30分钟快速上手AI Agent:从概念到实践构建智能体闭环系统
前几天,我分享了两篇关于Agent的详细课件,分别是《做一个Agent-上》与《做一个Agent-下》。这些内容引起了许多同学的关注,但也产生了一个有趣的现象:文章的分享数量远超阅读量,甚至达到了近2倍的差距。
这或许说明了一个问题:大家认为这些知识非常有用,但可能因为内容过于详实而望而却步,更希望推荐给朋友去学习。后续也确实有粉丝反馈,内容扎实,但希望能更精炼一些。
因此,在今天的文章中,我将尽量化繁为简,用更轻松的方式阐述核心概念。
什么是Agent
2025年被誉为AI Agent的元年,而2026年则被明确为Agent发展的“大年”。例如,近期备受关注的OpenClaw便是一个典型的Agent。可以预见,未来将有各式各样的Agent如雨后春笋般涌现,它们很可能深刻地改变我们的工作与生活方式。
尽管“Agent”一词出现的频率极高,但若要追问其确切含义,能清晰阐述的人却不多。
“Agent”一词源于拉丁语“agere”,本意为“去做、去行动”。从概念上讲,Agent就是一个行动者,一个能够主动感知环境、围绕目标自主决策并执行动作的实体。
在专业领域,AI Agent(智能体)正是将这种“行动者”的能力赋予了AI系统。它不再是被动响应指令、仅仅提供答案的模型,而是一个能够自主感知、决策和执行的智能实体。简而言之:传统大模型擅长“回答问题”,而Agent擅长“完成任务”。
它可以理解你的目标,自动拆解步骤、规划路径、调用各种工具,一步步地将事情执行完毕。
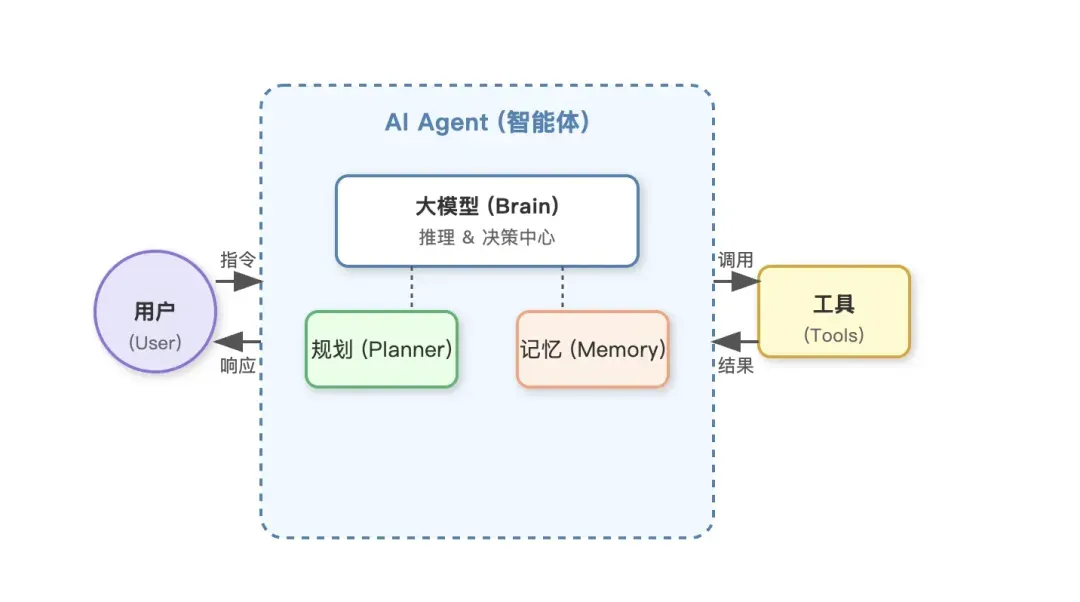
不过,最近我看到了另一张更为经典的图,它清晰地解释了Agent是什么,并隐约揭示了其发展规律:Agent是一场工作流(Workflow)复杂度的迁移,是泛化能力极强的、可被智能驱动的Workflow,或者说Agentic Workflow。
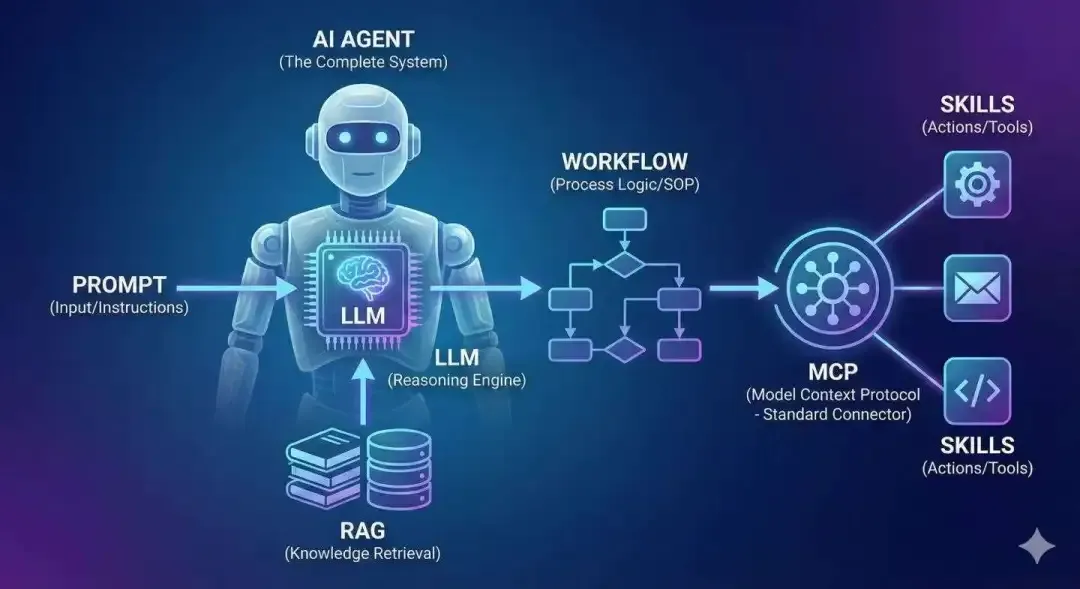
理解这句话,就理解了什么叫“让AI自己去干活”。本质上,Agent不过是模型使用范式中的一种罢了。
如何让AI做事
当前的主流大模型,如GPT、Qwen、DeepSeek等,学习了海量的公开知识,具备强大的推理和逻辑能力。它们的核心执行逻辑是:根据我们输入的内容,经过内部计算(推理)后,输出一段文本结果。
以调用DeepSeek官方API为例:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
从这个简单的例子可以看出:
- 模型接收的
messages包含了系统提示和用户问题。 - 模型最终只输出一段文本(
content),然后交互就结束了。
这意味着,大模型本身不会执行任何实际的操作,它只会“告诉你怎么做”,而不会“替你去执行”。
那么,如何才能让AI真正完成一项任务呢?答案是:为AI提供执行任务所需的能力(即工具)。
如果在没有AI的情况下,我们也能完成某件事,那就说明我们已经具备了相应的工具或函数。接下来,我们只需要把这些函数“告诉”AI,并引导它在合适的时机选择并调用正确的函数。
下面,我们就通过开发一个“旅游规划助手”智能体的具体案例,来详细讲解如何实现这一过程。
开发一个Agent
我们将通过开发一个旅游规划助手智能体,来逐步拆解让AI真正“做事”的步骤。
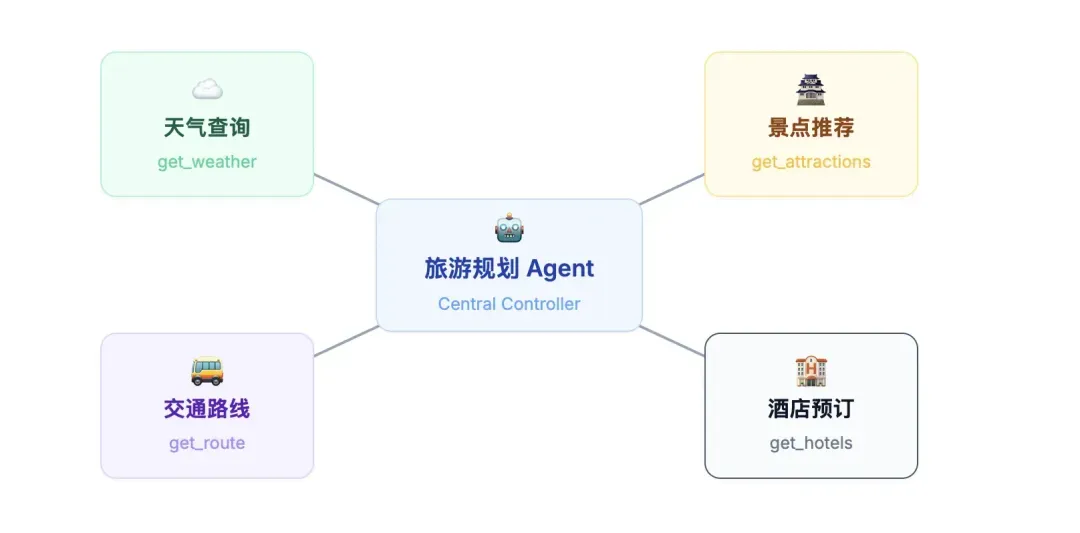
第一步:设计功能与函数
