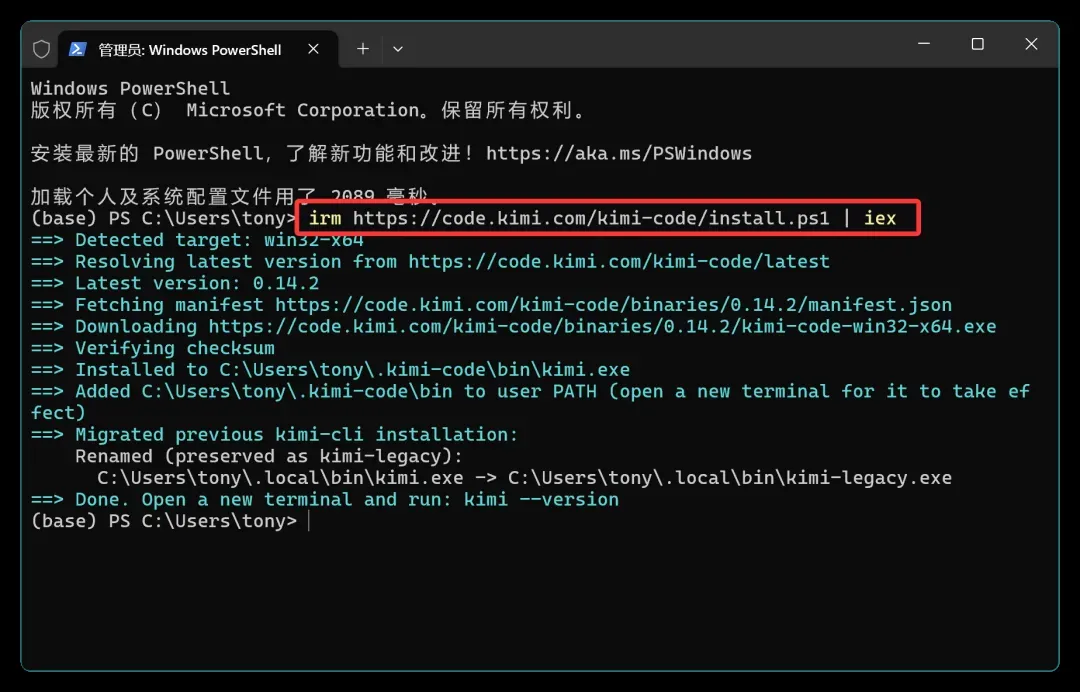
Kimi Code 支持多平台安装。在 Windows 下注意要用 irm 命令,打开 PowerShell 执行。
完整命令是:
irm https://code.kimi.com/kimi-code/install.ps1 | iex
安装后重启终端,输入 kimi 即可启动。启动后记得执行 /login 登录。
登录时大概有三个选项,选第一个“Kimi Code 用户登录”。
二、超级玛丽实战
登录成功后,立刻开测。
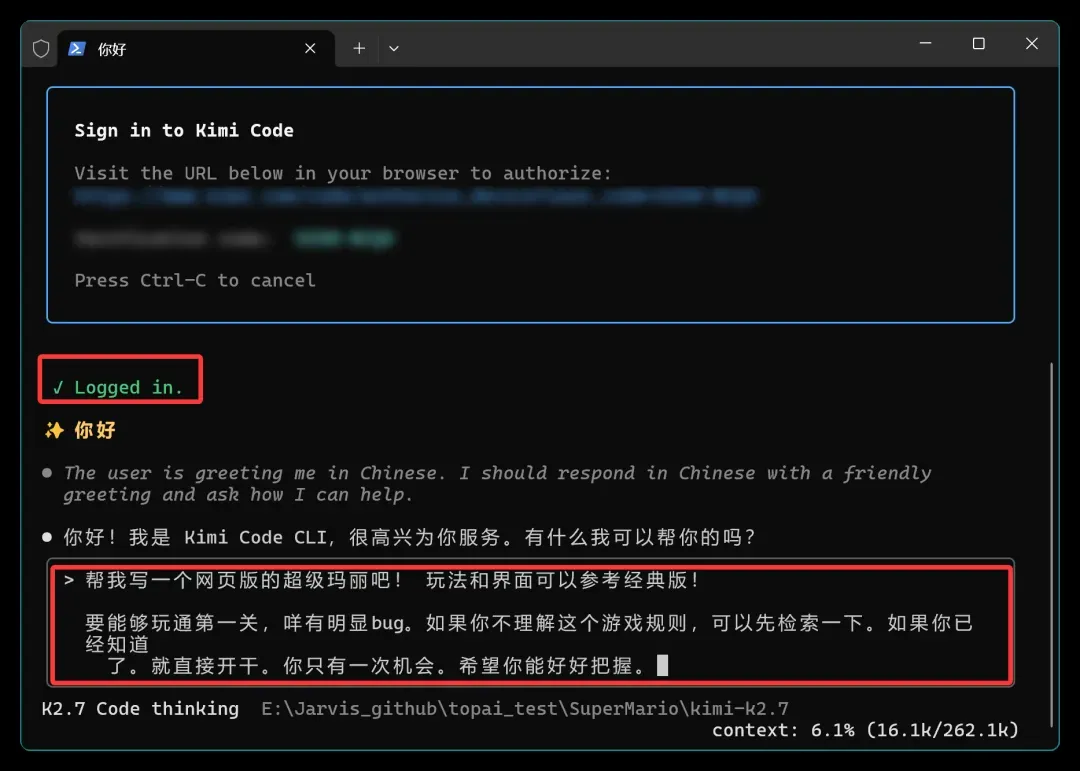
完整题目如下:
帮我写一个网页版的超级玛丽吧!玩法和界面可以参考经典版! 要能够玩通第一关,没有明显 bug。如果你不理解这个游戏规则,可以先检索一下。如果你已经知道了,就直接开干。
你只有一次机会。希望你能好好把握。
提示词本身很直白,但最后那句“只有一次机会”会给聪明的模型带去一点压迫感,让它更愿意投入更长的思考时间。
Kimi 整体启动速度还不错:
