AI热点监控工具AIHOT免费开放|我三年自媒体信息筛选经验全公开
今天,我决定把那个一直陪伴我、帮我追踪AI前沿动态、辅助选题决策的私用网站,正式面向所有人免费开放。
它几乎凝结了我做AI自媒体三年以来,所有关于信息获取的心得与经验。
我把它叫做:AIHOT。
很多朋友可能在过去的文章里,已经见过它的身影。
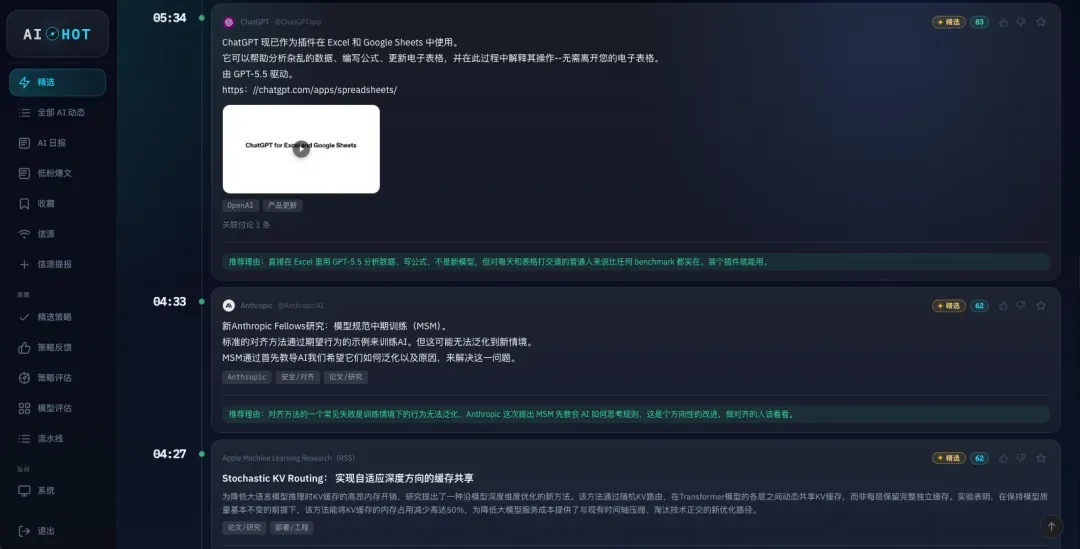
这个工具的功能说起来非常简单,一段话就能讲清:
它帮你以清晰的时间线,持续监控全球范围内与AI相关的所有信息,再通过我亲手打磨的筛选策略,把那些真正值得关注的内容提炼出来。本质上,它就是对信息海洋做了一次深度降噪,帮我们守住本就稀缺的注意力。
这个网站最初是为公司内部服务的,设计它的本心,就是想保护好我自己的创作精力。坦白说,一开始我完全没打算对外公开。
因为对于一个自媒体人而言,信息的时效性和独特性,有时就是安身立命的根本。
但,或许还是产品人的那股执念在作祟吧。我工作这些年来,一直在画原型、做产品,做了很多年。
我心里始终存着一个产品梦,还是想为这个美好的互联网留下一点自己的痕迹。而我最大的成就感来源,无非就是大家喜欢看我的文章,愿意用我做出的东西。
在每篇文章的末尾,我总会写一句:“谢谢你看我的文章。”
这句话,出自我最爱的一部电影——《头号玩家》。
那是绿洲的缔造者哈利迪在最后消散时,对身为玩家的主角说的告别语,也是我心目中全片最动人的一笔。

我也希望自己创造的东西,能被人看见,被人喜爱,仅此而已。
于是,在四月初的某个深夜,连说服自己的过程都没有,突然就动了念头:不如就开放给大家吧,让更多人可以一起使用。
