2026年AI Coding Plan深度选购指南:国内主流平台对比与省钱策略
本文目录:
PART 1 CodingPlan和TokenPlan
PART 2 国内各家Plan定价
PART 3 国内Plan推荐
全文3000字左右,预计阅读时间8分钟。
DeepSeek V4发布次日(4月25日),Pro版输出价格大幅下调:从24元/百万Token降至6元(降幅75%),缓存命中输入价格降至0.25元。4月26日二次降价:全系缓存输入价格降至原价的十分之一,Flash缓存输入仅需0.02元/百万Token,Pro版叠加2.5折优惠后低至0.025元。
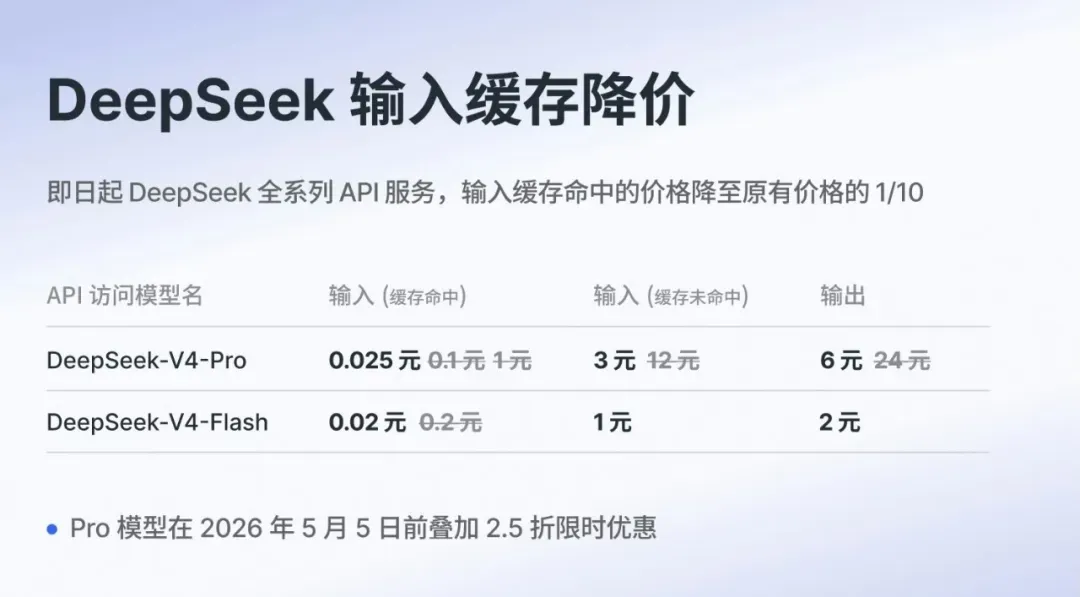
(最新消息:Pro模型2.5折优惠延续至5月31日)
DeepSeek依然坚持API按量计费,而国内其他厂商纷纷推出各自的月度订阅计划。本文将梳理各家现状,关注计费方式是否贴合个人使用习惯,以及响应速度、额度限制和稳定性能否满足编程场景的实际需求。
PART.01
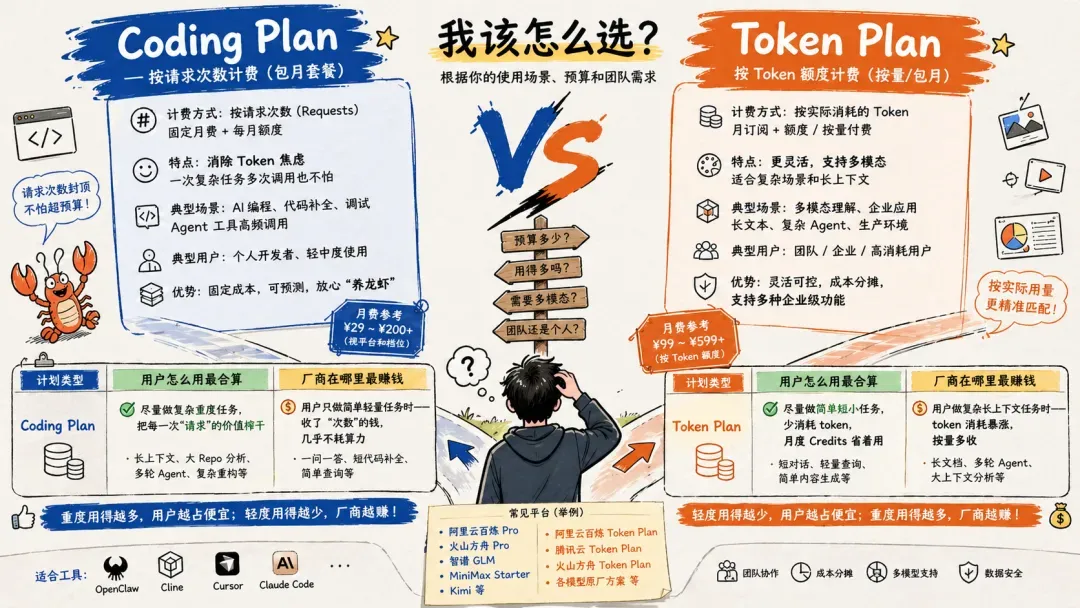
Coding Plan与Token Plan的深层逻辑


采用 Coding Plan 的厂商(按请求次数计费)
方舟(火山引擎)、讯飞星辰、百度千帆、无问芯穹、移动云、MiniMax、天翼云、阶跃星辰
计量方式:每5小时N次 / 每周N次 / 每月N次,每次调用消耗一次配额。
