2026年RAG嵌入模型终极对决:跨模态、跨语言与长文档检索能力全解析
总结 (TL;DR):我们针对公开基准测试所遗漏的四个实际生产场景,对10款主流嵌入模型展开深度评估:跨模态检索、跨语言检索、关键信息检索以及维度压缩。没有一款模型能够包揽所有测试的第一。Google 的 Gemini Embedding 2 是综合能力最强的“全能选手”。阿里巴巴达摩院开源的 Qwen3-VL-2B 在跨模态任务中力压所有闭源 API;若你希望通过压缩嵌入维度来降低存储成本,Voyage Multimodal 3.5 或 Jina Embeddings v4 则是最优解。
为什么仅靠 MTEB 来选择嵌入模型是不够的?
大多数 RAG(检索增强生成)原型系统都是从 OpenAI 的 text-embedding-3-small 起步的。它价格低廉、集成简便,对于单纯的英文文本检索来说表现也足够可靠。但一旦进入真实的生产环境,这个模型很快就会暴露出局限性。当你的数据处理管线开始摄入图片、PDF 以及多语种文档时,仅具备纯文本嵌入能力的模型便力不从心了。
MTEB 排行榜看起来会为你指引更优的选择,然而问题在于:MTEB 只衡量单一语境的文本检索。它完全不涉及跨模态检索(用一段文字查询来匹配图像库)、跨语言搜索(用中文查询找出英文文档),也不关心长文档的准确度,更不会告诉你,当你为了在向量数据库中节省存储空间而截断嵌入向量的维度时,模型会牺牲多少召回质量。
那么,到底该选用哪一款嵌入模型?答案取决于你的数据类型、语言种类、文档长度,以及你是否需要进行维度压缩。为了给出可靠的答案,我们专门构建了 CCKM 基准测试,并在上述每一个维度上,对 2025 年到 2026 年间发布的 10 款模型进行了严格评测。
什么是 CCKM 基准测试?
CCKM(分别代表跨模态 Cross-modal、跨语言 Cross-lingual、关键信息 Key information、MRL 套娃表示学习)测试的是标准基准测试所遗漏的四项核心能力:
| 测试维度 | 它测试什么 | 为什么这很重要 |
|---|---|---|
| 跨模态检索 | 在有几乎完全相同干扰项的前提下,将文本描述与正确的图像匹配。 | 多模态 RAG 管线需要将文本和图像的嵌入表示放入同一个向量空间。 |
| 跨语言检索 | 根据中文查询找到正确的英文文档,反之亦然。 | 生产环境里的知识库往往是多语种的。 |
| 关键信息检索 | 定位埋藏在 4K 到 32K 字符长文档中的特定事实(大海捞针)。 | RAG 系统常常需要处理合同、研究论文等超长文档。 |
| MRL 维度压缩 | 衡量当你把嵌入向量截断至 256 维时,模型会损失多少语义质量。 | 更少的维度意味着更低的向量数据库存储成本,但需要知道代价有多大。 |
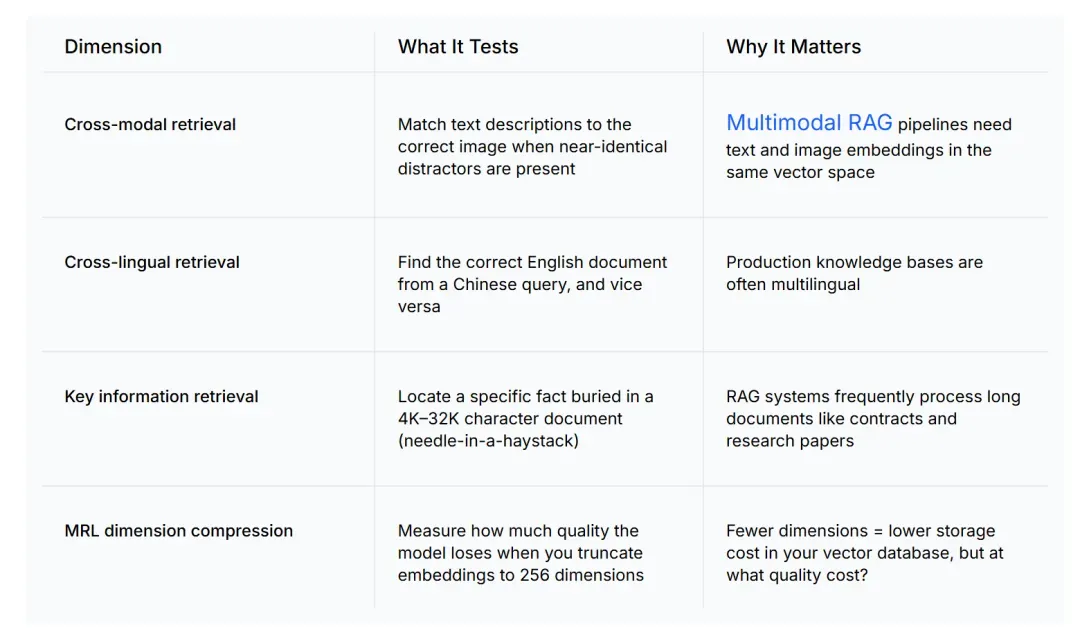
MTEB 无从覆盖上述任何一项。MMEB 虽然加入了多模态,却跳过了对难负例的测试,导致模型即使没有真正学会分辨微妙的差异,也能拿到高分。CCKM 正是为了填补这些评测空白而设计的。
测试的嵌入模型
我们评测了 10 款覆盖 API 服务和开源方案的模型,同时纳入了 2021 年发布的 CLIP ViT-L-14 作为基线参考。
| 模型名称 | 来源 | 参数量 | 维度 | 模态 | 核心特征 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | 未公开 | 3072 | 文本/图像/视频/音频/PDF | 全模态,覆盖面最广 | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | 文本/图像/PDF | MRL + LoRA 适配器 |
| Voyage Multimodal 3.5 | Voyage AI | 未公开 | 1024 | 文本/图像/视频 | 各项任务表现均衡 |
| Qwen3-VL-Embedding-2B | 阿里 Qwen | 2B | 2048 | 文本/图像/视频 | 开源,轻量级多模态 |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | 文本/图像 | 现代化的 CLIP 架构 |
| Cohere Embed v4 | Cohere | 未公开 | 固定 | 文本 | 企业级检索 |
| OpenAI text-embedding-3-large | OpenAI | 未公开 | 3072 | 文本 | 使用最广泛 |
| BGE-M3 | BAAI | 568M | 1024 | 文本 | 开源,支持 100+ 语言 |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | 文本 | 轻量级,专注于英文 |
| nomic-embed-text | Nomic AI | 137M | 768 | 文本 | 超轻量级 |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | 文本/图像 | 基准对照组 |
跨模态检索:哪些模型能处理文本到图像的搜索?
