2026年4月AI模型更新全面盘点:国产六强集中爆发,GPT‑5.5与Claude Opus 4.7开启后奇点时代
本文目录:
一、国内篇:六大模型轮番登场
二、国外篇:GPT‑5.5 与 Claude Opus 4.7 巅峰对决
三、模型能力对比:代码、知识推理、Agent 全方位较量
四、后奇点时代:分钟级对话被小时级工程取代
2026 年注定成为 AI Agent 时代的分水岭。国内六大模型集中爆发,小米、智谱、月之暗面、阿里、腾讯、DeepSeek 先后登台;海外 OpenAI 与 Anthropic 在短短六周内接连推出旗舰换代,推动整个行业迈入新阶段:Agent、工具调用、长链路任务与工程交付成为核心主线。今天,我们就来系统梳理 4 月国内外主流模型的最新进展。
一、国内篇:六大模型轮番登场
1. DeepSeek V4:千呼万唤终亮相,国产算力全面适配
DeepSeek V4 的发布时间历经多次调整,4 月终于正式发布。在讨论性能之前,有一件事值得特别拎出来:架构设计清晰指向摆脱对单一硬件生态的依赖,全力适配国产算力。主要有三点:引入 MXFP4 降低对 NVIDIA FP8 的依赖,可更顺畅地运行在华为昇腾、寒武纪、壁仞科技等国产芯片上;用 TileLang 替代 CUDA,算子层跨硬件迁移成本更低;优化 MegaMoE 并行通信,减少等待,目前在昇腾平台已稳定跑通。
V4 不只是性能优化,更是以技术栈重构为牵引,率先引领中国大模型迈向自主可控、软硬协同的国产算力新时代。

双版本 + MoE 架构
V4‑Pro(约 1.6T,~49B 激活)与 V4‑Flash(约 284B,~13B 激活)均采用 MoE,支持 1M context,长上下文能力显著领先上一代。
Agent 能力:开源第一梯队
Agentic Coding 的体验优于 Sonnet 4.5,交付质量接近 Opus 4.6(非思考模式),工具调用稳健,但长链路任务仍有一定局限。它对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品做了适配,代码任务和文档生成均有提升。然而,从实际接入 Claude Code 的测试来看,模型对 skill 的调用存在明显理解偏差——同样的 Prompt,GLM‑5.1、Kimi K2.6、MiMo‑V2.5‑Pro 均能正确触发自定义 skill,V4‑Pro 却需要极其精确的表述才能响应,约束遵守能力也弱于预期。这一点仍须持续观察是适配问题还是模型本身局限。
代码 & 数学:开源天花板
在代码、数学、竞赛类任务上,V4 超过已公开评测的开源模型,部分指标逼近甚至对标顶级闭源。
世界知识:仍有差距
知识广度明显强于开源阵营,但与闭源模型(Gemini‑3.1‑Pro)相比仍存在差距。
成本:直接击穿闭源价格带
推理成本约为闭源模型的 1/5~1/9,延续 DeepSeek 一贯的“性能/成本比”优势。此外,DeepSeek 在定价页底部标注了一行值得关注的小字:受限于高端算力,Pro 服务当前吞吐十分有限,预计下半年昇腾 950 超节点批量上市后,Pro 价格将大幅下调——也就是说,定价仍有进一步下探空间。