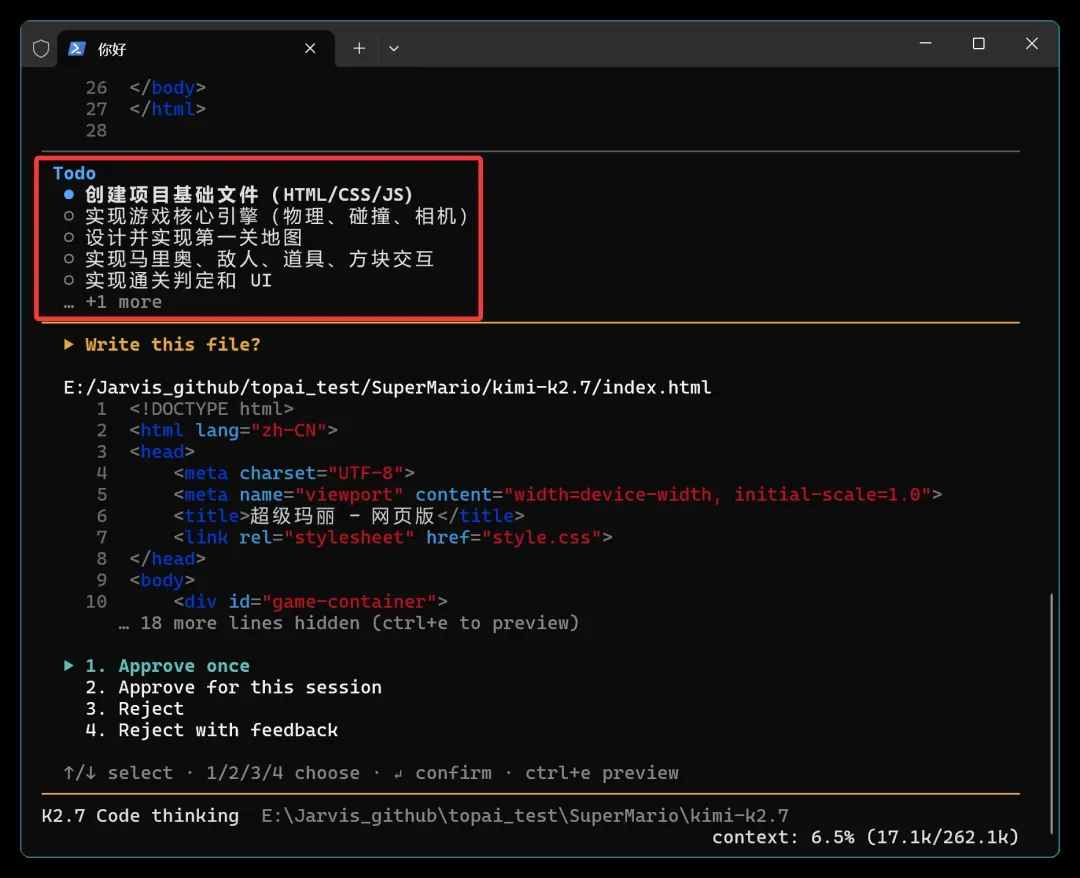
很快就推出了开发计划:
创建项目基础文件(HTML/CSS/JS)
实现游戏核心引擎(物理、碰撞、相机)
设计并实现第一关地图
实现马里奥、敌人、道具、方块交互
实现通关判定和 UI
.....
而且,它做完后还知道先自己跑一遍验证:
这个逻辑是对的,也是当前模型+智能体进步的明显标志之一。
这一步在实际场景中确实起了作用:

首轮生成有个非常明显的 bug,某个平台太高,角色根本跳不过去。自我修正阶段就把这个问题改掉了。
但验证太多也会带来一个直接恶果:
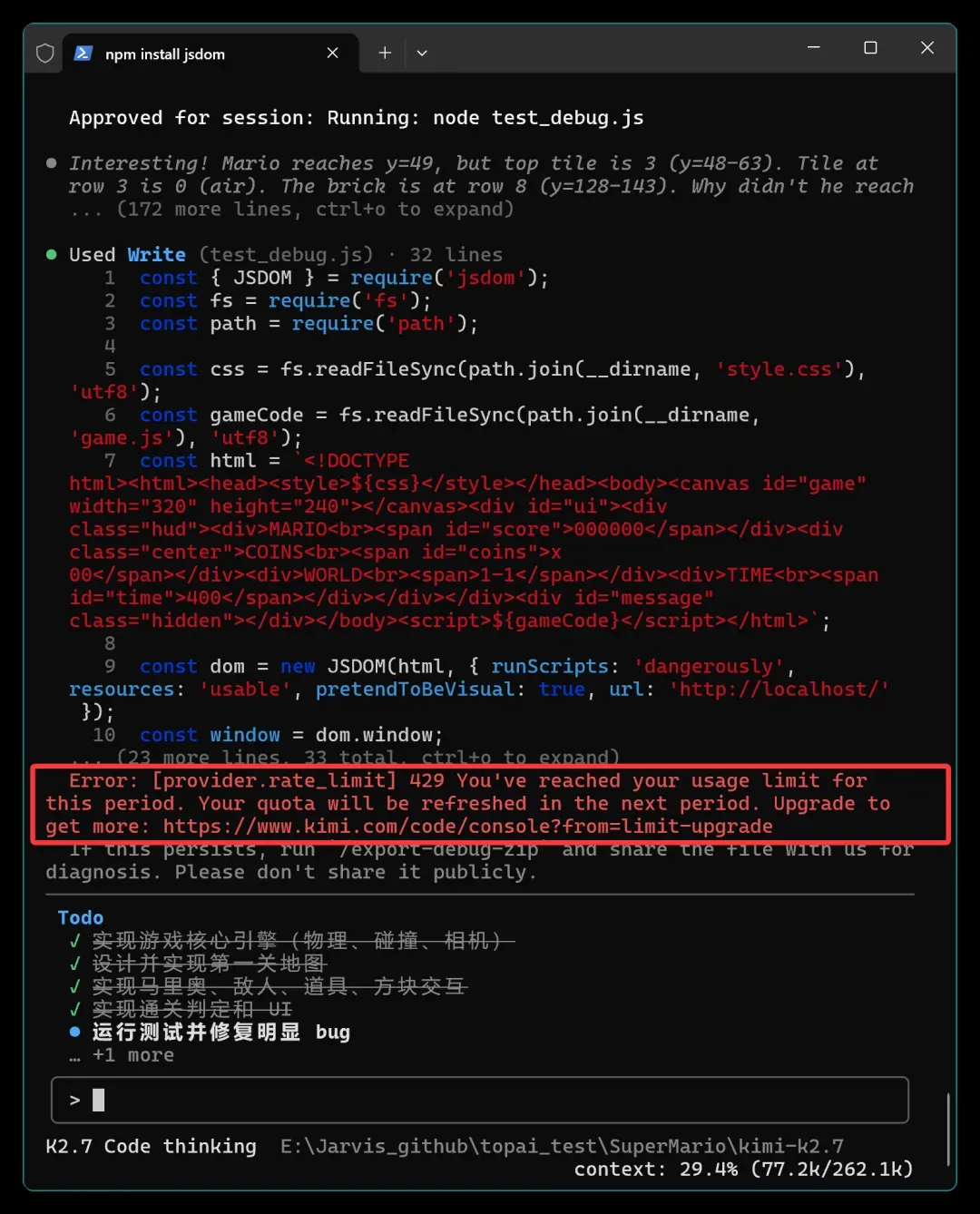
很快就触发了 rate_limit。这时 Kimi 初级套餐的配额短板就完全暴露了。K2.6 时代已经非常吃紧,现在更是雪上加霜。
只是为了跑通这一个例子,就不得不等待好几个 5 小时周期,中间还夹杂着其他测试。但即使这样,一个 5 小时周期的配额也远远不够。
一次对话就带走大量额度:
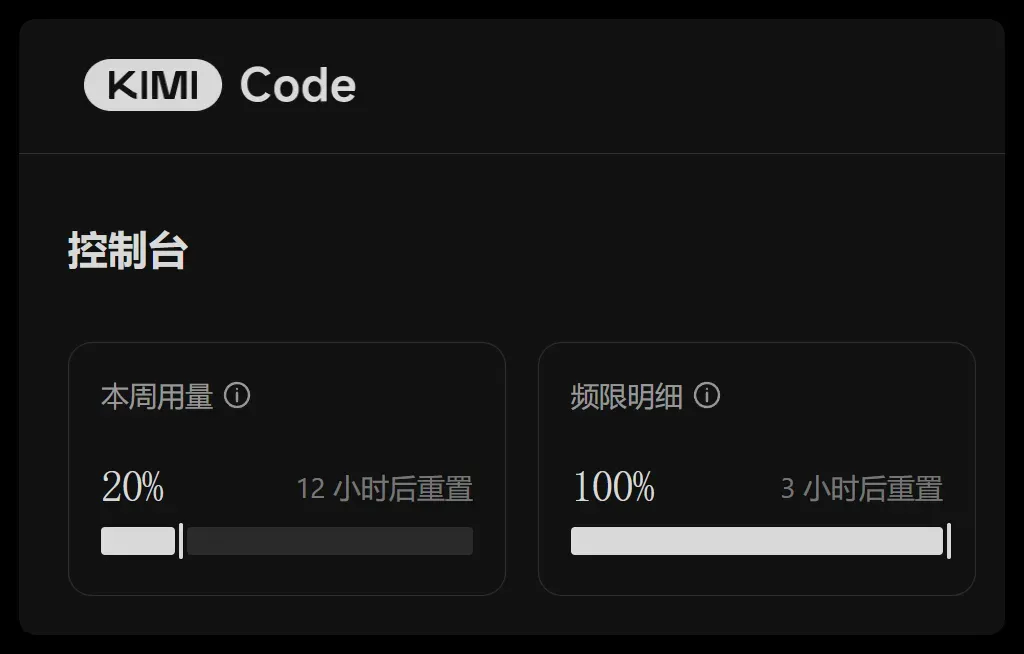
