从部署到对话:开源DLP3D 3D虚拟角色完整指南

数字生命计划 3D(DLP3D)是一个开源、实时的软件框架,其核心目标是赋予大型语言模型(LLM)生动的“身体”。通过该框架,LLM可以化身为富有表现力的3D虚拟角色。用户能够通过语音与这些角色进行自然的对话,而角色则会实时生成语音回复、丰富的全身动画以及物理模拟效果,并直接在浏览器窗口中同步呈现。整个系统的自定义程度极高,用户可自由定义角色的外观(替换3D模型)与内在个性(调整角色提示词),并能灵活对接任意的大语言模型或文本转语音服务。

技术架构解析
DLP3D的整体架构主要分为三大模块,协同工作以实现流畅的交互体验。
- Web前端应用:提供直观的图形用户界面,用于自定义虚拟角色并与之互动。每个角色的配置都是完全独立的,涵盖3D模型、使用的LLM、角色提示词和语音方案。与虚拟角色的交互如同使用对讲机:按住麦克风按钮说话即可。系统采用实时流式传输技术,将角色的音频、面部表情和身体动作数据实时推送到浏览器,无需消耗大量本地计算资源。其内部实现了强大的运行时动画管道,专门用于接收、组织和播放这些流式数据,并具备自适应动作混合、连接中断恢复及网络状态评估等机制,确保了交互的即时性和稳定性。
- Orchestrator(协调器):作为整个系统的实时智能对话引擎,负责协调并驱动个性化的多模态AI交互流程。它集成了多个核心模块:自动语音识别、大语言模型调用、文本转语音、情感分析、对话记忆管理以及3D动画生成。设计上注重模块化和流式处理,支持接入多家不同的AI服务提供商,并管理从对话开始到结束的完整生命周期。作为“指挥家”,Orchestrator将分散的AI服务和算法组件无缝同步,整合为统一、连贯的用户体验。
- 后端与云服务:主要包括AI服务接口层和Web应用后端。用户可以根据偏好,为LLM、TTS和ASR选择不同的服务提供商。后端还负责运行时所需的资产管理和数据库操作,为DLP3D生态系统提供统一的API,处理用户认证、虚拟角色资源访问等核心功能。
安装部署步骤
由于部署过程涉及下载较多文件,首先提供一个参考的目录结构,以便清晰地组织所有资源。
├─docker-compose.yml
├─configs
