阿里通义Wan团队发布实时视频对话模型Wan-Streamer:端到端全双工,AI真的能看见你
阿里通义Wan团队正式发布了Wan-Streamer v0.1,一个端到端的实时音视频交互基础模型。它完全抛弃了ASR、LLM、TTS与数字人模块的拼装思路,转而让一个Transformer同时承担文本、音频和视频的输入输出。模型侧延迟控制在200毫秒,全链路交互延迟约550毫秒,实时输出达25fps,首次在单一模型中实现了亚秒级、全双工的视频通话体验。
6月23日,团队在arXiv公开论文并上线演示站点,随即在海外科技社区引起震动。Min Choi的一条推文“我们完了,阿里刚刚展示了Wan-Streamer。AI智能体现在能看到你、听到你,并实时用视频回复你。这已经不只是语音模式了”获得了超24万次浏览,评论区反复出现一句话:This changes everything。读完论文和演示,可以明确地说,这并非又一篇普通AI论文,而是交互范式的一道分水岭。
Wan-Streamer重塑实时交互
当前的实时对话系统大致分为两类。一类是纯语音方案,如GPT-4o Realtime、豆包Voice和Gemini Live,响应敏捷却没有可视形象,你只能听到声音,看不到任何面孔、眼神或动作。另一类是音视频数字人方案,通过ASR语音识别、LLM、TTS语音合成和动画模块串联完成,每个模块间的边界都在叠加延迟,而且绝大多数系统从不公开端到端的真实响应时间。
Wan-Streamer彻底改写了这套流程。它用一个Transformer完成感知、推理、生成、回复时机判断、话轮管理和跨模态同步,没有任何外挂的ASR、LLM、TTS或动画模块,所有能力在同一个模型中联合优化。
| 方案类型 | 代表系统 | 交互形式 | 延迟指标 |
|---|---|---|---|
| 纯语音方案 | GPT-4o Realtime / 豆包 / Gemini | 无可见形象,纯音频交互 | 0.23 ~ 3.6s(端到端) |
| 数字人拼接方案 | StreamAvatar / LPM / Hallo-Live | 多模块拼接,仅计渲染 | 0.35 ~ 1.2s(不含大脑) |
| Wan-Streamer | 单一端到端Transformer | 同步音视频 + 全双工 | 0.2s / 0.55s(全链路) |
表中的关键差异在于,纯语音方案报告的是端到端延迟,数字人方案只报告渲染阶段的延迟(刻意隐去外部LLM、ASR、TTS的耗时)。Wan-Streamer是唯一一个同时输出同步音视频、如实公开端到端全链路时间,并把总延迟压到一秒以内的模型。
一个Transformer完成所有任务
Wan-Streamer的核心架构看似直接,实现却极为复杂:整个交互过程被建模为一条因果流,视觉帧、音频片段和文本token交错成一个序列,由block-causal attention协同调度。每个新进来的观测单元立即可用,每个生成的单元立刻输出并写回交互历史。整个技术栈从头到尾维持因果性——因果VAE、因果编码器、因果解码器,连同block-causal attention环环相扣。语言部分用next-token prediction训练,输出离散token;音频和视频部分则在连续潜在空间中通过条件flow matching联合生成,并以同一份上下文作为条件,使语音、动作和外观作为一个耦合整体去噪。这意味着嘴唇动作与语音韵律源自同一个底层表示,无需任何外部对齐工具。
