四款顶级AI模型356元横评实测:Opus 4.8 vs GPT-5.5 vs DeepSeek V4 vs MiniMax M3,真实能力排名揭晓
近期,AI模型领域的更新节奏明显加快。Opus 4.8、GPT-5.5、Qwen3.7-Plus、MiniMax M3四款重量级模型几乎在同一时间亮相,想逐一深入体验都颇为吃力。
前两天我留意到一个名为「Browse Code」的榜单,专门评估大语言模型在真实浏览器环境中完成编程与网页自动化任务的成功率。
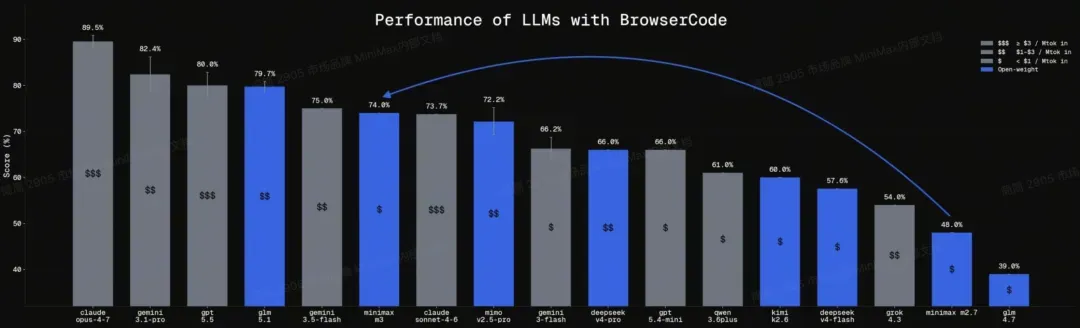
出乎意料的是,MiniMax M3在这个榜单上从之前M2.7时期的倒数第二,直接跃升至全球第五,与Claude 4.6 Sonnet、Gemini 3.5 Flash并列。
当然,单一榜单远远不能说明全部问题。因此我投入了356元,将Claude Opus 4.8、GPT-5.5、DeepSeek-V4-Pro和MiniMax M3这四款模型放在一起,使用完全相同的任务、提示词和评分标准,全部通过API连接Claude Code/Codex进行实测。
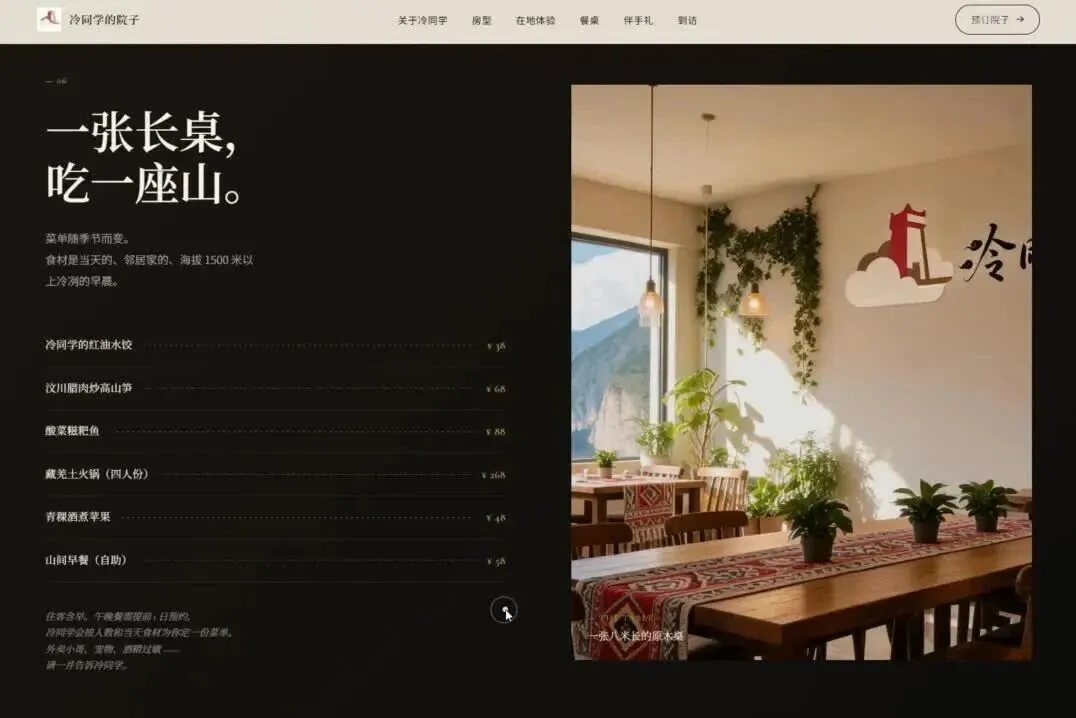
测试覆盖了3D编程、视觉编程、游戏开发以及Agent长程任务四大场景,横向对比结果如下。

一手横评
本次测评坚持“变量归一”的原则,只有如此对比才有意义。
四个模型使用同一份视觉素材、同一条提示词,分别通过各家API在Claude Code/Codex里运行,最终从任务完成度和输出质量两个维度来评价,场景覆盖3D编程、视觉编程(网站开发)、游戏开发以及Agent长程任务(涉及Office三件套与Coding)。