如果你的 RAG 系统需要同时处理图像和文本,嵌入模型就必须将这两种模态映射到同一个向量空间。典型的场景包括电商图片搜索、图文混合的知识库问答等。
测试方法:
我们从 COCO val2017 数据集中抽取了 200 对图文样本,并由 GPT-4o-mini 为每张图片生成一段详细描述,同时为每张图片精心编写了 3 个难负例——这些干扰文本通常只在一两个细节上与正确描述不同。模型需要在这 200 张图像和 600 个干扰项之间找到正确的匹配。
数据集示例
一张复古棕色皮革旅行箱,上面贴有“加州”、“古巴”等旅行贴纸,搁在金属行李架上,背景是清澈的蓝天——这是跨模态检索基准测试所用的测试图像。

正确描述
“The image features vintage brown leather suitcases with various travel stickers including ‘California’, ‘Cuba’, and ‘New York’, placed on a metal luggage rack against a clear blue sky.”
评分标准:
- 为所有图像和所有文本(200 个正确描述 + 600 个难负例)生成嵌入向量。
- 文本到图像 (t2i):使用每条描述在 200 张图像中搜索最相似的图像。如果排在第一位的结果是正确的图像,则计为一次命中。
- 图像到文本 (i2t):使用每张图像在所有 800 段文本中搜索最相似的文本。只有当排名第一的结果是正确描述,而非任意一个难负例时,才算命中。
- 最终得分:
hard_avg_R@1 = (t2i 准确率 + i2t 准确率) / 2

测试结果:
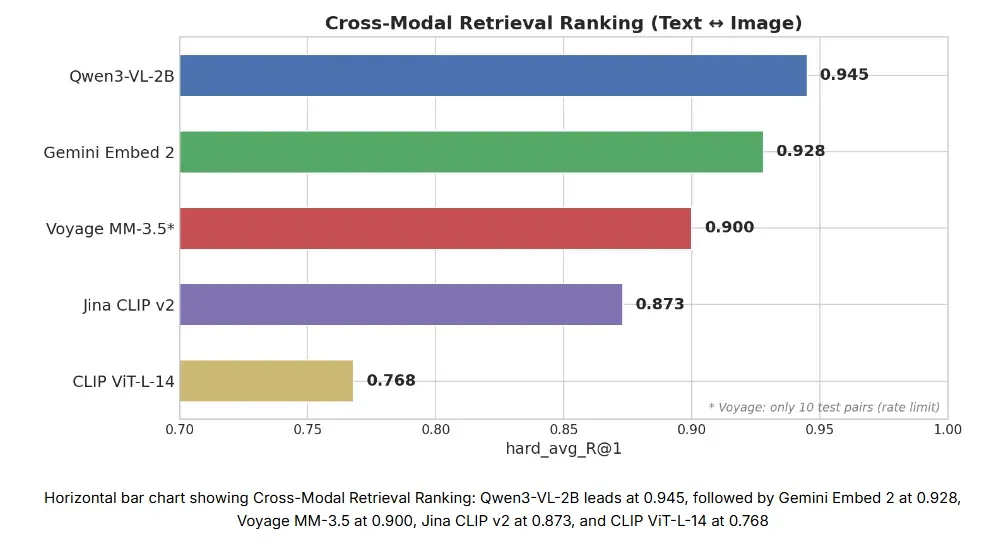
- 第 1 名:Qwen3-VL-2B (0.945)
- 第 2 名:Gemini Embedding 2 (0.928)
- 第 3 名:Voyage Multimodal 3.5 (0.900)
阿里巴巴 Qwen 团队开源的 20 亿参数模型 Qwen3-VL-2B 拔得头筹,领先于所有闭源 API。
这一结果很大程度上可以用模态间隙来解释。模态间隙衡量的是向量空间中文本簇和图像簇之间的 L2 距离。间隙越小,跨模态检索就越容易。Qwen 的模态间隙仅为0.25,大约是 Gemini (0.73) 的三分之一。在 Milvus 这类向量数据库中,较小的模态间隙意味着你可以将文本和图像的嵌入向量直接存入同一个集合中,并轻松地进行交叉搜索。
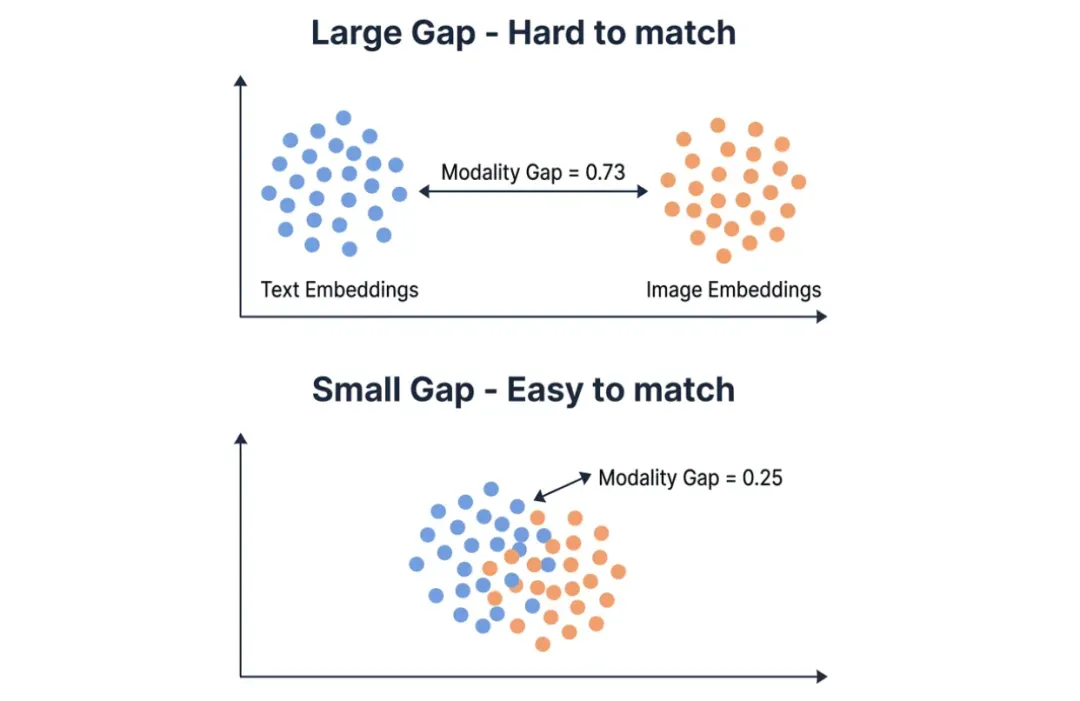 >可视化对比:较大的模态差距(0.73,文本与图像嵌入簇相距较远)与较小的模态差距(0.25,簇存在重叠)——较小的差距让跨模态匹配更加容易。
>可视化对比:较大的模态差距(0.73,文本与图像嵌入簇相距较远)与较小的模态差距(0.25,簇存在重叠)——较小的差距让跨模态匹配更加容易。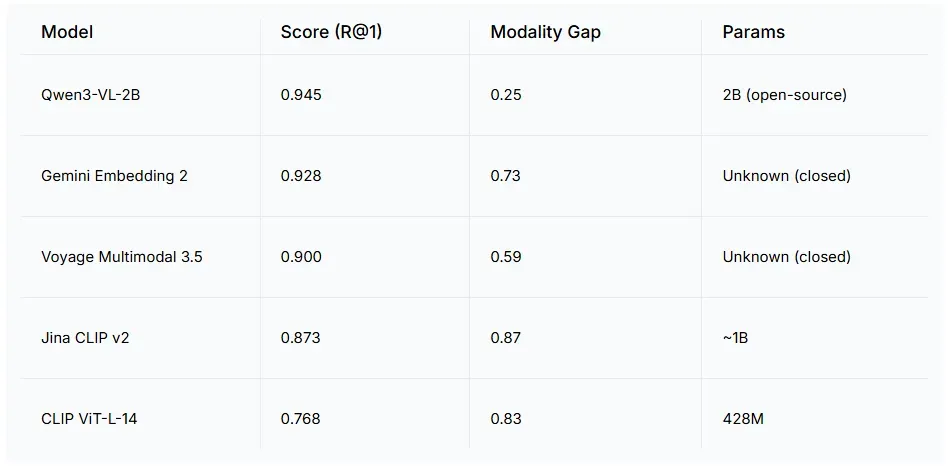
Qwen 的模态间隙仅为 0.25——大约是 Gemini(0.73)的三分之一。在诸如 Milvus 的向量数据库中,较小的模态间隙意味着你可以把文本和图像的嵌入向量存放在同一个集合内,并在二者之间直接进行跨模态相似度搜索。较大的间隙则会降低跨模态相似度匹配的可靠性,你可能需要额外引入一个重排序步骤来弥补。
跨语言检索: 中文查询能找到英文文档吗?