早期传闻 V4 会引入多模态能力,但最终发布版本仍停留在纯文本范式,视觉相关能力缺席。这一取舍直接限制了其在 Agent 场景中的能力边界,例如 Computer Use、图像理解与跨模态推理暂时无法落地。
横向对比,像 K2.6、MiMo‑V2.5‑Pro 以及 GPT‑5.5 已将多模态作为基础能力整合,覆盖文本、图像乃至复杂交互输入。在这样的技术基线下,V4 在能力结构上的不完整性更为明显,尤其在需要环境感知和复杂交互的应用场景中。
从产品演进节奏判断,多模态能力大概率会作为后续版本的重点补齐项,时间节点可能落在 V4.5 或 V5。在此之前,V4 更适合聚焦文本推理、编码和 Agent 工具链等单模态优势场景。
2. Kimi K2.6:“连续工作 13 小时”的代码特化模型

Kimi K2.6 延续 K2 系列的方向:大参数、MoE、长上下文、强工程能力。
开源 + MoE 架构
总参数约 1T,激活约 32B,支持约 260K context。第三方评测普遍认为它是“可自部署的顶级开源模型”,在架构规模上与 DeepSeek、Mixtral 同级。
Agent 能力:强调长链路 + 多智能体
官方主打 agent swarm(最多 300 个子 agent)与长时间执行(12 小时级任务)。从第三方分析看,K2.6 在 agentic coding 和多步骤执行上确实进入第一梯队,尤其适合并行任务与复杂工程流程。4000 step、长时间稳定运行等能力已展现出很强的工程潜力,只是距离“完全稳定的标准能力”仍需要更多验证。
代码能力:开源最强档,逼近闭源第一梯队
在真实软件工程基准上取得突破性成绩:
- SWE‑Bench Pro:58.6%(超越 GPT‑5.4 的 57.7% 和 Claude Opus 4.6 的 53.4%);
- SWE‑Bench Verified:80.2%(接近或持平顶级闭源);
- Terminal‑Bench 2.0:66.7%;
- Kimi Code Bench(内部端到端基准):较 K2.5 提升约 20%。
支持多语言(Python、Rust、Go 等)、多文件重构和性能优化,可不间断编写或修改 4000+ 行代码,在复杂系统开发、DevOps、创意前端生成等场景交付质量高,长程稳定性强。
开源阵营里的“Agent + Coding 旗舰”,在工程任务上逼近闭源,但在极限推理与稳定性验证上还没有明显扩展。
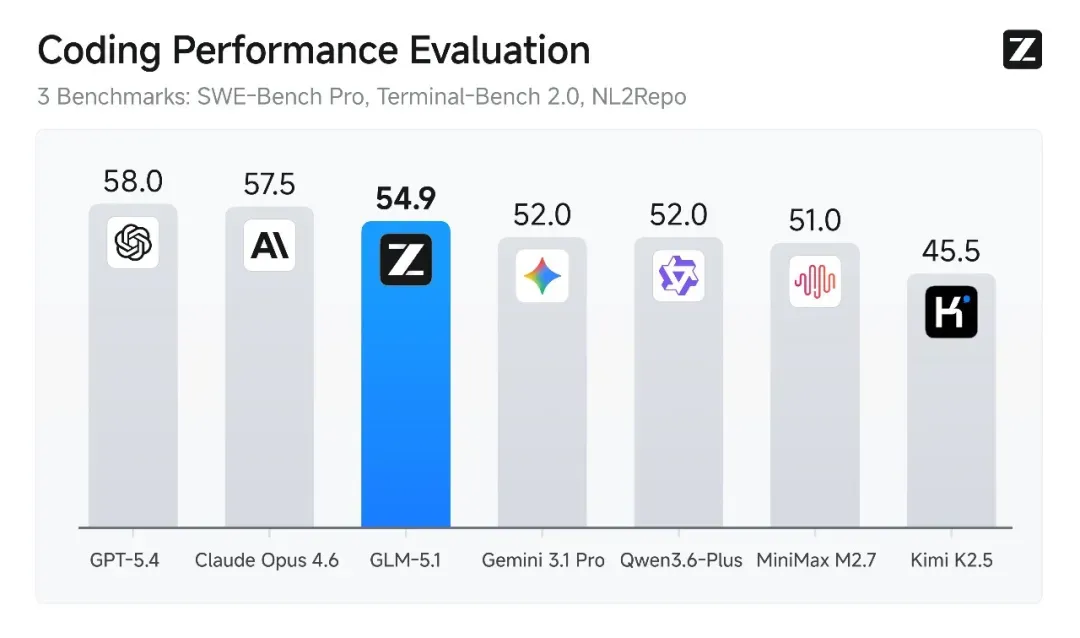
3. GLM‑5.1:开源模型登顶全球代码榜
4 月 7 日,智谱 AI 旗下平台 Z.ai 发布并开源 GLM‑5.1,在 SWE‑Bench Pro 测试中拿下 58.4% 的全球第一,超越 GPT‑5.4(57.7%)和 Claude Opus 4.6(57.3%)。
MoE 架构 + 超长上下文