如果它真的能帮到你们,那我会由衷地感到开心。
网站地址在这里:https://aihot.virxact.com/
因为确实没什么预算去买专门域名,所以用的是公司域名进行开发,可能网址会有点难记,还请见谅。
接下来,我想花一些篇幅,好好介绍一下这个产品,以及在我开发过程中踩过的坑和积累的经验。
先聊聊 AIHOT 这个产品本身。
在我看来,这个时代,很多工作已经不再是单纯的执行——执行部分,AI Agent已经能做得相当出色。现在,更多的工作重心落在了信息处理上,我个人习惯将它拆解为三个环节:
获取信息 → 对信息进行分析 → 基于信息做出决策。
对于内容创作而言,“获取信息”就是从信息汪洋中找到值得关注的线索;“分析”则是基于这些线索,看看有什么选题角度可以切入;而最后的“决策”,就是判断这个选题到底值不值得动笔。
目前,AIHOT主要解决的就是“获取信息”这个环节的问题,这也是我过去最大的痛点。如今的世界早已是信息洪流,尤其是在AI时代,垃圾信息铺天盖地。为了保护注意力,我们必须对信息做严格的筛选。
而且,在AI时代的信息黑暗森林法则之下,信源 比 信息 本身更重要。
所以,第一步,必定是筛选信源。
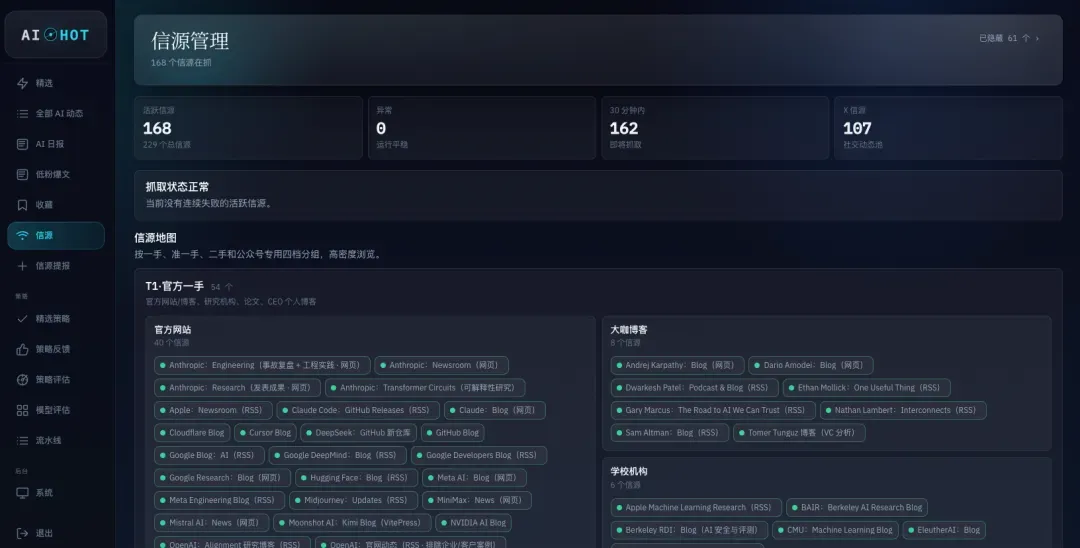
PS:这里我需要非常坦诚地说明一下,上方的截图是带有内部同事权限的AIHOT界面。公司同事和我们MCN签约博主通过企业飞书认证登录后,能看到更多功能。而大家看到的是下面这个无法登录的公开版本,在标签页上会精简很多,许多底层的策略和信息是不对外展示的。这一点目前确实没办法公开,还望大家理解,真的非常抱歉。