│ └─nginx
│ └─nginx.conf
├─data
│ ├─motion_database.db
│ ├─blendshapes_meta
│ ├─joints_meta
│ ├─mesh_glb
│ ├─motion_files
│ ├─restpose_npz
│ └─rigids_meta
└─weights
└─unitalker_v0.4.0_base.onnx
- 获取基础配置文件:访问项目地址(github.com/dlp3d-ai/dlp3d.ai),下载整个仓库或仅下载所需的
nginx.conf配置文件。然后,按照上述结构手动创建对应的文件夹。
提示:nginx.conf 文件内容负责配置反向代理和HTTPS,示例如下:
# ================== web_frontend HTTPS 18000 -> 3000 ==================
server {
listen 18000 ssl http2;
listen [::]:18000 ssl http2;
server_name localhost;
ssl_certificate /etc/ssl/localcerts/localhost.pem;
ssl_certificate_key /etc/ssl/localcerts/localhost-key.pem;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_pass http://web_frontend:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
# ================== web_backend HTTPS 18001 -> 18080 ==================
server {
listen 18001 ssl http2;
listen [::]:18001 ssl http2;
server_name localhost;
ssl_certificate /etc/ssl/localcerts/localhost.pem;
ssl_certificate_key /etc/ssl/localcerts/localhost-key.pem;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_pass http://web_backend:18080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
# ================== HTTPS 18002 -> 18081 ==================
server {
listen 18002 ssl http2;
listen [::]:18002 ssl http2;
server_name localhost;
ssl_certificate /etc/ssl/localcerts/localhost.pem;
ssl_certificate_key /etc/ssl/localcerts/localhost-key.pem;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_pass http://orchestrator:18081;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
- 下载 Docker 编排文件:同时,需要下载
docker-compose.yml文件,该文件定义了所有服务容器及其配置。
提示:docker-compose.yml 文件内容定义了 speech2motion、audio2face、mongodb、web_backend、orchestrator、web_frontend 和 nginx 等多个服务,并配置了它们之间的网络、卷挂载和健康检查。
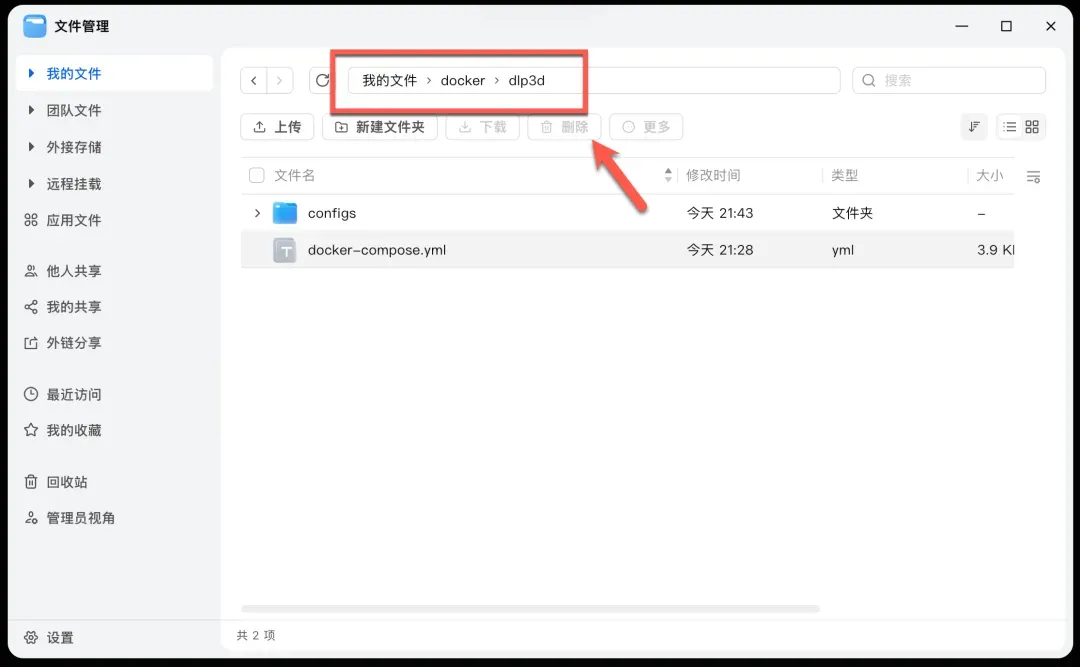
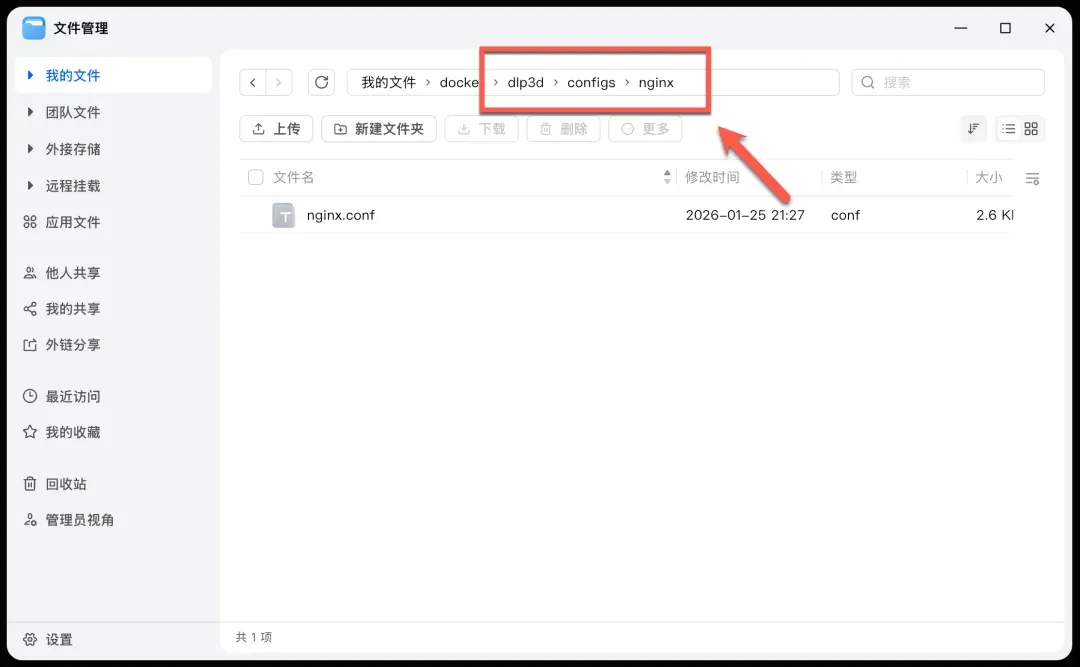
- 组织项目目录:创建一个项目根文件夹,将下载好的
nginx.conf和docker-compose.yml文件放入其中。请确保nginx.conf文件被放置在正确的子目录下:./configs/nginx/。