1)3D任务
首先让模型观察一张金门大桥的实景照片,然后根据桥梁的外观,用Three.js编写一个可交互的3D网页。
这项任务的考验是三维的:第一,模型必须具备视觉理解能力,能够从照片中提取关键的结构特征;第二,要能将这些特征精准映射到三维空间的几何关系上;第三,Three.js的代码质量必须过硬,不能写出运行即崩溃的内容。
三项能力缺一不可,任何一项的缺失都会导致结果大打折扣。
提示词:
参考“金门大桥.jpeg”的外观构造,帮我开发一个旧金山的金门大桥的3D交互网页,要求如下:
- 使用 Three.js,全部用程序化几何体生成,不加载外部3D模型。
- 桥体主色为国际橙色(#C47832),塔柱为Art Deco风格,桥体结构高度还原“金门大桥.png”的倒弧形外观结构。
- 准确还原金门大桥标志性的国际橙色桥塔、双塔悬索结构,包含主缆、吊索、桥面和车道分隔线。
- 环境包括:深蓝色波浪海水、天空渐变雾效,远处绿色山丘和城市群。
- 动态:海水浮动、云影移动、支持鼠标拖拽旋转/缩放。
- 性能:全屏自适应,使用Three.jsr128,输出一个可直接运行的HTML文件。
- 支持鼠标拖拽旋转、缩放、平移,初始视角从西南方向俯瞰大桥。
Claude Opus 4.8:
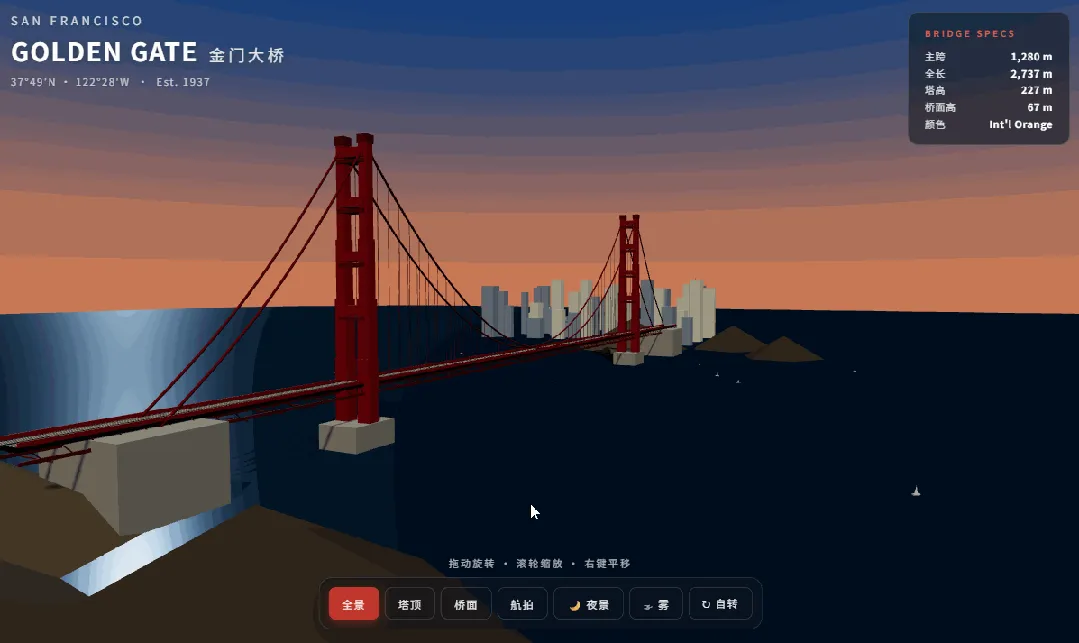
GPT-5.5:

DeepSeek-V4-Pro:

MiniMax M3:

在这个案例中,表现最为出色的是Claude Opus 4.8,MiniMax M3紧随其后。
这两款模型都准确还原了金门大桥最具标志性的物理细节:主缆从两侧塔顶向跨中自然垂落的倒弧形外观。这说明它们不只是在描述一座桥,而是真正理解了悬索桥的结构原理,并能将这种理解转化为三维几何体。