GLM‑5.1 采用 744B 总参数 MoE 架构(约 40B~44B 激活参数,256 专家仅激活 8 个),支持 200K context,最大输出 128K tokens。
Agentic & 长程工程:开源领先,可持续工作 8 小时
专为 Agentic Engineering 设计,是目前全球少数(开源中首个)可单次自主持续工作长达 8 小时的模型。能在长时程任务中自主规划、工具调用、多轮迭代、自我纠错与策略优化。即使经过 600~1000+ 轮工具调用,仍能保持创新与持续优化,最终交付完整工程级成果。
代码 & 工程能力:部分对标或超越顶级闭源
在真实软件工程基准上表现突出:
- SWE‑Bench Pro:58.4%(全球第一),超越 GPT‑5.4(57.7%)和 Claude Opus 4.6(57.3%),刷新开源纪录;
- SWE‑Bench Verified:77.8%(开源最高);
- NL2Repo(从零构建仓库):42.7%;
- Terminal‑Bench 2.0:63.5%(部分 harness 下更高)。
编程综合得分约 45.3(达 Claude Opus 4.6 的 94.6%),在复杂 Bug 修复、多文件工程、终端操作等真实开发场景中交付质量高,长链路可靠性强。
成本、部署与生态
MIT 完全开源,支持本地部署与商用。API 推理成本显著低于同级闭源(约 1/5 左右),在华为昇腾等国产算力上优化出色(Layer 级 MoE 均衡,吞吐提升约 30%),便于大规模部署与 Agent 产品适配,性价比优势明显,适合构建长程自主 Agent 与生产级编码工具链。
4. MiMo V2.5:一月一更的小米速度,Agent 能力挤入第一梯队
距 3 月 18 日小米发布三款自研大模型仅过去 36 天,4 月 22 日小米再推新一代 MiMo‑V2.5 系列,涵盖 MiMo‑V2.5、V2.5‑Pro、V2.5‑TTS Series 和 V2.5‑ASR 四款模型。
其中,MiMo‑V2.5‑Pro 是小米迄今最强大的模型,在通用智能体能力、复杂软件工程以及长程任务等维度上,已能与全球顶尖 Agent 模型(Claude Opus 4.6、GPT‑5.4)正面较量。
Agent 能力:挤入开源/国产第一梯队
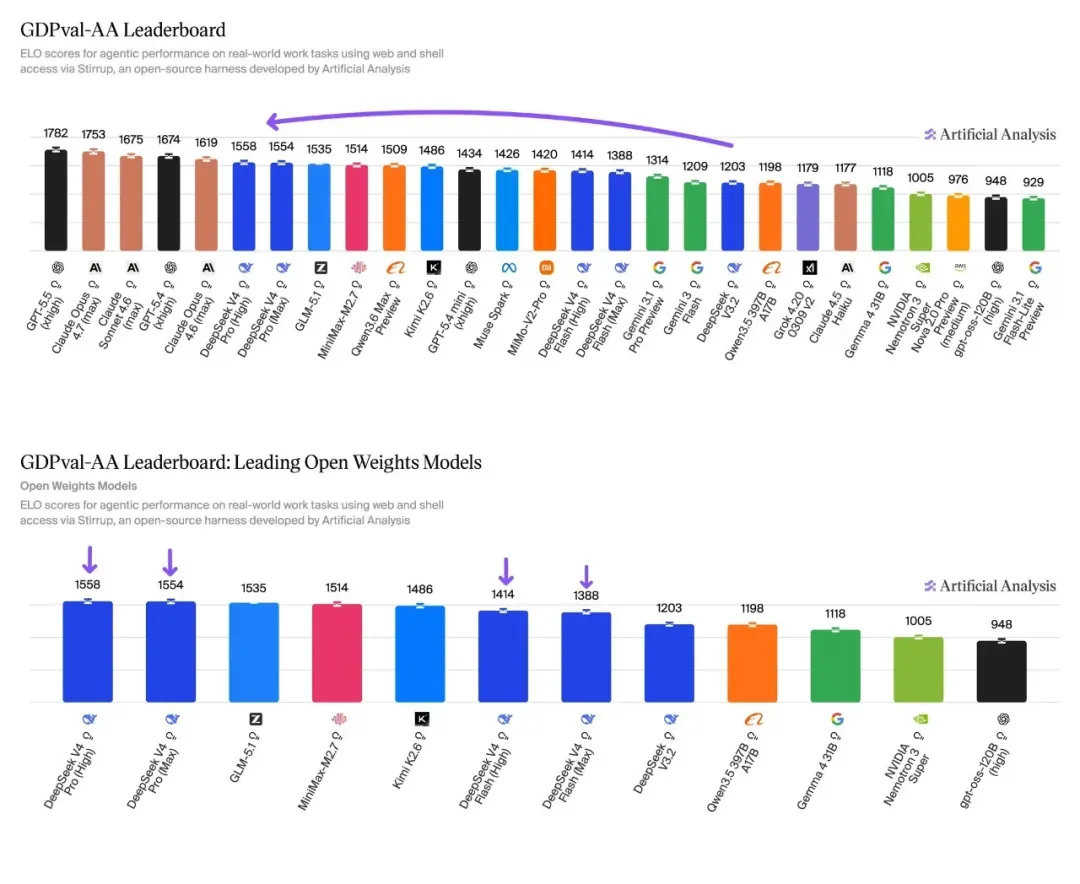
MiMo‑V2.5‑Pro 明显冲着 Agent 场景而去。通用智能体能力与复杂长程任务的提升十分明显,可与 Claude Opus 4.6、GPT‑5.4 正面竞争。它能自主完成过去需要人类专家花几天甚至几周才能做完的专业任务,支持上千轮工具调用,在规划、执行、迭代上都比较稳定。在 ClawEval、GDPVal、PinchBench 等基准中,表现均相当靠前。
代码 & 工程能力:前沿水平,性价比突出
在真实软件工程基准中表现强劲:
- SWE‑Bench Pro:MiMo‑V2.5‑Pro 达 57.2%(接近 Claude Opus 4.6 的 57.3% 与 GPT‑5.4 的 57.7%),MiMo‑V2.5 达 71.8%(在部分内部评测中领先);