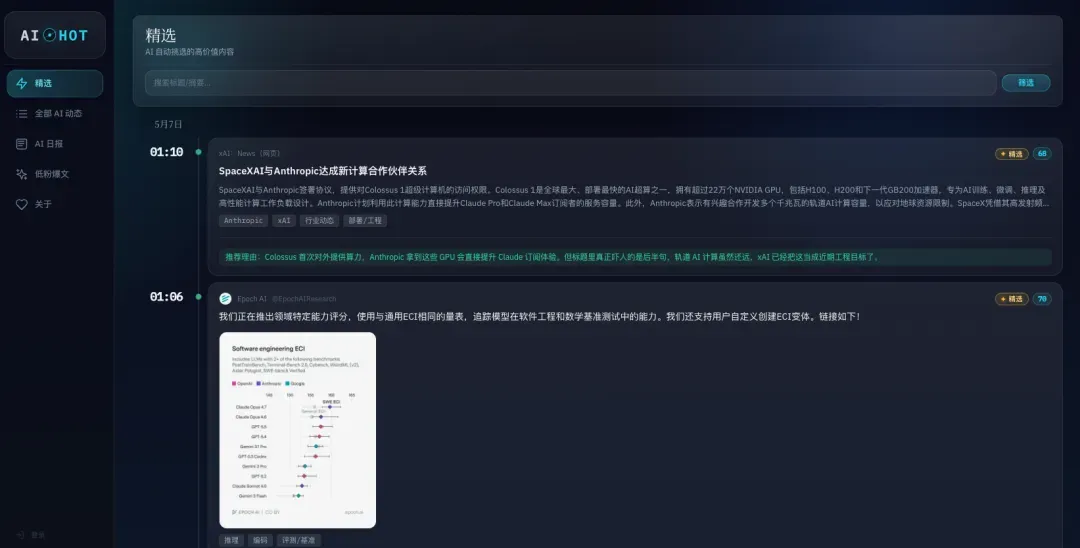
说回信源的部分。
我目前持续监控的信源共有168个,监控手段比较多样:有RSS订阅、有直接解析对方HTML抓取、有调用对方公开的API接口,也有我自己花钱采购的第三方数据接口等等。
每一个信源,都是我亲手逐一筛选过的,秉持着宁缺毋滥和一手信息优先的原则。这个过程大概调优了一个月,真的是靠日积月累慢慢填起来的。
信源等级我自己划分为三类,这和后续的精选策略权重直接挂钩,分别是T1、T1.5和T2。

比如OpenAI的官方博客、Anthropic的工程博客、奥特曼的个人Blog、CMU的博客等等,这些都是最值得关注的官方一手信息,也就是T1。
而这些官方机构的X账号,通常发布的内容比官方网站更多更杂,无用信息的比例也更高,所以我将它们定为T1.5,权重会略低一些。比如OpenAI的官推。
其他所有:技术大佬的个人号(比如奥特曼、达里奥等)、KOL、各类媒体、综合资讯站点,则统一归入T2。
信源挑选完成之后,才是我认为整套系统最复杂的部分——信息处理。
这168个信源其实已经不算多了,但每天抓取回来的信息,仍然有几百条。比如昨天一天,就抓了563条。
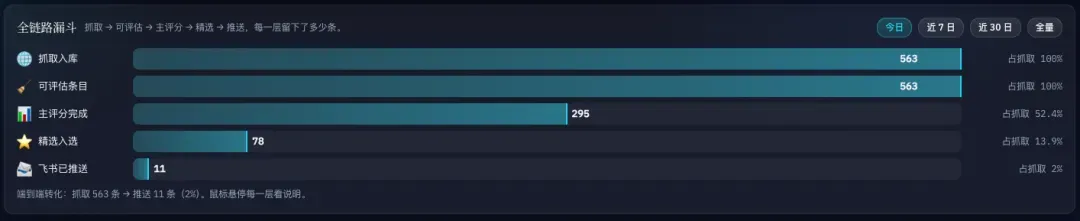
你要相信,这么多条目,不可能有人能逐一看完,这就是纯粹的信息爆炸,毫无意义。
而且其中有很多其实跟AI毫无关系。看上面的漏斗图就知道,大约有一半是无关信息。