在引入AI之前,我们必须确保即使没有AI,用户也能独立完成旅游规划。因此,我们首先要设计好旅游助手所需的核心功能,并实现对应的函数:
- 查询天气:根据目的地获取未来几天的天气预报。
- 查询热门景点:列出目的地的热门景点及其简介、门票等信息。
- 查询酒店:根据目的地和日期,推荐附近的酒店及价格。
- 查询公交路线:规划两个地点之间的公共交通路线。
在没有AI的情况下,用户需要手动依次执行这些查询操作:先查天气决定出行时间,再查景点筛选目标,接着查附近酒店,最后规划交通路线。整个过程虽能完成,但无疑较为繁琐。
第二步:让AI接管流程
我们的目标是,用户只需说一句“帮我规划下周去北京的行程”,AI就能自动调用上述函数,获取所有必要信息,并整合成一份完整的旅游计划。
那么,我们需要做什么呢?关键在于系统提示词(System Prompt)。我们需要在提示词中明确告诉AI:
- 它的身份和任务是什么。
- 它可以调用哪些工具(函数),这些工具的名称和参数是什么。
- 它应该如何以结构化的方式(例如JSON)来告诉我们它想调用哪个工具。
- 它如何判断信息是否已收集充足。
这里有一个问题:为什么需要JSON格式? 因为AI模型默认输出的是自然语言文本。为了让我们的程序能够精确理解AI的意图并执行对应的函数,我们需要AI以程序易于解析的结构化格式来输出其决策。JSON是目前最通用和友好的选择。当然,理论上XML或其他格式也可行,核心是“模型易输出,程序易解析”。
第三步:系统提示词示例
以下是一个为旅游规划助手设计的系统提示词示例,它明确要求AI以指定的JSON格式返回决策:
你是一位专业的旅游规划助手。你的目标是根据用户的需求,提供详尽、合理的旅游行程建议。
你有以下工具可以使用,每个工具都有对应的名称和参数。
get_weather(目的地, 日期) - 查询目的地天气预报。
get_attractions(目的地) - 查询热门景点列表(含简介、门票、开放时间)。
get_hotels(目的地, 入住日期, 退房日期) - 查询推荐酒店及价格。
get_route(起点, 终点) - 查询公共交通路线。
你必须输出一个 JSON 对象,不得包含其他任何文本。JSON 对象应包含以下字段:
action: 字符串,值为 “call_tool” 或 “respond”。
tool: 当 action 为 “call_tool” 时,此处填写要调用的工具名称(如 “get_weather”);否则留空。
parameters: 当 action 为 “call_tool” 时,此处填写调用工具所需的参数对象(例如 {"目的地": "北京", “日期”: “2025-03-15”});否则为空对象。
isSufficient: 表示当前收集到的信息是否足够完成用户的需求。如果为 true,则下一步应直接回答用户;如果为 false,则还需继续调用工具获取更多信息。
message: 当 action 为 “respond” 时,此处填写你要对用户说的自然语言回答;否则留空。
工作流程:
1. 你需要理解用户的请求,提取关键信息。
2. 如果需要调用工具获取信息,你需要将action的值设置成“call_tool“同时设置 parameters 的值,并将 isSufficient 设为 false。
3. 当你已经获得足够信息,可以回答用户的问题,你需要将action设置为“respond”,在 message 中给出完整的旅游规划建议,并将 isSufficient 设为 true。
