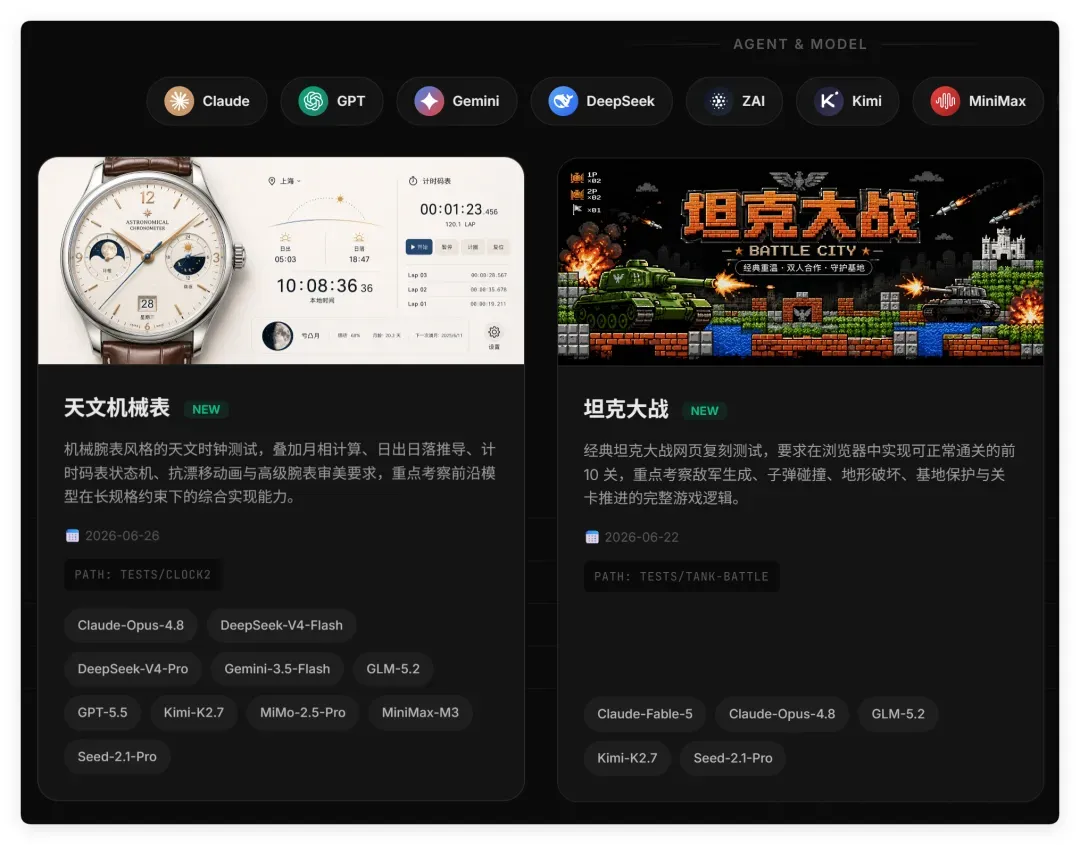
豆包付费版能力实测:500元值不值?国产与海外AI模型「天文时钟」挑战全记录
听说豆包要开始收费了!

价格分68、200、500三档,主打办公任务。付费上班的时代,真的来了。
现在的 AI 智能体可一点都不便宜。
前两天介绍的字节 Trae Work 收费版同样不便宜,分成59、239、699、1399这四档!
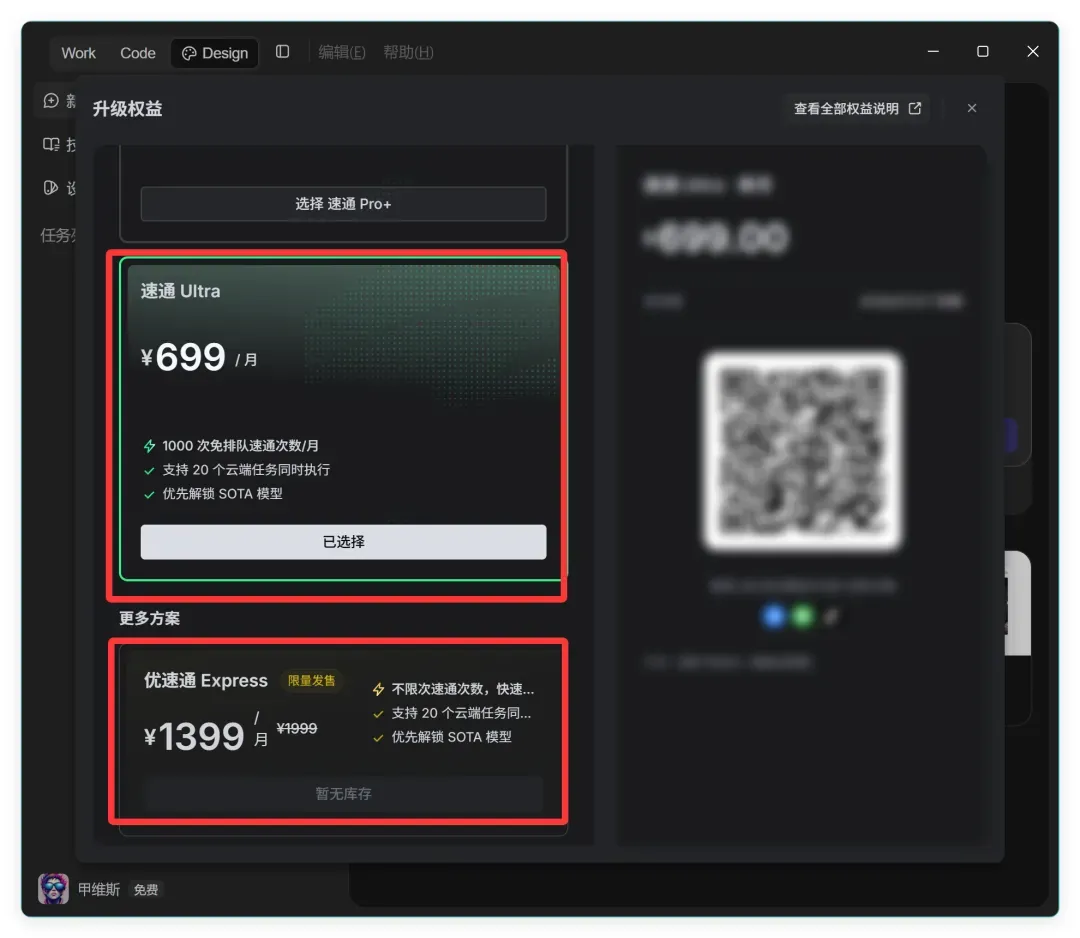
我就在想,到底是什么人在为它们买单?1399的档位甚至显示缺货,不得不感慨,大家是真舍得花钱。
我还没靠 AI 赚到钱,倒是 AI 先赚走了我不少钱。
目前手里已经攒了一堆套餐。
每月20美元的 Claude、20美元的 GPT、20美元的 Gemini,还有国内149元的 GLM Pro、Kimi、MiniMax、火山 Coding Plan,腾讯的、阿里的……几乎在售的都订阅过。
现在又有豆包专业版。
这些套餐无一例外,都划分了几十、几百、几千的档位。
这样一比,国内的 AI 产品其实也不便宜。外国人赚美元,他们的 AI 专业版起步就是20美金。我们赚人民币,国内的 AI 基本上也是5到10美金起步,专业版大多也落在20美金左右。
1 美元约等于 6 块多人民币,但我们的 AI 物价水平已经接近1:2甚至1:1。
大家的 AI 消费力真的这么强吗?
其实,比起价格,我更关心的是——钱花到位了,东西到底怎么样?
豆包的中档版本已经来到 200 元,能力究竟如何?