生产环境中的多语言知识库非常普遍。用户可能用中文提问,但答案只存在于一份英文文档中——反之亦然。嵌入模型需要跨越语言边界,对齐语义,而不是仅停留在单一语言上。
测试方法:
我们构造了 166 对中英文平行句子,覆盖三个难度层级:
跨语言难度层级:
- 简单层:字面翻译映射,如“我爱你”与“I love you”。
- 中等层:意译句子映射,例如“这道菜太咸了”与“This dish is too salty”,并配合难负例干扰。
- 困难层:中文成语映射,例如“画蛇添足”与“gilding the lily”,同时配以语义不同的难负例。
每种语言还配有 152 个难负例作为干扰项。

评分方法:
- 为所有中文文本(166 个正确匹配项 + 152 个干扰项)和所有英文文本(同样的数量)生成嵌入向量。
- 中文 → 英文:用每个中文句子在 318 个英文文本中检索其正确翻译。
- 英文 → 中文:同理反向操作。
- 最终得分:
hard_avg_R@1 = (中→英准确率 + 英→中准确率) / 2

测试结果: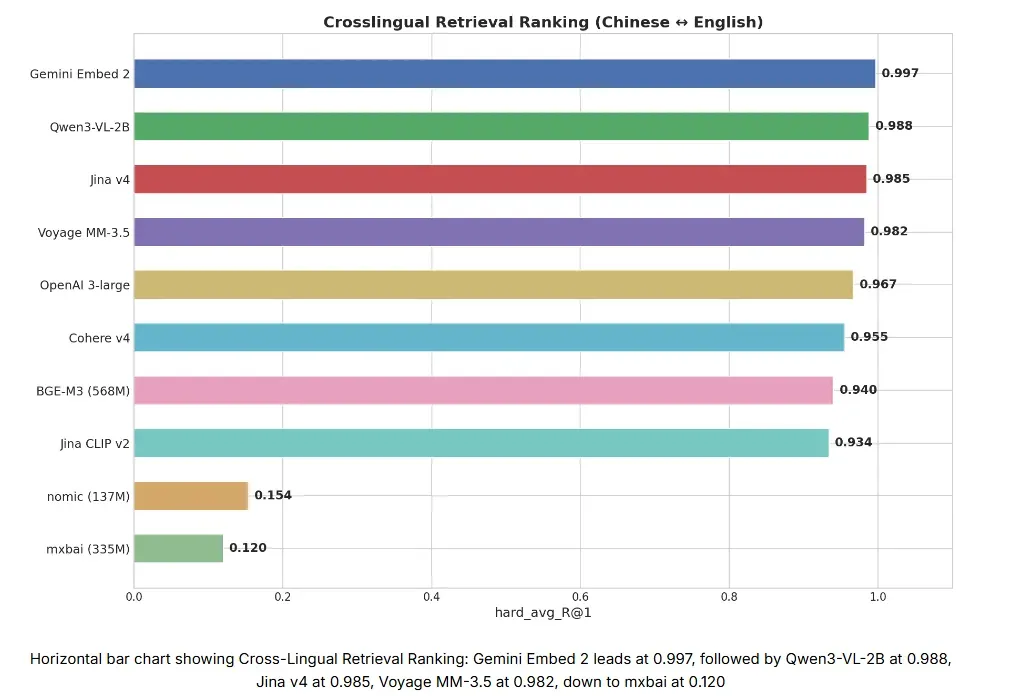
- 第 1 名:Gemini Embedding 2 (0.997)
- 第 2 名:Qwen3-VL-2B (0.988)
- 第 3 名:Jina Embeddings v4 (0.985)
Gemini Embedding 2 得分高达 0.997,是所有参测模型中最高的。它也是唯一在“困难”级别拿到满分 1.000 的模型。在这一级别,像“画蛇添足”→“gild the lily”这样的句对,要求模型具备真正的跨语言语义理解,而不是简单的模式匹配。
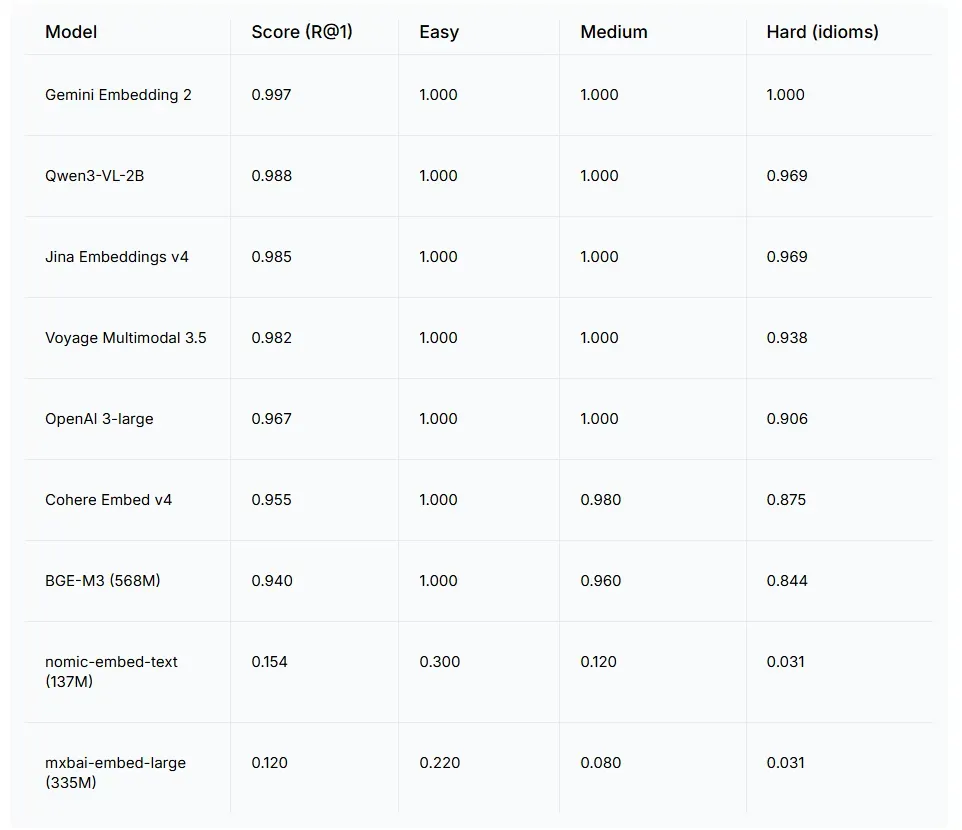
总分排名前七的模型均突破了 0.93——真正的差距体现在“困难”级别(中文成语测试)上。而 nomic-embed-text 和 mxbai-embed-large 这两款专注于英文的轻量级模型,在跨语言任务上的得分几乎为零。
关键信息检索:模型能在 32K Token 的文档中找到“那根针”吗?