第四步:实现循环调用
至此,就进入了Agent的核心部分——循环执行。我们将用户问题和系统提示词发送给AI。AI推理后,会按照约定格式输出JSON。我们的程序解析这个JSON:
- 如果
action是”call_tool”,则根据tool和parameters调用对应函数,将函数执行结果作为新的消息附加到对话历史中,然后再次请求AI。 - 如果
action是”respond”,则将message内容返回给用户,结束本次任务循环。
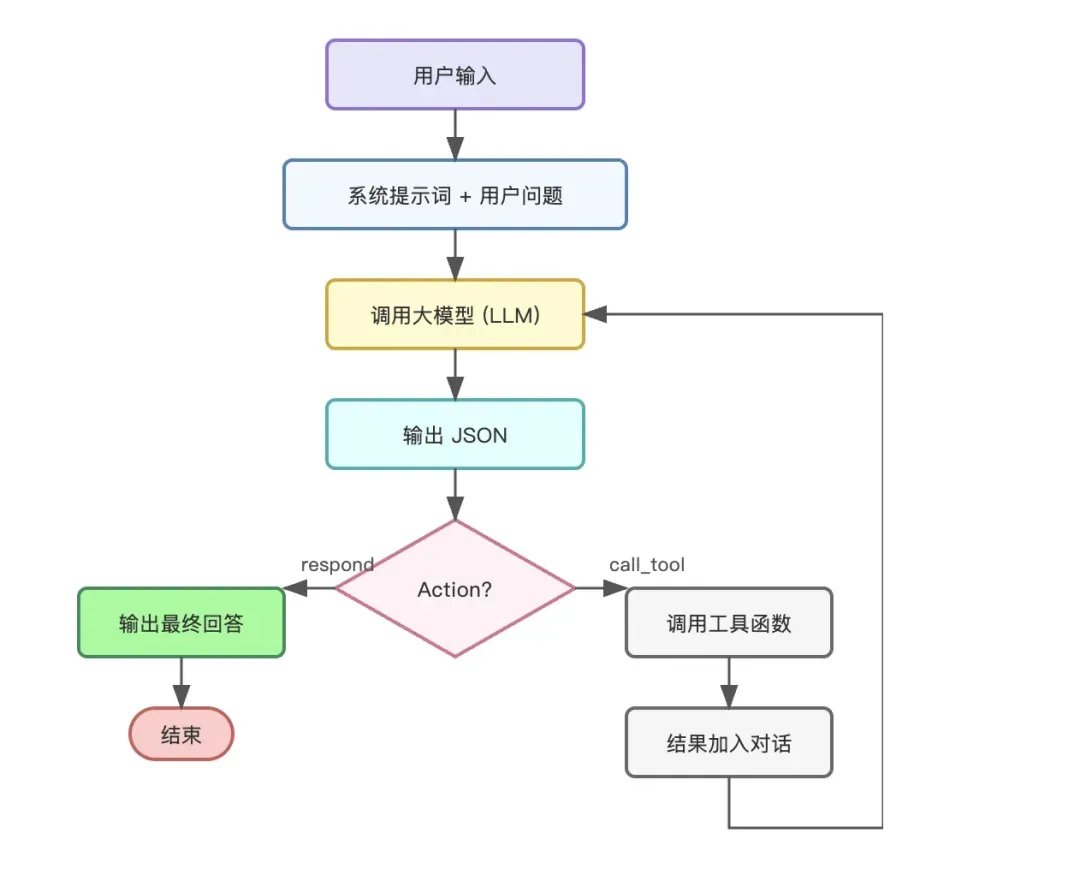
以下是一个简化的Python伪代码示例,展示了这个循环过程:
import json
import openai
def get_weather(destination, date):
return f"{destination} {date} 天气晴朗"
def get_attractions(destination):
return f"{destination} 的热门景点有故宫、颐和园..."
# ... 其他工具函数实现
# 系统提示词(内容同上)
system_prompt = "..."
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": “帮我规划下周去北京的行程“}
]
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
while True:
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
stream=False
)
# 解析 AI 返回的 JSON
try:
decision = json.loads(response.choices[0].message.content)
except:
print(“模型输出非 JSON,错误处理...“)
break
if decision[“action”] == “call_tool”:
tool_name = decision[“tool”]
params = decision[“parameters”]
# 调用对应工具
if tool_name == “get_weather”:
result = get_weather(**params)
elif tool_name == “get_attractions”:
result = get_attractions(**params)
# ... 其他工具调用
# 将工具执行结果加入对话历史
messages.append({"role": “tool”, “content”: result, “tool_call_id”: tool_name})
# 继续循环,让AI基于新信息做下一步决策
elif decision[“action”] == “respond”:
print(decision[“message”])
break
看到这里,一个简单的旅行助手智能体就开发完成了!用户只需输入一句话,它就能自主调用工具,完成一次完整的规划任务。
回顾一下,我们使用了哪些技术?其实非常简单:
- 大模型:作为核心的推理引擎。
- 系统提示词:定义了工具、规则和输出格式。
- 预置函数:提供实际执行能力。
- 解析JSON的循环代码:将模型的决策转化为实际的函数调用和执行。