比如苹果的Newsroom,它大部分内容不过是各种常规公告,不能因为苹果做了Apple Intelligence,就把苹果的所有新闻都当成AI新闻看待。

所以,这就引出了我最核心的模块:精选机制。
如何从已抓取的靠谱信源中,再提炼出真正值得关注的信息,精准推送到我面前——也就是“精选”这个标签页里那些经过甄选的内容。
你会发现,每条被精选的信息,在信息卡片上都被打上了标签和分数,点击标题还可以跳转到原文。
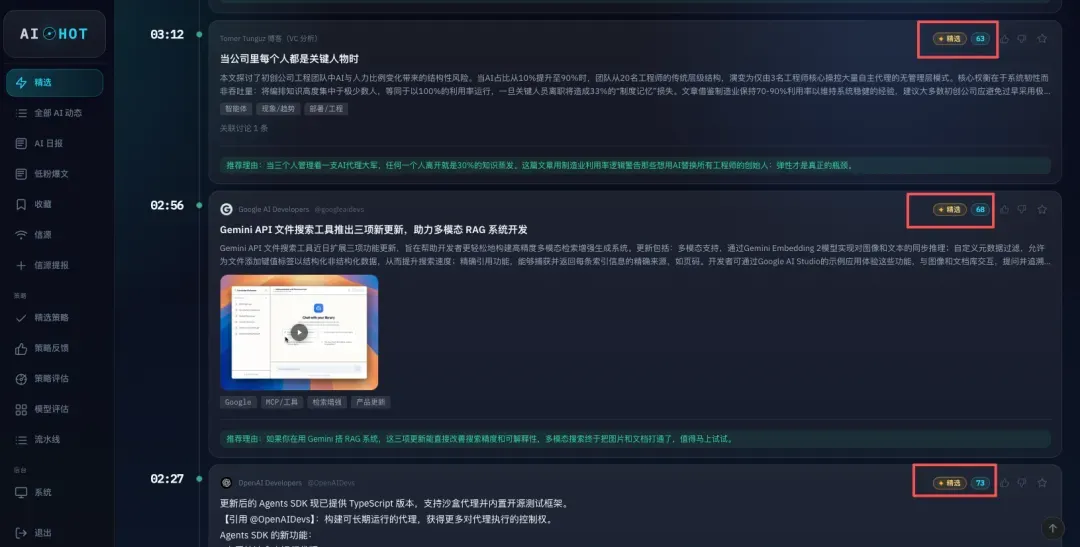
展示出来的效果看起来非常简单对吧?其实二月份刚开始做的时候,我也觉得这事会很简单。
当时我想,这能有多复杂?写个Prompt让大模型判断一下不就完了?让大模型直接给个分数,然后设定一个阈值,过了阈值就值得精选,完事了。
但越做到后面,越发现完全不是这么回事。我想得太天真了,实际情况远比想象中复杂。
这个评分策略,我前后整整迭代了11版。
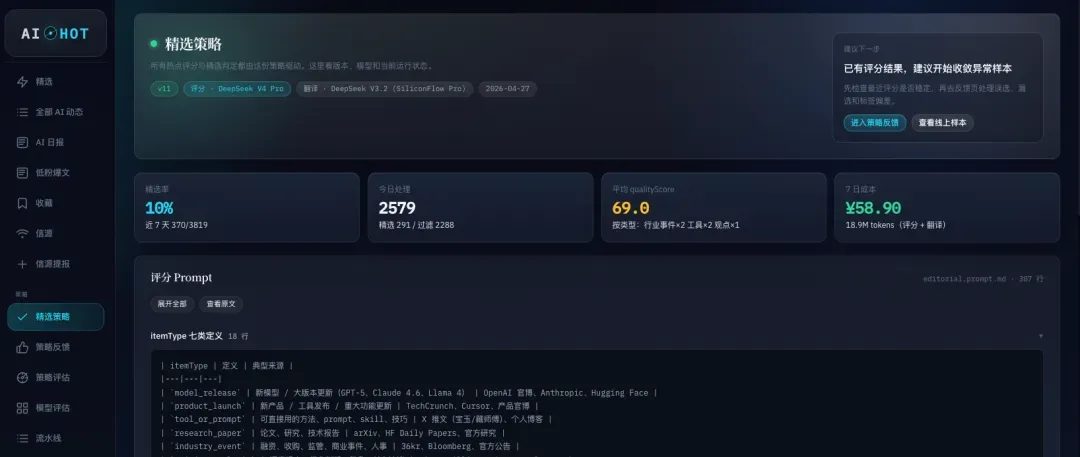
详细的Prompt、多维评分机制以及最终的数值设计,我确实不方便全盘托出,但整体的架构处理流程,我觉得还是可以和大家分享一下的。
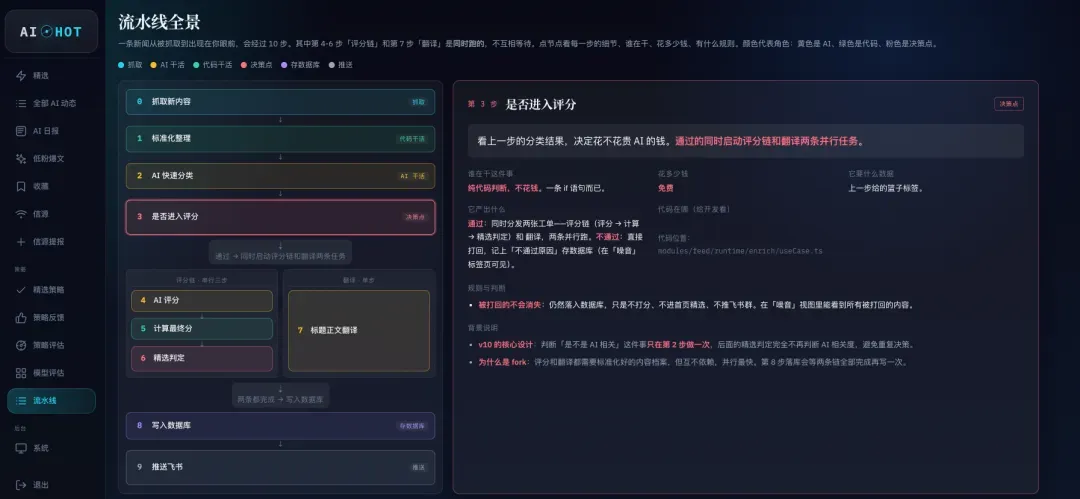
抓取完成后,首先由DeepSeek V3.2进行预筛,判断这条信息是否与AI相关。如果相关,就推送到下一步;如果无关,则直接落库,不再进行后续的评分。
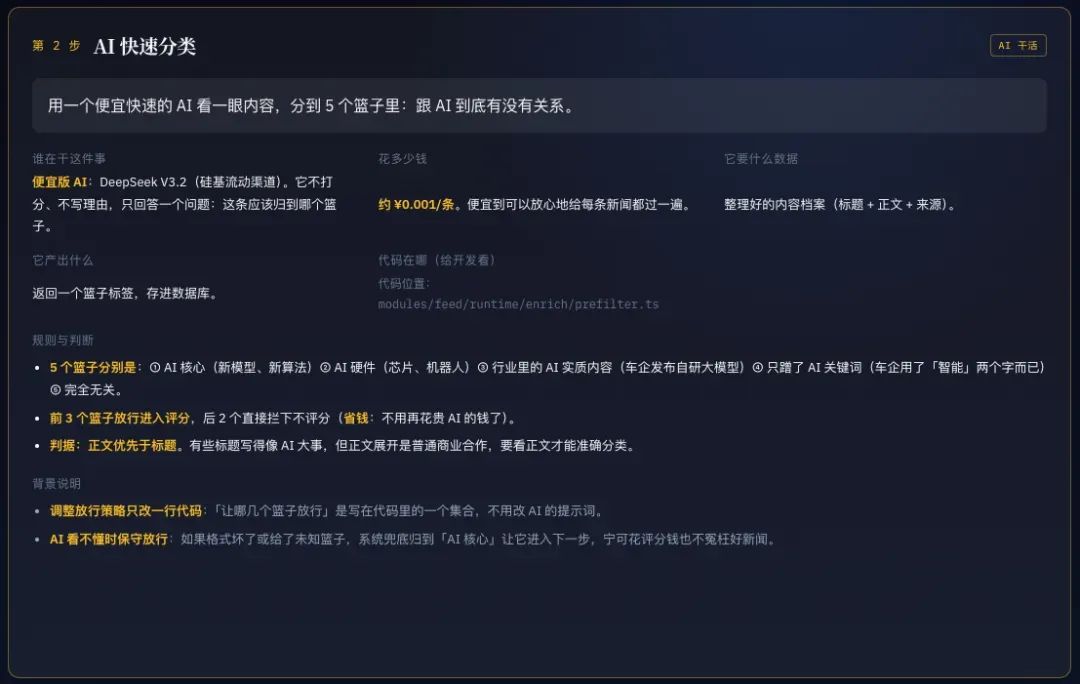
为什么要做预筛?原因很简单,就是控制成本。先用便宜的模型做初步过滤,通过的再交给后面更聪明的模型去做精细评分,这样能省下不少费用。