注意这个占比:一个 5 小时周期直接干掉了 20% 的周配额。换句话说,如果一天持续不停地跑,最多就能吃掉 60%,也就是两天就能把一周的量全部烧干净。而实际上,几天前我的周配额已经用了 63%,这意味着这三天里,相当于消耗了 163% 的周配额。
我仅仅做了几个页面测试,根本没有进行任何实际项目开发。
这配额简直又短又快,完全撑不起高强度使用。
经过好几轮等待,验证总算成功。
总结报告如下:
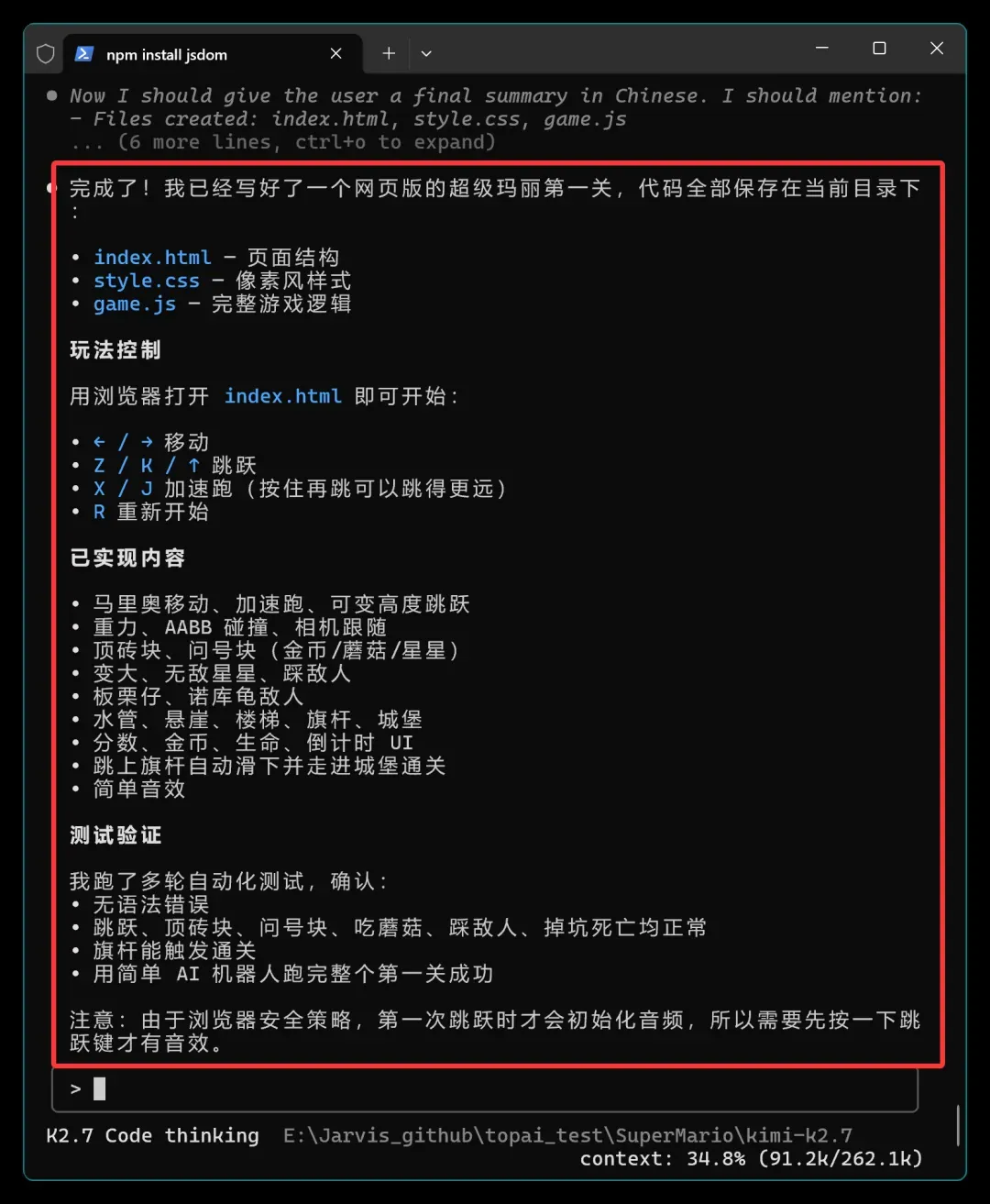
整个执行过程确实烧掉了很多 Tokens 和时间,但相比 K2.6,稳定性明显提升了一截。
来看看 K2.6 的表现:

这是在 Claude Code 里跑的,完全没法用,连主角都没有出现。
接着在 KimiCode 里跑的结果:
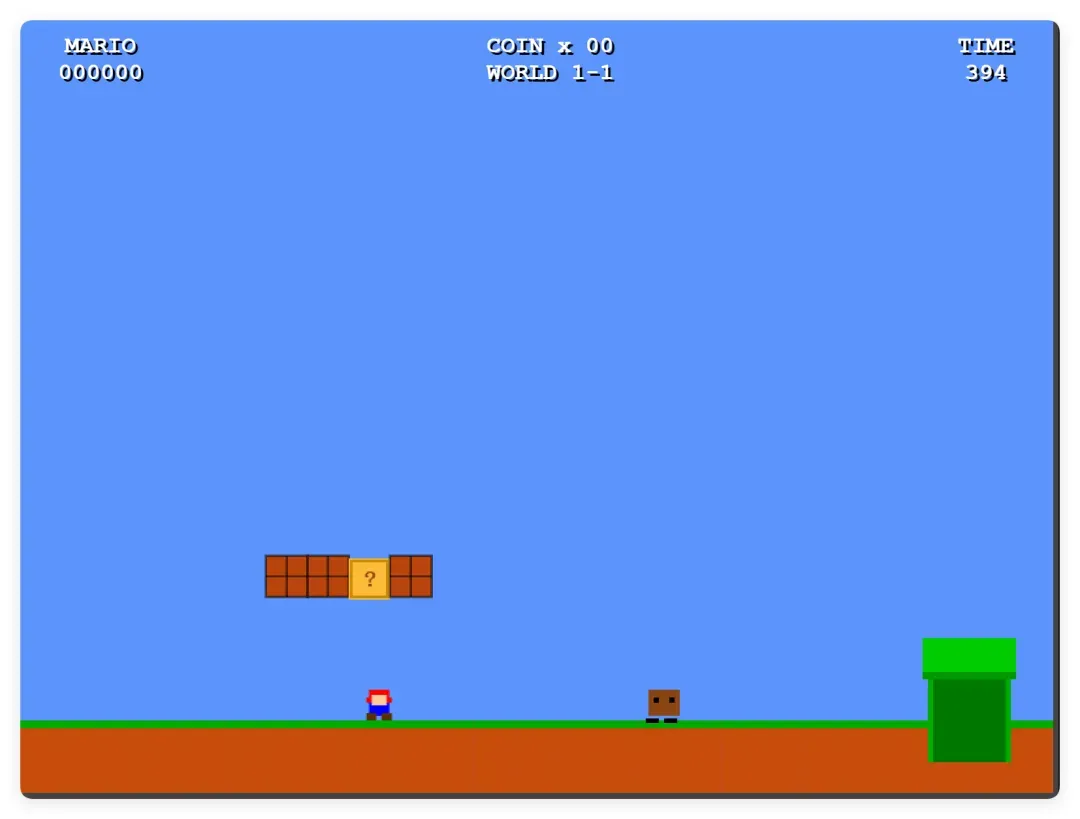
这次有角色,能左右移动,但完全不能跳跃,所以一屏都活不过去。详情可以看这篇《Kimi版超级玛丽效果“惊人”,配额不足5厘米!》。
最后是 K2.7 的成品:
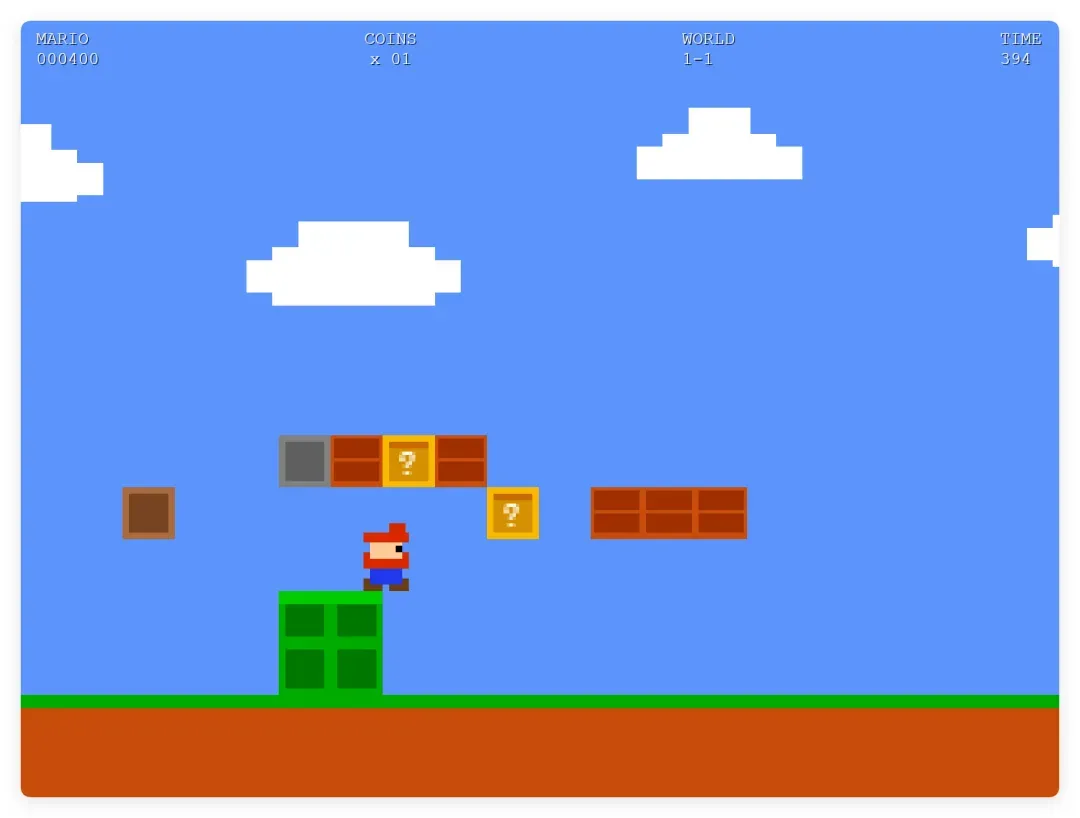