其核心可以概括为 模型 + 工具。通过提示词告知模型可用的工具及其用法,模型便能自主规划并调用工具来完成任务。
然而,将工具的定义和说明全部写在提示词里,在工程上并不优雅:
- 提示词会变得异常冗长,难以维护。
- 工具数量增多时,修改和版本管理会非常麻烦。
- 模型的输出格式完全依赖文本约束,不够稳定和可靠。
于是,在2022年,论文《ReAct: Synergizing Reasoning and Acting in Language Models》开始系统性地探讨这种模式的工程实现。随后,各大模型厂商纷纷推出了官方的 Function Calling(或 Tools Calling) 机制。
Function Calling 是一种为大模型设计的原生工具调用接口。它允许开发者以结构化的方式向模型“注册”工具,模型则会以标准化的格式返回调用请求。这省去了我们手动解析JSON的麻烦,也让工具的管理和使用变得更加清晰、高效。接下来,我们就详细介绍如何使用Function Calling来规范地开发智能体。
Function Calling
Function Calling 最早由 OpenAI 在2023年6月13日的API更新中以标准化接口的形式正式引入。随后,其他主流模型提供商(如 Anthropic Claude、Google Gemini、Qwen、DeepSeek 等)也迅速跟进,使其成为了现代大模型的一项标配能力。
我们来看看如何使用 DeepSeek 的 Function Calling 来重构之前的旅行规划助手,代码会变得更加清爽。
1. 定义工具(函数)
我们需要按照模型API要求的格式来定义工具。每个工具包含类型、名称、描述和参数结构(JSON Schema)。
tools = [
{
“type”: “function”,
“function”: {
“name”: “get_weather”,
“description”: “查询目的地的天气预报”,
“parameters”: {
“type”: “object”,
“properties”: {
“destination”: {
“type”: “string”,
“description”: “目的地城市名称”
},
“date”: {
“type”: “string”,
“description”: “查询日期,格式为 YYYY-MM-DD,如果不指定则返回未来几天的天气”
}
},
“required”: [“destination”]
}
}
},
# 其他函数(get_attractions, get_hotels, get_route)以同样格式定义
]
2. 简化系统提示词
由于工具信息已通过tools参数传递,系统提示词可以专注于定义AI的角色和任务目标,无需再详细描述工具。
system_prompt = “你是一位专业的旅游规划助手。
你的目标是根据用户的需求,
调用可用的工具获取信息,并整合成一份详尽的旅游行程建议。“
3. 实现调用循环
我们需要循环与模型交互:如果模型返回工具调用请求,程序就执行对应工具,并将结果添加到对话历史中,然后继续请求模型;如果模型返回最终答案,则输出给用户。
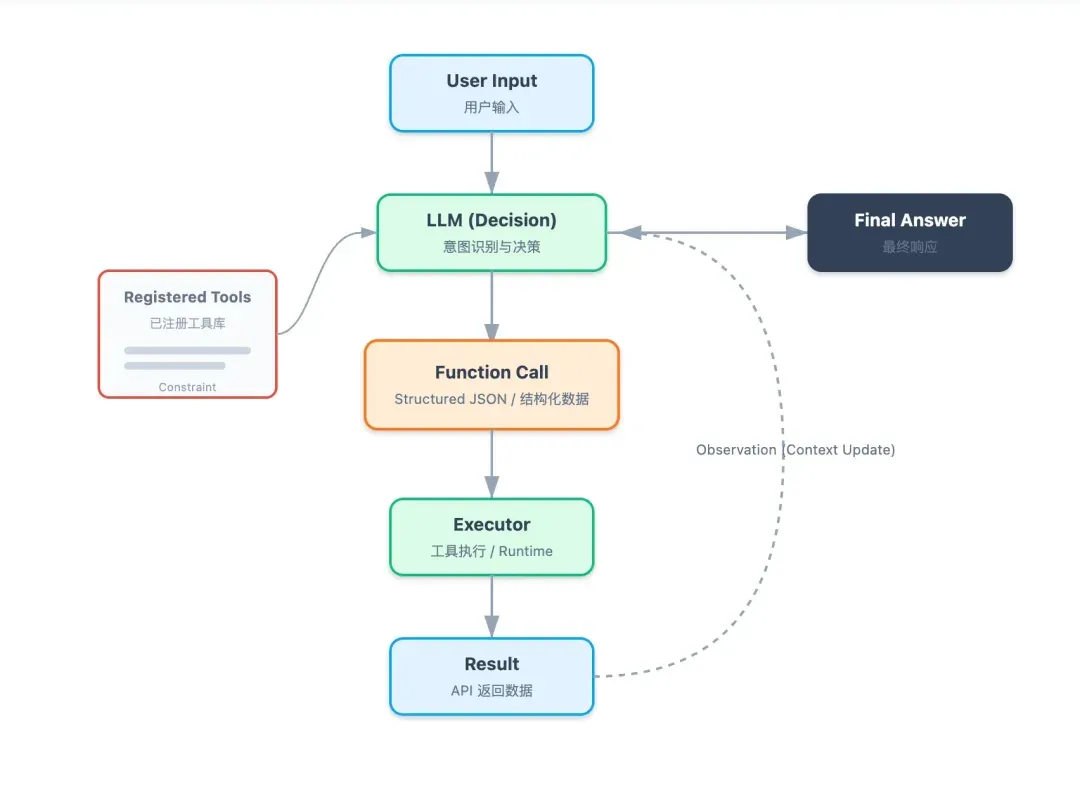
import openai
import json
# 初始化客户端(DeepSeek API 兼容 OpenAI 格式)
client = openai.OpenAI(