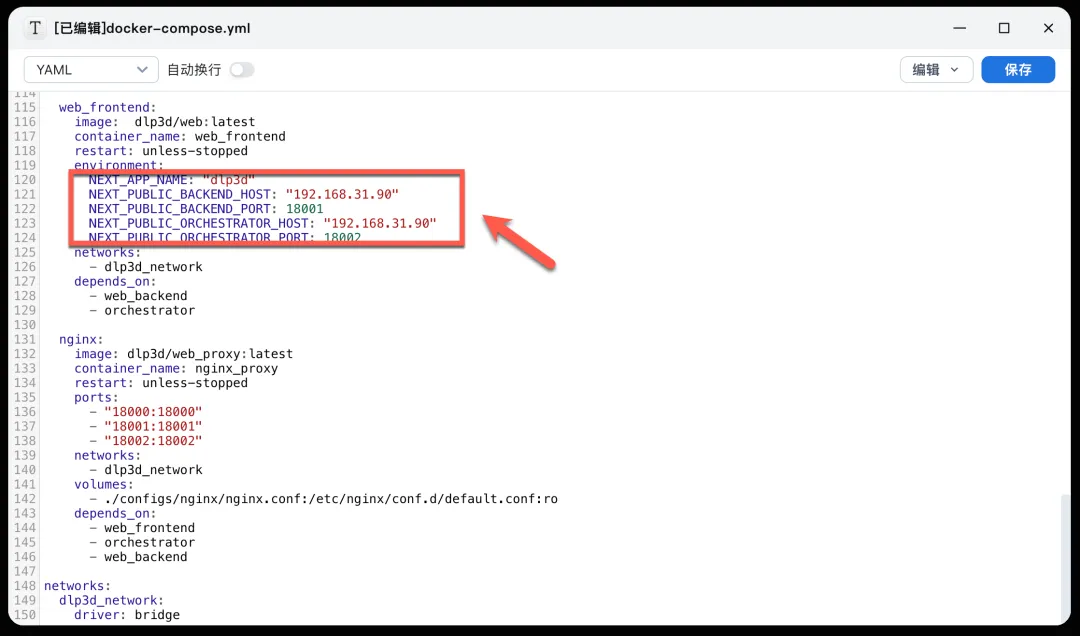
- 修改关键配置:使用文本编辑器打开
docker-compose.yml文件,找到web_frontend服务下的环境变量NEXT_PUBLIC_BACKEND_HOST和NEXT_PUBLIC_ORCHESTRATOR_HOST。将它们的值从”127.0.0.1″修改为你当前NAS或部署主机的实际IP地址,以确保前端能正确连接到后端服务。
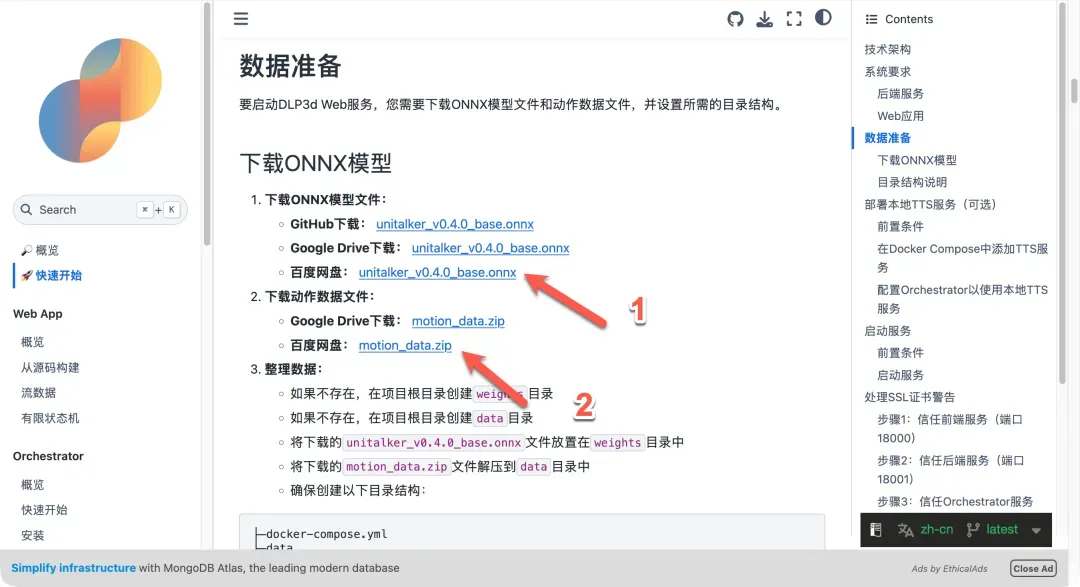
- 下载模型与数据文件:访问DLP3D官方文档的数据准备页面(https://dlp3d.readthedocs.io/zh-cn/latest/getting_started/quick_start.html#md-data-preparation),根据指引下载必需的ONNX模型文件(
unitalker_v0.4.0_base.onnx)和动作数据文件包。
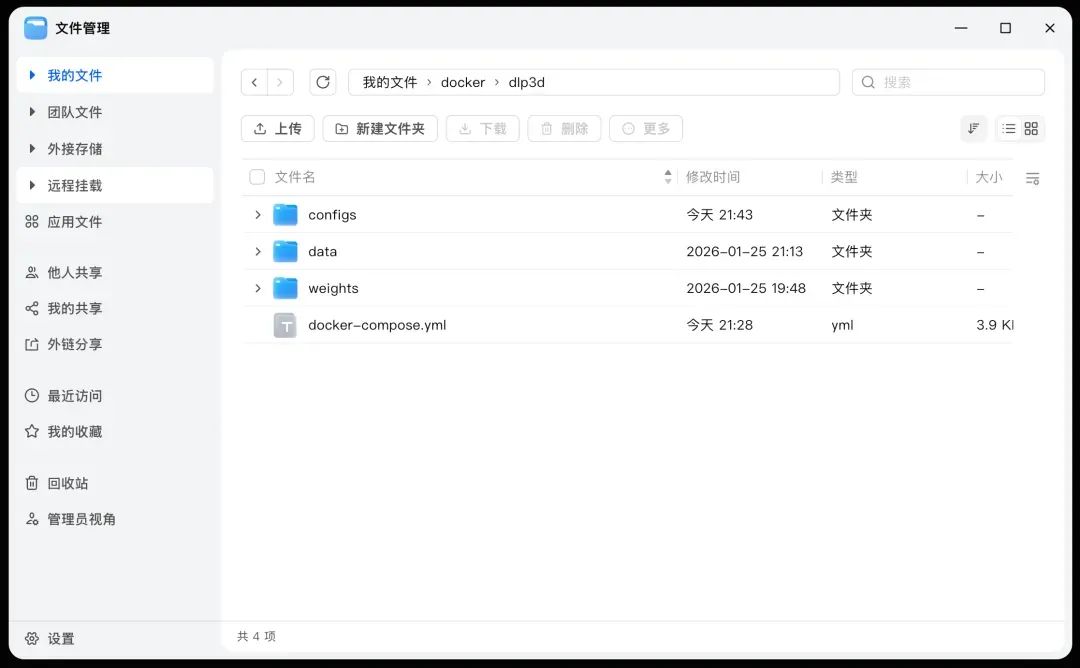
- 放置模型与数据:将下载的ONNX模型文件放入
./weights/目录,并将解压后的动作数据文件分别放入./data/目录下对应的子文件夹中,最终形成与第一步给出的参考结构完全一致的目录树。
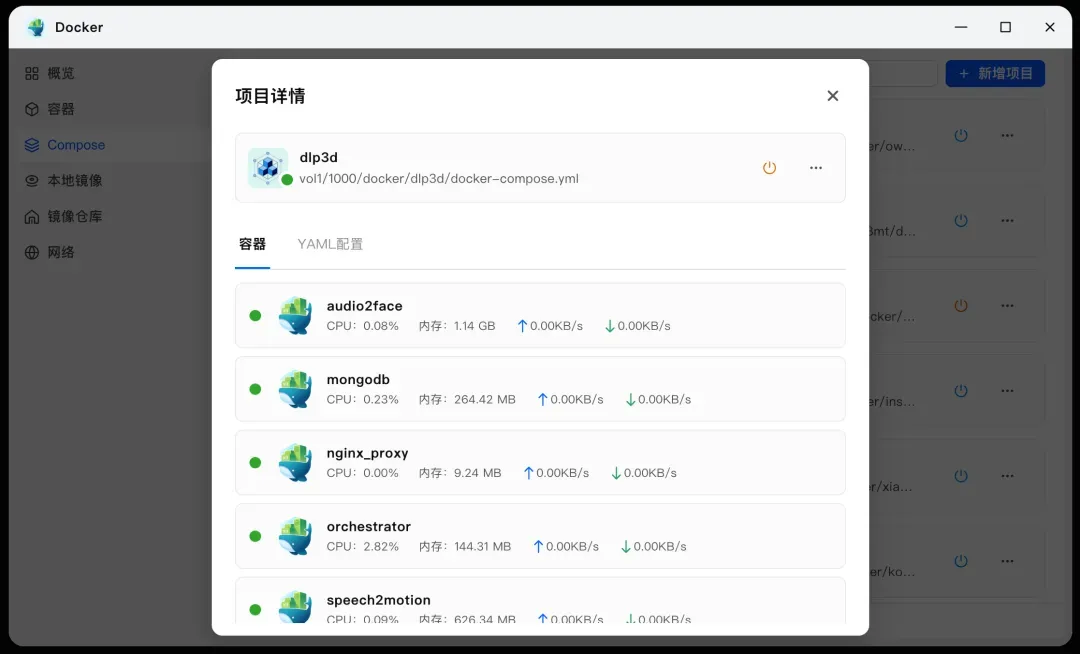
- 启动服务:在项目根目录(包含
docker-compose.yml的目录)下打开终端,执行命令docker-compose up -d。等待所有容器成功拉取镜像并启动后,使用docker-compose ps命令检查所有服务状态应为“运行中”。
使用与配置指南
服务启动后,在浏览器地址栏输入 https://你的NAS_IP:18000 即可访问DLP3D的Web界面。请注意,必须使用HTTPS协议。
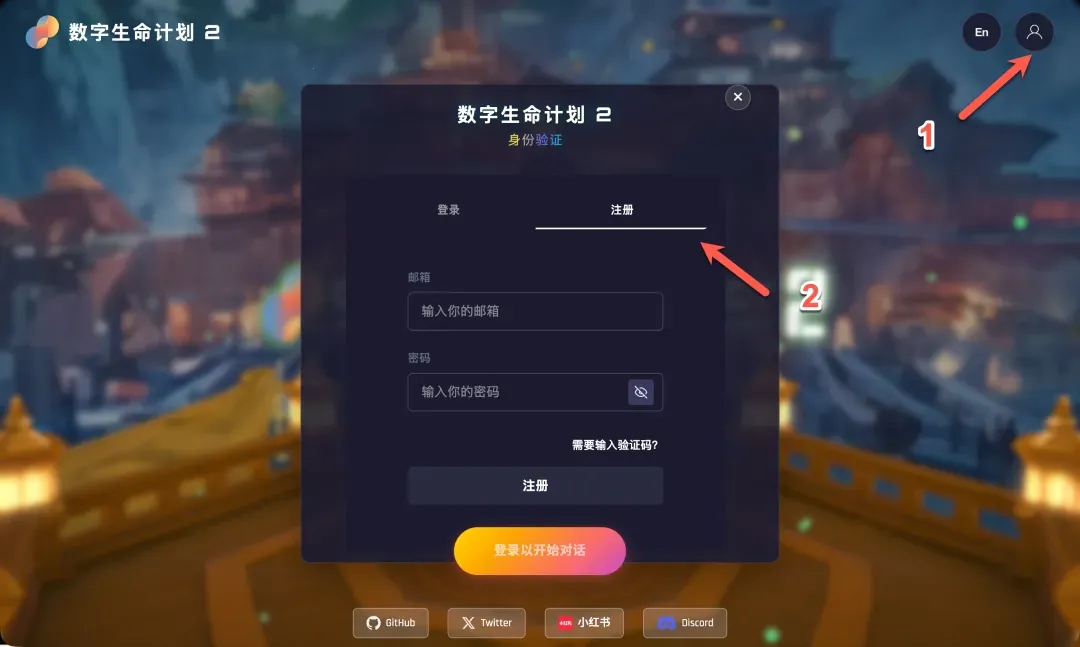
首次使用需要注册一个新账号,完成注册后使用该账号登录即可。(部分浏览器如Safari可能存在兼容性问题,建议使用Chrome或Edge)。