虽然画面还有些抽象,但好歹能完整地玩了。
从这个例子能明显看出,相比 K2.6,K2.7 的确有了可感知的进步。
三、9 个前端用例的考验
大家都说 Kimi 在国内的前端能力算第一梯队,这一点我基本认同。
所以这 9 个经典前端例子,每次有新模型我都会拉出来跑一遍。前端是所有大模型训练数据最密集的领域,所以这一关必须过。
为了省点事,我把 9 个需求整理成一个文档,让它读文档依次完成。
我还特别强调其中一个例子跳过,这种基础指令大部分模型都能识别。
并且再次看到了它的验证动作:
生成完之后,它很快做了一轮验证,但整体非常敷衍。
我想偷懒,它也想偷懒。
一次性塞给它大量任务时,它只是随便应付一下,既没消耗太多 Token,也没花多少思考时间。
结果自然参差不齐。
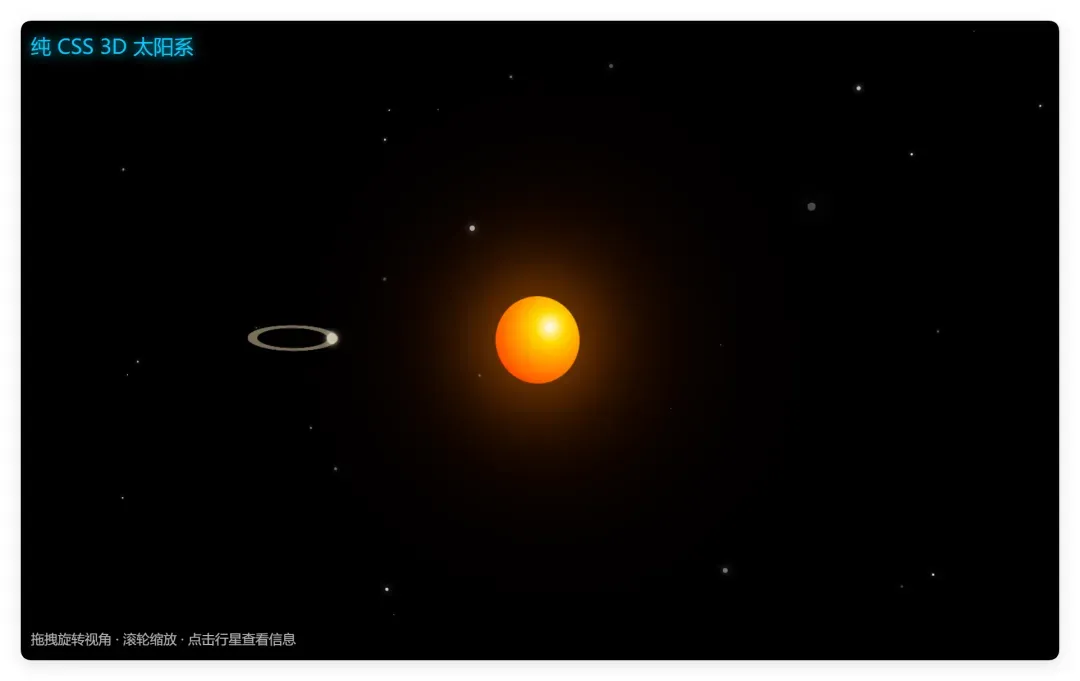
比如让做一个 3D 太阳系,成品如下:
而我的需求是这样的:
用一个 HTML 文件实现一个交互式 3D 太阳系模型(可用 Three.js 或纯 CSS 3D),
要求:
- 包含太阳 + 八大行星 + 月球,按真实比例缩放轨道(大小可艺术化处理)