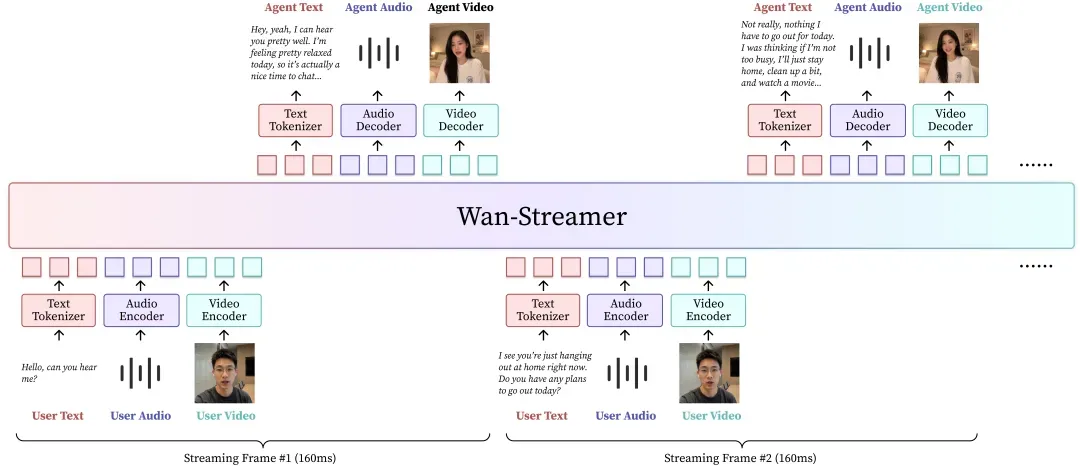
Wan-Streamer总体框架:在同一个Transformer中,语言、音频、视频的输入与输出交错建模,由block-causal attention统筹增量式流式生成。
Thinker-Performer双GPU流水线
为了将模型侧延迟压缩到200毫秒,部署时Wan-Streamer被拆分成两个角色。Thinker GPU负责因果编码、短序列token-causal Transformer计算、KV-cache构建以及上一帧的音视频解码与输出。Performer GPU则专职运行flow-matching求解器,为下一帧生成音视频潜在表示。两个GPU流水线重叠工作,解码与去噪互不阻塞。只要performer的计算时间加上通信开销能塞进160毫秒的流式单元内,系统就能维持实时吞吐。signal-to-signal全路径约200毫秒,叠加大约350毫秒的双向网络延迟后,总交互延迟稳定在550毫秒左右。
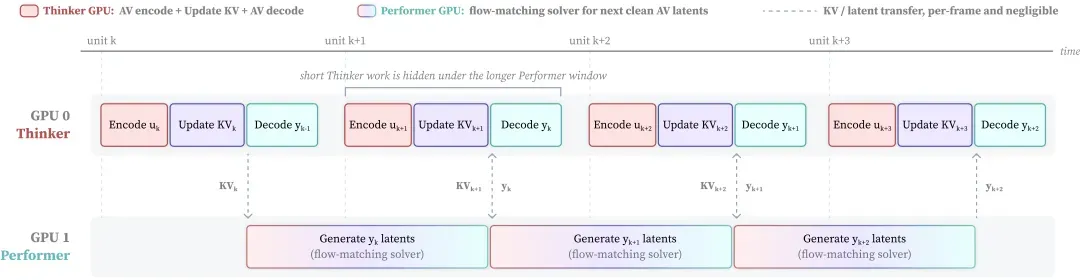
Thinker-Performer并行重叠:当前帧感知、上一帧解码、KV通信与下一帧去噪在相邻的流式单元之间以流水线方式执行。
分阶段训练与滚动蒸馏
训练分为三个阶段。第一阶段是独立任务预训练,模型学习单模态的理解与生成,包括图像转文本、ASR、TTS和视频生成。第二阶段进入端到端交互训练,接触真实的人际对话录音,学习轮次礼仪、打断时机以及长对话中的身份保持。第三阶段是滚动蒸馏,训练学生模型在连续步骤中基于自身的历史输出保持稳定,防止长期生成中出现质量漂移。这一设计值得特别注意:流式推理中,微小误差会在时间累积下导致视频或音频逐渐劣化。Wan-Streamer让学生模型在训练时就模拟这种误差累积,强制其学会自我纠正。
演示内容一览
官网放出了四段未经剪辑的预录演示:中文男声模拟居家的视频通话,聊刮胡子和选电影;中文女声轻松讨论八卦与周星驰的《功夫》;英文疲惫女生在车内对话,诉说自己的疲倦;英文自然对话谈论无意识刷手机和关闭通知。当前v0.1版本的分辨率为192p,25fps,团队表示后续很容易扩展到更高分辨率。更具里程碑意义的是一段实时录屏——左侧用户画面,右侧AI智能体实时回应,下方同步呈现文本流。这是目前唯一公开的端到端实时视频对话演示。
这意味着什么
Wan-Streamer的意义不在于某一项指标的突破,而是证明了一件根本性的事情:全双工音视频交互可以用一个模型原生实现。200毫秒的模型侧延迟让AI的响应速度真正进入人类自然对话的范畴——人类对话中的平均反应时间大约在200至300毫秒之间,Wan-Streamer恰好落在这个区间。可以判断,接下来的领域将明显分化为两条路线:以Wan-Streamer为代表的端到端统一模型将率先在消费级场景落地,如客服、教育、陪伴和直播;而以阿里云百炼数字人API等为代表的模块化编排方案,在企业高度定制化的场景中依然保有优势——客户需要换形象、换声音并细粒度控制每一环节。两条路线并不互斥,但Wan-Streamer的出现无疑将技术天花板向上推了一截。
保持理性:v0.1仍处于早期阶段
v0.1依然是概念验证:192p分辨率、双GPU部署、尚未开源,距离消费级产品还有相当距离。论文中展示的全双工能力目前只在文字描述中体现,演示为预录片段,真实的联网对话中,模型的倾听行为、打断处理以及长时间对话的一致性还需要更广泛的开放验证。