GPT-5.5和DeepSeek-V4-Pro则未能呈现出这一特征,输出的桥体形态各异。
特别是GPT-5.5,如何描述其编程审美呢?有一种“浓眉大眼”的粗糙感。在后续几个案例中,这一特点一直延续。而Claude和M3的视觉语言则完全相反,一看就非常精致、高级,具备明确的设计意识。
另外值得一提的是,DeepSeek设计的海洋流体动态效果颇有意思,但天空部分出现了穿模问题,说明三维空间碰撞逻辑的处理还不够扎实。

本轮实测:Claude Opus 4.8 > MiniMax M3 > GPT-5.5 > DeepSeek-V4-Pro。
2)视觉编程(网站开发)
前阵子向各位介绍过“冷同学的院子”这个民宿概念,这次顺手让模型为它开发一个官方网站。
我的提示词有意没有给出具体的设计指令,只是提供了民宿的信息和素材包,让模型自行判断——哪些素材应该采用、如何排版、采用何种设计语言。
这实质上是在测试两件事:一是视觉理解能力,即模型能否“看懂”图片和视频素材的内容与品质;二是设计决策能力,即能否根据品牌调性做出合理的创作取舍。
提示词:
给这家民宿设计一个官方网站。
民宿的基本信息:
- 民宿名称:冷同学的院子
- Slogan:云朵上的院子,冷同学的家
- 地理位置:四川汶川(羌族文化核心区、高山峡谷地带)
- 品牌调性关键词:温暖治愈 · 在地羌韵 · 自然松弛 · 外冷内热 · 有故事感
- 目标客群:追求慢生活的年轻人、亲子家庭、文化旅行者、成都周末度假客、川西旅游爱好者
文件夹【民宿资料包】放着很多民宿的素材,有logo、门店、房间、周边和宣传视频,你自己决定用哪些素材(不是所有素材都用上)。我只需要最终交付的网站顶级审美,让人看了就想马上去玩。