- MiMo Coding Bench(内部编码 Agent 基准):MiMo‑V2.5‑Pro 68.4%,MiMo‑V2.5 65.8%~62.3%,在日常复杂编码、多文件工程中接近前沿模型。
长链路编程、终端操作与仓库级任务交付质量高,适合生产级 Agent Coding 场景。
5. Qwen 3.6 plus:阿里组合拳,开源生态护城河
4 月 2 日,阿里千问发布 Qwen3.6‑Plus。千问 3.6 整体性能较 3.5 进步显著,涌现出极强的智能体编程能力,在系列权威评测中,编程表现超越了 2 倍乃至 3 倍参数量的 GLM‑5、Kimi‑K2.5 等模型。4 月 20 日,阿里又发布 Qwen3.6‑Max‑Preview,带来更强的世界知识和指令遵循能力,并在多项基准上显著提升智能体编程表现。
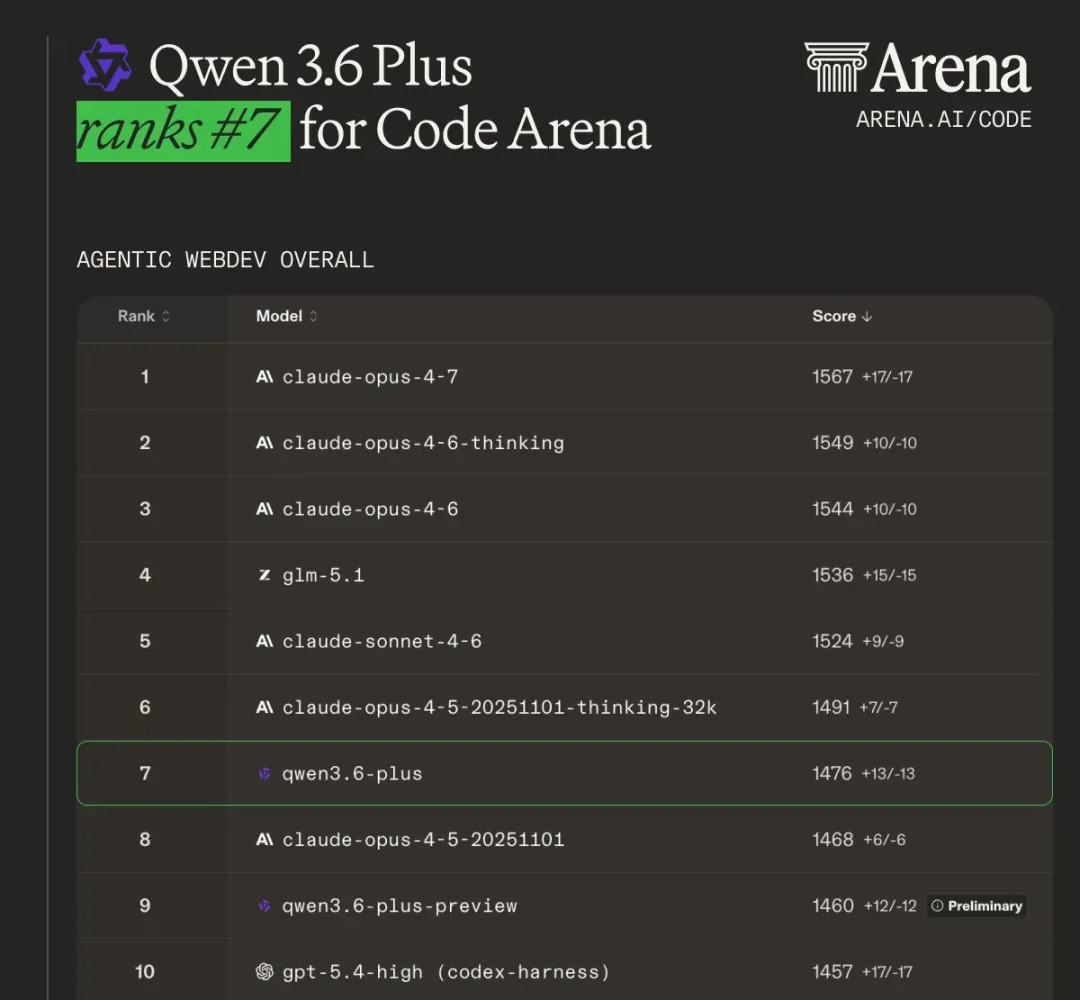
阿里以密集发布节奏巩固开源生态护城河,Plus→开源小尺寸→Max 旗舰的组合拳策略打得相当老道。
6. 混元 3.0 preview:姚顺雨腾讯首秀交卷,快慢思考融合
4 月 23 日,腾讯混元 Hy3 preview 语言模型发布并开源。这是一款主打快慢思考融合的 MoE 语言模型,总参数 295B,激活参数 21B,最大支持 256K 上下文长度,从训练到上线用了不到三个月。
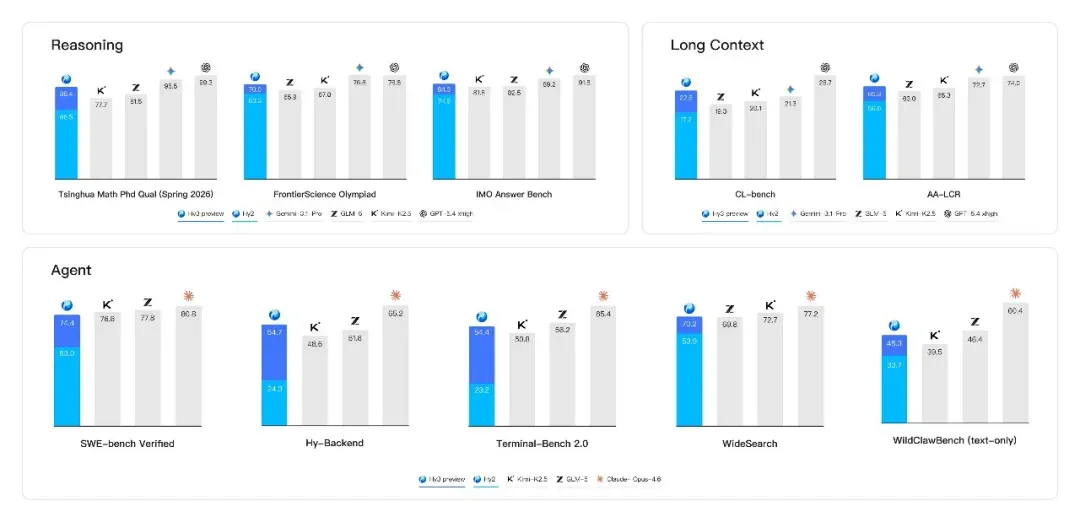
MoE 架构 + 快慢思考融合
Hy3 preview 采用 MoE 架构,总参数 295B,激活参数 21B(192 专家,激活 top‑8),额外包含 3.8B MTP 层参数,支持 256K 上下文。模型融合快慢思考机制,简单任务快速响应,复杂任务启动深度推理,推理效率与成本控制出色,适合高性价比部署。
Agent 能力:显著提升,实用性领先
专为实用 Agent 场景优化,在长链路工具调用、多轮协作、复杂工作流中表现突出,可稳定驱动最长 495 步的复杂 Agent 流程,覆盖文档处理、数据分析、知识检索和工具链编排等真实办公或生产场景。指令遵循与上下文学习能力大幅加强。
代码 & 工程能力:提升最显著,高性价比
代码与智能体能力是本次升级重点,得益于强化学习任务规模扩大与可验证环境构建,在真实软件工程基准中进步明显:
- SWE‑Bench Verified:取得有竞争力的成绩(较历史版本大幅跃升);
- Terminal‑Bench 2.0:主流代码 Agent 基准表现突出。
该模型由腾讯重金邀请的首席 AI 科学家姚顺雨加盟后全程主导推出,也承载着腾讯补齐 AI 短板、在大模型下半场实现追赶的核心期待。
二、国外篇:GPT‑5.5 与 Claude Opus 4.7 巅峰对决
1. GPT‑5.5:新一类智能,6 周一代
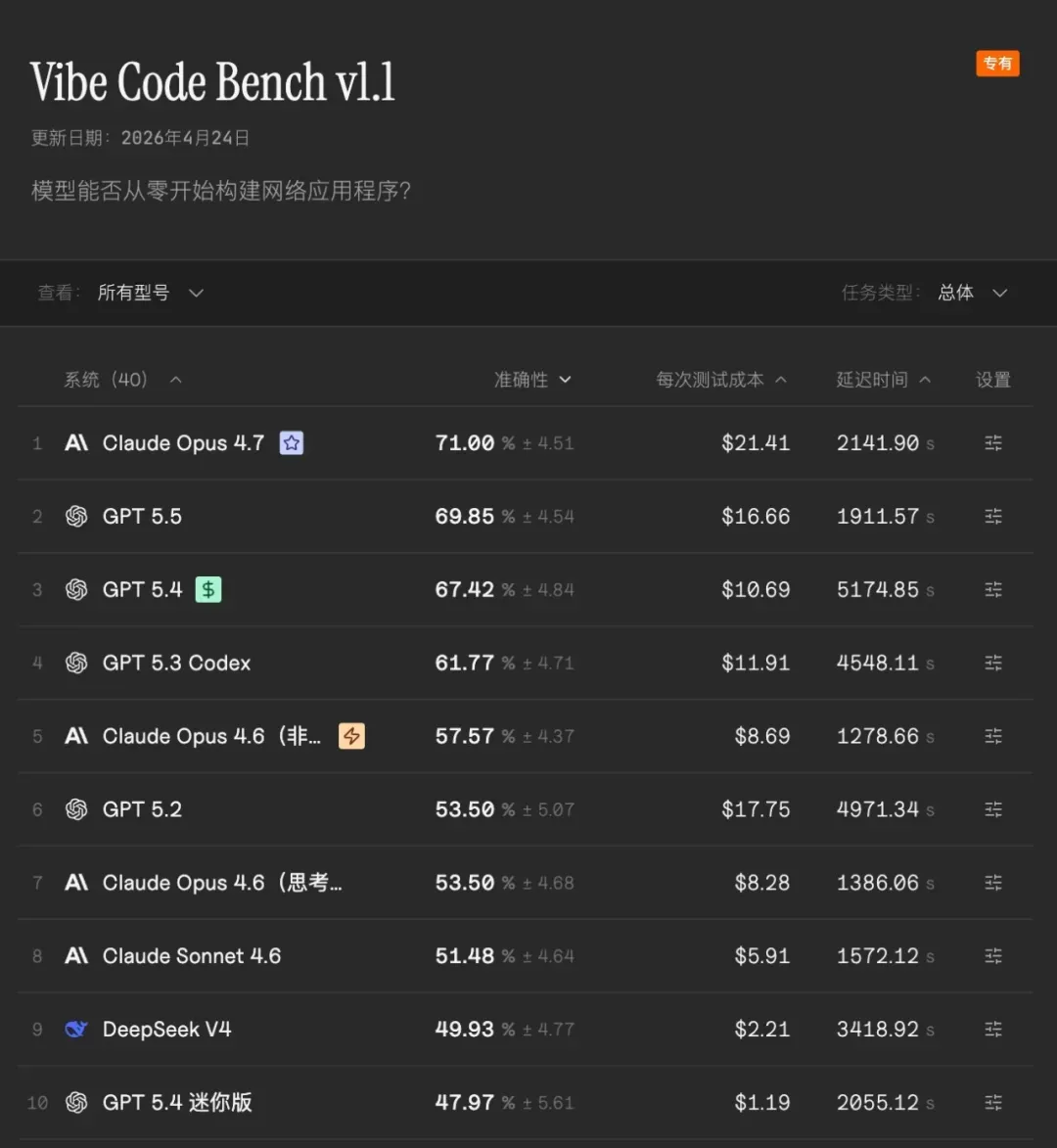
