阿里Wan2.7-Image深度实测:捏脸锁色、局部重绘,AI生图不再是开盲盒
你是否也有这样的体验:
用 AI 生成图像,跑出来的脸几乎一模一样,像是同一条流水线上贴了不同发型。好不容易调出一张满意的构图,想微调一个小细节,结果所有不想改动的地方全乱了。调色要“多巴胺风”,它给你荧光粉;要暗调电影感,它偏偏亮得刺眼。还有文字,要么干脆乱码,要么完全不按提示词来,根本没法直接用在封面或海报上。
这些痛点,做内容的人几乎每天都在踩坑。
上周,阿里发布了最新的生图模型 Wan2.7-Image,据说一口气把这几大难题打包解决了。我第一时间上手实测,看看这次更新究竟能给自媒体博主、电商从业者带来哪些实质变化。
下面就聊聊我实操后最真实的感受。
1. 告别千篇一律,捏出真正的“活人感”
做自媒体的都知道,想要一个有辨识度的人物配图,以前基本靠“抽卡”。AI 常常生成高颅顶、大眼睛、过度磨皮的脸——清一色的“AI感”,一眼就能看出不是真人。
Wan2.7-Image 这次打通了一套细颗粒度的捏脸系统,可以从骨骼结构、五官特征等维度精细描述,捏出真正拥有辨识度的面孔。
可调参数大致包括:
- 脸型:鹅蛋脸、圆脸、方脸、长方脸,甚至六角形脸。
- 眼部特征:杏仁眼、深邃眼窝、圆眼、丹凤眼。
- 肤色、发型、胡须、纹身、眼镜……几乎你能想到的所有细节都能独立控制。
想要什么脸,直接描述即可。
我分别用简单和复杂两组提示词做了测试。第一组用非常基础的提示词,没有精细控制任何五官:“一个年轻女性肖像,半身照,电影感光影,高清细节,真实皮肤质感”,一次生成 4 张。

结果 4 张图在脸型轮廓、颧骨位置、下颌线弧度上各自不同;皮肤纹理、毛孔、轻微泛红全部保留,没有那种过度磨皮的假面感。
接着我加大难度,用了一段很“刁钻”的提示词:
“正面半身肖像特写,人物平静地看向镜头。一位 35 岁左右的亚洲女性,长方脸型,骨骼感明显,颧骨微高,单眼皮,眼神带有沉静的阅历感。留着自然垂落的黑色中长直发。重点要求:绝对不要 AI 磨皮,必须保留真实的皮肤瑕疵,脸颊要有明显的色斑、雀斑和毛孔,眼底有轻微的细纹和暗沉。侧面窗边柔和的自然漫射光,背景是虚化的窗框和绿植,极强的纪实摄影质感与活人感。”

成图出来的瞬间,那种扑面而来的真实感确实让人有些恍惚。画面上不再是那个美颜拉满的假人,而是一个有血有肉、带着生活痕迹的真实女性。放大看,不均匀的色斑、细腻的毛孔、下颌角的自然阴影,甚至额前微微凌乱的碎发,都极度逼真。
对于做短剧、漫画这类需要多个不同角色持续出场的项目,再也不容易撞脸了。而对于电商和自媒体创作者来说,无论是定制专属模特形象,还是打造个人 IP 的虚拟分身,都能通过这项功能快速实现,不必再完全依赖真人拍摄与后期修图。
2. 精准调色,告别色彩抽盲盒
这是我这次测试里最惊喜的功能。
以前做品牌的内容,想统一视觉风格,每张图跑出来的颜色都不一样,后期调色调到怀疑人生。Wan2.7-Image 直接内置了调色盘功能,自带 6 个主流色系供我们选择。