至于为什么选DeepSeek V3.2,纯粹是因为这个任务非常简单,DeepSeek V3.2这个智力水平的模型已经绰绰有余。而且我用DeepSeek V3.2几乎等于免费——去年过年时我蹭了一波DeepSeek的热度,推了一下硅基流动,那时候积累的邀请奖励换成Token,到现在将近十万人民币的量还没用完。
预筛通过之后,就是大模型并行进行评分和翻译+摘要。
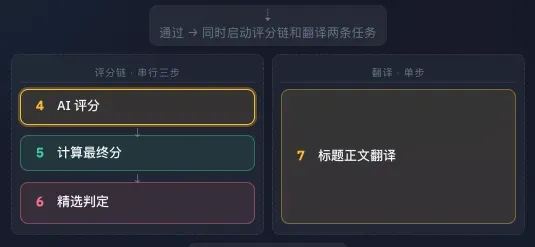
这个AI评分的环节,实际上是我踩过的最大的坑。
最开始二月份启动时,我的想法是:
模型这么强,我直接写个Prompt让它给每条新闻打分就好了。判断重要不重要,它能行;判断分类,它能行;甚至判断读者爱不爱看,也能全交给它。
我写好了第一版Prompt,跑了一周。
结果一塌糊涂。一些极其硬核、让人三秒钟都看不下去的论文,动不动就被打到90分;而Sam Altman转发了一条OpenAI实习生的鸡汤推文,模型居然给出87分。
同一件事被官方源、X账号、IT之家等不同媒体报道了七遍,这七遍全部挤进了精选。
这真的太离谱了。
于是我开始向Prompt里疯狂加规则。
大佬转发要降分,同一事件已被报道过要降分,营销软文必须压到50分以下,国内大公司发布模型不能仅因为英文环境就低估……
加着加着,Prompt膨胀到了三百多行。
到了三月份,我做了一件当时自认为很里程碑的事情:引入了人类反馈标注机制。我和同事每天点选几条精选信息,标记“对”或“不对”,系统则把反馈喂回去,让它持续迭代。