OpenAI 在 4 月发布 GPT‑5.5,在 Agent 编码、计算机使用、知识工作和早期科学研究等领域实现阶跃式提升。距 GPT‑5.4 上线仅六周,凸显了前沿 AI 实验室争夺企业客户的激烈程度。从社区反馈与实际使用来看,GPT‑5.5 在编程、Agent 执行以及文档处理等多个关键场景均有提升,整体评价相比 Claude Opus 4.7 更为稳定,主观体验与部分任务表现均呈现一定优势。
Agent 能力:显著领先,自主执行能力强
专为 Agentic 工作设计,是 OpenAI 当前最强的自主执行模型。它能独立规划、多步工具调用、迭代优化、检查结果并完成端到端任务,大幅减少用户干预。在 GDPval(知识工作)达 84.9%(领先 Claude Opus 4.7 的 80.3%),OSWorld‑Verified(计算机使用)达 78.7%(微弱领先 Opus 4.7 的 78.0%)。BrowseComp 等搜索 Agent 任务表现稳健,长时程连贯性与目标维持能力提升,适合复杂研究、数据分析与多工具协作场景。
代码 & 工程能力:Agentic Coding 顶尖,部分基准领先
在真实软件工程基准中展现强劲实力:
- Terminal‑Bench 2.0(复杂命令行工作流):82.7%(SOTA,领先 GPT‑5.4 的 75.1%、Claude Opus 4.7 的 69.4%);
- SWE‑Bench Pro:58.6%(较 GPT‑5.4 的 57.7% 提升,解决更多单次端到端任务,但落后于 Claude Opus 4.7 的 64.3%);
- Expert‑SWE(内部 20 小时级长时程编码任务):73.1%(领先 GPT‑5.4 的 68.5%)。
在复杂 Bug 修复、终端操作、多文件重构与长链路工程中交付质量高,单次通过率与工具协调能力突出,适合生产级 Agentic Coding 与 Codex 工作流。在 Codex 环境中,GPT‑5.5 在多步骤任务中的规划与执行更加连贯,响应速度与任务完成度均有所优化,用于功能迭代与局部修改时往往能直接完成目标,减少中间干预。
三个产品形态同步上线:标准版、Thinking 版(扩展推理)和 Pro 版(最高精度)。API 定价为输入每百万 token 5 美元、输出 30 美元,Pro 版为 30 美元/180 美元。
2. Claude Opus 4.7:更强代码能力,视觉升级与任务预算机制
此前,Claude Opus 4.6 在 3 月 3 日前后因三个 Bug 出现持续约两个月的“降智”,Anthropic 在服务器端下调推理强度、上下文管理失误、提示词过度约束,导致复杂任务表现明显下降。4 月 16 日,Anthropic 发布 Claude Opus 4.7 正式全面上线。Opus 4.7 是 Opus 4.6 在高级软件工程方面的显著提升,最困难的任务尤为突出,用户可将此前需要密切监督的最高难度编码工作交给 Opus 4.7。
