零代码2小时构建专属Claude Code:26万人阅读的架构拆解与实战指南
很多人以为 agent = LLM + API 调用,但实际上,调用 API 只要十行代码,真正棘手的部分在于 Harness Engineering —— 即如何把工具和模型运转的整体“马具”搭建好。
担心信息安全、想搭建内部专属工具?本文就将借助一个爆火的开源项目,带你零代码、在两小时内理清架构,亲手复刻出一个属于你自己的 Claude Code。
最近,X 平台上的开发者小八仅用两天时间和一万行 TypeScript,就从零复刻了一个 Claude Code。
他的帖子发布不到 24 小时,就积累了超过 26 万次观看和 720 个点赞。
读完这个项目后,最大的感受并非“技术多么高超”,而是这套架构思想的普适性——几乎所有人都能借鉴。不用写任何代码,只要吃透核心结构,按需实现即可。本文将对这个项目进行系统的技术拆解,让你也能用上独属于自己的 Claude Code(或者任意 agentic CLI)。
第一步:跑通最小可用循环
在写任何代码(哪怕 VibeCoding)之前,需要先在头脑中理清一个最小可行原型:用户输入 → CLI 组装请求 → API 调用(SSE 流式)→ 解析响应事件流 → 依据 stop_reason 分支决策。
把这个循环的图画清楚,架构的基调也就定了。
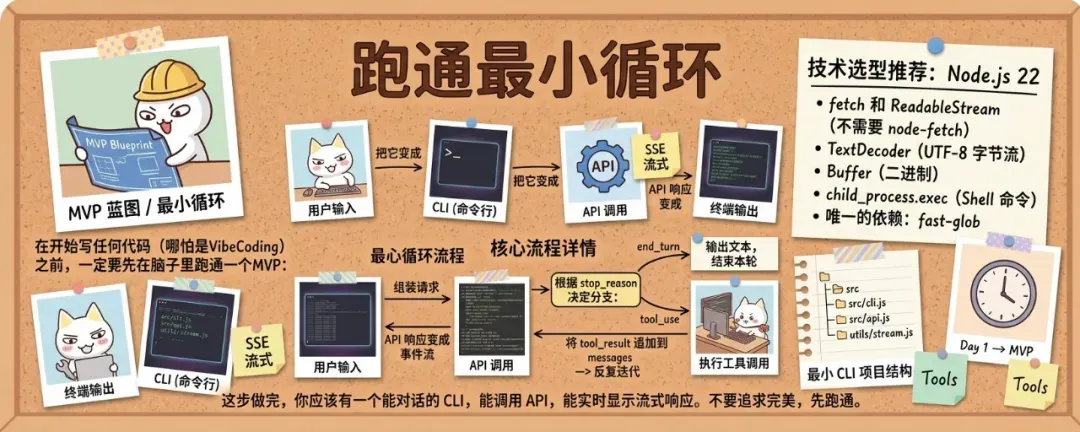
核心流程可以概括为:
用户输入 → 组装请求 → API 调用(SSE 流式)→ 解析响应事件流 →
根据 stop_reason 决定分支:
- end_turn → 输出文本,结束本轮
- tool_use → 执行工具调用 → 将 tool_result 追加到 messages → 反复迭代
技术栈强烈推荐使用 Node.js 22,因为其内置标准库已经足够:
fetch和ReadableStream已稳定,无需引入 node-fetchTextDecoder处理 UTF-8 字节流Buffer处理二进制child_process.exec执行 Shell 命令
唯一的外部依赖只有 fast-glob。
完成这一步后,你应该获得一个能够对话、调用 API 并实时显示流式响应的 CLI。不要追求完美,先跑通再说。
第二步:设计 System Prompt 分段架构
最直观的 system prompt 做法,是把所有指令拼接成一个长字符串直接传给 API。这种方式在原型阶段可行,但在生产环境下存在一个关键问题:缓存几乎无法命中。
例如,一段 system prompt 可能是:
你是一个编程助手,擅长 Python 和 JavaScript。你要遵循以下规范:1. 写注释 2. 用类型提示 3. 避免全局变量...