也可以上传自己的图片来新增调色盘,让模型直接提取其中的主色。
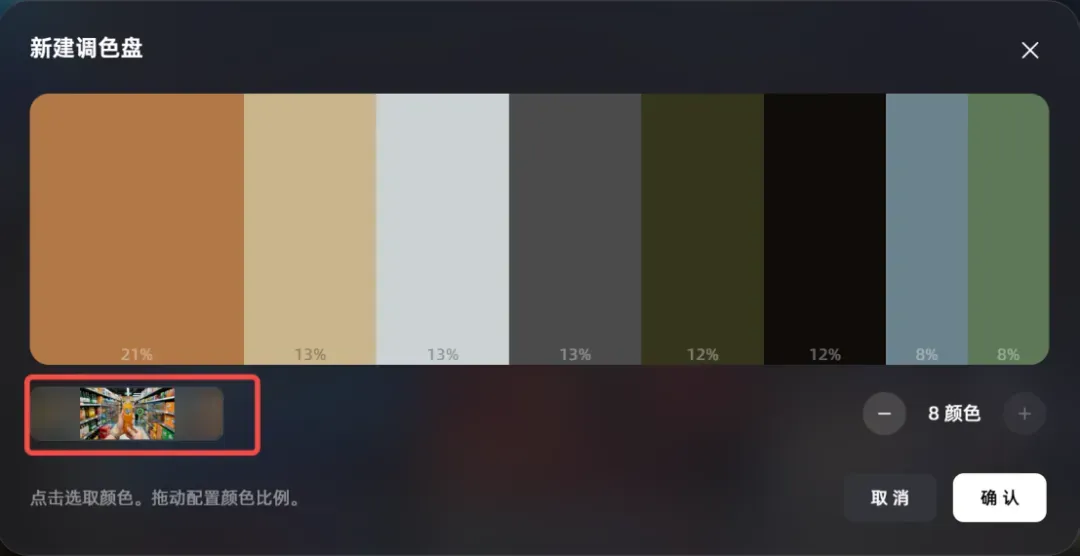
生成的图像色彩非常到位,整体质感也很好。

然后,我故意做了一个刁难式的测试:生成一棵树,但把调色盘全部锁定在蓝色系,完全排除绿色。

在常规模型里,只要看到“树”这个词,潜意识一定会往里塞绿色,哪怕明确说了“蓝色”,它也常常偷偷加绿。但这次,整棵树的叶片、树干全部落在深蓝和青蓝色系里,没有一丝杂色;连树叶随风飘动的动态感都有了,却依然死死咬住那套蓝色,毫不动摇。
还有一个更贴近实际工作的场景:把品牌 Logo 上传进调色盘,它会自动提取你的品牌主色。之后不管生成什么图,整体配色都会自动对齐品牌 VI。做电商、做品牌内容的,以后批量出图,再也不用担心颜色跑偏了。
3. 超长文本渲染,文字终于不乱码了
AI 生图中的文字渲染,一直以来都是重灾区。英文里写个“SALE”你可能得到“SAIE”,中文更惨,经常就是一堆看起来像汉字其实读不出的鬼画符。
Wan2.7-Image 这次文本渲染能力大幅提升,支持 12 种语言、最高 3K tokens 的超长文本输入,很好地解决了模糊、错乱、漏写这些老问题。
比如,生成一张“书桌上一个笔记本上写着《Wish You Were Here》歌词的原文”的图片。

可以看到,笔记本上的歌词不仅拼写正确,还有合理的排版样式。
它甚至能用来生成示意图、流程图这类素材。例如:
“生成一张学术风格的信息图表,标题‘大语言模型发展时间线’,从左到右排列 2020–2025 年的重要模型节点,包含 GPT-3、ChatGPT、GPT-4、Claude 3、Gemini 等,每个节点标注发布年份和关键特征,蓝白配色,简洁学术风格。”
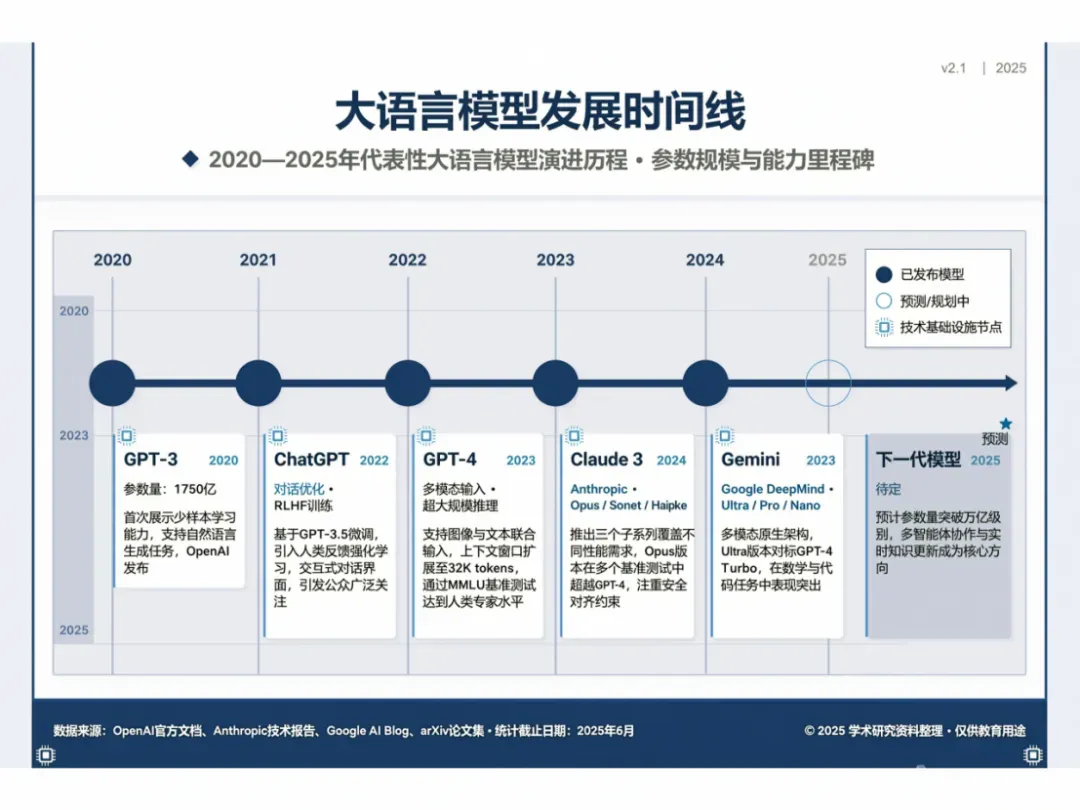
这对做学术或科普内容的朋友来说非常便利。
此外,像超长文本和数学公式,Wan2.7-Image 也能轻松承载,生成效果非常稳定。