api_key=“your-deepseek-api-key”, # 替换为你的 API Key
base_url=“https://api.deepseek.com”
)
# 工具的具体实现(模拟)
def get_weather(destination, date=None):
# 实际场景中应调用天气 API
return f“{destination} 的天气晴朗,气温15-25℃,适合出行。”
# ... 其他工具函数省略
messages = [
{“role”: “system”, “content”: “你是一个专业的旅游规划助手”},
{“role”: “user”, “content”: user_input}
]
while True:
result = client.chat.completions.create(
messages=messages,
model=“deepseek-chat”,
stream=False,
tools=tools) # 将定义好的tools传入
assistant_msg = result.choices[0].message
messages.append(assistant_msg)
# 检查模型是否要求调用工具
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 调用对应的函数
if function_name == “get_weather”:
tool_result = get_weather(**function_args)
elif function_name == “get_attractions”:
tool_result = get_attractions(**function_args)
# ... 其他工具
# 将工具执行结果以特定格式加入对话历史
messages.append({
“role”: “tool”,
“content”: str(tool_result),
“tool_call_id”: tool_call.id
})
# 继续循环,让模型基于工具结果进行下一步推理
else:
# 模型返回了最终答案
final_answer = assistant_msg.content
print(f“助手:{final_answer}”)
break

至此,我们使用 大模型 + Function Calling 的方式构建了一个能够自主执行任务的旅行智能体。但是,这个智能体还存在一个明显的缺陷:它无法记住对话历史。
当用户完成一次规划后继续提问,比如“帮我把早上的景点换成更有历史底蕴的”,模型会感到困惑,因为它并不知道“早上的景点”具体指代什么。每一次模型调用在默认情况下都是独立的,模型只会根据当前输入的提示词生成回答。
要让模型拥有“记忆”,不能指望模型自己去查找历史,而需要在工程层面手动保存每次对话的完整交互记录(包括用户问题、模型回复、工具调用及结果等),并在下一次调用时,将这段历史作为上下文提供给模型。只有这样,模型才能理解当前问题与过往对话的关联。
接下来,我们就探讨如何为智能体添加记忆能力。
为智能体添加记忆能力
要让智能体具备持续对话的能力,关键在于解决其“记忆”问题。这里的“记忆”指的是模型在当前输入之外,能够访问和使用的信息集合,可能来自历史对话、外部存储或系统内部状态,其核心目标是为当前推理提供必要的上下文。
构建记忆能力,需要解决三个核心问题:
- 记在哪里:选择存储机制,如数据库或内存。