采用 Token Plan 的厂商(按 Credits / Tokens 计费)
智谱(与Claude Pro额度等值)、小米(MiMo Credits/月)、阶跃星辰(Credits/月)、腾讯云、阿里云百炼、九章云极
计量方式:根据实际消耗的 token 或 Credits 从月度池中扣除,长对话、大文档场景消耗更快。

Coding Plan 的经济逻辑
✅ 对用户有利的情形:执行复杂任务,如长上下文分析、大型仓库代码审查,每次调用实际 token 消耗极高,但仍只计为一次请求。
✅ 对厂商有利的情形:用户执行简单任务,例如一问一答、短代码补全,token 消耗极少,但同样被计为一次调用。
Token Plan 的经济逻辑
✅ 对用户有利的情形:轻量查询、短对话时 token 消耗少,月度 Credits 可以使用更长时间。
✅ 对厂商有利的情形:当用户进行长文档处理、大上下文或多轮 Agent 任务时,token 消耗激增,Credits 迅速耗尽。
各厂商推出 Coding Plan 和 Token Plan,本质上是在为不同用户画像、场景和成本结构匹配更合适的计费框架。前者更像是为个人开发者设计的“编程包月”,以请求次数换取成本确定性,缓解 Agent 时代中最令开发者不安的 Token 账单焦虑;后者则延续了更为精细化的通用计费模式,按实际 Token 消耗结算,更适应团队协作、多模态调用和复杂业务体系。
