AI编程的验证新范式:用循环工程打破交付瓶颈
核心观察
AI编程和智能代理领域正在发生一个关键变化:生成能力已经充足,真正制约交付质量的不是“写不出来”,而是“验不过来”。Claude Code的创建者Boris Cherny已经半年不再亲自写代码,日常工作变成了“设计-生成-检查”的交替循环,让AI在几乎无人监督的状态下持续产出。这种模式正在重新定义团队交付代码的方式。
生成冗余,验证成为窄口
过去两年,文本和代码生成能力的飞跃,让“无法生成”的痛点基本消失。如今决定交付质量的不再是输出的长度或语法是否正确,而是生成结果能否通过测试、是否满足功能复选框、是否符合视觉验收标准。能力的过剩反而让验证环节的负载急剧膨胀。
工程实践里已经有清晰的信号:一些团队在引入AI代理编程后,Pull Request数量飙升200%,但代码审查和测试通过的耗时并没有同比例降低。原因在于人工审批仍是串行瓶颈,模型可以并行生成大量候选方案,却没有足够并行的验证容量去消化它们。生成的红利被串行的验证堵在了路上。
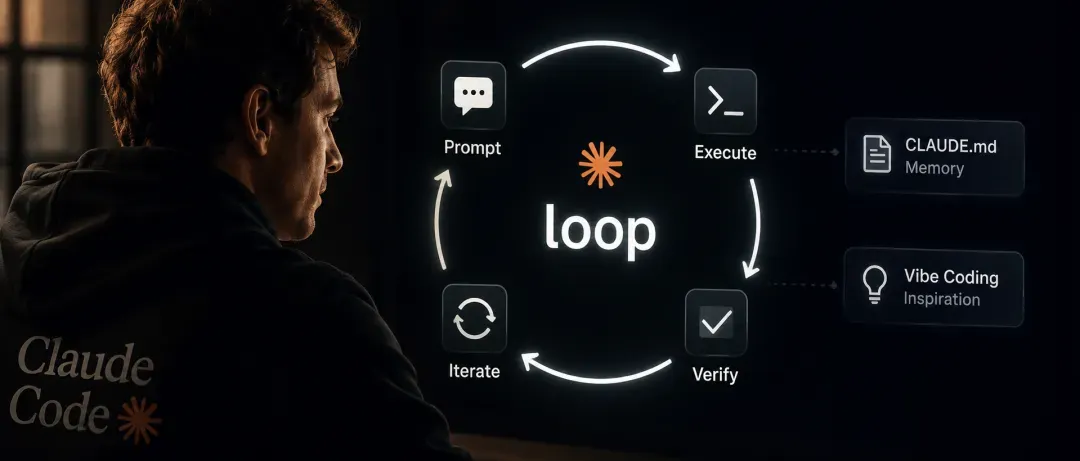
Loop Engineering的核心机制
Loop Engineering的做法是把任务拆成“生成器”和“检查器”两个角色:生成器负责产出方案,检查器负责审查输出、运行测试、给出反馈,二者形成自动闭环。循环的收敛条件通常是任务通过验收标准,或者触达预设的迭代次数上限。
这套机制被提炼为一个三级系统,用来区分任务的自动化程度:
- 第一级:当检查器有清晰、可量化的标准时,循环全自动运行,人工介入降到最低。
- 第二级:当检查器遇到判断盲区或验收条件模糊时,人类介入调整条件,再交回循环。
- 第三级:当任务本身的需求和边界需要重新定义时,问题交还人类做决策。
三级系统的价值在于从“一轮爆发”转向“多轮收敛”。对团队而言,循环本身的设计和轮次管理,成了新的工作产出,而不再是每一轮生成的具体内容。
最小可行的闭环:Karpathy的 LLM Wiki
Loop Engineering并不需要重型框架就能落地。Andrej Karpathy的 LLM Wiki 就是一个最小示范:他将个人知识整理为标准 Markdown 目录树,AI在其中持续整理、更新、跨文件链接修订,没有复杂调度系统,也没有多Agent编排,却完成了知识维护的完整闭环。
这个案例揭示了两个要点。其一,标准化格式是让AI自我检查的前提:如果文档结构参差不齐,模型根本无法批量判定一次更新是否真正完成。其二,人类真正需要设计的是系统的目标、验收标准和循环边界,而不是每一轮生成的具体文案。把“做什么”的指令,转变为“怎样才算做好”的约束,才是启动自动化闭环的钥匙。
减少人工,而非消除人工
Claude Code产品负责人Cat Wu给出的建议很直接:提前把设计系统、组件库、规范语境等上下文整理清楚,一次性注入,而不是让模型每次都重新猜测。这与Loop Engineering的思路一致:验收标准越明确,AI就越能在无人值守下完成大部分重复工作。
Loop Engineering减少的是重复执行类的人工投入,而不是把人类踢出决策链。真正能从这种模式中获益的团队,通常已经清楚如何定义交付物标准,知道要用什么类型的测试、截图、结构约束来验收AI的产出。对还在积累使用经验的团队,可以先找一个验收标准清晰的小任务跑一轮自动循环,收集失败案例,再逐步扩展适用范围。
判断
一个人生成的瓶颈在大多数场景已经被解决,现在急缺的是并行验证能力和验收标准设计。Loop Engineering的本质,是把人类从重复执行的串行链路里释放出来,将精力重新投向目标设定、标准设计和边界判断。这或许才是AI时代能够让人类真正“休息”的前提。