登录成功后进入主控制面板,整体界面布局清晰,核心功能在于配置AI服务的API,这部分会稍显繁琐。
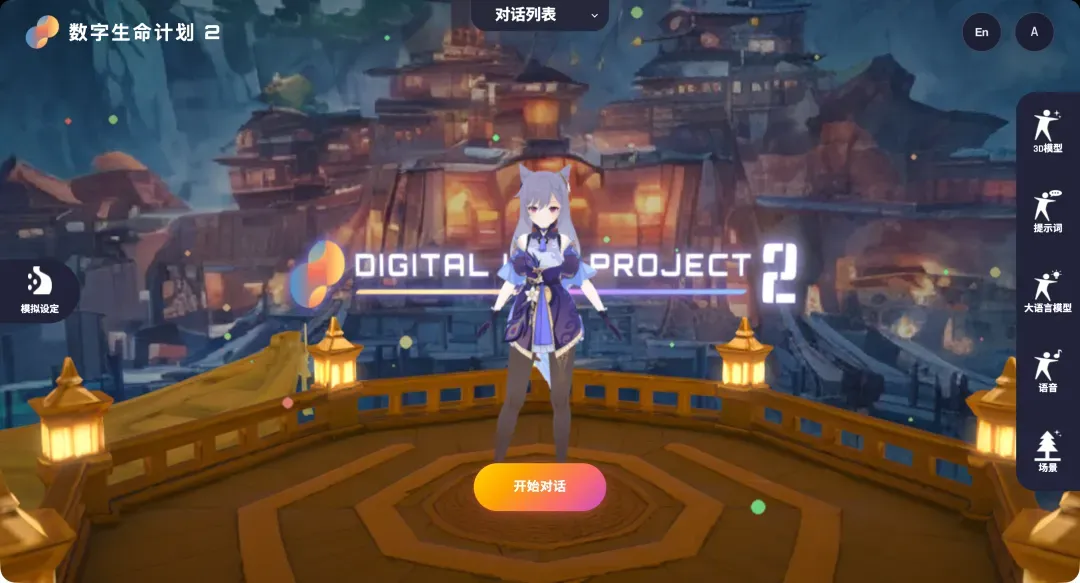
核心功能介绍与配置
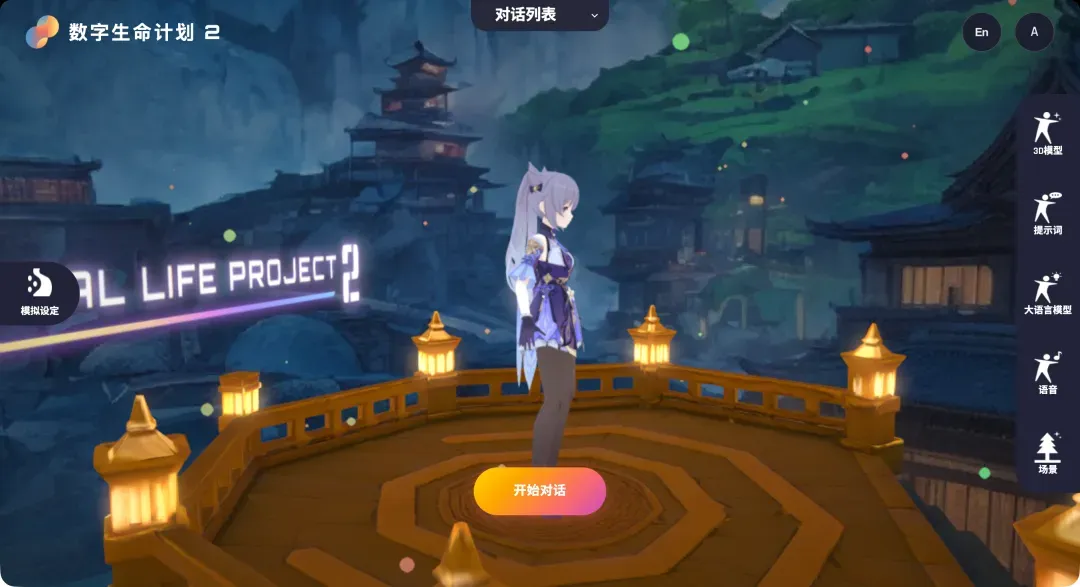
- 3D场景交互:在角色展示界面,按住鼠标左键并拖动可以360度旋转视角,全方位观察3D虚拟角色的细节。相较于Live2D等2D模型,3D模型在视觉维度和细节呈现上拥有显著优势。
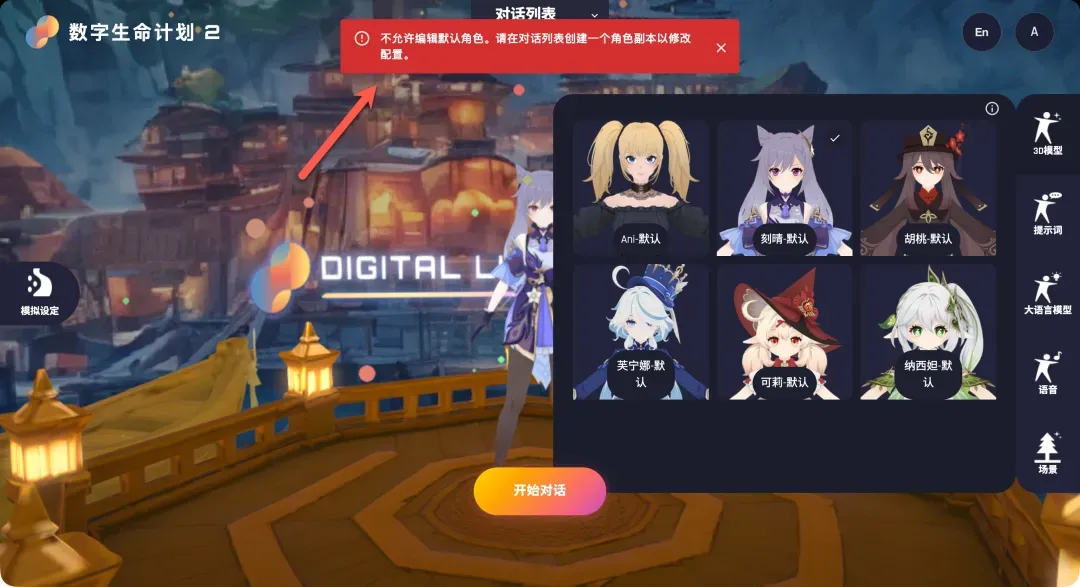
- 角色管理:点击顶部的“对话列表”,可以查看并切换不同的虚拟角色。系统默认提供几个预设角色,每个角色绑定了固定的模型、提示词、LLM和语音。若要创建个性化角色,需要基于现有角色复制并修改。
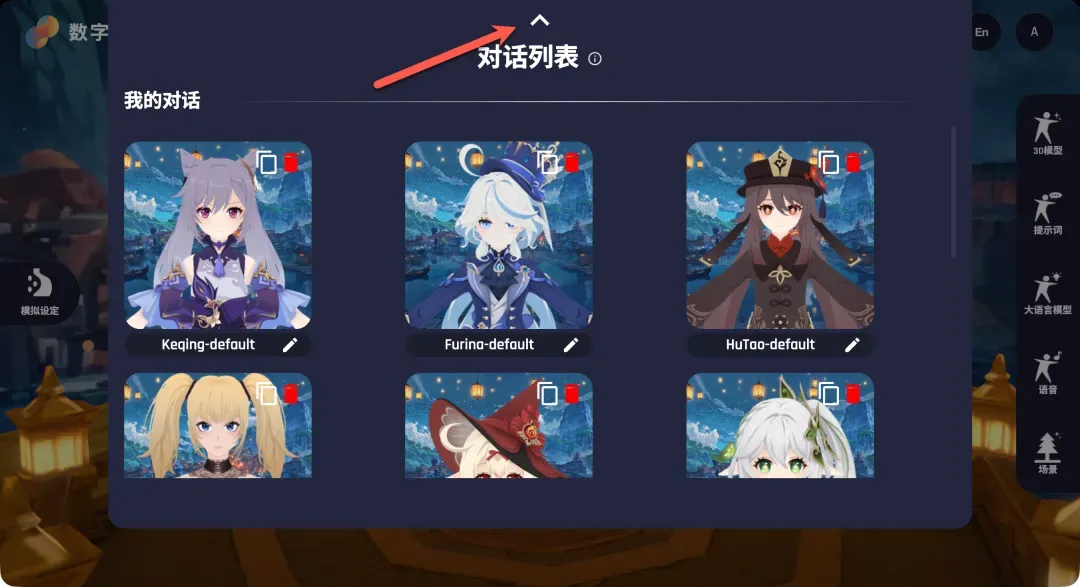
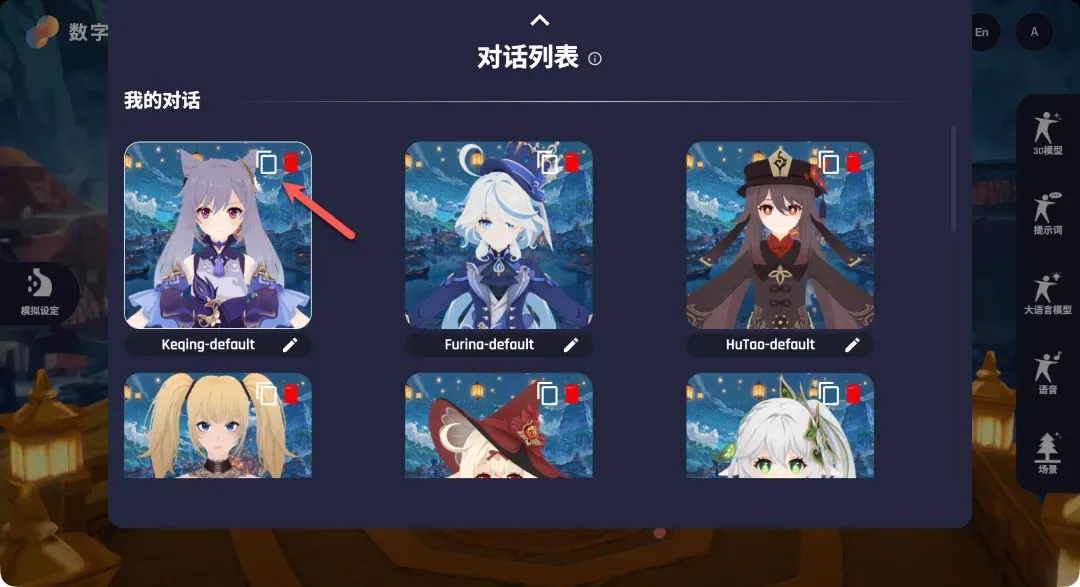
点击角色卡片上的“复制”按钮即可创建副本,新创建的角色会出现在列表底部,建议立即修改名称以便区分。

- 模型与场景:系统内置了6个不同风格的3D角色模型,精度和质感都相当不错。例如,之前广受欢迎的Grok虚拟角色Ani也在其中,不同角色出场会伴随不同的待机动作。用户也可以为角色切换不同的虚拟场景背景。
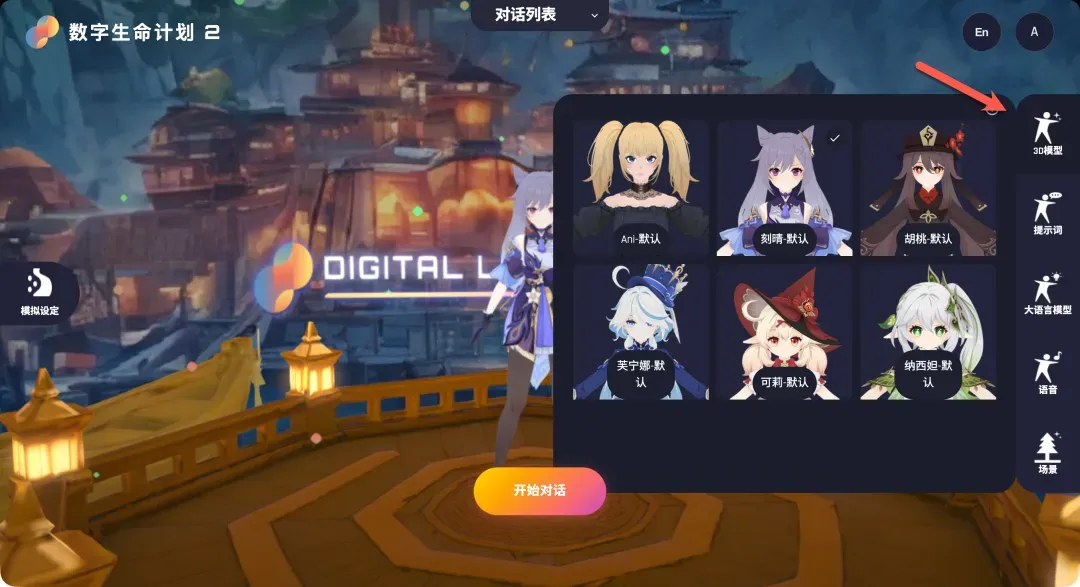

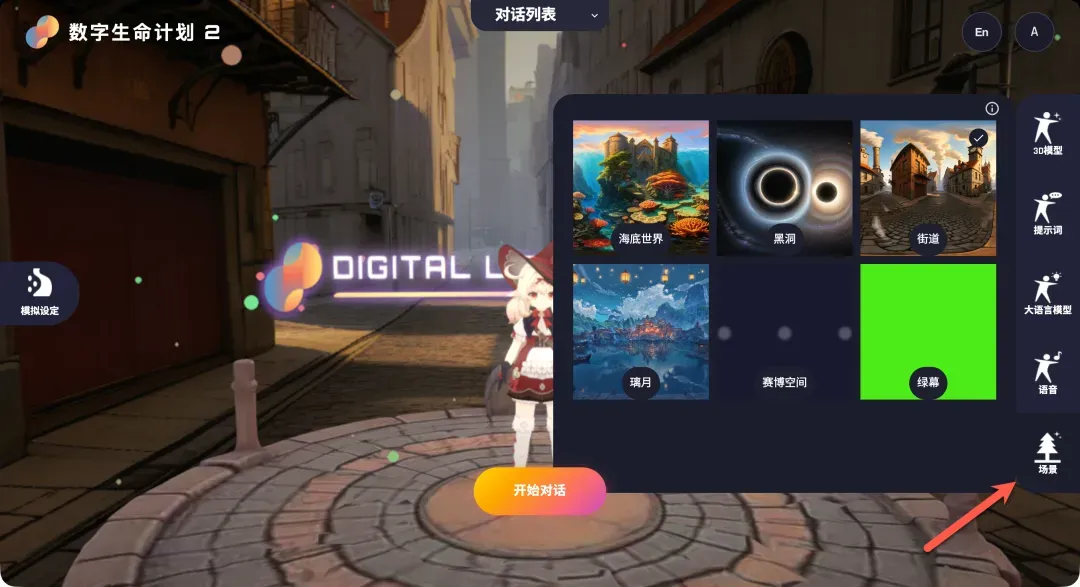
接下来是让虚拟角色“活”起来的关键步骤:配置AI服务的API。这主要分为大语言模型和语音服务两大部分。
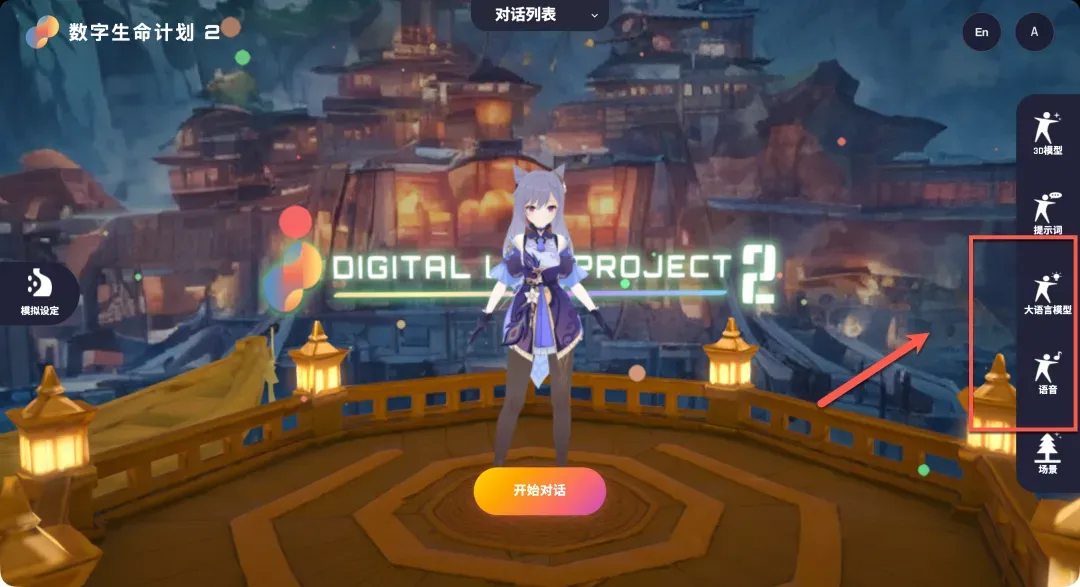
配置大语言模型(LLM)
对于国内用户,可选的LLM提供商相对有限。这里以DeepSeek为例演示对接流程。
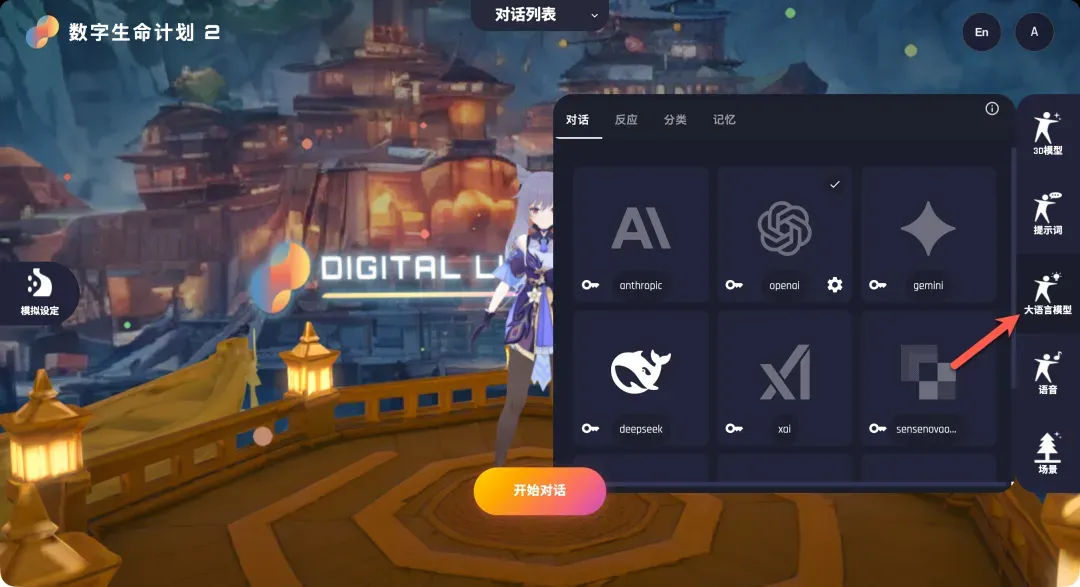
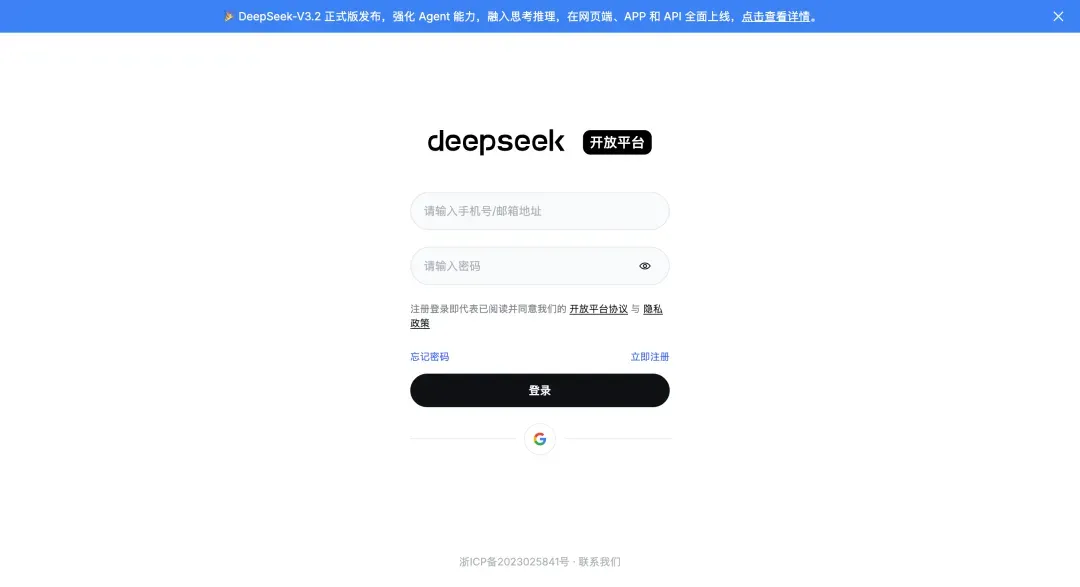