当前工作目录:https://watermelonwater.tech/insights_imgs/零代码2小时创建ClaudeCode3.webp)
---
## 第三步:实现工具执行管线
工具执行管线是项目中最复杂的一环。推荐的设计包含六个阶段:**展示工具调用 → 权限检查 → 前置钩子 → 快照文件 → 执行工具 → 后置钩子**。
作为第一版,至少需要实现下面五个核心工具:
| 工具 | 作用 |
|----------|----------------------------------|
| **Read** | 读取文件内容 |
| **Write** | 写入文件(确保父目录存在) |
| **Edit** | 精确字符串替换 |
| **Bash** | 执行 Shell 命令(120 秒超时) |
| **Glob** | 文件匹配 |
在权限检查方面,可以设计三种模式:
- **default**:safe 类工具自动执行,dangerous 及 write 类工具需要用户确认;
- **auto**:绕过所有交互提示,适用于 CI 环境;
- **plan**:只读沙箱,让用户先查看执行计划再决定是否真正执行。
更加巧妙的是两阶段分类器:先用纯规则表快速匹配,常见安全命令(如 `ls`、`cat`、`grep`)直接放行,危险命令(如 `rm`、`sudo`)直接拒绝,足以覆盖超过 90% 的场景,实现零延迟。对于规则未覆盖的情况,再将命令字符串发送给 Haiku 模型,由其返回 `allow/deny/ask_user` 决策,这部分延迟约 300-500 毫秒,对整体循环影响微乎其微。
这个设计充分利用了“规则为效率、LLM 为兜底”的思想,90% 的情形通过规则表快速判定,仅对少数模糊案例调用 LLM。
---
## 第四步:设计记忆系统
LLM 本身是无状态的,每轮对话都从空白的上下文开始,之前建立的偏好、项目约定和用户反馈全部丢失。记忆系统正是为了解决这一问题。
可以利用文件系统实现持久记忆,**不引入数据库,不使用新的存储格式**。记忆文件存放在项目专属目录下,每个文件都是带有 YAML frontmatter 的 Markdown 文件,共分为四种类型:
| 类型 | 内容 |