从商业角度看,Coding Plan 是为消除“编程 Agent 账单焦虑”而生的个人友好型方案,Token Plan 则是更成熟、更精准的计费方式,虽然长期来看 Token Plan 存在取代前者的趋势,但目前 Coding Plan 仍有利于吸引高频编程用户、拓展生态,而 Token Plan 更擅长成本控制、能力扩展与企业级管理。两种模式并行,反映出 AI 产品正从面向个人开发者的工具消费,迈向面向团队和企业的系统性供给。
PART.02
国内各家 Plan 定价一览
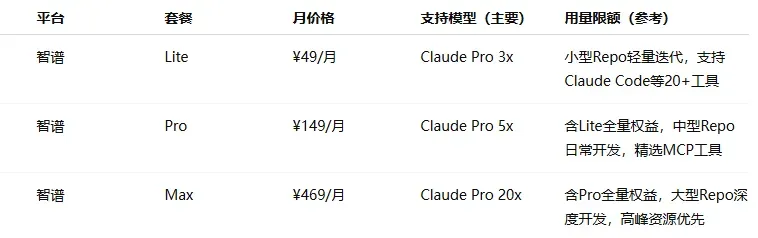
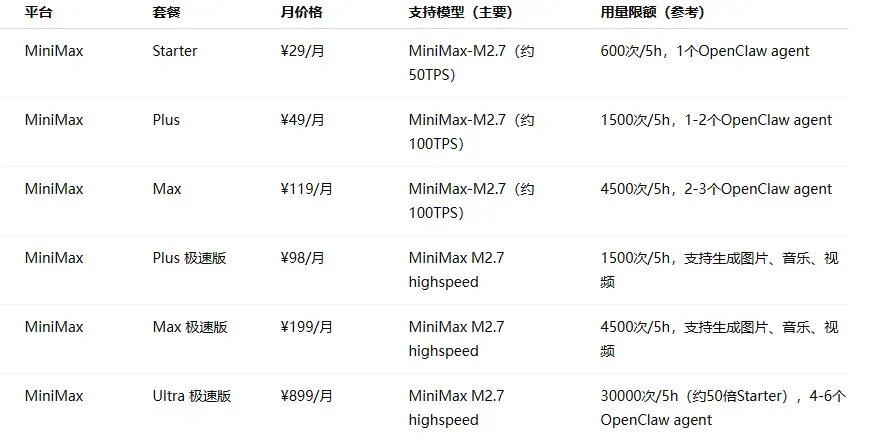
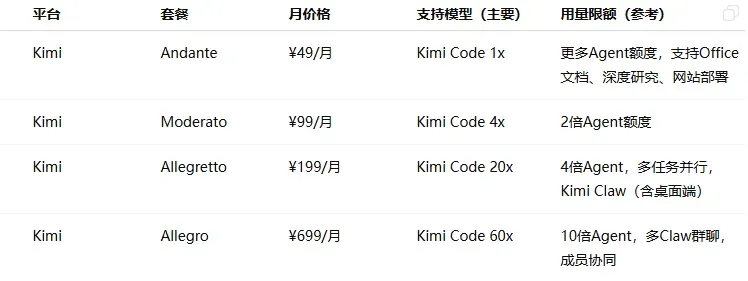
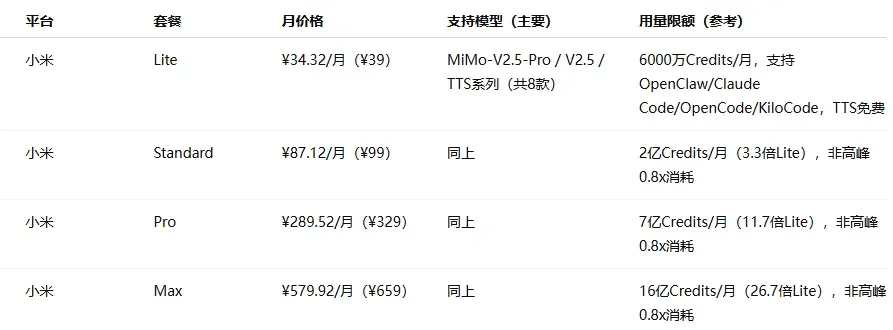



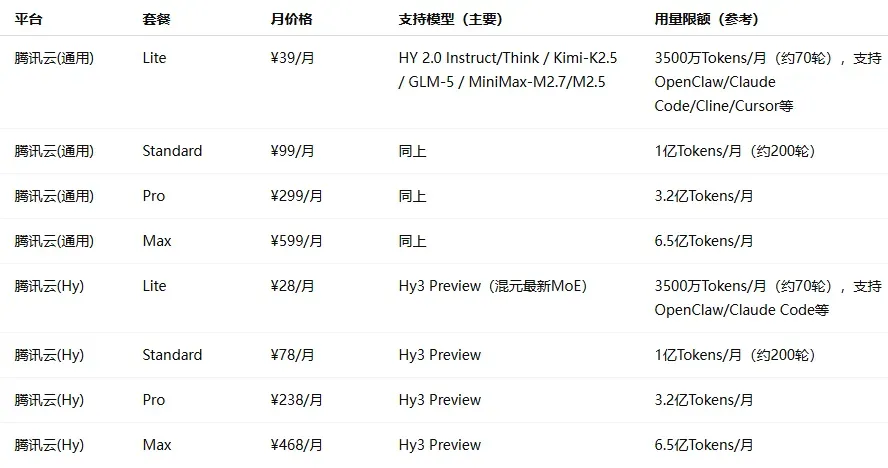
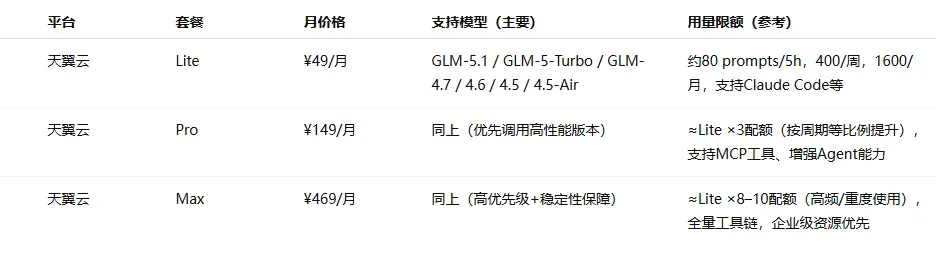
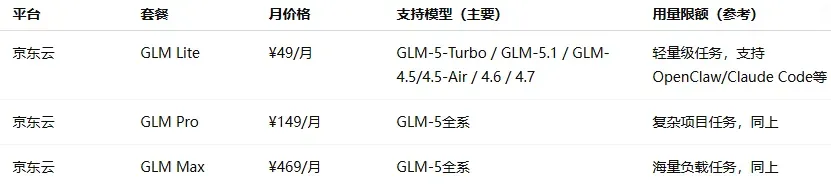


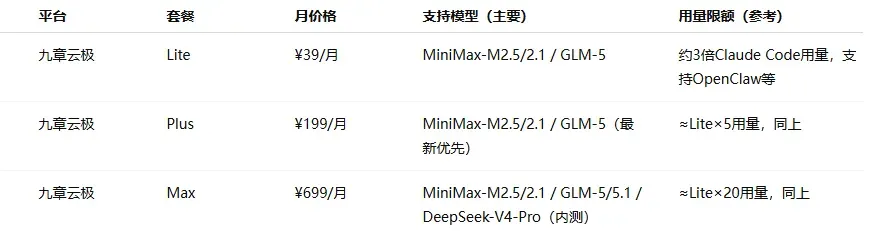
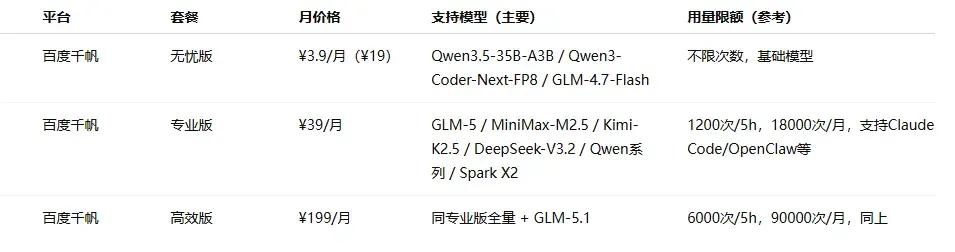
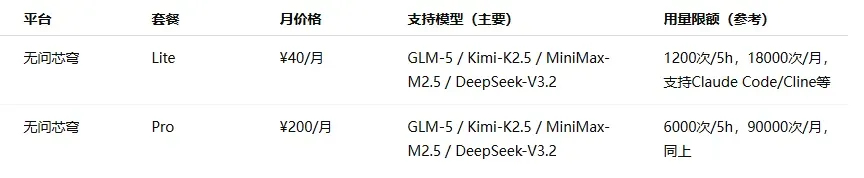