Claude Opus 4.8:

(可上下滑动,查看全图)
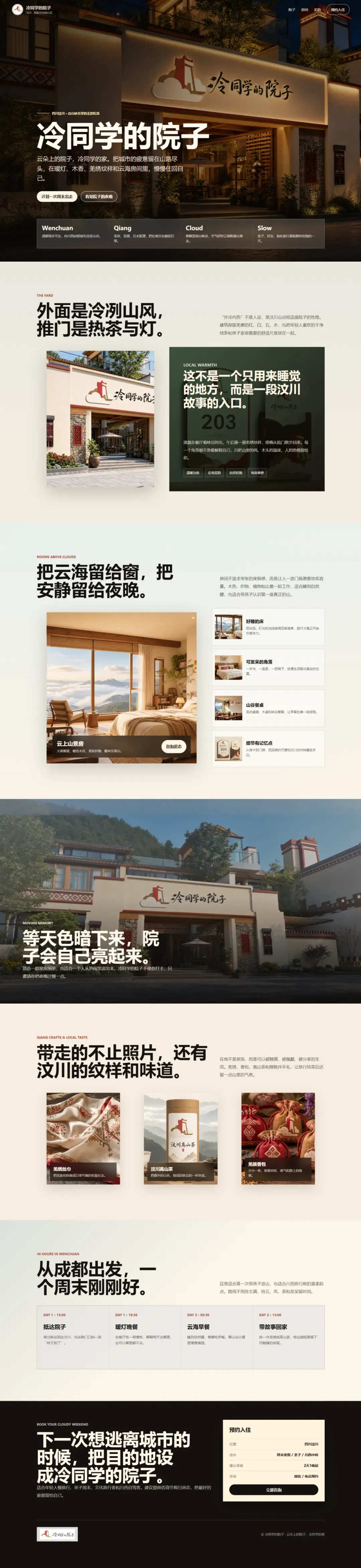
GPT-5.5:
(可上下滑动,查看全图)
DeepSeek-V4-Pro:

(可上下滑动,查看全图)
MiniMax M3:
已关注
Follow
Replay Share Like
Close
观看更多
更多
退出全屏
切换到竖屏全屏**退出全屏
沃垠AI已关注
Share Video
,时长01:10
0/0
00:00/01:10
切换到横屏模式
继续播放
进度条,百分之0
00:00
/
01:10
01:10
全屏
倍速播放中
继续观看
横评Opus 4.8、GPT-5.5、DeepSeek V4、MiniMax M3,356元测出来的真实排名
观看更多
Original
,
横评Opus 4.8、GPT-5.5、DeepSeek V4、MiniMax M3,356元测出来的真实排名
沃垠AI已关注
Share点赞Wow
Added to Top StoriesEnter comment
这一轮表现最好的是MiniMax M3。它的确“看懂”了我的素材与需求,一上来就先梳理了开发计划。

随后定义了设计语言:以大面积的米白留白结合克制的几何形态来体现“冷”,用羌红、赭金、暖木色来诠释“热”,再将这两套视觉语言巧妙融合,形成“外冷内热”的调性表达。审美上参考了Aman侘寂、松赞在地文化以及虹夕诺雅的克制感。

这就是视觉理解能力和设计品位所带来的差距。仅靠阅读文字提示词,是无法达到这种程度的。