我还为这个迭代机制配了一个内部评估流程:每次AI评分规则升级,我都会用新规则重新评估过去500条新闻,对比新版本和老版本谁选得更准。
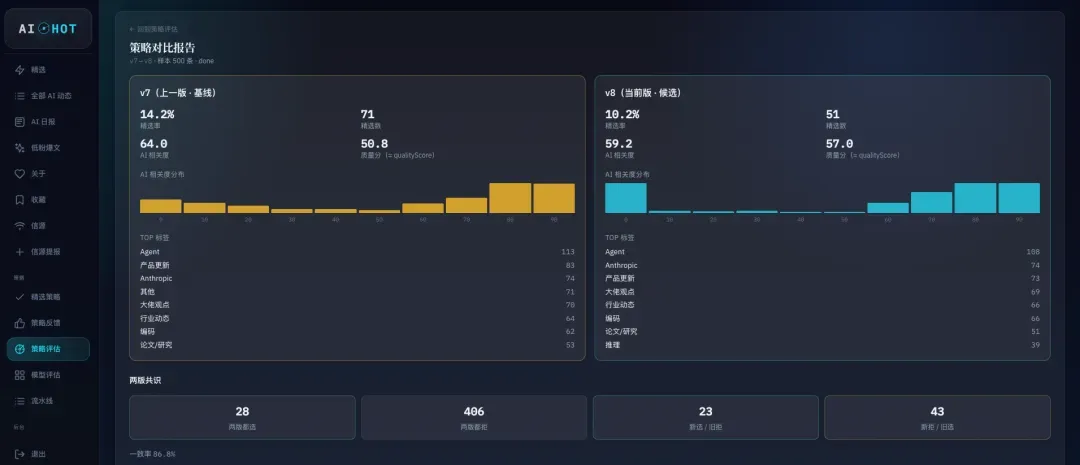
听起来很酷对吧?模型 + 人类反馈 + 自动评估 + 持续迭代,整套标准的AI产品实践。
但跑了一周之后,我几乎崩溃了。因为你要知道,规则加得越多,模型的泛化能力反而越差,它变得越来越笨。为了弥补,我又加了更多规则,结果选得更离谱了。
为了解决这些问题,我又引入了双维度评分和实体热度感知(让模型知道哪家公司最近热度高),但效果直接崩盘。
V7到V8策略的迭代,是一次彻头彻尾的负向优化。
我选择全面回滚,推倒重来。
那一刻,我忽然想起自己曾经写过的一篇文章:
你绝不能把所有事情都甩给模型:打分是它、权重计算是它、打标是它、判断是否精选的还是它。
所以我直接推倒重构,重新梳理了流程和机制。一个核心原则:能用代码处理的,一概不用模型。
现在,大模型评分只做一件事,就是依照我的Prompt,为每一条信息打出5个维度的细分分数,不再产出最终综合分。这样既准确,又客观。
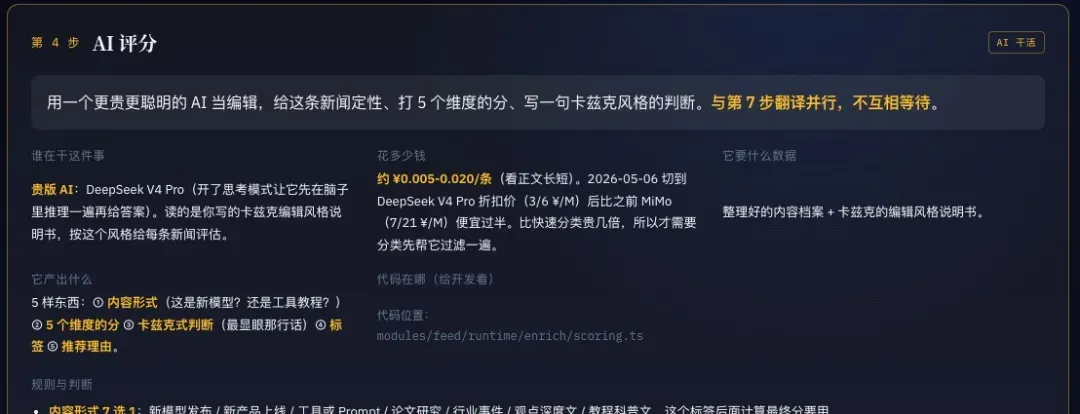
其他事情,模型完全不用管了。Prompt也从六百多行直接缩减到两百行。
我目前使用的打分模型是DeepSeek V4 Pro,它的世界知识极强。在这种需要调用世界知识进行判断的任务下,再加上费用打折,性价比真的很高。
打完分之后,所有根据信源重要程度、类型、所属公司等维度的权重再计算,也不再由模型负责了。我直接用代码写好明确的计算公式,拿着大模型给出的五个维度分,通过公式重新计算,得出最终的质量分。