视觉能力是此次升级的另一亮点。Opus 4.7 是首个支持高分辨率图像的 Claude 模型,最高支持 2576px/3.75MP 分辨率(前代上限为 1568px/1.15MP)。开发者层面,新增“任务预算(Task Budget)”机制,让 Claude 在执行长程任务时能根据剩余 token 倒计时合理规划工作节奏,优雅地完成任务。定价与 Opus 4.6 相同:输入 5 美元/百万 token,输出 25 美元/百万 token。
值得关注的是,Anthropic 同期推出了能力更强但仅向极少数机构开放的 Claude Mythos Preview(专注于网络安全方向),并将 Opus 4.7 定位为“比 Mythos 能力稍低、但为大众正式发布的最强模型”,以此作为安全护栏的试验场,积累经验后逐步扩大更强模型的发布范围。
三、模型能力对比:代码、知识推理、Agent 全方位较量
1. 代码能力:Opus 4.7 确立旗舰地位,国产开源激战正酣
代码能力的首要指标是 SWE‑Bench Pro——Scale AI 维护的工业级基准,涵盖跨 Python/Go/TypeScript/JavaScript 语言的真实 GitHub 仓库问题修复,是目前最难被刷分的代码测试。Claude Opus 4.7 以 64.3% 领跑全场可公开商用模型,较上代 Opus 4.6(53.4%)提升近 11 个百分点,领先竞争对手约 6 个百分点。
Anthropic 的限量发布模型 Mythos Preview 以 77.8% 高悬于此表之上,代表当前真实技术天花板,但并非面向公众的产品。国产开源阵营在 SWE‑Bench Pro 上几乎打平:Kimi K2.6 以 58.6%、GLM‑5.1 以 58.4% 几乎并列,GPT‑5.5 同处 58.6%。三分之差在评测框架下没有统计意义。从 SWE‑Bench Verified(单文件修复)来看,差距更明朗:Opus 4.7 以 87.6% 领先,Kimi K2.6 以 80.2%、DeepSeek V4‑Pro 以 80.6% 紧随其后,GLM‑5.1 以 77.8% 列第四。
终端 Agent 编程(Terminal‑Bench 2.0)测试在真实命令行环境中规划、执行、错误处理的综合能力。GPT‑5.5 以 82.7% 一骑绝尘,成为本轮最亮眼的亮点之一。国产模型中 DeepSeek V4‑Pro 以 67.9% 超越 Claude Opus 4.6(65.4%),是国产模型在该赛道的最佳成绩;Kimi K2.6(66.7%)和 Qwen3.6‑Max(65.4%)紧跟其后。
2. 知识推理:国际模型仍有优势,但差距快速缩小
HLE(人类最后的考试)是当前最权威的知识推理压力测试,包含 2500 道来自数学、自然科学、人文学科的博士级难题,多数模型得分仍在 50% 上下。在“带工具”条件下(允许主动调用搜索、计算器等),Claude Opus 4.7 以 54.7% 位居可公开商用模型最高,Kimi K2.6 以 54.0% 几乎并驾齐驱,Claude Opus 4.6 为 53.0%,Gemini 3.1 Pro 为 51.4%。DeepSeek V4‑Pro 官方数据为 48.2%,仍有一定差距。
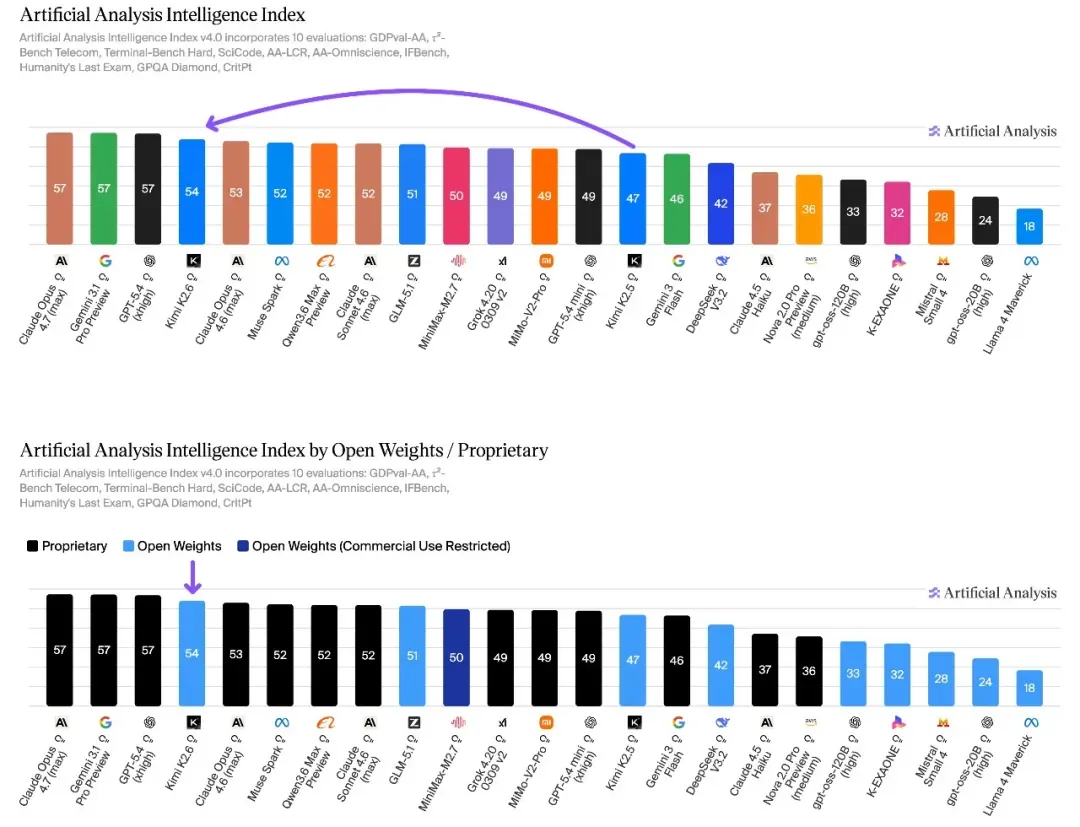