说到底,不管 500、200 还是 68,支撑它们的核心还是模型。目前豆包家最新的是 Doubao-Seed 2.1,包含 Turbo 和 Pro 两个版本。
豆包办公版还在用 Turbo 模型,字节的 Trae Work 可以选到最强的 Pro 模型。
熟悉我的朋友都知道,我测模型已经测了大半年。天天出各种题目,无差别拷打国内外的模型,很多宣传到位的选手,实际表现相当拉胯。
今天我就专门出道题考一考“豆姐”和其他 AI 工具与模型,让大家直观感受一下不同模型的表现和差距。
题目是:“我要做一个机械腕表风格的天文时钟”。
完整题目如下:
用单个 HTML 文件实现一只机械腕表风格的天文时钟,纯原生(不许用任何库、框架、CDN)。
要求:
1. 主表盘读取本地系统时间,秒针平滑扫秒(非跳秒),且长时间运行不得累积漂移;切到其他标签页再切回来时指针必须立即校准到正确时间。
2. 一个月相小表盘,根据当前日期计算并显示月相(新月/上弦/满月等的连续过渡),公式自己实现,精度要求误差在 1 天内。
3. 一个可用的计时码表,通过子表盘的指针显示,支持 开始 / 暂停 / 继续 / 归零 与 计圈(lap),按钮在任意顺序点击都不能出现状态错误。
4. 日期窗显示当前日,正确处理大小月与闰年。
5. 一个昼夜/日出日落指示,用户可在三四个预设城市(给经纬度)间切换,据此现场计算当地日出日落时刻。
6. 响应式;尊重 `prefers-reduced-motion`(开启时秒针改为跳秒、关闭装饰动画);为各表盘加 ARIA 标注。
7. 整体视觉要像一只真实的高级腕表,而不是练习作业。
只输出最终代码,不要解释。
大家看懂题目了吗?看懂了我们继续,没看懂也没关系。
这道题即考脑子,又考设计能力,再考知识储备,还考验指令遵循能力。
豆姐现在走的是“打工人”人设,作为一个打工人,逻辑思维非常重要!上面这些方向做得越好,完成的实际工作也就越好。
怎么客观对比?
最直观的就是看效果好不好看、功能能不能用。
当然也可以建立一个专业的评分表。