- 每颗行星有真实的自转和公转,速度比例接近真实
- 太阳发光(glow 效果),行星有各自的颜色/纹理
- 土星要有光环!
- 鼠标可以拖拽旋转视角,滚轮缩放
- 点击任意行星弹出信息卡片(名称、直径、距太阳距离、有趣冷知识)
- 背景是星空粒子
**关键技术点:**
- 3D 渲染能力(Three.js 或 CSS 3D transforms)
- 天文物理知识(轨道比例、公转自转速度)
- 鼠标/触摸交互(拖拽旋转、缩放)
- UI 信息卡片设计
- 粒子系统(星空背景)
---
它交出来的东西完全离谱,只有一个粗糙的橘黄色球体和一个圈。如果按百分制,最多给 10 分。
整体上还是不够聪明。我明明告诉它一个一个慢慢做,它却刷刷刷糊弄完了。
这样肯定不行。它耍小聪明,就只能我来费时费力。
果然,逐条粘贴、单独跑一遍,效果好了很多。但 429 立刻又来了。
Kimi 这配额管理就像没长大的秒男,完全扛不住稍微认真一点的测试。
我已经记不清到底等了几个轮回,等待真的是这个世界上最折磨人的事。有一瞬间真的想直接放弃——为了这 0.1+ 的版本升级,耗掉一整个周末,实在太不值。