- 怎么记住:设计写入策略,区分短期与长期记忆。
- 怎么想起:实现检索机制,在需要时高效找到相关信息。
针对这些问题,目前已有多种记忆实现方式,各有侧重:
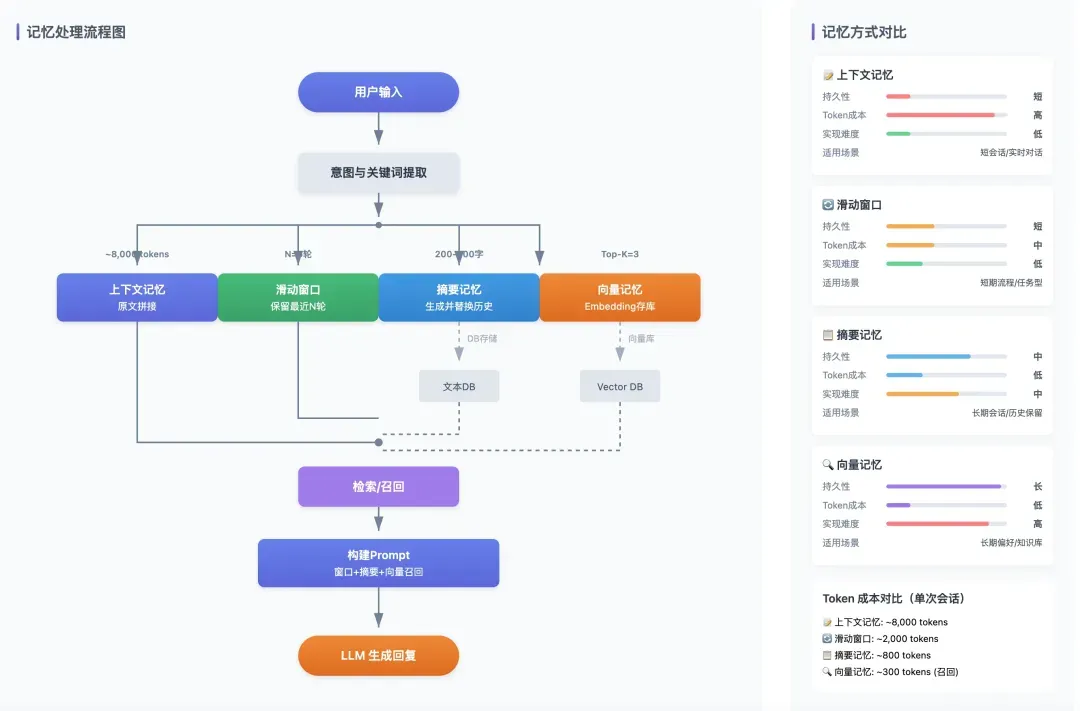
1. 上下文记忆
这是最基础的方式,即把完整的对话历史按顺序拼接到当前提示词中。模型通过阅读所有历史来保持连贯性。
- 优点:实现简单,适合短对话或原型验证。
- 缺点:受模型Token长度限制,成本随对话增长而增加;无法支持长期或跨会话记忆。
- 本质:一种短期、一次性的情景记忆。
2. 滑动窗口记忆
在上下文记忆基础上,只保留最近N轮对话,丢弃更早的内容。主要用于控制Token成本。
- 优点:有效控制提示词长度和开销。
- 缺点:关键信息一旦被移出窗口,就会永久丢失。
- 适用场景:业务流程短、上下文有效期明确的对话。
- 本质:对情景记忆的生命周期管理。
3. 摘要记忆
调用模型对较长的历史对话进行压缩,生成一段简要描述,后续对话使用该摘要替代原始长篇历史。
- 优点:显著降低Token消耗,保留对话主线。
- 缺点:摘要过程会造成信息损失,质量依赖模型总结能力。
- 适用场景:需保留整体脉络但对细节精度要求不高的场景。
- 本质:将情景记忆转化为低精度的语义记忆。
4. 向量记忆
一种长期记忆实现方式。将对话内容、用户偏好等文本转化为向量,存入向量数据库。需要回忆时,将当前问题也转化为向量,在数据库中查找语义最相近的内容。
- 优点:不受对话长度限制,支持跨会话长期记忆;基于语义匹配,更智能。
- 缺点:检索结果是“语义相似”而非“精确匹配”;实现复杂度较高。
- 适用场景:需要长期知识积累和个性化服务的智能体。
- 本质:当前Agent系统中最常见的语义记忆工程实现。
以上几种方式并非互斥,实践中常组合使用。例如,用滑动窗口保存短期上下文,用向量记忆存储长期偏好,再结合摘要记忆定期压缩历史。
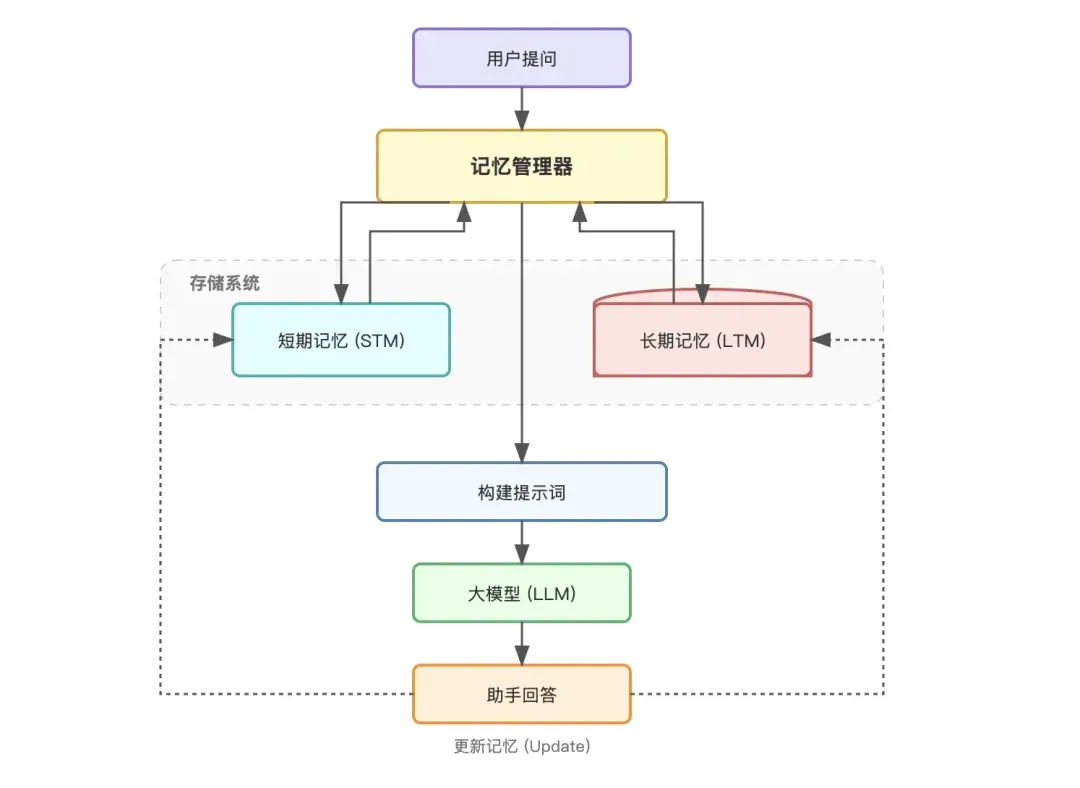
记忆系统的简化实现
为了让智能体具备记忆能力,我们需要设计一个记忆管理系统,通常包含短期记忆和长期记忆两部分。下面以伪代码形式展示其核心架构。
短期记忆实现
短期记忆用于保存最近的对话交互,通常采用滑动窗口策略。
from collections import deque
class ShortTermMemory:
def __init__(self, max_messages=20):
“”“
初始化短期记忆。
:param max_messages: 最多保留的消息条数。
”“”
self.messages = deque(maxlen=max_messages)
def add(self, message: dict):
“”“添加一条消息到短期记忆。”“”
self.messages.append(message)
def get_all(self) -> list:
“”“返回当前所有消息。”“”
return list(self.messages)
def clear(self):
self.messages.clear()
长期记忆实现(向量检索示例)
长期记忆存储跨会话的关键信息,如用户偏好。这里简化展示向量检索的核心逻辑。
import numpy as np
from typing import List
class LongTermMemory:
def __init__(self, embedding_model):