RAG 系统常常需要处理长篇文档,如法律合同、研究论文以及含有大量非结构化数据的内部报告。关键问题在于:嵌入模型能否从周围成千上万字的文本中,准确锁定某一个特定的事实?
**测试方法:**我们选取了长度从 4K 到 32K 字符不等的维基百科文章作为“haystack”(检索文档),并在文档的不同位置(开头、25%、50%、75% 和结尾)插入一条虚构的事实,即“needle”(目标信息)。模型需要根据查询,判断引入针的那一版文档的相似度最高。
示例:
- 针(Needle):“子午线公司(Meridian Corporation)公布了2025年第三季度8.473亿美元的季度营收。”
- 查询(Query):“子午线公司的季度营收是多少?”
- 检索文档(Haystack):一篇关于光合作用的 32,000 字符维基百科文章,针被藏于文章某处。
评分方式:
为查询、包含针的文档以及不含针的文档分别生成嵌入向量。若查询与含针文档更为相似,记为一次命中。对所有文档长度和针的位置的准确率取平均。最终指标:整体准确率 (overall_accuracy) 和退化率 (degradation_rate,即准确率从最短文档到最长文档的下降幅度)。
测试结果:
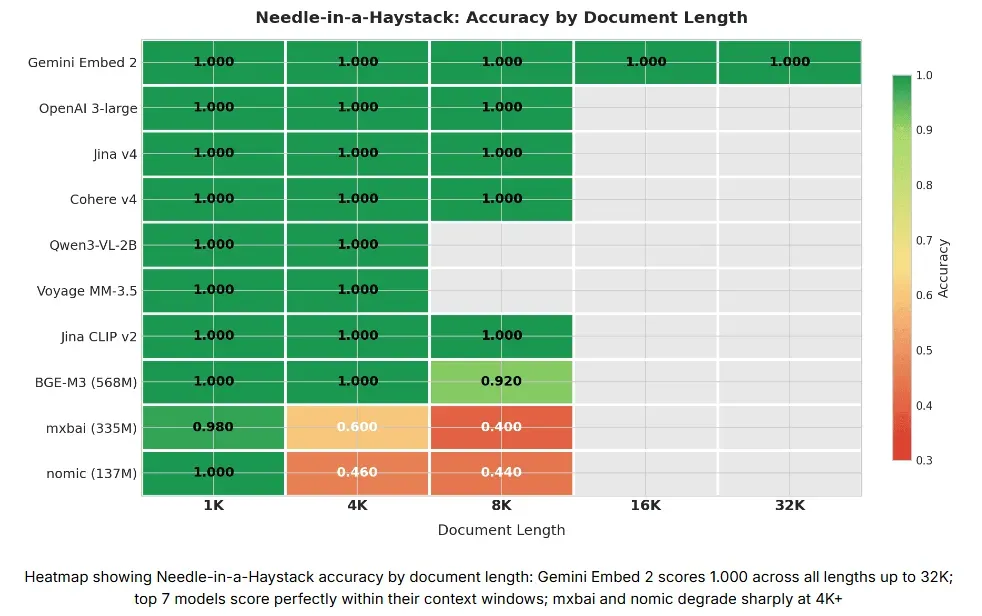
- Gemini Embedding 2 是唯一一个能够覆盖 4K–32K 全量程测试的模型,并且在所有长度下都获得了 1.000 的满分。本次测试中没有其他模型的上下文窗口能抵达 32K。
- 排名前七的模型在各自的上下文窗口内都表现完美。
- 轻量级模型(mxbai 和 nomic)在仅 4K 字符(约 1000 个 token)时,准确率就骤降至 0.4–0.6。
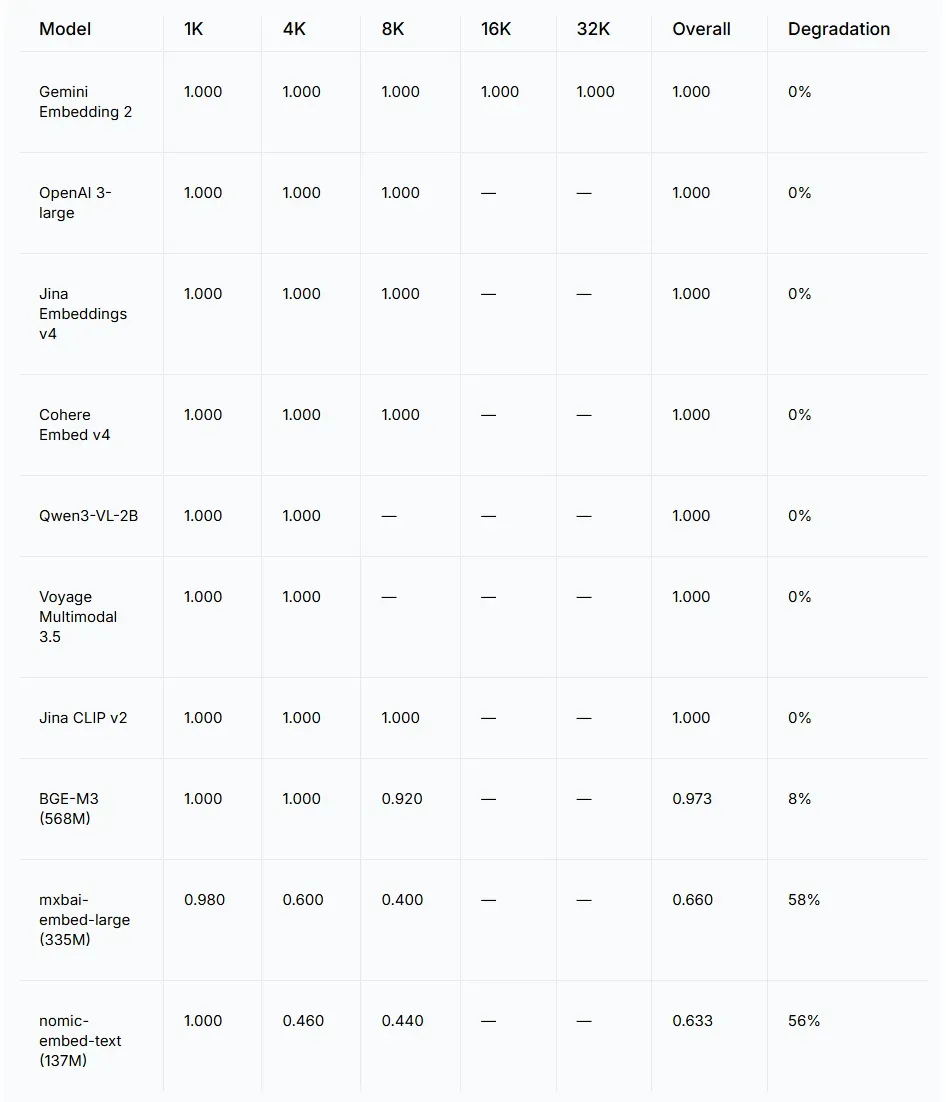
“—” 表示文档长度超出了模型的上下文窗口。
在各自上下文窗口的范围内,排名前七的模型均拿到满分。BGE-M3 在 8K 长度时开始下滑(得分 0.920)。轻量级模型在 4K 字符时得分就已跌至 0.4–0.6。对于 mxbai 来说,这种下降部分原因是其上下文窗口只有 512 个 token,大部分文档内容被截断。
MRL 维度压缩:在 256 维下你会损失多少?
Matryoshka 表示学习 (MRL) 是一种训练技巧,它让向量的前 N 个维度本身就具有语义上的可表示性。比如,一个 3072 维的向量,即使被截断到只保留前 256 维,仍然能保留绝大部分语义信息。维度越少,在向量数据库中的存储和内存开销就越低——将维度从 3072 降到 256,最高可以实现 12 倍的存储节省。
方法
我们使用了 STS-B 基准中的 150 个句子对,每对句子都带有人工标注的相似度分数(0–5)。针对每个模型,我们先生成全维度嵌入向量,然后分别将其截断到 1024 维、512 维和 256 维。
评分方法:
在每个维度层级上计算句子嵌入之间的余弦相似度,然后利用斯皮尔曼等级相关系数(Spearman’s ρ)将模型产生的相似度排序与人工标注的相似度排序进行比较。
什么是 Spearman’s ρ?
它衡量的是两组排序之间的一致性。如果人类认为句子对 A 最相似、B 次之、C 最不相似(即顺序 A > B > C),而模型通过余弦相似度也得出了完全相同顺序,那么 Spearman’s ρ 就会接近 1.0。ρ = 1.0 表示完全一致;ρ = 0 表示无相关性。
最终指标:
- spearman_rho:越高越好,反映模型排序与人类判断的一致性;
- min_viable_dim:在性能下降不超过全维度表现 5% 的前提下,所能使用的最小维度。
结果
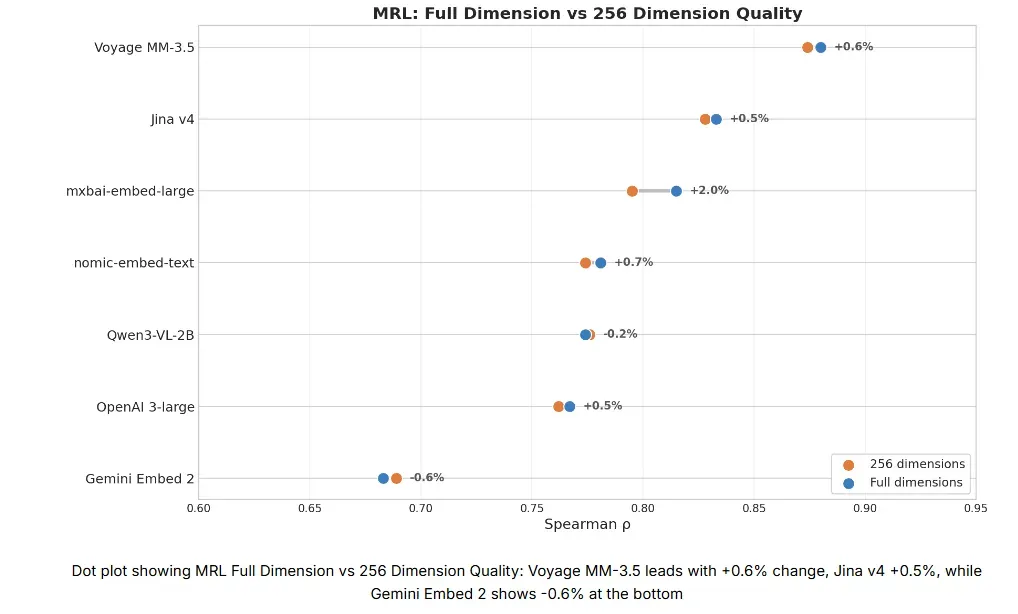 点图对比了 MRL 模型在全维度和 256 维度下的质量差异:
点图对比了 MRL 模型在全维度和 256 维度下的质量差异:
- Voyage MM-3.5 表现最佳,相似度相关性仅小幅提升 0.6%;
- Jina v4 紧随其后,同样提升 0.5%;
- 而 Gemini Embed 2 垫底,截断到 256 维后相关性下降了 0.6%。
如果你打算通过截断嵌入维度来降低 Milvus 或其他向量数据库的存储成本,这一结果至关重要——它表明有些模型(如 Voyage MM-3.5 和 Jina v4)在大幅压缩维度时不仅能维持、甚至略微提升语义质量,而另一些模型(如 Gemini Embed 2)则可能出现性能下滑。
Voyage 与 Jina v4 之所以领先,是因为它们在训练时明确将 Matryoshka 表示学习作为优化目标。这清楚地表明,能否在维度截断后保持质量,关键不在于模型尺寸,而在于是否专门为此进行了训练。
关于 Gemini 的表现需要特别说明:
MRL 排名衡量的是模型在截断后保留语义质量的能力,而非其全维度嵌入的检索性能。事实上,Gemini 在全维度设置下非常强大——先前的跨语言任务和关键信息检索成绩已经证明了这一点。它只是没有针对维度压缩做专项优化。
因此,如果你的应用场景根本不需要降低嵌入维度(例如存储成本不是瓶颈,或者你始终使用完整向量),那么这一 MRL 指标对你来说并不适用。
你应该使用哪个嵌入模型?
没有任何一款模型能在所有测试中独占鳌头。下面是完整的评分卡:
| 模型 | 参数量 | 跨模态 | 跨语言 | 关键信息 | MRL ρ |
|---|---|---|---|---|---|
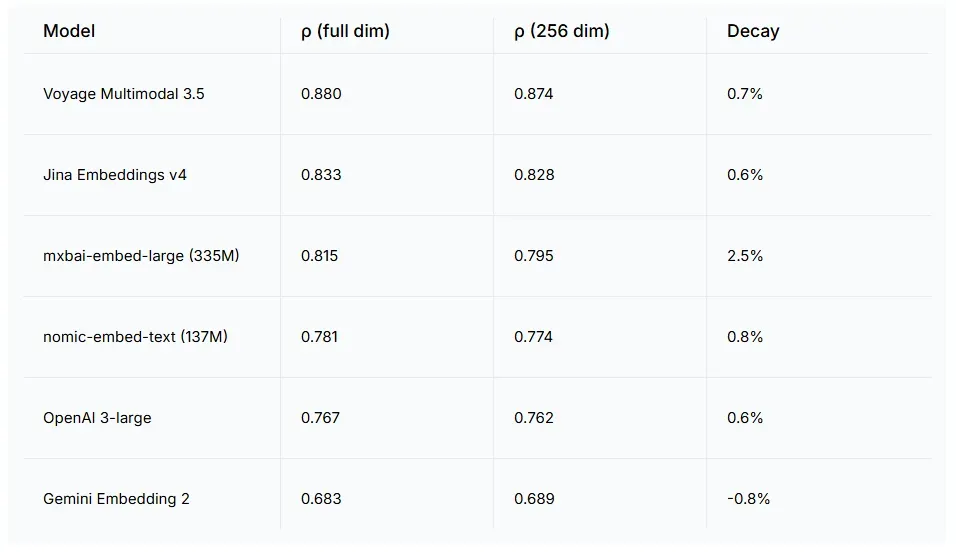
| Gemini Embedding 2 | 未公开 | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | 未公开 | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | 未公开 | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | 未公开 | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
“—” 表示该模型不支持对应模态或能力。CLIP 仅作为 2021 年的基线参考。
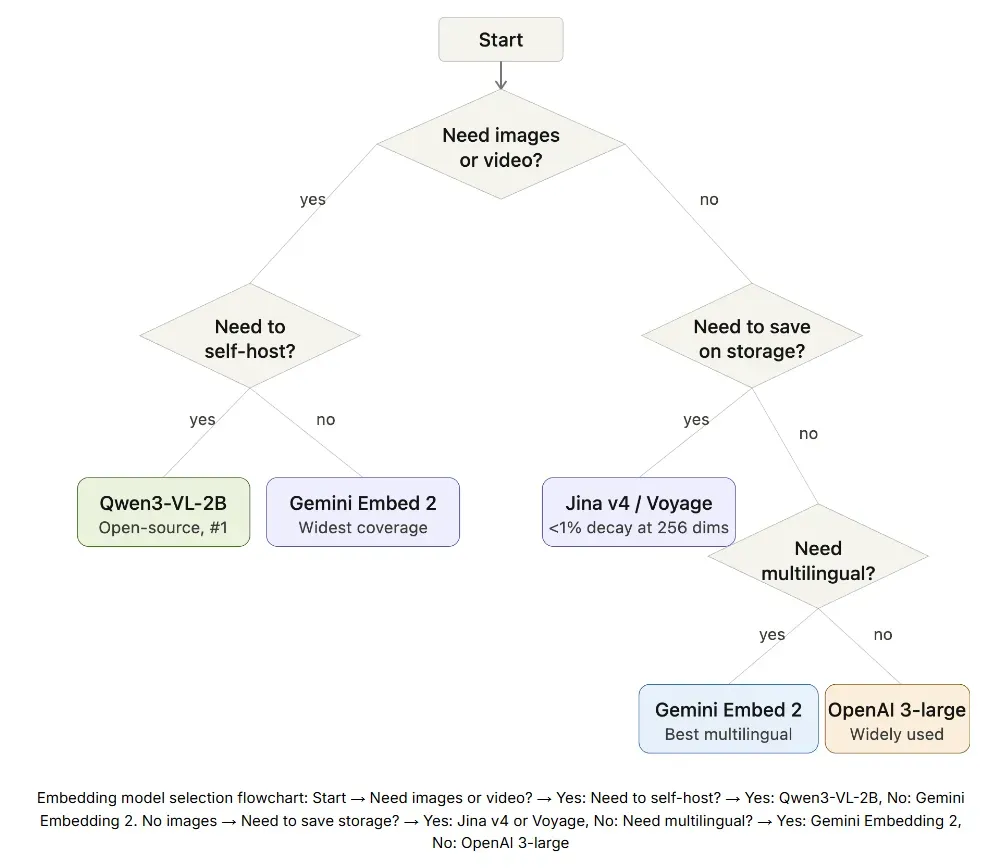
嵌入模型选型流程图:
开始 → 需要处理图像或视频吗?
- 是 → 需要自托管(本地部署)吗?
- 是 → Qwen3-VL-2B
- 否 → Gemini Embedding 2
- 否(仅文本)→ 需要节省存储空间吗?
- 是 → Jina v4 或 Voyage
- 否 → 需要多语言支持吗?
- 是 → Gemini Embedding 2
- 否 → OpenAI 3-large
综合表现最佳模型:Gemini Embedding 2
综合来看,Gemini Embedding 2 是本次评测中整体实力最强的模型。
优势
- 跨语言能力第一(0.997),是唯一在成语级对齐上近乎完美的模型;
- 关键信息检索能力第一(所有长度下均为 1.000,最高支持 32K token);
- 跨模态能力第二(0.928);
- 支持模态最广:涵盖文本、图像、视频、音频、PDF 共五种模态,绝大多数模型最多只支持三种。
劣势
- MRL 维度压缩能力最弱(ρ = 0.668);
- 跨模态精度被开源模型 Qwen3-VL-2B 超越。
如果你不需要维度压缩,在“跨语言 + 超长文档检索”这一组合需求上,Gemini 几乎没有真正的竞争对手。但如果你追求极致的跨模态精度或存储优化,专用模型(如 Qwen3-VL-2B、Voyage、Jina v4)的表现会更理想。
局限性说明
- 未涵盖所有值得关注的模型:例如 NVIDIA 的 NV-Embed-v2 和 Jina 即将发布的 v5-text 原本在候选名单中,但未纳入本轮评测。
- 聚焦文本与图像模态:尽管部分模型声称支持视频、音频和 PDF 嵌入,但这些模态未在本次测试中被实际评估。
- 未覆盖代码检索等垂直领域场景。
- 样本量相对较小:模型之间微小的分数差距可能处于统计误差范围内。
- 结果时效性有限:本文的结论很可能在一年内过时。新模型层出不穷,排行榜会随着每次发布而洗牌。
更持久的投资是构建你自己的评估流水线:
清晰定义你的数据类型、查询模式、文档长度,并在新模型出现时用你自己的数据进行测试。
公共基准(如 MTEB、MMTEB、MMEB)值得持续关注,但最终的决策应当始终基于你的真实业务场景。
本次评测的几个突出发现:
- 跨模态能力:Qwen3-VL-2B(0.945)排名第一,Gemini(0.928)第二,Voyage(0.900)第三。一个开源的 20 亿参数模型击败了所有闭源 API。决定性因素在于模态对齐能力,而不是参数规模。
- 跨语言能力:Gemini(0.997)领先——它是唯一在成语级语义对齐上取得近乎满分的模型。前八名模型得分均超过 0.93。而纯英文的轻量级模型得分接近于零。
- 关键信息保留能力:API 模型和大型开源模型在处理长达 8K 的文本时表现完美。参数量低于 3.35 亿的模型在 4K 长度上就已经开始退化。Gemini 是唯一能够完美处理 32K 长文本的模型。
- MRL 维度压缩能力:Voyage(0.880)和 Jina v4(0.833)领先,在压缩到 256 维时性能损失不到 1%。Gemini(0.668)垫底——它在全维度下表现强劲,但并未针对维度截断进行优化。