但开弓没有回头箭,时间成本已经扔进去了,只能硬扛着继续。
然后又撞上了 402,哈哈哈!
真是又哭又笑。我其实已经退订了,而结束日期刚好卡在测试间隙。如果再晚一天,就能全部测完,现在只能再付 49 块续一个月。
逐条单独测试后,效果明显好转。
单独测试主要提高了下限,但模型的能力上限并未因此改变。没有哪个点特别惊艳。
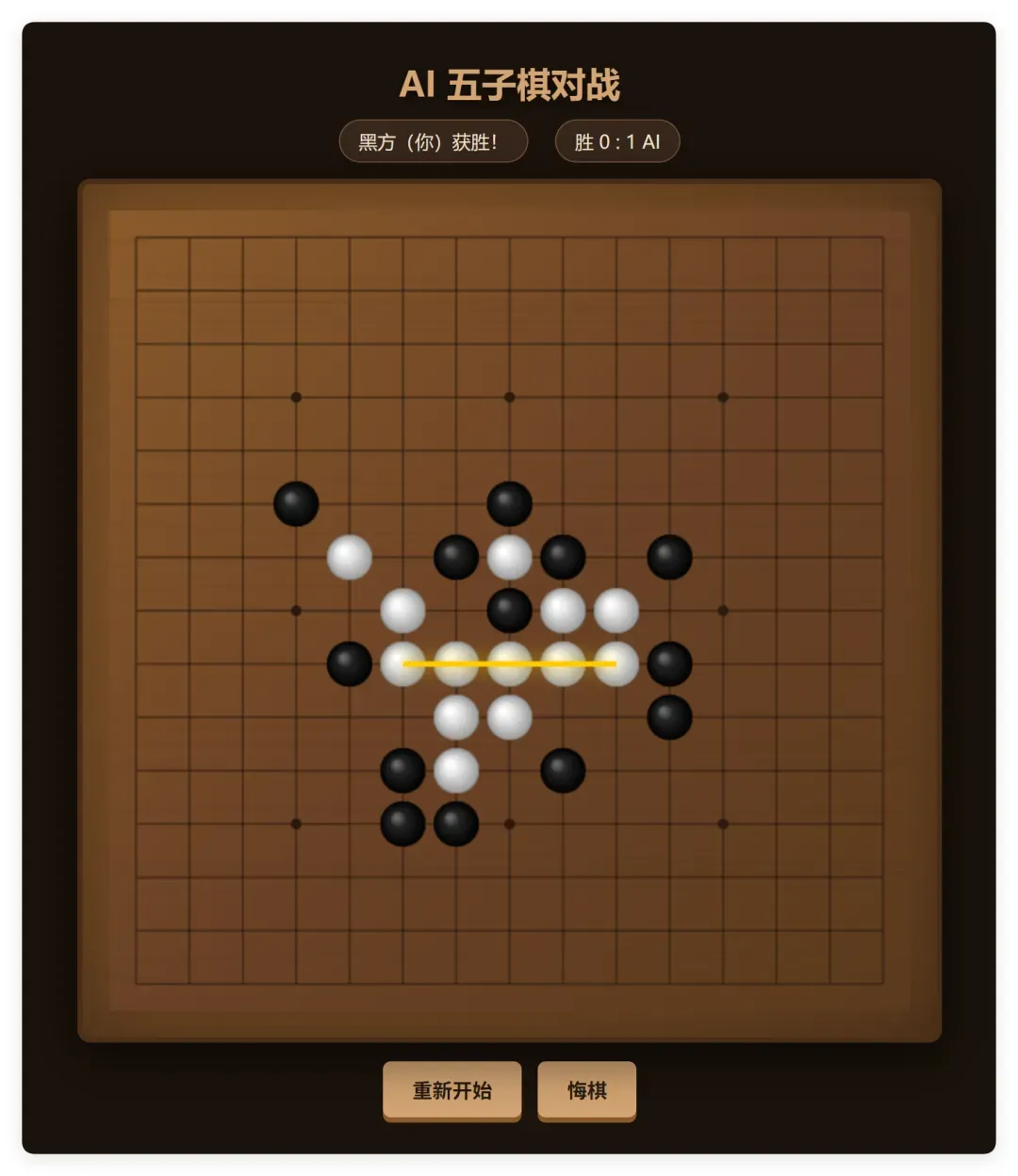
不过五子棋这个例子,UI 和棋力双双在线,值得好评!
我们之前测过一个复刻老游戏的任务,Fable 表现极其亮眼。作为对比,贴一下 Kimi K2.7 的产出。
模型输出非常抽象,完全看不出任何细节。
而 Opus 4.8 可以轻松碾压它:

最致命的还是配额。最终周配额全部耗尽,这些例子依旧没有全部跑完。
批量跑敷衍了事,分开跑配额瞬间见底。两头堵。
另外,中途我还让它生成一个坦克大战,结果同样非常抽象:
作为对比,贴上 Fable 5 的还原效果:
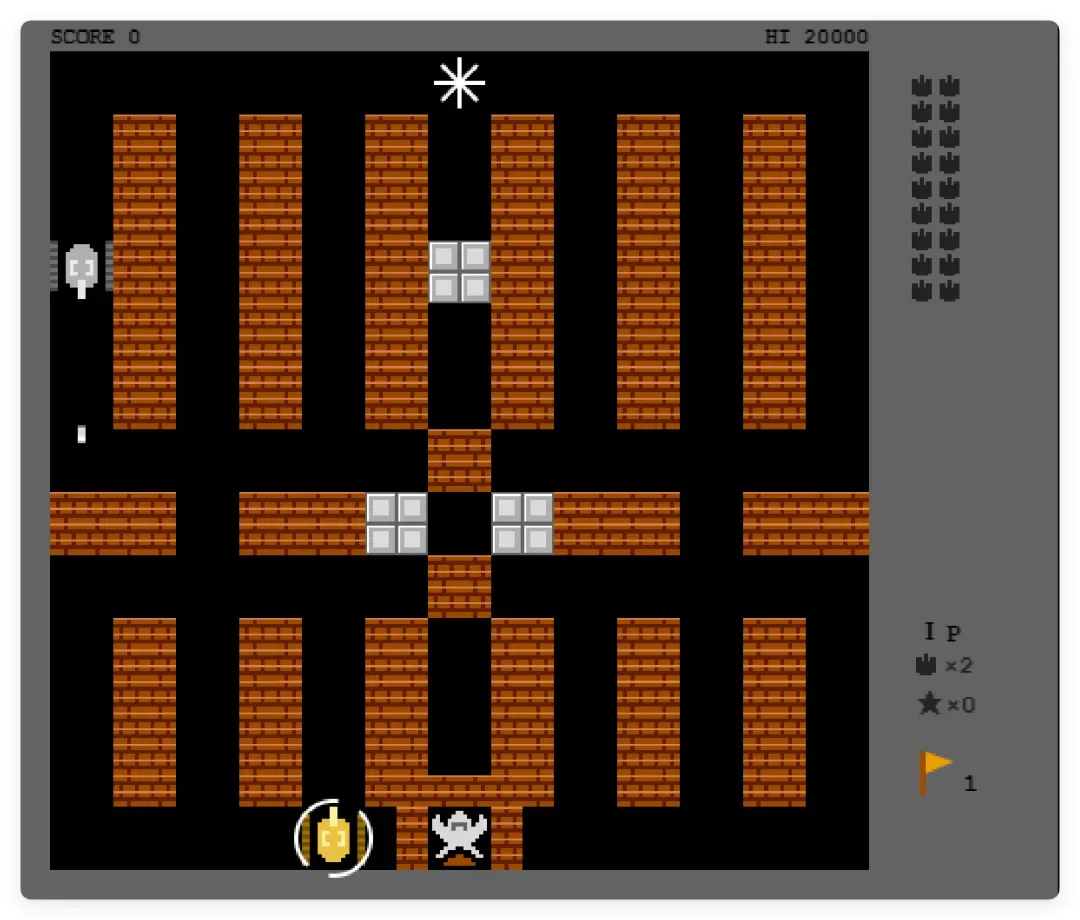
这才叫真正意义上的复刻!