self.embedding_model = embedding_model
self.vectors = [] # 存储向量
self.texts = [] # 存储原始文本
def _embed(self, text: str) -> np.ndarray:
return self.embedding_model.encode(text) # 假设有embedding模型
def add(self, text: str, metadata: dict = None):
“”“将文本存入长期记忆。”“”
vector = self._embed(text)
self.vectors.append(vector)
self.texts.append(text)
def query(self, query_text: str, top_k: int = 3) -> List[str]:
“”“根据查询文本,返回最相关的 top_k 条记忆。”“”
if not self.vectors:
return []
query_vec = self._embed(query_text)
# 计算余弦相似度 (简化)
similarities = [
np.dot(query_vec, v) / (np.linalg.norm(query_vec) * np.linalg.norm(v))
for v in self.vectors
]
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [self.texts[i] for i in top_indices]
记忆管理器(整合短期与长期)
记忆管理器负责协调两种记忆,并构建最终的对话上下文。
class MemoryManager:
def __init__(self, embedding_model, short_term_max_messages=20, long_term_top_k=3):
self.short_term = ShortTermMemory(max_messages=short_term_max_messages)
self.long_term = LongTermMemory(embedding_model)
self.long_term_top_k = long_term_top_k
def add_short_term(self, message: dict):
self.short_term.add(message)
def add_long_term(self, text: str, metadata: dict = None):
# 实际应用中可在此处进行重要性过滤
self.long_term.add(text, metadata)
def build_messages(self, current_query: str, system_prompt_base: str = “”) -> List[dict]:
# 1. 从长期记忆检索相关背景
long_memories = self.long_term.query(current_query, top_k=self.long_term_top_k)
# 2. 构建增强的系统提示词
if long_memories:
memory_context = “以下是可能与当前问题相关的历史记忆:\n” + “\n”.join(f”- {mem}” for mem in long_memories)