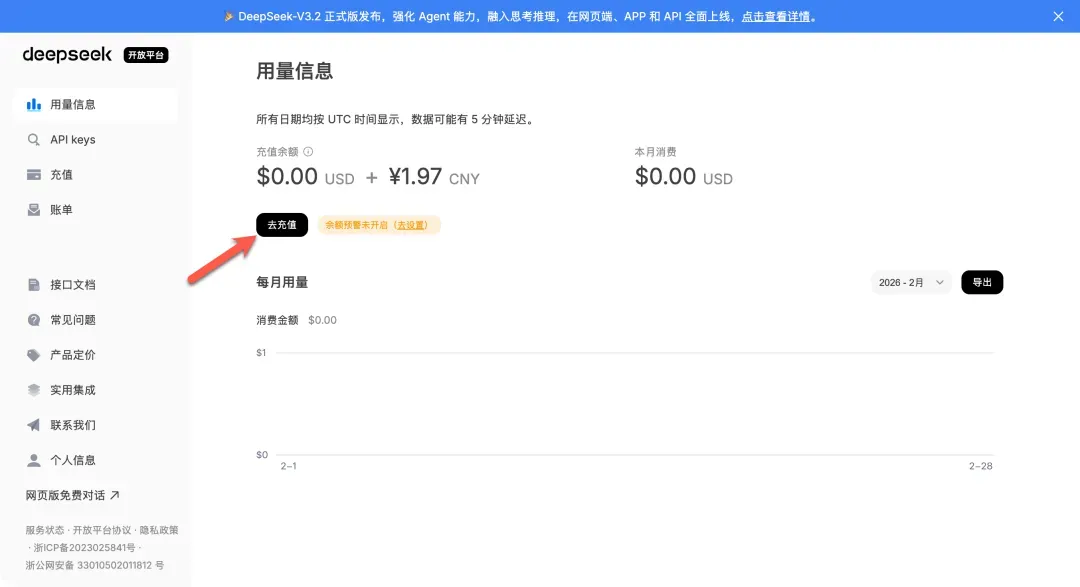
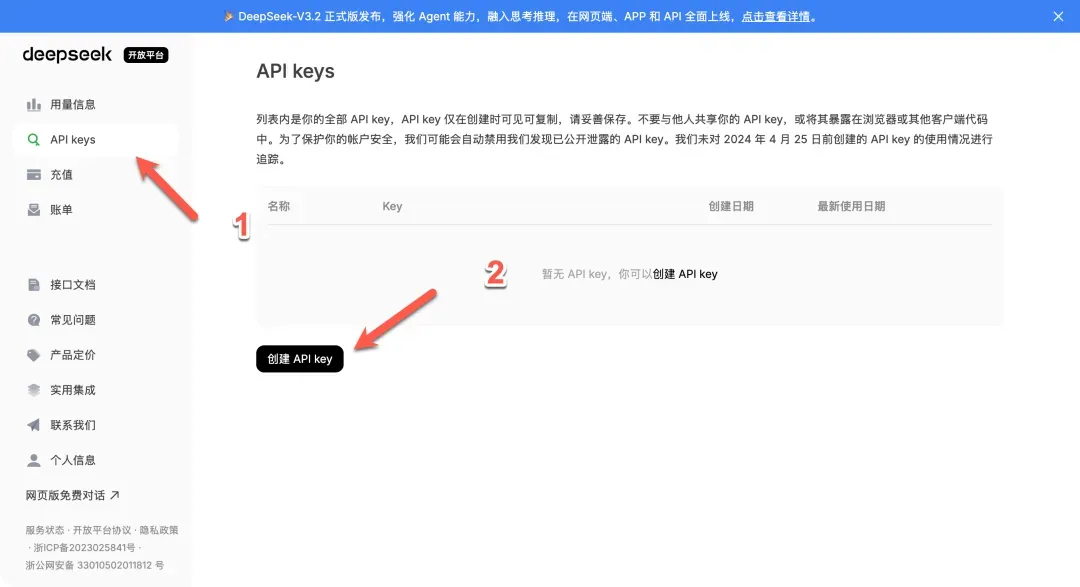
- 获取API Key:访问DeepSeek开放平台(platform.deepseek.com)注册/登录。进入后,需要在账户中充值少量余额(例如1元)以激活API调用。随后,在“API密钥”管理页面创建一个新的密钥,并妥善保存。
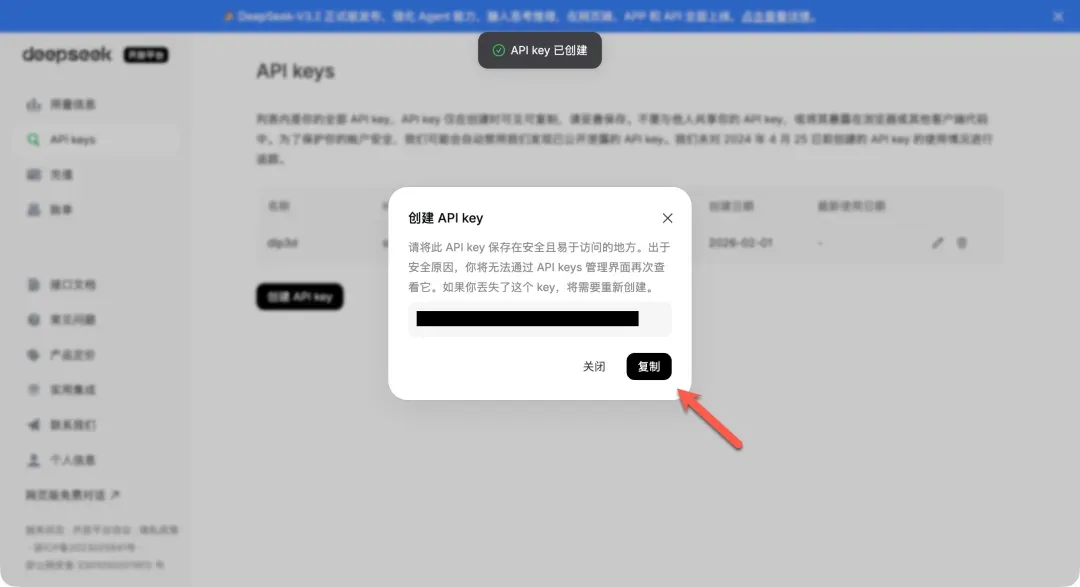
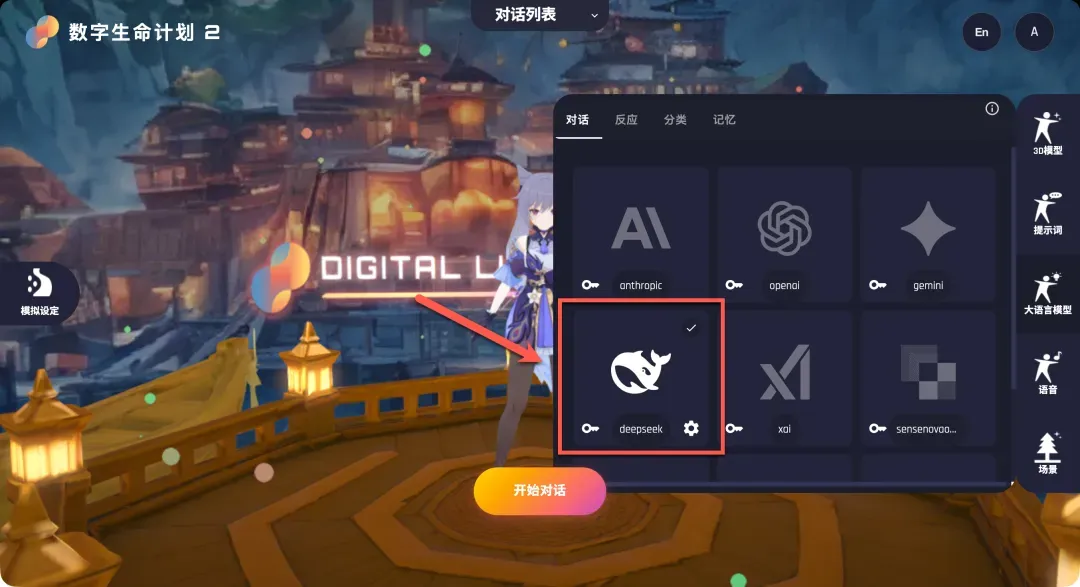
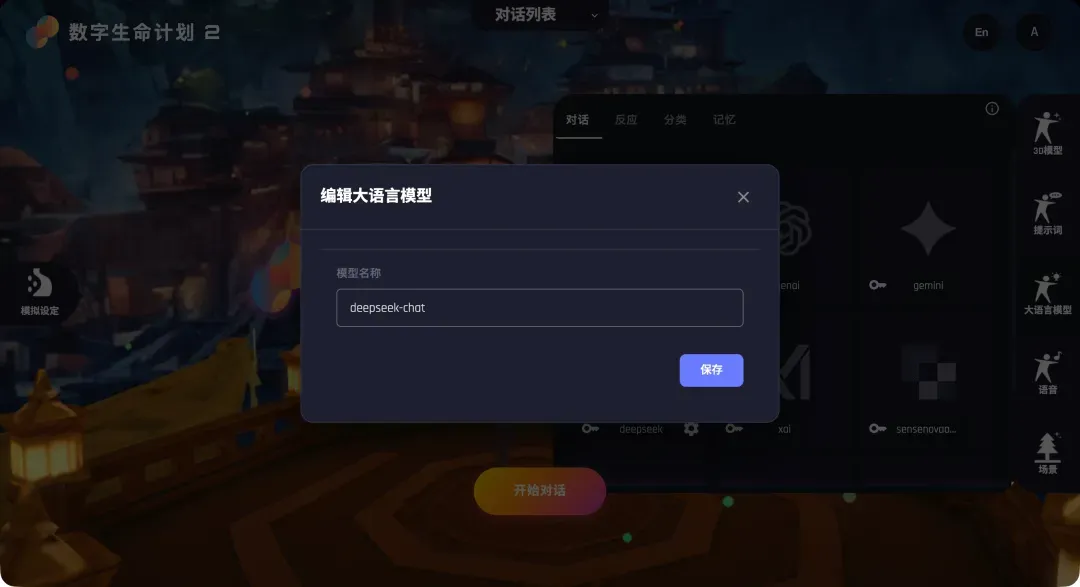
- 在DLP3D中配置:回到DLP3D的LLM配置页面,点击DeepSeek选项旁的“钥匙”图标,在弹出的对话框中填入刚才复制的API密钥。
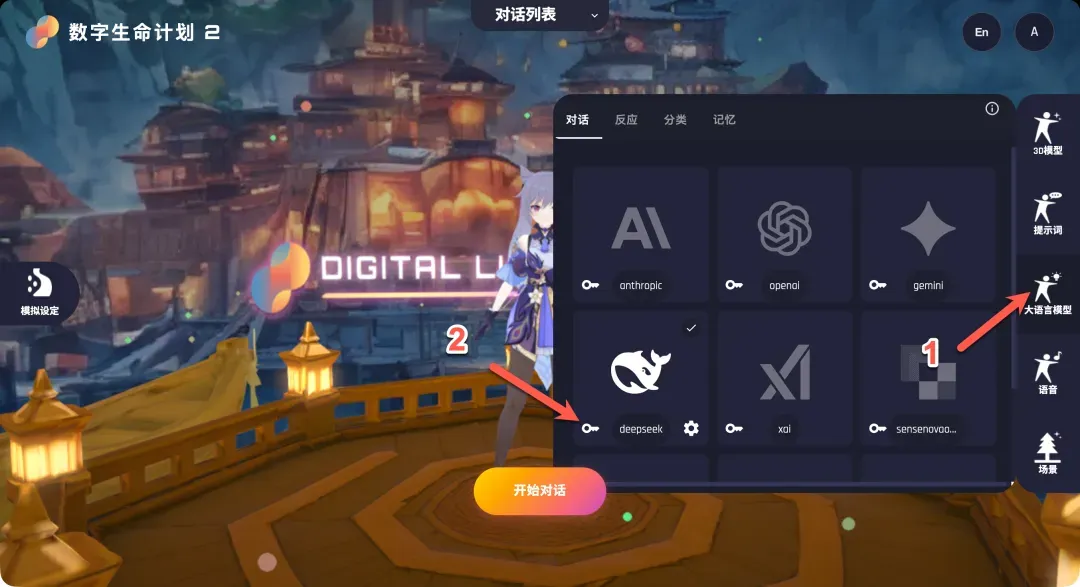
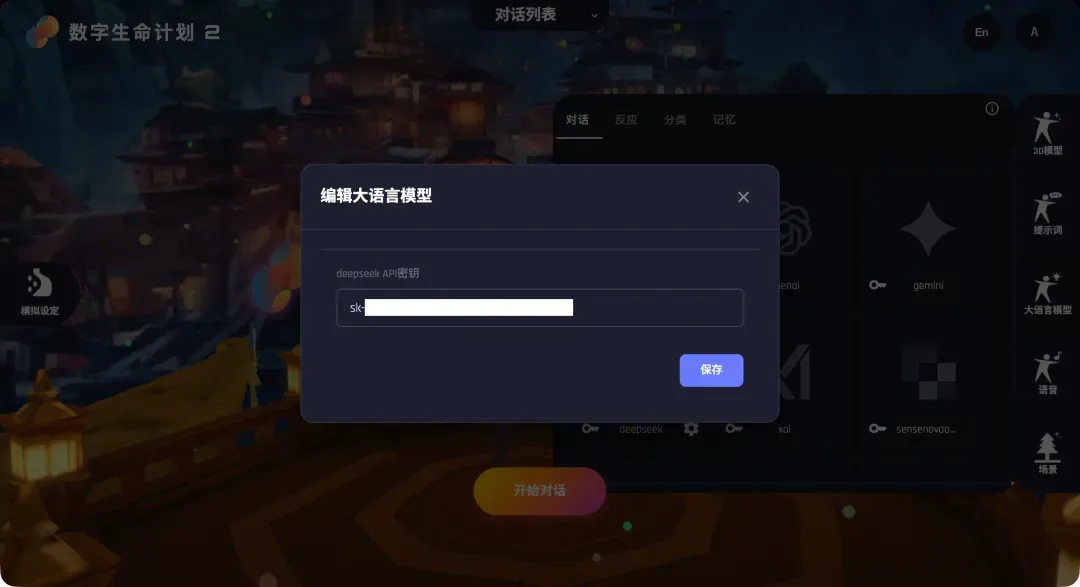
- 指定模型:点击下方的“设置”按钮,在弹出的模型名称输入框中填写DeepSeek对应的模型名,例如“deepseek-chat”。保存后,点击DeepSeek卡片,右上角出现勾选标记即表示配置成功。
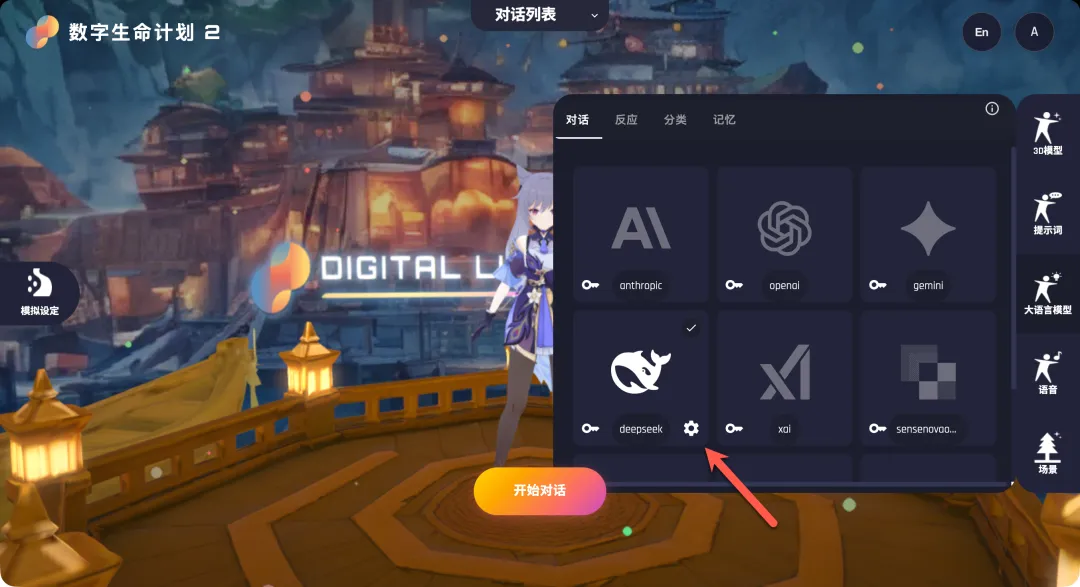
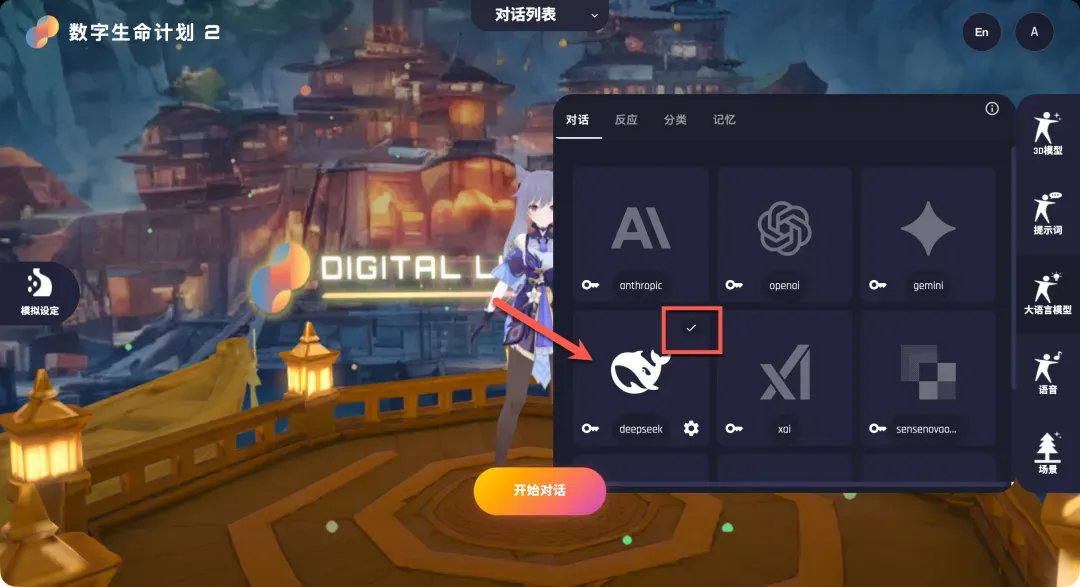
配置其他LLM相关选项(如情感分析、关键词提取等)时,重复此过程,选择DeepSeek并填写对应模型名即可。
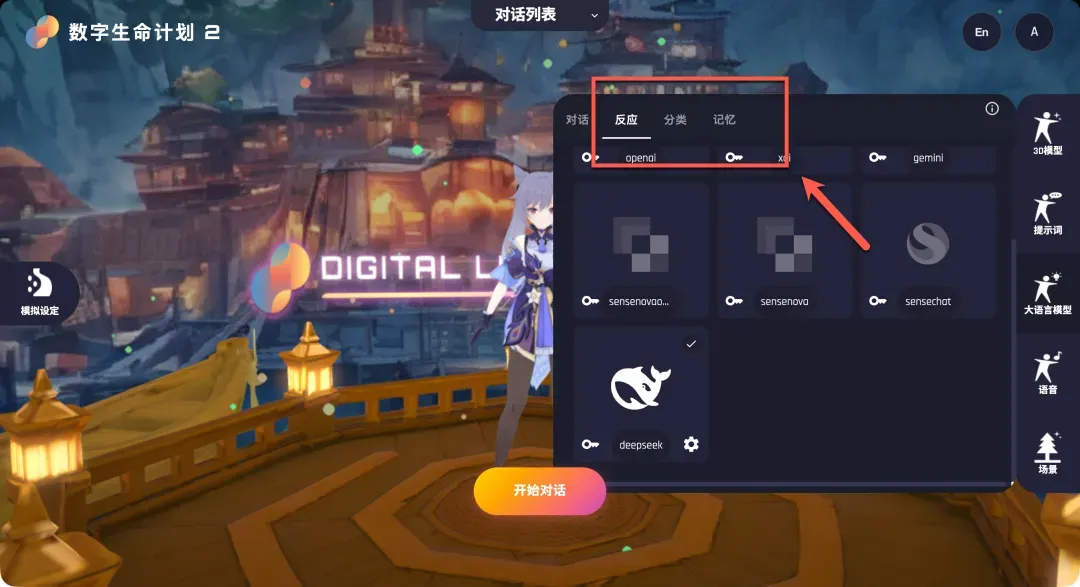
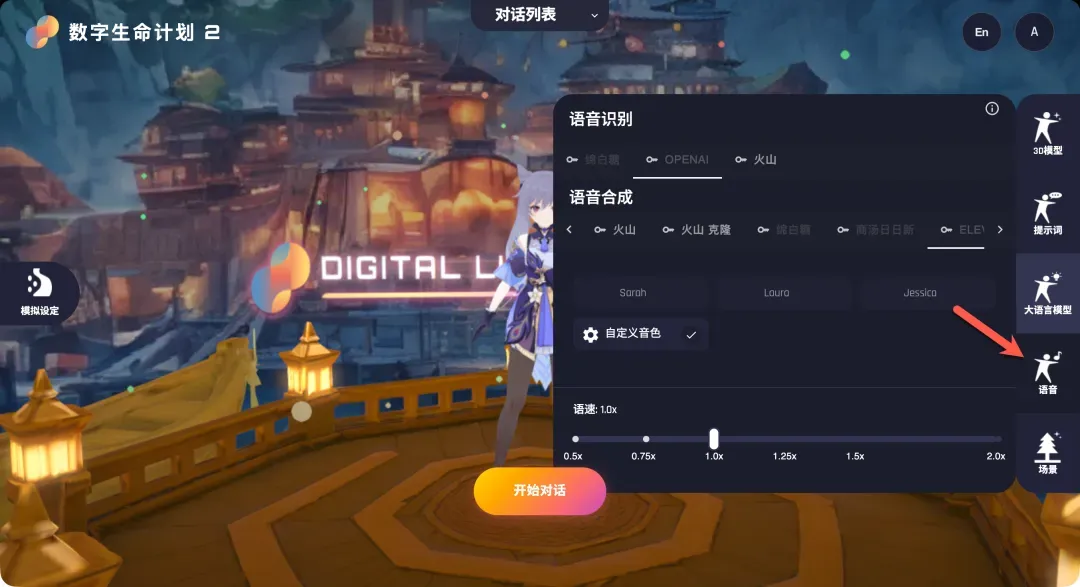
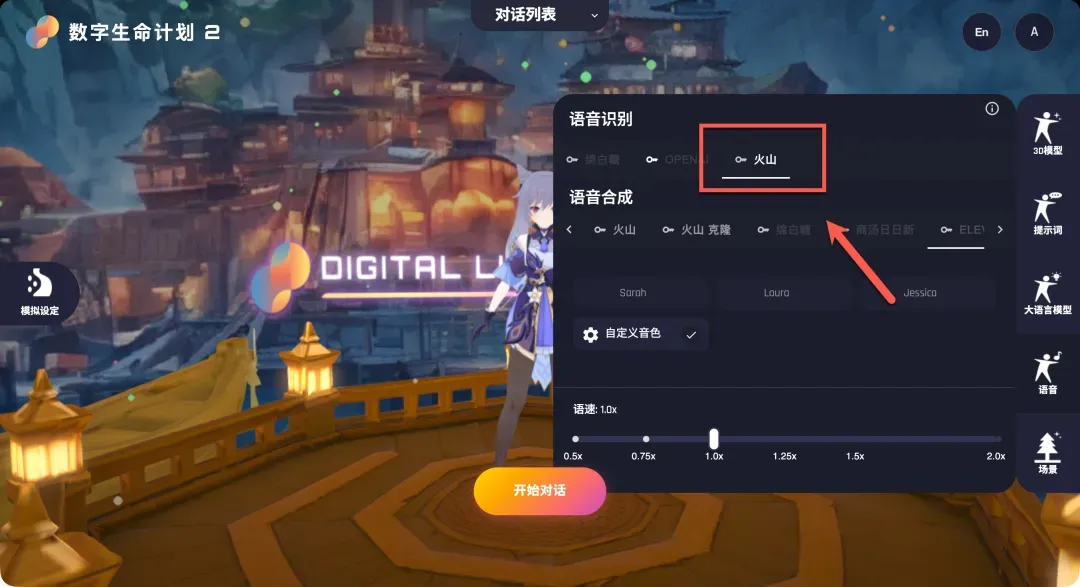
配置语音服务(ASR & TTS)
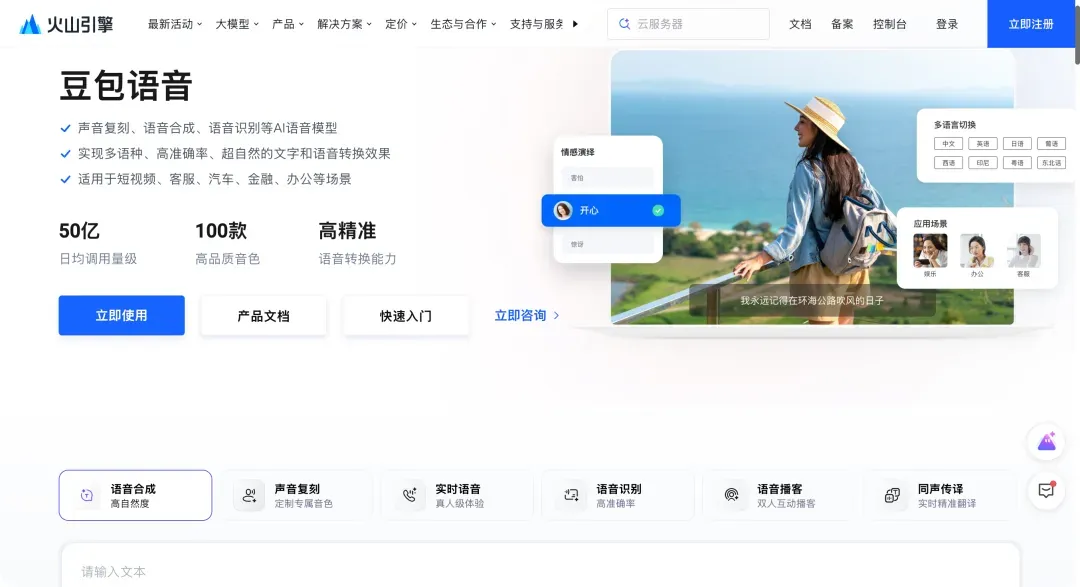
语音服务包含语音识别和语音合成两部分。此处以火山引擎的豆包语音服务为例。
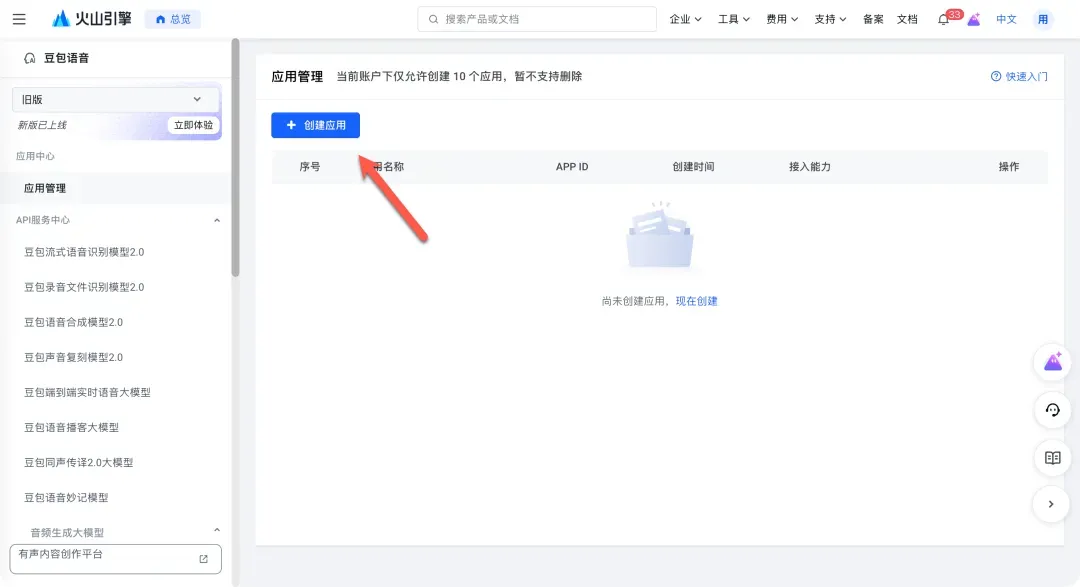