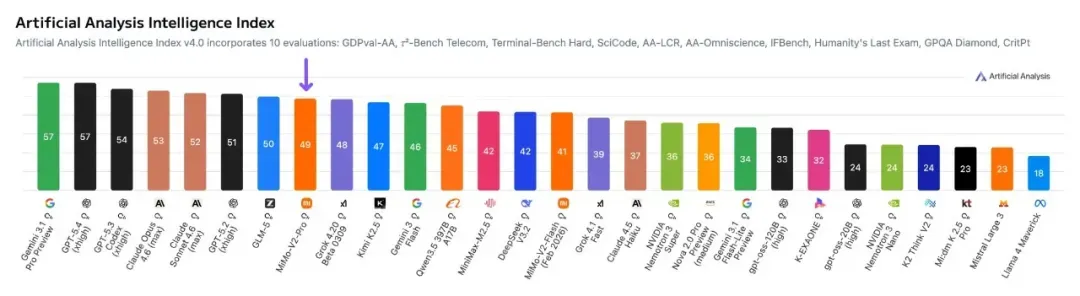
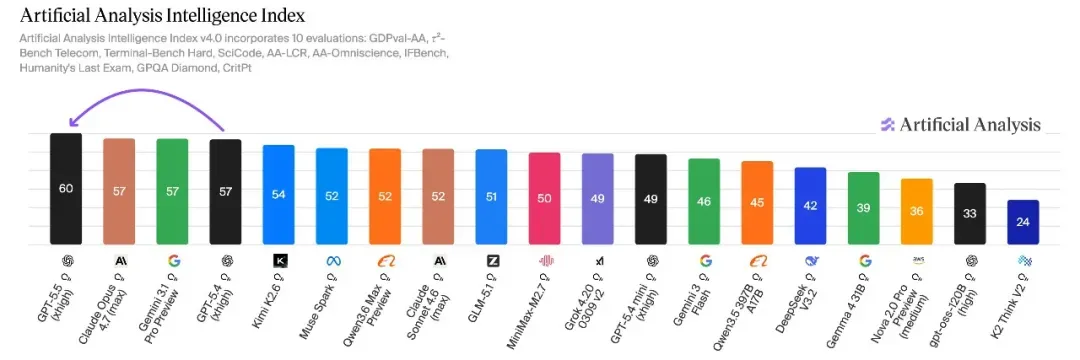
GPQA Diamond(研究生科学推理)方面,Claude Opus 4.7、Gemini 3.1 Pro、GPT‑5.4 在 94%~94.4% 区间三足鼎立,Kimi K2.6 以 90.5% 进入该梯队,其余国产模型暂未公布数据。GPT‑5.5 的知识维度综合表现通过 Artificial Analysis Intelligence Index 显示,GPT‑5.5(xhigh)以 60 分领先,Opus 4.7 和 Gemini 3.1 Pro Preview 均为 57 分,知识与幻觉控制的进步是 GPT‑5.5 较前代提升最显著的领域之一。
3. Agent 能力:工具调用精度与持续工作时长成为新标尺
这是 4 月这批模型最核心的竞争轴,也是国产模型奋力追赶的关键战场。
工具调用精度方面,Claude Opus 4.7 在 MCP‑Atlas 基准上以 77.3% 位列第一,高于 Gemini 3.1 Pro(73.9%)和 GPT‑5.4(68.1%)。DeepSeek V4‑Pro 录得 73.6%,与 Gemini 基本持平。这意味着 Opus 4.7 在需要密集调用外部工具的企业级场景中可靠性依然最高。
持续工作时长方面,各家展示方式不同,比较时需注意方法论差异:
- GLM‑5.1 强调“单次任务 8 小时自主工作不停机”;
- Kimi K2.6 可不间断编码 13 小时,历经 12 套优化策略、超 1000 次工具调用,最终将金融引擎峰值吞吐量提升 133%;
- GPT‑5.5 在内部基准 Expert‑SWE 中,能处理人类估计约 20 小时才能完成的复杂任务,是目前公开声称单任务跨度最长的指标。
MiMo V2.5‑Pro 虽尚未公布 SWE‑Bench 等标准化指标,但在 Artificial Analysis 综合智能榜上以 54 分与 Kimi K2.6 并列全球开源第一,Agent 指数同样位居开源并列第一。
4. API 定价:价差高达 35 倍,国产模型性价比优势显著
定价方面的分化是这轮更新中最不容忽视的结构性信息。
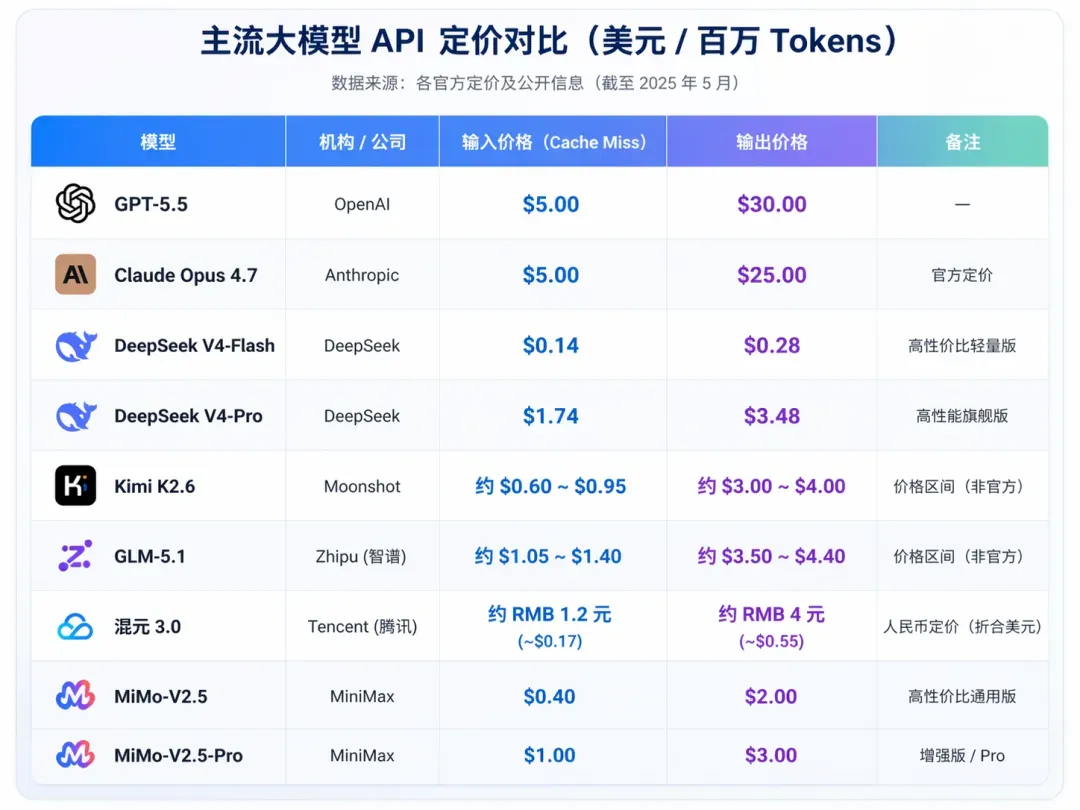
GPT‑5.5 API 定价为每百万输入 token 5 美元、输出 30 美元,Pro 版 30 美元/180 美元,是当前旗舰 API 中定价最高的。Claude Opus 4.7 维持输入 5 美元、输出 25 美元。国产阵营中,DeepSeek V4‑Flash 以输入 0.14 美元、输出 0.28 美元上线,是旗舰级开源模型中性价比最突出的选择;V4‑Pro 为 1.74 美元/3.48 美元,仍不到 GPT‑5.5 的三分之一。Kimi K2.6 约 0.60 美元/3.00 美元,GLM‑5.1 约 1.40 美元/5.60 美元;混元 3.0(Hy3)以人民币 1.2 元/4 元(约合 0.17 美元/0.55 美元)成为本次发布中价格最低的大型 MoE 模型。输入价格层面,Claude Opus 4.7($5)与混元 3.0($0.17)之间存在近 30 倍价差;GPT‑5.5($5)与 DeepSeek V4‑Flash($0.14)之间更高达 35 倍。