system_content = f“{system_prompt_base}\n\n{memory_context}”
else:
system_content = system_prompt_base
# 3. 获取短期记忆(最近对话)
short_context = self.short_term.get_all()
# 4. 组合所有部分
messages = [{“role”: “system”, “content”: system_content}]
messages.extend(short_context)
messages.append({“role”: “user”, “content”: current_query})
return messages
在对话循环中使用记忆管理器
将记忆管理器集成到之前的对话循环中,智能体便具备了记忆能力。
# 初始化记忆管理器(需传入一个embedding模型实例)
memory = MemoryManager(embedding_model=some_embedding_model)
system_base = “你是一位专业的旅游规划助手。你可以调用工具获取天气、景点、酒店和路线信息。”
while True:
user_input = input(“用户:”)
if user_input.lower() in (“exit”, “quit”):
break
# 关键步骤:构建带有记忆的对话上下文
messages = memory.build_messages(user_input, system_prompt_base=system_base)
# 原有的工具调用循环(此处省略,与之前Function Calling部分相同)
# ... 调用模型,处理工具调用,得到最终答案 final_answer ...
# 将本轮完整的交互存入短期记忆
memory.add_short_term({“role”: “user”, “content”: user_input})
memory.add_short_term({“role”: “assistant”, “content”: final_answer})
# 示例:将用户明确表达的偏好或最终计划存入长期记忆
if “我喜欢” in user_input or “偏好” in user_input:
memory.add_long_term(f“用户偏好:{user_input}”, metadata={“type”: “preference”})
if “规划” in user_input and final_answer:
memory.add_long_term(f“生成的旅游计划摘要:{final_answer[:100]}...”, metadata={“type”: “plan”})
print(f“助手:{final_answer}”)
结语
为了追求极致的简洁易懂,本文略过了诸如MCP(Model Context Protocol)、Skills、ReAct详细架构等进阶概念,只聚焦于最核心的“模型+工具+记忆”闭环。希望通过这个从零构建旅游规划助手的旅程,你能清晰地理解AI Agent是如何“学会做事”的。
怎么样,这次的内容足够清晰直白了吧?相信你已经对Agent有了更直观的把握。从理解概念到动手实现一个具备基本能力的智能体,道路就在脚下。