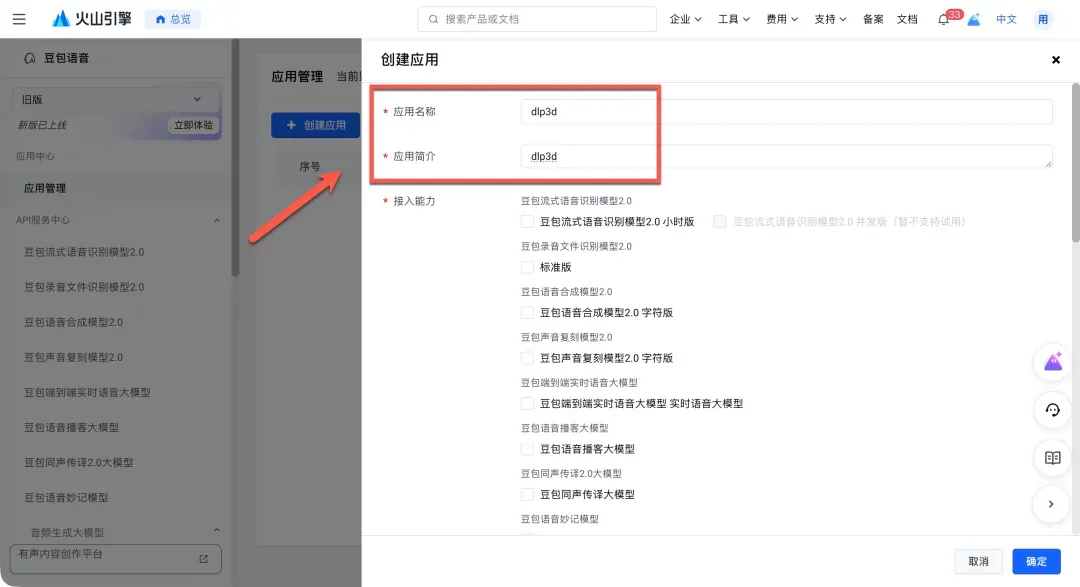
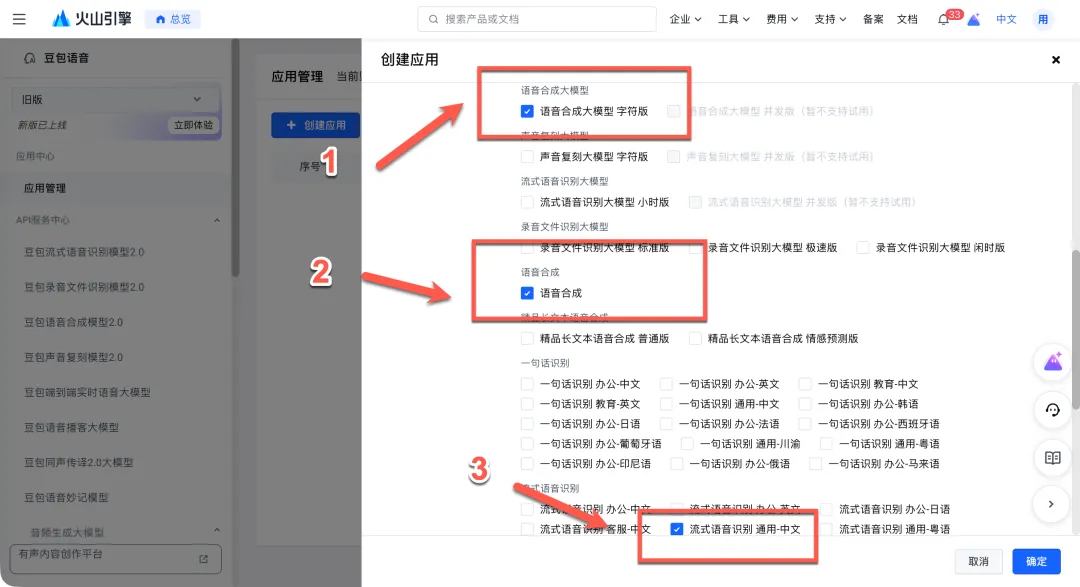
- 创建火山引擎应用:访问火山引擎语音技术产品页(https://www.volcengine.com/product/voice-tech)并注册登录。进入控制台(https://console.volcengine.com/speech),点击“创建应用”,填写应用名称和简介。
- 选择服务能力:在创建过程中,需要勾选以下三项服务能力以支持DLP3D的全部语音功能:
语音合成大模型:语音合成大模型 字符版语音合成:语音合成流式语音识别:流式语音识别 通用-中文新用户通常会获得一定的免费额度。
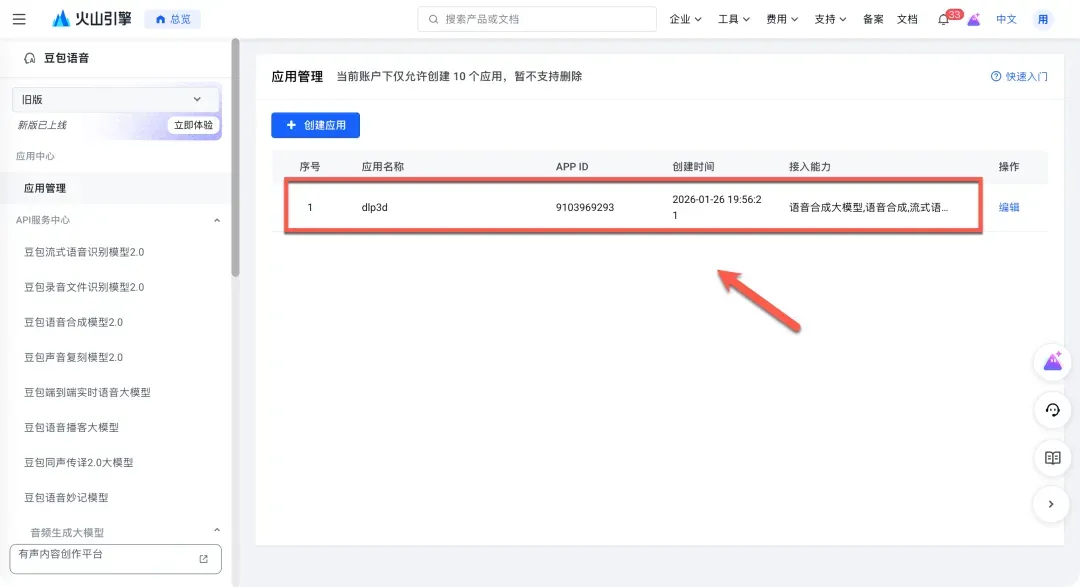
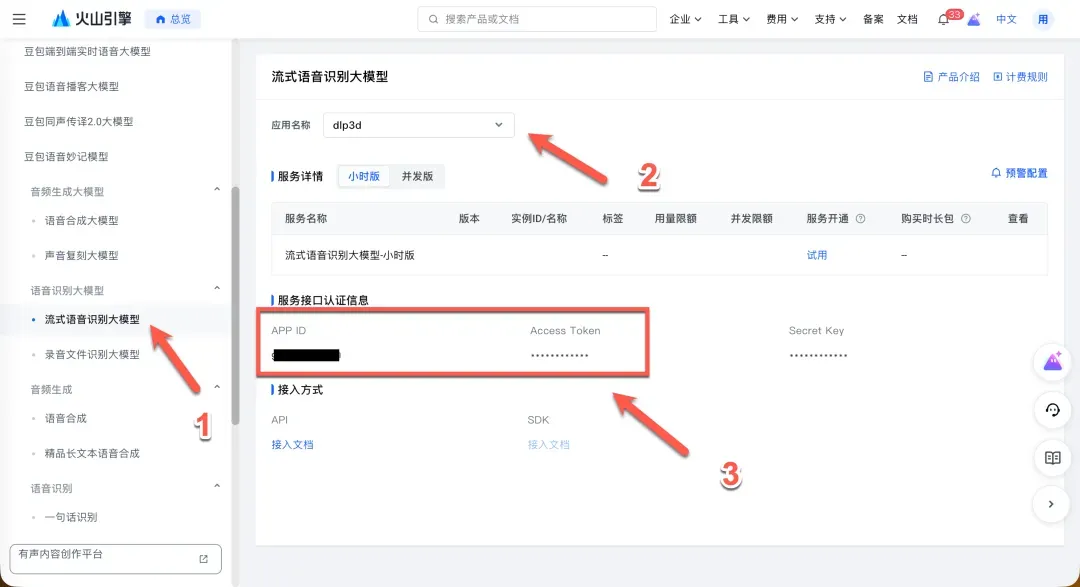
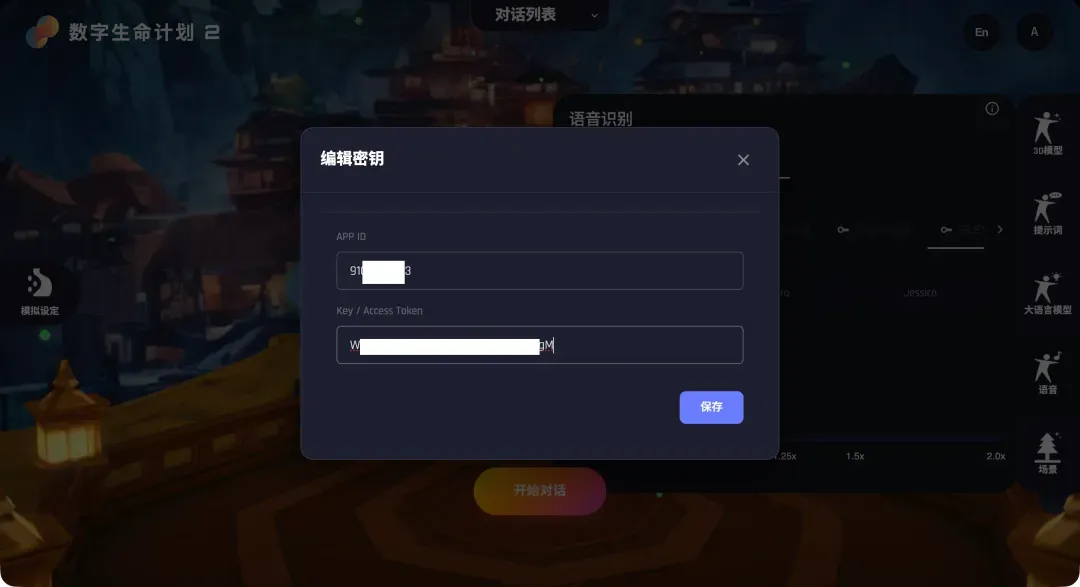
- 获取密钥:应用创建成功后,在控制台左侧导航栏进入“流式语音识别大模型”或“语音合成大模型”页面,选择你刚创建的应用,即可查看到所需的
APP ID和Access Token。
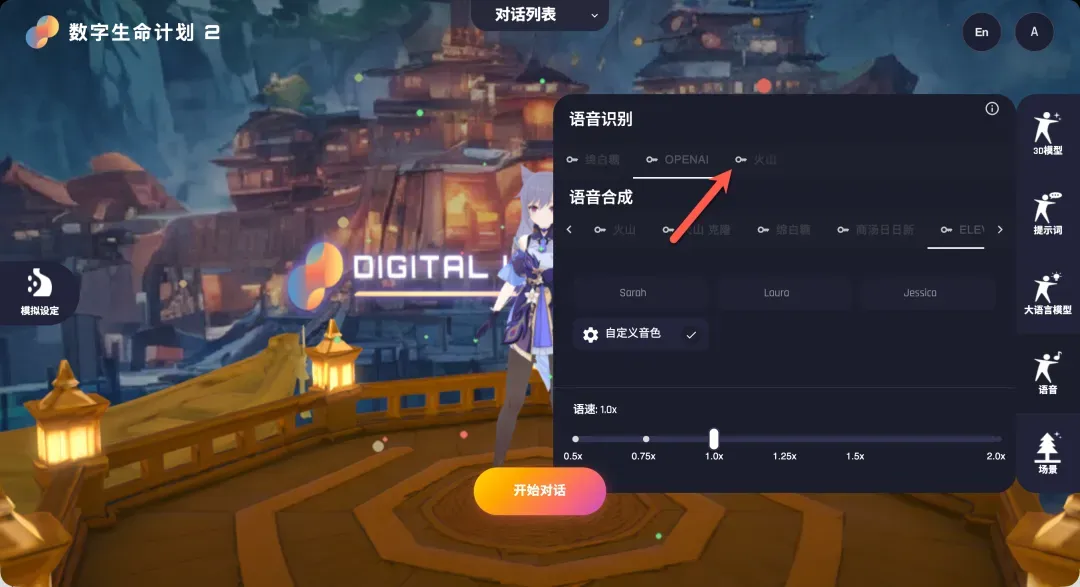
- 在DLP3D中配置:
- 语音识别:点击“火山”选项旁的“钥匙”图标,将火山引擎控制台中获取的
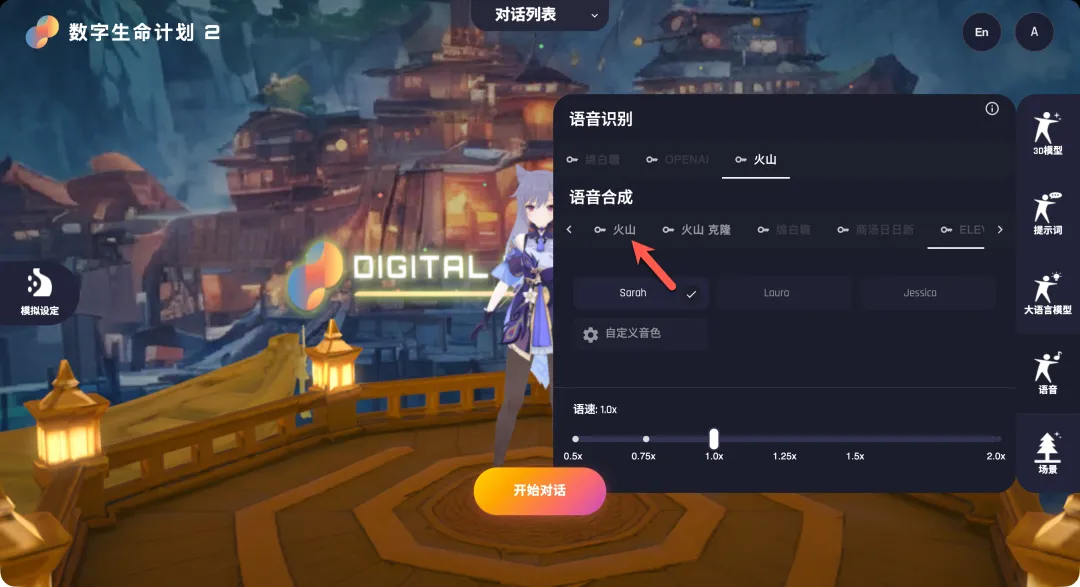
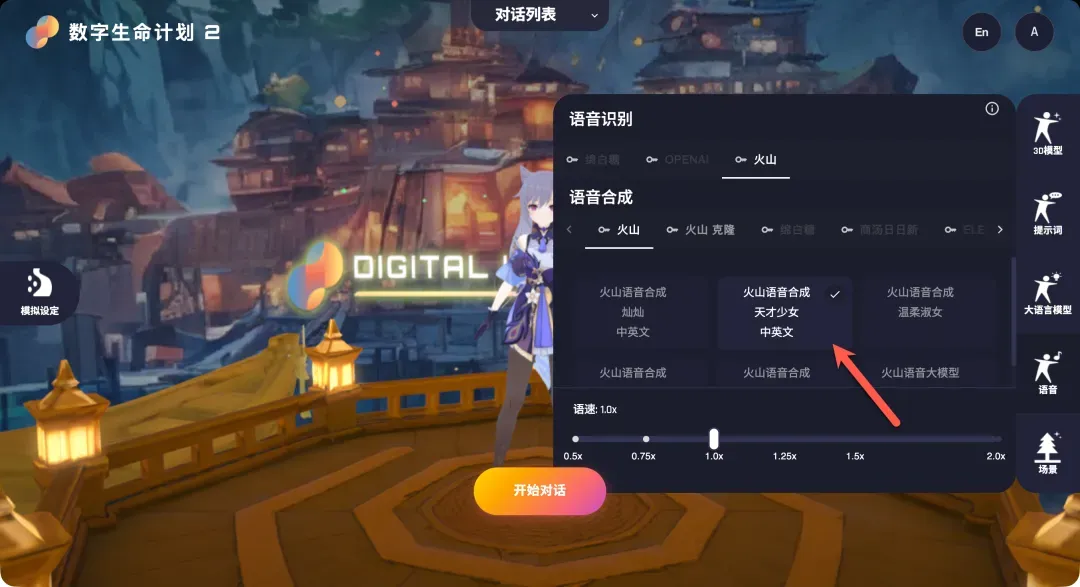
APP ID和Access Token分别填入对应字段。 - 语音合成:点击“火山”选项下方的“设置”按钮(密钥通常与识别服务共享,已填写则无需重复),在弹出的界面中选择你喜欢的合成音色。
- 语音识别:点击“火山”选项旁的“钥匙”图标,将火山引擎控制台中获取的
开始对话体验
完成所有API配置后,返回主界面,系统会开始初始化当前角色并连接所有服务。

加载过程可能需要几秒钟时间(如果LLM服务未充值,可能会一直卡在此处)。