现在首页上展示的,就是计算后的最终分值。
而一条信息是否值得精选,也不再由模型判断,而是根据质量分,再由代码判断是否达到了每个分类下的精选阈值。
比如,OpenAI官网发布的内容,60分的权重可能已经非常值得一看;但像我这样的AI博主做的一篇转发评测,严格来说属于二手信息,60分可能只是普通水平,你就不一定需要看到它。
因此,如果过了阈值,就进入精选;如果没过,就不展示。
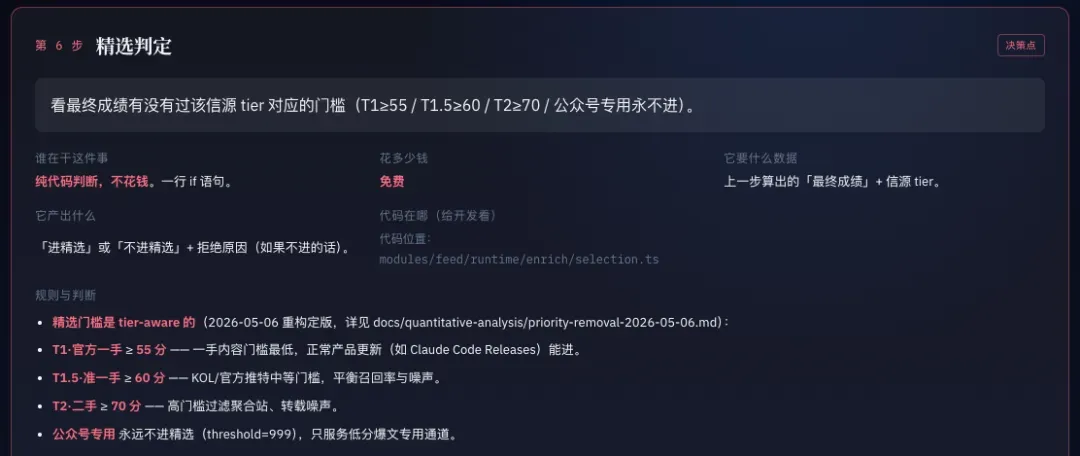
用代码控制的最终效果,就是极度的可控与可调。
现在的数值设计,是我用量化方式跑了几百次数值回测后调出来的,目前我自己还比较满意。如果以后感觉不好,调整起来也非常简单:在公式里改一下某个权重、调整某个参数,或者修改某个类别的阈值门槛,几秒钟的事。
这套机制,本质上就是模拟我自己作为内容创作者,每天刷信息流时脑子里那套隐形的过滤逻辑。
在评分与精选之外,还有一套东西,我称之为事件聚类系统。
比如昨天,GPT-5.5 Instant发布,除了OpenAI官方会报道,还有一堆人会同时报道。
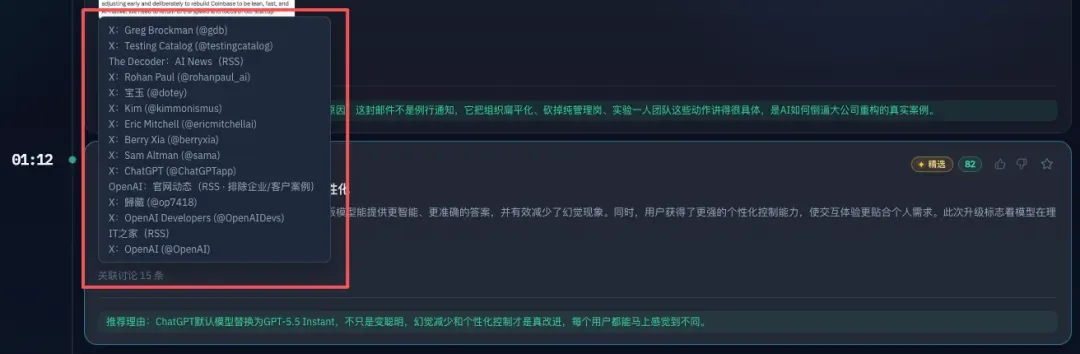
如果不做聚类,精选页上同一个事件可能就会冒出七八条甚至十几条,那体验绝对是灾难。
所以,在设计AIHOT时,我会用embedding把语义相近的条目汇聚到一个事件簇里,然后在簇内选一条最权威的作为主条目,其它的则折叠进去。
精选页上,同一件事只会展示一条,点开后才能看到所有相关的报道。
官方源发布的永远优先成为主条目。官网的优先级高于官方推特,官方推特又优先于KOL。