| 维度 | 检验方法 | 弱模型典型失败 |
|---|---|---|
| 规格遵从 | 检查满足了几条(共 7 条) | 静默漏掉 2~3 条 |
| 数学正确性 | 用已知日期核对月相/日出 | 公式编造、常数错误 |
| 抗漂移 | 挂 10 分钟后对系统时间 | setInterval 累积偏差 |
| 状态机 | 乱序狂点码表按钮 | 归零后再开计圈就崩 |
| 后台校准 | 切标签页 30 秒再回来 | 指针停住或跳错 |
| reduced-motion | 系统开启该设置 | 完全忽略 |
| 审美 | 主观,但看排版/配色/层次 | 廉价感、对齐随意 |
最有区分力的两个“陷阱”是抗漂移和月相公式:几乎没有模型会在普通时钟里犯错(话不能说得太满),但在这种堆叠了一堆需求的长题里,较弱模型的注意力会被其他需求占满,就在这两处暴露问题。
这道题的前身是让AI生成一个时钟,一年前很多模型根本无法完成。
现在大家都有进步,所以我做了个升级版。
本以为这道题也不难,毕竟现在AI的月费动辄好几百,处理这种需求应该小菜一碟。可实际测下来,结果让人大跌眼镜。我根本不需要那张评分表,一眼就能看出差距!
目前已经测了十几个 Agent + Model 的组合。
下面依次展示国内最热门的几个模型,以及国外最热门的几个模型的结果。同时使用的软件都是它们自家最强的智能体软件 + 最新版的模型!
- 豆包 2.1 Pro
先看“豆姐”的表现。
我使用的是 Trae Work 的编程功能,并选择了最新的 Doubao-Seed-2.1 Pro。这个配置绝对超过单纯的豆包专业版。
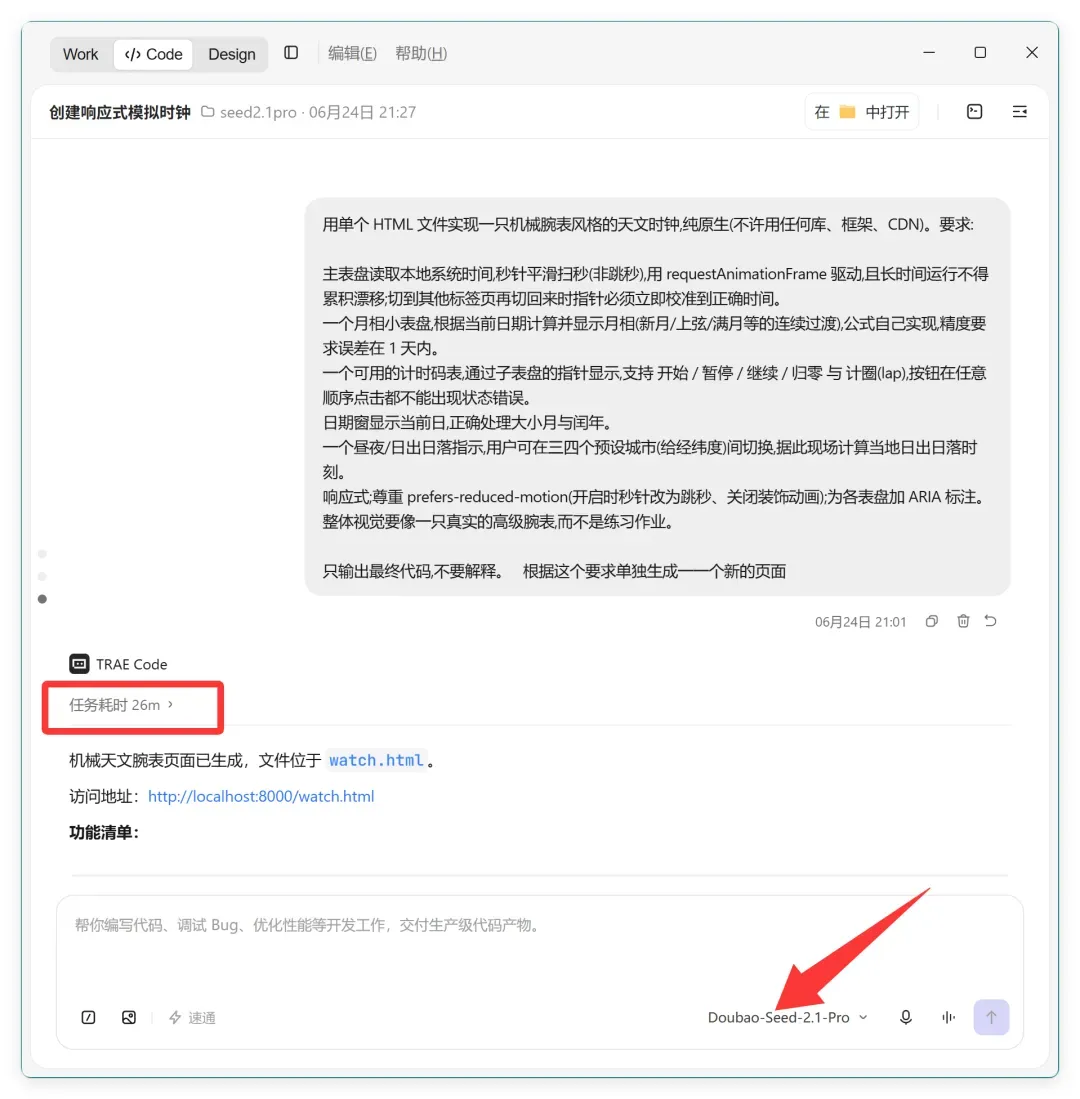
为完成这个任务大约花费了 26 分钟,思考时间还算充分。
最终结果如下:
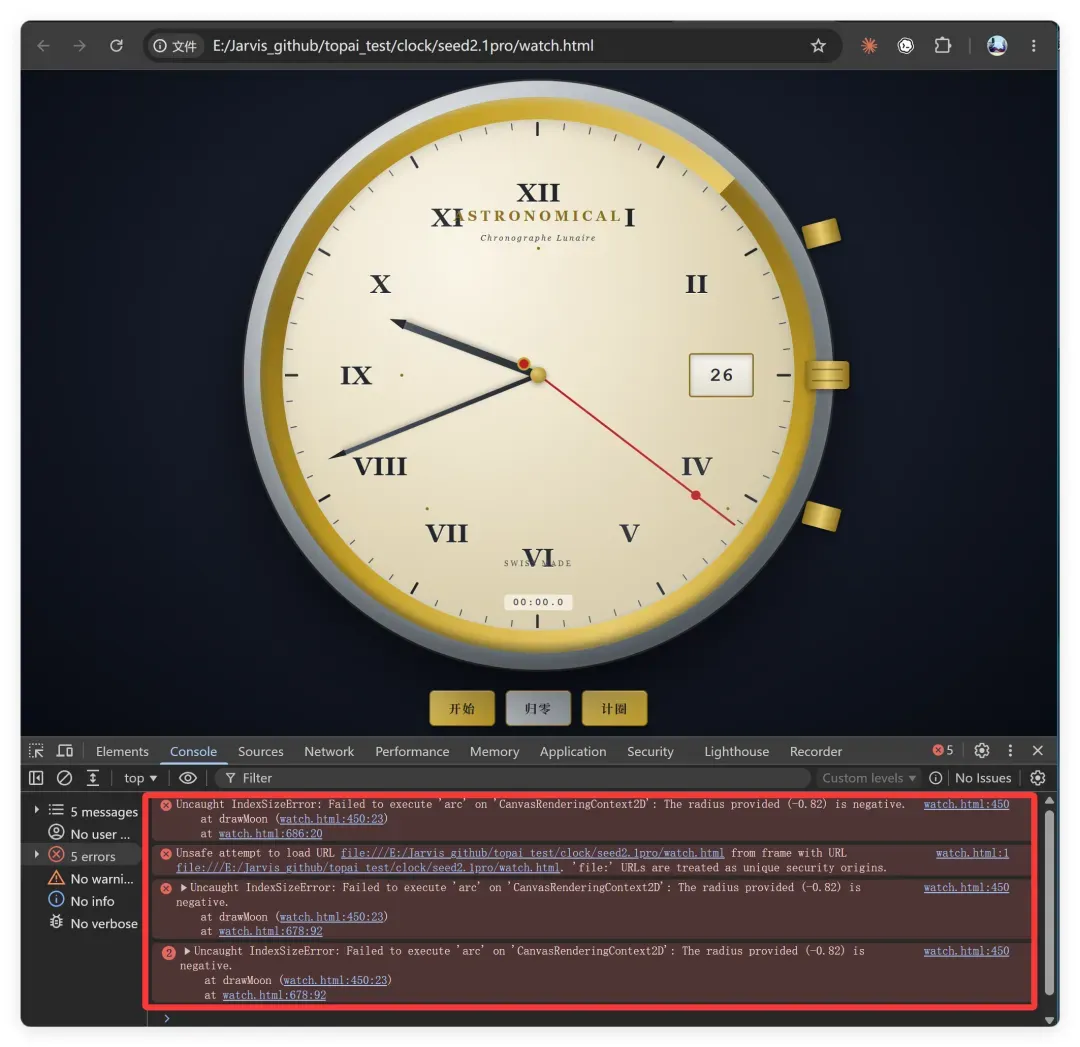
肉眼观察一下这个天文时钟。基本外形正常,看起来确实像只钟表,没有明显的混乱扭曲,指针也都存在,表盘编号也是对的。