在房型展示的版面中,M3采用了左右交错的错位布局来呈现房型和价格,节奏把控得非常好,看完确实会让人产生预订的冲动。
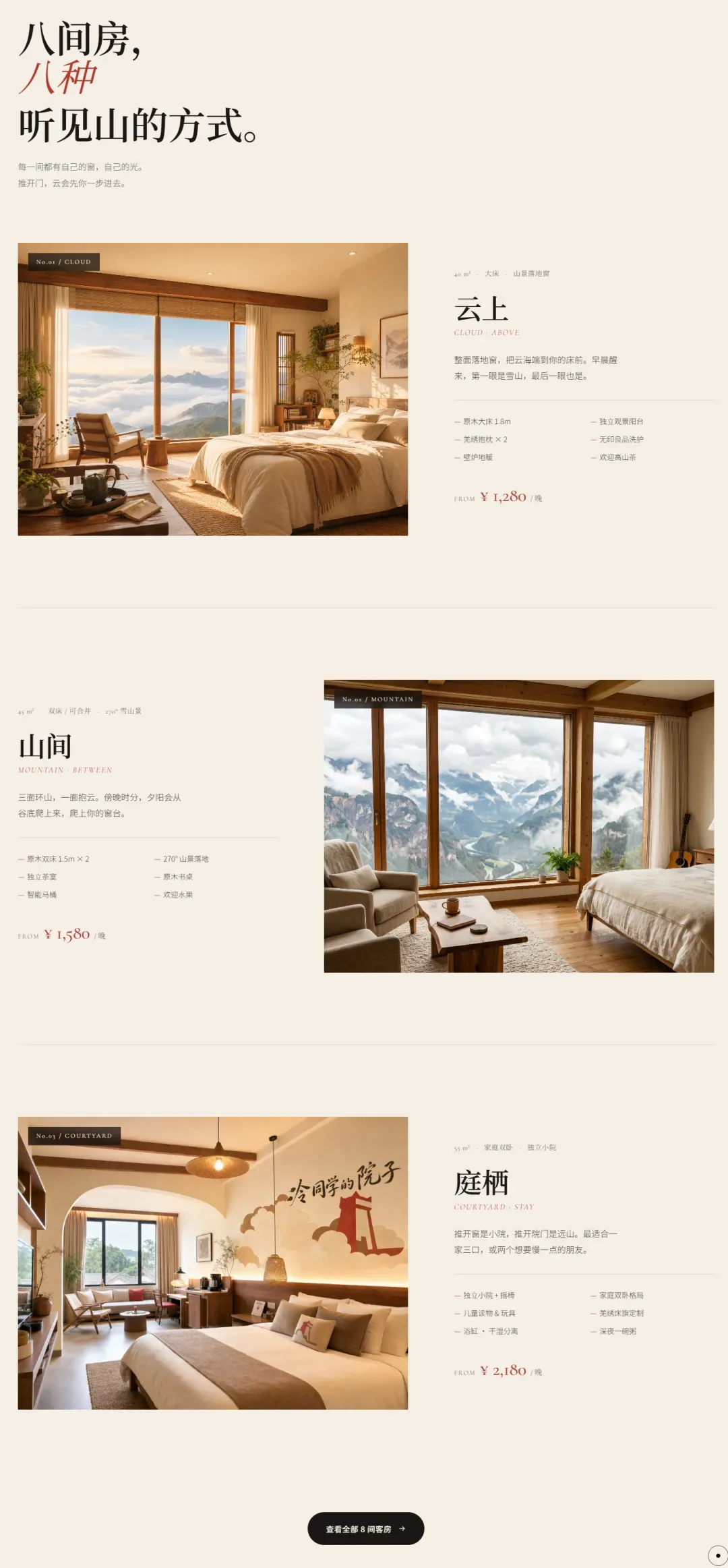
Opus 4.8也不逊色,几处书法字体的运用尤其令人喜爱,素材选择十分克制,没有一股脑全部堆砌上去。
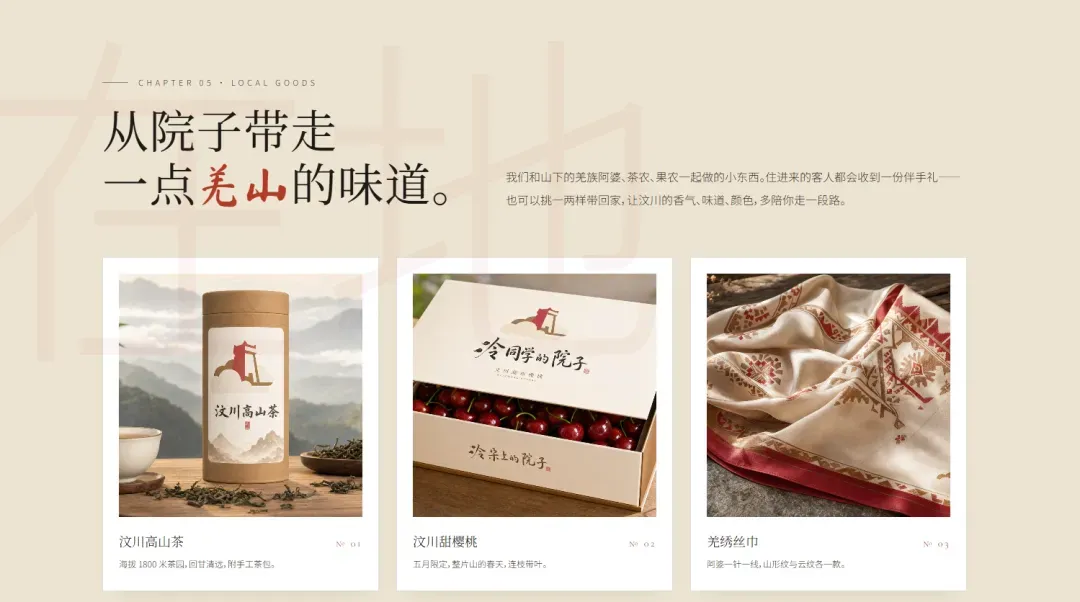
GPT-5.5继续延续它那“浓眉大眼”的直男审美:大号标题、四四方方的排版,毫无灵活性可言,确实非常难看。
DeepSeek-V4-Pro的审美虽然比GPT-5.5稍微耐看一点,但它缺乏视觉理解能力,根本不知道哪些图片应该使用、用在何处,索性把所有素材一并堆进去,导致图文错乱,部分页面文不对题。这是能力上的硬伤,不是靠调整提示词能够解决的。
本轮测试:MiniMax M3 > Claude Opus 4.8 > GPT-5.5 > DeepSeek-V4-Pro。
3)游戏开发
不知道各位是否在手机上玩过“抓大鹅”?你可能没玩过,但你的另一半大概率玩过。
这次我先与AI沟通设计了一份PRD,再让模型根据这份PRD开发一款网页版的抓大鹅游戏。
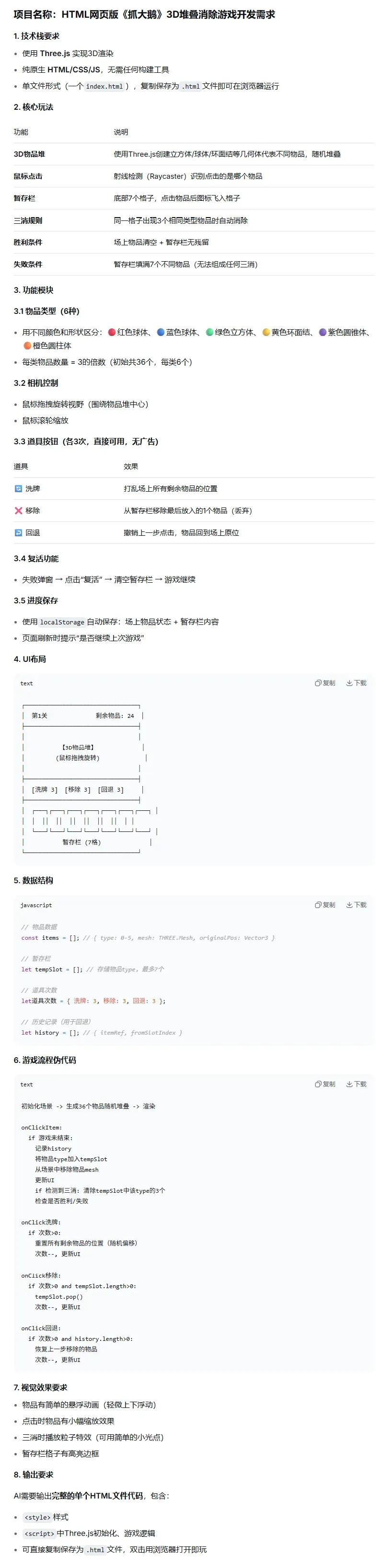
(可上下滑动,查看全图)
这项任务的难点在于:模型能否完整、准确地理解设计文档中的功能描述,并将每条需求精准地转化为可运行的代码,同时兼顾游戏体验和视觉完成度。
提示词:
请按PRD“大鹅.png”的要求,帮我创建一个网页版《抓大鹅》3D堆叠消除游戏。要求:
1、6种不同颜色/形状的物品,共36个,随机堆叠在3D空间中。
2、鼠标点击物品后消失,图标进入底部7格暂存栏。