这意味着什么?以前做封面图、信息图、长图海报,文字部分必须回到 PS 里手动叠加;现在可以一次生成,大幅节省了排版时间。
4. 交互式编辑,哪里不满意改哪里
这是最让人解气的功能。
以往改 AI 图片的细节简直像在拆盲盒:你只想换个 Logo,它却把整个背景一起替换了;你只想移动一个物品,光影全部变味。遇到这种情况,只能推翻重来,然后新图又会冒出别的毛病,反复消耗积分与耐心。
现在只需要在图上直接画框,圈出想要修改的区域,告诉它具体怎么改,其他地方纹丝不动。
例如,把芬达易拉罐改成可口可乐:


还可以对某个细节进行位置和动作调整,例如:
“将图中框选的小猫移动到虚框位置,并且姿势变成趴在窗台上。”


对于做电商的朋友来说,未来主图改个文案、换个角标,都不需要全部重新生成,局部编辑就能快速完成,这是真正的降本增效。
5. 多主体一致,分镜换场景也不换脸
做过短剧脚本或连载内容的人,一定懂那种崩溃:第一张图角色长这样,第二张换个机位脸就变了,第三张换件衣服整个人都接不上了。
Wan2.7-Image 支持最多 9 张参考图锁定角色特征,一次生成最多 12 张逻辑连贯的组图。
我上传了一张参考人物,让模型生成 3 个场景各 4 张图:咖啡馆内看书、户外街拍、正式会议室,共 12 张。提示词如下:
“基于参考人物,生成 12 张图,分 3 个场景,每个场景 4 张:场景一(咖啡馆):女孩坐在咖啡馆靠窗位置看书,手捧一本书,桌上放着一杯拿铁,暖黄色室内光,全景、中景、特写、侧面各一张;场景二(户外街拍):女孩站在街头,穿着休闲,自然光,背景是模糊的城市街道,正面、侧面、回头、远景各一张;场景三(正式会议室):女孩坐在会议桌前,穿正装,冷色调室内灯光,背景是会议室白板,正面、侧面、低头看文件、抬头各一张。要求:保持人物面部特征、发型、整体气质完全一致,光影符合各场景逻辑,人物服饰与场景匹配。”

12 张图全部跑完,人物的面部特征、发型轮廓、整体气质从头到尾没有变过。咖啡馆是暖光,户外是自然光,会议室是冷光,三个场景的光影逻辑各自独立且准确;人物服饰与姿态也和场景自然匹配,完全没有生硬插入的感觉。
对需要持续输出统一 IP 形象的自媒体尤其是矩阵号来说,这个能力直接把制作门槛切掉了一半。
测完这五个场景,我只剩一句话:以前用 AI 生图,像在开盲盒,全凭运气;现在,它把方向盘实实在在交回了我们手上——脸能捏,色能锁,文字能精准呈现,改一处也再不会让全局崩掉。
感兴趣的小伙伴可以直接去万相官网免费跑图体验: https://tongyi.aliyun.com/wan/explore