|--------------|--------------------------------------------|
| **user** | 用户偏好(角色、习惯、专长) |
| **feedback** | 行为纠正(用户确认或否定的做法) |
| **project** | 项目约定(无法从代码/git 推导的上下文) |
| **reference**| 外部资源指针(URL、文档链接) |
`MEMORY.md` 作为索引文件,在每次对话之初注入 system prompt,模型按需通过 Read 工具读取具体记忆内容。
为什么选择 Markdown?很多人下意识会考虑使用数据库或设计 JSON 格式,但用**普通 Markdown 文件**可以让用户直接编辑,不存在格式锁定,几乎没有学习成本。用户可以随时打开、修改并保存,灵活且直观。
---
## 第五步:后续优化方向
核心功能跑通后,可以考虑以下优化:
- **Deferred Tools 按需加载**:当拥有超过 20 个工具时,可将低频工具标记为 deferred,模型需要时再去获取完整 schema,能将 tools 数组的固定开销降低约 40%。
- **多 Agent 协作**:单个 Agent 受串行执行限制,当任务可以拆解为多个独立子任务时,多 Agent 并行处理可以显著缩短整体耗时。
- **MCP 动态工具**:MCP 本质上是一种标准化的工具发现协议,让工具成为可独立部署的进程,通过统一接口被任何兼容客户端发现和调用。
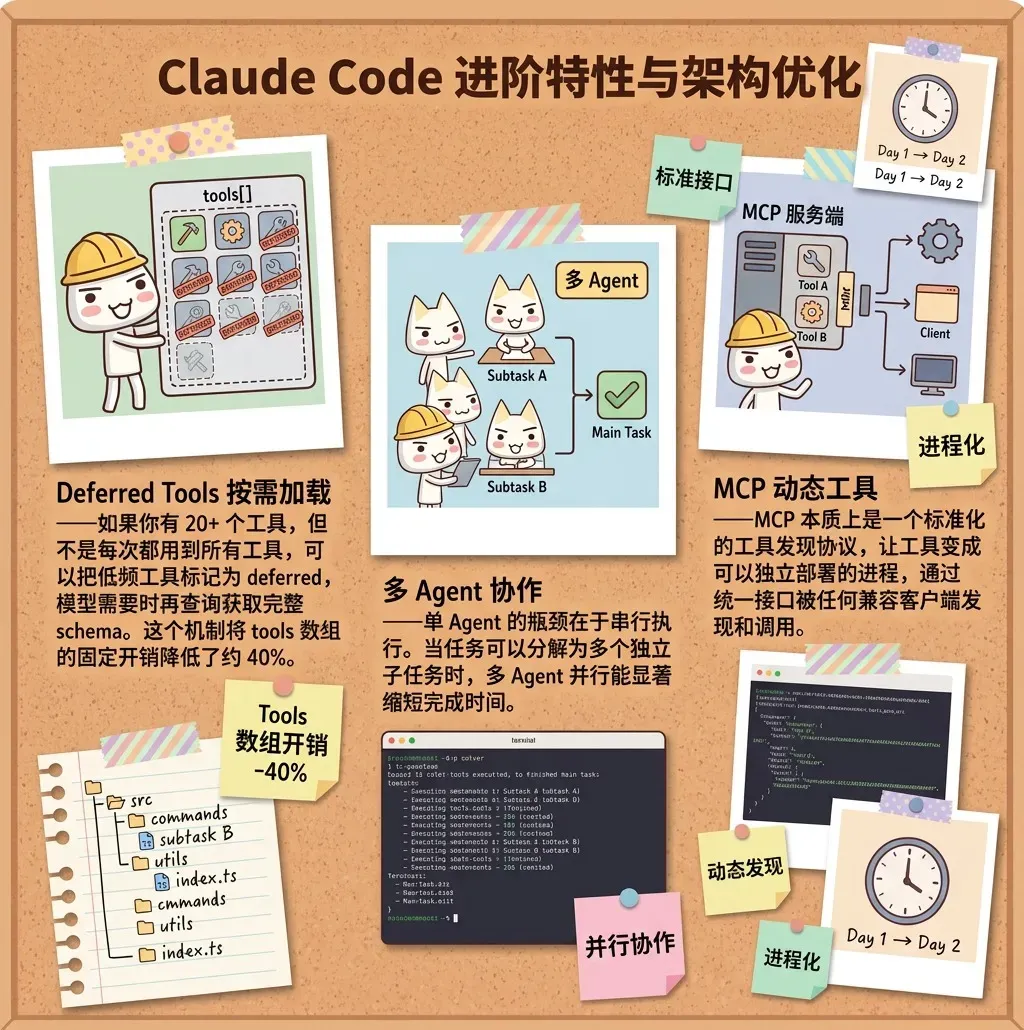
这些优化是否实施,完全取决于你的需求。如果只是个人使用,核心功能已足够;若打算做成产品,这些点值得投入。
---
## 总结
**构建 agent 工具或产品的核心难点,始终在于 Harness Engineering。** 调用 API 只是十行代码的事,真正的挑战包括:
- 工具调用结果如何正确地回传给模型
- 在流式输出中插入用户交互
- 处理长任务中的错误恢复
- 设计安全可控的权限系统
- 优化 token 成本
这些都归属于 Harness Engineering 的范畴。
**先跑通小循环,再按需优化,切勿追求一步到位。**