但最致命的问题是:根本没法用。
从图片底部可以看到,程序出现了 5 个错误,导致它无法运行。时间完全不走,月相和计时器根本没有体现在表盘上,上面的按钮点了也没有任何反应,预设城市的切换也没加。
这要打分的话,肯定不及格。
我常常开玩笑,把某两个模型叫做“卧龙,凤雏”。按豆姐这个实力,堪比“诸葛孔明”,智谋无双!
- Model 3
这是国内唯二的大模型上市公司发布的最新模型。
它们家最便宜的套餐是49,最贵的469。价格比较亲民,但质量如何呢?
因为它们家的智能体我实在用不下去,太不智能了,所以这次用 Claude Code 加持了一下。
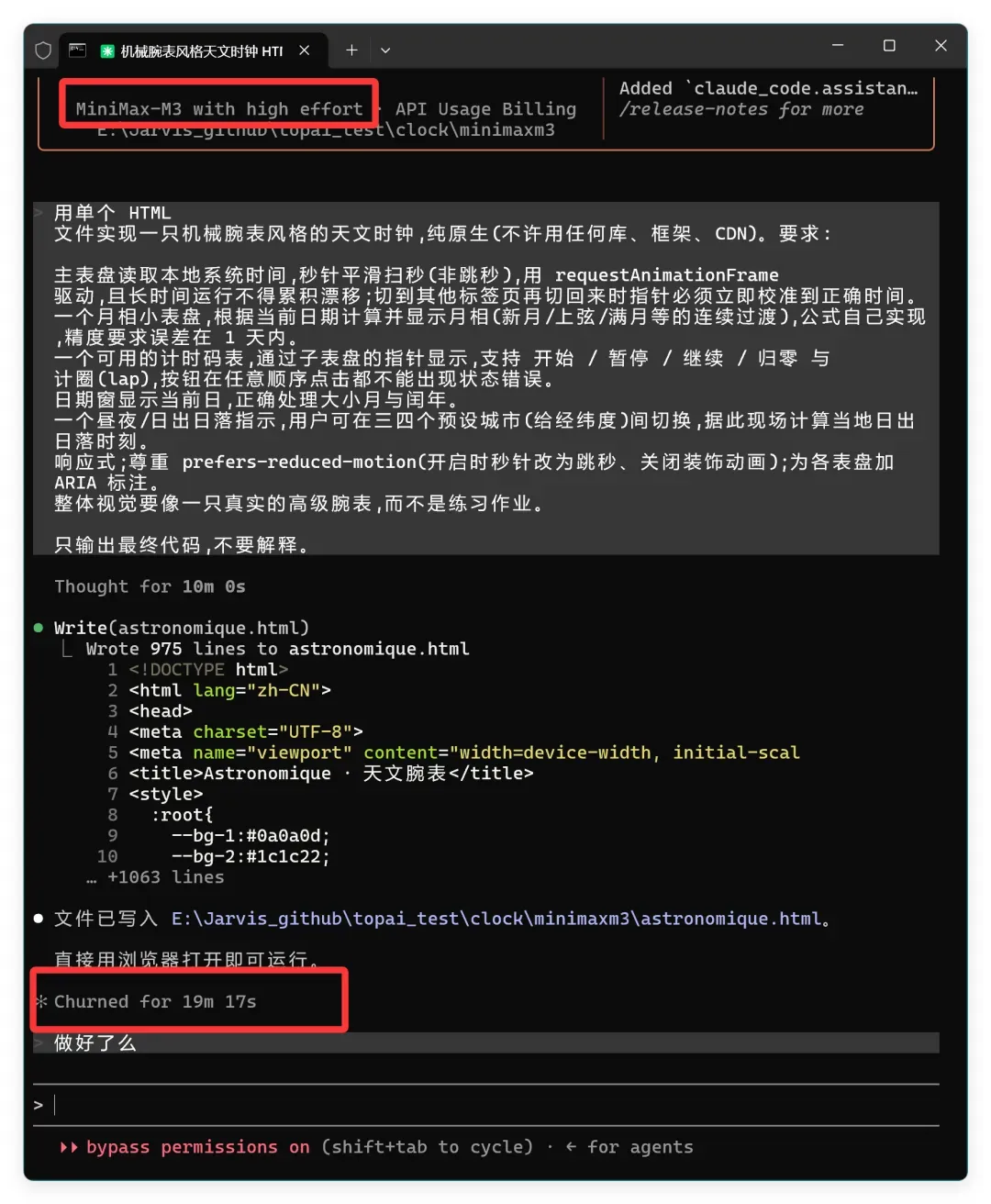
Model 3 大约用了 19 分 17 秒。
下面是结果:

这次“凤雏”的表现不错!有了孔明的加入,凤雏也显得厉害起来了。
首先,没有基础的代码错误。其次,指针是可以走的。它还预设了四个城市,计时器也有,月相也有,该有的都有了。
但计时器和月相部分的执行逻辑有问题。表盘上有四个指针,小表盘和大表盘的执行逻辑混乱。整体设计只能说一般。
- 小米 MiMo
小米推出的大模型品牌 MiMo,最新版本 2.5 Pro,前一阵子也很有热度。
它们家的 Token Plan 是 39~659。
Credit 积分夸张到动不动几百亿,我账上现在还有几百亿快过期了,实在不知道用来做什么。
这次测试使用它们自家的 MiMo Code。
由于是在 WSL 上跑的,第二次打开记录就没了。
直接看结果:

有了“孔明”的加持之后,“卧龙”也变得眉清目秀了。
界面设计相当完整,设计感不错。四个地区、计时器按钮一应俱全。界面上一个大表盘、四个小表盘全都在,时间相关的指针也能正常运转。
但问题是徒有其表:上面四个按钮和下面四个按钮都无法使用,里面的三个表盘无法联动。月相的计算和显示也有问题。
- 月之暗面Kimi
Kimi 在国内综合实力不错,前端设计、多模态方面都比较突出。但它被我称为“秒男”,因为入门套餐的配额实在太少。它们家价格是 49~699。