价格区间分布:入门档(¥20–50/月)最为普遍,几乎每家厂商都有覆盖;中级档集中在 ¥99–200 之间;旗舰档从 ¥469 到 ¥899 不等。
各家定位差异明显:模型原厂(如 MiniMax、智谱、Kimi、小米等)更侧重自身主力模型的深度体验和自家生态的闭环;云厂商等平台(如阿里云、火山引擎、腾讯云等)本质上承担的是“模型分发”角色,通过 Plan 打包多种模型,解决接入和切换的成本问题,但在前沿模型的跟进速度上往往较慢。
由于算力紧张和成本压力,部分热门订阅方案如 GLM、无问芯穹等一直处于抢购缺货或直接售罄的状态。
PART.03
国内 Plan 选择建议

阿里百炼已经从 Coding Plan 转向 Token Plan(Lite 版于4月13日停服,Pro版已售罄)。Token Plan 更适于长文本、多模态和重度 Agent 等高消耗场景。
“薅羊毛”的空间几乎只存在于 Coding Plan。Coding Plan 按次计费,重度用户每次请求消耗的算力往往远超厂商预期,相当于用固定价格撬动了超额计算资源。而 Token Plan 则完全不存在这种空间,消耗多少 token 就支付多少费用,厂商的收入与成本始终保持匹配,用得多付得多,不存在“以少博多”的可能。
这正是 Token Plan 逐渐取代 Coding Plan 的根本原因 —— 厂商在这种模式下无法持续盈利。
对于重度用户,建议采用“Coding Plan 主力 + 按量 Token 补充峰值”的混合策略。各家套餐调整频繁,购买前务必小额试用,验证真实的额度消耗情况。