重要提示:对话功能需要浏览器授予网页麦克风访问权限。如果出现权限提示,请点击“允许”。若已授权但仍无法使用,可以尝试在浏览器设置中关闭后再重新打开对该站点的麦克风权限。

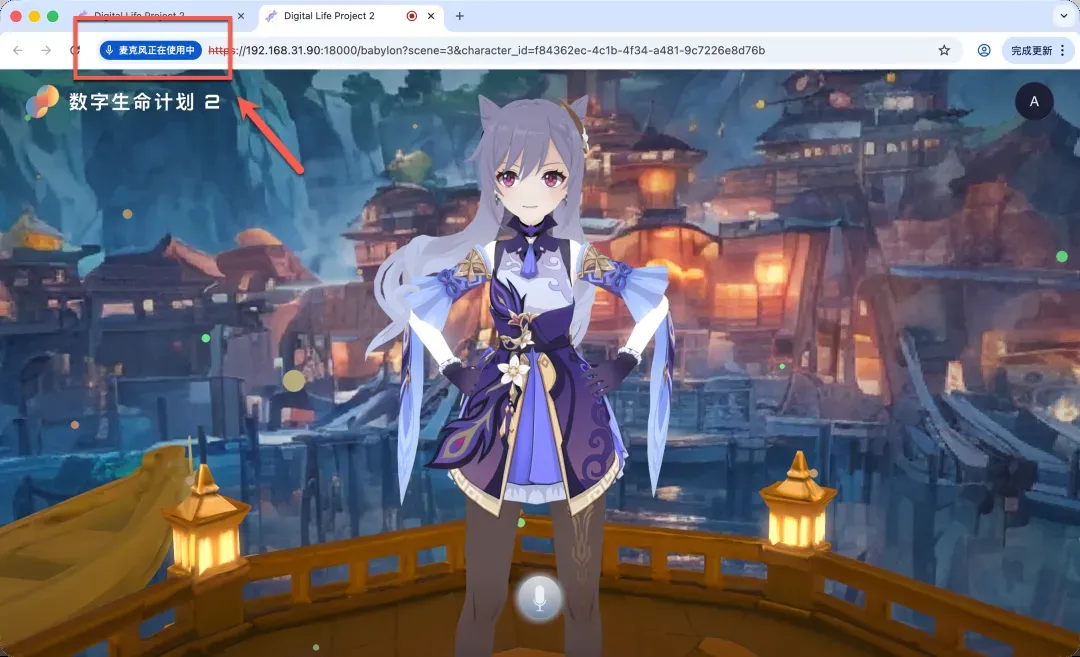
一切就绪后,界面会显示“正常使用中”。此时,长按中央的麦克风按钮开始说话,松开后系统便会处理你的语音,虚拟角色将生成带有口型动画和肢体动作的语音回复。虽然存在一定的响应延迟,但整体交互感已经形成。界面左侧还会显示一个有趣的“好感度”指示器,为对话增添了一些游戏化元素。



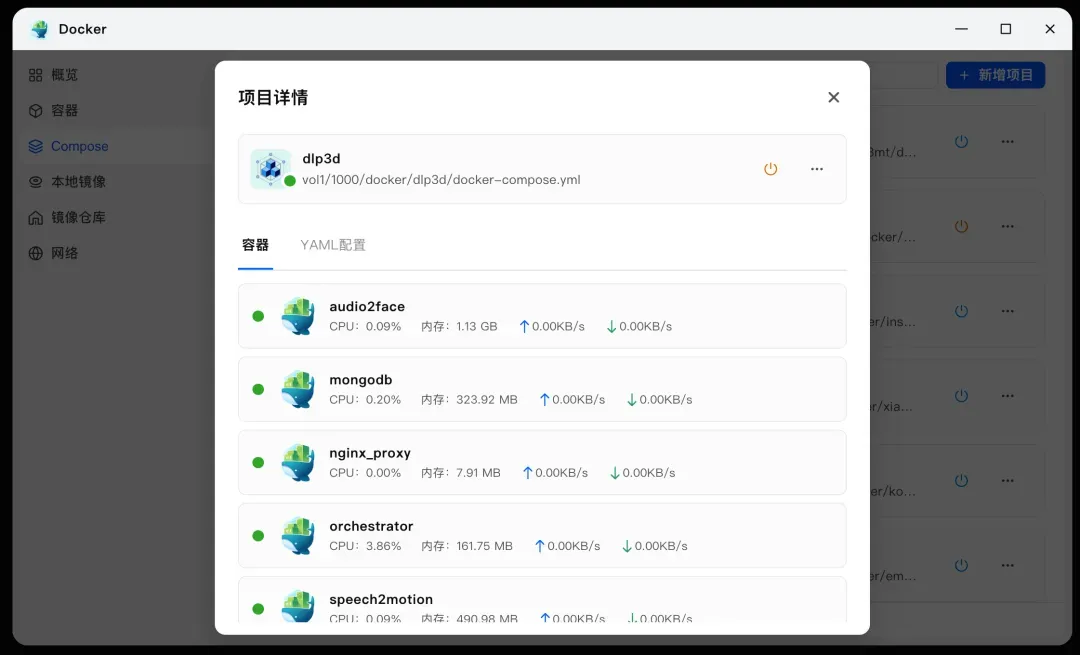
需要注意的是,由于DLP3D由多个Docker容器组成,其对宿主机的内存资源有一定要求,部署前请确保设备有足够的内存余量。
体验总结
人工智能技术的飞速发展,使得个性化AI伴侣逐渐成为未来数字生活的一个可预见趋势。想象一下,拥有一位贴心的私人AI助手,不仅能在闲暇时进行对话交流,还能协助规划日程、提升工作效率。市场上虽已出现不少成熟的商业应用,但其不开源、无法本地部署的特性,总让人在数据隐私和控制权上有所顾虑。
DLP3D数字生命计划,是目前为止我体验过的完成度最高的开源3D虚拟角色解决方案。很早之前就有关注,但因缺乏详尽的部署教程而搁置。直到仔细研读官方文档后,才得以成功部署。实际体验令人满意:打开网页即可与3D角色进行语音对话,并且伴有基础的动作和口型同步。坦白说,我的初始预期较高,而DLP3D在核心功能上基本达到了预期效果。
当然,项目目前仍处于发展阶段,存在一些可改进之处。例如,对国内模型提供商的支持范围可以更广,并增加对第三方标准OpenAI接口的兼容;用户尚不能便捷地自定义上传3D模型和场景;角色姿态和动作的高级自定义编辑界面也有待丰富。尽管如此,DLP3D已经展现出了巨大的潜力,为开发者和爱好者提供了一个绝佳的起点。强烈推荐对AI、虚拟角色或具身智能感兴趣的朋友亲自部署尝试,探索属于自己的“数字生命”。
综合推荐:⭐⭐⭐⭐(免费开源,交互式3D虚拟角色) 使用体验:⭐⭐⭐⭐(完成度高,配置逻辑清晰) 部署难度:⭐⭐⭐(需要一定技术基础,但文档指引明确)