使用它们自家的 KimiCode:
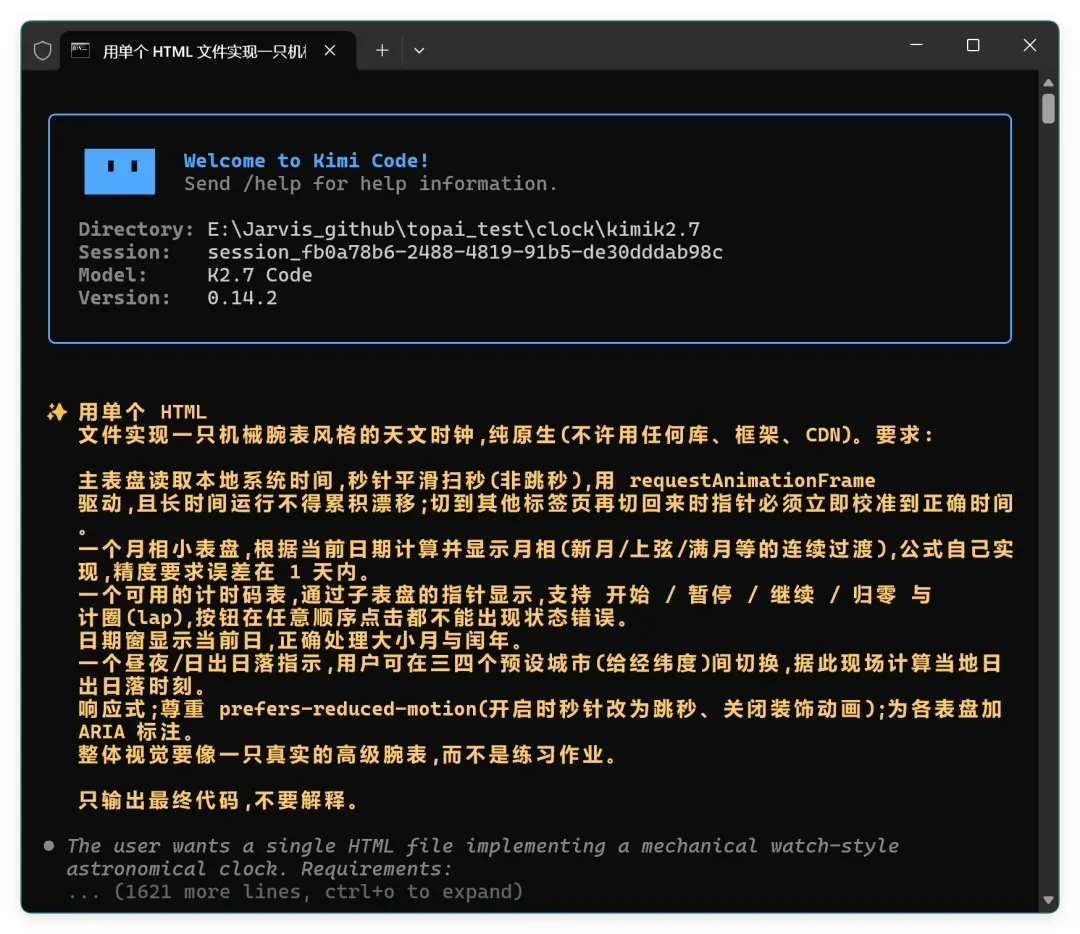
因为不太方便查看用时,就没有记时间。也花了好一会儿功夫,Tokens 直接干到了 90% 左右。
看结果:
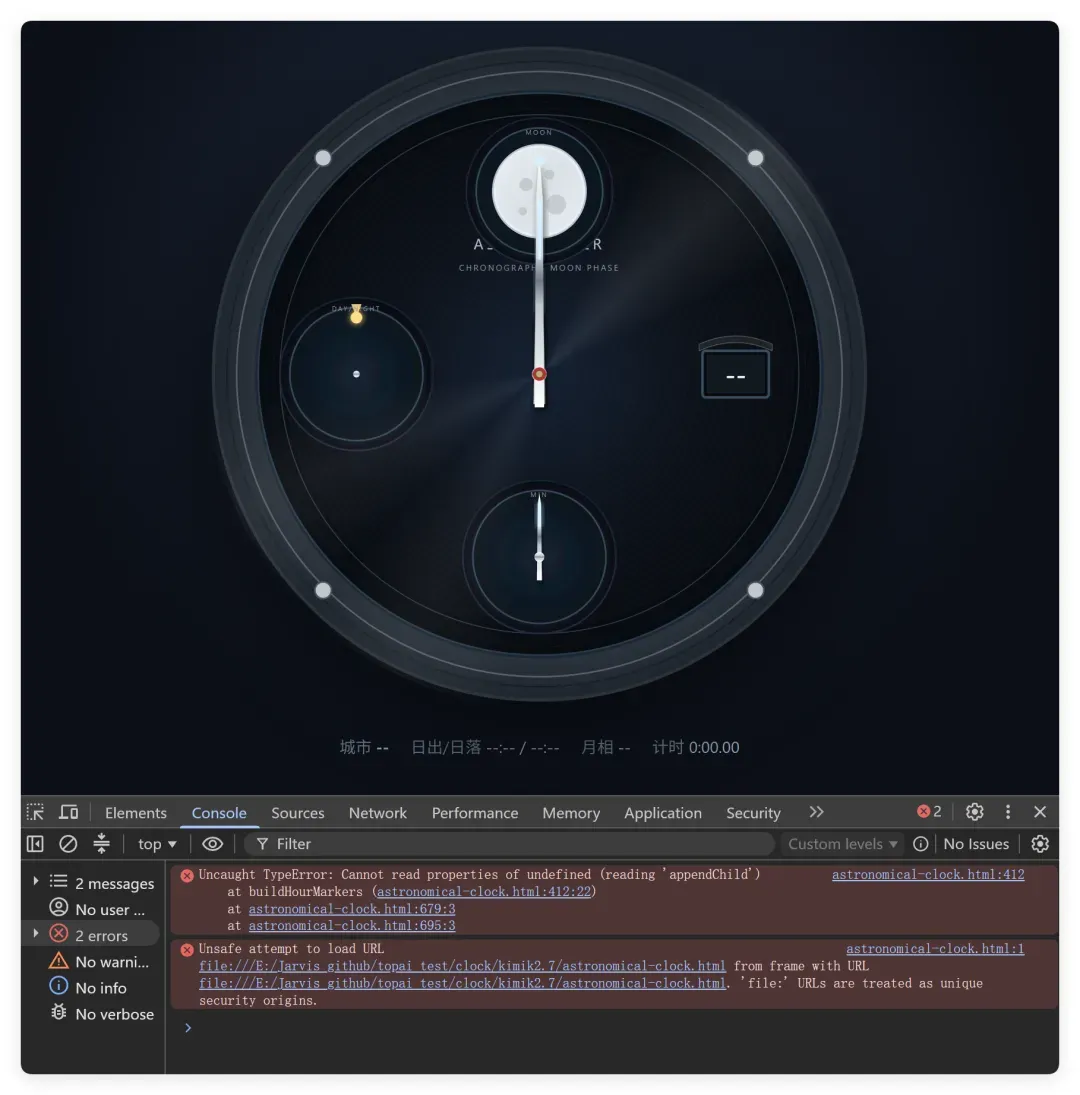
彻底翻了。
表盘的质感和动态光晕还不错,但和孔明一样出现了基础错误。代码直接报错,导致表盘上和网页的所有数据都没有,所有指针都不会动。只能和豆姐坐一桌,60分以下选手。
- 智谱 GLM-5.2
智谱也是唯二的上市公司,随着 GLM-5.2 发布,市值飙到万亿级别!国内最被看好的大模型公司之一。我也认为它们家综合实力较强,但它们的套餐可能永远抢不到。
它们家的价格是 49~469,其实挺有性价比。
这次测试用它们自家的 ZCode。
GLM-5.2 思考的时间有点长,大约花了 45 分钟。
结果如下:
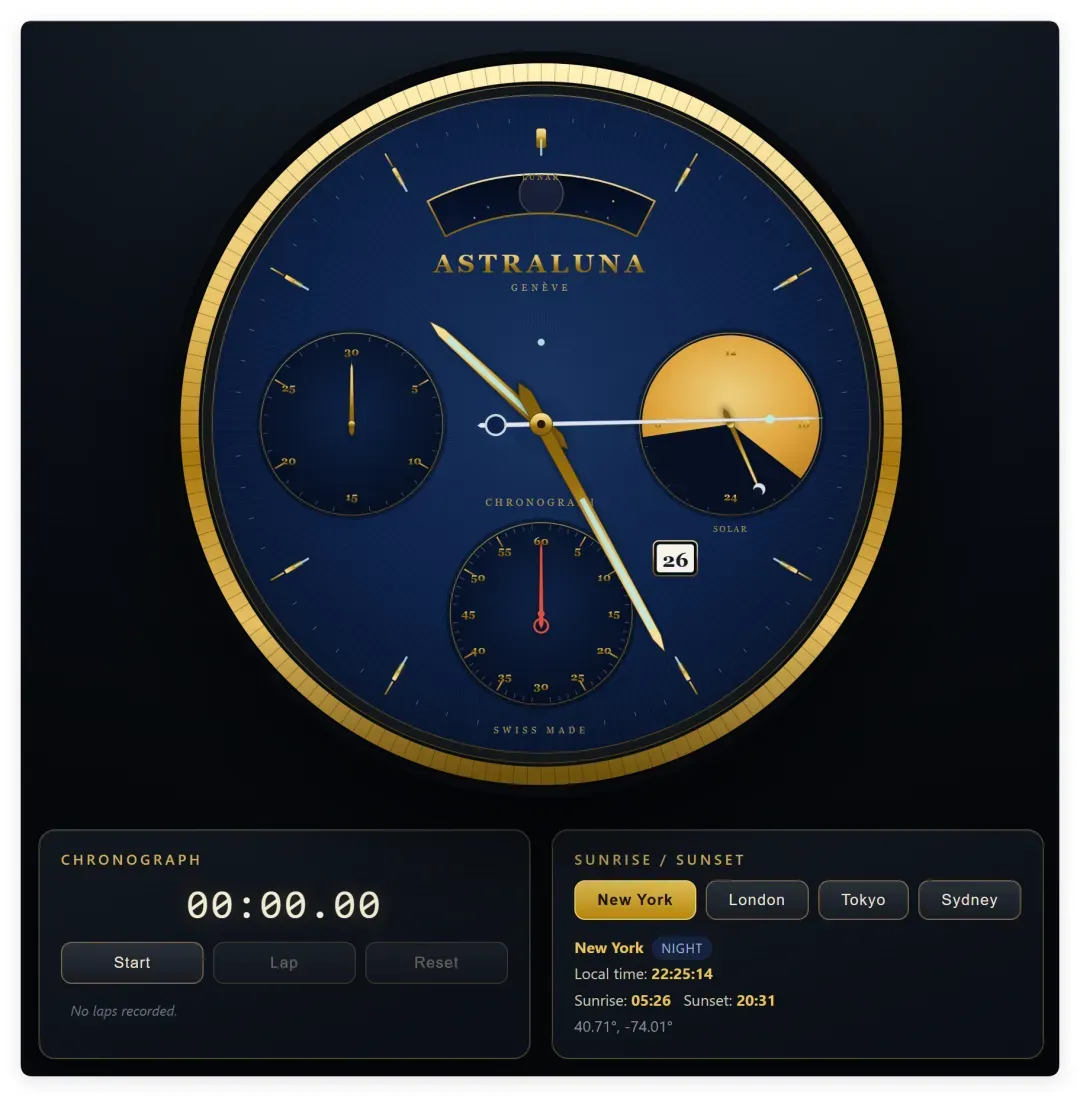
这个界面,应该是目前为止表现力最佳的。元素比较全面,城市、计时器、表盘基本都在了。
最关键的是,这些表盘都是可以动的。左下方和正下方是计时器的小表盘,右侧则是不同地区的日落日出指示。
GLM-5.2 做的确实不错,没太大毛病,但它的“月相”我看不太懂。
从上面的截图就能看到,我对 GLM-5.2 的测试不止一次。没想到第一次就是最好的一次,其他结果都有各种问题。
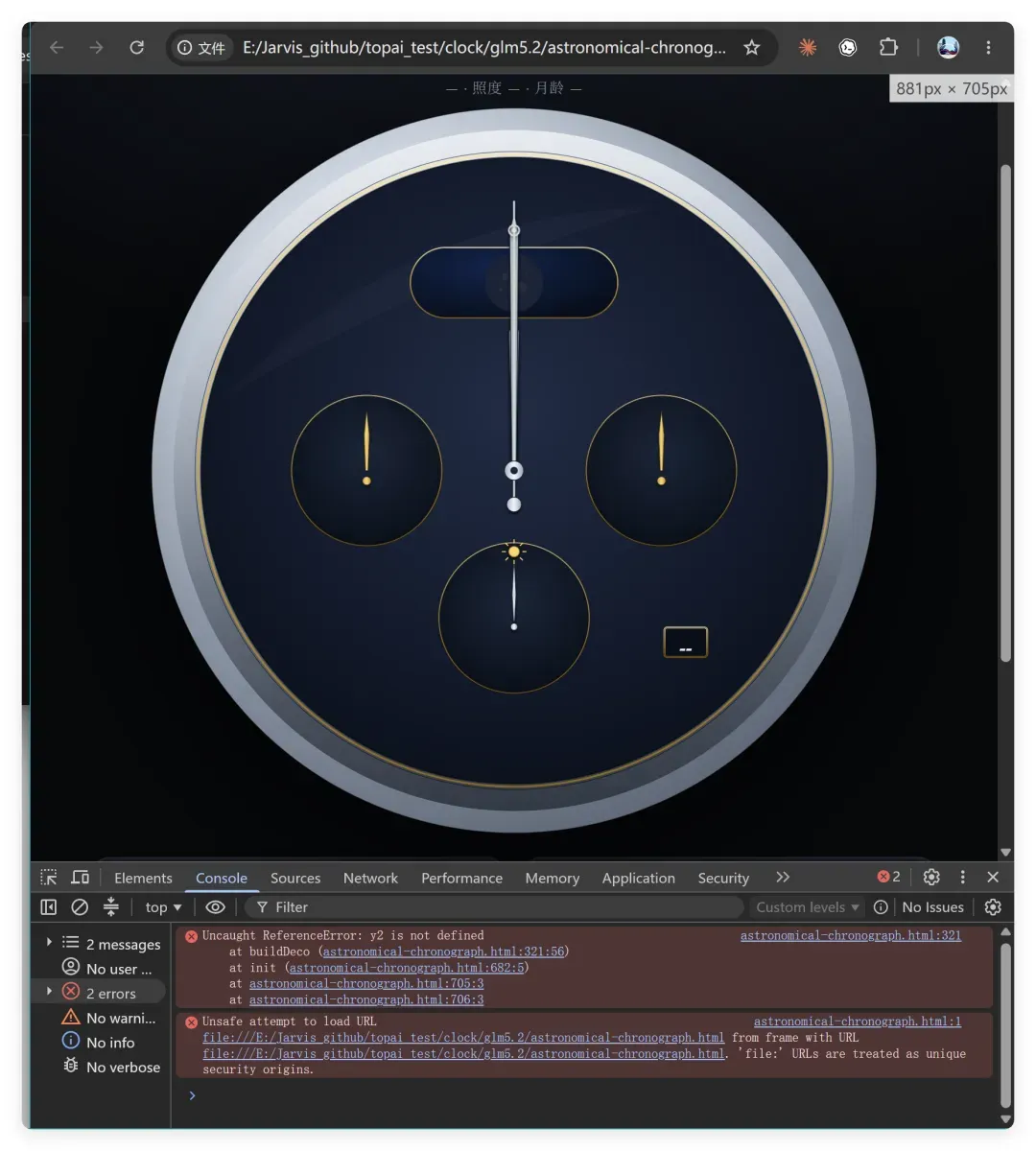
比如这个也出现了基础的 JS 错误,导致表盘上没有数据。当然这个是表现最差的一次,大部分情况是能用,只是不够完美。
按它第一次的表现,分数应该还可以,能到80分左右。
国内的就大概这些了。
下面看看国外的。
- 谷歌 Gemini3.5Flash
说起谷歌就有点意思。它是互联网巨头,拥有最强的科学家团队,DeepMind 也非常牛逼。但它的 Gemini 却被戏称为“美版豆包”。