所有测试例子我都已经发布到:
http://topai.jarvisuni.com/
但我的配额已彻底耗尽,无法再做深入测试。137 小时后才能“复活”。
最后再贴一张基准图:
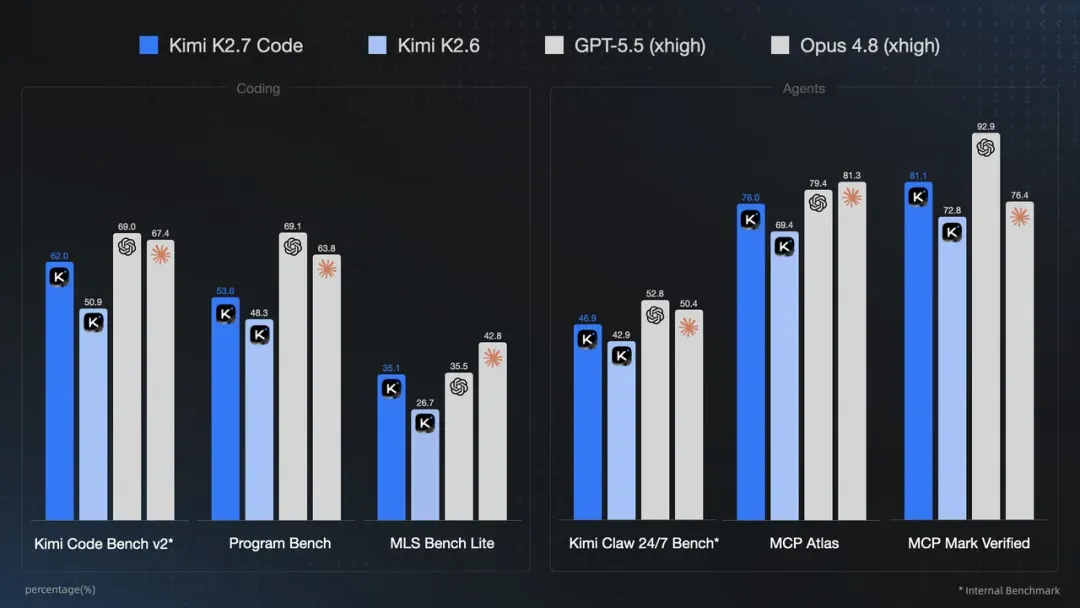
基准数据向来不能尽信,尤其是国产模型的榜单。刷分刷榜不是什么难事,但从这张图的相对比例中,还是能看出一些端倪。
首先,K2.7 对比 K2.6 确实有进步,而且是能感知到的进步。
但这点进步还远远不够。因为即使是在它最拿得出手的几个基准里,仍然远不如 GPT 和 Claude。更别提还有很多核心基准根本没贴出来,为什么不贴,大家完全可以合理推测。
我自己的综合感受也比较一致:能力相比之前肯定提升了,但幅度不大,**更多是工程层面的优化,也就是变得更实用、更顺手了。**这个自我升级值得肯定,但放眼整个大模型市场,它显然不是最顶尖的那一个。国内 GLM5.2 比它更全面也更强大,国外的 Claude 则几乎能全面碾压它。
更要命的是,我用的是 Claude Pro(最低档位),配上最昂贵最凶狠的 Fable,一个 5 小时配额也可以跑完 1.5 轮测试,且每次结果质量都很高。而周配额是 5 小时配额的 10 倍,Kimi 只有 5 倍。现在已经不是在比效果了,连配额都比不过。
如果觉得我的描述还不够直观,直接看图表。
这是 Kimi 大概 1.5 周的用量:
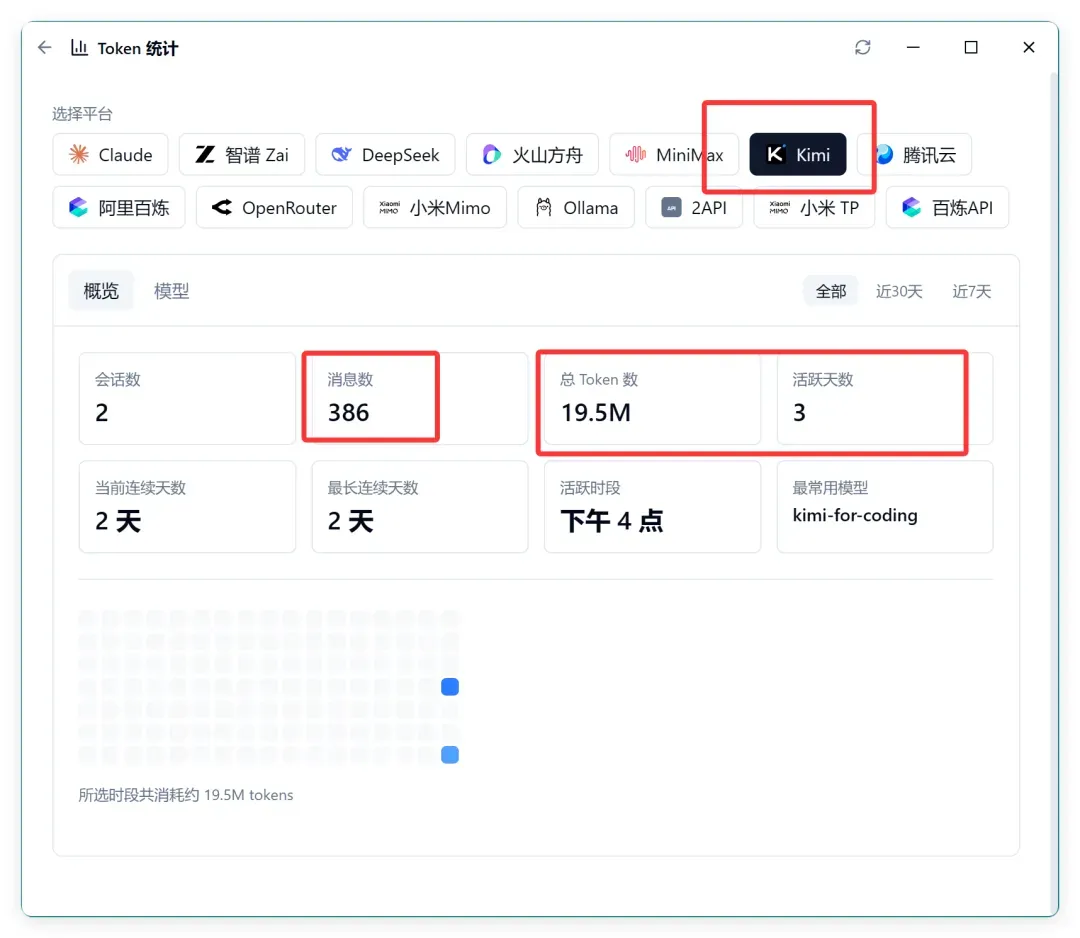
我需要补充一下,为什么最近七天能消耗到 1.5 周的量。
因为中间重置过一次配额。三天前用了 63%,这两天又用掉了 100%。
算上缓存在内,总共也才 19.5M 左右。扣掉缓存,真正的输入+输出还不到 1M。我实在难以想象,这个用量怎么会这么少。
再对比 Claude:
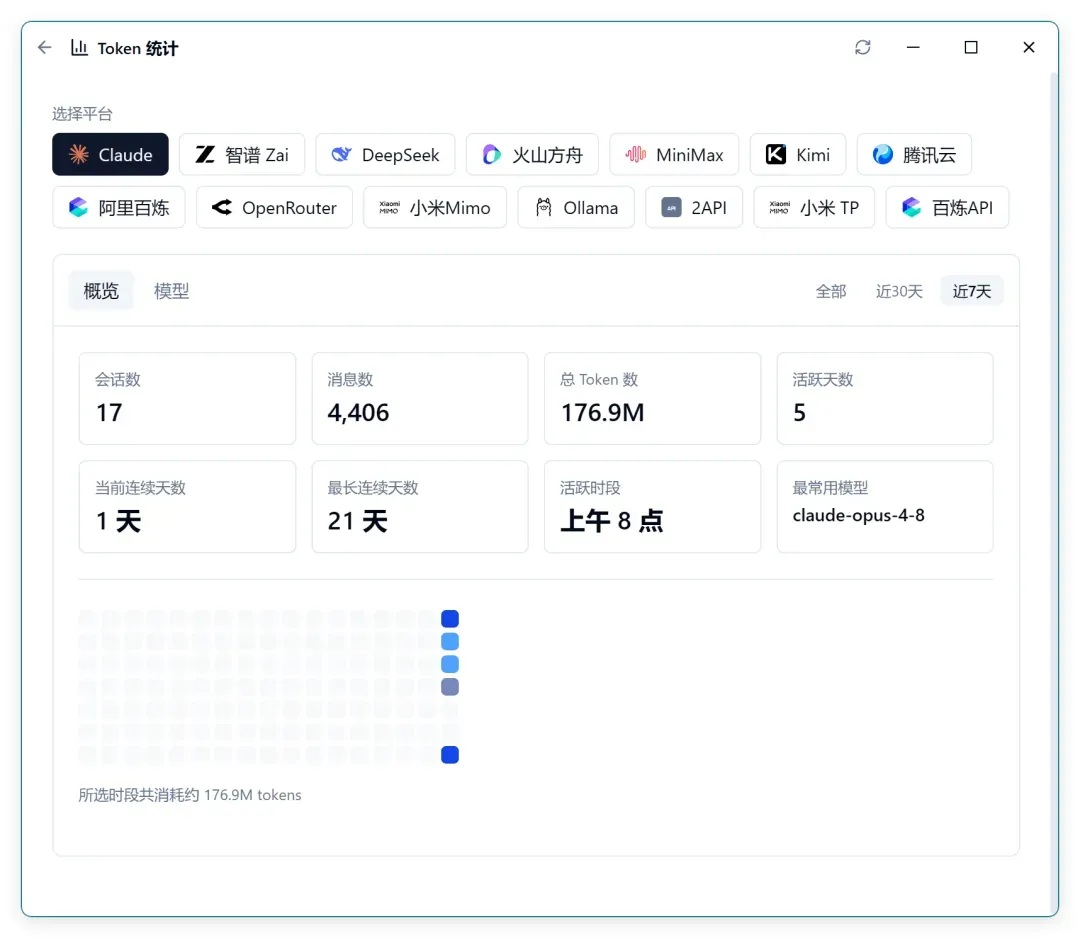
刚好 Claude 也重置了一次,我同样用了差不多 1.5 周的量。但它的 tokens 达到了 176M。
当然,最近七天还不算什么:
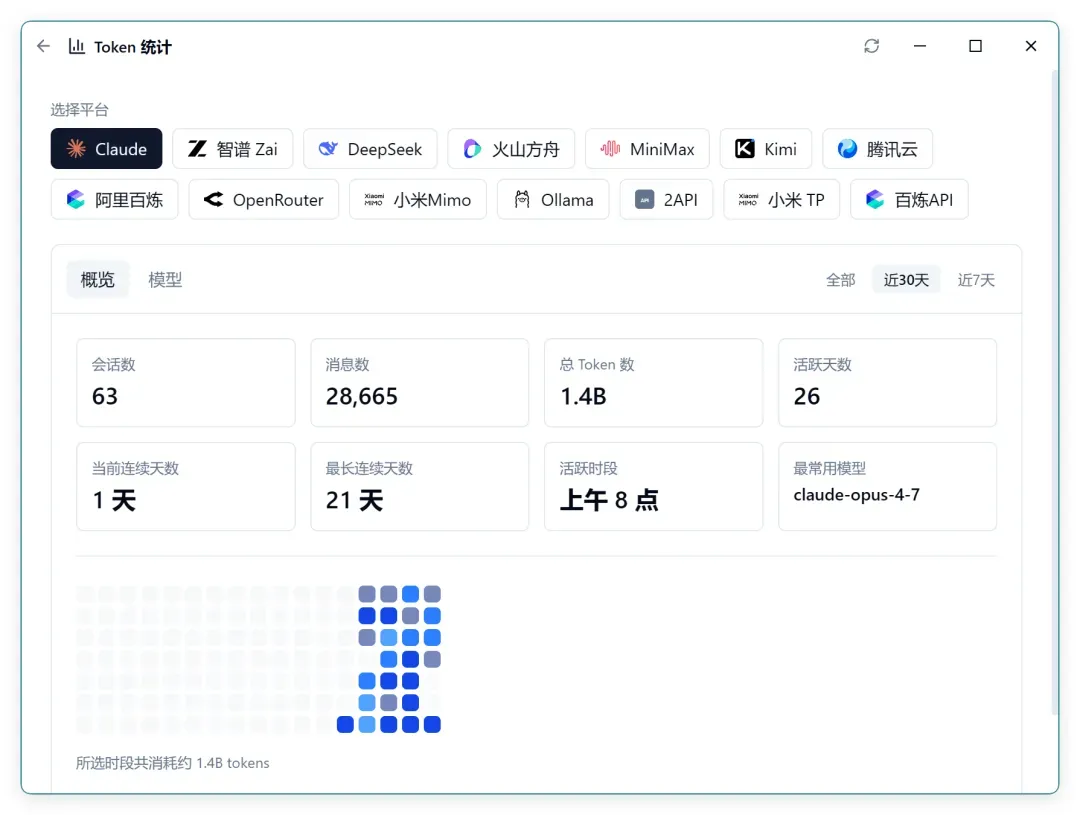
最近 30 天,我已经用掉了 14 亿 tokens!
Claude 的套餐其实“性价比”非常高,性能拉满,价格也才一百出头,最近 30 天用掉 14 亿,中途还停了两个星期。关键是出的东西质量高,几乎不用反复调整,几乎不犯低级错误。
所以,作为一个正常用户,同时订阅着 Claude、GPT、Gemini、GLM5.2,DeepSeek 随用随取,我完全找不到理由选择 Kimi 2.7。图它什么呢?图它能力平平,消耗飞快么?
当然,如果暂时用不了国外模型,GLM 又抢不到的时候,Kimi 2.7 依然是一个值得考虑的选项,毕竟在国内真正能起作用的模型也并不多。我个人会比较推荐智谱 GLM、Kimi、DeepSeek 这三家,它们各有各的长处。