评测分数只是参考,真正的差异体现在具体工作场景里。这里有一些参考:
- 写作与内容生产:稳定性和事实控制优先
长文本写作、研究综述、行业分析对幻觉控制和结构组织要求更高。GPT‑5.5 更适合高密度内容生产,知识覆盖与一致性控制明显提升,适合深度文章、报告和策略分析;Claude Opus 4.6 风格更自然,语义连贯性强,适合偏“人类表达”的写作任务,但 Opus 4.7 被普遍认为在表达能力上不及 4.6。国内推荐 Kimi K2.6,中文语境下更贴近本土表达,信息整合能力强,适合资料整理型写作和长文汇总。
- 代码开发:从“写函数”到“跑系统”
代码能力已分为单点修复与端到端工程执行两个层级。Claude Opus 4.7 在 SWE‑Bench 维度最强,适合复杂代码理解、重构和跨文件修改,偏“资深工程师”;GPT‑5.5 在 Terminal‑Bench 表现突出,适合自动跑脚本、调试环境和连续执行任务;国内推荐 GLM‑5.1,性价比极高,工程任务稳定,适合大规模调用和自动化流水线。
- 文档分析和知识处理:上下文与检索能力
典型场景为 PDF 分析、合同审阅、技术文档理解和多轮问答。GPT‑5.5 长上下文加工具调用能力强,适合复杂资料交叉分析;Claude Opus 4.7 阅读体验好,回答更“解释型”,适合需要推导过程的任务;国内推荐 GLM‑5.1 和 Kimi K2.6,在持续任务和长时间处理上优势显著,适合批量文档处理和长流程任务。
- Agent 与自动化执行:决定未来上限的能力
GPT‑5.5 是当前最强的通用 Agent 执行模型,适合复杂、多步骤、跨工具任务;Claude Opus 4.7 工具调用精度最高,适合企业级流程(API 编排、系统集成);国内推荐 DeepSeek V4‑Pro,在成本与性能间取得平衡,适合做高频 Agent;Kimi K2.6 长时间运行能力突出,适合持续编码或复杂链路任务。
四、后奇点时代:分钟级对话被小时级工程作业取代
分钟级对话的时代正在被小时级工程作业取代。
从 GLM‑5.1 的“8 小时持续工作”、Kimi K2.6 的“13 小时不间断编码”,到 MiMo V2.5 的“千次工具调用”,“任务完成时间线”已成为 4 月各家模型对决的核心指标之一。
国产模型全面告别价格战。
智谱三度提价,小米同步优化 Token Plan,阿里开源生态配合旗舰并进,Agent 旺盛需求促使国产模型集体转向不卷 Token 价格、卷性能的路线。
算力自主成为战略命题。
GLM‑5.1 全程昇腾 910B 训练、DeepSeek V4 全面迁移华为 CANN 架构——这不只是技术选择,更是中国 AI 在芯片封锁压力下主动构建自主计算路径的战略布局。