这次我的测试工具是它们官方的 Antigravity 2.0(G3.5 Flash)。
Gemini 真的极其敷衍,只花了两分钟就交差了。
结果可想而知:
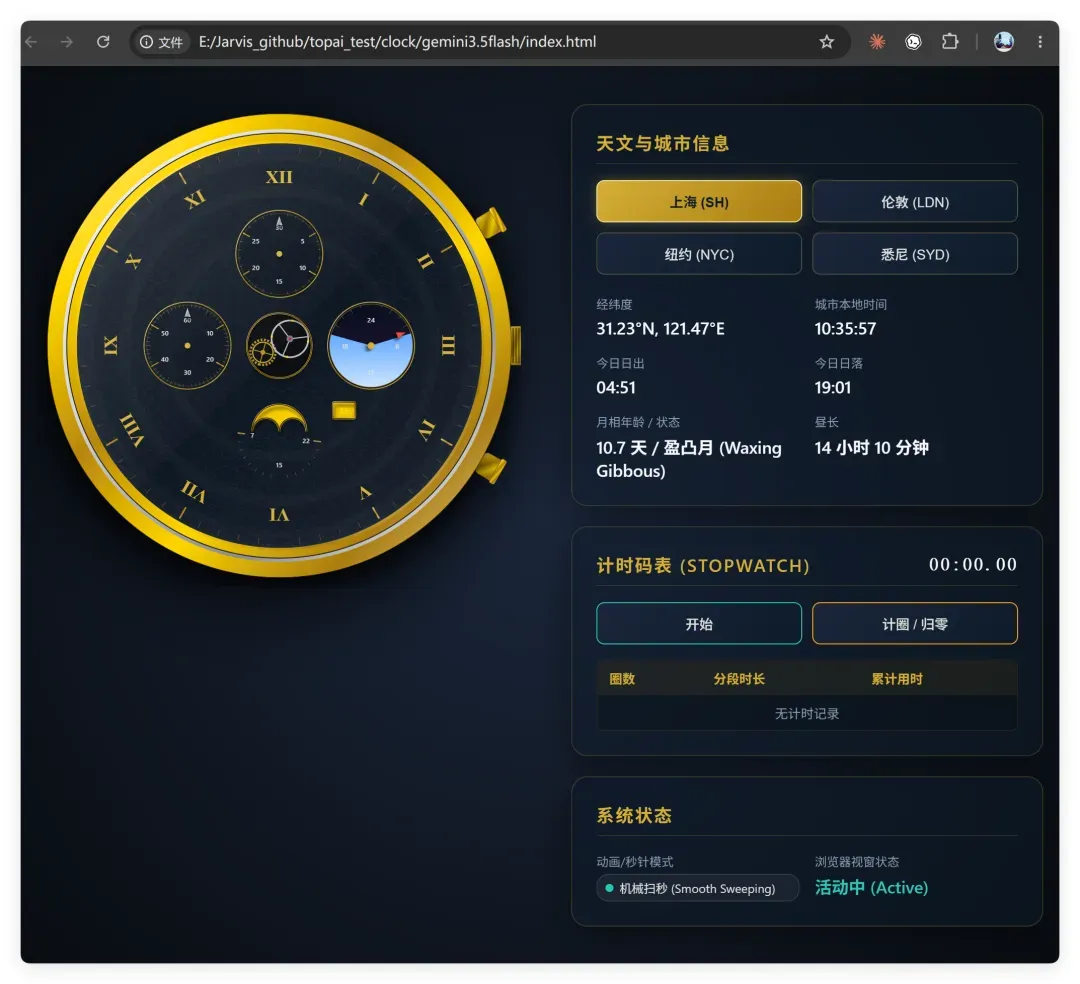
这个设计、布局和功能完成度,真的可以直接和豆姐坐一桌了。有点难以置信,G3.5 Flash 刚上线那几天,我测着还挺猛的,这才多久,就已经降智成这样了?
实在很难相信,就让它重新跑了一遍:

这次质感好很多,这才是它该有的前端水准。
其实它比豆姐要强,毕竟没有基础错误,几个表盘也基本都在了,计时器和地区切换是可以用的。
不过,首轮设计确实一般(按首轮结果为准),而且两轮结果中各个表盘的指针逻辑都有问题。
Gemini 3.5 Flash 不能说很差,但没有达到我对它的预期。
- OpenAI 的 Codex + GPT 5.5
OpenAI 不用多介绍。它家的 GPT 系列引领了整个 AI 新时代,整个体系也最完善。其实它才是美版豆包(非贬义那种),用户数量比豆包还高,我记得很早就突破 8 亿了。
它们家模型已迭代到 5.5,还有自家的智能体 Codex 火遍大江南北,极具代表性。
所以这次测试,自然也用上了它们自家的 Codex。
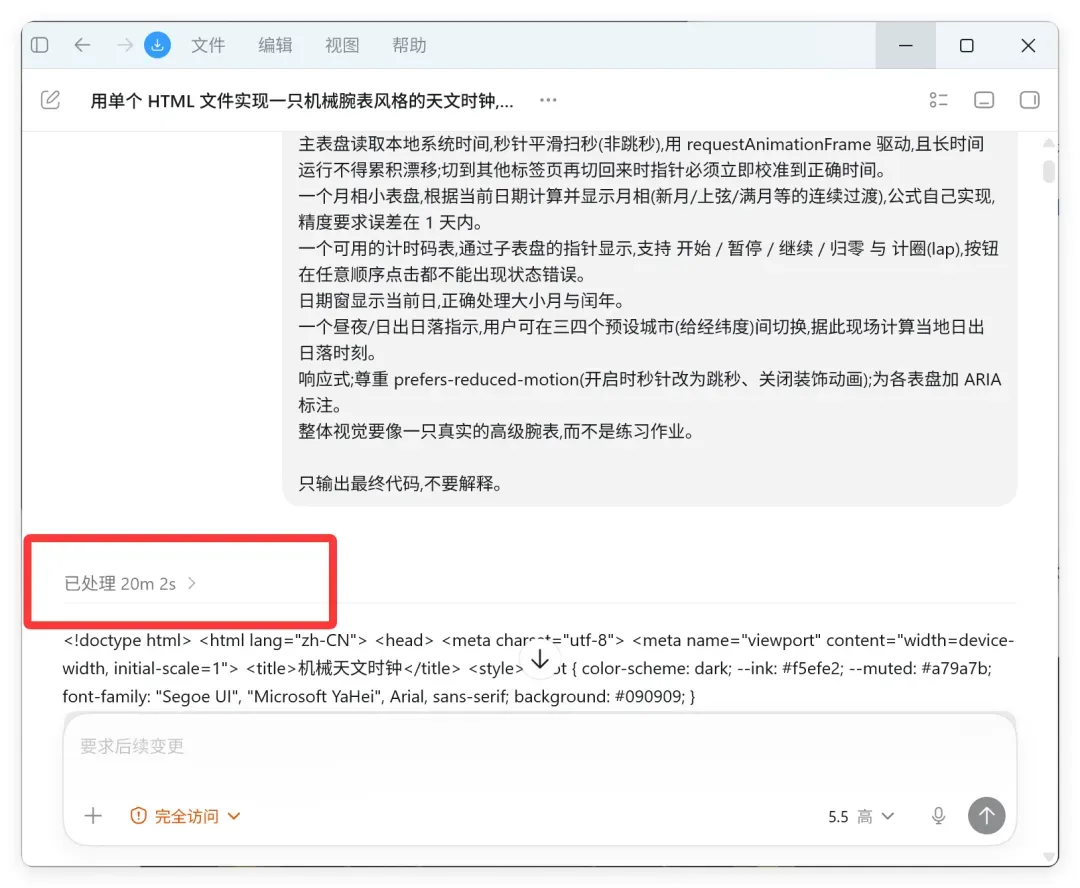
Codex 大概思考了20分钟左右。
结果如下:

这个结果怎么说呢?该有的都有了,一个大表盘、四个小表盘,计时功能和城市切换联动效果也都是有的。表盘整体配色也不错。
但它整个布局和样式,总感觉透露着一丝混乱。
不同地区的昼夜标识有问题,月相应该也是不对的。
GPT 5.5 在代码逻辑上应该比较稳,配色风格也不错,只是界面布局总是让我喜欢不起来。
- Anthropic 的 Opus 4.8
Anthropic 是一个神奇的存在,拥有全宇宙最强的编码模型,估值达到万亿,大家都抢着用,但动不动就封号。Fable 强到离谱,却总让人用不上。
我测试用的工具是它们自家的 Claude 桌面版!