入门/轻度体验
- MiniMax Starter、GLM Lite、Mimo Lite
- 适合预算50元以内,体验国内前沿模型的开发者
中度个人开发者
- 阿里云百炼 Pro、火山方舟 Pro
- 适合日常使用频率较高、需要多模型切换的场景
重度开发者 / 追求代码能力
- 智谱 GLM Pro / Max
- 适合复杂编程任务、Agent 长链路、代码重构与工程化开发
- 代码能力强、工具生态丰富,能够支撑深度使用
多模态 / UI 还原 / 截图编程
- Kimi
- 适用前端开发、截图理解、界面还原以及原生 Agent 使用场景
还需要特别留意的是,云厂商聚合类平台有时会出现响应缓慢、卡顿、延迟高的情况,这些现象在高峰时段尤为突出。Agent 类工具一旦进入多轮调用,等待时间和报错概率都会明显上升。这类平台本质上属于“模型超市”,将多家模型聚合后再次分发,为了压低价格、扩大销量,通常采用更激进的额度设计和更紧张的资源调度,高峰期容易排队,首 Token 延迟拉长、输出变慢,甚至触发限流。
因此,实际选择时需要更为务实。轻度试水可以优先关注 MiniMax 等速度反馈较快的方案;若更看重编程能力和工具生态,智谱 GLM 依旧是非常强劲的选择;如果需要多模型切换与整体稳定性,阿里云百炼通常比火山方舟更稳定一些。对于高频、重度且长期使用的用户,建议将“响应速度”单独作为一项筛选指标进行测试,而非仅仅关注月费与总额度。