还有一个AI日报的功能,是前段时间顺手做的小功能。

大概每天早上北京时间8点,系统会自动把过去24小时的精选内容,再做一次轻度的提炼,按版块整理出一份日报。
版块分为五块:模型发布/更新、产品发布/更新、行业动态、论文研究、技巧与观点。
你每天早上起来,打开日报页面,一份干干净净的“AI世界昨日要闻”已经等在那里了。
而且,这份日报完全不需要任何大模型来生成。因为所有的精选、分类、翻译,在信息入库的那一刻就已经全部做完了。日报只需要把已经处理好的条目按类型分桶,再按分数排个序,就完事了。
我测试过速度,每天早上只需要一秒钟,日报就能生成并展示,而且质量我觉得也还算不错。
AIHOT还有不少体验层面的细节,受限于篇幅,这里就不展开了。我虽然不是专业的开发或程序员,这个网站上可能也隐藏着一些我不知道的诡异bug。但我毕竟做了快十年的用户体验设计,打磨细节、抠各种让用户更顺畅的点,我觉得我还是擅长的。
关于AIHOT未来的计划,我一定会继续开发下去。因为还有好多想法,受限于我的业余时间,一直没来得及做。
比如趋势预测功能,可以抓取那些处于加速曲线爆发初期、还没有特别热的事件。
比如给每条信息拉出过去一个月相关的上下文脉络。
比如我自己做一个AIHOT热度指数,等等。
不过未来的这些进阶功能,确实可能没办法向大家全量开放,大概率会是公司员工以及我们MCN签约博主的专属。
但我会尽力去寻找平衡,毕竟,我还是希望有更多人能用上我的产品。
如果大家有任何建议或反馈,都可以在AIHOT的网页上直接留言。留言会实时推送到我的飞书,我绝对能第一时间看到。