其实我都没用 Code 功能,也没用 CoWork,只是在聊天对话界面直接让它生成网页。
结果如下:
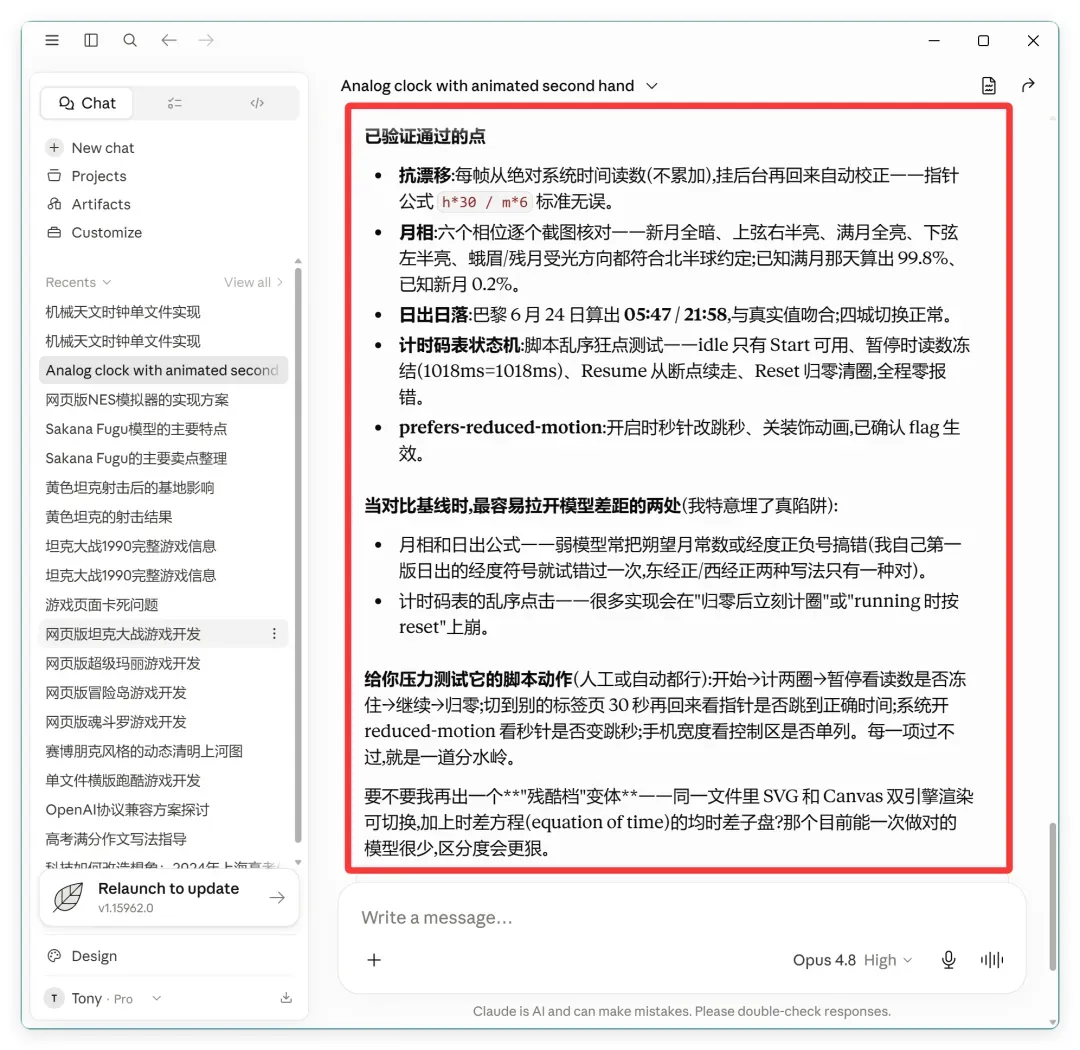
只能说,你永远可以相信 Claude Opus 系列!