3、暂存栏出现3个相同物品时自动消除。
4、暂存栏满7个不同物品时失败,场上物品清空时胜利。
5、提供洗牌、移除、回退三个道具按钮,各3次使用次数。
6、支持鼠标拖拽旋转视角和滚轮缩放。
7、支持localStorage保存进度和复活功能。
8、输出一个完整的html文件,可直接在浏览器运行。
Claude Opus 4.8:
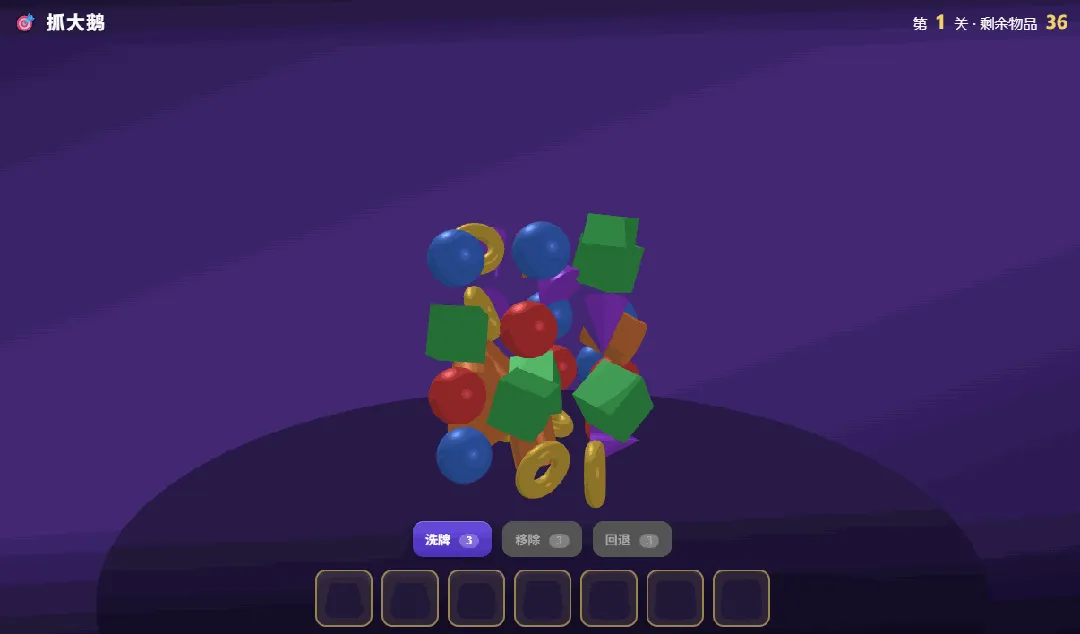
GPT-5.5:
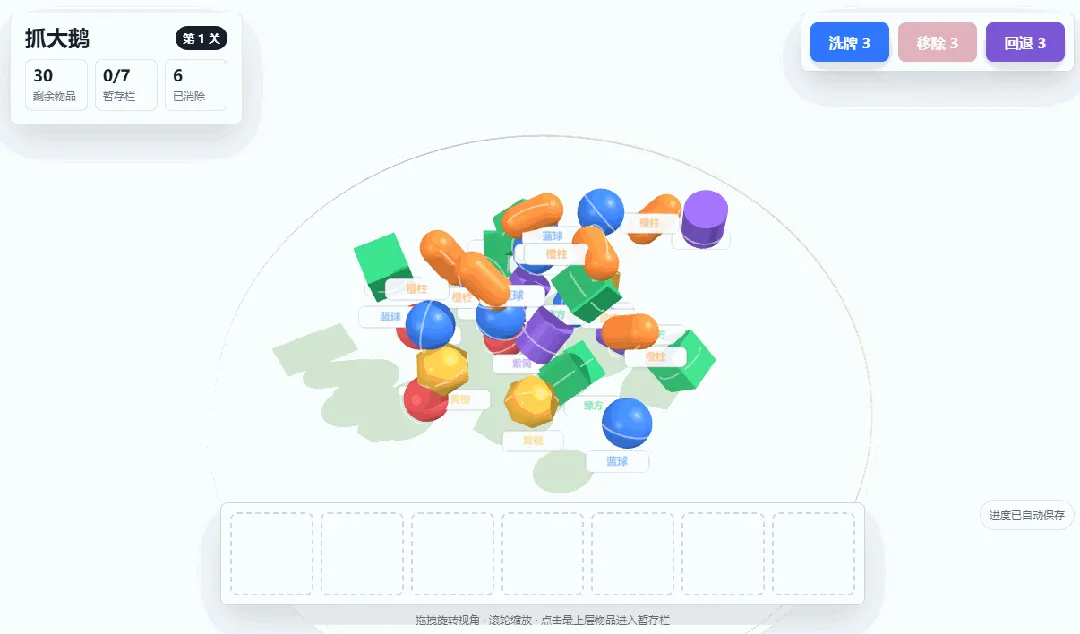
DeepSeek-V4-Pro:
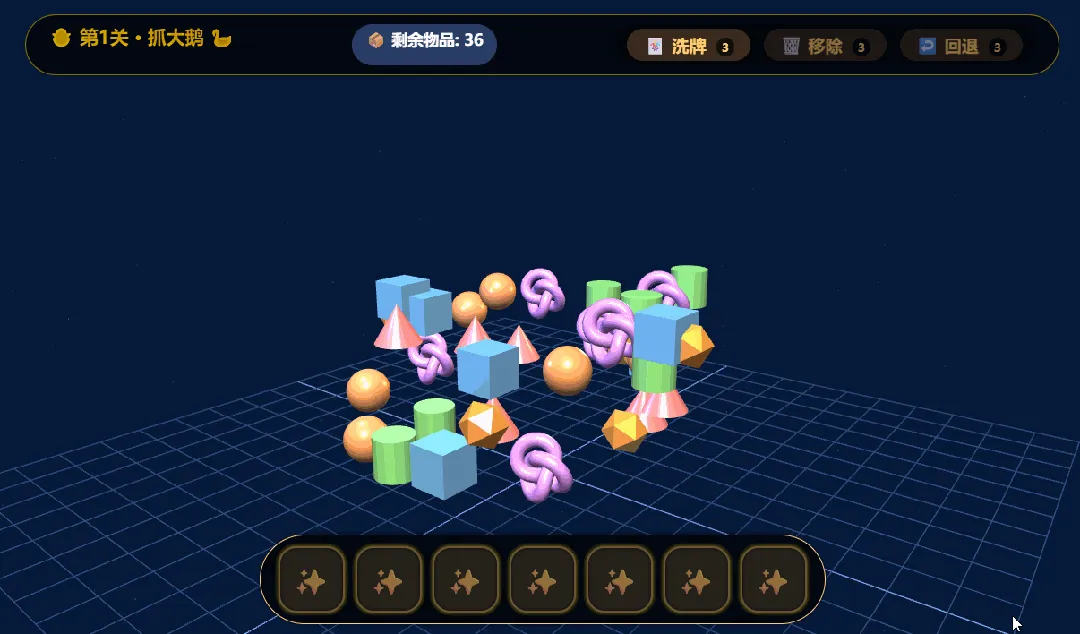
MiniMax M3:
四款模型都成功开发出了游戏,核心功能均正确无误,这表明面对有明确PRD的开发任务时,主流模型基本都已达标。
有意义的差异集中在两点:一是前端审美,Claude仍然最耐看,DeepSeek和M3也可以,GPT-5.5最丑;二是细节完成度,PRD中有一项要求是“通关后奖励一只大鹅”,只有M3做到了,其余三款模型都遗漏了这个细节。
本轮测试:Claude Opus 4.8 ≈ MiniMax M3 > DeepSeek-V4-Pro > GPT-5.5。
4)Agent长程任务
最后一个案例也最为复杂:我们让各模型借助Claude Code/Codex,完成一个联网搜索 + Word/PDF生成 + Skill调用 + 网站开发的复杂长程任务。
提示词:
联网搜索电影《火遮眼》的关键信息内容,尽量从权威信源获取内容。先给我创建一份2000字的word调研报告(含pdf版)。然后调用guizang-ppt skill生成一份12页的PPT,宣传一下这部电影。
Claude Opus 4.8:

(可上下滑动,查看全图)
GPT-5.5:

DeepSeek-V4-Pro:
MiniMax M3:
这个任务的难点在于“长”——不仅仅是单步执行,而是要求模型在跨越多个工具调用节点的过程中,始终保持上下文连贯、指令不漂移。这对模型的长程稳定性和工具协调能力要求很高。
先说PPT的完成度:GPT-5.5、Opus 4.8和M3都交付了质量不错的PPT,Claude每页带有微动画,GPT-5.5贴上了真实配图(应该得益于Codex),M3的色彩搭配更为悦目。DeepSeek-V4-Pro在这一项上明显落后,排版、配色和交互都不在同一水平线上。
调研报告的内容质量方面,Opus 4.8、M3和GPT-5.5不相上下,DeepSeek-V4-Pro垫底。
DeepSeek-V4-Pro还有一个问题值得单独指出:它在Claude Code中运行得非常慢,且频繁中途停顿不再继续输出。这个PPT任务它运行了整整36分钟,期间多次卡住。
这大概率是由于DeepSeek未针对Claude Code做充分适配所导致的,属于工程层面的问题,而非模型能力本身。但从用户体验的角度来看,这种差异是实实在在存在的。
本轮测试:GPT-5.5 ≈ Claude Opus 4.8 ≈ MiniMax M3 > DeepSeek-V4-Pro。
实测总结
四轮任务跑下来,先看综合能力,再算成本。
能力层面,Claude Opus 4.8是本次横评中综合实力最强的,一如既往地稳健。
M3是最大的惊喜,整体水平大约介于Opus 4.7和4.8之间,与Opus 4.8的差距比我预想的要小。
GPT-5.5表现不够稳定,有时在线,有时掉链子,前端审美上的短板在编程场景中成了一个贯穿始终的减分项。
DeepSeek-V4-Pro的整体能力不及其他三家,Agent长程任务的稳定性以及代码生成质量均存在差距。
成本方面,本期测评的费用明细如下:
- Claude Opus 4.8,通过API测试,50美元;
- GPT-5.5,在Codex中使用,约2美元;
- MiniMax M3,我订阅的是Token Plan极速版,每月有12亿额度的M3 Token,本期大约消耗2000万token,折合约2元;
- DeepSeek-V4-Pro,大量输入命中缓存,不到2元。
换算下来总计356元,而两款国产模型加起来的费用还不到总金额的零头。性价比这件事,真是越来越不好意思讨论了。

写在最后
模型究竟好不好用,很多时候只有真正上手才知道,基准分数只是参考,而非定论。
至少从这几轮编码任务来看,Claude Opus 4.8的前沿地位依旧稳固。MiniMax M3也不差,大约处于Opus 4.7的水准,已经非常接近4.8了。
GPT-5.5或许在办公类任务上更具优势,但编程层面的审美问题并非小事,在编程场景中是一处明显的硬伤,而且这个问题不是靠调整提示词就能解决的。
DeepSeek-V4-Pro性价比依然极高,但此次测评也暴露了它在Agent适配、长程稳定性以及代码生成质量方面与另外三家的真实差距。差距并非追不上,只是需要时间。
说实话,这轮测试最让我感到兴奋的是几天前发布的M3。没想到它能如此接近Opus 4.8。1M上下文、原生多模态、编程达到SOTA水准,配合Token Plan的定价,真的可以胜任诸多任务。
如果你有想测试的场景,欢迎在评论区提出,咱们互相借鉴。我们下期见。