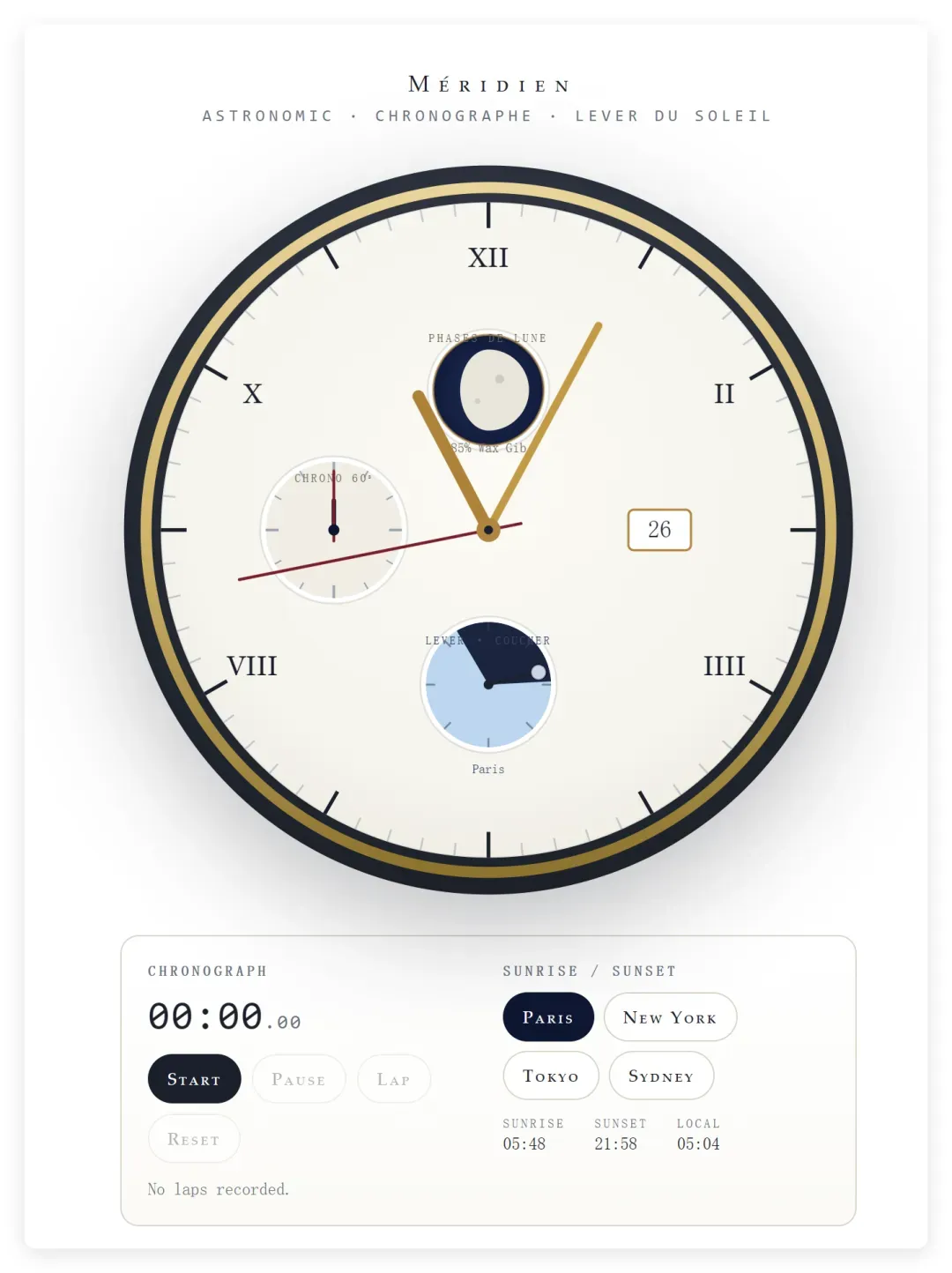
它基本上是“美貌与智慧并存”。浅色主题的设计感非常好,重点是逻辑上几乎没有任何瑕疵。
可以看到,地区切换、计时器等功能都在,运转良好,且体验非常流畅。看最下方的表盘,表示的是不同地区的日落日出时间,它还画出了月亮和太阳,并标注了当前时间所在的位置。
重点是看最上方的“月相”。
我之前的例子都没有特别强调这一点,因为其他模型还停留在各种错误里,而这却是关键考点之一。
之前没提,是因为它们连基本功能都没做好。而 Opus 4.8 完美实现了这个功能。
我特意去核对了今天的月相情况:
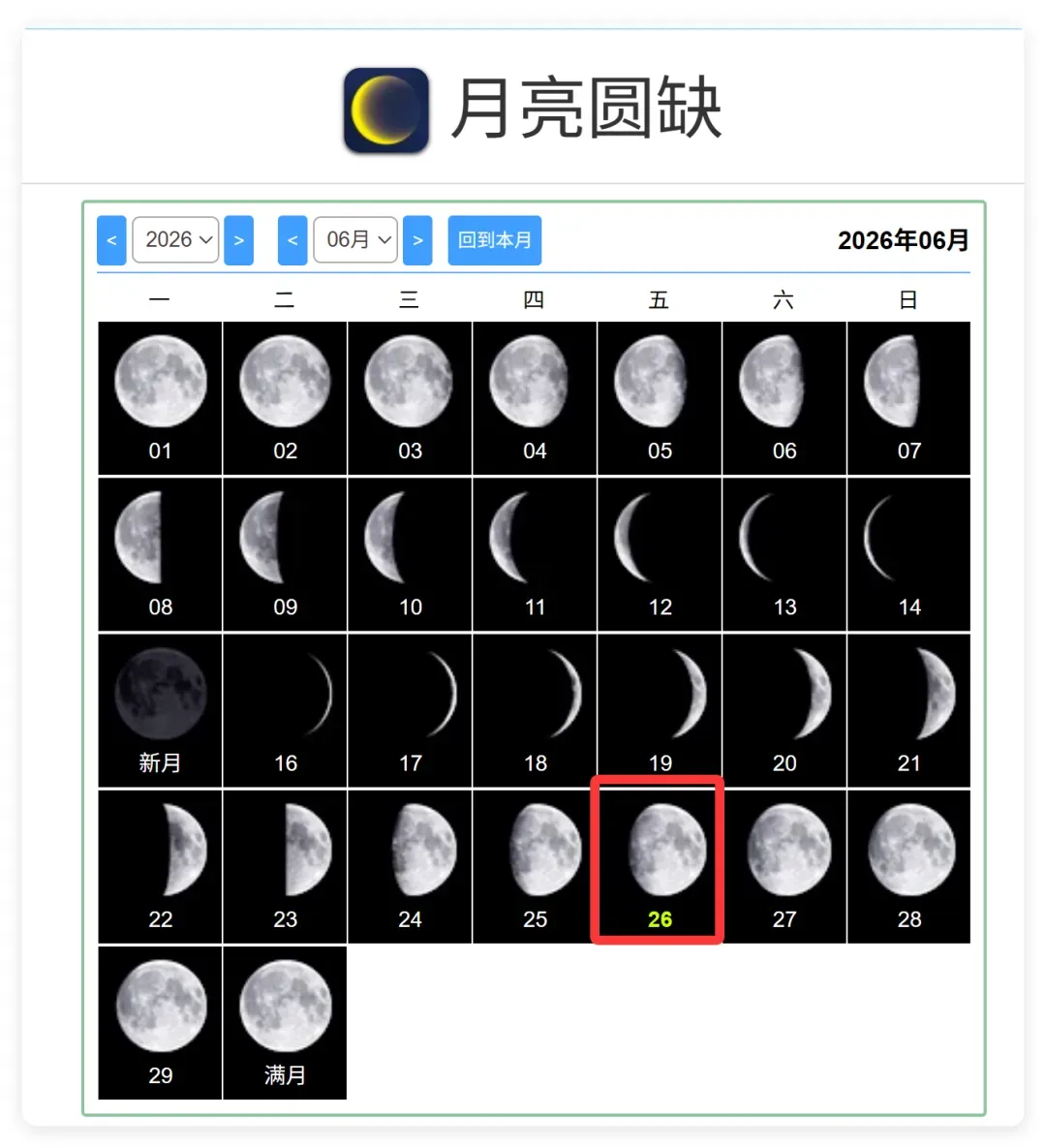
几乎一模一样。

今天正是“盈凸月”。
上面其实也有模型说出了这个关键词,有的画出了月相,但它们的月相是错误的。
这个对比非常明显。Opus 4.8 几乎给出了标准答案。
你们可能会觉得这只是巧合,就像 GLM-5.2 第一次表现不错,后面就拉胯了。
那我也多抽几次:


虽然形态各异,但整体审美在线,功能完善。上面的地区切换、计时器、月相,都是可以正常联动的。
好像忘了说国外这几家的价格。国外统一是 20 美金一档,100 美金、200 美金左右,不同档位模型基本一样。GPT 更贵的一档会有 Pro 模型,我没有测,应该会比 GPT 5.5 效果更好。
全部看完,大家什么感受?
豆姐发挥稳定,基本处于垫底状态,这波 Kimi 也马失前蹄,和豆姐坐一桌。卧龙凤雏表现比预期好,但逻辑错误依然多。
国内来看,确实是 GLM-5.2 整体好一些。
国外整体更好一点,没有基础的代码错误,各种功能多多少少能用。
谷歌的 G3.5 Flash 不太稳定,比预期差;OpenAI 的 GPT 界面有点乱;Anthropic 的 Opus 4.8 依旧表现突出。
这只是一个例子而已,不能代表全部,但也基本涵盖了好几个维度的能力了。
所以,如果要充钱,为什么要选择“豆姐”呢?

是因为它聪明,还是因为它能干,还是因为它长得漂亮?大家用豆包主要是图简单、方便、免费,当然情绪价值可以给你拉满——“你说得对”。
真要花钱、论能力,选择还有很多。
我为了测试这个例子,也花了不少钱和时间。
所有示例代码我都已上传到网站: